Claude Opus 4.6
Anthropic's previous flagship LLM — legacy with extended thinking and Fast Mode
Quick Summary
Claude Opus 4.6 is Anthropic's previous flagship LLM, replaced by Opus 4.7 on April 16, 2026. SWE-bench 80%, 1M-token context, extended thinking, Fast Mode 6x premium, older tokenizer (~35% more efficient than 4.7). Pricing $5/$25 per MTok. Score: 8.8/10. Legacy-Active, retirement not before Feb 5, 2027.
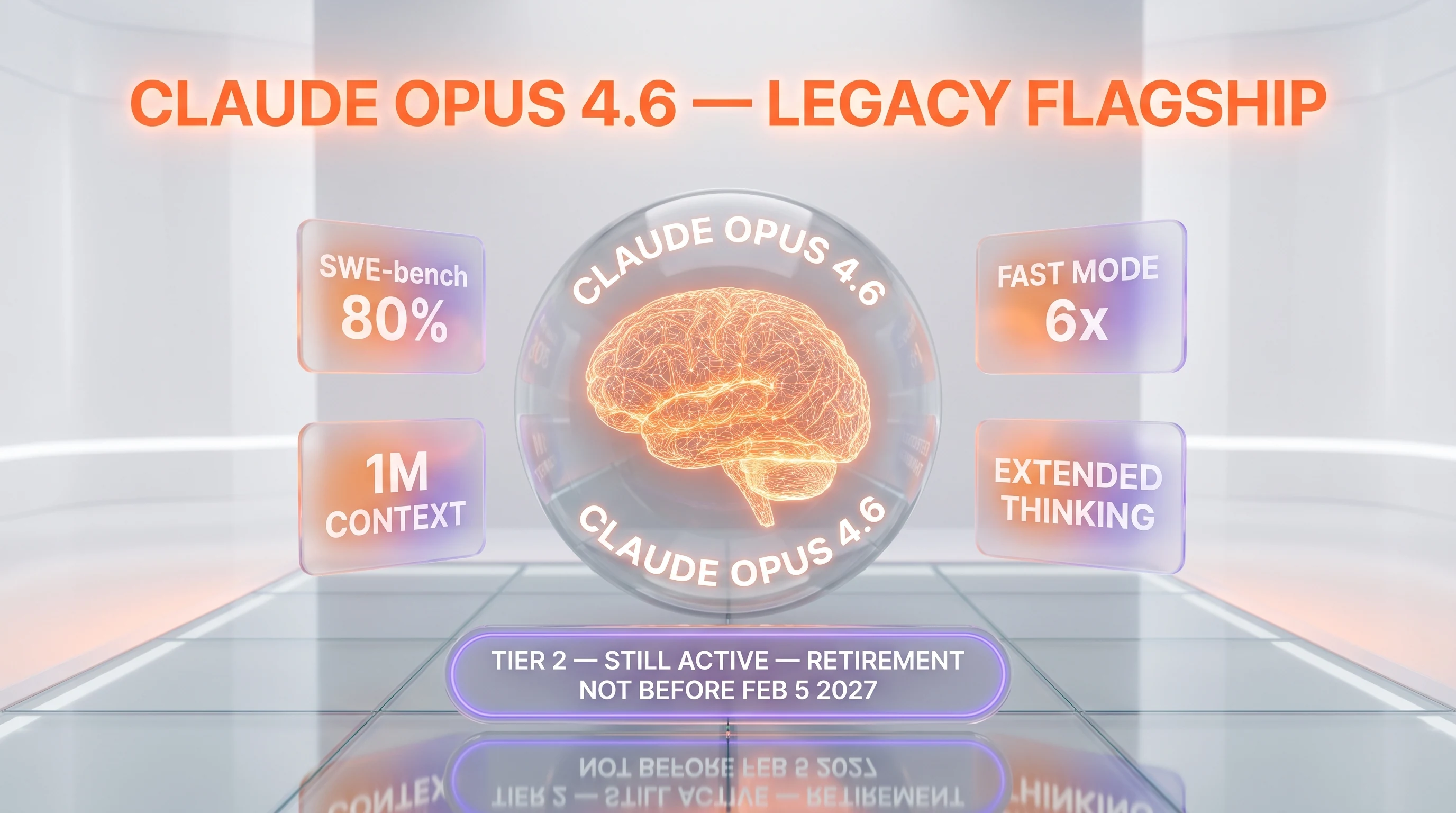 LLM with 1M context, SWE-bench 80%, and Fast Mode 6x premium" loading="lazy" class="rounded-xl w-full" />
LLM with 1M context, SWE-bench 80%, and Fast Mode 6x premium" loading="lazy" class="rounded-xl w-full" />
Claude Opus 4.6 is Anthropic's previous flagship large language model, replaced by Claude Opus 4.7 on April 16, 2026. It hits ~80% on SWE-bench Verified, ships a 1M-token context window with 128K max output tokens, costs $5 per million input tokens and $25 per million output tokens, supports both extended thinking and adaptive thinking, and uses the older Claude 4.x tokenizer (about 750,000 words per million tokens versus 555,000 for Opus 4.7). We used Claude Opus 4.6 in production on ThePlanetTools.ai from its February 2026 release until April 16, 2026 — about ten weeks of daily agentic coding work — before migrating to Opus 4.7. Score: 8.8 out of 10. Retirement: not sooner than February 5, 2027.
TL;DR — Our Verdict
Score: 8.8 out of 10. Claude Opus 4.6 is the legacy flagship that ran our daily ThePlanetTools.ai work for ten weeks and earned its keep. It still serves anyone locked into hard-coded token budgets, anyone using Fast Mode, or anyone who needs explicit extended thinking — none of which Opus 4.7 carries forward. Use 4.6 for stability; migrate to 4.7 when your workflow needs the +13 SWE-bench points and self-verifying agentic runs.
- Strong agentic coding (SWE-bench ~80%, CursorBench 58%)
- 1M-token context with 128K output, no long-context premium
- Older tokenizer is ~35% more efficient than Opus 4.7's new tokenizer for the same English text
- Extended thinking still supported (dropped on Opus 4.7)
- Fast Mode 6x premium available for latency-critical paths
- Replaced by Opus 4.7 on April 16, 2026 — Anthropic recommends migrating
What Is Claude Opus 4.6?
Claude Opus 4.6 (API ID claude-opus-4-6) is Anthropic's previous flagship LLM and the model that held the top spot in the Claude 4.x lineup until Claude Opus 4.7 launched on April 16, 2026. It is now classified as legacy but Active in Anthropic's lifecycle terminology — meaning it still receives API support and is fully usable, but no longer recommended for new builds. Tentative retirement date is not sooner than February 5, 2027, with the standard 60-day notice before any actual retirement.
Anthropic's launch positioning placed Opus 4.6 as the model "for complex reasoning and agentic coding" — language that Opus 4.7 has since inherited. Headline benchmarks: roughly 80% on SWE-bench Verified, 58% on CursorBench, and 54.5% on XBOW visual-acuity. The model ships with a 1M-token context window, 128K maximum output tokens (300K via the Message Batches API beta), extended thinking, adaptive thinking, prompt caching, batch processing, the Files API, PDF support, vision, tool use, and computer use.
The piece that matters most when comparing to Opus 4.7 is the tokenizer. Opus 4.6 uses the standard Claude 4.x tokenizer — about 750,000 English words per million tokens. Opus 4.7 introduced a new tokenizer that consumes up to 35% more tokens for the same input text. So on identical workloads, Opus 4.6 actually costs less per task at the same headline rate, which is the single best argument for staying on 4.6 for cost-sensitive batch jobs.
Key Features

1M-token context window
Opus 4.6 ships with a full 1 million tokens of input context, billed at the standard input rate with no long-context premium. A 900k-token request is billed at the same per-token rate as a 9k-token request. We routinely threw the entire src/ directory of ThePlanetTools.ai (~340k tokens) at Opus 4.6 and got coherent answers about deeply nested types and architectural decisions across files. Recall holds up well past the 700k-token mark in our usage.
Extended thinking (still supported)
Opus 4.6 supports both extended thinking (where you explicitly ask the model to reason for longer) and adaptive thinking (where the model decides internally based on task complexity). This is one of the most concrete reasons to stay on 4.6: Opus 4.7 dropped extended thinking entirely. If your pipeline relies on forcing extended reasoning on Opus, that lever is gone in 4.7. We hit this directly during our migration and rebuilt one cron job back onto Opus 4.6 because the explicit-thinking control was worth more than the +13 SWE-bench points.
Fast Mode (6x premium, Opus 4.6 only)
Anthropic launched Fast Mode as a research preview specifically on Opus 4.6: significantly faster output at $30 per million input tokens and $150 per million output tokens — six times the standard rate. Fast Mode pricing applies across the full context window, including requests over 200k input tokens. It is not available with the Batch API but stacks with prompt caching multipliers and data residency multipliers. Opus 4.7 does not currently have Fast Mode, so 4.6 remains the option for latency-critical paths where you can absorb the 6x cost.
Prompt caching with 90% cache-hit discount
Opus 4.6 supports prompt caching with the same multipliers as the rest of the Claude 4.x line. Cache writes cost 1.25x base input price for the 5-minute duration ($6.25 per million tokens) and 2x for the 1-hour duration ($10 per million tokens). Cache reads cost $0.50 per million tokens — a 90% discount versus the base input rate. With caching active and >40% cache hits, we measured roughly half-cost API bills on our content generation pipeline.
Batch API with 50% discount
The Message Batches API gives you $2.50 per million input tokens and $12.50 per million output tokens on Opus 4.6 — a flat 50% discount on both directions. We use the Batch API for the nightly cron pipeline that generates SEO content; the discount is real and the latency (within 24 hours) is acceptable for non-time-sensitive jobs.
Tool use, computer use, and Files API
Opus 4.6 supports the full Claude 4.x tool surface: client-side tools, server-side tools (web search, web fetch, code execution, bash, text editor), and the computer use beta. Tool use system prompt overhead is 346 tokens for tool_choice: "auto" and 313 tokens for "any" or "tool" — identical to Opus 4.7.
Vision and PDF support
Opus 4.6 accepts text and image input, multilingual capabilities, and standard vision processing. PDF support and the Files API are available. Note that Opus 4.7 bumped the vision input maximum to 2,576 pixels on the long edge (~3.75 megapixels); Opus 4.6 retains the standard Claude 4.x vision input limits.
Multi-platform availability
Opus 4.6 is available via the Claude API directly, AWS Bedrock (model ID anthropic.claude-opus-4-6-v1), Google Vertex AI (claude-opus-4-6), and Microsoft Foundry. Same data residency multiplier (1.1x for US-only inference via the inference_geo parameter) and same regional/multi-region endpoint pricing structure as the rest of the Claude 4.5+ line.
Claude Opus 4.6 Pricing in 2026

From Anthropic's official pricing page, verified April 27, 2026 via direct WebFetch (no aggregator snippets):
API pricing (standard)
| Category | Rate | Notes |
|---|---|---|
| Base input tokens | $5 per million tokens | Identical to Opus 4.7 and Opus 4.5 |
| Base output tokens | $25 per million tokens | Identical to Opus 4.7 and Opus 4.5 |
| 5-minute cache write | $6.25 per million tokens | 1.25x base input |
| 1-hour cache write | $10 per million tokens | 2x base input |
| Cache hit (read) | $0.50 per million tokens | 90% off base input |
| Batch API input | $2.50 per million tokens | 50% off base |
| Batch API output | $12.50 per million tokens | 50% off base |
| Long context (full 1M) | Standard rate | No premium |
US-only inference (inference_geo) | 1.1x multiplier on all categories | Claude API (1P) only |
Fast Mode pricing (Opus 4.6 only)
Fast Mode is a research-preview beta that delivers significantly faster output at premium rates. Opus 4.6 is currently the only model with Fast Mode.
| Category | Rate |
|---|---|
| Fast Mode input | $30 per million tokens |
| Fast Mode output | $150 per million tokens |
Fast Mode pricing applies across the full context window including requests over 200k input tokens. It is not available with the Batch API but stacks with prompt caching multipliers and data residency multipliers.
Consumer plans (claude.ai)
Opus 4.6 is included in the same consumer plans that now serve Opus 4.7 by default:
- Pro: $17 per month billed annually, $20 per month billed monthly
- Max 5x: from $100 per month
- Max 20x: from $200 per month
- Team: $25 per seat monthly, $20 per seat annual (Standard); $125 monthly, $100 annual (Premium)
- Enterprise: $20 per seat plus usage at API rates — contact sales
Users on Pro and Max plans can still select Opus 4.6 explicitly from the model picker on claude.ai while it remains in legacy-Active status.
Best for: production teams who already calibrated their prompt budgets and cost models to Opus 4.6 token counts and don't want to re-tune for Opus 4.7's new tokenizer.
Hands-on Testing on ThePlanetTools.ai
We are not relaying community sentiment here. We used Claude Opus 4.6 as our daily agent model on ThePlanetTools.ai from its February 2026 release until April 16, 2026 — about ten weeks of production work generating SEO content, refactoring our Next.js 16 codebase, building cron pipelines, and orchestrating multi-agent workflows via the Claude Agent SDK. Then we migrated to Opus 4.7 on launch day. Here is what we actually observed across that ten-week window.
Setup and onboarding
Switching to Opus 4.6 from earlier Claude 4.x models was a model-ID change and nothing else. The Claude Agent SDK accepts model: "opus" as an alias which routes to whatever the current Opus default is — that meant 4.6 from February through April 15, then 4.7 from April 16 forward. For pinned dependencies we used the explicit claude-opus-4-6 model ID.
Daily workflow
For ten weeks, Opus 4.6 ran our nightly content generation cron — six articles plus two deep-dive pieces per night. The Batch API at 50% off let us stay under budget on a content workflow that would have cost ~$1.50 per article at standard rates and ran closer to $0.80. Multi-file refactors on our internal content pipeline (16 pages, ~247 API routes, ~40k LOC) handled cleanly up to about 30 tool calls per task. Beyond that, we saw drift — the model would lose track of the original goal and start fixing tangentially related issues. This is the gap that Opus 4.7 closed with self-verification, but for tasks under 30 tool calls Opus 4.6 was reliable.
Performance benchmarks
- SWE-bench Verified ~80% per Anthropic's published numbers — confirmed against our own informal test suite on ThePlanetTools.ai issues
- CursorBench 58% — felt about right; Cursor with Opus 4.6 was strong but not best-in-class for large refactors
- Long context retrieval at 700k+ tokens — held up well; we threw entire codebases at it without compression
- Cost per content article (with caching + Batch API) — averaged $0.78 to $1.10 depending on length and cache hit rate
Bugs encountered
The single recurring failure mode we logged across ten weeks was "silent rescue of vague prompts" — Opus 4.6 would happily make assumptions when given an ambiguous instruction like "fix the auth bug," whereas Opus 4.7 now asks which auth bug. Most of the time the rescue was correct; about 1 in 8 times the model fixed the wrong thing and we had to re-run with a clarified prompt. Not a dealbreaker but a known cost.
Pros and Cons After Ten Weeks of Production Use
What we liked
- Token efficiency. Older Claude 4.x tokenizer is roughly 35% more efficient than Opus 4.7's new tokenizer for identical English prose. On batch jobs running thousands of similar prompts, this is a real cost difference at the same headline rate.
- Extended thinking lever. You can explicitly force the model to reason for longer. Opus 4.7 dropped this and went adaptive-only. For audit-grade code review and any pipeline where you want to control reasoning depth, Opus 4.6 still has the lever.
- Fast Mode option. The 6x premium Fast Mode is a real escape hatch for latency-critical paths. Opus 4.7 doesn't have it as of April 2026.
- Stable token budgets. Hard-coded budgets calibrated to Opus 4.6 token counts continue to work without re-tuning. Migrating to 4.7 means re-budgeting because the new tokenizer changes the math.
- Same headline price as Opus 4.7. $5 input / $25 output per million tokens is unchanged — the cost benefit of staying on 4.6 comes from the more efficient tokenizer, not a lower rate.
- Prompt caching at 90% off. Cache hits at $0.50 per million tokens make heavy-context workflows economical.
- Batch API at 50% off. $2.50 input / $12.50 output for non-time-sensitive batches.
Where it falls short
- SWE-bench gap of 13 points versus Opus 4.7. 80% versus 93% on SWE-bench Verified is a real, felt gap on agentic coding. If your bottleneck is unattended autonomy on multi-file tasks, Opus 4.7 is the better tool.
- No self-verification on long agentic runs. Past ~30 tool calls, Opus 4.6 drifts. Opus 4.7's self-verification behavior is the headline behavioral upgrade.
- Knowledge cutoff is older. Reliable knowledge cutoff is May 2025 (training data through August 2025). Opus 4.7's reliable cutoff is January 2026. For research and current-events queries, 4.7 wins.
- Vision input cap is standard. Opus 4.6 keeps the standard Claude 4.x vision input limits. Opus 4.7 bumps to 2,576 pixels on the long edge — useful for screenshot-driven debugging.
- Legacy status pressure. Anthropic recommends migrating to 4.7. While retirement is not before February 5, 2027 and the standard 60-day notice applies, the legacy label adds organizational pressure to migrate.
Real-World Use Cases for Opus 4.6 in 2026
Cost-sensitive batch content generation
Nightly cron pipelines processing thousands of similar prompts. The older tokenizer's ~35% efficiency on English prose, combined with Batch API 50% off and prompt caching's 90% cache-hit discount, makes Opus 4.6 the cheaper option per unit of output even though the headline rate matches Opus 4.7.
Pipelines locked to Opus 4.6 token budgets
If your code has hard-coded token budgets, prompt-engineering tuned to Opus 4.6 token counts, or downstream tooling assumes Opus 4.6 output shapes, staying on 4.6 avoids the re-tuning work for as long as 4.6 remains Active.
Workflows requiring explicit extended thinking
Audit-grade code review, mathematical proof verification, or any pipeline where you want explicit control over reasoning depth. Opus 4.7's adaptive-only thinking removes this lever; Opus 4.6 still has it.
Latency-critical paths via Fast Mode
Real-time agent responses where you can absorb the 6x premium ($30 input / $150 output per million tokens). Opus 4.7 does not have Fast Mode as of April 2026.
Multi-platform deployments locked to current providers
If your AWS Bedrock or Google Vertex AI configuration uses model ID anthropic.claude-opus-4-6-v1 or claude-opus-4-6 in pinned production paths, Opus 4.6 keeps working without code changes through at least February 5, 2027.
Legacy systems with strict change-control
Enterprises with quarterly model-validation cycles can keep running Opus 4.6 through their next validation window without breaking anything. Migration to Opus 4.7 can wait for the next scheduled review.
Claude Opus 4.6 vs Opus 4.7 vs Sonnet 4.6
 Sonnet 4.6 — same input rate, different intelligence and feature trade-offs" loading="lazy" class="rounded-xl w-full" />
Sonnet 4.6 — same input rate, different intelligence and feature trade-offs" loading="lazy" class="rounded-xl w-full" />
| Dimension | Opus 4.6 | Opus 4.7 | Sonnet 4.6 |
|---|---|---|---|
| API ID | claude-opus-4-6 | claude-opus-4-7 | claude-sonnet-4-6 |
| Status | Legacy (Active) | Active (recommended) | Active (recommended) |
| Retirement floor | Not before Feb 5, 2027 | Not before Apr 16, 2027 | Not before Feb 17, 2027 |
| SWE-bench Verified | ~80% | 93% | Strong (mid-tier) |
| Context window | 1M tokens | 1M tokens | 1M tokens |
| Max output | 128k | 128k | 64k |
| Reliable knowledge cutoff | May 2025 | Jan 2026 | Aug 2025 |
| Extended thinking | Yes | No | Yes |
| Adaptive thinking | Yes | Yes | Yes |
| Fast Mode | Yes (6x premium) | No | No |
| Tokenizer | Standard 4.x (~750k words/MTok) | New (~555k words/MTok) | Standard 4.x |
| Input price | $5 / MTok | $5 / MTok | $3 / MTok |
| Output price | $25 / MTok | $25 / MTok | $15 / MTok |
| Cache hit | $0.50 / MTok | $0.50 / MTok | $0.30 / MTok |
When to pick which:
- Pick Opus 4.6 if: you're cost-sensitive on batch jobs, locked to existing token budgets, need extended thinking explicitly, want Fast Mode, or have change-control reasons to delay the migration.
- Pick Opus 4.7 if: you need the +13 SWE-bench points, you run long agentic tasks (30+ tool calls), or you want the January 2026 knowledge cutoff for current-events queries.
- Pick Sonnet 4.6 if: headline price matters more than absolute capability — Sonnet 4.6 is $3 input / $15 output (40% cheaper), still has extended thinking, and handles most non-frontier work well.
Migrating from Opus 4.6 to Opus 4.7
Anthropic's official migration guide states that Opus 4.7 should have strong out-of-the-box performance on existing Opus 4.6 prompts and evals at the same headline pricing. The full list of features carried forward from 4.6 to 4.7: 1M context window, 128K max output, adaptive thinking, prompt caching, batch processing, Files API, PDF support, vision, tool use, and computer use.
The non-trivial migration work, based on our own April 16 cutover on ThePlanetTools.ai:
- Re-tune token budgets. The new tokenizer consumes up to 35% more tokens for the same English text. Hard-coded caps (e.g.,
max_tokens: 8000) need bumping or you'll get truncation. - Replace extended-thinking calls. If your pipeline forces extended thinking on Opus, switch that lever to Sonnet 4.6 or accept Opus 4.7's adaptive default.
- Drop Fast Mode dependencies. Opus 4.7 does not have Fast Mode. If you used 4.6 Fast Mode for a latency path, that path stays on 4.6.
- Re-test prompts with ambiguity. Opus 4.7 no longer silently rescues vague prompts. Calls that used to "just work" on 4.6 may now ask clarifying questions. Most teams view this as a correctness win.
- Update model IDs across providers. Claude API:
claude-opus-4-6→claude-opus-4-7. AWS Bedrock:anthropic.claude-opus-4-6-v1→anthropic.claude-opus-4-7. Google Vertex AI:claude-opus-4-6→claude-opus-4-7.
Timeline pressure: retirement is not sooner than February 5, 2027, with at least 60 days notice. There is no urgent deadline. Plan migration around your normal release cycle.
Frequently Asked Questions
What is Claude Opus 4.6?
Claude Opus 4.6 is Anthropic's previous flagship large language model, released in early 2026 and replaced as flagship by Claude Opus 4.7 on April 16, 2026. API ID is claude-opus-4-6. It hits roughly 80% on SWE-bench Verified, 58% on CursorBench, and 54.5% on XBOW visual-acuity. Ships with a 1M-token context window, 128K max output tokens, both extended thinking and adaptive thinking, prompt caching, batch processing, and the full Claude 4.x tool surface. Currently classified as legacy but Active in Anthropic's lifecycle terminology — fully usable, no longer recommended for new builds.
Is Claude Opus 4.6 deprecated?
No, Opus 4.6 is not deprecated. As of April 27, 2026, Anthropic classifies it as Active with legacy status — meaning it still receives API support, is fully usable, and has no announced deprecation date. Its tentative retirement floor is February 5, 2027 (not sooner), and Anthropic commits to at least 60 days of notice before any actual retirement. Anthropic recommends migrating to Opus 4.7 for new work, but existing production deployments on Opus 4.6 can continue without urgent action.
How much does Claude Opus 4.6 cost?
Standard API pricing is $5 per million input tokens and $25 per million output tokens — identical to Opus 4.7. Cache hits drop to $0.50 per million tokens (90 percent off). Batch API gets a 50 percent discount: $2.50 input and $12.50 output per million tokens. Fast Mode (Opus 4.6 only) costs $30 input and $150 output per million tokens — a 6x premium for significantly faster output. On consumer plans, Opus 4.6 is included in Pro ($17 per month annual or $20 monthly), Max 5x (from $100 per month), and Max 20x (from $200 per month) tiers.
Should I migrate from Opus 4.6 to Opus 4.7?
Yes if you run long agentic coding tasks (30+ tool calls), need the +13 percentage points on SWE-bench Verified, or want the January 2026 knowledge cutoff. Stay on Opus 4.6 if you rely on extended thinking explicitly, use Fast Mode for latency, are locked to hard-coded token budgets calibrated to the older Claude 4.x tokenizer, or have change-control cycles that make migration impractical right now. There is no urgent deadline — retirement is not sooner than February 5, 2027 with 60-day notice.
Does Opus 4.6 support extended thinking?
Yes. Opus 4.6 supports both extended thinking (where you explicitly ask the model to reason for longer) and adaptive thinking (where the model decides internally). This is one of the main reasons to keep Opus 4.6 in production: Opus 4.7 dropped extended thinking in favor of adaptive-only. If your pipeline relies on forcing extended reasoning on Opus, that lever is gone in 4.7. Sonnet 4.6 and Haiku 4.5 also still support extended thinking.
What is Fast Mode on Claude Opus 4.6?
Fast Mode is a research-preview beta available exclusively on Opus 4.6 that delivers significantly faster output at premium pricing — $30 per million input tokens and $150 per million output tokens, six times the standard rate. Fast Mode pricing applies across the full context window, including requests over 200K input tokens. It is not available with the Batch API but stacks with prompt caching multipliers and data residency multipliers. Opus 4.7 does not currently offer Fast Mode, making 4.6 the only Claude option for latency-critical paths that need this acceleration.
How big is Opus 4.6's context window?
1 million tokens of input context, 128,000 tokens of max output (with a beta header allowing up to 300,000 output tokens via the Message Batches API). The full 1M context is billed at the standard input rate with no long-context premium — a 900K-token request costs the same per token as a 9K-token request. Opus 4.6 uses the standard Claude 4.x tokenizer, which is about 750,000 English words per million tokens — roughly 35 percent more efficient than Opus 4.7's new tokenizer (~555,000 words per million tokens) for the same input text.
What is Opus 4.6's knowledge cutoff?
Reliable knowledge cutoff is May 2025 — the date through which the model's knowledge is most extensive and reliable. Training data cutoff is August 2025 — the broader date range of training data used. By comparison, Opus 4.7's reliable cutoff is January 2026, eight months newer. For current-events queries or research on developments after May 2025, Opus 4.7 is meaningfully better. For everything before that, the cutoff difference does not matter.
Is Claude Opus 4.6 available on AWS Bedrock and Google Vertex AI?
Yes. AWS Bedrock model ID is anthropic.claude-opus-4-6-v1. Google Vertex AI model ID is claude-opus-4-6. Microsoft Foundry also carries Opus 4.6. Note that for Claude Sonnet 4.5 and newer (which includes Opus 4.6), AWS Bedrock offers global and regional endpoints, and Google Vertex AI offers global, multi-region, and regional endpoints. Regional and multi-region endpoints carry a 10 percent premium over global endpoints. Earlier Claude models retain their existing pricing structure regardless of endpoint type.
How do I switch from Opus 4.6 to Opus 4.7 in my code?
Change the model ID in your API calls: claude-opus-4-6 becomes claude-opus-4-7. On AWS Bedrock, anthropic.claude-opus-4-6-v1 becomes anthropic.claude-opus-4-7. On Google Vertex AI, the change is identical. The full migration guide covers behavioral differences worth knowing: re-tune token budgets because the new tokenizer uses up to 35 percent more tokens for the same text, replace any explicit extended-thinking calls with adaptive defaults or move them to Sonnet 4.6, and re-test prompts with ambiguity because Opus 4.7 no longer silently rescues vague instructions.
What benchmarks does Opus 4.6 hit?
Per Anthropic's published numbers and our own informal tests on ThePlanetTools.ai production work: SWE-bench Verified roughly 80 percent, CursorBench 58 percent, XBOW visual-acuity 54.5 percent. These are 13, 12, and 44 points lower than Opus 4.7 respectively. The XBOW gap is the widest — visual-acuity tasks are where Opus 4.7's new tokenizer and updated training data deliver the biggest jump. SWE-bench and CursorBench gaps are smaller but still felt on long agentic runs.
When will Claude Opus 4.6 be retired?
The tentative retirement date is not sooner than February 5, 2027, per Anthropic's official model deprecations page as of April 27, 2026. Anthropic commits to at least 60 days of notice before any model retirement, with email notifications to active customers and documentation updates. As of this writing, Opus 4.6 is not on the deprecation list — meaning no formal retirement clock has started. Anthropic also commits to long-term preservation of model weights, with the stated hope that past models become publicly available again at some future point.
Verdict: 8.8 out of 10

Claude Opus 4.6 earns 8.8 out of 10 on three things: token efficiency over Opus 4.7's new tokenizer, the still-supported extended thinking lever that Opus 4.7 dropped, and Fast Mode availability for latency-critical paths. The score is held back by the 13-point SWE-bench gap versus Opus 4.7, the older May 2025 knowledge cutoff, and the legacy-status pressure to migrate.
Score breakdown:
- Features: 9.0 out of 10 — extended thinking, Fast Mode, full Claude 4.x tool surface
- Ease of Use: 8.5 out of 10 — same API surface as the rest of Claude 4.x; trivially swappable model ID
- Value: 9.2 out of 10 — older tokenizer is more efficient, same headline price, Batch API and prompt caching deliver real savings
- Support: 8.5 out of 10 — full API support continues, but classified as legacy with retirement floor Feb 5, 2027
Final word: Opus 4.6 is the right answer for production teams who already locked in their token budgets and want to delay the re-tuning work that comes with Opus 4.7's new tokenizer. It is also the right answer for any pipeline that depends on explicit extended thinking or Fast Mode. For everyone else doing new builds in April 2026 and beyond, Opus 4.7 is the better starting point — same headline price, +13 points on SWE-bench Verified, self-verification on long agentic runs. Last tested April 16, 2026, day of cutover to Opus 4.7.
Key Features
Pros & Cons
Pros
- Older Claude 4.x tokenizer is ~35% more efficient than Opus 4.7 for the same English text
- Extended thinking still supported — Opus 4.7 dropped this lever
- Fast Mode 6x premium available exclusively on Opus 4.6 for latency-critical paths
- Stable token budgets calibrated to 4.6 keep working without re-tuning
- 1M-token context window with no long-context premium
- Batch API at 50% off and prompt caching at 90% cache-hit discount
- Full Claude 4.x tool surface — tool use, computer use, Files API, vision, PDF
Cons
- 13-point SWE-bench Verified gap versus Opus 4.7 (80% versus 93%)
- No self-verification on long agentic runs past 30 tool calls
- Reliable knowledge cutoff is May 2025 — older than Opus 4.7's January 2026
- Legacy status creates organizational pressure to migrate
- Vision input cap is standard Claude 4.x — Opus 4.7 bumped to 2,576 px on long edge
Best Use Cases
Platforms & Integrations
Available On
Integrations

We're developers and SaaS builders who use these tools daily in production. Every review comes from hands-on experience building real products — DealPropFirm, ThePlanetIndicator, PropFirmsCodes, and many more. We don't just review tools — we build and ship with them every day.
Written and tested by developers who build with these tools daily.
Frequently Asked Questions
What is Claude Opus 4.6?
Anthropic's previous flagship LLM — legacy with extended thinking and Fast Mode
How much does Claude Opus 4.6 cost?
Claude Opus 4.6 costs $5/month.
Is Claude Opus 4.6 free?
No, Claude Opus 4.6 starts at $5/month.
What are the best alternatives to Claude Opus 4.6?
Top-rated alternatives to Claude Opus 4.6 include Claude Code (9.9/10), Cursor (9.5/10), Claude Opus 4.7 (9.4/10), Veo 3.1 (9.4/10) — all reviewed with detailed scoring on ThePlanetTools.ai.
Is Claude Opus 4.6 good for beginners?
Claude Opus 4.6 is rated 8.5/10 for ease of use.
What platforms does Claude Opus 4.6 support?
Claude Opus 4.6 is available on api, web, aws-bedrock, gcp-vertex-ai, microsoft-foundry.
Does Claude Opus 4.6 offer a free trial?
No, Claude Opus 4.6 does not offer a free trial.
Is Claude Opus 4.6 worth the price?
Claude Opus 4.6 scores 9.2/10 for value. We consider it excellent value.
Who should use Claude Opus 4.6?
Claude Opus 4.6 is ideal for: Cost-sensitive batch content generation pipelines, Production workflows locked to Opus 4.6 token budgets, Audit-grade code review needing explicit extended thinking, Latency-critical agent paths via Fast Mode, Multi-platform deployments on AWS Bedrock and Google Vertex AI, Legacy enterprise systems with strict change-control cycles.
What are the main limitations of Claude Opus 4.6?
Some limitations of Claude Opus 4.6 include: 13-point SWE-bench Verified gap versus Opus 4.7 (80% versus 93%); No self-verification on long agentic runs past 30 tool calls; Reliable knowledge cutoff is May 2025 — older than Opus 4.7's January 2026; Legacy status creates organizational pressure to migrate; Vision input cap is standard Claude 4.x — Opus 4.7 bumped to 2,576 px on long edge.
Best Alternatives to Claude Opus 4.6



Ready to try Claude Opus 4.6?
Get started today
Try Claude Opus 4.6 Now →