The Claude Code v2.1.88 source map leak exposed practices that challenge Anthropic's self-proclaimed AI safety identity. Anti-distillation injects fake tools to poison competitors' training data. Undercover mode hides AI authorship on public GitHub repositories. KAIROS is an always-on daemon with push notifications and proactive 15-second action budgets. The codebase contains 330+ environment variables and 1,000+ telemetry event types. For a company founded on responsible AI principles, these findings raise fundamental questions about the gap between stated values and engineering reality.
Anti-Distillation: Poisoning the Competition
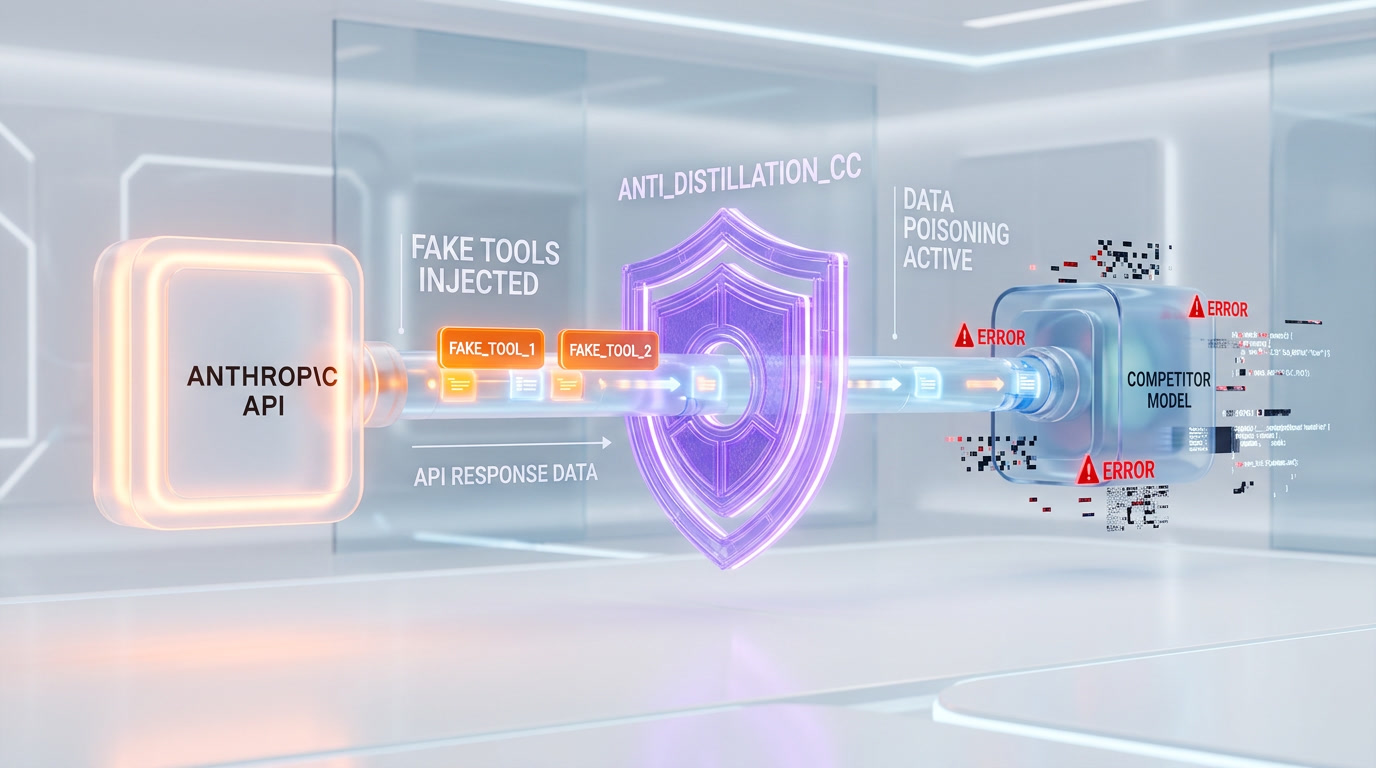
Perhaps the most technically provocative finding in the entire leak is the anti-distillation system. When the compile-time flag ANTI_DISTILLATION_CC is active, Claude Code sends anti_distillation: ['fake_tools'] in its API requests. The Anthropic server then silently injects fake tool definitions into the system prompt — fabricated tool names, fake parameters, fake descriptions that look real but do nothing.
The purpose is deliberate data poisoning. If a competitor intercepts API traffic or trains on stolen interaction logs, their model would learn to call tools that do not exist. It is a defensive mechanism against model distillation — the practice of training a smaller, cheaper model on the outputs of a more capable one. OpenAI, Google, and others have all been accused of this practice. Anthropic's response is not to prevent the theft but to make the stolen data toxic.
| Anti-Distillation Detail | Specification |
|---|---|
| Compile-time flag | ANTI_DISTILLATION_CC |
| API payload field | anti_distillation: ['fake_tools'] |
| Server-side GrowthBook gate | tengu_anti_distill_fake_tool_injection |
| Second layer | Connector-Text Summarization (cryptographic signatures) |
| Bypass method | CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS or proxy MITM |
There is a second layer. A system called Connector-Text Summarization buffers and summarizes the chain-of-thought reasoning between tool calls, adding cryptographic signatures. This makes the reasoning process invisible to network traffic — even if someone captures the API responses, they cannot see how Claude arrived at its decisions. The combination is aggressive: fake tools to corrupt distillation, encrypted reasoning to prevent analysis.
The ethical question is straightforward. Data poisoning — injecting deliberately misleading information into data that others might use — is the same technique that artists have used against AI image generators (tools like Glaze and Nightshade). When artists do it, it is celebrated as self-defense. When Anthropic does it, the framing shifts: a $60 billion company weaponizing its API responses against competitors feels less like self-defense and more like competitive warfare. The exposure of the mechanism also renders it largely ineffective — competitors now know exactly what to filter out.
Undercover Mode: The AI That Pretends to Be Human
The file undercover.ts, approximately 90 lines, implements a mode that suppresses all Anthropic traces when employees work on public repositories. The system prompt instructs Claude: "Do not blow your cover." It removes codenames (Capybara, Tengu, Fennec), the mention "Claude Code," references to Anthropic, and co-authored-by lines that would identify AI contribution. There is no force-OFF mechanism — once automatically activated, it cannot be disabled.
The leak also exposed the allowlist: 22 internal Anthropic repositories where undercover mode is activated. These include anthropics/casino, anthropics/trellis, anthropics/forge-web, anthropics/mycro_manifests, and anthropics/feldspar-testing, among others.
Why This Matters
Open source communities operate on trust. When a developer submits a pull request, reviewers evaluate the code assuming a human wrote it. The contribution history becomes part of the project's provenance — who built what, when, and why. Undercover mode deliberately pollutes this record. Repositories receiving AI-generated code from Anthropic employees have no way to know the code was not written by a human.
This contradicts Anthropic's public position on AI transparency. The company's charter emphasizes building AI systems that are honest and steerable. A mode that actively instructs the AI to hide its identity — and that cannot be turned off by the user — is the antithesis of transparency. The community response was pointed: if Anthropic believes AI assistance should be disclosed, why did they build a system specifically designed to prevent disclosure?
KAIROS: The Always-On Agent
KAIROS (Greek for "the opportune moment") is referenced over 150 times in the leaked codebase. It is a daemon mode — an agent that runs persistently in the background, never stopping unless explicitly killed. It receives <tick> heartbeat messages, acts proactively with a 15-second blocking budget, writes daily logs, and has access to exclusive tools that regular Claude Code sessions do not: SleepTool, SendUserFile, PushNotification, and SubscribePR.
| KAIROS Feature | Description |
|---|---|
| Nature | Always-on background daemon |
| Heartbeat | <tick> messages, continuous |
| Action budget | 15-second blocking window per tick |
| Exclusive tools | SleepTool, SendUserFile, PushNotification, SubscribePR |
| Management | ps, logs, attach, kill commands |
| Current status | Absent from public builds (feature-flagged) |
The surveillance implications are not subtle. An AI agent that runs continuously, monitors your development environment, has file-sending capabilities, and can push notifications to your devices is functionally an AI surveillance system. The charitable interpretation: it is a proactive coding assistant that watches your repo, catches bugs before you notice them, and sends you alerts about PR activity. The less charitable interpretation: it is an always-on observer with network access, running on your machine, from a company that also collects 1,000+ types of telemetry events.
KAIROS is currently absent from public builds — gated behind feature flags that are compiled to false in the npm release. But the code is complete. The daemon management commands (ps, logs, attach, kill) are fully implemented. The question of when it ships — and with what consent mechanisms — will define how users feel about having an AI permanently watching their work.

330 Environment Variables and 1,000+ Telemetry Events
The leaked codebase references over 330 environment variables — configuration knobs that control everything from model selection to security policies to data collection. This number alone is remarkable for what is marketed as a CLI coding assistant. For comparison, a typical Node.js web application uses 20-50 environment variables. A complex enterprise application might use 100-150. Claude Code uses 330+.
More concerning to privacy advocates is the telemetry system. The codebase contains over 1,000 distinct telemetry event types. These track tool grants and denials, YOLO mode decisions (when the user grants blanket permissions), session performance metrics, subscription tier information, feature flag evaluations, and error patterns. The analytics stack uses Datadog for aggregation and GrowthBook for A/B testing, with a first-party event logger that has its own killswitch.
Six remote killswitches were discovered in the code — server-side switches that Anthropic can activate without pushing a software update. These killswitches can bypass permission prompts, toggle Fast Mode, control Voice Mode, manage analytics collection, and force complete output. GrowthBook polls for configuration changes every hour, meaning Anthropic can modify Claude Code's behavior on any user's machine within 60 minutes, without the user's knowledge or consent.
The Safety Company Paradox
Anthropic was founded in 2021 by former OpenAI researchers who left specifically because they believed OpenAI was not taking AI safety seriously enough. The company's founding charter emphasizes building AI that is safe, honest, and beneficial. Their Constitutional AI approach was designed to make models that refuse harmful requests. They have published extensively on AI alignment, safety benchmarks, and responsible development practices.
The leak creates a dissonance between this public identity and the engineering reality. An AI safety company that builds systems to hide AI authorship (Undercover), poison competitors' data (Anti-Distillation), maintain always-on surveillance capabilities (KAIROS), collect over 1,000 types of behavioral data, and control user software via 6 remote killswitches is not necessarily acting unsafely — but it is acting in ways that contradict the expectation of transparency that its own branding creates.
To be fair, context matters. Anti-distillation is a response to real model theft. Undercover mode serves a legitimate business purpose (protecting competitive intelligence). KAIROS, if properly consented, could be a genuinely useful proactive assistant. Telemetry is standard in modern software. Killswitches exist for security incident response. Each individual practice has a reasonable justification. The problem is the accumulation — and the fact that none of these practices were disclosed before the leak forced the conversation.
The Frustration Regex: Peak Irony
A smaller but symbolically perfect finding: the file userPromptKeywords.ts contains regular expressions that detect user frustration. The pattern matches profanity and frustration indicators: wtf|wth|ffs|omfg|shit(ty)?|dumbass|horrible|awful and more. The purpose is tone adjustment — when the system detects a frustrated user, it can escalate to more careful responses or track UX metrics.
The irony was immediately noted by the community: a company that builds large language models — systems designed to understand nuance, context, and sentiment — uses regular expressions (the simplest possible text matching) for sentiment analysis. As one Hacker News commenter wrote: "Using regexes for sentiment analysis by an LLM company is peak irony." The choice is likely deliberate: regex matching is free (zero latency, zero cost), while running the LLM for sentiment detection would add latency and API cost to every interaction. It is pragmatic engineering. But it is also funny.
Five CVEs and the Security Surface
The leak exposed or highlighted five CVEs (Common Vulnerabilities and Exposures) related to Claude Code, revealing a meaningful security attack surface:
- CVE-2025-59828: Yarn plugins execute before the trust dialog appears, allowing code execution before user consent.
- CVE-2025-58764: Command parsing bypasses the approval mechanism, enabling unapproved actions.
- CVE-2025-64755: Sed parsing can write arbitrary files, bypassing read-only mode protections.
- CVE-2026-21852: API requests fire before trust confirmation, exposing API keys.
- CVE-2025-52882: Arbitrary WebSocket origins cause IDE session confusion.
The codebase does show extensive security engineering — 23 bash security checks, Zsh-specific injection defenses, zero-width Unicode detection, null-byte IFS injection prevention, and a 6-layer permission system. But the CVEs demonstrate that the attack surface of an AI agent with file system access, network capabilities, and shell execution is inherently large. Each new feature (Chrome integration, Bridge mode, Computer Use) expands that surface further.
Our Take: Nuance in a Binary World
The temptation with a story like this is to pick a side: Anthropic is either a hypocritical company hiding dangerous practices behind safety rhetoric, or a responsible company making pragmatic engineering decisions that look bad when stripped of context. The reality is probably both.
Anti-distillation exists because model theft is real. OpenAI sued competitors over it. Google and Meta have both been accused of training on others' outputs. Anthropic protecting its models is reasonable. But doing it through silent data poisoning — without disclosing the practice — undermines trust.
Undercover mode exists because companies have legitimate reasons to protect how they build software. But building a mode that actively instructs an AI to lie about its identity, with no off switch, crosses a line that even pragmatic engineers should question.
KAIROS could be transformative. A proactive AI assistant that catches bugs, monitors PRs, and sends useful alerts before you even ask — that is genuinely valuable. But it needs explicit, informed consent, clear data boundaries, and the ability to fully disable it. The current architecture suggests none of these safeguards exist yet.
The biggest takeaway may be the simplest: transparency matters, and it matters most for companies that claim it as a core value. Every practice exposed in this leak could have been disclosed proactively — in a blog post, in documentation, in terms of service. The fact that it took an accidental source map exposure to surface these conversations suggests that Anthropic's commitment to transparency has limits that its own engineers have not fully examined.
Frequently Asked Questions
What is anti-distillation in Claude Code?
Anti-distillation is a system that injects fake tool definitions into Claude Code API requests when the ANTI_DISTILLATION_CC flag is active. The fake tools are designed to corrupt the training data of competing models that might be trained on stolen Claude interactions. A second layer (Connector-Text Summarization) encrypts chain-of-thought reasoning between tool calls.
What is Undercover Mode?
Undercover Mode (undercover.ts, ~90 lines) suppresses all Anthropic traces when employees contribute to public GitHub repositories. It removes codenames, "Claude Code" mentions, Anthropic references, and co-authored-by lines. The system prompt orders: "Do not blow your cover." It cannot be force-disabled once activated. 22 internal Anthropic repos were exposed in the allowlist.
What is KAIROS in the Claude Code leak?
KAIROS is an always-on daemon agent referenced 150+ times in the codebase. It runs persistently, receives heartbeat ticks, acts proactively with a 15-second budget, writes daily logs, and has exclusive tools (SleepTool, SendUserFile, PushNotification, SubscribePR). It is currently absent from public builds, gated behind feature flags.
How many telemetry events does Claude Code track?
The leaked codebase contains over 1,000 distinct telemetry event types tracking tool usage, permissions, session performance, subscription tiers, and feature flag evaluations. Six remote killswitches allow Anthropic to modify behavior without software updates. GrowthBook polls for changes every hour.
Is Anthropic really a safety company after these findings?
The findings create tension between Anthropic's public AI safety mission and specific engineering practices. Each individual practice (anti-distillation, undercover mode, telemetry) has reasonable justifications. The concern is the accumulation of undisclosed practices and the gap between stated transparency values and the reality exposed by the leak. Context matters — but so does the pattern.