
Google Gemma 4 is a family of four open-source language models (E2B, E4B, 26B MoE, 31B Dense) released April 2, 2026, under Apache 2.0. The 31B model ranks #3 globally among open models on Arena AI with 89.2% on AIME 2026, 80% on LiveCodeBench v6, and 256K context. All models support native image, video, and function calling. Edge models (E2B/E4B) add audio input and run on phones and Raspberry Pi.
Why Gemma 4 Matters: The Numbers That Count
We have been tracking Google's open-source AI efforts since Gemma 1 dropped in February 2024, and Gemma 4 is the release that finally puts Google toe-to-toe with Meta and Alibaba in the open-weights race. The 31B Dense model hit Arena AI at rank #3 among open models — competing with models 20x its parameter count — while the 26B MoE variant secured rank #6 with only 3.8B active parameters during inference.
The most consequential change is not the benchmarks. It is the license. Gemma 4 ships under standard Apache 2.0 — no custom clauses, no MAU limits, no "Harmful Use" carve-outs. Google matched Qwen's licensing and undercut Meta's Llama 4, which still carries a 700M monthly active user cap and an acceptable use policy that requires legal review.
| Model | Total Params | Active Params | Context | Modalities | License |
|---|---|---|---|---|---|
| Gemma 4 E2B | 5.1B (w/ embeddings) | 2.3B | 128K | Text, Image, Video, Audio | Apache 2.0 |
| Gemma 4 E4B | 8B (w/ embeddings) | 4.5B | 128K | Text, Image, Video, Audio | Apache 2.0 |
| Gemma 4 26B A4B | 26B (MoE) | 3.8B | 256K | Text, Image, Video | Apache 2.0 |
| Gemma 4 31B | 31B (Dense) | 31B | 256K | Text, Image, Video | Apache 2.0 |
Best for: Developers building agentic AI applications, startups needing frontier-level reasoning on a single GPU, edge/mobile AI teams deploying multimodal models on-device, and enterprises wanting commercially permissive open-source LLMs.
Benchmark Deep Dive: How Gemma 4 Stacks Up
Google published extensive benchmarks across reasoning, coding, math, vision, and agentic tasks. We cross-referenced these with third-party results from Hugging Face and Artificial Analysis. Here is where Gemma 4 stands.
Reasoning and Knowledge
| Benchmark | Gemma 4 31B | Gemma 4 26B MoE | Gemma 4 E4B | Gemma 4 E2B |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% |
| AIME 2026 (Math) | 89.2% | 88.3% | 42.5% | 37.5% |
| GPQA Diamond (Science) | 84.3% | 82.3% | 58.6% | 43.4% |
| BigBench Extra Hard | 74.4% | 64.8% | 33.1% | 21.9% |
| Arena AI (Text, estimated) | 1452 | -- | -- | -- |
The 31B model scoring 89.2% on AIME 2026 is the headline number. For context, that puts it in the territory of models like GPT-4.5 and Claude Opus on math reasoning — at a fraction of the parameter count. The 26B MoE is even more remarkable: 88.3% on AIME with only 3.8B parameters active per forward pass.
Coding Performance
| Benchmark | Gemma 4 31B | Gemma 4 26B MoE | Gemma 4 E4B | Gemma 4 E2B |
|---|---|---|---|---|
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% |
| Codeforces ELO | 2,150 | 1,718 | 940 | 633 |
A Codeforces ELO of 2,150 places the 31B model at the "Master" competitive programming tier. The 26B MoE variant at 1,718 is solidly "Expert" level — impressive for a model that activates fewer parameters than GPT-2 during inference.
Vision and Multimodal
| Benchmark | Gemma 4 31B | Gemma 4 26B MoE | Gemma 4 E4B | Gemma 4 E2B |
|---|---|---|---|---|
| MMMU Pro (Multimodal Reasoning) | 76.9% | 73.8% | 52.6% | 44.2% |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% |
All four Gemma 4 models process images and video natively. The vision encoder uses learned 2D positions with multidimensional RoPE and preserves aspect ratios, with configurable token budgets (70, 140, 280, 560, or 1,120 tokens per image). Video is supported across all sizes — up to 60 seconds at 1 fps by processing sequences of frames.

Agentic Capabilities: The Tau-2 Benchmark Leap
The single most dramatic improvement from Gemma 3 to Gemma 4 is in agentic tool use. On the tau-2-bench (Retail) benchmark, Gemma 4 31B scores 86.4% and the 26B MoE scores 85.5%. For reference, Gemma 3 27B scored 6.6% on the same benchmark.
That is not a typo. We went from 6.6% to 86.4% in one generation.
Gemma 4 was designed for agentic workflows from the ground up. All models support native function calling, structured JSON output, and system instructions. The architecture includes specific optimizations for multi-step tool use — planning, executing API calls, processing results, and iterating. Google explicitly markets these models for "autonomous agents that plan, navigate apps, and complete tasks on your behalf."
For developers building AI agents, this changes the calculus significantly. You can now deploy a 26B MoE model that activates only 3.8B parameters per step, runs on a single consumer GPU, and handles complex multi-tool workflows at 85%+ accuracy — all under Apache 2.0 with zero licensing overhead.
The Apache 2.0 Shift: Why the License Matters More Than Benchmarks
Previous Gemma releases used a custom Google license with usage restrictions that Google could update unilaterally. Fine-tuned derivatives had ambiguous commercial status. Enterprises had to run the license past legal before deploying.
Gemma 4 under Apache 2.0 eliminates all of that. The implications are concrete:
- No MAU caps — Meta's Llama 4 still imposes a 700M monthly active user limit. Gemma 4 has none.
- No acceptable use policy — Llama 4 includes policy requirements that add compliance overhead. Gemma 4 does not.
- Commercial derivatives allowed — Fine-tune it, distill it, merge it, ship it. Standard Apache 2.0 terms.
- Same license as Qwen — Alibaba's Qwen 3.5 also uses Apache 2.0. Google now matches the most permissive open-model license in the market.
- Immutable terms — Apache 2.0 cannot be retroactively changed. Previous Gemma licenses could be modified by Google.
As VentureBeat noted, this license change may matter more than the benchmark improvements for enterprise adoption. Legal teams can green-light deployment without custom license review.
Gemma 4 vs Llama 4 vs Qwen 3.5: The Open-Source Showdown
The open-source LLM landscape in April 2026 has three major contenders. Here is how they compare head-to-head.
| Feature | Gemma 4 31B | Llama 4 Scout (109B) | Qwen 3.5-27B |
|---|---|---|---|
| Active Params | 31B (dense) | 17B (of 109B MoE) | 27B (dense) |
| Context Window | 256K | 10M | ~128K |
| MMLU Pro | 85.2% | -- | ~82% |
| AIME 2026 | 89.2% | -- | ~49% |
| GPQA Diamond | 84.3% | 74.3% | ~80% |
| LiveCodeBench v6 | 80.0% | -- | ~43% |
| Native Vision | Yes | Yes | Yes |
| Native Audio | Edge models only | No | No |
| License | Apache 2.0 | Community (700M MAU cap) | Apache 2.0 |
| Smallest Model | 2.3B effective | 109B | 0.8B |
| Agentic (tau-2) | 86.4% | -- | -- |
Our take: Gemma 4 31B dominates on reasoning, math, and coding benchmarks. Llama 4 Scout's 10M context window remains unmatched — if you need to process entire codebases or extremely long documents, Scout is still the only option. Qwen 3.5 offers the widest range of model sizes (0.8B to 397B) and remains extremely competitive, but Gemma 4's AIME and LiveCodeBench numbers have leapfrogged it in math and coding.
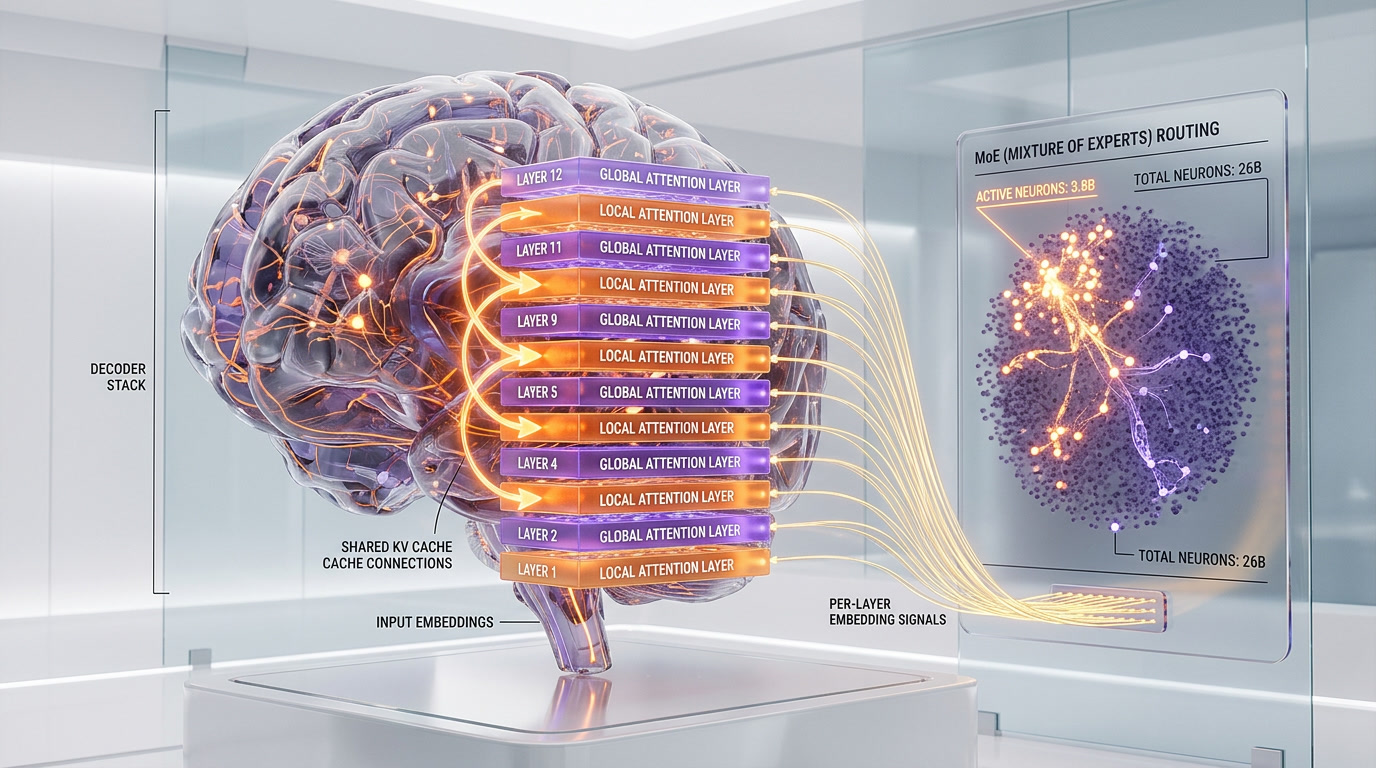
Architecture: What Changed Under the Hood
Researcher Sebastian Raschka analyzed the 31B architecture and noted it remains "architecturally close to Gemma 3 27B," suggesting the massive performance leap came primarily from improved training recipes and data rather than a radical architecture overhaul. That said, several technical innovations stand out.
Alternating Attention
Gemma 4 alternates between local sliding-window attention (512-1024 tokens) and global full-context layers. Local layers handle nearby token dependencies efficiently. Global layers maintain long-range coherence across the full 256K context window. This dual approach reduces memory pressure while preserving quality on long documents.
Shared KV Cache
The last N layers of the model reuse key-value states computed by earlier layers, eliminating redundant projections. This directly reduces VRAM consumption during inference — critical for fitting the 31B model on consumer hardware.
Per-Layer Embeddings (PLE)
A secondary embedding table sends a residual signal to every decoder layer, enabling per-layer specialization at modest parameter cost. This is one of the less conventional design choices that differentiates Gemma 4 from standard transformer architectures.
26B MoE: The Efficiency Champion
The 26B Mixture-of-Experts model activates only 3.8B of its 26B total parameters during each forward pass. Despite using fewer active parameters than GPT-2, it achieves 97% of the 31B Dense model's quality on most benchmarks. Community benchmarks show 300 tokens per second on M2 Ultra hardware — fast enough for real-time video processing.
Edge and Local Deployment: AI on Your Phone
The E2B and E4B models are purpose-built for edge deployment. They run completely offline on smartphones, Raspberry Pi boards, and NVIDIA Jetson Orin Nano devices. Google claims they operate up to 4x faster than previous Gemma versions on the same hardware.
These are not text-only models stripped for mobile. They handle text, images, video, and audio natively — all within a 128K context window. Use cases include real-time translation, on-device document analysis, voice assistants, and offline image understanding.
Hardware requirements are practical:
- E2B: ~5GB with embeddings. Fits on modern smartphones with quantization.
- E4B: ~8GB with embeddings. Runs on laptops and tablets.
- 26B MoE: ~26GB total, but only 4B active during inference. Single consumer GPU.
- 31B Dense: ~33GB. Requires a 40GB+ VRAM GPU (RTX 4090, A6000) or quantized deployment.
Day-zero inference engine support was comprehensive: llama.cpp, Ollama, MLX (Apple Silicon with TurboQuant), vLLM, LM Studio, transformers.js (browser/WebGPU), ONNX, and mistral.rs (Rust-native). Quantized formats include GGUF, INT4, and INT8 via bitsandbytes.
Multimodal Capabilities: Text, Image, Video, and Audio
All Gemma 4 models process text and images natively. Video is supported across all sizes (up to 60 seconds at 1 fps). The E2B and E4B edge models add native audio input via a USM-style conformer encoder — enabling speech recognition, audio QA, and multimodal function calling directly on-device.
Practical multimodal features include:
- OCR and document understanding — Variable-resolution image processing with configurable token budgets
- Chart and diagram analysis — High accuracy on MATH-Vision (85.6% for 31B)
- Object detection and GUI element detection — Built-in capabilities for app navigation
- Speech-to-text — E2B and E4B process audio natively, no separate ASR pipeline needed
- Video understanding — Frame-by-frame analysis with audio context (edge models)
The vision encoder is notably flexible. Configurable token budgets (70 to 1,120 tokens per image) let developers trade off between speed and quality depending on the use case. A quick classification might use 70 tokens per image; detailed document OCR can use 1,120.
How to Run Gemma 4 Right Now
Gemma 4 is available immediately through multiple channels:
- Google AI Studio — Free access to 31B and 26B MoE models in the browser. No API key needed for exploration.
- Hugging Face — All four models with base and instruction-tuned (IT) checkpoints.
- Ollama —
ollama run gemma4for local deployment with one command. - Kaggle — Notebooks with pre-configured environments.
- Vertex AI — Cloud deployment through Google Cloud with managed infrastructure.
- AI Edge Gallery — Google's app for running models on Android devices.
For developers who want to fine-tune, supported frameworks include TRL (supervised fine-tuning and DPO), Unsloth Studio, Vertex AI custom training, PEFT, and bitsandbytes 4-bit quantization. Both text-only and multimodal training pipelines are available.
What This Means for the Open-Source AI Landscape
Gemma 4 does not exist in isolation. It enters a market where Meta's Llama 4, Alibaba's Qwen 3.5, DeepSeek R2, and Mistral's latest models are all competing for developer adoption. Three trends are clear.
First, the performance floor has risen dramatically. A 31B parameter model scoring 89.2% on AIME 2026 and 80% on LiveCodeBench would have been unthinkable 12 months ago. Models in the 25-35B range now match or exceed what 100B+ models achieved in 2025.
Second, Apache 2.0 is becoming the standard. With both Google and Alibaba on Apache 2.0, Meta's custom Llama license looks increasingly restrictive. The pressure on Meta to simplify its licensing will only grow.
Third, edge AI is no longer a compromise. The E4B model scoring 42.5% on AIME 2026 from a phone-capable 4.5B parameter model means serious math reasoning is possible on-device. Combined with native audio and vision, these edge models enable genuinely useful offline AI applications — not toy demos.
For ThePlanetTools readers building AI products, the practical implication is clear: the cost and complexity of deploying capable AI has dropped significantly. You can now ship agentic, multimodal, commercially licensed AI in your product using a model that fits on a single consumer GPU — or even a smartphone.
Frequently Asked Questions
Is Gemma 4 truly open source?
Yes. Gemma 4 is released under the Apache 2.0 license, which is a standard open-source license recognized by the Open Source Initiative. Unlike previous Gemma versions that used a custom Google license with restrictions, Apache 2.0 allows free commercial use, modification, distribution, and creation of derivative works with no MAU limits or acceptable use policy requirements.
Can I run Gemma 4 on my laptop?
Yes. The E2B model (~5GB with embeddings) runs on most modern laptops. The E4B (~8GB) works on laptops with 16GB+ RAM. The 26B MoE model needs ~26GB total but only activates 4B parameters at inference time, making it feasible with quantization on high-end laptops. The 31B Dense model requires ~33GB VRAM and typically needs a dedicated GPU like an RTX 4090.
How does Gemma 4 compare to Llama 4?
Gemma 4 31B outperforms Llama 4 Scout on reasoning benchmarks like GPQA Diamond (84.3% vs 74.3%) while using far fewer parameters. Llama 4 Scout's key advantage is its 10M token context window compared to Gemma 4's 256K. Licensing also differs: Gemma 4 uses unrestricted Apache 2.0 while Llama 4 has a custom community license with a 700M MAU cap.
What languages does Gemma 4 support?
Gemma 4 is natively trained on over 140 languages with cultural context awareness. The MMLU Multilingual benchmark score of 85.2% for the 31B model demonstrates strong cross-language capabilities beyond just English performance.
Can I use Gemma 4 for commercial products?
Yes, without restriction. Apache 2.0 permits commercial use, modification, and distribution. You can fine-tune, distill, merge, and ship Gemma 4 derivatives in commercial products. No royalties, no MAU limits, no acceptable use policy compliance required.
What makes the 26B MoE model special?
The 26B Mixture-of-Experts model activates only 3.8B parameters per forward pass while maintaining 97% of the 31B Dense model's quality on most benchmarks. It achieves 88.3% on AIME 2026 with dramatically lower compute requirements. Community benchmarks show 300 tokens per second on M2 Ultra hardware, making it the efficiency sweet spot in the lineup.
Does Gemma 4 support function calling and AI agents?
Yes. Gemma 4 includes native function calling, structured JSON output, and system instruction support. On the tau-2-bench (Retail) agentic benchmark, the 31B model scores 86.4% — up from 6.6% for Gemma 3 27B. This 13x improvement indicates that agentic workflows were a primary design goal.
Where can I download Gemma 4 for free?
Gemma 4 is available on Hugging Face, Ollama (run ollama run gemma4), Kaggle, LM Studio, and Google AI Studio. Google AI Studio offers free browser-based access to the 31B and 26B MoE models without requiring an API key for initial exploration.
Frequently Asked Questions
Is Google Gemma 4 31B better than Meta Llama 4 Scout?
On reasoning, math, and coding benchmarks, Gemma 4 31B clearly wins: 89.2% on AIME 2026, 80% on LiveCodeBench v6, and a Codeforces ELO of 2,150 (Master tier). However, Meta Llama 4 Scout has a 10M token context window versus Gemma 4's 256K — making Scout the only choice for processing entire codebases or extremely long documents. On licensing, Gemma 4 is superior: pure Apache 2.0 with no user caps, while Llama 4 Scout still imposes a 700M monthly active user limit and an acceptable use policy that requires legal review.
Is Google Gemma 4 31B better than Qwen 3.5-27B?
Yes, on math and coding benchmarks. Gemma 4 31B scores 89.2% on AIME 2026 versus Qwen 3.5-27B's approximately 49%, and 80% on LiveCodeBench v6 versus Qwen's ~43%. Both share Apache 2.0 licensing, which is a tie. Qwen 3.5 has a broader model size range — from 0.8B up to 397B — giving more flexibility at the small and very large ends. Gemma 4 counters with stronger agentic performance (86.4% on tau-2-bench Retail) and native edge models (E2B/E4B) that run on phones and Raspberry Pi with audio support.
How does Gemma 4 compare to GPT-4.5 and Claude Opus on math?
Gemma 4 31B scores 89.2% on AIME 2026, placing it in the same territory as GPT-4.5 and Claude Opus on math reasoning — despite being a fraction of the parameter count. Even more striking, the Gemma 4 26B MoE model scores 88.3% on AIME while activating only 3.8B parameters per forward pass. Both GPT-4.5 and Claude Opus are closed-source, paid models; Gemma 4 is completely free under Apache 2.0 with no usage restrictions.
Who should use Google Gemma 4?
Gemma 4 is best for four groups: (1) Developers building agentic AI applications — the 31B model scores 86.4% on tau-2-bench Retail, up from Gemma 3's 6.6%; (2) Startups needing frontier-level reasoning on a single GPU — the 26B MoE variant activates only 3.8B parameters during inference; (3) Edge and mobile AI teams — E2B (2.3B effective params) and E4B (4.5B effective params) support audio input and run on phones and Raspberry Pi with a 128K context window; (4) Enterprises wanting commercially safe open-source LLMs — Apache 2.0 requires no legal review, no MAU tracking, and allows fine-tuning, distillation, and commercial distribution.
What are Google Gemma 4's limitations?
Gemma 4 has four notable limitations: (1) Context window caps at 256K tokens — Meta Llama 4 Scout offers 10M tokens, essential for very long document workloads; (2) No native audio on 26B and 31B models — audio input is exclusive to the edge models E2B and E4B; (3) Smaller model size ceiling — Qwen 3.5 scales to 397B parameters versus Gemma 4's maximum 31B Dense; (4) The architecture remains close to Gemma 3 27B, meaning performance gains came primarily from training data improvements rather than a radical architecture overhaul — future headroom may be more limited.
Does Google Gemma 4 integrate with Hugging Face?
Yes. All four Gemma 4 models — E2B, E4B, 26B MoE, and 31B Dense — are available on Hugging Face Hub under Apache 2.0. They are fully compatible with the Transformers library and support standard inference pipelines, PEFT fine-tuning, and quantization. Third-party benchmark results from Hugging Face and Artificial Analysis have independently validated Google's published scores, confirming the 89.2% AIME 2026 and 80% LiveCodeBench v6 figures for the 31B model.
Is Google Gemma 4 truly free for commercial use?
Yes, with no restrictions. Gemma 4 ships under standard Apache 2.0 — no modifications, no carve-outs. There are no monthly active user caps (unlike Meta Llama 4's 700M MAU ceiling), no acceptable use policy requiring compliance review, and no restrictions on fine-tuning, distillation, model merging, or commercial deployment. Apache 2.0 terms are also immutable — Google cannot retroactively change the license, unlike previous Gemma releases which used a custom Google license that could be unilaterally modified.
What is the context window of each Google Gemma 4 model?
Context windows vary by model size: Gemma 4 E2B (2.3B effective params) and E4B (4.5B effective params) support 128K tokens; Gemma 4 26B MoE and 31B Dense both support 256K tokens. For images, all models offer configurable token budgets of 70, 140, 280, 560, or 1,120 tokens per image with aspect ratio preservation. For video, all models support sequences up to 60 seconds at 1 fps. Meta Llama 4 Scout remains the only open model with a 10M token context window.



