
Somewhere inside Claude Code, there is a system designed to lie to competitors. The ANTI_DISTILLATION_CC flag triggers Anthropic's servers to inject fake tool definitions into system prompts — poisoning the training data of any model trained on scraped Claude traffic. A second layer called Connector-Text Summarization uses cryptographic signatures to make chain-of-thought reasoning invisible on the network. Both systems were being rolled out via GrowthBook feature flags before the March 31, 2026 source leak exposed them.
How ANTI_DISTILLATION_CC Works
The mechanism lives in claude.ts, the central API client file for Claude Code. It is one of the most strategically significant discoveries in the entire leak — a system purpose-built to sabotage competitors who try to distill Claude's capabilities by recording its API traffic.
Here is the step-by-step flow:
- Feature flag check — Claude Code checks whether the GrowthBook flag
tengu_anti_distill_fake_tool_injectionis active for the current user session - Client-side signal — If active, Claude Code includes
anti_distillation: ['fake_tools']in its API request payload alongside the real tools and messages - Server-side injection — Anthropic's API server receives the signal and silently injects fake tool definitions (decoys) into the system prompt before it reaches the model
- Model behavior — Claude sees both real and fake tools but is trained to only use the real ones. Responses come back normal
- Poison effect — Anyone intercepting and replaying this traffic to train a competing model gets training data that includes tools that do not exist
| Component | Location | Role |
|---|---|---|
| ANTI_DISTILLATION_CC flag | claude.ts (client) | Triggers fake tool injection |
| tengu_anti_distill_fake_tool_injection | GrowthBook (remote config) | Progressive rollout control |
| anti_distillation: ['fake_tools'] | API request payload | Signal to server |
| Fake tool definitions | Server-side injection | Decoy tools in system prompt |
| Connector-Text Summarization | betas.ts (client + server) | Hides chain-of-thought reasoning |
The elegance of this system is in its asymmetry. Anthropic's own model knows which tools are real because it was trained that way. A competitor's model, trained on stolen traffic, would not know the difference. The fake tools become invisible landmines in the training data.

Why Fake Tools Are Devastating for Distillation
To understand why this matters, we need to understand how model distillation through API scraping works.
Distillation is the process of training a smaller, cheaper model to mimic a larger, more expensive one. The standard approach is straightforward: send thousands of prompts to the target model (in this case, Claude), record the responses, and use those input-output pairs as training data for your own model. Companies like Anthropic have suspected for years that competitors and third parties do this at scale.
The fake tool injection poisons this process in three specific ways:
1. Tool Hallucination
A model trained on data containing fake tool definitions will learn to "call" tools that do not exist. When deployed, it will attempt to use these phantom tools, producing errors or nonsensical behavior that is immediately distinguishable from legitimate AI performance. This is not a subtle degradation — it is a catastrophic failure mode.
2. Fingerprinting
The fake tools injected by Anthropic's servers are likely unique per session or per user. This means that if a distilled model starts calling a specific fake tool, Anthropic can trace it back to the exact session or account that scraped the data. This turns anti-distillation into a forensic tool for identifying the source of data theft.
3. Statistical Contamination
Even if an attacker filters out obvious fake tools, the presence of decoy definitions in the system prompt subtly alters the model's token distribution across the entire response. Training on this contaminated distribution means the distilled model inherits biases and patterns that do not exist in Claude's actual behavior. The poison spreads beyond just the fake tools themselves.
The GrowthBook Connection
The feature flag controlling anti-distillation — tengu_anti_distill_fake_tool_injection — is managed through GrowthBook, the feature flag platform Anthropic uses internally. Several details are significant:
- "tengu" is the internal codename for the Claude Code project itself, appearing hundreds of times across the codebase
- The flag was being progressively rolled out, meaning not all users had it active at the time of the leak
- It is restricted to first-party CLI sessions only — third-party API users do not trigger the injection
- GrowthBook allows Anthropic to enable or disable the feature without shipping a code update, making it operationally invisible
The progressive rollout is tactically smart. By only activating fake tool injection for a subset of users, Anthropic creates a natural A/B test: if distilled models start showing tool hallucinations, the hallucinated tools can be mapped back to specific rollout cohorts, further improving forensic traceability.
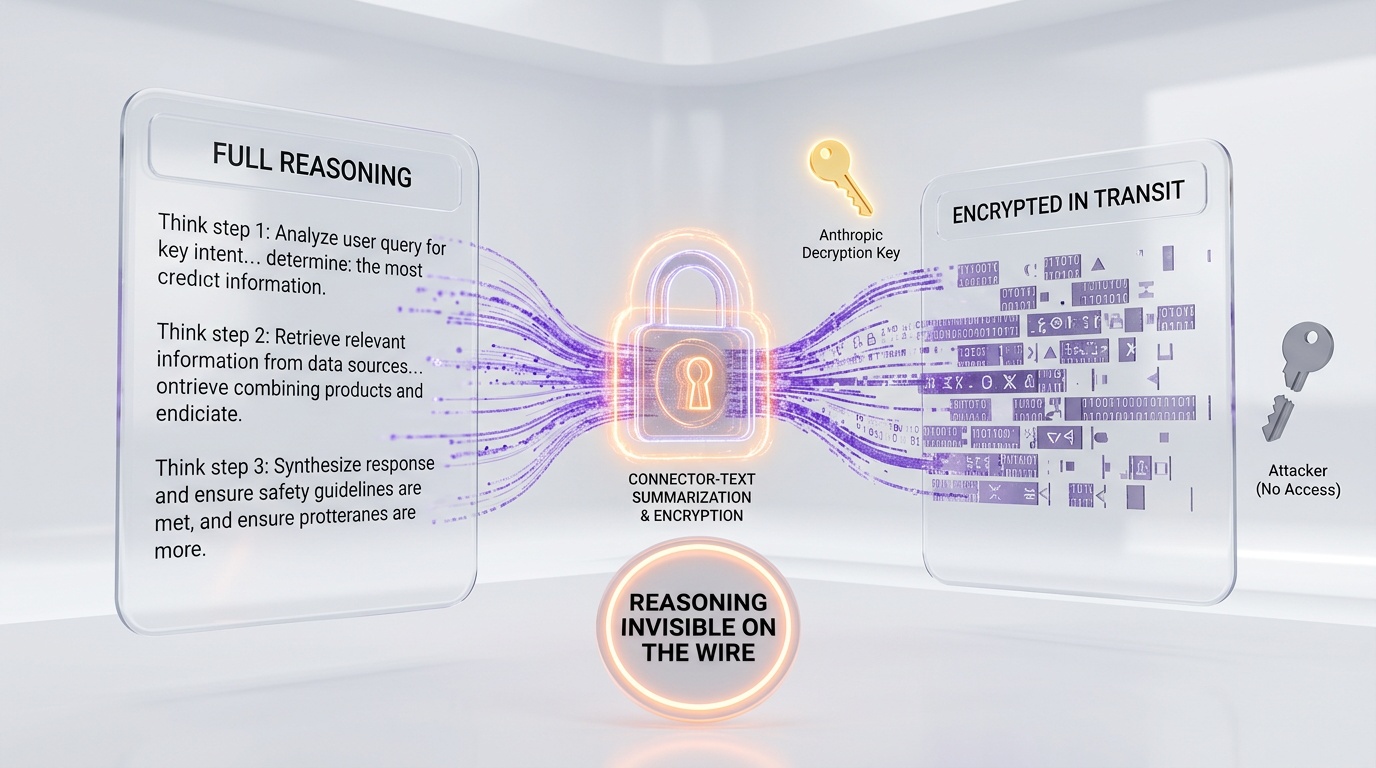
Connector-Text Summarization: The Second Layer
The fake tool injection is the first line of defense. The second is more subtle and arguably more sophisticated. Located in betas.ts, the Connector-Text Summarization system targets a different part of the distillation pipeline: the chain-of-thought reasoning.
Here is how it works:
- Buffer — When Claude generates text between tool calls (its "thinking" or reasoning), the server buffers this text instead of streaming it directly to the client
- Summarize — The server replaces the full reasoning with a compressed summary
- Sign — The summary is returned with a cryptographic signature that allows Anthropic to verify its integrity and restore the original text if needed
- Replace — On subsequent turns, the signed summary replaces the original reasoning in the conversation history
The anti-distillation effect is powerful: anyone intercepting the network traffic between Claude Code and Anthropic's servers sees only the summary, not the actual chain-of-thought reasoning that makes Claude effective. A model trained on these summaries would learn the conclusions but not the reasoning process — like a student who memorizes answers without understanding the proofs.
| What an interceptor sees | What actually happened |
|---|---|
| Compressed summary of reasoning | Full multi-step chain-of-thought |
| Cryptographic signature blob | Integrity verification + original text key |
| Tool call result | Same (not modified) |
| Final response | Same (not modified) |
The cryptographic signatures serve a dual purpose. For Anthropic, they allow the system to restore the full reasoning when needed (so Claude's performance is not degraded). For attackers, they are opaque binary data that cannot be reversed without Anthropic's private keys. The reasoning is effectively encrypted in transit.
Strategic Impact of the Exposure
The irony of the Claude Code leak is that it exposed the very systems designed to protect against data theft. Now that both anti-distillation mechanisms are public knowledge, their effectiveness is significantly reduced:
- Fake tool filtering — Competitors who previously scraped Claude traffic blindly can now write filters to identify and remove fake tool definitions from their training data
- Summarization detection — Knowing that reasoning is summarized allows interceptors to potentially detect and discard those segments, or to collect data only from sessions where the feature is not active
- Flag identification — The feature flag name is now public, making it possible to monitor GrowthBook configuration changes
- Scope limitation — Knowing that anti-distillation only activates for first-party CLI sessions tells attackers to focus on third-party API usage instead
Anthropic will almost certainly redesign these mechanisms now that they are public. But the window between the leak and the redesign is a period of reduced protection — exactly the kind of vulnerability that anti-distillation was meant to prevent.
The Industry Context
Anti-distillation is not an Anthropic invention. The broader AI industry has been dealing with model theft through API scraping for years. OpenAI's terms of service explicitly prohibit using ChatGPT outputs to train competing models. Google has similar restrictions for Gemini.
But Anthropic's approach is different in a critical way: instead of relying on legal terms of service (which are hard to enforce internationally), they built technical countermeasures directly into the product. This is the difference between putting a "No Trespassing" sign on your lawn and installing an invisible fence with embedded trackers.
The fake tool injection is particularly aggressive because it is not just defensive — it is actively hostile. It does not merely protect Anthropic's data; it sabotages anyone who takes it. This is a weaponized defense, and its existence suggests that Anthropic has evidence (or strong suspicion) that their API traffic is being scraped for distillation at scale.
Whether this level of aggression is justified depends on the scale of the threat. If competitors are genuinely building models on stolen Claude data, poisoning that data is arguably the most effective countermeasure available. If the threat is more theoretical, it is an unnecessarily adversarial stance that could damage trust with legitimate users who discover fake tools in their sessions.
What Users Should Know
For regular Claude Code users, the practical impact of anti-distillation is minimal. The fake tools are injected into the system prompt on the server side and are invisible to the user. Claude's actual behavior is not affected — it uses only the real tools and produces normal responses.
The Connector-Text Summarization system does mean that your conversation history may contain summarized reasoning rather than full chain-of-thought text. In most cases, this is imperceptible. However, if you are debugging complex multi-step operations and reviewing the conversation log, you may notice that some of Claude's intermediate reasoning appears more compressed than expected.
Neither system collects additional user data or modifies the quality of Claude's outputs. They are purely defensive mechanisms designed to protect Anthropic's intellectual property from competitors — not to monitor or modify user experience.
Frequently Asked Questions
What is ANTI_DISTILLATION_CC in Claude Code?
ANTI_DISTILLATION_CC is a flag in Claude Code's API client (claude.ts) that, when activated via the GrowthBook feature flag tengu_anti_distill_fake_tool_injection, sends anti_distillation: ['fake_tools'] in API requests. This triggers Anthropic's servers to inject fake tool definitions into system prompts, poisoning any training data collected by intercepting the traffic.
How do fake tools poison competitor training data?
A model trained on data containing fake tool definitions learns to call tools that do not exist. When deployed, it produces tool hallucinations — attempting to use phantom tools that cause errors. The fake tools may also be unique per session, allowing Anthropic to forensically trace the source of data theft.
What is Connector-Text Summarization?
It is a second anti-distillation layer in betas.ts that buffers Claude's chain-of-thought reasoning between tool calls, replaces it with a compressed summary, and signs it with a cryptographic signature. Network interceptors see only the summary, not the full reasoning. Anthropic can restore the original via the signature.
Does anti-distillation affect regular Claude Code users?
No. The fake tools are invisible to users — they are injected server-side and Claude only uses real tools in its responses. Connector-Text Summarization may compress some intermediate reasoning in conversation logs, but output quality is unaffected. Both systems are purely defensive against data theft.
Is anti-distillation still effective after the leak?
Its effectiveness is significantly reduced. Competitors now know how to filter fake tools and detect summarized reasoning. Anthropic will likely redesign both mechanisms. However, the window between exposure and redesign creates a period of reduced protection — exactly what the system was built to prevent.



