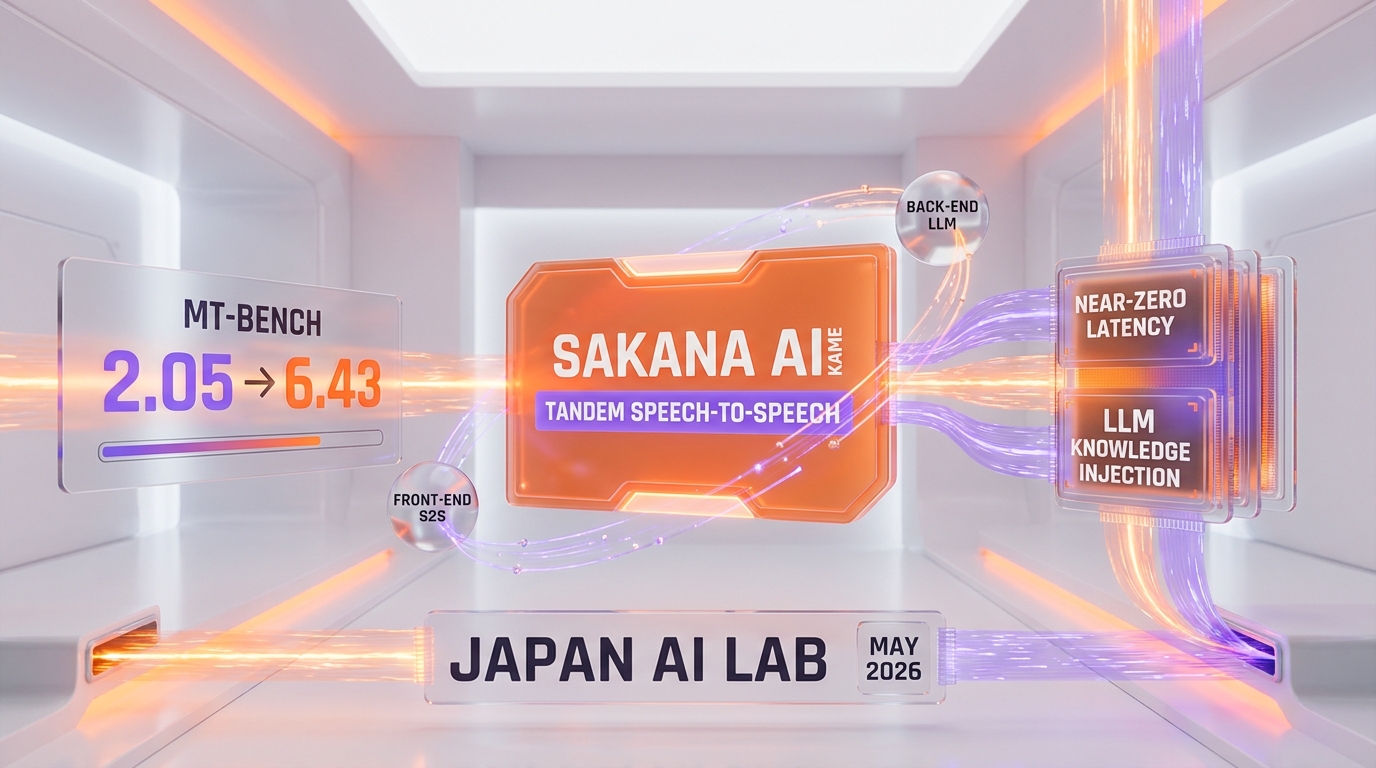
KAME (Knowledge-Access Model Extension) is a tandem speech-to-speech architecture from Sakana AI, the Tokyo research lab, that injects a back-end LLM's knowledge into a fast front-end speech model in real time. On a speech-synthesized MT-Bench subset, KAME lifts the average score from 2.05 (Moshi baseline) to 6.43 while keeping median response latency at 0.0 seconds — the same as the raw speech-to-speech model and far below the 2.1-second latency of a cascaded pipeline. The paper, accepted at ICASSP 2026, reframes voice AI from "think, then speak" to "speak while thinking."
For two years the voice AI conversation has been dominated by the same three names — ElevenLabs, Cartesia, OpenAI's Realtime API. Every release has been a variation on the same trade-off: either you get a fast, monolithic speech-to-speech model that sounds natural but reasons poorly, or you bolt an LLM onto an ASR-plus-TTS pipeline and pay for it with latency that breaks the rhythm of a real conversation. Sakana AI just published a paper that does not pick a side. It runs both at once.
This is a research result, not a product launch, and we are treating the timing honestly: the work surfaced in our feeds in early May 2026, but Sakana AI's own announcement is dated April 29, 2026, and the underlying arXiv preprint (2510.02327) traces back further. What matters is that the numbers are now public, the model is on Hugging Face, and the architecture is unusually clean. We read the full paper. Here is what KAME actually does, why the 2.05-to-6.43 jump is the headline, and why a Japanese lab best known for evolutionary model merging is suddenly the most interesting name in voice AI.
The Big Picture: Why Voice AI Has Been Stuck
Conversational voice AI in 2026 splits into two camps, and both have a structural flaw.
Camp One: Direct Speech-to-Speech
Direct speech-to-speech (S2S) models — Kyutai's Moshi is the canonical example — take audio in and produce audio out through a single monolithic transformer. Because nothing has to synchronize with an external system, turnaround time is extremely low. The model can start responding before you finish your sentence. That is what makes a conversation feel alive.
The problem is capacity. An S2S model has to encode not just the words but the paralinguistic envelope around them — speaking style, prosody, emotion, timing. For a given model size, a text-only LLM can pack far more world knowledge into its parameters because every parameter is spent on text. The S2S model is spending a large fraction of its capacity on sounding human, which leaves less for being right. On the speech-synthesized MT-Bench subset Sakana AI used, the Moshi baseline scores an average of 2.05 out of 10. It is fast and fluent and frequently wrong.
Camp Two: Cascaded Pipelines
The cascaded approach — automatic speech recognition, then a text LLM, then text-to-speech — is what most production voice agents run today, including stacks built on tools like ElevenLabs, Cartesia, and the GPT Realtime family. Knowledge is excellent because you can plug in a frontier LLM. But the pipeline has to wait for the user to finish speaking before ASR and the LLM can even start. Sakana AI's cascaded baseline, a modified version of Kyutai's Unmute running GPT-4.1, scores 7.70 — but at a median latency of 2.1 seconds. In a live conversation, a two-second gap before every reply is the difference between talking to a person and talking to a kiosk.
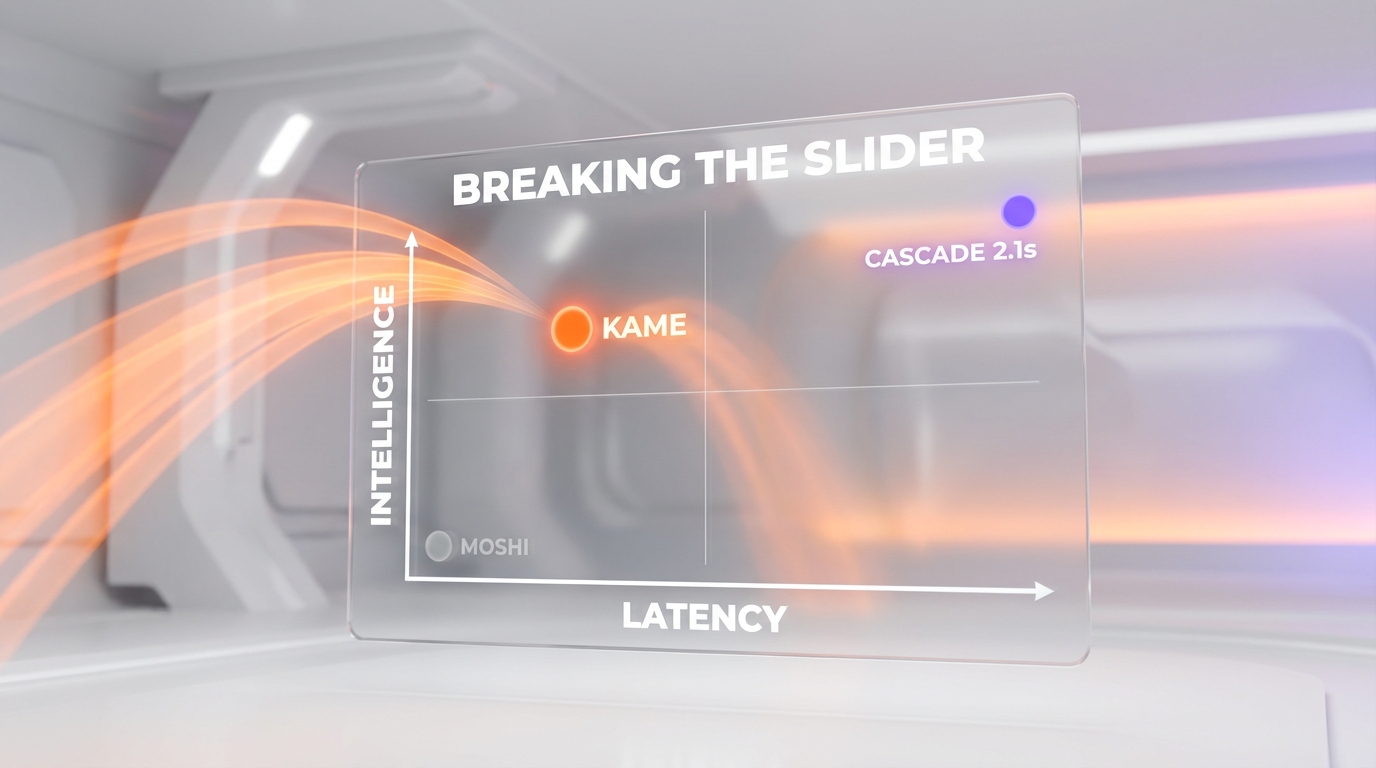
So the field has been frozen on a slider: drag toward latency and you lose intelligence; drag toward intelligence and you lose latency. KAME's contribution is to stop treating it as a slider.

The Tandem Architecture: Two Models on Two Clocks
KAME stands for Knowledge-Access Model Extension. The core idea is a tandem system: a front-end S2S model and a back-end text LLM that run on different time scales and stay asynchronously connected, rather than chained in sequence.
The Front-End: A Four-Stream Moshi
The front-end adapts Kyutai's Moshi architecture — an encoder, an S2S transformer, and a decoder. Moshi natively models three interleaved token streams: input audio, an inner-monologue text stream, and output audio. KAME adds a fourth: an oracle stream. This new stream carries the gradually evolving candidate response coming from the back-end LLM, and the front-end transformer is specifically trained to condition its speech generation on both its own internal context and this incoming oracle guidance.
The front-end runs fast — it consumes audio tokens at roughly 80-millisecond intervals. It does not wait for anyone. It starts answering immediately, the way a confident person starts a sentence before they have fully formed the thought.
The Back-End: A Swappable LLM on a Slower Clock
In parallel, a streaming speech-to-text component transcribes the user as they talk and periodically feeds partial transcripts to a back-end LLM. The back-end runs on a slower cycle — roughly 100 to 500 milliseconds. For each partial transcript, it generates a candidate response and streams it back to the front-end as oracle tokens. The front-end revises its in-progress speech as better guidance arrives. When two candidate responses overlap, KAME prioritizes the most recent one, because it was generated from a longer, more complete transcript and is therefore the most informed.
This is the paradigm shift Sakana AI describes: the system moves from "think, then speak" to "speak while thinking." It begins the answer on instinct and corrects it mid-utterance as the deeper reasoning catches up — which, not coincidentally, is exactly how humans talk.
Why "Back-End Agnostic" Is the Real Unlock
The front-end and back-end operate on different representations — one on audio, one on text — and the coupling between them is deliberately loose. That loose coupling means the back-end LLM is completely swappable. The paper shows GPT-4.1 and Claude-opus-4.1 as back-ends; Sakana AI's public demo also runs Gemini variants. You can pick the brain that fits the task without retraining the voice. This is the structural advantage cascaded systems have always had — and the one monolithic S2S models structurally cannot have. KAME keeps it while discarding the latency.
The Headline Number: 2.05 to 6.43
The single result that makes this paper matter is in Table 2 of the preprint. On the speech-synthesized MT-Bench subset — multi-turn question answering, with the categories unsuited to voice (Coding, Extraction, Math, Roleplay, Writing) excluded, scored by LLM-as-a-judge over six runs — the numbers are:
| System | Reasoning | STEM | Humanities | Average | Median latency |
|---|---|---|---|---|---|
| Moshi (S2S baseline) | 1.32 | 1.94 | 2.88 | 2.05 | 0.0 s |
| KAME w/ GPT-4.1 | 5.44 | 6.65 | 7.19 | 6.43 | 0.0 s |
| KAME w/ Claude-opus-4.1 | 5.72 | 6.53 | 6.43 | 6.23 | 0.0 s |
| Unmute (cascaded, GPT-4.1) | 7.08 | 8.35 | 7.67 | 7.70 | 2.1 s |
The average jumps from 2.05 to 6.43 — more than triple — and the median latency stays at 0.0 seconds. That zero is not a typo or rounding sleight of hand: for at least half of the sessions, both Moshi and KAME start responding before the user's question even ends. KAME adds the knowledge of a frontier LLM without adding a single measurable beat of delay over the raw speech-to-speech model.
Reading the Subscores Honestly
The gain is broad, not narrow. Reasoning climbs from 1.32 to 5.44, STEM from 1.94 to 6.65, humanities from 2.88 to 7.19. This is not one cherry-picked category carrying the average. The model got better at the kinds of questions a real assistant gets asked.
It is also worth being precise about what KAME does not claim. It does not beat the cascaded system. Unmute still scores 7.70 to KAME's 6.43. Sakana AI is transparent about why.

The Honest Caveat: Why KAME Trails the Cascade
The paper does not hide the gap to the cascaded system, and the explanation is the most interesting part of the analysis.
It Is a Timing Problem, Not a Knowledge Problem
Sakana AI ran a control: they isolated the back-end LLM's text responses from the KAME-with-GPT-4.1 runs and scored them directly. Those text answers averaged 7.79 — comparable to the cascaded Unmute system. The back-end brain is not the bottleneck. The gap comes from the front-end starting to answer with significantly less information, before the full question has landed and before the best oracle guidance has arrived. Sometimes KAME has to correct itself mid-sentence after a contradictory oracle, which is natural in spoken conversation but produces redundant phrasing that an LLM-as-a-judge penalizes in the written transcript.
This is a subtle and honest point. The score gap is partly an artifact of judging spontaneous, self-correcting speech as if it were polished prose. Humans do the same thing — start a sentence, catch themselves, revise — and we do not score each other down for it.
The Latency-Quality Curve
To probe the trade-off, the researchers forced KAME to delay its response by emitting silence and padding tokens for a fixed window before speaking. Initially, a small forced delay improves quality — the model gets more oracle guidance before committing. But the benefit flattens at higher latency, which the authors attribute to a lack of long-pause examples in training, fixable with data curation. The takeaway: the gap to the cascade is premature generation, not a ceiling on the architecture. KAME is sitting at one operating point on a tunable curve, and it is sitting there on purpose.
How KAME Was Trained: Inventing the Oracle Data
One reason this architecture has not appeared before is that the training data for it does not exist in the wild. KAME's front-end needs oracle tokens that not only carry external knowledge but also evolve in real time as the user's speech unfolds. No conversational dataset is annotated that way. Sakana AI's solution is characteristically clever.
Simulated Oracle Augmentation
They synthesize the oracle stream from a standard dataset that already contains a user input and a ground-truth response. A separate "simulator" LLM is prompted to produce an oracle sentence whose accuracy is controlled by how much of the user's utterance has been heard so far, measured as the ratio of words observed. Early in the utterance the oracle is a plausible but uninformed guess; as more words arrive it is constrained progressively closer to the true answer; when the utterance completes, the ground-truth response is used directly. This six-level "hint" schedule teaches the front-end to listen to oracle guidance that starts vague and sharpens over time — exactly the signal a live back-end LLM produces.
Building the Conversational Corpus
To get scale, they converted text question-answer benchmarks into spoken dialogue using a TTS system and a word-aligner: 22,800 sessions seeded from MMLU-Pro, 11,742 from GSM8K, and 22,040 from HSSBench. The front-end was then trained with a combined text-and-audio loss, weighting audio 1.5x, with all other hyperparameters inherited from the original Moshi setup. The training recipe is a contribution in itself: it shows how to bootstrap a brand-new architecture from data that was never collected for it.
Sakana AI: The Lab Behind the Result
KAME did not come from a voice AI specialist. It came from Sakana AI, a Tokyo research lab founded by ex-Google researchers, including a co-author of the original Transformer paper. Sakana's reputation was built on a different kind of work: evolutionary model merging, which combines existing open models without gradient training, and the AI Scientist, an agent that runs end-to-end research experiments. The throughline is a preference for nature-inspired, efficiency-first ideas over brute-force scaling.
Why This Pedigree Matters Here
KAME fits that philosophy precisely. It does not propose a bigger speech model. It proposes a smarter arrangement of models that already exist — a front-end you keep and a back-end you swap. The authors are So Kuroki, Yotaro Kubo, Takuya Akiba, and Yujin Tang, and the paper is accepted at ICASSP 2026, the flagship signal-processing venue, which is a deliberate signal that this is rigorous speech research, not a demo.
The Geographic Angle
Almost every voice AI release we cover originates from a US or European lab. KAME is a reminder that the frontier is wider than the trio that dominates English-language coverage. Japan's AI ecosystem has been quietly strong in robotics, speech, and efficient architectures for years; a clean ICASSP result on the central trade-off in conversational AI is the kind of work that travels regardless of where it was written.

What It Means for the Voice AI Stack
If you build voice agents today, you almost certainly run a cascade and you almost certainly fight latency. KAME does not retire that stack overnight — it is a research model on Hugging Face, not a managed API. But it changes the design conversation in three concrete ways.
It Reframes the Build-vs-Buy Question
The standard answer to "how do I get a voice agent that is both smart and fast" has been "you cannot, pick one, then engineer around the loss." KAME demonstrates that the trade-off is not fundamental. That alone reshapes how teams evaluate vendors like ElevenLabs, Cartesia, and the GPT Realtime API: the question shifts from "which side of the slider do I accept" to "who ships a tandem architecture first."
It Makes the Back-End a Commodity Slot
Because the back-end is swappable, the value migrates to the front-end speech model and the orchestration between the two. The LLM becomes a pluggable component — GPT-4.1, Claude-opus-4.1, Gemini, whatever fits the task. That is good for builders and complicated for any vendor whose moat is owning the whole pipeline end to end.
It Validates the "Speak While Thinking" Pattern
Adjacent research is converging on the same instinct that fast and slow processes should run in parallel rather than in sequence. We have covered this theme elsewhere — efficient interaction models from Thinking Machines Lab explore a related "respond now, refine continuously" idea (that work is still pre-publication on our side, so we are noting it without linking). KAME gives the pattern a clean speech-domain result and a number anyone can cite.
Our Take
We have read a lot of voice AI papers that claim to solve the latency-quality trade-off and turn out to have moved it somewhere you cannot see. KAME is not that. The honesty is the tell: Sakana AI publishes the gap to the cascade, isolates the cause to early generation rather than back-end weakness, and shows the latency-quality curve instead of cropping it. That is what a real result looks like.
Strategically, the most underrated line in the paper is "the back-end LLM is completely swappable." Architectures that decouple the fast path from the smart path tend to win, because they let each half improve independently and let the market commoditize the expensive half. KAME is a small model with a big idea, and the idea is more portable than the model. The number to remember is 2.05 to 6.43 at zero added latency. The thing to watch is which production voice vendor implements a tandem front-end first — and whether the next one comes from San Francisco, Paris, or Tokyo.
Frequently Asked Questions
What is Sakana AI KAME?
KAME (Knowledge-Access Model Extension) is a tandem speech-to-speech architecture from Sakana AI, a Tokyo research lab. It runs a fast front-end speech model and a slower back-end text LLM in parallel, injecting the LLM's knowledge into the speech model in real time through an "oracle" stream. On a speech-synthesized MT-Bench subset it lifts the average score from 2.05 to 6.43 while keeping median latency at 0.0 seconds. The paper is accepted at ICASSP 2026.
What does the 2.05 to 6.43 MT-Bench result mean?
On the speech-synthesized MT-Bench subset used in the paper, the Moshi speech-to-speech baseline averages 2.05 out of 10, while KAME with a GPT-4.1 back-end averages 6.43 — more than triple — at the same 0.0-second median latency. The gain is broad: reasoning rises from 1.32 to 5.44, STEM from 1.94 to 6.65, and humanities from 2.88 to 7.19. It is not a single cherry-picked category carrying the average.
How does the KAME tandem architecture work?
A front-end S2S model (a four-stream adaptation of Kyutai's Moshi) processes audio at roughly 80-millisecond intervals and starts answering immediately. In parallel, a streaming speech-to-text component feeds partial transcripts to a back-end LLM running on a 100-to-500-millisecond cycle, which streams candidate answers back as "oracle" tokens. The front-end is trained to revise its speech as better oracle guidance arrives, shifting from "think, then speak" to "speak while thinking."
Why doesn't KAME beat the cascaded system?
It does not — Sakana AI's cascaded Unmute baseline scores 7.70 versus KAME's 6.43. The paper isolates the cause: when the back-end LLM's text answers from the KAME runs are scored alone, they average 7.79, comparable to the cascade. The gap is not back-end weakness but the front-end starting to speak with less information and self-correcting mid-utterance, which an LLM-as-a-judge penalizes as redundant phrasing in the transcript.
Is the back-end LLM in KAME swappable?
Yes. The front-end and back-end operate on different representations and are loosely coupled, so the back-end LLM is completely swappable without retraining the voice model. The paper reports results with GPT-4.1 and Claude-opus-4.1 back-ends (averaging 6.43 and 6.23), and Sakana AI's public demo also runs Gemini variants. This back-end agnosticism is the structural advantage cascaded systems have, kept without the latency penalty.
How is KAME different from ElevenLabs, Cartesia, or the GPT Realtime API?
ElevenLabs and Cartesia are production speech and voice platforms, and OpenAI's GPT Realtime API is a managed real-time voice endpoint; most production agents using them run a cascaded ASR-LLM-TTS pipeline. KAME is a research architecture, not a managed product — it is a tandem design that runs a fast speech model and a back-end LLM concurrently rather than in sequence, which is why it keeps cascade-level knowledge gains without cascade-level latency. It is published on Hugging Face, not offered as an API.
What latency does KAME actually achieve?
The paper reports a 0.0-second median response latency for both the Moshi baseline and KAME, versus 2.1 seconds for the cascaded Unmute system. A 0.0-second median means that for at least half of the test sessions the model begins responding before the user's question ends. KAME adds frontier-LLM knowledge without adding measurable latency over the raw speech-to-speech model.
What is Sakana AI and why does this come from them?
Sakana AI is a Tokyo research lab founded by ex-Google researchers, known for evolutionary model merging and the AI Scientist research agent. Its philosophy favors efficient, nature-inspired arrangements of existing models over brute-force scaling. KAME fits that pattern exactly: it does not build a bigger speech model, it composes a swappable back-end LLM with a kept front-end. The authors are So Kuroki, Yotaro Kubo, Takuya Akiba, and Yujin Tang.
How was KAME trained without real oracle data?
The required oracle data — knowledge tokens that evolve in real time as speech unfolds — does not exist naturally, so Sakana AI synthesized it. A "simulator" LLM produces oracle sentences whose accuracy is controlled by how much of the user's utterance has been heard, following a six-level hint schedule from uninformed guess to ground truth. Text Q&A benchmarks (MMLU-Pro, GSM8K, HSSBench) were converted to spoken dialogue with TTS, yielding tens of thousands of training sessions.
When was KAME released and where can I find it?
Sakana AI's announcement is dated April 29, 2026, and the work is accepted at ICASSP 2026; the underlying arXiv preprint is 2510.02327. The result reached wider AI-news coverage in early May 2026. The model is published on Hugging Face under SakanaAI/kame, with the official write-up on Sakana AI's site. It is a research release, not a commercial API.
Does KAME replace cascaded voice pipelines today?
Not yet. KAME is a research model, not a managed API, and it still trails a tuned cascaded system on raw quality (6.43 versus 7.70). What it changes is the design conversation: it demonstrates the latency-quality trade-off is not fundamental, which reshapes how teams evaluate voice stacks and shifts value toward the front-end speech model and orchestration while turning the back-end LLM into a swappable slot.
Why does the Japan origin of KAME matter?
Almost every widely covered voice AI release comes from a US or European lab, so the central trade-off in conversational AI has mostly been framed by that trio. A clean ICASSP 2026 result from a Tokyo lab on exactly that trade-off is a reminder that the research frontier is wider than English-language coverage suggests, and that Japan's strength in speech and efficient architectures produces work that travels regardless of origin.
Sources: Sakana AI official announcement and model card (sakana.ai, Hugging Face SakanaAI/kame), and the KAME arXiv preprint (arXiv:2510.02327), accepted at ICASSP 2026. All MT-Bench scores and latency figures are from Table 2 of the preprint. For related production voice tools, see our reviews of ElevenLabs, Cartesia, GPT Realtime, and Claude, plus our ElevenLabs vs Cartesia comparison and our deep dive on the best ElevenLabs voices.



