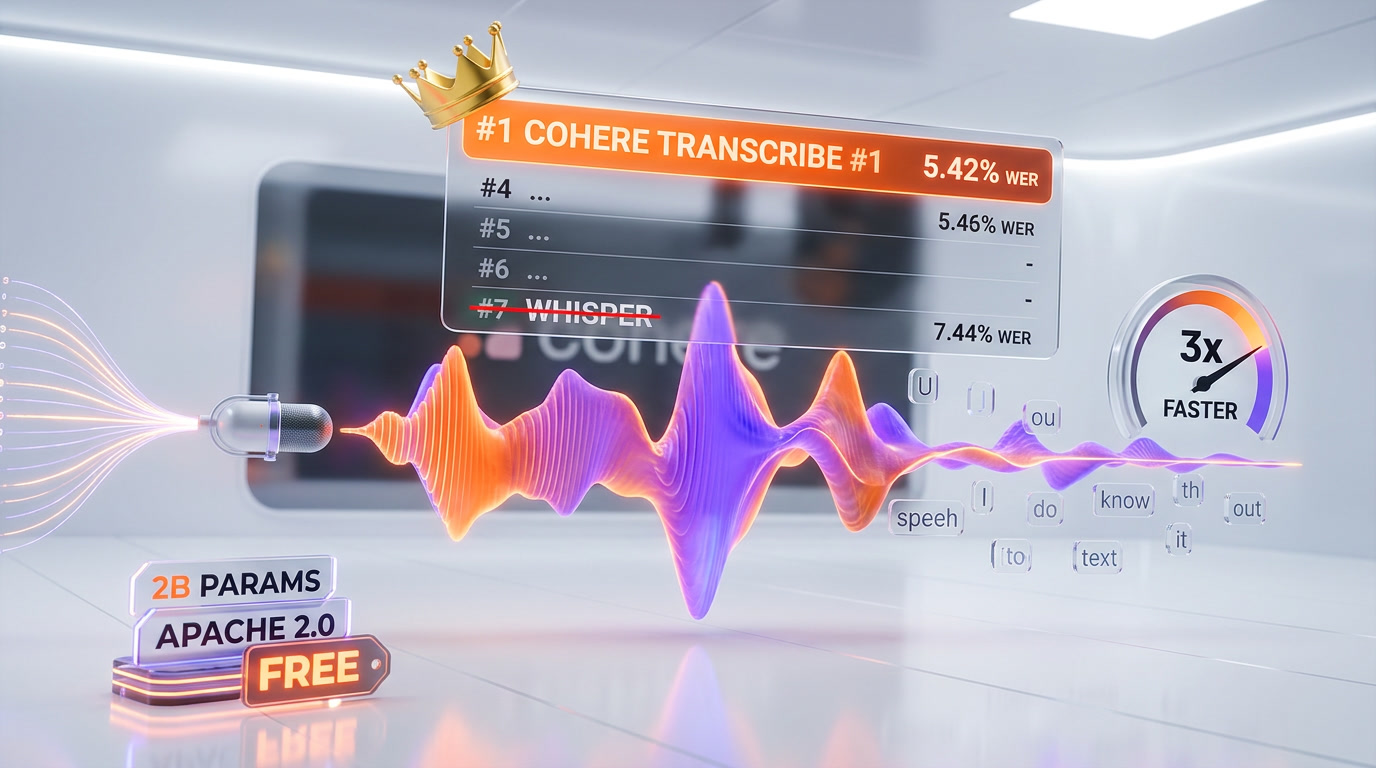
Cohere Transcribe is a 2-billion-parameter open-source automatic speech recognition (ASR) model released on March 26, 2026 under Apache 2.0. It ranks #1 on HuggingFace's Open ASR Leaderboard with a 5.42% average word error rate, beating OpenAI Whisper Large v3 (7.44% WER) by 27%. It supports 14 languages, processes 525 minutes of audio per minute, and is free to use via Cohere's API.
Why Cohere Transcribe Matters Right Now
The speech-to-text space just got its biggest shakeup since OpenAI released Whisper in September 2022. Cohere, the Toronto-based enterprise AI company, dropped Transcribe on March 26, 2026 -- and it immediately claimed the top position on the industry's most watched benchmark.
We have been tracking ASR models closely since Whisper first democratized speech recognition. What makes Cohere Transcribe significant is not just the benchmark win -- it is the combination of state-of-the-art accuracy, open-source licensing, and a model small enough to run on a gaming laptop. That trifecta has never existed before in the ASR space.
| Model | Parameters | Avg WER | License | Languages | RTFx vs. Whisper |
|---|---|---|---|---|---|
| Cohere Transcribe | 2B | 5.42% | Apache 2.0 | 14 | 3x faster |
| Zoom Scribe v1 | -- | 5.47% | Proprietary | -- | -- |
| IBM Granite 4.0 1B | 1B | 5.52% | Apache 2.0 | -- | -- |
| NVIDIA Canary Qwen 2.5B | 2.5B | 5.63% | Open | -- | -- |
| Qwen3-ASR-1.7B | 1.7B | 5.76% | Open | -- | -- |
| ElevenLabs Scribe v2 | -- | 5.83% | Proprietary | -- | -- |
| OpenAI Whisper Large v3 | 1.5B | 7.44% | MIT | 99 | Baseline |
Best for: Enterprise teams needing production-grade transcription with data sovereignty, developers building RAG pipelines with audio inputs, and anyone running ASR on edge devices or consumer GPUs.
Benchmark Deep Dive: 5.42% WER Across 8 Datasets
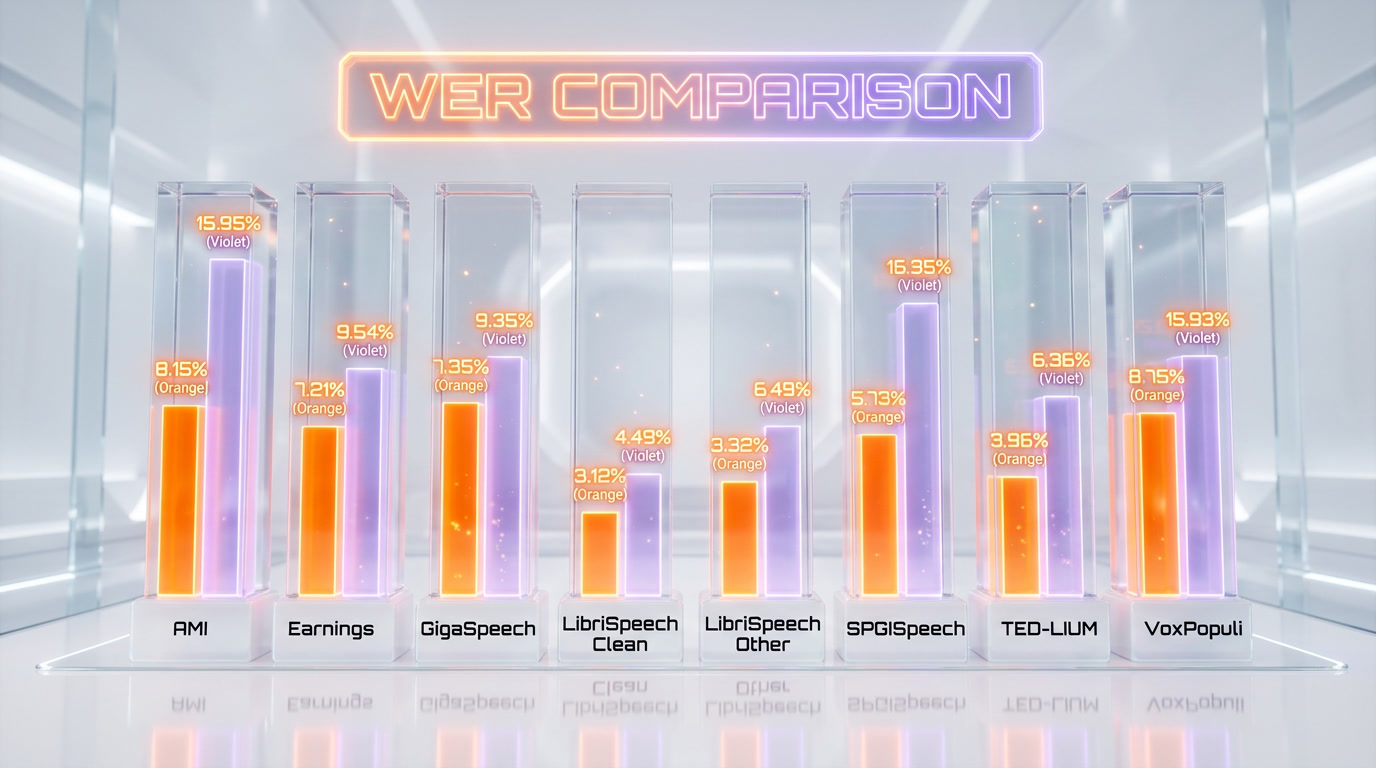
The HuggingFace Open ASR Leaderboard evaluates models across 8 English benchmark datasets, each testing different real-world scenarios. We went through the per-dataset numbers, and Cohere Transcribe's consistency is what stands out -- it does not just win on average; it leads or stays competitive on every single test.
| Dataset | Cohere Transcribe | Whisper Large v3 | What It Tests |
|---|---|---|---|
| AMI | 8.15% | 15.95% | Multi-speaker meetings |
| Earnings 22 | 10.84% | 11.29% | Financial earnings calls |
| GigaSpeech | 9.33% | 10.02% | Web audio (YouTube, podcasts) |
| LibriSpeech Clean | 1.25% | 2.01% | High-quality audiobooks |
| LibriSpeech Other | 2.37% | 3.91% | Noisy/accented audiobooks |
| SPGISpeech | 3.08% | 2.94% | Financial transcripts |
| TED-LIUM | 2.49% | 3.86% | TED talks |
| VoxPopuli | 5.87% | 9.54% | European Parliament speeches |
The most dramatic gap is on AMI (meeting recordings): 8.15% vs. 15.95%. That is nearly a 50% reduction in word errors for the exact use case most enterprises care about -- meeting transcription. On LibriSpeech Clean, Cohere Transcribe hits 1.25% WER, approaching human-level accuracy.
Human Evaluation: 64% Preference Over Whisper
Benchmarks tell one story. Human preference tells another. Cohere ran pairwise evaluations where annotators compared transcripts side by side without knowing which model produced them.
The results reinforce the benchmark data. In English-language head-to-head comparisons, annotators preferred Cohere Transcribe over Whisper Large v3 in 64% of cases. Against IBM Granite, the preference rate jumped to 78%. Overall, Cohere Transcribe achieved a 61% average preference rate across all competitors tested.
Multilingual human evaluations showed similarly strong results: 70% preference in Japanese, 60% in Italian, and 51% in French. The Japanese result is particularly notable given that ASR models historically struggle with non-Latin scripts.
Architecture: Why 90% Encoder Makes It 3x Faster
Cohere Transcribe uses an asymmetric encoder-decoder architecture that explains both its accuracy and its speed advantage. More than 90% of the model's 2 billion parameters sit in a Fast-Conformer encoder that processes acoustic representations. The decoder -- which generates text tokens autoregressively -- is intentionally kept lightweight.
This design choice is the key to the model's efficiency. Autoregressive decoding (generating one token at a time) is the computational bottleneck in most sequence-to-sequence models. By front-loading parameters into the encoder, Cohere keeps the slow sequential decoding step as light as possible.
Technical Specifications
- Architecture: Encoder-decoder X-attention Transformer with Fast-Conformer encoder
- Parameters: 2B total (>90% in encoder)
- Training data: 500,000 hours of curated audio-transcript pairs + synthetic augmentation
- Tokenizer: 16K multilingual BPE with byte fallback
- Augmentation: Non-speech background noise at SNR 0-30 dB
- VRAM footprint: Under 8 GB when quantized
- Throughput: 525 minutes of audio processed per minute
- Real-time factor: 3x faster than similarly sized competitors
The training data volume of 500,000 hours is substantial but not unprecedented -- Whisper was trained on 680,000 hours. What differs is Cohere's focus on curated quality over raw quantity, plus synthetic noise augmentation that improves robustness in real-world environments.
14 Languages Across Three Regions
Cohere Transcribe supports 14 languages grouped by region:
- European (9): English, French, German, Italian, Spanish, Portuguese, Greek, Dutch, Polish
- Asia-Pacific (4): Mandarin Chinese, Japanese, Korean, Vietnamese
- MENA (1): Arabic
This is significantly fewer than Whisper's 99 languages. However, Cohere's approach prioritizes depth over breadth -- the 14 supported languages cover the vast majority of enterprise use cases globally. On the multilingual ASR leaderboard, Cohere Transcribe ranks 4th overall and 2nd among open-source models.
One limitation we noted: the model expects monolingual audio per segment. Code-switching (mixing languages within a single utterance) is not officially supported, though Cohere notes some limited code-switched capability has been observed.
Three Deployment Paths: Open Source, API, and Model Vault
Cohere offers three distinct ways to deploy Transcribe, each targeting a different use case:
1. Open-Source Self-Hosted
Download the full model weights from HuggingFace (CohereLabs/cohere-transcribe-03-2026) and run it on your own infrastructure. Apache 2.0 license means full commercial use with no restrictions. At under 8 GB VRAM when quantized, it fits on a modern gaming laptop or a budget cloud GPU instance. vLLM integration is available for up to 2x additional throughput improvement.
2. Free API Tier
Cohere provides a free tier with rate limits through their dashboard. This is the fastest way to test the model without any infrastructure setup. Ideal for prototyping and low-volume use cases.
3. Model Vault (Managed Enterprise)
Cohere's dedicated, secure inference platform for production workloads. Pricing is per hour-instance with discounted long-term commitment plans. Specific per-minute costs require contacting Cohere's sales team. This option gives enterprises low-latency private cloud inference without managing GPU infrastructure.

Cohere Transcribe vs. OpenAI Whisper: The Full Picture
The Whisper comparison deserves its own section because Whisper has been the de facto standard in open-source ASR since 2022. We have used Whisper Large v3 extensively in production workflows, and switching to Cohere Transcribe is a real consideration.
| Feature | Cohere Transcribe | Whisper Large v3 |
|---|---|---|
| Avg WER | 5.42% | 7.44% |
| Parameters | 2B | 1.5B |
| Languages | 14 | 99 |
| License | Apache 2.0 | MIT |
| Speed (RTFx) | 3x faster | Baseline |
| VRAM (quantized) | <8 GB | ~6 GB |
| Meeting transcription (AMI WER) | 8.15% | 15.95% |
| Human preference (head-to-head) | 64% | 36% |
| Code-switching | Limited | Yes |
| Translation | No | Yes (to English) |
| Managed enterprise offering | Yes (Model Vault) | No (API via OpenAI only) |
Whisper still wins on language breadth (99 vs. 14) and built-in translation capability. If you need to transcribe Swahili or Icelandic, Whisper remains your only open-source option. But for the 14 languages Cohere supports -- which cover the majority of enterprise and consumer audio -- Transcribe delivers measurably better accuracy and significantly faster inference.
The 27% WER reduction is not incremental. In production, that translates to noticeably fewer corrections needed in meeting notes, call center analytics, and subtitle generation. For teams processing thousands of hours monthly, those error reductions compound into real cost and time savings.
What This Means for Enterprise Speech AI
Cohere has built its reputation on enterprise-focused AI with a strong emphasis on data sovereignty. Transcribe extends that philosophy into speech recognition. Three things stand out for enterprise buyers:
Data sovereignty. With Apache 2.0 licensing and under-8GB quantized VRAM, enterprises can run Transcribe entirely on-premises. Audio data never leaves the corporate network. This is a non-negotiable requirement in healthcare, finance, legal, and government sectors.
Production readiness. The 3x speed advantage means lower inference costs per minute of audio. For a company transcribing 10,000 hours of call center audio monthly, that 3x throughput improvement directly translates to 3x fewer GPU hours needed -- or the ability to process 3x more audio on the same infrastructure.
Agent integration. Cohere has signaled plans to integrate Transcribe with North, its AI agent orchestration platform. This positions Transcribe not just as a standalone transcription tool but as the speech input layer for autonomous enterprise agents that listen, understand, and act on spoken language.
Known Limitations We Identified
No model is perfect, and we want to flag two issues Cohere themselves acknowledge:
Hallucination on non-speech audio. Transcribe can eagerly transcribe background noise, music, or other non-speech sounds as if they were speech. Cohere recommends using voice activity detection (VAD) or a noise gate as preprocessing. This is a common issue across ASR models, but it is worth building into your pipeline from day one.
Monolingual assumption. The model expects each audio segment to contain only one language. A bilingual meeting (e.g., switching between English and Spanish) will produce degraded results. You need to segment audio by language first or use a separate language detection step.
The ASR Competitive Landscape in 2026
Cohere Transcribe's arrival tightens an already competitive ASR leaderboard. The top 6 models are now separated by less than half a percentage point of WER:
- Cohere Transcribe -- 5.42% (open-source, Apache 2.0)
- Zoom Scribe v1 -- 5.47% (proprietary)
- IBM Granite 4.0 1B -- 5.52% (open-source, Apache 2.0)
- NVIDIA Canary Qwen 2.5B -- 5.63% (open)
- Qwen3-ASR-1.7B -- 5.76% (open)
- ElevenLabs Scribe v2 -- 5.83% (proprietary)
The gap between #1 and #6 is just 0.41 percentage points. This suggests ASR accuracy for English is approaching a plateau where further improvements will be increasingly marginal. The next competitive differentiators will likely be speed, cost efficiency, multilingual depth, and enterprise deployment flexibility -- areas where Cohere's 3x throughput advantage and Apache 2.0 licensing give it an edge.
Our Take: A Legitimate Whisper Replacement for Most Use Cases
We have spent years recommending Whisper Large v3 as the default open-source ASR model. Cohere Transcribe changes that recommendation for the 14 languages it supports. The 27% WER improvement is too significant to ignore, the 3x speed advantage directly cuts inference costs, and the Apache 2.0 license removes any commercial deployment friction.
For teams that need 99-language support or built-in translation, Whisper remains essential. For everyone else building English-first (or major-language) transcription pipelines, Cohere Transcribe should be your new default starting point.
The fact that it runs on under 8 GB of VRAM makes it accessible to individual developers and small teams, not just enterprises with GPU clusters. That democratization of state-of-the-art speech recognition is arguably the most impactful aspect of this release.
Frequently Asked Questions
What is Cohere Transcribe?
Cohere Transcribe is a 2-billion-parameter open-source automatic speech recognition (ASR) model released by Cohere on March 26, 2026. It converts audio to text and currently ranks #1 on HuggingFace's Open ASR Leaderboard with a 5.42% average word error rate across 8 benchmark datasets.
How does Cohere Transcribe compare to OpenAI Whisper?
Cohere Transcribe achieves 5.42% average WER compared to Whisper Large v3's 7.44% -- a 27% relative improvement. It is also 3x faster at inference. However, Whisper supports 99 languages vs. Transcribe's 14, and Whisper includes built-in translation that Transcribe lacks.
Is Cohere Transcribe free to use?
Yes, in two ways. The model is open-source under Apache 2.0 and can be downloaded from HuggingFace for self-hosting at zero cost. Cohere also provides a free API tier with rate limits for testing and low-volume use. Enterprise managed deployment through Model Vault requires paid plans.
What languages does Cohere Transcribe support?
Cohere Transcribe supports 14 languages: English, French, German, Italian, Spanish, Portuguese, Greek, Dutch, Polish, Arabic, Vietnamese, Mandarin Chinese, Japanese, and Korean.
Can I run Cohere Transcribe on my own hardware?
Yes. When quantized, the model requires under 8 GB of VRAM, making it runnable on modern gaming laptops with GPUs like the RTX 4060 or higher. It also supports vLLM for optimized inference with up to 2x additional throughput improvement.
What are the limitations of Cohere Transcribe?
Two main limitations: (1) it can hallucinate transcriptions from non-speech audio like background music, so voice activity detection preprocessing is recommended, and (2) it assumes monolingual audio per segment, meaning code-switching between languages within a single utterance is not reliably supported.
How was Cohere Transcribe trained?
The model was trained on 500,000 hours of curated audio-transcript pairs with synthetic data augmentation including non-speech background noise at 0-30 dB signal-to-noise ratios. It uses a 16K multilingual BPE tokenizer with byte fallback.
What is the architecture of Cohere Transcribe?
It uses an asymmetric encoder-decoder design: over 90% of its 2B parameters are in a Fast-Conformer encoder that processes audio, paired with a lightweight Transformer decoder for text generation. This design minimizes the computational cost of autoregressive decoding, enabling the 3x speed advantage.
Frequently Asked Questions
Is Cohere Transcribe better than OpenAI Whisper Large v3?
Yes, on every major benchmark. Cohere Transcribe achieves 5.42% average WER vs. Whisper Large v3's 7.44% — a 27% improvement. In head-to-head human evaluations, annotators preferred Cohere Transcribe in 64% of cases. The gap is especially large on meeting transcription (AMI dataset): 8.15% WER vs. Whisper's 15.95%, a nearly 50% reduction in word errors. Cohere Transcribe is also 3x faster in inference. However, Whisper still supports 99 languages vs. Cohere's 14, and includes built-in translation to English, which Cohere does not currently offer.
Is Cohere Transcribe better than ElevenLabs Scribe v2?
According to HuggingFace's Open ASR Leaderboard, yes. Cohere Transcribe ranks #1 at 5.42% average WER, while ElevenLabs Scribe v2 ranks 6th at 5.83% WER. Beyond accuracy, the critical difference is licensing: Cohere Transcribe is open-source (Apache 2.0) and can be self-hosted, while ElevenLabs Scribe v2 is proprietary API-only. For teams requiring data sovereignty or offline inference, Cohere Transcribe is the clear choice.
How does Cohere Transcribe compare to IBM Granite 4.0 ASR?
Cohere Transcribe (5.42% WER) outperforms IBM Granite 4.0 1B (5.52% WER) on HuggingFace's Open ASR Leaderboard. In human preference evaluations, annotators chose Cohere Transcribe over IBM Granite in 78% of cases — the highest preference rate recorded in the study. Cohere Transcribe's 2B parameter encoder-heavy architecture also delivers 3x faster inference than similarly sized competitors.
How does Cohere Transcribe compare to NVIDIA Canary Qwen 2.5B?
Cohere Transcribe (5.42% WER) beats NVIDIA Canary Qwen 2.5B (5.63% WER) on the HuggingFace Open ASR Leaderboard. Despite having similar parameter counts (2B vs. 2.5B), Cohere Transcribe's Fast-Conformer encoder architecture, which houses 90%+ of parameters in the encoder rather than the decoder, delivers better accuracy and 3x faster real-time inference. Both models carry open licenses.
Who should use Cohere Transcribe?
Cohere Transcribe is best suited for three audiences: (1) Enterprise teams needing production-grade transcription with full data sovereignty — self-host under Apache 2.0 on under 8 GB VRAM; (2) Developers building RAG pipelines with audio inputs, where low WER (5.42%) directly improves retrieval quality; (3) Anyone running ASR on edge devices or consumer GPUs, since the model runs on a modern gaming laptop when quantized. It is not ideal for use cases requiring 99-language coverage or built-in translation — for those, Whisper Large v3 remains the benchmark.
What are Cohere Transcribe's limitations?
Cohere Transcribe has three notable limitations: (1) Language support — only 14 languages vs. OpenAI Whisper's 99; (2) No translation — Whisper can transcribe and translate to English in one pass; Cohere Transcribe cannot; (3) Code-switching — the model expects monolingual audio per segment and does not officially support mixed-language utterances, though some limited capability has been observed. The model also requires under 8 GB VRAM when quantized, which may need optimization on very low-end hardware.
Does Cohere Transcribe integrate with vLLM?
Yes. When self-hosting Cohere Transcribe via HuggingFace (model ID: CohereLabs/cohere-transcribe-03-2026), vLLM integration is available and delivers up to 2x additional throughput improvement on top of the base 525 minutes-of-audio-per-minute processing speed. Combined with the Fast-Conformer encoder architecture, this makes Cohere Transcribe one of the most efficient open-source ASR deployments available in 2026.
Is Cohere Transcribe free to use?
Yes, in two ways. First, it is fully open-source under Apache 2.0, meaning you can download the weights from HuggingFace (CohereLabs/cohere-transcribe-03-2026) and self-host it commercially at no cost. Second, Cohere offers a free API tier with rate limits through their dashboard — no GPU required. For production-scale enterprise workloads, Cohere also offers a managed Model Vault deployment at hourly instance pricing with discounted long-term commitment plans.



