
DeepSeek V4 is a ~1 trillion parameter Mixture-of-Experts AI model with 37 billion active parameters per token, a 1 million token context window powered by Engram conditional memory, and native multimodal generation across text, image, and video. The model is expected to launch in April 2026 under an Apache 2.0 open-weight license, with projected API pricing around $0.30 per million input tokens — roughly 50x cheaper than closed-source competitors like Claude Opus 4.6 ($15 per million tokens) and GPT-5.4.
Why DeepSeek V4 Matters Right Now
We have been tracking DeepSeek's trajectory since V2 disrupted the open-source LLM landscape in 2024. Each release has triggered what the industry now calls a "DeepSeek moment" — a sudden recalibration of what open models can achieve at what cost. V3 did it with 671 billion parameters trained for just 2.788 million H800 GPU hours. V4 is poised to do it again, at a scale that directly challenges the closed-model incumbents.
The stakes are higher this time. According to Chinese tech outlet Whale Lab (via Dataconomy), DeepSeek V4 and Tencent's new Hunyuan model are both set for April 2026 launches. Multiple earlier release windows — mid-February, Lunar New Year, late February, early March — all passed without an official drop. But a "V4 Lite" variant (~200B parameters) briefly appeared on DeepSeek's platform on March 9, 2026, suggesting an incremental rollout strategy is underway.
DeepSeek V4 Technical Specifications
| Specification | DeepSeek V3.2 (Current) | DeepSeek V4 (Expected) |
|---|---|---|
| Total Parameters | 671B | ~1 Trillion |
| Active Parameters/Token | 37B | ~32-37B |
| Architecture | MoE + Multi-head Latent Attention | MoE + Engram + mHC + Sparse Attention |
| Context Window | 128K tokens | 1M tokens (8x increase) |
| Multimodal | Text only | Native text + image + video |
| Training Hardware | NVIDIA H800 | Huawei Ascend 910B/910C (target) |
| API Pricing (Input) | $0.14 per million tokens | ~$0.30 per million tokens (projected) |
| API Pricing (Output) | $0.28 per million tokens | ~$0.50 per million tokens (projected) |
| Cache Hit Pricing | $0.028 per million tokens | ~$0.03 per million tokens (projected) |
| License | DeepSeek License | Apache 2.0 (confirmed) |
Even at projected pricing of $0.30 per million tokens input, DeepSeek V4 would remain approximately 50x cheaper than Claude Opus 4.6 ($15 per million tokens) and roughly 27x cheaper than GPT-5.4 for equivalent input volume. The cache-hit pricing at $0.03 per million tokens makes long-context and repeated-prompt workflows extraordinarily affordable.
Three Architectural Breakthroughs That Define V4
DeepSeek V4 is not a simple parameter scale-up of V3. Three architectural innovations set it apart from every model currently available.
1. Engram Conditional Memory
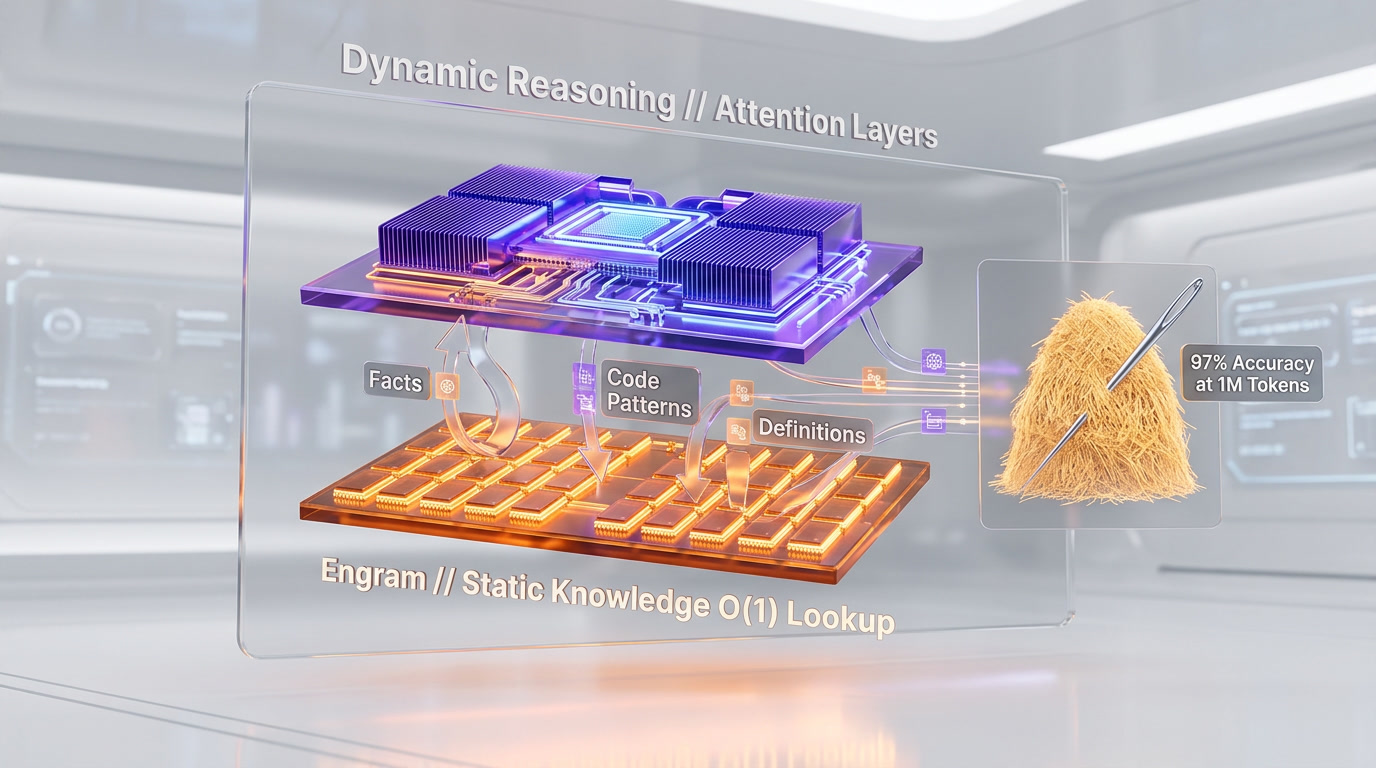
Published in a research paper on January 13, 2026, Engram is DeepSeek's most consequential innovation. The system decouples static knowledge retrieval from dynamic neural reasoning by using a hash-based lookup table stored in system DRAM rather than GPU VRAM.
When the model encounters static patterns — factual knowledge, common code patterns, standard definitions — Engram retrieves them in O(1) constant time instead of running them through expensive attention layers. DeepSeek's internal benchmarks claim 97% Needle-in-a-Haystack accuracy at the 1 million token scale, compared to 84.2% for standard attention mechanisms. The researchers demonstrated offloading a 100-billion-parameter embedding table to system DRAM with throughput penalties below 3%.
For developers, this means V4 should handle full-codebase reasoning — entire repositories loaded into context — without the degradation that plagues other long-context models at scale.
2. Manifold-Constrained Hyper-Connections (mHC)
While details remain sparse, mHC appears to be DeepSeek's answer to the routing inefficiency problem in Mixture-of-Experts architectures. In traditional MoE, expert selection can be noisy — tokens get routed to suboptimal experts, wasting compute. mHC constrains expert routing along learned manifolds, ensuring more consistent expert utilization and reducing the "dead expert" problem that has plagued scaled MoE models.
3. DeepSeek Sparse Attention
The 1 million token context window would be impractical with standard quadratic attention. DeepSeek Sparse Attention works in tandem with Engram to eliminate quadratic scaling on long-context tasks. Internal reports describe a tiered KV cache system delivering 40% memory reduction and 1.8x inference speedup compared to V3's attention mechanism.
Benchmark Claims: Impressive but Unverified
We want to be transparent: all V4 benchmark numbers currently available come from DeepSeek's internal testing and pre-release leaks. No independent evaluation exists yet. Here is what has been claimed.
| Benchmark | DeepSeek V4 (Claimed) | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| HumanEval | 90% | -- | -- | -- |
| SWE-bench Verified | 80-85% | 80.9% | ~80% | 80.6% |
| Needle-in-Haystack (1M) | 97% | -- | -- | -- |
| Context Window | 1M tokens | 1M tokens | 128K | 2M tokens |
| Multimodal | Native (text+image+video) | Text + Vision | Text + Vision + Audio | Native multimodal |
If the 80-85% SWE-bench Verified score holds under independent evaluation, V4 would match or exceed Claude Opus 4.6's current record of 80.9% — a remarkable achievement for an open-weight model priced at a fraction of the cost.
The 90% HumanEval claim is particularly aggressive. We will reserve judgment until third-party evaluations confirm these numbers.
The Huawei Ascend Challenge
One of the most consequential aspects of DeepSeek V4 is its planned optimization for Huawei Ascend 910B and 910C chips. This represents a deliberate move away from NVIDIA hardware — partly driven by U.S. export controls and partly by Chinese government pressure to build domestic AI infrastructure.
However, this transition has not been smooth. According to multiple reports, DeepSeek's large-scale training on Ascend chips encountered frequent failures: inter-chip communication latency, memory consistency errors, and training interruptions that caused completed progress to be repeatedly lost. For the DeepSeek-R2 reasoning model, DeepSeek ultimately reverted to NVIDIA hardware for training while relegating Huawei chips to inference tasks only.
Whether V4's training successfully ran on Ascend hardware — or whether DeepSeek faced similar issues — remains an open question that will significantly impact the model's narrative as a "fully Chinese" AI breakthrough.
Running V4 Locally: Hardware Requirements
One advantage of open weights under Apache 2.0 is local deployment. Based on pre-release specifications, here are the projected hardware requirements for running DeepSeek V4 locally.
| Quantization | Minimum Hardware | VRAM Required |
|---|---|---|
| INT8 | 2x NVIDIA RTX 4090 | ~48GB |
| INT4 | 1x NVIDIA RTX 5090 | ~32GB |
| FP16 (Full) | Multi-node cluster (8x A100/H100) | ~2TB+ |
The INT4 quantized variant running on a single RTX 5090 is particularly significant — it puts a trillion-parameter model within reach of individual developers and small teams, something that was unthinkable even 12 months ago.
Where V4 Fits in the April 2026 Landscape
We are in the most competitive period the AI industry has ever seen. In the first quarter of 2026 alone, we witnessed GPT-5.4 "Thinking" from OpenAI, Claude Opus 4.6 with 1M context from Anthropic, Gemini 3.1 from Google DeepMind, and Grok 4 from xAI. Each excels in different areas.
Claude Opus 4.6 leads in multi-file reasoning and intent understanding. GPT-5.4 dominates reasoning controls and computer use. Gemini 3.1 Pro topped 13 of 16 major benchmarks. DeepSeek V4's differentiator is clear: open weights, radical cost efficiency, and a 1M-token context that costs pennies to use.

For enterprises bound by data sovereignty requirements, V4's open weights under Apache 2.0 mean full self-hosting with no vendor lock-in. For startups operating on thin margins, V4's projected 50x cost advantage over Opus could be the difference between profitability and burn.
V4 Lite: The Preview That Appeared and Vanished
On March 9, 2026, a model labeled "V4 Lite" briefly appeared on DeepSeek's platform before being pulled. Based on limited testing during its availability, V4 Lite appeared to be a ~200B parameter variant — likely a distilled or pruned version of the full V4 architecture.
This suggests DeepSeek may follow a tiered release strategy: Lite first for broad accessibility, followed by the full 1T model for enterprise and research use. A similar approach worked for Meta with Llama 3's multiple size variants.
What We Are Watching
Based on our tracking of the DeepSeek V4 development cycle, here are the key questions that will determine whether this becomes the next true "DeepSeek moment."
- Independent benchmarks: Will third-party evaluations confirm the 80-85% SWE-bench and 90% HumanEval claims? DeepSeek's internal numbers have historically been close to reality, but the gap between internal and independent scores has widened across the industry.
- Ascend training verification: Was V4 actually trained end-to-end on Huawei Ascend chips, or did DeepSeek revert to NVIDIA hardware as they did with R2? This matters for the geopolitical narrative and for Huawei's AI chip credibility.
- Multimodal quality: Native multimodal pre-training is architecturally distinct from bolting on vision modules. If V4's image and video understanding genuinely matches dedicated multimodal models, it changes the open-source multimodal landscape overnight.
- Engram in practice: The 97% Needle-in-a-Haystack claim at 1M tokens is extraordinary. Real-world coding tasks — debugging across large codebases, multi-file refactoring — will be the true test.
- Community adoption speed: V3 was integrated into major frameworks within days of release. V4's 1T parameter count raises the bar for local deployment, but quantized variants could accelerate adoption.
Release Timeline: Our Best Estimate
Based on the Whale Lab report, the V4 Lite preview on March 9, and DeepSeek co-founders Liang Wenfeng and Yao Shunyu reportedly submitting related papers in April (per 36Kr), we expect the following timeline:
- Early-to-mid April 2026: V4 Lite public release (200B parameters, text-focused)
- Mid-to-late April 2026: Full V4 model weights on Hugging Face (Apache 2.0)
- Late April 2026: V4 API availability on DeepSeek's platform with official pricing
- May 2026: Multimodal capabilities (image + video) rolled out incrementally
These are projections based on public signals, not confirmed dates. DeepSeek has missed every previously reported window, so patience is warranted.
Frequently Asked Questions
When is DeepSeek V4 releasing?
DeepSeek V4 is expected to launch in April 2026, according to Chinese tech outlet Whale Lab. Multiple earlier release windows (February and March 2026) passed without an official launch. A "V4 Lite" variant briefly appeared on March 9, 2026, suggesting a phased rollout strategy.
How many parameters does DeepSeek V4 have?
DeepSeek V4 has approximately 1 trillion total parameters using a Mixture-of-Experts architecture, with roughly 32-37 billion parameters active per token. This is a 50% increase over V3's 671 billion total parameters, though active parameters per token remain comparable.
Is DeepSeek V4 open source?
Yes. DeepSeek has confirmed that V4 weights will be released under the Apache 2.0 license, one of the most permissive open-source licenses available. This allows commercial use, modification, and redistribution without restrictions.
How much will DeepSeek V4 API cost?
Projected pricing is approximately $0.30 per million input tokens and $0.50 per million output tokens, with cache-hit pricing around $0.03 per million tokens. This would make V4 roughly 50x cheaper than Claude Opus 4.6 and 27x cheaper than GPT-5.4 for input tokens.
Can I run DeepSeek V4 locally?
Yes, with appropriate hardware. Pre-release specifications suggest INT8 quantized V4 requires 2x RTX 4090 (48GB VRAM), while INT4 quantized fits on a single RTX 5090 (32GB VRAM). Full FP16 inference requires a multi-node cluster with 2TB+ VRAM.
What is Engram memory in DeepSeek V4?
Engram is a conditional memory system published by DeepSeek on January 13, 2026. It stores static knowledge in system DRAM using hash-based lookup tables, enabling O(1) retrieval time instead of expensive GPU attention computation. It claims 97% accuracy on Needle-in-a-Haystack tests at 1 million token scale.
How does DeepSeek V4 compare to GPT-5.4 and Claude Opus 4.6?
DeepSeek V4 claims 80-85% SWE-bench Verified (comparable to Opus 4.6's 80.9%), 90% HumanEval, and a 1M-token context window. Its key differentiators are open weights (Apache 2.0), dramatically lower pricing (~50x cheaper than Opus), and native multimodal generation. However, all V4 benchmarks remain unverified by independent evaluators.
Is DeepSeek V4 multimodal?
Yes. DeepSeek V4 features native multimodal generation across text, image, and video, integrated during pre-training rather than added as bolt-on modules. This architectural approach differs from models that add vision through adapter layers after training.
Frequently Asked Questions
Is DeepSeek V4 better than Claude Opus 4.6?
DeepSeek V4 is projected to match Claude Opus 4.6 on SWE-bench Verified (80–85% vs 80.9%) at roughly 50x lower cost — $0.30 per million tokens input vs $15 per million tokens for Claude Opus 4.6. Claude leads in multi-file reasoning and intent understanding, but V4's Apache 2.0 open weights and $0.03 per million tokens cache-hit pricing make it dramatically more affordable for long-context and high-volume workloads. Independent benchmarks have not yet confirmed V4's claimed scores.
Is DeepSeek V4 better than GPT-5.4?
GPT-5.4 dominates in reasoning controls and computer use workflows, whereas DeepSeek V4 bets on open weights and cost efficiency. V4's projected $0.30 per million tokens input pricing is approximately 27x cheaper than GPT-5.4 for equivalent input volume. For enterprises requiring local deployment or full data sovereignty, V4's Apache 2.0 license provides a structural advantage that GPT-5.4's closed architecture fundamentally cannot match.
How does DeepSeek V4 compare to Gemini 3.1 Pro?
Gemini 3.1 Pro topped 13 of 16 major benchmarks and offers a 2M-token context window — double V4's 1M-token ceiling. However, Gemini 3.1 Pro is fully closed-source. DeepSeek V4's Apache 2.0 license enables local deployment on hardware as accessible as a single RTX 5090 in INT4 quantization (~32GB VRAM). Both models support native multimodal generation, but V4's open weights give enterprises full control over deployment and costs.
Who should use DeepSeek V4?
DeepSeek V4 is best suited for: enterprises with data sovereignty requirements that cannot send data to closed APIs like GPT-5.4 or Claude Opus 4.6; developers and small teams needing trillion-parameter capability at $0.30 per million tokens instead of $15 per million tokens; and teams running full-codebase reasoning or long-document pipelines where the 1M-token context at $0.03 per million tokens cache pricing makes costs tractable. The INT4 variant also opens V4 to self-hosted infrastructure on a single RTX 5090.
What are DeepSeek V4's limitations?
DeepSeek V4 has four key limitations as of April 2026: (1) All benchmark claims — 90% HumanEval, 80–85% SWE-bench Verified, 97% Needle-in-a-Haystack — are unverified, sourced only from internal DeepSeek testing with no independent evaluation yet. (2) Training on Huawei Ascend 910B/910C chips has been plagued by inter-chip communication failures and memory consistency errors. (3) Multiple earlier release windows (February, March 2026) passed without an official launch. (4) Full FP16 deployment requires a multi-node cluster with ~2TB+ VRAM, inaccessible to most teams.
Does DeepSeek V4 integrate with Huawei Ascend chips?
DeepSeek V4 targets Huawei Ascend 910B and 910C chips for both training and inference, partly driven by U.S. export controls restricting NVIDIA hardware access. However, the transition has encountered significant failures: inter-chip communication latency, memory consistency errors, and repeated training interruptions causing completed progress to be lost. For DeepSeek-R2, the team ultimately reverted to NVIDIA hardware for training while using Ascend only for inference. Whether V4 training successfully completed on Ascend remains unconfirmed.
What hardware do I need to run DeepSeek V4 locally?
Based on pre-release specifications, running DeepSeek V4 locally under its Apache 2.0 license requires: INT4 quantization on 1x NVIDIA RTX 5090 (~32GB VRAM), INT8 quantization on 2x NVIDIA RTX 4090 (~48GB VRAM), or FP16 full precision on a multi-node cluster of 8x A100/H100 with ~2TB+ VRAM. The INT4 variant on a single RTX 5090 is the most accessible path for individual developers — putting a trillion-parameter model within reach of teams that a year ago could not have considered it.
What is Engram memory in DeepSeek V4 and how is it different from standard attention?
Engram, published January 13, 2026, is DeepSeek's conditional memory architecture that decouples static knowledge retrieval from dynamic neural reasoning. It uses a hash-based lookup table stored in system DRAM rather than GPU VRAM, allowing static patterns — facts, common code, standard definitions — to be retrieved in O(1) constant time instead of passing through expensive attention layers. DeepSeek claims 97% Needle-in-a-Haystack accuracy at 1 million tokens (vs 84.2% for standard attention) and demonstrated offloading a 100B-parameter embedding table to DRAM with under 3% throughput penalty.



