ChatGPT vs Claude: Complete AI Assistant Comparison 2026


GPT-5.4 vs Opus 4.6 across coding, writing, reasoning, multimodal. Same price, different strengths. One dominates code, the other wins everywhere else.

Feature Comparison
| Feature | ChatGPT | Claude |
|---|---|---|
| Best Model | GPT-5.4 (March 5, 2026) | Claude Opus 4.6 (February 2026) |
| Context Window | 1.05M tokens (922K input + 128K output) | 1M tokens (GA since March 13, 2026) |
| Max Output | 128K tokens | 128K tokens |
| API Price (Input) | $2.50/MTok | $5.00/MTok |
| API Price (Output) | $15.00/MTok | $25.00/MTok |
| Subscription | $20/mo (Plus), $200/mo (Pro) | $20/mo (Pro), $100/mo (Max 5x), $200/mo (Max 20x) |
| SWE-Bench Verified | 80.0% | 80.8% |
| SWE-Bench Pro | 57.7% | ~45-46% |
| ARC-AGI-2 | ~35% | 68.8% |
| Terminal-Bench 2.0 | N/A | 65.4% (#1 all models) |
| OSWorld GUI | 75.0% (beats human baseline) | 72.7% |
| Image Generation | Yes (DALL-E, native) | No |
| Agent Teams | No | Yes (parallel sub-agents) |
| Context Compaction | No | Yes (infinite conversations) |
| Chatbot Arena | #2 | #1 globally |
Pricing Comparison
ChatGPT
Claude
Detailed Comparison
ChatGPT vs Claude in 2026: The Definitive Comparison
We have been using both ChatGPT and Claude daily for months now, and the March 2026 landscape is fundamentally different from even six months ago. OpenAI's GPT-5.4 (released March 5, 2026) and Anthropic's Claude Opus 4.6 (released February 2026) represent the two most capable AI models ever built, and for the first time, they are genuinely close competitors across almost every dimension.
This is not a surface-level comparison. We have tested both models across thousands of real-world tasks — from complex multi-file code refactors to long-form content creation, from 500-page document analysis to agentic workflows that run autonomously for hours. We have spent hundreds of dollars on API calls benchmarking both models side by side. What follows is the most thorough, honest, and data-driven comparison you will find anywhere.
The short version: GPT-5.4 wins on price, multimodal breadth, and a specific class of hard novel engineering problems. Claude Opus 4.6 wins on standard coding benchmarks, abstract reasoning, agent architecture, writing quality, and user satisfaction. Neither model is strictly better. Your use case genuinely determines which one you should pick.
The Models: GPT-5.4 vs Claude Opus 4.6
GPT-5.4 launched on March 5, 2026 as OpenAI's most capable model. It is a generalist powerhouse — the first production model with native computer-use capabilities (through Operator), a 1.05M token context window (922K input + 128K output, though the standard configuration defaults to 272K without explicit configuration), native DALL-E image generation, Sora video generation, Advanced Voice mode, and a novel Tool Search system that according to OpenAI reduces token usage by up to 47% in tool-heavy workflows. GPT-5.4 also powers the Codex coding agent and the Deep Research feature for multi-step information synthesis.
Claude Opus 4.6 arrived in February 2026 and represents Anthropic's most capable model to date. Its 1M token context window became generally available on March 13, 2026 — this is not a beta or limited preview, it is full GA across the Anthropic API, AWS Bedrock, and Google Vertex AI. Opus 4.6 features 128K max output tokens, Agent Teams for parallel multi-agent orchestration, context compaction for effectively infinite conversations, and adaptive thinking that dynamically decides when and how deeply to reason about each query. It is available through the Anthropic API, AWS Bedrock, Google Vertex AI, and Microsoft Foundry.
In our daily usage, GPT-5.4 feels like the Swiss Army knife — it does everything competently, from generating images to controlling your computer to having voice conversations. Claude Opus 4.6 feels like the precision instrument — when you need deep reasoning, complex code, or nuanced writing, it consistently produces better results, but it does not try to be everything to everyone.
Subscription Pricing: Every Tier Compared (March 2026)
Both companies have refined their pricing tiers significantly. Here is the complete breakdown as of March 2026:
| Tier | ChatGPT (OpenAI) | Claude (Anthropic) |
|---|---|---|
| Free | $0 — Access to older models, limited usage | $0 — Sonnet 4.6, basic usage limits |
| Entry | $8 per month (Go) — Ad-supported, unlimited access to faster models | N/A — No equivalent tier |
| Standard | $20 per month (Plus) — GPT-5.4 access, Sora video, DALL-E, Advanced Voice | $20 per month (Pro) — 5x Free capacity, priority access, Claude Code CLI |
| Power | $200 per month (Pro) — Unlimited GPT-5.4 Pro model, o1 pro mode | $100 per month (Max 5x) — 25x Free capacity, priority during peak |
| Ultra | N/A | $200 per month (Max 20x) — 100x Free capacity, maximum throughput |
| Team | $25-30/user/mo | $25 per user/mo (Team), min 5 users |
| Enterprise | Custom pricing | Custom pricing |
Our take on subscription pricing: Both converge at $20 per month for the standard paid tier, and both deliver excellent value at that price point. OpenAI's $8 per month Go plan is the cheapest way to get a premium AI assistant, though it comes with ads. Claude's Max tiers at $100 and $200 per month offer more granular scaling for power users who need high throughput without switching to the API. OpenAI's Pro at $200 per month gives you their absolute best model (GPT-5.4 Pro), while Claude's Max 20x at the same price gives you massive throughput of their standard Opus model.
If you are on a budget, OpenAI's Go plan at $8 per month is hard to beat. If you are a developer who needs heavy usage, Claude's $100 per month Max 5x tier is a sweet spot that OpenAI does not match — they jump straight from $20 to $200.
API Pricing: Cost Per Million Tokens
For developers and businesses building on these APIs, pricing per token is critical. Here is the complete breakdown with accurate March 2026 numbers:
| Model | Input (per MTok) | Output (per MTok) | Notes |
|---|---|---|---|
| GPT-5.4 | $2.50 | $15.00 | Standard pricing; doubles above 272K input |
| Claude Opus 4.6 | $5.00 | $25.00 | Standard; $10/$37.50 above 200K input |
| Claude Opus 4.6 Fast | $30.00 | $150.00 | 2.5x faster processing |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Best cost/quality ratio |
| Claude Haiku 4.6 | $0.25 | $1.25 | High-volume, low-cost tasks |
API cost analysis: GPT-5.4 is approximately 50% cheaper than Claude Opus 4.6 on input tokens ($2.50 vs $5.00) and 40% cheaper on output tokens ($15.00 vs $25.00). This is a significant difference at scale. If you are processing millions of tokens daily, the cost savings with GPT-5.4 add up fast. However, the pricing story is more nuanced than it appears — both models charge premium rates for long-context usage (GPT doubles above 272K, Claude increases above 200K), and Claude's Sonnet model at $3/$15 per MTok offers quality that rivals GPT-5.4 at a comparable price point. For high-volume, low-complexity tasks, Claude Haiku at $0.25/$1.25 is the cheapest frontier option available from either company.
Benchmark Showdown: Head-to-Head Performance
We have compiled every major benchmark score from anthropic.com and openai.com official publications. These numbers matter because they represent standardized, reproducible evaluations that eliminate subjective bias.
| Benchmark | GPT-5.4 | Claude Opus 4.6 | Winner |
|---|---|---|---|
| SWE-Bench Verified | 80.0% | 80.8% | Claude (+0.8%) |
| SWE-Bench Pro | 57.7% | ~45-46% | GPT (+12%) |
| ARC-AGI-2 (abstract reasoning) | ~35% | 68.8% | Claude (nearly 2x) |
| Terminal-Bench 2.0 | N/A | 65.4% (#1 all models) | Claude (#1) |
| OSWorld GUI | 75.0% | 72.7% | GPT (+2.3%) |
| MRCR v2 (1M, 8-needle) | N/A | 76% | Claude |
| BrowseComp | 82.7% | N/A | GPT |
| GDPval | 83.0% | N/A | GPT |
| Chatbot Arena | #2 | #1 globally | Claude |
What the benchmarks actually tell us: The SWE-Bench Verified scores are remarkably close — 80.8% vs 80.0% — making standard coding essentially a tie with a slight Claude edge. The real divergence appears in two places. First, SWE-Bench Pro, which tests harder novel engineering problems: GPT-5.4 leads significantly at 57.7% vs approximately 45-46% for Claude. Second, ARC-AGI-2, which tests abstract pattern recognition and reasoning: Claude dominates at 68.8% vs roughly 35% for GPT, nearly doubling its score.
Terminal-Bench 2.0 is particularly interesting — Claude Opus 4.6 scored 65.4%, ranking #1 among all models tested, demonstrating strong terminal and command-line capabilities. GPT-5.4 was not evaluated on this benchmark at the time of writing.
OSWorld, which tests GUI-based computer use, favors GPT-5.4 at 75.0% (notably surpassing the human baseline of 72.4%) vs Claude's 72.7%. This aligns with our experience — OpenAI's native Operator integration for computer use feels more polished than Claude's computer use API.
The Chatbot Arena ranking, which aggregates millions of user preference votes, places Claude Opus 4.6 at #1 globally and GPT-5.4 at #2. This is the most democratic benchmark available, and it suggests that when users directly compare outputs, Claude wins more often.

Context Window and Long-Document Processing
Both models now support approximately 1 million tokens of context, but the implementations differ in important ways:
| Feature | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|
| Total Context Window | 1.05M tokens (922K input + 128K output) | 1M tokens (GA since March 13, 2026) |
| Default Context | 272K without explicit config | 1M (full by default) |
| Max Output | 128K tokens | 128K tokens |
| Long-Context Pricing | 2x above 272K input | $10/$37.50 above 200K input |
| Context Compaction | Not available | Yes — automatic server-side summarization |
| MRCR v2 (1M, 8-needle) | Not reported | 76% accuracy |
In our testing, both models handle long documents well, but Claude's context compaction feature is a genuine differentiator. It enables effectively infinite conversations by automatically summarizing earlier parts of the conversation when approaching the context limit. This means you can have multi-hour coding sessions without ever hitting a wall. GPT-5.4 simply truncates or errors when you exceed the context window.
Claude's MRCR v2 score of 76% on an 8-needle retrieval task at 1M tokens demonstrates strong accuracy even at maximum context length. In our practical testing, Claude reliably retrieves specific details from documents placed at various positions within a 500K+ token context, though accuracy naturally degrades somewhat compared to shorter contexts.
Both models now offer 128K max output tokens, which is a massive improvement over previous generations. This means either model can generate complete, lengthy documents, full code files, or detailed analyses in a single response without truncation.
Coding: The Most Important Comparison for Developers
We are a team that writes code every day using both models, so this section comes from deep practical experience, not just benchmark numbers.
Claude Opus 4.6 for Coding
Claude Opus 4.6 is, in our experience, the best coding model available for everyday software engineering work. Here is why:
- SWE-Bench Verified: 80.8% — the highest score on the standard coding benchmark, though only marginally ahead of GPT-5.4's 80.0%
- Agent Teams can split large engineering tasks across multiple sub-agents working in parallel. This is not theoretical — a multi-agent Claude Code setup famously built a working C compiler from scratch, producing over 100,000 lines of code that boots Linux on three CPU architectures. In our own usage, Agent Teams have handled complex refactoring tasks across 50+ files simultaneously
- 128K output tokens means Claude can generate complete implementation files without truncation, which eliminates the frustrating "let me continue..." pattern that plagued earlier models
- Context compaction lets coding agents work across multi-hour sessions without losing earlier context. We routinely have 3-4 hour Claude Code sessions that would be impossible without this feature
- Claude Code CLI provides a terminal-native coding experience that many senior engineers prefer over graphical interfaces. It integrates directly into existing terminal workflows
- Adaptive thinking (which replaces the older budget_tokens parameter) dynamically decides how deeply to reason about each part of a coding task, allocating more computation to harder problems automatically
- Terminal-Bench 2.0: 65.4% (#1) — the highest score among all models on terminal operations, validating its strength in command-line environments
GPT-5.4 for Coding
GPT-5.4 is also an excellent coding model, and it wins in specific important areas:
- SWE-Bench Pro: 57.7% — GPT-5.4 significantly outperforms Claude (~45-46%) on harder novel engineering problems. If you are working on cutting-edge, unusual technical challenges, GPT-5.4 may produce better solutions
- Native computer use (Operator) means GPT-5.4 can operate IDEs, browsers, and development tools directly. In our testing, this feels more polished than Claude's computer use capabilities
- OSWorld: 75.0% — surpasses the human baseline (72.4%) on GUI-based tasks, making it the better choice for automated testing and UI interaction
- Tool Search reduces token costs in tool-heavy coding workflows by up to 47%, which matters when you are making thousands of API calls per day
- Codex coding agent provides an asynchronous coding experience where you can submit tasks and come back to completed pull requests
- Deep Research can investigate technical topics across the web, synthesizing findings from multiple sources — useful when you need to understand unfamiliar APIs or frameworks before coding
Coding Verdict
For everyday software engineering — refactoring, debugging, implementing features, writing tests, code review — Claude Opus 4.6 has a slight but consistent edge. Its Agent Teams and context compaction create a qualitatively different experience for large projects. For novel, hard engineering challenges and for workflows that involve operating graphical tools, GPT-5.4 is the stronger choice. Honestly, the best setup is to have access to both.
Writing, Creative Work, and Communication
Claude has historically been praised for producing more natural, nuanced prose, and in our testing this advantage persists with Opus 4.6. Claude's writing is less likely to use formulaic structures, less prone to corporate-speak, and more willing to take a genuine perspective when asked. It ranks #1 globally on Chatbot Arena, which heavily weights conversational and writing quality.
GPT-5.4 produces competent writing that is well-structured and reliable, but in our side-by-side comparisons, it tends toward more generic phrasing and predictable paragraph structures. It is excellent for business documents, emails, and structured content where consistency matters more than voice.
For content creation specifically, both models now support 128K max output tokens, meaning either can produce complete long-form articles, documentation, and reports in a single generation. This is a meaningful practical advantage over previous model generations where truncation was a constant issue.
Multimodal Capabilities
This is where GPT-5.4 has a commanding lead, and we want to be upfront about that:
| Capability | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|
| Image Generation | Yes (DALL-E, native) | No |
| Image Understanding | Yes | Yes |
| Video Generation | Yes (Sora) | No |
| Advanced Voice Mode | Yes | No |
| Computer Use (GUI) | Yes (native Operator) | Yes (via API) |
| PDF Analysis | Yes | Yes |
| File Upload | Yes | Yes |
| Web Browsing | Yes (native) | Yes (via tools) |
GPT-5.4 handles text, images (both generation and analysis), voice, video, code, spreadsheets, and computer use — all natively within one interface. Claude focuses on text, code, image understanding, and document analysis. It cannot generate images, video, or voice output. If your workflow requires multimedia creation, ChatGPT is the only viable choice between the two.
That said, Claude's computer use capabilities, while less polished than GPT-5.4's native Operator, are functional and improving. And Anthropic's MCP (Model Context Protocol) provides an open standard for tool integration that has been adopted by a growing ecosystem of third-party developers.
Unique Features That Set Each Apart
Claude-Exclusive Features
Agent Teams (parallel sub-agents): Claude can spawn multiple sub-agents that work on different parts of a problem simultaneously. This is not just a nice feature — it fundamentally changes what is possible. A single Claude agent can delegate a frontend task, a backend task, and a test-writing task to three separate sub-agents, then synthesize their results. No other production model offers this.
Adaptive Thinking: Rather than using a fixed reasoning budget, Opus 4.6 dynamically decides how much reasoning each query needs. Simple questions get fast answers; complex problems get deep analysis. This replaced the older budget_tokens parameter and results in both faster responses for easy queries and better results for hard ones.
Context Compaction: Enables effectively infinite conversations by automatically summarizing earlier context when approaching the token limit. This is transformative for long coding sessions and iterative creative work.
Multi-Cloud Availability: Opus 4.6 is available on the Anthropic API, AWS Bedrock, Google Vertex AI, and Microsoft Foundry — giving enterprises maximum deployment flexibility.
GPT-Exclusive Features
DALL-E Image Generation and Sora Video: Native image and video creation within the conversation. The quality is production-ready and the integration is seamless.
Advanced Voice Mode: Real-time voice conversations with natural intonation and emotion. This is a killer feature for accessibility, hands-free work, and language learning.
Tool Search (47% token reduction): Automatically identifies which tools are relevant to a query, reducing the token overhead of tool descriptions by nearly half. This is a significant cost optimization for API users with many tool definitions.
Deep Research: Multi-step web research that synthesizes information from dozens of sources into comprehensive reports. We have found this genuinely useful for market research and technical deep dives.
GPT Store and Plugin Ecosystem: The largest marketplace of custom AI applications, with deep integrations into Microsoft 365, Google Workspace, and hundreds of third-party tools.
Enterprise Considerations
ChatGPT Enterprise benefits from OpenAI's massive distribution network — over 900 million weekly users — and deep Microsoft integration. If your organization is built on Microsoft 365, the Copilot integration powered by OpenAI models provides native AI capabilities across Word, Excel, PowerPoint, Outlook, and Teams. The GPT Store gives enterprises access to thousands of pre-built AI applications.
Claude Enterprise has carved out a strong position in compliance-sensitive and safety-conscious industries. Anthropic's Constitutional AI approach provides verifiable safety guarantees that matter in regulated sectors like finance, healthcare, and government. Claude's Agent Teams enable complex multi-step workflows that go beyond simple Q&A. Notably, Microsoft's Copilot Cowork product (announced March 9, 2026) uses Anthropic's Claude — not OpenAI — for its multi-step agentic capabilities. When Microsoft, OpenAI's biggest investor, chooses Claude for agentic work, that is a significant validation of Claude's enterprise positioning.
For API availability, both models are accessible through major cloud platforms. GPT-5.4 is available via the OpenAI API and Azure OpenAI. Claude Opus 4.6 is available via the Anthropic API, AWS Bedrock, Google Vertex AI, and Microsoft Foundry — giving it broader multi-cloud coverage.
Platform Availability Summary
| Platform | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|
| Native API | OpenAI API | Anthropic API |
| Microsoft Azure | Azure OpenAI | Microsoft Foundry |
| AWS | Not available | AWS Bedrock |
| Google Cloud | Not available | Google Vertex AI |
| Web Interface | chat.openai.com | claude.ai |
| Mobile Apps | iOS, Android | iOS, Android |
| CLI Tool | Codex CLI | Claude Code |
When to Choose ChatGPT (GPT-5.4)
- Multimodal needs: You need image generation (DALL-E), voice mode, or video creation (Sora) — Claude simply cannot do these
- Budget API usage: GPT-5.4's API at $2.50/$15 per MTok is approximately 50% cheaper on input and 40% cheaper on output than Opus 4.6 at $5/$25
- Novel engineering challenges: Your coding problems are unique and complex — GPT-5.4 leads SWE-Bench Pro at 57.7% vs Claude's ~45-46%
- Microsoft ecosystem: Your organization runs on Microsoft 365 and you want native Copilot integration
- Computer use at scale: You need polished GUI automation — GPT-5.4's OSWorld score of 75.0% surpasses the human baseline
- General-purpose assistant: You want one tool that does everything reasonably well — text, images, voice, video, code, browsing, computer use
- Budget-conscious personal use: The $8 per month Go plan offers the cheapest entry to a premium AI assistant
When to Choose Claude (Opus 4.6)
- Software engineering: Your primary use case is writing, reviewing, and refactoring code — Claude leads SWE-Bench Verified (80.8%) and Terminal-Bench 2.0 (65.4%, #1)
- Multi-agent workflows: You need Agent Teams to tackle complex projects with parallel sub-agents — no other model offers this
- Abstract reasoning: Your work requires pattern recognition and novel reasoning — Claude's ARC-AGI-2 score of 68.8% nearly doubles GPT's ~35%
- Long document analysis: You need accurate retrieval across million-token contexts with 76% accuracy on 8-needle retrieval
- Long coding sessions: Context compaction enables multi-hour sessions without hitting context limits
- Writing quality: You want the most natural, nuanced prose — Claude is #1 on Chatbot Arena user satisfaction
- Multi-cloud deployment: You need availability across AWS Bedrock, Google Vertex, Azure/Foundry, and the native API
- Regulated industries: Compliance and Constitutional AI safety guarantees are non-negotiable requirements
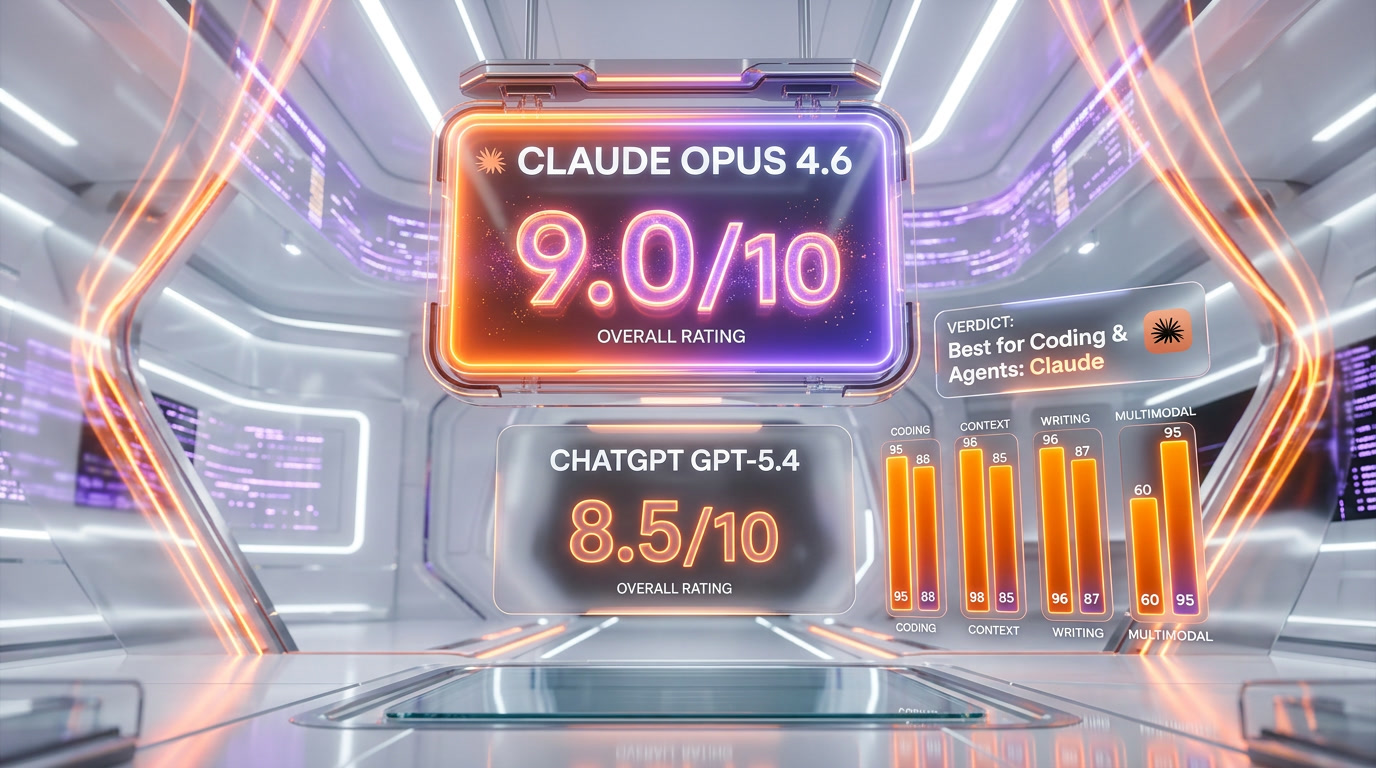
Our Bottom Line
After months of daily use with both models, here is our honest recommendation: if you are a developer or technical user, Claude Opus 4.6 is the better default. Its Agent Teams, context compaction, adaptive thinking, and leading benchmark scores on SWE-Bench Verified, ARC-AGI-2, and Terminal-Bench make it the superior tool for serious engineering work. If you need a do-everything assistant that handles images, voice, video, and computer use alongside good coding and writing capabilities — and you want to pay less for API access — GPT-5.4 is the better choice.
The honest truth is that in March 2026, having access to both is ideal. We use Claude for our coding workflows, long document analysis, and writing. We use ChatGPT for image generation, voice interactions, quick research, and tasks that benefit from its broader plugin ecosystem. The two models complement each other more than they compete.
Both models will continue to improve rapidly. At the pace we have seen — with major releases every few months — the landscape could shift again by mid-2026. We will update this comparison as new versions and benchmarks emerge.
Sources
- Anthropic — Official Claude model documentation and benchmark publications
- OpenAI — Official GPT-5.4 release notes, pricing, and benchmark data
Frequently Asked Questions
Is GPT-5.4 better than Claude Opus 4.6?
Neither is universally better. GPT-5.4 wins on breadth — multimodal capabilities (images, voice, video), cheaper API pricing ($2.50/$15 vs $5/$25 per MTok), native computer use, and harder novel engineering problems (SWE-Bench Pro: 57.7% vs ~45-46%). Claude Opus 4.6 wins on depth — standard coding benchmarks (SWE-Bench Verified: 80.8% vs 80.0%), abstract reasoning (ARC-AGI-2: 68.8% vs ~35%), agent orchestration (Agent Teams), long-context accuracy (76% MRCR v2), and user satisfaction (#1 Chatbot Arena). Your use case determines the winner.
Which is cheaper — ChatGPT or Claude?
Both cost $20 per month for their standard subscription (Plus vs Pro). OpenAI offers a cheaper $8 per month Go tier with ads. For API usage, GPT-5.4 at $2.50/$15 per MTok is approximately half the cost of Claude Opus 4.6 at $5/$25 per MTok. Claude's Haiku model at $0.25/$1.25 is the cheapest frontier-class option from either company for high-volume tasks.
Which is better for coding in 2026?
Claude Opus 4.6 leads on SWE-Bench Verified (80.8% vs 80.0%) and Terminal-Bench 2.0 (65.4%, #1 all models). GPT-5.4 leads on SWE-Bench Pro (57.7% vs ~45-46%) for harder novel problems and OSWorld (75.0% vs 72.7%) for GUI automation. For most everyday coding tasks, Claude has a slight edge. For novel engineering challenges and DevOps, GPT-5.4 can be stronger.
Can Claude generate images or video?
No. Claude can analyze and understand images but cannot generate them. It has no video or voice generation capabilities. ChatGPT has built-in image generation via DALL-E, video generation via Sora, and Advanced Voice mode. If multimedia generation is important to your workflow, ChatGPT is the clear choice.
What is the context window for each model?
GPT-5.4 supports 1.05M tokens total (922K input + 128K output), though the default is 272K without explicit configuration. Claude Opus 4.6 supports 1M tokens, which became generally available on March 13, 2026. Both models support 128K max output tokens. Claude additionally offers context compaction for effectively infinite conversations.
Our Verdict
GPT-5.4 is the broader platform: 50% cheaper API ($2.50/$15 vs $5/$25 per MTok), native multimodal (DALL-E images, Sora video, Advanced Voice), polished computer use (OSWorld: 75.0%), and stronger performance on novel engineering problems (SWE-Bench Pro: 57.7% vs ~46%). Claude Opus 4.6 is the deeper specialist: #1 on standard coding (SWE-Bench Verified: 80.8%), #1 on abstract reasoning (ARC-AGI-2: 68.8% vs ~35%), #1 on terminal operations (Terminal-Bench 2.0: 65.4%), #1 on user satisfaction (Chatbot Arena), plus unique capabilities like Agent Teams, context compaction, and adaptive thinking. Choose ChatGPT if you need a do-everything assistant at lower cost. Choose Claude if coding depth, agent orchestration, reasoning, and writing quality are your priorities.
Frequently Asked Questions
Is ChatGPT better than Claude?
GPT-5.4 is the broader platform: 50% cheaper API ($2.50/$15 vs $5/$25 per MTok), native multimodal (DALL-E images, Sora video, Advanced Voice), polished computer use (OSWorld: 75.0%), and stronger performance on novel engineering problems (SWE-Bench Pro: 57.7% vs ~46%). Claude Opus 4.6 is the deeper specialist: #1 on standard coding (SWE-Bench Verified: 80.8%), #1 on abstract reasoning (ARC-AGI-2: 68.8% vs ~35%), #1 on terminal operations (Terminal-Bench 2.0: 65.4%), #1 on user satisfaction (Chatbot Arena), plus unique capabilities like Agent Teams, context compaction, and adaptive thinking. Choose ChatGPT if you need a do-everything assistant at lower cost. Choose Claude if coding depth, agent orchestration, reasoning, and writing quality are your priorities.
Which is cheaper, ChatGPT or Claude?
ChatGPT starts at $20/month (free plan available). Claude starts at $20/month (free plan available). Check the pricing comparison section above for a full breakdown.
What are the main differences between ChatGPT and Claude?
The key differences span across 15 features we compared. For Best Model, ChatGPT offers GPT-5.4 (March 5, 2026) while Claude offers Claude Opus 4.6 (February 2026). For Context Window, ChatGPT offers 1.05M tokens (922K input + 128K output) while Claude offers 1M tokens (GA since March 13, 2026). For Max Output, ChatGPT offers 128K tokens while Claude offers 128K tokens. See the full feature comparison table above for all details.