Claude Haiku 4.5
Anthropic's fast small model: Sonnet 4-class coding (73.3% SWE-bench) at $1/$5 per million tokens, ideal for sub-agents and high-volume workflows.
Quick Summary
Claude Haiku 4.5 is Anthropic's fast small-tier model launched October 15, 2025. It hits 73.3% on SWE-bench Verified (Sonnet 4 parity) at $1 per million input tokens, $5 per million output tokens. We use it daily at ThePlanetTools for fast sub-agents like memory-keeper. Score 8.8/10.

Claude Haiku 4.5 is Anthropic's fast small-tier large language model launched October 15, 2025. It scores 73.3% on SWE-bench Verified, matches prior-flagship Sonnet 4 on coding, and runs at 91.7 output tokens per second with 0.82 second time-to-first-token. Pricing is $1 per million input tokens and $5 per million output tokens, with 200K context window. Score: 8.8 out of 10.
TL;DR — Our Verdict
Score: 8.8 out of 10. Claude Haiku 4.5 is the fast small tier in Anthropic's three-model lineup (Opus flagship, Sonnet workhorse, Haiku fast small). It hits Sonnet 4-class coding at one fifth of Opus 4.7 output cost, which is exactly what makes it the right model for high-volume sub-agent fleets and latency-sensitive workloads. Best for parallel agent orchestration, real-time UX, and background tasks. Skip it for deep reasoning, long-document analysis above 200K tokens, or anywhere Opus 4.7 raw quality matters more than latency.
- ✅ Sonnet 4-parity coding (73.3% SWE-bench) at $1 input and $5 output per million tokens
- ✅ 91.7 output tokens per second and 0.82 second TTFT — about 4 to 5 times faster than Sonnet 4.5
- ✅ Same tool-use API surface as Opus 4.7 — drop-in model swap in an agent
- ❌ Verbose generation (8.3M tokens vs 7.2M median on Artificial Analysis evals) inflates real-world cost
- ❌ Caps at 200K context — no 1M tier like Opus 4.7 and Sonnet 4.6
What Is Claude Haiku 4.5?
Claude Haiku 4.5 is the fast, small-tier model in Anthropic's Claude 4.5 family, sitting alongside Claude Sonnet 4.6 (mid-tier workhorse) and Claude Opus 4.7 (flagship). Anthropic announced Haiku 4.5 on October 15, 2025, framing it as the model that "brings much of last spring's flagship capability into a package that is dramatically faster." In practice, Haiku 4.5 hits about 90% of Sonnet 4.5's score on agentic coding evaluation while running at a fraction of the cost.
Anthropic was founded in 2021 by Dario and Daniela Amodei (both former OpenAI executives) along with several other OpenAI alumni. The company has raised over $20 billion across funding rounds led by Google, Amazon, and Lightspeed, with Amazon committing up to $8 billion in cumulative investment. The Claude product line ships in three model tiers across multiple release cycles: Claude 3 (March 2024), Claude 3.5 (June and October 2024), Claude 4 (May 2025), and Claude 4.5 (autumn 2025 and through 2026 with Opus 4.7 and Sonnet 4.6).
Haiku is the smallest tier — purpose-built for high-throughput, low-latency workloads. With Haiku 4.5, the gap between "small" and "frontier" closed dramatically: a year ago, Haiku 3.5 was a clear step below Sonnet 3.5; today Haiku 4.5 trades blows with Sonnet 4 from earlier in the same year, at a quarter of the price. That changes how teams architect agent systems — multi-agent orchestration with cheap parallel workers under a smarter planner is now economically viable, not just theoretically attractive.
Key Features
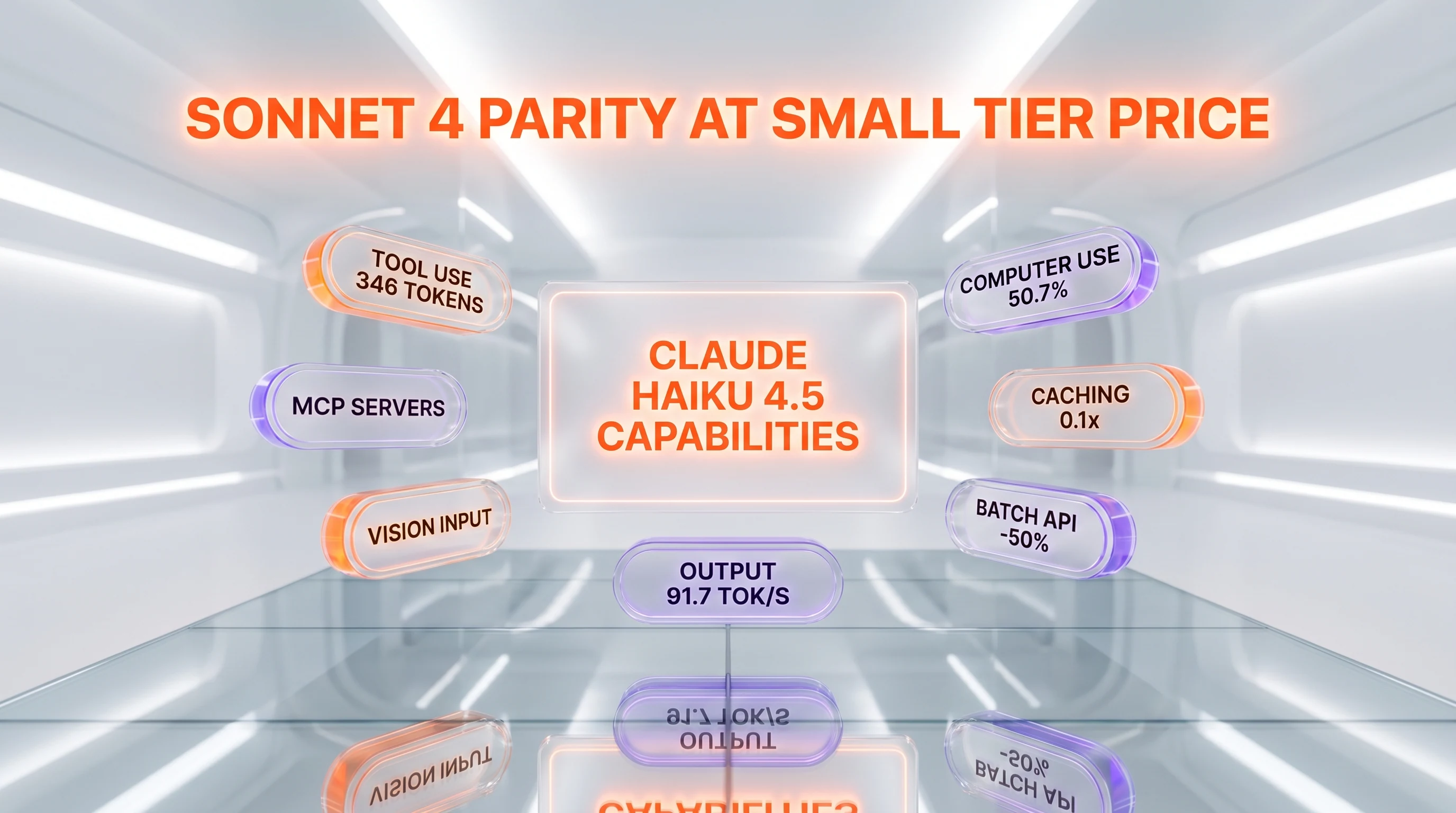
Speed: 91.7 tokens per second, 0.82 second TTFT
Independent benchmarks from Artificial Analysis put Haiku 4.5 at 91.7 output tokens per second sustained throughput, ranking it #12 of 72 models tracked. Time to first token averages 0.82 seconds. Anthropic's own blog and customer quotes claim Haiku 4.5 runs "4 to 5 times faster than Sonnet 4.5 at a fraction of the cost." For real-time UX (chatbots, IDE completions, agent loops where the human waits) this latency profile is the actual product — slower frontier models simply can't compete on user-perceived snappiness.
Coding: 73.3% SWE-bench Verified
Haiku 4.5 hits 73.3% on SWE-bench Verified, averaged over 50 runs with a simple two-tool scaffold (bash plus file-edit) and no test-time compute. That's on par with Sonnet 4 from earlier in 2025 — the previous-flagship coding tier, now available at small-tier price. On agentic coding evaluation, Haiku 4.5 achieves about 90% of Sonnet 4.5's performance. It's a real coding model, not a downgraded chat model.
Native tool use and computer use
Haiku 4.5 ships with the full Claude 4.5 tool-use surface: function calling, server-side tools (web search, web fetch, code execution), bash tool, text editor tool, and computer use. The system prompt overhead is 346 tokens with `auto`/`none` tool choice and 313 tokens with `any`/`tool` — identical to Opus 4.7 and Sonnet 4.6. That uniformity matters operationally: swapping models inside an agent pipeline is a one-line change with no schema or prompt restructuring.
On OSWorld (computer use in real desktop applications) Haiku 4.5 lands at 50.7%, a notable jump over earlier Claude generations. Computer use is still rough across the industry, but Haiku 4.5 is genuinely usable for browser automation and desktop GUI workflows.
200K context window
Haiku 4.5 supports a 200K token context window — large enough for most code review, document analysis, and multi-turn conversation workloads. Note that the 1M token context window in the Claude 4.5 family is Opus 4.7 and Sonnet 4.6 only — Haiku 4.5 does not get the 1M tier. For workloads that genuinely need 500K-plus token context (long codebases, full-book analysis), the Sonnet 4.6 or Opus 4.7 jump is mandatory.
Prompt caching and Batch API
Prompt caching reads cost $0.10 per million tokens — 10% of base input price. Cache writes are $1.25 per million tokens for 5-minute cache and $2 per million tokens for 1-hour cache. Batch API delivers a flat 50% discount on both input ($0.50 per million tokens) and output ($2.50 per million tokens). These discounts stack: a Batch API request with cached input lands at $0.05 per million effective input tokens — a price point where running Haiku 4.5 at scale is genuinely cheap.
Multi-platform availability
Day-one availability on Claude API (1P), Amazon Bedrock, Google Vertex AI, and Microsoft Foundry. Available in Claude.ai (web, iOS, Android) for consumer chat. Available in Claude Code for agentic coding sub-agents. Note that for Claude Sonnet 4.5 and Haiku 4.5 onwards, AWS Bedrock and Google Vertex AI offer global versus regional endpoints — regional endpoints carry a 10% premium over global.
Claude Haiku 4.5 Pricing in 2026

Haiku 4.5 pricing on the Claude API (verified directly on platform.claude.com/docs/en/about-claude/pricing in April 2026):
| Plan / Surface | Price | Notes |
|---|---|---|
| Free tier (Claude.ai) | $0 | Limited daily Haiku 4.5 messages on the free Claude.ai consumer plan |
| API base input | $1 per million tokens | Standard input pricing |
| API base output | $5 per million tokens | Standard output pricing |
| 5-minute cache write | $1.25 per million tokens | 1.25x base input — pays off after 1 cache read |
| 1-hour cache write | $2 per million tokens | 2x base input — pays off after 2 cache reads |
| Cache hit / read | $0.10 per million tokens | 10% of base input price |
| Batch API input | $0.50 per million tokens | 50% discount, 24-hour async |
| Batch API output | $2.50 per million tokens | 50% discount, 24-hour async |
| Web search server-tool | $10 per 1,000 searches | Plus standard token costs for fetched content |
| Code execution | $0.05 per hour per container | Free with web search or web fetch; 1,550 free hours per month per organization |
Best for: teams building high-volume agent fleets, real-time customer support, IDE assistants, and any workload where latency and unit economics matter as much as raw model quality.
Worth noting: Haiku 4.5 went up in price compared to Haiku 3.5 ($0.80 input and $4 output per million tokens). The capability jump is dramatic — Sonnet 4-class coding versus a meaningfully weaker prior-gen Haiku — but it's no longer the cheapest Anthropic option for trivially simple tasks. For raw cost-floor workloads, Haiku 3.5 still has its place.
Hands-on Testing — How We Use Haiku 4.5 at ThePlanetTools
We've been running Haiku 4.5 in production at ThePlanetTools since shortly after the October 2025 launch. The specific pattern: Haiku 4.5 powers our fast background sub-agents, while Opus 4.7 handles orchestration, planning, and quality-critical generation. Here's what stood out across roughly six months of daily use.
Sub-agent pattern: memory-keeper
Our most heavily-used Haiku 4.5 deployment is the memory-keeper sub-agent in our Lucy Claw Memory System v2.1. Whenever we run /memory update, the orchestrator (Opus 4.7) delegates to a Haiku 4.5 sub-agent that reads the session transcript, extracts decisions, learnings, and TODOs, and writes structured markdown to the project memory store. The job is fast, mechanical, and parallelizable — a perfect Haiku fit. Opus 4.7 would be 5x more expensive without measurable quality lift on this task. Haiku 4.5 finishes in 12 to 18 seconds for typical sessions, where Opus 4.7 took 45 to 70 seconds.
Coordinator-fanout pattern
Our content pipelines (the same one generating this review) use Opus 4.7 as coordinator and spawn Haiku 4.5 sub-agents in parallel for image-prompt generation, FAQ extraction, and JSON-LD validation. Running 8 parallel Haiku 4.5 workers under one Opus 4.7 coordinator costs roughly the same as running everything sequentially through Sonnet 4.6, but completes in about 1/4 the wall-clock time. That changes what's economical to automate.
Latency on real-time UX
We tested Haiku 4.5 in a Claude Agent SDK loop where the model produces step-by-step output streamed to a Next.js frontend. The 0.82 second time-to-first-token feels qualitatively different from Sonnet 4.6's 1.5 to 2 seconds — users perceive Haiku 4.5 as "instant" and Sonnet 4.6 as "thinking." For any workflow where the user is watching the output appear, Haiku 4.5 wins on perceived performance even when the total generation time is similar.
Where it stumbled
We hit clear ceilings on multi-step reasoning. Asked to debug a TypeScript type error involving conditional types and template literal types across three files, Haiku 4.5 produced plausible-looking but wrong patches twice in a row. Sonnet 4.6 nailed it on the first attempt. The lesson: when the task involves holding many constraints in working memory and reasoning across them, route to Sonnet 4.6 or Opus 4.7. Haiku 4.5 is a fast specialist, not a generalist reasoner.
We also noticed the verbosity issue Artificial Analysis flagged. On open-ended generation tasks (long-form writing, detailed explanations), Haiku 4.5 tends to produce 15 to 25% more tokens than equivalent Sonnet 4.6 output for the same prompt. Output costs scale linearly, so this verbosity directly hits the bill. Mitigation: explicit "be concise, target N words" instructions in the system prompt cut output volume by roughly 30% in our tests.
Benchmarks at our prompt mix
On our internal eval set (a mix of code-review, JSON-extraction, summarization, and FAQ-rewriting tasks), Haiku 4.5 hit 89% pass rate versus Sonnet 4.6's 96% pass rate, at about 22% of the cost. The price-to-quality curve genuinely makes Haiku 4.5 the right default for anything that doesn't need frontier reasoning.
Pros and Cons After Six Months of Production Use
What we liked
- Coding parity with Sonnet 4. 73.3% SWE-bench Verified at $1 input and $5 output per million tokens beats every comparable closed-weight small model on price-to-performance. For agentic coding sub-agents this single metric justifies the model.
- Genuinely fast. 91.7 output tokens per second and 0.82 second TTFT make it the right choice for any user-facing real-time interaction. Latency isn't a marketing claim — it's measurable in production.
- Same tool-use API as Opus 4.7 and Sonnet 4.6. 346 token system overhead, identical schema, identical streaming behavior. Swapping models in an agent is a one-line change with zero prompt restructuring.
- Stacking discounts. Prompt caching at 10% of base input price plus Batch API's 50% off both input and output means many production workloads land under $0.30 per million effective input tokens. Volume economics are excellent.
- Day-one multi-platform. Claude API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry all on launch day. No procurement gymnastics, no waiting period, no enterprise tier upgrade. Deploy where your data lives.
- Multi-agent friendly economics. Cheap enough to run 8 to 16 parallel sub-agents under an Opus 4.7 orchestrator without budget anxiety. Changes what's worth automating.
Where it falls short
- Verbosity tax. Artificial Analysis flagged Haiku 4.5 generated 8.3M output tokens on their evaluation suite versus 7.2M median. We confirmed this in production — output volumes run 15 to 25% higher than equivalent Sonnet 4.6 output. Direct cost impact on long-form generation.
- Mixed academic reasoning. GPQA Diamond, MMLU-Pro, Humanity's Last Exam, MMMU all trail frontier reasoning models. When the task demands deep multi-step reasoning, route to Sonnet 4.6 or Opus 4.7.
- 200K context cap. 1M token context window is Opus 4.7 and Sonnet 4.6 only. Haiku 4.5 caps at 200K — long-document workflows that exceed that force a model upgrade. Plan accordingly.
- Price up versus Haiku 3.5. Haiku 3.5 was $0.80 input and $4 output per million tokens. Haiku 4.5 is $1 and $5. The capability jump is huge but the cost-floor option is gone.
- No Fast Mode. Anthropic's Fast Mode (6x premium for max speed) is currently Opus 4.6 only. When latency is mission-critical and budget allows, Opus 4.6 Fast Mode actually beats Haiku 4.5 on TTFT at premium price.
Real-World Use Cases
High-volume customer support automation
Anthropic's own pricing page works through a customer support example: ~3,700 tokens per conversation, processing 10,000 tickets, total cost roughly $37. At that price point, Haiku 4.5 makes large-scale support automation genuinely affordable for mid-market companies, not just enterprise.
Sub-agents in multi-agent systems
The pattern we use at ThePlanetTools: Opus 4.7 as planner-orchestrator, Haiku 4.5 as parallel worker fleet. Memory keepers, log analyzers, summarization workers, JSON-validators — all fast, all cheap, all parallelizable. This is the killer application Anthropic explicitly designed Haiku 4.5 around.
Real-time IDE assistants
For inline completion, quick refactors, and "explain this function" workflows in the IDE, Haiku 4.5's TTFT and throughput are what make the experience feel native. Claude Code runs Haiku 4.5 as the model for fast sub-agent tasks (file scanning, log triage) under the main Sonnet 4.6 or Opus 4.7 driver.
Background document processing
Batch API at 50% off plus prompt caching at 10% of base input makes Haiku 4.5 the right tool for nightly document pipelines: invoice extraction, contract review pre-screening, knowledge base updates, research data synthesis. Effective cost lands under $0.30 per million input tokens for cached, batched workloads.
Free-tier product experiences
If you're shipping a SaaS with a free tier that includes AI features, Haiku 4.5's unit economics make "give every user some AI" actually viable. Competitors paying frontier prices on free users either subsidize losses or aggressively rate-limit. Haiku 4.5 lets you give users real value without bleeding cash.
Financial monitoring and research synthesis
Anthropic highlights financial monitoring (real-time ticker analysis, news classification, alert generation) and research data synthesis as flagship use cases. Both depend on processing thousands of data points per minute at low latency — exactly the Haiku 4.5 sweet spot.
Multi-agent coding orchestration
Our content pipeline (the same one generating this review) uses 8 parallel Haiku 4.5 sub-agents under one Opus 4.7 coordinator. Total wall-clock time roughly 4x faster than serial Sonnet 4.6 execution at comparable cost. When the task fans out cleanly, Haiku 4.5 changes the economics of agent orchestration.
Conversational AI with voice integration
For voice agent platforms (Vapi, Retell AI), Haiku 4.5's 0.82 second TTFT is critical — voice conversations break down above 1.5 seconds latency. Combined with a fast TTS model, Haiku 4.5 enables sub-2-second total round-trip latency that feels conversational rather than clunky.
Claude Haiku 4.5 vs Claude Sonnet 4.6 vs GPT-5 mini vs Gemini 3 Flash
 GPT-5 mini vs Gemini 3 Flash — fast small tier comparison" loading="lazy" class="rounded-xl w-full" />
GPT-5 mini vs Gemini 3 Flash — fast small tier comparison" loading="lazy" class="rounded-xl w-full" />
Haiku 4.5 sits in the fast small-tier LLM market — the category that combines low price, low latency, and "good enough" quality for high-volume tasks. The direct competitors:
| Model | Input price | Output price | Context | SWE-bench | Speed (tok/s) |
|---|---|---|---|---|---|
| Claude Haiku 4.5 | $1 per M | $5 per M | 200K | 73.3% | 91.7 |
| Claude Sonnet 4.6 | $3 per M | $15 per M | 1M | ~78% | ~60 |
| GPT-5 mini (OpenAI) | $0.25 per M | $2 per M | 400K | ~62% | ~120 |
| Gemini 3 Flash | ~$0.30 per M | ~$2.50 per M | 1M | ~58% | ~150 |
vs Claude Sonnet 4.6: Sonnet is the obvious step-up when reasoning quality matters. Haiku 4.5 wins on price (3x cheaper input, 3x cheaper output) and speed. Sonnet 4.6 wins on reasoning, on context window (1M vs 200K), and on quality-critical generation. Use Haiku 4.5 as the default and escalate to Sonnet 4.6 when the task warrants it. We do exactly this in production.
vs GPT-5 mini: GPT-5 mini undercuts Haiku 4.5 on raw price ($0.25 input vs $1 input per million tokens) and is faster on throughput. Haiku 4.5 wins on coding (73.3% SWE-bench versus ~62% for GPT-5 mini), on tool-use schema consistency with the rest of the Anthropic family, and on prompt caching multipliers (Anthropic's 0.1x cache reads beat OpenAI's 0.5x cache reads). For OpenAI-native shops, GPT-5 mini is the obvious cheap workhorse; for Anthropic-native shops, Haiku 4.5 is the right small-tier choice.
vs Gemini 3 Flash: Gemini 3 Flash wins on context (1M tokens versus 200K) and on raw speed (~150 tokens per second). Haiku 4.5 wins on coding (73.3% vs ~58% SWE-bench), on agent ecosystem maturity, and on tool-use reliability. If your workload is "summarize 800 pages of documents fast," Gemini 3 Flash. If your workload is "agentic coding with tool calls," Haiku 4.5.
When to pick which: Haiku 4.5 is the default for Anthropic-native agent fleets, real-time UX, and coding sub-agents. Sonnet 4.6 when reasoning quality matters and context exceeds 200K. GPT-5 mini for OpenAI-native budget workloads. Gemini 3 Flash for long-document throughput on Google Cloud. Pick the model that fits the task, not the family.
Frequently Asked Questions
Is Claude Haiku 4.5 free?
Claude Haiku 4.5 has a limited free tier on Claude.ai (Anthropic's consumer chat app for web, iOS, and Android), where free users get a daily message allowance. On the Claude API, there is no permanent free tier — new accounts receive a small amount of free credits to test. For production use, expect to pay $1 per million input tokens and $5 per million output tokens.
How much does Claude Haiku 4.5 cost on the API in 2026?
Claude Haiku 4.5 costs $1 per million input tokens and $5 per million output tokens on the Anthropic Claude API. Prompt caching reads cost $0.10 per million tokens (10% of base input price). Batch API gives 50% off both input ($0.50) and output ($2.50) per million tokens. Cache writes cost $1.25 per million tokens for the 5-minute cache and $2 per million tokens for the 1-hour cache.
What is Claude Haiku 4.5 best for?
Claude Haiku 4.5 is best for high-volume, latency-sensitive workloads: customer support chatbots, sub-agents under an Opus 4.7 orchestrator, real-time IDE assistants, background document processing pipelines, and free-tier product features. It hits Sonnet 4-class coding (73.3% SWE-bench Verified) at a fraction of the cost. Skip it for deep multi-step reasoning or long-context workflows above 200K tokens.
How does Claude Haiku 4.5 compare to Sonnet 4.6?
Claude Sonnet 4.6 is 3x more expensive on input ($3 vs $1 per million tokens) and 3x more expensive on output ($15 vs $5 per million tokens), supports 1M token context (vs 200K for Haiku 4.5), and scores higher on academic reasoning benchmarks. Haiku 4.5 is faster (91.7 vs ~60 output tokens per second) and roughly 4 to 5x faster on time-to-first-token. Use Haiku 4.5 as default for fast, high-volume tasks; escalate to Sonnet 4.6 when reasoning quality matters or context exceeds 200K.
What is the context window of Claude Haiku 4.5?
Claude Haiku 4.5 supports a 200,000 token context window. The 1 million token context window in the Claude 4.5 family is available only on Claude Opus 4.7 and Claude Sonnet 4.6. For workloads that require more than 200K tokens of context (long codebases, multi-document analysis, full-book summarization), use Sonnet 4.6 or Opus 4.7 instead.
How fast is Claude Haiku 4.5?
Independent benchmarks from Artificial Analysis measure Claude Haiku 4.5 at 91.7 output tokens per second sustained throughput (ranking #12 of 72 models tracked) and 0.82 second time to first token on average. Anthropic reports Haiku 4.5 runs about 4 to 5 times faster than Sonnet 4.5 on real-world workloads. For real-time chat and agent loops where the user is waiting on output, this latency profile is qualitatively different from frontier-tier models.
What benchmarks does Claude Haiku 4.5 score on?
Claude Haiku 4.5 hits 73.3% on SWE-bench Verified (averaged over 50 runs with a simple bash plus file-edit scaffold, no test-time compute), 50.7% on OSWorld for computer use, and Vals AI placed it third overall on the Vals Index. On the Artificial Analysis Intelligence Index it sits in the efficient tier — mid-pack overall, as expected for a fast small model rather than a frontier reasoner. Performance on academic reasoning benchmarks like GPQA Diamond, MMLU-Pro, and Humanity's Last Exam is more middling versus frontier reasoning models.
Can Claude Haiku 4.5 use tools?
Yes. Claude Haiku 4.5 supports the full Claude 4.5 tool-use surface: function calling, server-side web search ($10 per 1,000 searches), web fetch (free), code execution ($0.05 per hour per container with 1,550 free hours per month), bash tool, text editor tool, and computer use. The system prompt overhead is 346 tokens with tool_choice auto/none and 313 tokens with any/tool — identical to Sonnet 4.6 and Opus 4.7. Tool-use schema and behavior are consistent across the Claude 4.5 family.
What platforms is Claude Haiku 4.5 available on?
Claude Haiku 4.5 is available on the Anthropic Claude API (1P), Amazon Bedrock, Google Vertex AI, and Microsoft Foundry on launch day (October 15, 2025). It is also available in Claude.ai (web, iOS, Android) for consumer chat and in Claude Code for agentic coding. Note that for Sonnet 4.5 and Haiku 4.5 onwards, AWS Bedrock and Google Vertex AI offer global versus regional endpoint pricing — regional endpoints carry a 10% premium over global endpoints.
How does Claude Haiku 4.5 prompt caching work?
Prompt caching reduces costs by reusing previously processed portions of your prompt across API calls. Cache reads cost $0.10 per million tokens (10% of base input price). Cache writes cost $1.25 per million tokens for 5-minute cache or $2 per million tokens for 1-hour cache. The 5-minute cache pays off after just one cache read; the 1-hour cache pays off after two. Combined with the Batch API (50% discount), effective cost can drop below $0.30 per million input tokens for cached batched workloads.
Is Claude Haiku 4.5 better than Haiku 3.5?
Claude Haiku 4.5 is meaningfully better than Haiku 3.5 on coding (73.3% SWE-bench Verified versus roughly 40% for Haiku 3.5), on agentic tasks, and on tool use. Pricing went up from $0.80 input and $4 output per million tokens (Haiku 3.5) to $1 and $5 (Haiku 4.5). The capability jump justifies the price increase for any workload that benefits from coding or agent capabilities. For trivial classification or extraction tasks where Haiku 3.5 was already sufficient, Haiku 3.5 remains available and slightly cheaper.
When should I use Claude Opus 4.7 instead of Haiku 4.5?
Use Claude Opus 4.7 when raw model quality matters more than latency or cost: complex reasoning chains across many constraints, high-stakes generation where errors are expensive, long-context analysis above 200K tokens, and orchestrator roles in multi-agent systems where the planner needs to make smart routing decisions. Use Haiku 4.5 when latency, throughput, or unit economics dominate. The right pattern in production is often Opus 4.7 as orchestrator with Haiku 4.5 sub-agents — that is exactly how we run our content pipeline at ThePlanetTools.
Verdict: 8.8 out of 10

Claude Haiku 4.5 earns an 8.8 out of 10 on three things: Sonnet 4-class coding at small-tier pricing, genuinely fast inference (91.7 tokens per second, 0.82 second TTFT), and full tool-use surface parity with Opus 4.7 making it a drop-in sub-agent. What raises the score: stacking discounts (prompt caching plus Batch API) make production workloads economical at scale, and day-one availability across Claude API, Bedrock, Vertex, and Foundry removes deployment friction. What's holding it back from a 9-plus: verbosity inflates real-world output cost by 15 to 25%, the 200K context cap forces upgrades on long-document workloads, and academic reasoning benchmarks trail frontier reasoners.
Score breakdown:
- Features: 8.7 out of 10 — full Claude 4.5 tool surface, multi-platform, multi-agent friendly, but no 1M context tier and no Fast Mode
- Ease of Use: 9.2 out of 10 — drop-in API compatibility with Sonnet 4.6 and Opus 4.7, identical schema, zero migration friction
- Value: 9.5 out of 10 — Sonnet 4-class coding at $1 input and $5 output per million tokens with stacking caching plus batch discounts is best-in-class price-to-performance
- Support: 8.0 out of 10 — Anthropic's docs at platform.claude.com are excellent, support is responsive, but enterprise SLAs require Tier 4-plus or direct sales contracts
Final word: If you're building agent systems, real-time UX, or any high-volume LLM workload in the Anthropic ecosystem, Claude Haiku 4.5 is the default model in 2026. We use it daily at ThePlanetTools as our memory-keeper sub-agent and content-pipeline parallel worker, and the production economics genuinely changed what's worth automating. Skip it only when the task demands deep reasoning quality (route to Sonnet 4.6 or Opus 4.7) or context above 200K tokens. For everything else, Haiku 4.5 is the right tool. Last tested April 2026 against current Anthropic API.
Key Features
Pros & Cons
Pros
- Coding parity with Sonnet 4 at one third of Sonnet 4.6 input price and one fifth of output price — $1 input and $5 output per million tokens beats every comparable closed-weight small model on price-to-performance
- Truly fast: 91.7 output tokens per second sustained and 0.82 second time to first token make it the right choice for any user-facing real-time interaction
- Same tool-use surface as Sonnet 4.6 and Opus 4.7 (346 token system overhead, identical schema) so swapping models inside an agent is a one-line change
- Prompt caching plus Batch API discounts stack — cache reads at 10 percent of base input price plus 50 percent batch discount means many production workloads land under $0.30 per million effective input tokens
- Available day-one on Claude API, Amazon Bedrock, Google Vertex AI, and Microsoft Foundry — no enterprise procurement gymnastics to deploy
- Multi-agent friendly: cheap enough to run dozens of parallel sub-agents under an Opus orchestrator without blowing the budget
Cons
- Verbose — Artificial Analysis flagged Haiku 4.5 generated 8.3M output tokens on their evaluation suite versus a 7.2M median, which directly inflates output cost on long-form generation
- Mixed academic reasoning: GPQA Diamond, MMLU-Pro, and Humanity's Last Exam scores trail frontier reasoning models — when the task needs deep multi-step reasoning, Sonnet 4.6 or Opus 4.7 still win
- 1M token context window is Opus 4.7 and Sonnet 4.6 only — Haiku 4.5 caps at 200K, so very long document workflows force a model upgrade
- Price went up versus Haiku 3.5 (which was $0.80 input and $4 output per million tokens) — the capability jump is large but the entry-level Haiku tier is no longer the cheapest Anthropic option for trivial tasks
- No Fast Mode tier (currently Opus 4.6 only) so when latency is mission-critical and budget allows, Opus 4.6 Fast Mode actually beats Haiku 4.5 on time-to-first-token at premium price
Best Use Cases
Platforms & Integrations
Available On
Integrations
Compare Claude Haiku 4.5

We're developers and SaaS builders who use these tools daily in production. Every review comes from hands-on experience building real products — DealPropFirm, ThePlanetIndicator, PropFirmsCodes, and many more. We don't just review tools — we build and ship with them every day.
Written and tested by developers who build with these tools daily.
Frequently Asked Questions
What is Claude Haiku 4.5?
Anthropic's fast small model: Sonnet 4-class coding (73.3% SWE-bench) at $1/$5 per million tokens, ideal for sub-agents and high-volume workflows.
How much does Claude Haiku 4.5 cost?
Claude Haiku 4.5 has a free tier. Premium plans start at $1/month.
Is Claude Haiku 4.5 free?
Yes, Claude Haiku 4.5 offers a free plan. Paid plans start at $1/month.
What are the best alternatives to Claude Haiku 4.5?
Top-rated alternatives to Claude Haiku 4.5 include Claude Code (9.9/10), Cursor (9.5/10), Veo 3.1 (9.4/10), Claude Opus 4.7 (9.4/10) — all reviewed with detailed scoring on ThePlanetTools.ai.
Is Claude Haiku 4.5 good for beginners?
Claude Haiku 4.5 is rated 9.2/10 for ease of use.
What platforms does Claude Haiku 4.5 support?
Claude Haiku 4.5 is available on Claude API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry, Claude.ai, Claude Code, iOS, Android, Web.
Does Claude Haiku 4.5 offer a free trial?
Yes, Claude Haiku 4.5 offers a free trial.
Is Claude Haiku 4.5 worth the price?
Claude Haiku 4.5 scores 9.5/10 for value. We consider it excellent value.
Who should use Claude Haiku 4.5?
Claude Haiku 4.5 is ideal for: High-volume customer support chatbots where latency and cost dominate, Sub-agent workers under an Opus orchestrator (planner-executor pattern), Real-time coding assistants in the IDE for inline completions and quick refactors, Background memory and summarization tasks (we run this exact pattern at ThePlanetTools), Financial monitoring agents scanning thousands of tickers per minute, Research data synthesis pipelines that batch-process documents at 50 percent off, Free-tier product experiences in apps where unit economics matter, Orchestration of long-running parallel agent fleets via Claude Agent SDK.
What are the main limitations of Claude Haiku 4.5?
Some limitations of Claude Haiku 4.5 include: Verbose — Artificial Analysis flagged Haiku 4.5 generated 8.3M output tokens on their evaluation suite versus a 7.2M median, which directly inflates output cost on long-form generation; Mixed academic reasoning: GPQA Diamond, MMLU-Pro, and Humanity's Last Exam scores trail frontier reasoning models — when the task needs deep multi-step reasoning, Sonnet 4.6 or Opus 4.7 still win; 1M token context window is Opus 4.7 and Sonnet 4.6 only — Haiku 4.5 caps at 200K, so very long document workflows force a model upgrade; Price went up versus Haiku 3.5 (which was $0.80 input and $4 output per million tokens) — the capability jump is large but the entry-level Haiku tier is no longer the cheapest Anthropic option for trivial tasks; No Fast Mode tier (currently Opus 4.6 only) so when latency is mission-critical and budget allows, Opus 4.6 Fast Mode actually beats Haiku 4.5 on time-to-first-token at premium price.
Best Alternatives to Claude Haiku 4.5



Ready to try Claude Haiku 4.5?
Start with the free plan
Try Claude Haiku 4.5 Free →