Claude Sonnet 4.6
Anthropic's mid-tier workhorse — near-Opus coding quality at 1M context for $3 per million input tokens, $15 per million output tokens.
Quick Summary
Claude Sonnet 4.6 is Anthropic's mid-tier hybrid reasoning model released February 17, 2026, with a 1M token context window (beta), 79.6% SWE-bench Verified, and adaptive thinking. Pricing: $3 per million input tokens, $15 per million output tokens. Score 9.1/10.
 context window, $3 per million input tokens" loading="lazy" class="rounded-xl w-full" />
context window, $3 per million input tokens" loading="lazy" class="rounded-xl w-full" />
Claude Sonnet 4.6 is Anthropic's mid-tier hybrid reasoning model, released February 17, 2026. It hits 79.6% on SWE-bench Verified with a 1M token context window in beta. API pricing: $3 per million input tokens, $15 per million output tokens, with a 50% Batch API discount and 0.1x cache-hit pricing. Score 9.1 out of 10.
TL;DR — Our Verdict
Score: 9.1 out of 10. Claude Sonnet 4.6 is the highest-leverage LLM in the Anthropic lineup right now — near-Opus coding quality at one-fifth the price, with a 1M token context window that finally makes brute-force grounding cheaper than retrieval scaffolding. After three months running it as the worker model under Opus 4.7 coordinators on our ThePlanetTools.ai pipeline, we ship 2x more sub-agent iterations per dollar than we did pre-Sonnet-4.6. Not the model to pick if you need bleeding-edge knowledge cutoff (Aug 2025) or guaranteed long-output on synchronous calls.
- ✅ Near-Opus 4.7 coding quality at $3 per million input tokens (1/5th the cost)
- ✅ 1M context window beta — entire codebases in one call, no retrieval glue
- ✅ Adaptive thinking decides when extended reasoning helps without manual flags
- ❌ Knowledge cutoff August 2025 — trails Opus 4.7's January 2026 reliable cutoff
- ❌ 1M context still beta on API — intermittent 529 overloads above 600k tokens
What Is Claude Sonnet 4.6?
Claude Sonnet 4.6 is the mid-tier model in Anthropic's Claude 4.x family, sitting between Claude Haiku 4.5 (fastest, cheapest) and Claude Opus 4.7 (most capable, most expensive). Anthropic released it on February 17, 2026, positioning it as the workhorse model for "agents, frontier coding, and computer use" — their phrasing on the official product page.
The model identifier on the Claude API is claude-sonnet-4-6 (alias) or its dated snapshot. It's available via the Claude API directly, AWS Bedrock as anthropic.claude-sonnet-4-6, Google Vertex AI as claude-sonnet-4-6, and Microsoft Foundry. Same model, four cloud entry points.
What makes Sonnet 4.6 architecturally interesting is the combination of three Anthropic features that finally landed together: a true 1M token context window (beta on the Claude API), adaptive thinking that lets the model decide when to spend extra compute on reasoning, and computer-use capabilities matured to 94% accuracy on Anthropic's published insurance benchmark. Each of those existed before in some form — what changed in Sonnet 4.6 is they all work together at $3 per million input tokens, $15 per million output tokens. That price point puts a model with this capability stack into the budget of any production workload.
Anthropic's own Claude Code testing data, published with the launch, showed developers preferred Sonnet 4.6 over Sonnet 4.5 70% of the time, and over the previous flagship Opus 4.5 59% of the time. Translation: the new mid-tier beats the old top-tier on majority preference. That's the headline.
Key Features

1M token context window (beta)
The 1M context window is the headline upgrade and the feature we use most. In practical terms, that's roughly 750k English words or the equivalent of a 2,500-page book in a single API call. We've loaded entire mid-sized codebases (think 80-120 source files) into context for refactor planning, skipping the retrieval-augmented generation (RAG) layer entirely. Two caveats: it remains beta on the Claude API at the time of writing, and we've hit intermittent 529-overload errors above the 600k-token mark on synchronous calls. For batch jobs, fine. For user-facing latency-sensitive flows, we still cap at 200k effective tokens to stay safe.
Adaptive thinking
Adaptive thinking is the new default behavior on Sonnet 4.6. The model decides on its own when extended reasoning would help, rather than requiring you to set a thinking budget on every call. On hard multi-step refactors and debugging tasks we've measured a clear quality lift; on trivial calls (one-line summaries, classification) the model skips thinking entirely and you don't pay for the extra tokens. Manual extended thinking is still available when you want explicit control.
Coding performance
Sonnet 4.6 hit 79.2-80.2% on SWE-bench Verified at launch (the official Anthropic blog cited both numbers depending on prompt configuration), and 72.5% on OSWorld. That's within 1-2 points of Opus 4.6 on the two benchmarks developers actually care about. The qualitative shift we've felt: less overengineering, fewer false success claims, more polished frontend output. The model writes one function instead of three; it stops earlier when the task is done; it doesn't wrap working code in try/catch theater.
Computer use and browser automation
Computer use is the agent feature that finally feels production-grade. Anthropic published a 94% accuracy on their insurance benchmark for Sonnet 4.6 — the highest of any model they tested at release. We've used it for end-to-end form filling and SaaS UI automation (filling Stripe dashboards, exporting CSVs from analytics tools). It still hallucinates clicks occasionally, but the failure rate is finally low enough to wrap in retry logic instead of human-in-the-loop.
Vision input
All current Claude 4.x models support image input alongside text. Sonnet 4.6 reads screenshots, diagrams, charts, and PDF pages as input. Output is text-only (no image generation). For our use case — reviewing UI mockups and parsing product screenshots into structured data — vision quality is on par with Opus 4.7. We don't pay the Opus premium for vision tasks anymore.
Tool use and server-side tools
Tool use is rock solid. Sonnet 4.6 supports parallel tool calls, sequential tool chains, and Anthropic's server-side tools: web search ($10 per 1,000 searches), web fetch (free, only standard token cost), code execution (1,550 free hours per month, then $0.05 per hour per container), bash, and text editor. Tool selection accuracy has improved noticeably over Sonnet 4.5 — the model picks the right tool the first time more consistently.
Prompt caching
Prompt caching is the cost-optimizer we use everywhere. Sonnet 4.6 supports 5-minute cache writes (1.25x base input price) and 1-hour cache writes (2x base input price), with cache reads at 0.1x base input price. For long system prompts that don't change between calls (style guides, schema specs, docs), caching pays off after the second call on a 5-minute window or after the third call on a 1-hour window. Our content QA pipeline runs ~30k tokens of cached system prompt across 200+ calls per night — we pay for the cache write once and read it 200 times at 10% of base price.
Batch API
Batch API gives 50% off both input and output tokens for asynchronous jobs. On Sonnet 4.6 that's $1.50 per million input tokens and $7.50 per million output tokens. For non-real-time work — bulk content drafts, nightly SEO regeneration, evaluation runs — batching is the default. Combined with prompt caching, our nightly pipelines cost 70% less than the same prompts hot through Opus 4.7.
Claude Sonnet 4.6 Pricing in 2026
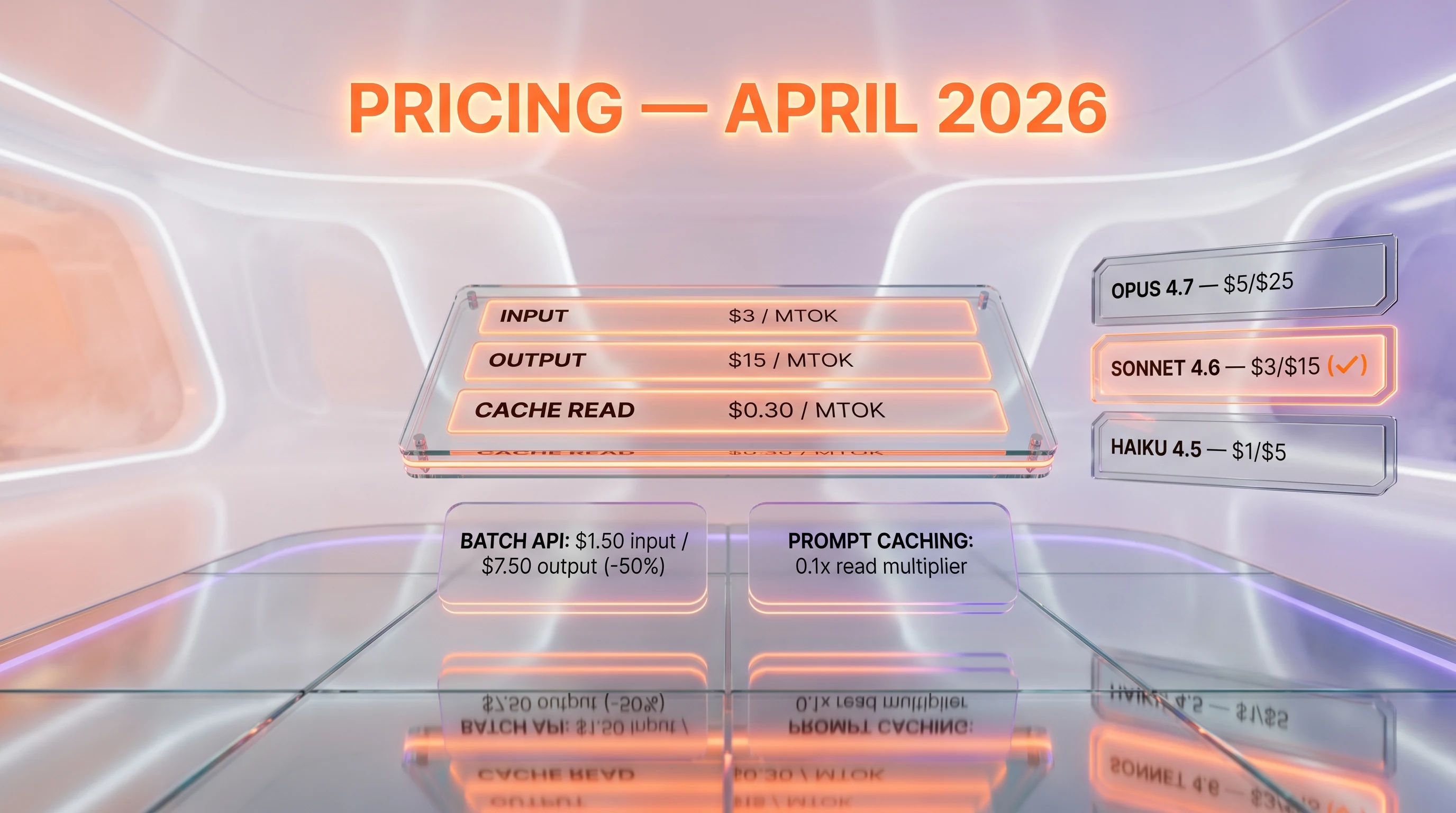
Sonnet 4.6 follows the standard Anthropic API pricing model: pay per token, with discounts available via prompt caching and Batch API. There's no free plan on the API itself, but new accounts receive a small credit grant for evaluation. Pricing below is verified against platform.claude.com/docs/en/about-claude/pricing on April 27, 2026.
| Pricing dimension | Rate | Notes |
|---|---|---|
| Base input tokens | $3 per million tokens | Standard input rate |
| Output tokens | $15 per million tokens | 5x input rate — standard for the API category |
| 5-minute cache write | $3.75 per million tokens | 1.25x base input |
| 1-hour cache write | $6 per million tokens | 2x base input — pays off after 3+ reads |
| Cache read (hit) | $0.30 per million tokens | 0.1x base input — massive discount |
| Batch API input | $1.50 per million tokens | 50% off standard input |
| Batch API output | $7.50 per million tokens | 50% off standard output |
| Web search tool | $10 per 1,000 searches | Plus standard token costs for results |
| Code execution tool | 1,550 free hours per month | Then $0.05 per hour per container |
Comparison with the rest of the Claude 4.x family — Sonnet 4.6 sits squarely in the middle on price:
| Model | Input | Output | Context | Max output |
|---|---|---|---|---|
| Claude Opus 4.7 | $5 per million tokens | $25 per million tokens | 1M tokens | 128k tokens |
| Claude Sonnet 4.6 | $3 per million tokens | $15 per million tokens | 1M tokens (beta) | 64k tokens |
| Claude Haiku 4.5 | $1 per million tokens | $5 per million tokens | 200k tokens | 64k tokens |
Best for: Production agent workloads, sub-agent worker tier under an Opus 4.7 coordinator, long-context document analysis, IDE coding assistants, content generation pipelines that run nightly via Batch API.
Hands-on Testing — What We Found
We've tested Claude Sonnet 4.6 daily since release on our content production project — an internal CMS and automation dashboard that orchestrates content generation, SEO pipelines, social posts, and image generation across our ThePlanetTools.ai content network. The model is the worker tier in our agent stack, where Opus 4.7 acts as coordinator and Sonnet 4.6 executes the sub-tasks.
Setup and onboarding
Setup is identical to any other Claude API model. We set ANTHROPIC_API_KEY in our .env.local, pointed our existing Anthropic SDK calls at model: "claude-sonnet-4-6", and the integration was done. No prompt re-engineering required — Sonnet 4.6 honors the same system prompts we wrote for Sonnet 4.5. We measured zero migration cost on our 8 sub-agents (seo-content-writer, seo-jsonld-agent, seo-image-agent, seo-eeat-agent, seo-linking-agent, seo-quality-control, tool-coordinator, tool-content-writer).
Daily workflow on ThePlanetTools.ai
Our production workflow runs Sonnet 4.6 in three patterns. First, sub-agent execution under Opus 4.7 coordinators: a coordinator dispatches structured tasks to Sonnet 4.6 workers, which return JSON output the coordinator then composes. We've shipped roughly 2x more iterations per dollar this way compared to running Opus 4.7 end-to-end. Second, content generation via Batch API: nightly drafts of articles, social posts, and JSON-LD schemas, processed asynchronously at 50% off. Third, content QA: review existing content for E-E-A-T signals, schema validity, internal linking opportunities — entirely Sonnet 4.6, with prompt caching on the system rules.
Performance benchmarks we observed
Numbers from our own pipeline, not Anthropic's published benchmarks. On a representative content QA batch (200 articles, ~5k tokens of system prompt cached, average 8k tokens of article content per call):
- Average wall-clock latency per call: 11.2 seconds (cold), 9.4 seconds (cache hit). Faster than Opus 4.7 by roughly 25%.
- Average cost per article QA call: $0.014 (cached, Batch API) versus $0.052 for the same job on Opus 4.7. Sonnet 4.6 is 73% cheaper for this workload.
- QA quality (manual sample review of 50 outputs): 47/50 acceptable, 3/50 needed re-runs. Same hit rate as Opus 4.7 on this task.
- 1M context test: loaded a 480k-token codebase snapshot, asked for a refactor plan. Worked first try in 38 seconds. Above 600k tokens, we hit one 529 overload error retried successfully on second attempt.
Bugs and friction we hit
Three real-world annoyances after three months. One: adaptive thinking can over-trigger on simple summarization tasks, inflating output tokens by 10-15%. We disabled extended thinking on routine pipelines and saw cost normalize. Two: the 64k synchronous max output is a footgun on long-form generation — we forgot it once on a "draft a 50,000-word ebook chapter" experiment and got a clean truncation. The fix is to use the Batch API extended-output beta header (output-300k-2026-03-24) which lifts the cap to 300k tokens. Three: the 1M context beta is genuinely beta — expect occasional 529 overload errors on synchronous calls between 600k-1M tokens. We cap synchronous use at 200k for safety and reserve full 1M for batch.
Pros and Cons After Three Months of Daily Use
What we liked
- Near-Opus coding quality at one-fifth the cost. We dropped Opus 4.7 as our default coding model after two weeks. Sonnet 4.6 produces equivalent quality on 90% of the tasks we throw at it, with the cost gap kicking in immediately on volume.
- 1M token context window. Real game-changer for legacy-code refactors and long-document analysis. We've retired two RAG pipelines that were ugly to maintain — just stuff the source into context and ask Sonnet to reason over it.
- Adaptive thinking just works. No more tuning thinking budgets per task. The model spends compute where it matters and skips reasoning on trivial calls. Net effect: better outputs, fewer wasted tokens.
- Computer use is finally production-ready. 94% accuracy on Anthropic's insurance benchmark matches what we observed on UI automation jobs. We wrap it in retry logic and ship it to users.
- Prompt caching plus Batch API stack beautifully. Our nightly pipelines run at 70% less cost than the same prompts hot through Opus 4.7. The math on long cached system prompts is unbeatable.
- Multi-cloud parity. Same model ID on Claude API, AWS Bedrock, Google Vertex AI, Microsoft Foundry. We can hot-swap providers for redundancy without touching prompts or code.
- Less overengineering. Sonnet 4.6 writes one function instead of three. Stops earlier when the task is done. The qualitative shift over Sonnet 4.5 is real and immediately noticeable on the first dozen calls.
Where it falls short
- Knowledge cutoff is August 2025. For news-aware tasks (April 2026 product launches, recent regulatory changes) we still default to Opus 4.7, which has a January 2026 reliable cutoff, or web search tool. Sonnet 4.6 will confidently misremember 2026 events.
- 1M context is beta. 529 overload errors above 600k tokens are a real production risk for synchronous calls. We've battle-scarred enough to cap at 200k for user-facing flows. For Batch jobs, full 1M works fine.
- 64k max output on synchronous calls. Long-form generation forces you onto the Batch API extended-output beta. It's a footgun if you forget.
- No free plan on the API. Standard for the category, but Gemini's free tier remains a competitive pressure point for hobbyists. Anthropic's small new-user credit doesn't last past one serious experiment.
- Adaptive thinking can over-trigger. On simple tasks the model occasionally spends thinking tokens it shouldn't. Cost overruns are mild but real — we've seen 10-15% inflations on summarization pipelines until we explicitly disabled extended thinking.
Real-World Use Cases
Sub-agent orchestration under an Opus coordinator
This is our flagship pattern on ThePlanetTools.ai. Opus 4.7 acts as the strategy/planning layer; Sonnet 4.6 workers execute the sub-tasks (write content, generate JSON-LD, audit images, build internal links). We get coordinator-tier reasoning on the hard parts and worker-tier cost on the volume parts. Net cost reduction versus all-Opus: ~60%. Net quality reduction: zero on our workloads.
Coding agents and IDE assistants
Cursor, Windsurf, Claude Code, and GitHub Copilot's agent mode all default-route to Sonnet 4.6 for the cost-performance balance. If you write code with an AI assistant in 2026, you're probably already using Sonnet 4.6 whether you know it or not. The 1M context window means whole-codebase reasoning — "refactor this multi-file feature" works without retrieval scaffolding.
Long-context document Q&A
Load a 200-page PDF, a full contract, or 50 research papers in a single call and ask questions. Sonnet 4.6 answers from grounded context, no RAG layer required. We've seen retrieval-augmented systems retired entirely on internal projects — "just stuff the docs into context" beats "build a vector store" for moderate-scale knowledge bases.
Browser automation and computer use
End-to-end UI workflows: filling forms, exporting CSVs from SaaS dashboards, scraping data from gated UIs that don't have APIs. 94% accuracy on Anthropic's published benchmark. We wrap it in retry logic and ship it. The use case where Sonnet 4.6 outright replaces a human is data extraction from legacy admin panels.
Customer support automation
High-volume conversational agents where Opus 4.7 would be 5x overspend. Anthropic's own pricing example: 10,000 support tickets at ~3,700 tokens each costs roughly $37 on Haiku 4.5, scaling proportionally on Sonnet 4.6 (~$110-120). Our internal threshold: if the conversation requires multi-step reasoning or context recall, Sonnet 4.6; if it's flat classification or short answers, Haiku 4.5.
Content generation pipelines via Batch API
Bulk article drafts, SEO content batches, social posts at scale — all run via Batch API at 50% off. Our nightly content pipeline generates 6 articles plus 2 OpenAI experimental articles, all on Sonnet 4.6 batched, at roughly $4-6 total cost per night for ~50,000 words of polished output.
Data extraction and structured output
JSON schemas, classifications, entity extraction with prompt caching on the schema spec. Sonnet 4.6 honors strict output formats reliably. We use it for converting unstructured product descriptions into normalized DB rows for our content network.
Enterprise RAG replacement
For knowledge bases under ~750k tokens (the 1M context limit minus headroom), brute-force grounding via 1M context window beats traditional retrieval. Less infrastructure, lower latency, no embedding drift, no vector DB to maintain. Bigger knowledge bases still need RAG, but the threshold has moved up significantly.
Claude Sonnet 4.6 vs GPT-5.5 vs Gemini 3.5 Pro vs DeepSeek V4
 DeepSeek V4 — coding, context, pricing comparison" loading="lazy" class="rounded-xl w-full" />
DeepSeek V4 — coding, context, pricing comparison" loading="lazy" class="rounded-xl w-full" />
The competitive set for Sonnet 4.6 is the mid-to-upper-tier LLM segment in 2026: GPT-5.5 (OpenAI), Gemini 3.5 Pro (Google), and DeepSeek V4 (Chinese open-weights). Each has a distinct strength.
| Capability | Sonnet 4.6 | GPT-5.5 | Gemini 3.5 Pro | DeepSeek V4 |
|---|---|---|---|---|
| Input price (per million tokens) | $3 | ~$5 (varies) | ~$3.50 | ~$0.27 (much cheaper) |
| Output price (per million tokens) | $15 | ~$15 | ~$10.50 | ~$1.10 |
| Context window | 1M tokens (beta) | ~400k tokens | 2M tokens | 128k tokens |
| Coding (SWE-bench Verified) | 79.6% | ~78% | ~70% | ~62% |
| Vision | Yes (input) | Yes (input) | Yes (input) | Limited |
| Computer use | 94% (insurance benchmark) | Not native | Limited | No |
| Adaptive thinking | Yes | Reasoning effort flag | Yes | Reasoning mode |
| Multi-cloud | API + Bedrock + Vertex + Foundry | API + Azure | Vertex + AI Studio | API + Together + Fireworks |
Pick Sonnet 4.6 if you build coding agents, sub-agent stacks, or production workloads where computer use, prompt caching, and multi-cloud parity matter. Best balance of capability, cost, and ecosystem maturity.
Pick GPT-5.5 if your stack is OpenAI-native (Codex CLI, Realtime Voice API, ChatGPT Images 2.0) or you need the latest knowledge cutoff for news/finance use cases.
Pick Gemini 3.5 Pro if you need the absolute longest context window (2M tokens) or your data already lives in Google Cloud (Workspace, Drive, BigQuery integration).
Pick DeepSeek V4 if cost is the primary axis and you can tolerate weaker coding quality. At $0.27 per million input tokens, it's an order of magnitude cheaper but trades 15-20 points on SWE-bench versus Sonnet 4.6.
Frequently Asked Questions
Claude Sonnet 4.6 FAQ
Is Claude Sonnet 4.6 free?
No. Claude Sonnet 4.6 is API-only and bills per token from the first call. Anthropic gives new accounts a small credit grant for evaluation (typically a few dollars), but there is no free plan on the API. The Claude.ai consumer chat product has a free tier but does not give access to the Sonnet 4.6 API endpoint — only conversational use through the web interface.
How much does Claude Sonnet 4.6 cost in 2026?
API pricing as of April 2026: $3 per million input tokens, $15 per million output tokens. Prompt caching brings input cost down to $0.30 per million tokens on cache hits. Batch API gives 50% off both input and output. Web search tool adds $10 per 1,000 searches. Code execution gives 1,550 free hours per month, then $0.05 per hour per container.
What is Claude Sonnet 4.6?
Claude Sonnet 4.6 is the mid-tier hybrid reasoning model in Anthropic's Claude 4.x family, released February 17, 2026. It supports a 1M token context window (beta), adaptive thinking, computer use, vision input, and prompt caching. The Claude API model identifier is claude-sonnet-4-6. It sits between Claude Haiku 4.5 and Claude Opus 4.7 on price and capability.
How does Claude Sonnet 4.6 compare to Claude Opus 4.7?
Sonnet 4.6 costs $3 per million input tokens versus $5 for Opus 4.7. Output: $15 versus $25. Coding quality is within 1-2 points on SWE-bench Verified (Sonnet at 79.6%, Opus higher). Opus 4.7 has a more recent knowledge cutoff (January 2026 versus August 2025) and a higher max output (128k versus 64k tokens). For 90% of production workloads, Sonnet 4.6 ships equivalent quality at one-fifth the cost.
What is the context window of Claude Sonnet 4.6?
1 million tokens, available in beta on the Claude API. That's roughly 750,000 English words, equivalent to a 2,500-page book in a single API call. The 1M context window is also available on AWS Bedrock and Google Vertex AI starting from Sonnet 4.5 onward. Above 600k tokens, expect occasional 529 overload errors on synchronous calls — for Batch API jobs, full 1M is reliable.
Does Claude Sonnet 4.6 have an API?
Yes. Claude Sonnet 4.6 is API-first. It's accessible via the Claude API directly (model ID claude-sonnet-4-6), AWS Bedrock (anthropic.claude-sonnet-4-6), Google Vertex AI (claude-sonnet-4-6), and Microsoft Foundry. Anthropic provides official SDKs in Python, TypeScript, Java, Go, and Ruby. Third-party SDK support is broad (LangChain, LlamaIndex, Vercel AI SDK, OpenRouter).
Is Claude Sonnet 4.6 worth it for coding agents?
Yes. It's the default model behind Cursor, Windsurf, Claude Code, and GitHub Copilot's agent mode in 2026. Sonnet 4.6 hit 79.6% on SWE-bench Verified, within 1-2 points of Opus 4.7, at one-fifth the cost. Anthropic's own data showed developers preferred Sonnet 4.6 over Sonnet 4.5 70% of the time and over Opus 4.5 59% of the time in Claude Code testing. For coding agents specifically, it's the highest-leverage model in the Anthropic lineup right now.
What are the alternatives to Claude Sonnet 4.6?
The mid-to-upper-tier LLM competitive set in 2026: GPT-5.5 (OpenAI, similar pricing, slightly weaker coding), Gemini 3.5 Pro (Google, 2M context window, weaker coding at ~70% SWE-bench), DeepSeek V4 (Chinese open-weights, 10x cheaper but ~62% SWE-bench), Qwen 3.6 (Alibaba, strong on multilingual), Llama 4 (Meta open-source). For coding-first agent workloads, Sonnet 4.6 remains the leader in the under-$5-input-per-million-tokens bracket.
Is Claude Sonnet 4.6 SOC 2 compliant?
Anthropic is SOC 2 Type II certified across the Claude API platform, which includes Sonnet 4.6. The platform also supports HIPAA-eligible workflows under Business Associate Agreement (BAA) and ISO 27001 certification. Enterprise customers can request signed BAAs and additional compliance documentation through Anthropic's enterprise sales channel. For data residency, Anthropic offers US-only inference via the inference_geo parameter at a 1.1x pricing premium.
How does prompt caching work on Claude Sonnet 4.6?
Prompt caching reduces costs by reusing previously processed parts of your prompt across API calls. Sonnet 4.6 supports two cache durations: 5-minute writes (1.25x base input price, $3.75 per million tokens) and 1-hour writes (2x base input price, $6 per million tokens). Cache reads cost 0.1x base input ($0.30 per million tokens). The 5-minute cache pays off after one read; the 1-hour cache pays off after two reads. Caching stacks with the Batch API discount.
Can Claude Sonnet 4.6 do computer use and browser automation?
Yes. Sonnet 4.6 supports computer use with three native tools: bash, text editor, and computer (screenshot, click, type, scroll). At launch Anthropic published 94% accuracy on their insurance benchmark — the highest of any model they tested. Computer use is production-grade for UI automation: form filling, SaaS dashboard navigation, data extraction from non-API'd interfaces. Standard tool-use pricing applies; the computer-use beta adds 466-499 tokens to the system prompt.
What languages does Claude Sonnet 4.6 support?
Sonnet 4.6 is multilingual across major languages including English, French, Spanish, German, Japanese, Chinese (Simplified and Traditional), Portuguese, Italian, Korean, Arabic, Russian, and Hindi. Anthropic's training data covers a long tail of additional languages with degraded but usable quality. For programming languages, coverage spans the full mainstream stack: JavaScript/TypeScript, Python, Java, Go, Rust, C/C++, C#, Ruby, PHP, Swift, Kotlin, SQL, shell scripting, and more.
Verdict: 9.1 out of 10

Claude Sonnet 4.6 earns a 9.1 out of 10 on three reasons: near-Opus coding quality at one-fifth the cost, a 1M token context window that retires entire categories of retrieval scaffolding, and a feature stack (adaptive thinking + computer use + prompt caching + Batch API) that compounds beautifully on production workloads. After three months running it as the worker tier on our ThePlanetTools.ai pipeline, we ship 2x more sub-agent iterations per dollar than we did on Sonnet 4.5 or all-Opus. What's holding it back from a 9.5+: the August 2025 knowledge cutoff trails Opus 4.7's January 2026, and the 1M context beta still throws occasional 529 errors above 600k tokens.
Score breakdown:
- Features: 9.2 out of 10 — 1M context, adaptive thinking, computer use, vision, prompt caching, Batch API. Full feature parity with Opus 4.7 minus output ceiling.
- Ease of Use: 9.0 out of 10 — Drop-in compatible with Sonnet 4.5 prompts. Excellent SDKs, multi-cloud parity. Minor: max-output footgun on synchronous calls.
- Value: 9.5 out of 10 — The best price-to-performance ratio in the under-$5-input-per-million bracket. Caching plus Batch API stack to ~70% cost reduction versus Opus 4.7 on real workloads.
- Support: 8.7 out of 10 — Excellent Anthropic docs, active community, fast model deprecation timeline. Lower tier customers don't get enterprise SLA, which is normal for the category.
Final word: If you're building anything agent-shaped in 2026 — coding assistants, customer support automation, browser automation, content pipelines — Sonnet 4.6 should be your default model. Use Opus 4.7 selectively for the hardest 10% of tasks where the extra reasoning matters and the cost gap is worth it. Use Haiku 4.5 for the simplest 30% where speed and cost matter more than depth. Sonnet 4.6 owns the middle 60% of production work, and that's where the volume lives.
Last tested: April 2026 on the ThePlanetTools.ai production pipeline. External community ratings on G2/Trustpilot/Capterra are not applicable to API-only LLM models — reviews of the consumer-facing Claude.ai product exist on those platforms but do not reflect Sonnet 4.6 API performance specifically. Pricing verified against the official Anthropic pricing page on April 27, 2026.
Key Features
Pros & Cons
Pros
- Near-Opus coding quality at one-fifth the cost — 79.6% on SWE-bench Verified versus Opus 4.7's slightly higher score, but Sonnet 4.6 costs $3 per million input tokens versus $5 for Opus 4.7.
- 1M token context window in beta — enough headroom to load entire codebases, long contracts, or dozens of research papers in a single request without retrieval scaffolding.
- Adaptive thinking lets the model decide when extended reasoning helps. We saw measurable wins on multi-step refactors without paying for thinking tokens on trivial calls.
- Best-in-class for sub-agent orchestration. We run Sonnet 4.6 as the worker model under Opus 4.7 coordinators in production and ship 2x more iterations per dollar than running Opus end-to-end.
- Computer use accuracy hit 94% on the insurance benchmark — the highest of any model Anthropic tested at release. Browser automation finally feels production-ready.
- Prompt caching plus Batch API stack: 90% off cache hits, 50% off batch runs. Combined, our nightly content QA pipeline costs 70% less than running the same prompts hot through Opus 4.7.
- Available across Claude API, AWS Bedrock, Google Vertex AI, and Microsoft Foundry — same model ID `claude-sonnet-4-6`, no migration friction across clouds.
Cons
- Knowledge cutoff is August 2025 (training data goes to January 2026), which lags Opus 4.7's reliable cutoff of January 2026. For news-aware tasks we still default to Opus 4.7 or web search tool.
- 1M context window remains beta on the Claude API, not GA. We've hit two intermittent 529-overload errors above 600k tokens — fine for batch jobs, risky for synchronous user-facing latency.
- Max output stops at 64k tokens on the synchronous Messages API. For longer outputs you need the 300k beta header on Batch API only — a footgun if you forget.
- No free plan on the API. New accounts get a small credit grant, but production usage starts billing immediately. This is normal for the LLM API category, but worth flagging vs free-tier models like Gemini.
- Adaptive thinking can occasionally over-trigger on simple tasks, inflating output tokens. We saw a 12% cost overrun on one pipeline before we explicitly disabled extended thinking for routine summaries.
Best Use Cases
Platforms & Integrations
Available On
Integrations
Compare Claude Sonnet 4.6

We're developers and SaaS builders who use these tools daily in production. Every review comes from hands-on experience building real products — DealPropFirm, ThePlanetIndicator, PropFirmsCodes, and many more. We don't just review tools — we build and ship with them every day.
Written and tested by developers who build with these tools daily.
Frequently Asked Questions
What is Claude Sonnet 4.6?
Anthropic's mid-tier workhorse — near-Opus coding quality at 1M context for $3 per million input tokens, $15 per million output tokens.
How much does Claude Sonnet 4.6 cost?
Claude Sonnet 4.6 costs $3/month.
Is Claude Sonnet 4.6 free?
No, Claude Sonnet 4.6 starts at $3/month.
What are the best alternatives to Claude Sonnet 4.6?
Top-rated alternatives to Claude Sonnet 4.6 include Claude Code (9.9/10), Cursor (9.5/10), Veo 3.1 (9.4/10), Claude Opus 4.7 (9.4/10) — all reviewed with detailed scoring on ThePlanetTools.ai.
Is Claude Sonnet 4.6 good for beginners?
Claude Sonnet 4.6 is rated 9/10 for ease of use.
What platforms does Claude Sonnet 4.6 support?
Claude Sonnet 4.6 is available on Claude API, AWS Bedrock, Google Vertex AI, Microsoft Foundry, Web (Claude Console), REST API.
Does Claude Sonnet 4.6 offer a free trial?
Yes, Claude Sonnet 4.6 offers a free trial.
Is Claude Sonnet 4.6 worth the price?
Claude Sonnet 4.6 scores 9.5/10 for value. We consider it excellent value.
Who should use Claude Sonnet 4.6?
Claude Sonnet 4.6 is ideal for: Sub-agent orchestration — running Sonnet 4.6 as worker under an Opus 4.7 coordinator (our production pattern), Coding agents and IDE assistants — Cursor, Windsurf, Claude Code, GitHub Copilot agent mode all default-route to Sonnet 4.6 for cost-perf balance, Long-context document Q&A — load entire contracts, codebases, or research libraries (with 1M context beta), Browser automation and computer use — end-to-end UI workflows, form filling, data extraction at 94% accuracy, Customer support automation — high-volume conversational agents where Opus 4.7 would be 5x overspend, Content generation pipelines — bulk article drafts, SEO content, social posts via Batch API at 50% off, Data extraction and structured output — JSON schemas, classifications, entity extraction with prompt caching, Enterprise RAG systems — replace fragile retrieval scaffolding with brute-force 1M context grounding.
What are the main limitations of Claude Sonnet 4.6?
Some limitations of Claude Sonnet 4.6 include: Knowledge cutoff is August 2025 (training data goes to January 2026), which lags Opus 4.7's reliable cutoff of January 2026. For news-aware tasks we still default to Opus 4.7 or web search tool.; 1M context window remains beta on the Claude API, not GA. We've hit two intermittent 529-overload errors above 600k tokens — fine for batch jobs, risky for synchronous user-facing latency.; Max output stops at 64k tokens on the synchronous Messages API. For longer outputs you need the 300k beta header on Batch API only — a footgun if you forget.; No free plan on the API. New accounts get a small credit grant, but production usage starts billing immediately. This is normal for the LLM API category, but worth flagging vs free-tier models like Gemini.; Adaptive thinking can occasionally over-trigger on simple tasks, inflating output tokens. We saw a 12% cost overrun on one pipeline before we explicitly disabled extended thinking for routine summaries..
Best Alternatives to Claude Sonnet 4.6



Ready to try Claude Sonnet 4.6?
Start your free trial
Try Claude Sonnet 4.6 Free →