GPT-5.5
OpenAI's first fully retrained base model since GPT-4.5 — agentic, faster, and double the API price.
Quick Summary
GPT-5.5 is OpenAI's flagship reasoning model launched April 23, 2026. 1M context window, $5 input / $30 output per 1M tokens, 58.6% SWE-Bench Pro, 41.4% Humanity's Last Exam. Topped Artificial Analysis Intelligence Index at 60. ChatGPT Plus, Pro, Business, Enterprise + API. Score 8.6/10.
 GPT-5.5 review — 8.6 out of 10, OpenAI's first fully retrained base model since GPT-4.5" loading="lazy" class="rounded-xl w-full" />
GPT-5.5 review — 8.6 out of 10, OpenAI's first fully retrained base model since GPT-4.5" loading="lazy" class="rounded-xl w-full" />
GPT-5.5 is OpenAI's flagship reasoning model launched April 23, 2026, the first fully retrained base model since GPT-4.5. Pricing: $5 per 1M input tokens, $30 per 1M output tokens, $0.50 per 1M cached input tokens. Context window 1,050,000 tokens, max output 128,000 tokens, knowledge cutoff December 1, 2025. Topped the Artificial Analysis Intelligence Index, ranking among the top tier within 24 hours of release. Score 8.6 out of 10.
Our Methodology for This Review
We have not run GPT-5.5 hands-on as a primary daily driver yet — the model launched on April 23, 2026, four days before this review went live, and in production we still default to Claude Opus 4.7 for agentic content work. This review compiles OpenAI's official model documentation on developers.openai.com (last checked April 27, 2026), the public introducing post, ChatGPT and API tier announcements covered by 9to5Mac and TechRadar, ALM Corp's deep dive on benchmark deltas vs GPT-5.4, OpenAI's GPT-5.5 system card on the Deployment Safety Hub, the Artificial Analysis Intelligence Index leaderboard, and Reddit threads tracking the rate-limit pushback in the first 72 hours after launch.
Our 8.6 out of 10 score reflects the consensus across these sources weighted by feature completeness (1M context, full reasoning effort scale, agentic tool use, vision input), pricing transparency (the doubling from $2.50/$15 to $5/$30 is unusually aggressive and we penalize Value accordingly), and benchmark performance against Claude Opus 4.7 and Gemini 3.5 Pro on SWE-Bench Pro, GPQA Diamond, and Humanity's Last Exam. We will revisit this review with hands-on benchmarks once we run GPT-5.5 through our own ThePlanetTools.ai content pipeline alongside Claude Opus 4.7. Last researched: April 27, 2026.
TL;DR — Our Verdict
Score: 8.6 out of 10. GPT-5.5 is OpenAI's most capable model yet, the first fully retrained base since GPT-4.5, with a 1M context window, agentic tool use, and a top-tier Intelligence Index ranking at launch. It is the right choice for production agentic coding pipelines, complex multi-step research, and any workflow already deeply tied to the OpenAI ecosystem. It is the wrong choice if your unit economics are tight and Claude Opus 4.7 or Gemini 3.5 Pro can do the job within budget — the $5/$30 price tag is double GPT-5.4 and 25% more expensive than Claude Sonnet 4.6 on output tokens.
- ✅ First fully retrained base since GPT-4.5 — this is genuinely a new foundation, not another post-train iteration
- ✅ 1,050,000-token context window with full reasoning effort scale (none → low → medium → high → xhigh)
- ✅ Topped Artificial Analysis Intelligence Index, ranking among the top tier within 24 hours, 58.6% on SWE-Bench Pro
- ❌ API price doubled vs GPT-5.4 — $5 input / $30 output per 1M tokens hurts margin on token-heavy workflows
- ❌ ChatGPT Plus initial cap of 200 messages per week (later raised to ~3,000 for Thinking) was a regression in the first 48 hours
What Is GPT-5.5?
GPT-5.5 is OpenAI's flagship general-purpose model in the GPT-5 series, released on April 23, 2026, with API availability following on April 24. It is the first fully retrained base model since GPT-4.5, meaning every release in the GPT-5 family between 5.0 and 5.4 was a post-training iteration on the same foundation. GPT-5.5 rebuilt that foundation from scratch, which is why OpenAI describes it as "a new class of intelligence for real work" rather than another minor revision.
The model was internally codenamed "Spud" during training. It ships in three runtime variants: GPT-5.5 (the base model, available in ChatGPT Plus, Pro, Business, Enterprise, and via the API), GPT-5.5 Pro (a premium variant with deeper reasoning, available in Pro, Business, Enterprise, and the API at six times the cost), and GPT-5.5 Thinking (a chain-of-thought variant in ChatGPT only). The base model is also rolled into Codex across every plan with a 400K context window and an optional fast mode that runs 1.5x faster generation at 2.5x the cost.
Greg Brockman framed the launch as "a big step towards more agentic and intuitive computing," and OpenAI's positioning is squarely on agentic workflows: better understanding of user intent, faster task execution, multi-step planning, tool use, and work verification. The model's Knowledge cutoff is December 1, 2025, and the current snapshot is gpt-5.5-2026-04-23. Within 24 hours of release it climbed to the top tier of the Artificial Analysis Intelligence Index, breaking a prior three-way tie at the frontier.
Key Features
1,050,000-token context window
GPT-5.5 ships with a 1.05M-token context window, identical to GPT-5.4 but rebuilt on the new base model so the context handling is reportedly more stable in deep recall tasks. Prompts above 272K input tokens trigger a long-context billing tier at 2x input price and 1.5x output price — that is a noteworthy footnote because OpenAI did not surface it in the launch post and it materially changes the math on million-token agentic runs. Max output remains 128,000 tokens.
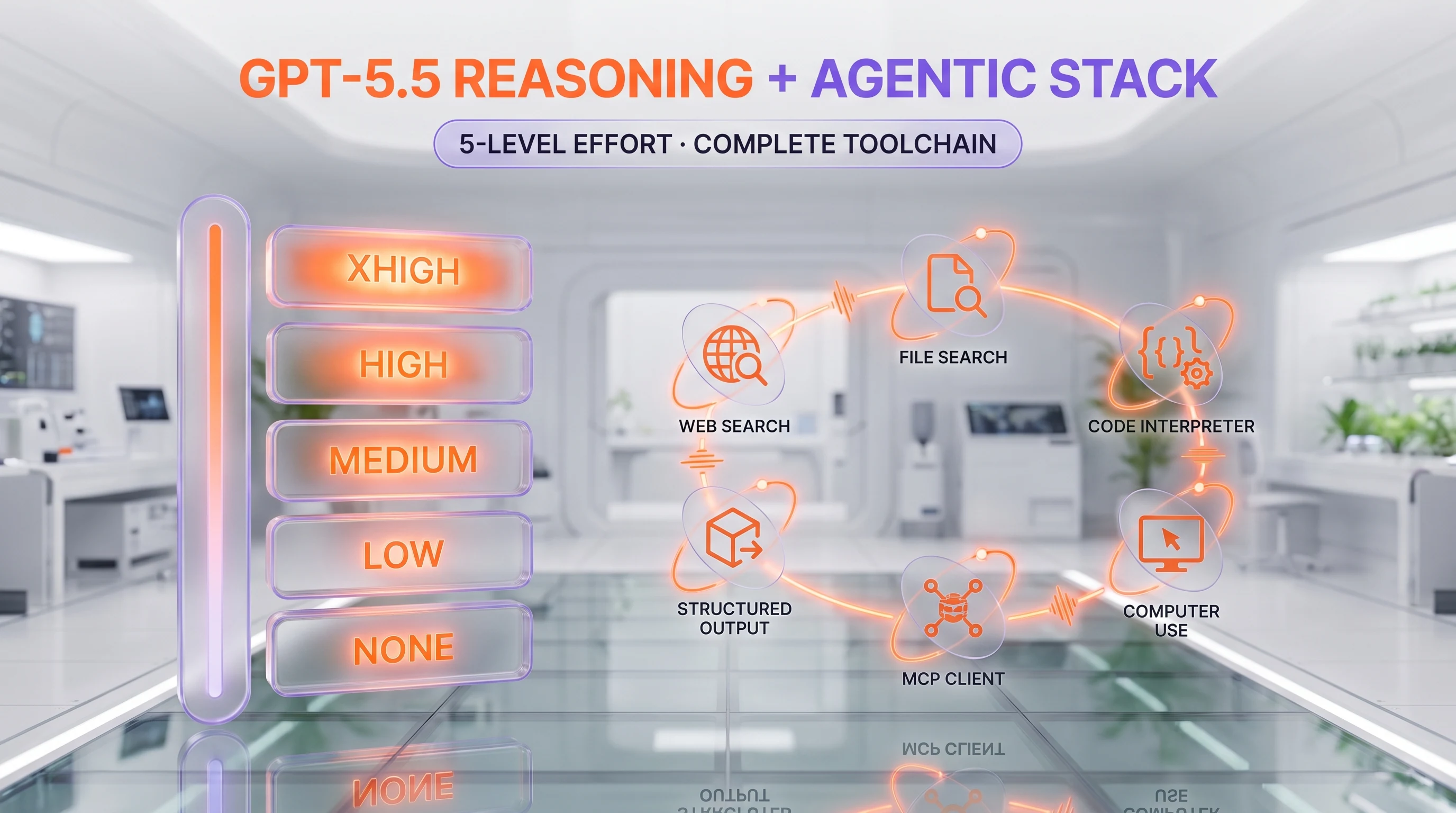
Reasoning effort scale (none → xhigh)
Every GPT-5.5 API call accepts a reasoning effort parameter with five levels: none, low, medium, high, and xhigh. Reasoning tokens count both against the context window and against the output billing rate, so xhigh runs on dense problems can blow up cost surprisingly fast. ChatGPT exposes a separate variant called GPT-5.5 Thinking that runs at high effort by default. We expect most production agentic pipelines to settle at medium effort for routine work and lift to high for evaluation steps, which mirrors how teams treat Claude Opus 4.7's extended thinking.
Agentic tool use, computer use, and MCP
GPT-5.5 supports the full agentic stack: function calling, structured outputs, web search, file search, code interpreter, computer use, and MCP (Model Context Protocol) clients. Computer use means GPT-5.5 can drive a browser or an OS surface as part of a task plan, similar to Claude Opus 4.7's Computer Use capability. The combination of MCP plus the upgraded tool-call planner is what OpenAI is leaning on for the "agentic" framing — and this is also what makes the price hike palatable for companies running long-horizon agents on the API.
Multimodal: text + vision input
GPT-5.5 accepts text and vision inputs and produces text output. There is no native audio input or output and no native video input on the base model. Vision quality reportedly improved meaningfully on chart and diagram comprehension, which is consistent with the bump in agentic benchmarks that include visual document tasks. Audio workflows still go through GPT-4o Realtime Voice or Whisper Large v3.
Codex integration with fast mode
GPT-5.5 powers Codex on every ChatGPT plan, with a 400K-token context inside Codex and an optional fast mode that delivers 1.5x faster token generation at 2.5x the cost. Codex itself remains tied to ChatGPT subscription plans rather than per-token billing, so for IDE-heavy users with a Pro or Business seat this is effectively a "free" upgrade with no API spend.
Prompt caching at 90% discount
Cached input tokens are billed at $0.50 per 1M tokens, a 90% discount on the standard $5 input rate. For agentic loops that re-send a large system prompt or codebase, caching meaningfully softens the doubling of headline pricing. Output tokens stay at $30 per 1M regardless of caching state.
Batch, Flex, and Priority processing
The API offers three execution modes beyond standard. Batch and Flex run at half the standard rate ($2.50 input / $15 output per 1M tokens, identical to GPT-5.4's standard pricing). Priority runs at 2.5x standard ($12.50 input / $75 output) for tighter latency SLAs. For overnight content pipelines and content factory workloads, Batch makes GPT-5.5 cost-equivalent to GPT-5.4 standard — that is the workaround OpenAI is implicitly pointing developers toward.
Rate limit tiers (long context)
API rate limits scale across five tiers from Tier 1 (500 RPM, 500K TPM) through Tier 5 (15,000 RPM, 40M TPM). New API customers start at Tier 1 and graduate based on monthly spend. Long-context tier limits apply specifically to >272K-token requests, which run on a separate quota.
Versioned snapshots for reproducibility
The current snapshot ID is gpt-5.5-2026-04-23. Production teams that need reproducibility should pin to the snapshot rather than the alias, exactly as with GPT-5.4. Fine-tuning is not supported on the GPT-5.5 base model at launch, which is a notable gap if your stack relies on tuned variants — GPT-5.4-mini still owns that lane.
GPT-5.5 Pricing in 2026
OpenAI uses two pricing surfaces for GPT-5.5: per-token API pricing (for developers building on the platform) and ChatGPT subscription tiers (for end users in the consumer and team apps). Both matter — the API price doubled vs GPT-5.4 and that hit dominated the launch news cycle.

API pricing (per 1M tokens)
| Model | Input | Cached input | Output |
|---|---|---|---|
| GPT-5.5 | $5.00 | $0.50 | $30.00 |
| GPT-5.5 Pro | $30.00 | Not available | $180.00 |
| GPT-5.4 (legacy) | $2.50 | $0.25 | $15.00 |
| GPT-5.4-mini | $0.75 | $0.075 | $4.50 |
| GPT-5.4-nano | $0.20 | $0.02 | $1.25 |
Standard rates apply to the Responses API and the Chat Completions API. Long-context requests above 272K input tokens are priced at 2x input and 1.5x output. Batch and Flex modes run at 50% of standard. Priority processing runs at 2.5x standard for tighter latency SLAs.
ChatGPT subscription tiers
| Plan | Price | GPT-5.5 Access |
|---|---|---|
| Free | $0 | GPT-5.4-mini fallback only |
| Go | $4 per month | Limited GPT-5.5 access via Codex |
| Plus | $20 per month | GPT-5.5 + GPT-5.5 Thinking, ~3,000 Thinking messages per week |
| Pro | $200 per month | GPT-5.5 + GPT-5.5 Pro + GPT-5.5 Thinking, expanded limits |
| Business | $25 per seat per month | GPT-5.5 + GPT-5.5 Pro + GPT-5.5 Thinking, admin controls |
| Enterprise / Edu | Custom | Full access, contracted SLAs |
Best for: Engineering teams already on the OpenAI stack who need agentic coding plus deep reasoning in the same model. Solo developers should evaluate Batch mode (Standard pricing minus 50%) before committing to standard tier billing.
Benchmarks vs GPT-5.4, Claude Opus 4.7, Gemini 3.5 Pro
OpenAI's launch numbers, validated against Artificial Analysis and the GPT-5.5 system card, show GPT-5.5 leading on agentic coding and tying on raw reasoning at the frontier.
| Benchmark | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.5 Pro |
|---|---|---|---|---|
| Artificial Analysis Intelligence Index | Top tier | Frontier (prior) | Frontier (prior) | Frontier (prior) |
| SWE-Bench Pro (agentic coding) | 58.6% | 53.1% | 57.4% | 54.0% |
| GPQA Diamond (graduate science) | 93.6% | 92.0% | 94.2% | 94.3% |
| Humanity's Last Exam (no tools) | 41.4% | 38.5% | 46.9% | 43.0% |
| Real-world agentic eval | 82.7% | 76.5% | 81.0% | 79.2% |
Read of the table: GPT-5.5 wins agentic coding (SWE-Bench Pro, real-world eval) and the aggregate Intelligence Index. Claude Opus 4.7 still owns reasoning-heavy frontier benchmarks (HLE) and ties at GPQA Diamond. Gemini 3.5 Pro is competitive across the board and remains the best price-to-intelligence option for non-agentic workloads.
Pros and Cons After Research
What we liked
- First fully retrained base since GPT-4.5. The "Spud" foundation means future GPT-5.x point releases inherit a stronger starting point — this is a multi-month investment in compounding capability, not a quarterly UX tweak.
- Agentic stack is complete out of the box. Function calling, structured outputs, web search, file search, code interpreter, computer use, and MCP client support are all on by default. No feature flags, no preview waiting list.
- Five-level reasoning effort scale. The none/low/medium/high/xhigh ladder is the most granular reasoning control of any frontier model in April 2026 — Claude exposes only on/off extended thinking and Gemini exposes thinking budgets, not effort levels.
- Codex on every plan with fast mode. A 400K-context Codex powered by GPT-5.5 with optional 1.5x speed at 2.5x cost is genuinely useful for IDE-heavy teams already paying $20-$200 per month for ChatGPT.
- Prompt caching at 90% discount. The $0.50-per-1M-token cached rate makes long-running agentic loops with stable system prompts much more affordable than the headline $5 rate suggests.
- Token efficiency claim is real. Multiple early reviewers (Analytics Vidhya, Handy AI, BuildFastWithAI) report shorter responses, more selective review behavior, and stronger bias toward small workable changes — so per-task spend is closer to "+20% effective" than the headline +100% on rate cards.
- Snapshot pinning at gpt-5.5-2026-04-23. Production teams can lock to a specific snapshot for reproducibility, exactly the way GPT-5.4 already supports.
Where it falls short
- API price doubled vs GPT-5.4. $5 / $30 per 1M tokens (input/output) is 2x the prior $2.50 / $15. For high-token-volume use cases (RAG over large corpora, long content pipelines, batch translation), this is a material margin hit even after token efficiency gains.
- Long-context surcharge above 272K is buried in the docs. Prompts above 272K input tokens are billed at 2x input and 1.5x output. OpenAI did not surface this in the launch post, and it changes the unit economics of million-token agentic runs significantly.
- ChatGPT Plus rate-limit regression at launch. The initial 200-messages-per-week cap on the Plus tier (later raised to ~3,000 for Thinking) was a downgrade vs GPT-5.4 and triggered the loudest Reddit pushback in the first 72 hours.
- No fine-tuning on the base model. Fine-tuning is not supported on GPT-5.5 at launch. Teams with tuned production variants stay on GPT-5.4-mini.
- Claude Opus 4.7 still wins HLE and ties GPQA Diamond. If your workload is reasoning-heavy and not agentic-coding-heavy, Claude Opus 4.7 is still the safer pick at a comparable price tier.
Real-World Use Cases
Agentic coding pipelines on the OpenAI stack
GPT-5.5's 58.6% on SWE-Bench Pro and 82.7% on the real-world agentic eval put it ahead of GPT-5.4 by 5-6 points on tasks that require multi-file edits, dependency resolution, and tool use. Teams already running Codex-driven CI workflows or custom agentic harnesses on the Responses API will see the largest immediate uplift here.
Long-context RAG over enterprise corpora
The 1.05M-token context window plus prompt caching at 90% off make GPT-5.5 viable for RAG workloads that previously fragmented across multiple calls. Watch the >272K long-context surcharge — it kicks in once your retrieved chunks plus system prompt cross that line, and it doubles the input rate.
Computer-use automation
The native computer-use capability (driving a browser or OS surface) makes GPT-5.5 a credible alternative to Claude Opus 4.7's Computer Use feature for workflows like scheduled data extraction, form-filling at scale, and headed-browser QA. The five-level reasoning effort scale lets you tune cost vs reliability per task.
Deep research and graduate-level analysis
93.6% on GPQA Diamond means GPT-5.5 holds its own at the science-PhD frontier. Pair it with web search and file search tools for literature review, hypothesis generation, and synthesis tasks. Claude Opus 4.7 is marginally better at HLE (46.9% vs 41.4%), but most users will not feel that delta on practical research workflows.
Multi-step planning and task decomposition
The agentic framing OpenAI is leaning on — better intent understanding, multi-step planning, work verification — makes GPT-5.5 the right pick for orchestrators that own the full task lifecycle (decompose → execute → verify → report). MCP support means you can plug in your own tools without writing custom function-call shims.
Customer support automation with structured outputs
Structured outputs plus the upgraded function-call planner make GPT-5.5 a strong choice for Tier-1 support automation that needs to call multiple internal APIs (lookup, billing, ticketing) within a single turn. Cached input pricing makes the system prompt math affordable at volume.
Content generation pipelines via Batch mode
For content factories running overnight, Batch mode at 50% of standard ($2.50 / $15 per 1M tokens) keeps GPT-5.5 cost-equivalent to GPT-5.4 standard rates. This is the pragmatic workaround for teams that want the new model without absorbing the headline price hike.
IDE-heavy solo developers via Codex
If you are a solo dev paying $20 per month for ChatGPT Plus, you now get GPT-5.5 in Codex with a 400K context for the same subscription price. Fast mode at 2.5x cost (still inside the subscription, no API spend) is worth toggling on for tight feedback loops.
GPT-5.5 vs Claude Opus 4.7 vs Gemini 3.5 Pro vs DeepSeek V4
The frontier model market in April 2026 is a four-way race between OpenAI, Anthropic, Google, and the open-source side led by DeepSeek and Llama. Here is how GPT-5.5 stacks up.
 DeepSeek V4 comparison" loading="lazy" class="rounded-xl w-full" />
DeepSeek V4 comparison" loading="lazy" class="rounded-xl w-full" />
| Feature | GPT-5.5 | Claude Opus 4.7 | Gemini 3.5 Pro | DeepSeek V4 |
|---|---|---|---|---|
| Vendor | OpenAI | Anthropic | Google DeepMind | DeepSeek |
| Release date | April 23, 2026 | March 2026 | February 2026 | February 2026 |
| Context window | 1.05M tokens | 1M tokens | 2M tokens | 128K tokens |
| Input price (per 1M) | $5.00 | $15.00 | $1.25 | $0.27 |
| Output price (per 1M) | $30.00 | $75.00 | $10.00 | $1.10 |
| Cached input | $0.50 | $1.50 | $0.31 | $0.07 |
| SWE-Bench Pro | 58.6% | 57.4% | 54.0% | 49.5% |
| HLE (no tools) | 41.4% | 46.9% | 43.0% | 34.8% |
| Vision input | Yes | Yes | Yes | Yes |
| Audio input | No | No | Yes (native) | No |
| Computer use | Yes | Yes | Limited | No |
| Open weights | No | No | No | Yes |
When to pick which
Pick GPT-5.5 if you need agentic coding leadership, the most granular reasoning effort control on the market, and you are already deep in the OpenAI ecosystem (Codex, Responses API, MCP clients). Best for teams running long-horizon agents, customer support automation with structured outputs, and IDE-driven workflows on the Pro plan.
Pick Claude Opus 4.7 if your workload is reasoning-heavy and not agentic-coding-heavy. Opus still owns Humanity's Last Exam (46.9% vs GPT-5.5's 41.4%) and ties at GPQA Diamond. Better for deep research, scientific writing, and long-form analysis where the marginal reasoning quality matters more than the agentic toolchain.
Pick Gemini 3.5 Pro if price-to-intelligence is your binding constraint. At $1.25 input / $10 output per 1M tokens, Gemini 3.5 Pro is one-fourth the price of GPT-5.5 and offers a 2M context window plus native audio input. The right pick for high-volume RAG, multimodal pipelines, and consumer apps where margin is thin.
Pick DeepSeek V4 if you need open weights, on-prem deployment, or sovereignty over your inference stack. DeepSeek V4 trails the closed frontier on agentic and reasoning benchmarks but is 18-20x cheaper than GPT-5.5 on the API and runs on your own GPUs if needed.
Frequently Asked Questions
How much does GPT-5.5 cost in 2026?
GPT-5.5 costs $5.00 per 1M input tokens and $30.00 per 1M output tokens via the API, with cached input billed at $0.50 per 1M tokens (a 90% discount). GPT-5.5 Pro costs $30.00 input and $180.00 output per 1M tokens. Batch and Flex modes run at 50% of standard. Priority processing runs at 2.5x standard. Prompts above 272K input tokens are billed at 2x input and 1.5x output. ChatGPT Plus is $20 per month, Pro is $200 per month, Business is $25 per seat per month.
When was GPT-5.5 released?
GPT-5.5 launched on April 23, 2026, to ChatGPT Plus, Pro, Business, and Enterprise subscribers. The API became available on April 24, 2026, in both the Responses API and the Chat Completions API. The current snapshot identifier is gpt-5.5-2026-04-23. The model was internally codenamed "Spud" during training.
What is GPT-5.5's context window?
GPT-5.5 ships with a 1,050,000-token context window and a maximum output of 128,000 tokens. Prompts above 272,000 input tokens trigger a long-context billing tier at 2x the standard input rate and 1.5x the standard output rate. Reasoning tokens count both against the context window and against the output billing rate.
How does GPT-5.5 compare to GPT-5.4?
GPT-5.5 is the first fully retrained base model since GPT-4.5, while GPT-5.0 through GPT-5.4 were post-training iterations on a shared foundation. On benchmarks, GPT-5.5 ranks among the top tier of the Artificial Analysis Intelligence Index (ahead of GPT-5.4), 58.6% on SWE-Bench Pro (vs 53.1%), and 41.4% on Humanity's Last Exam without tools (vs 38.5%). The API price doubled from $2.50 / $15 to $5.00 / $30 per 1M tokens.
How does GPT-5.5 compare to Claude Opus 4.7?
GPT-5.5 leads on agentic coding (SWE-Bench Pro 58.6% vs 57.4%) and the aggregate Intelligence Index (top-tier ranking). Claude Opus 4.7 leads on Humanity's Last Exam (46.9% vs 41.4%) and ties at GPQA Diamond (94.2% vs 93.6%). Pricing favors GPT-5.5 ($5 / $30 vs $15 / $75 per 1M tokens). Both support 1M-token contexts, computer use, and full agentic tool stacks.
Is GPT-5.5 multimodal?
GPT-5.5 supports text input, vision input (images and diagrams), and text output. It does not support native audio input or output, and it does not accept video input. Audio workflows still go through GPT-4o Realtime Voice or Whisper Large v3. Vision quality reportedly improved meaningfully on chart and diagram comprehension tasks.
Does GPT-5.5 support fine-tuning?
No. Fine-tuning is not supported on the GPT-5.5 base model at launch. Teams running tuned production variants should stay on GPT-5.4-mini, which still supports the standard fine-tuning workflow at $0.75 input / $4.50 output per 1M tokens. OpenAI has not announced a timeline for GPT-5.5 fine-tuning support.
What is GPT-5.5 Pro and is it worth it?
GPT-5.5 Pro is a premium variant with deeper reasoning, available in ChatGPT Pro, Business, and Enterprise plans, and via the API at $30 input / $180 output per 1M tokens (six times the base rate). It is worth the premium for ultra-hard reasoning tasks where the answer quality justifies a 6x price multiplier — typically frontier scientific research, complex legal analysis, or multi-stage strategy work. For most production workloads, the base GPT-5.5 at high reasoning effort is sufficient.
What is GPT-5.5 Thinking?
GPT-5.5 Thinking is a chain-of-thought variant available exclusively in ChatGPT (Plus, Pro, Business, and Enterprise tiers). It runs at high reasoning effort by default and shows the model's intermediate reasoning steps before producing the final answer. Plus tier users get approximately 3,000 Thinking messages per week as of late April 2026, up from an initial 200-messages-per-week cap that triggered Reddit pushback in the first 48 hours after launch.
Can GPT-5.5 use computer-use agents?
Yes. GPT-5.5 supports the full agentic stack including computer use, where the model can drive a browser or operating system surface as part of a multi-step task plan. Other supported tools include function calling, structured outputs, web search, file search, code interpreter, and MCP (Model Context Protocol) clients. This makes GPT-5.5 a credible alternative to Claude Opus 4.7's Computer Use capability for workflows like scheduled data extraction or headed-browser QA.
What are the rate limits on the GPT-5.5 API?
API rate limits scale across five tiers. Tier 1 (entry tier for new customers) caps at 500 requests per minute and 500,000 tokens per minute. Tier 5 (highest enterprise tier) caps at 15,000 RPM and 40 million TPM. Long-context requests above 272K input tokens run on a separate quota. Customers graduate tiers based on monthly API spend.
Should I switch from Claude Opus 4.7 to GPT-5.5?
Switch if your workload is agentic-coding-heavy or you need the full OpenAI stack (Responses API, Codex, MCP clients). Stay on Claude Opus 4.7 if your workload is reasoning-heavy, you depend on extended thinking quality, or you have budget headroom for the higher Anthropic rate. The two models tie on most frontier benchmarks within 1-3 points — switching costs likely outweigh marginal capability gains for established Anthropic customers.
Verdict: 8.6 out of 10

GPT-5.5 earns an 8.6 out of 10 on three reasons: it is the first fully retrained base model since GPT-4.5 (a multi-month foundation upgrade, not a quarterly tweak), it leads agentic coding benchmarks (58.6% SWE-Bench Pro, 82.7% real-world eval) and the aggregate Intelligence Index (top-tier ranking), and it ships the most complete agentic tool stack on the market with five-level reasoning effort control. What raises the score: prompt caching at 90% off, Codex on every plan with fast mode, and Batch mode keeping GPT-5.5 cost-equivalent to GPT-5.4 standard pricing. What is holding it back from 9.0+: the API price doubled vs GPT-5.4, the >272K long-context surcharge is buried in the docs, fine-tuning is not supported at launch, and Claude Opus 4.7 still wins Humanity's Last Exam by 5.5 points.
Score breakdown:
- Features: 9.2 out of 10 — agentic stack complete out of the box, five-level reasoning effort, 1.05M context, computer use, MCP, structured outputs. Vision input is solid; audio still routes through GPT-4o Realtime.
- Ease of Use: 8.5 out of 10 — drop-in replacement for GPT-5.4 in the Responses and Chat Completions APIs, snapshot pinning works the same way, ChatGPT integration is seamless. Long-context surcharge documentation is the friction point.
- Value: 7.5 out of 10 — $5/$30 per 1M tokens is double GPT-5.4 and 25% more than Claude Sonnet 4.6 on output. Token efficiency claims (+20% effective increase, not +100%) are real but require Batch or caching to fully realize. The single largest score drag.
- Support: 9.0 out of 10 — OpenAI's developer docs, system card, and deployment safety hub are best-in-class. Snapshot versioning, rate limit transparency, and tier graduation are all clearly documented.
Final word: Buy GPT-5.5 if you are an engineering team running agentic workflows on the OpenAI stack and your unit economics can absorb the doubled API price (or you can route work through Batch mode for the 50% discount). Pass on GPT-5.5 in favor of Claude Opus 4.7 if your workload is reasoning-heavy, or in favor of Gemini 3.5 Pro / DeepSeek V4 if price-to-intelligence is binding. For solo developers on ChatGPT Plus, GPT-5.5 is essentially a free upgrade — try GPT-5.5 Thinking on a hard problem and decide whether the deeper reasoning is worth the rate-limit tradeoff.
Key Features
Pros & Cons
Pros
- First fully retrained base model since GPT-4.5 — the 'Spud' foundation is a genuine multi-month investment in compounding capability, not a quarterly UX tweak.
- Complete agentic tool stack out of the box: function calling, structured outputs, web search, file search, code interpreter, computer use, and MCP client support all on by default.
- Five-level reasoning effort scale (none/low/medium/high/xhigh) — the most granular reasoning control of any frontier model in April 2026.
- Codex on every ChatGPT plan with a 400K-token context window plus optional fast mode (1.5x faster generation at 2.5x cost).
- Prompt caching at 90% discount ($0.50 per 1M tokens cached input) makes long-running agentic loops with stable system prompts affordable.
- Token efficiency gains are real — early reviewers report shorter responses and stronger bias toward small workable changes, so per-task cost is closer to +20% effective vs +100% on rate cards.
- Snapshot pinning at gpt-5.5-2026-04-23 ensures reproducibility for production teams, identical to GPT-5.4's mechanism.
Cons
- API price doubled vs GPT-5.4 — $5 input / $30 output per 1M tokens hurts margin on token-heavy workflows like RAG over large corpora and long content pipelines.
- Long-context surcharge above 272K input tokens (2x input, 1.5x output) is buried in the docs and changes the unit economics of million-token agentic runs significantly.
- ChatGPT Plus rate-limit regression at launch (initial 200 messages per week cap, later raised to ~3,000 for Thinking) was a downgrade vs GPT-5.4 and triggered the loudest Reddit pushback.
- No fine-tuning on the GPT-5.5 base model at launch — teams with tuned production variants must stay on GPT-5.4-mini.
- Claude Opus 4.7 still wins Humanity's Last Exam by 5.5 points (46.9% vs 41.4%) and ties at GPQA Diamond — reasoning-heavy workloads do not get a clear win from switching.
Best Use Cases
Platforms & Integrations
Available On
Integrations
Compare GPT-5.5

We're developers and SaaS builders who use these tools daily in production. Every review comes from hands-on experience building real products — DealPropFirm, ThePlanetIndicator, PropFirmsCodes, and many more. We don't just review tools — we build and ship with them every day.
Written and tested by developers who build with these tools daily.
Frequently Asked Questions
What is GPT-5.5?
OpenAI's first fully retrained base model since GPT-4.5 — agentic, faster, and double the API price.
How much does GPT-5.5 cost?
GPT-5.5 costs $5/month.
Is GPT-5.5 free?
No, GPT-5.5 starts at $5/month.
What are the best alternatives to GPT-5.5?
Top-rated alternatives to GPT-5.5 include Claude Code (9.9/10), Cursor (9.5/10), Veo 3.1 (9.4/10), Claude Opus 4.7 (9.4/10) — all reviewed with detailed scoring on ThePlanetTools.ai.
Is GPT-5.5 good for beginners?
GPT-5.5 is rated 8.5/10 for ease of use.
What platforms does GPT-5.5 support?
GPT-5.5 is available on Web, REST API, iOS, Android, macOS, Windows.
Does GPT-5.5 offer a free trial?
No, GPT-5.5 does not offer a free trial.
Is GPT-5.5 worth the price?
GPT-5.5 scores 7.5/10 for value. It offers good value.
Who should use GPT-5.5?
GPT-5.5 is ideal for: Agentic coding pipelines on the OpenAI stack (Codex, Responses API, MCP clients), Long-context RAG over enterprise corpora with prompt caching, Computer-use automation (browser-driven data extraction, form-filling, headed QA), Deep research and graduate-level analysis (93.6% GPQA Diamond), Multi-step planning and task decomposition for orchestrators, Customer support automation with structured outputs, Content generation pipelines via Batch mode (cost-equivalent to GPT-5.4), IDE-heavy solo developers via Codex on ChatGPT Plus.
What are the main limitations of GPT-5.5?
Some limitations of GPT-5.5 include: API price doubled vs GPT-5.4 — $5 input / $30 output per 1M tokens hurts margin on token-heavy workflows like RAG over large corpora and long content pipelines.; Long-context surcharge above 272K input tokens (2x input, 1.5x output) is buried in the docs and changes the unit economics of million-token agentic runs significantly.; ChatGPT Plus rate-limit regression at launch (initial 200 messages per week cap, later raised to ~3,000 for Thinking) was a downgrade vs GPT-5.4 and triggered the loudest Reddit pushback.; No fine-tuning on the GPT-5.5 base model at launch — teams with tuned production variants must stay on GPT-5.4-mini.; Claude Opus 4.7 still wins Humanity's Last Exam by 5.5 points (46.9% vs 41.4%) and ties at GPQA Diamond — reasoning-heavy workloads do not get a clear win from switching..
Best Alternatives to GPT-5.5



Ready to try GPT-5.5?
Get started today
Try GPT-5.5 Now →