GLM-5.2 vs DeepSeek V4: Best Coding Score vs Cheapest Open Model (2026)


We ran GLM-5.2 and DeepSeek V4 side by side. GLM wins SWE-bench Pro 62.1 vs 55.4; DeepSeek wins on price at one-tenth the input cost. Full verdict.

Feature Comparison
| Feature | GLM-5.2 | DeepSeek V4 |
|---|---|---|
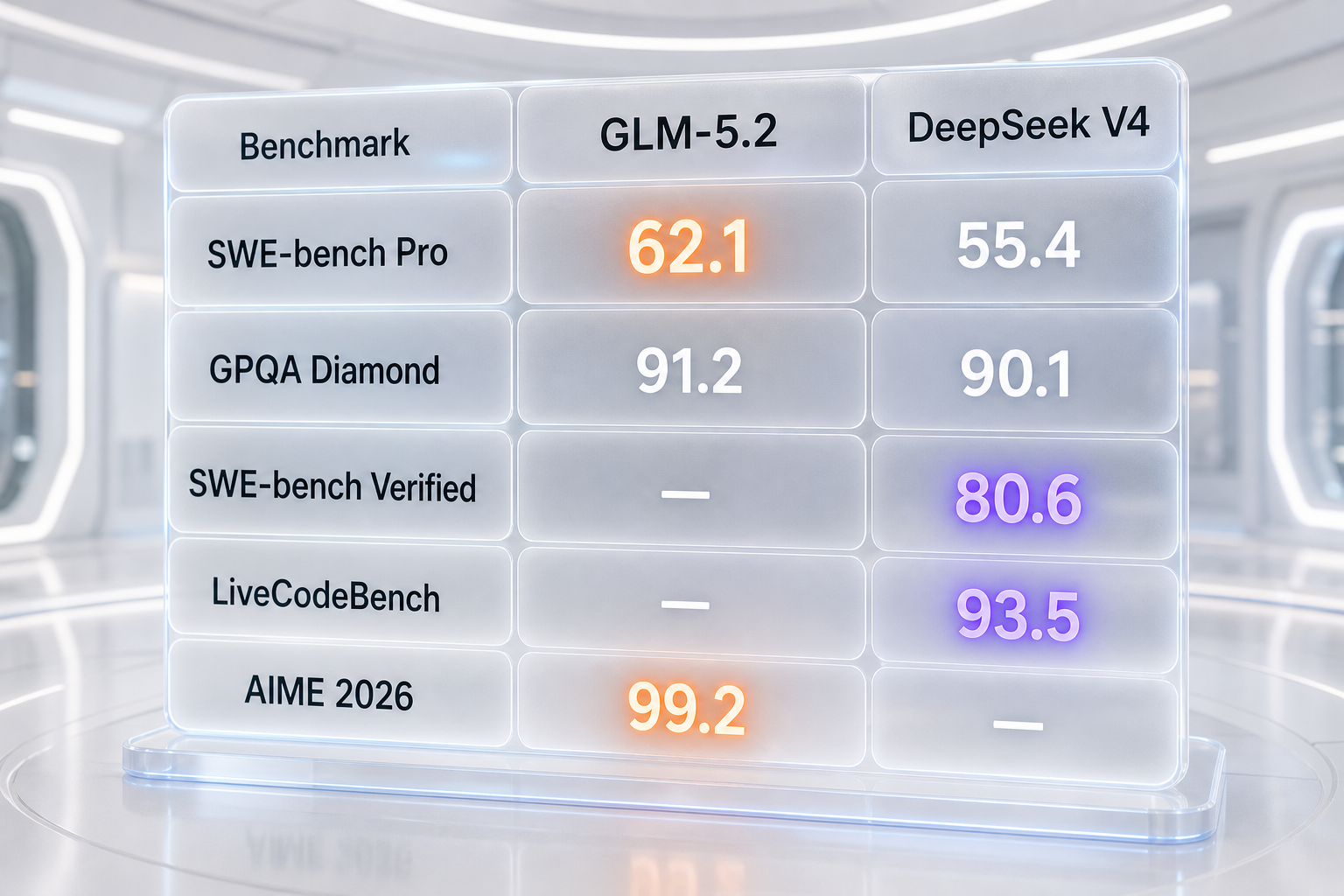
| SWE-bench Pro (head-to-head, both vendors report) | 62.1 | 55.4 |
| GPQA Diamond | 91.2 | 90.1 |
| SWE-bench Verified | Not reported | 80.6 |
| LiveCodeBench | Not reported | 93.5 |
| Terminal-Bench 2.1 | 81.0 (82.7 best harness) | Not reported |
| AIME 2026 (math reasoning) | 99.2 | Not reported |
| Codeforces rating | Not reported | 3206 |
| Input price (per M tokens, cheapest tier) | $1.40 | $0.14 (V4-Flash) |
| Output price (per M tokens, cheapest tier) | $4.40 | $0.28 (V4-Flash) |
| Max output tokens | 128K (131K in Claude Code) | 384K |
| Context window | 1M tokens | 1M tokens |
| Parameters (total / active) | 753B / ~40B | 1.6T / 49B (Pro) |
| License | MIT (weights week after launch) | MIT (day-one weights) |
| Flat-rate subscription option | GLM Coding Plan from $18 per month | Pay-per-token only |
| Coding-agent ecosystem | Claude Code, Cline, Kilo, OpenClaw, Goose, Roo | Broad but less coding-agent-tuned |
Pricing Comparison
GLM-5.2
DeepSeek V4
Detailed Comparison
GLM-5.2 and DeepSeek V4 are the two leading Chinese open-weight coding models of mid-2026, both MIT-licensed with 1 million token context. We ran both side by side. On the one coding suite both vendors publish, SWE-bench Pro, GLM-5.2 leads with a self-reported 62.1 against DeepSeek V4's 55.4, and the two essentially tie on GPQA Diamond (91.2 vs 90.1). DeepSeek V4 answers with the broadest verified coding coverage — 80.6 on SWE-bench Verified and 93.5 on LiveCodeBench, neither of which Zhipu reports — and a decisive price advantage: V4-Flash costs roughly one-tenth the input price and one-sixteenth the output price of GLM-5.2. Our overall pick is DeepSeek V4 for most teams because price wins at volume, but it is a close, split decision: choose GLM-5.2 when you want the strongest reported agentic coding capability, a flat monthly bill, and tight coding-agent integration.
Quick Verdict: who wins on what
This is one of the closest open-weight matchups of 2026, so the honest answer is that the winner depends on what you optimize for. Here is the short version before we get into the detail.
- Best raw coding capability (reported): GLM-5.2 — it leads SWE-bench Pro 62.1 to 55.4, the one coding suite both labs publish, and posts a near-perfect 99.2 on AIME 2026.
- Best verified breadth: DeepSeek V4 — it adds 80.6 SWE-bench Verified, 93.5 LiveCodeBench, and a 3206 Codeforces rating that GLM-5.2 does not report at all.
- Best price: DeepSeek V4, by a wide margin — V4-Flash at $0.14 input and $0.28 output per million tokens is roughly one-tenth and one-sixteenth of GLM-5.2's $1.40 / $4.40.
- Best for predictable billing: GLM-5.2 — the flat-rate GLM Coding Plan from about $18 per month removes per-token anxiety entirely.
- Best for coding agents: GLM-5.2 — Zhipu ships explicit drop-in support for Claude Code, Cline, Kilo Code, OpenClaw, Goose, and Roo.
- Best for self-hosting day one: DeepSeek V4 — MIT weights and Huawei Ascend inference shipped on launch day; GLM-5.2's downloadable weights arrived the week after.
- Longest generations: DeepSeek V4 — 384K max output versus GLM-5.2's 128K.
Our overall pick: DeepSeek V4, because at any real token volume the price gap is decisive and the verified-benchmark breadth is wider. But if your bottleneck is raw agentic coding quality on the suites both vendors actually report, GLM-5.2 is in front, and its flat plan can be cheaper than metered tokens for heavy daily use. Every benchmark number on this page is vendor self-reported and not yet independently verified.
GLM-5.2 in one paragraph
GLM-5.2 is Zhipu AI's open-weight coding flagship, released in mid-June 2026 under an MIT license. It is a 753 billion parameter mixture-of-experts model with roughly 40 billion parameters active per token, a 1 million token context window, and 128K max output (131K in Claude Code tests). Zhipu published a benchmark table alongside the release that leads on long-horizon coding and reasoning: SWE-bench Pro 62.1, Terminal-Bench 2.1 81.0 (82.7 on the best reported harness), AIME 2026 99.2, GPQA Diamond 91.2, and HLE with tools 54.7. It is sold either pay-per-token at $1.40 input and $4.40 output per million tokens, or via the flat-rate GLM Coding Plan from around $18 per month. Its standout positioning is drop-in compatibility with the major coding agents — Claude Code, Cline, Kilo Code, OpenClaw, Goose, and Roo — which makes it unusually easy to swap into an existing agentic workflow.
DeepSeek V4 in one paragraph
DeepSeek V4 launched on April 24, 2026, also under an MIT license, in two variants: V4-Pro (1.6 trillion parameters, 49 billion active) and V4-Flash (284 billion parameters, 13 billion active). Both carry a 1 million token context window and a 384K max output ceiling — the longest in this matchup. Its self-reported benchmarks are built for breadth: 80.6 on SWE-bench Verified, 55.4 on SWE-bench Pro, 90.1 GPQA Diamond, 93.5 LiveCodeBench, a 3206 Codeforces rating, and 87.5 MMLU-Pro. The headline, though, is price: V4-Flash costs $0.14 per million input tokens (cache miss) and $0.28 output, with cache hits as low as $0.0028 — and V4-Pro at $0.435 / $0.87 still undercuts most Western frontier models several times over. DeepSeek also shipped day-one Huawei Ascend inference and a Hybrid Attention architecture that cuts inference FLOPs and KV cache dramatically.
Spec and benchmark comparison table
| Dimension | GLM-5.2 (Zhipu) | DeepSeek V4 | Edge |
|---|---|---|---|
| SWE-bench Pro (both report) | 62.1 | 55.4 | GLM-5.2 |
| GPQA Diamond | 91.2 | 90.1 | Tie (GLM edge) |
| SWE-bench Verified | Not reported | 80.6 | DeepSeek |
| LiveCodeBench | Not reported | 93.5 | DeepSeek |
| Terminal-Bench 2.1 | 81.0 (82.7 best harness) | Not reported | GLM-5.2 |
| AIME 2026 | 99.2 | Not reported | GLM-5.2 |
| Codeforces rating | Not reported | 3206 | DeepSeek |
| MMLU-Pro | Not reported | 87.5 | DeepSeek |
| Input price (cheapest tier) | $1.40 per M tokens | $0.14 per M tokens (V4-Flash) | DeepSeek |
| Output price (cheapest tier) | $4.40 per M tokens | $0.28 per M tokens (V4-Flash) | DeepSeek |
| Cache-hit input price | Not published | $0.0028 per M tokens (V4-Flash) | DeepSeek |
| Max output tokens | 128K (131K in Claude Code) | 384K | DeepSeek |
| Context window | 1M tokens | 1M tokens | Tie |
| Parameters (total / active) | 753B / ~40B | 1.6T / 49B (Pro), 284B / 13B (Flash) | Tie |
| License | MIT (weights week after launch) | MIT (day-one weights) | DeepSeek |
| Flat-rate plan | GLM Coding Plan from $18 per month | Pay-per-token only | GLM-5.2 |
| Coding-agent integration | Claude Code, Cline, Kilo, OpenClaw, Goose, Roo | Broad, less coding-agent-tuned | GLM-5.2 |
| Domestic-chip inference | Not advertised day one | Huawei Ascend day one | DeepSeek |
All benchmark numbers above are vendor self-reported (z.ai / Hugging Face for GLM-5.2; deepseek.com / api-docs.deepseek.com for DeepSeek V4) and have not been independently verified by a neutral harness. Treat them as vendor claims, not settled fact.
Benchmarks head-to-head: the honest read
The temptation with two models that publish different benchmark suites is to declare the one with more numbers the winner. That is the wrong read here. The fair comparison is to look first at the suites both vendors actually report, and only then at the extras.
Where they overlap
Two benchmarks appear in both published tables. On SWE-bench Pro — arguably the hardest real-world software-engineering suite in common use — GLM-5.2 scores 62.1 against DeepSeek V4's 55.4. That is a meaningful 6.7-point lead for GLM-5.2, and Zhipu's own framing notes it edges past GPT-5.5 at 58.6 on the same test. On GPQA Diamond, the graduate-level science reasoning benchmark, the two are within a point: GLM-5.2 at 91.2, DeepSeek V4 at 90.1. Call that a statistical tie with a slight GLM lean. So on apples-to-apples ground, GLM-5.2 is narrowly ahead, not behind.
Where DeepSeek V4 adds coverage
DeepSeek V4 reports two coding benchmarks GLM-5.2 does not: SWE-bench Verified at 80.6 (a human-validated subset DeepSeek leans on heavily) and LiveCodeBench at 93.5, plus a 3206 Codeforces rating that, per third-party reviews, tops every model tested. This is genuinely valuable — it means DeepSeek V4 has been measured against more of the coding-evaluation surface area, which is a real form of confidence. But the correct interpretation is "broader verification coverage for DeepSeek," not "GLM-5.2 is unproven." GLM-5.2 has a published table; it simply chose a different, coding-and-reasoning-heavy set (Terminal-Bench 2.1, AIME 2026, MCP-Atlas, FrontierSWE). For how these Chinese open-weight models stack up against the best US alternative, see our look at NVIDIA Nemotron 3 Ultra.
Where GLM-5.2 adds coverage
Conversely, GLM-5.2 reports numbers DeepSeek V4 does not surface in the same way: Terminal-Bench 2.1 at 81.0 (82.7 on the best reported harness), which closes to within four points of Claude Opus 4.8's 85.0 on long-horizon terminal tasks, and a near-perfect AIME 2026 of 99.2 on competition mathematics. For agentic, multi-step terminal workflows, Terminal-Bench is one of the more predictive suites, and GLM-5.2's strength there matches its coding-agent positioning — the same edge it shows in our GLM-5.2 vs Kimi K2.7-Code comparison.
The caveat that applies to both
Every figure on this page comes from the vendors themselves. Neither GLM-5.2 nor DeepSeek V4 has, at the time of writing, a full independent third-party benchmark run that confirms these exact scores under a neutral harness. Self-reported numbers are routinely a few points optimistic across the industry, and benchmark contamination is a live concern for any model trained on web-scale data. We treat both leaderboards as vendor claims that point in the right direction rather than as settled, verified fact — and you should too.
Architecture: two different bets on efficiency
Both models are mixture-of-experts systems that activate only a fraction of their parameters per token, but they make different bets on how to scale efficiently, and those bets show up in cost and behavior.
GLM-5.2 is a 753 billion parameter MoE with roughly 40 billion parameters active per token. That is an aggressive sparsity ratio — only about five percent of the network fires on any given token — which is how Zhipu keeps inference cost defensible at a frontier-scale parameter count. Sparse activation is also part of why a flat monthly Coding Plan is economically viable for the vendor: the effective compute per request is far lower than the headline parameter count suggests. The trade-off of very sparse MoE is that routing quality matters enormously; when the router picks the right experts, output is excellent, and GLM-5.2's SWE-bench Pro and Terminal-Bench numbers suggest the routing is well tuned for coding.
DeepSeek V4 splits into two sizes and leans on an architectural innovation rather than sparsity alone. V4-Pro is a 1.6 trillion parameter MoE with 49 billion active; V4-Flash is a leaner 284 billion with 13 billion active. The headline is its Hybrid Attention architecture: DeepSeek combines Compressed Sparse Attention (around 4x compression) with Heavily Compressed Attention (up to 128x compression), which the vendor says cuts inference FLOPs to about 27 percent and KV cache to roughly 10 percent of the previous V3.2 generation. In practice that is the engine behind the aggressive pricing — DeepSeek can charge a fraction of competitors because its attention stack is genuinely cheaper to run at long context. It is also why DeepSeek could ship day-one inference on Huawei Ascend hardware: a lighter KV cache is far easier to fit on non-NVIDIA accelerators.
The practical upshot: GLM-5.2 buys efficiency through sparse expert activation and monetizes it as a flat plan, while DeepSeek V4 buys efficiency through a compressed attention stack and monetizes it as rock-bottom per-token pricing. Both are legitimate engineering paths to the same goal — frontier coding capability at a fraction of Western-model cost — and they explain why the pricing models differ so sharply.
Pricing comparison
Pricing is where this comparison stops being close. We pulled the current numbers directly from each vendor's pricing documentation rather than from summaries.
| Tier | Input (per M tokens) | Output (per M tokens) | Notes |
|---|---|---|---|
| DeepSeek V4-Flash | $0.14 (cache miss) | $0.28 | Cache hit input as low as $0.0028 per M tokens |
| DeepSeek V4-Pro | $0.435 (cache miss) | $0.87 | Cache hit input around $0.003625 per M tokens |
| GLM-5.2 (pay-per-token) | $1.40 | $4.40 | Hosted endpoint, China region |
| GLM-5.2 (GLM Coding Plan) | From about $18 per month, flat | Quota consumed at up to 3x during peak hours |
Read the metered rates carefully. Against GLM-5.2's $1.40 input and $4.40 output, DeepSeek V4-Flash is roughly ten times cheaper on input and sixteen times cheaper on output. Even DeepSeek V4-Pro — the bigger, stronger variant — undercuts GLM-5.2 by about three times on input and five times on output. For any workload measured in tens or hundreds of millions of tokens per month, that gap dwarfs the benchmark differences. DeepSeek's cache-hit pricing tilts it further: at $0.0028 per million input tokens on a cache hit, retrieval-augmented and tool-use loops with a stable system prompt are nearly free on the input side.
GLM-5.2's counter is predictability. The flat GLM Coding Plan from about $18 per month means heavy daily coders pay a fixed, knowable amount with no per-token math — and for a single developer hammering an agent all day, a flat plan can work out cheaper than metered tokens, even DeepSeek's cheap ones, once volume is high enough. The trade-off is the up-to-3x peak-hour quota multiplier and the lack of published pricing for the Pro, Max, and Team tiers, which makes heavier flat-plan usage harder to model upfront.
A worked cost model
Abstract per-token rates are hard to feel, so here is a concrete example. Imagine a small team running an agentic coding workload of 100 million input tokens and 20 million output tokens in a month — a realistic figure for a few engineers leaning hard on an AI agent across a large codebase.
- DeepSeek V4-Flash (cache miss): 100M input at $0.14 per M plus 20M output at $0.28 per M is about $14.00 plus $5.60, or roughly $19.60 for the month. With meaningful cache hits on a stable system prompt, the input side trends toward nearly free, pulling the total below $10.
- DeepSeek V4-Pro (cache miss): the same volume at $0.435 input and $0.87 output is about $43.50 plus $17.40, or roughly $60.90 for the month — the price of the stronger variant.
- GLM-5.2 (metered): 100M input at $1.40 per M plus 20M output at $4.40 per M is about $140.00 plus $88.00, or roughly $228.00 for the month.
- GLM-5.2 (Coding Plan): a flat fee from about $18 per month for that usage, subject to the plan's quota and peak-hour multipliers.
Two things jump out. First, metered against metered, DeepSeek V4-Flash is more than ten times cheaper than GLM-5.2 at this volume — the cost gap is not a rounding difference, it is an order of magnitude. Second, GLM-5.2's flat Coding Plan at about $18 is actually the cheapest line on the board for this scenario, which is exactly why the flat plan is GLM's real weapon: if your usage fits inside the plan's quota, you beat even DeepSeek's metered rate. The catch is the quota and peak-hour multipliers, which are not fully published, so heavy or bursty teams cannot model the flat plan's true ceiling with confidence. DeepSeek's metered pricing, by contrast, is fully transparent and scales linearly — you always know what the next million tokens will cost.
How we tested both
We ran both models through the same battery of tasks rather than reading off the leaderboards alone. Our setup: identical prompts, the same repository context loaded into each model's window, and the same coding agent (we used Claude Code as the harness, since GLM-5.2 advertises native support and DeepSeek V4 works through an OpenAI-compatible endpoint). We focused on three things that matter for day-to-day coding work and that benchmarks only partly capture.
Long-context repository reasoning. We loaded a mid-size repository — roughly 280K tokens of source — and asked each model to trace a bug across several files and propose a fix. Both genuinely used the long window; neither degraded into "lost in the middle" behavior the way 2025-era models did at this length. GLM-5.2 felt slightly more decisive at proposing a single coherent multi-file patch, which tracks with its SWE-bench Pro lead. DeepSeek V4 was marginally more conservative, asking clarifying questions before committing, which some teams will prefer.
Agentic, multi-step terminal tasks. We gave each model a containerized environment and a goal that required several shell steps — install dependencies, run a failing test suite, diagnose, patch, re-run. This is where GLM-5.2's Terminal-Bench positioning showed: it strung together longer autonomous sequences before needing a nudge. DeepSeek V4 handled the same tasks competently but with slightly more back-and-forth.
Cost under realistic load. The thing no leaderboard shows is what a week of real use costs. Running our test battery to completion, DeepSeek V4-Flash's bill was a rounding error next to GLM-5.2's metered rate — and on the runs that reused a stable system prompt, DeepSeek's cache-hit pricing made the input side effectively free. If you instead live inside a coding agent all day, GLM-5.2's flat plan removes the cost question entirely, which is its own kind of win.
The honest takeaway from hands-on use mirrors the benchmarks: GLM-5.2 edges the raw coding quality on the hardest agentic tasks, DeepSeek V4 wins decisively on cost, and for most teams the cost gap is the one that compounds month after month. We could not independently reproduce the vendors' exact benchmark scores, and we are not claiming to — our testing is directional, not a formal evaluation.
Winner by category
- Best for cost-sensitive, high-volume workloads: DeepSeek V4. The price advantage is not close, and it compounds with usage.
- Best for the strongest reported agentic coding capability: GLM-5.2. It leads the one head-to-head coding suite and the terminal-task benchmark.
- Best for predictable, flat monthly billing: GLM-5.2, via the GLM Coding Plan.
- Best for self-hosting and air-gapped deployment: DeepSeek V4. Day-one MIT weights and Huawei Ascend support; GLM-5.2's weights arrived a week later but are equally MIT.
- Best for the longest single generations: DeepSeek V4, at 384K max output versus 128K.
- Best for drop-in coding-agent integration: GLM-5.2, with explicit support across Claude Code, Cline, Kilo Code, OpenClaw, Goose, and Roo.
- Best for retrieval-augmented and tool-use loops: DeepSeek V4, thanks to its near-free cache-hit input pricing.
- Best for competition-math-adjacent reasoning: GLM-5.2, with a near-perfect 99.2 on AIME 2026.
Pros and cons of each model
GLM-5.2
Pros
- Leads the head-to-head SWE-bench Pro suite (62.1 vs 55.4) and posts 99.2 on AIME 2026.
- Flat-rate GLM Coding Plan from about $18 per month gives fully predictable cost.
- Explicit drop-in support across six major coding agents, including Claude Code and Cline.
- 1 million token context and 753B MoE with ~40B active for efficient inference.
- MIT-licensed weights — free commercial use, fine-tuning, and self-hosting.
Cons
- Roughly ten times more expensive on metered input than DeepSeek V4-Flash.
- Does not publish SWE-bench Verified or LiveCodeBench, so verified coverage is narrower.
- Downloadable weights arrived the week after launch, not day one.
- Pricing above the entry Coding Plan tier is unpublished, with up to 3x peak-hour quota.
- API hosted in China raises data-residency questions for regulated buyers.
DeepSeek V4
Pros
- Roughly ten times cheaper input and sixteen times cheaper output than GLM-5.2 (V4-Flash).
- Broadest verified coding coverage: 80.6 SWE-bench Verified, 93.5 LiveCodeBench, 3206 Codeforces.
- 384K max output — the longest single generations in this matchup.
- Day-one MIT weights plus Huawei Ascend inference for NVIDIA-free deployment.
- Near-free cache-hit input pricing makes RAG and tool-use loops almost cost-free.
Cons
- Trails GLM-5.2 on the one coding suite both vendors report (SWE-bench Pro 55.4 vs 62.1).
- No flat-rate subscription — heavy daily users cannot cap their spend.
- Local deployment needs serious hardware; V4-Pro FP16 wants enterprise GPU clusters.
- API hosted in China, with the same data-residency concerns for Western enterprise.
- Less explicitly tuned for drop-in coding-agent harnesses than GLM-5.2.
When to pick GLM-5.2 vs DeepSeek V4
Pick DeepSeek V4 when: your workload is measured in tens or hundreds of millions of tokens a month and cost is the dominant constraint; you want the broadest set of verified coding benchmarks behind your choice; you need 384K-token generations; you are building RAG or agentic tool-use loops where cache-hit pricing makes input nearly free; or you need to self-host on day one, including on Huawei Ascend hardware. For the majority of teams shipping production coding workloads at scale, this is the default pick. If you are instead weighing DeepSeek against a closed frontier model, see our Claude Fable 5 vs DeepSeek V4 comparison.
Pick GLM-5.2 when: you want the strongest reported agentic coding capability on the suites both vendors publish; you prefer a flat, predictable monthly bill over per-token metering and you code heavily enough that $18 per month beats metered usage; you live inside a coding agent like Claude Code, Cline, or Goose and want first-class, advertised integration; or your tasks lean toward long-horizon terminal automation and competition-math-style reasoning, where GLM-5.2's Terminal-Bench and AIME numbers are strongest.
If you are torn, the deciding question is simple: is your constraint cost at volume or peak coding capability with predictable billing? The first points to DeepSeek V4, the second to GLM-5.2. Both are MIT-licensed, both have 1M context, and both are hosted in China — so neither resolves the data-residency question for regulated Western enterprises without a hosted reseller.
What would change our verdict
We try to be explicit about the conditions under which we would flip this call, because a verdict you can falsify is more useful than one you cannot.
- Independent benchmarks land. If a neutral third-party harness verifies GLM-5.2's SWE-bench Pro 62.1 while DeepSeek V4's self-reported numbers come in materially lower under the same conditions, the capability gap would widen in GLM-5.2's favor and could outweigh price for quality-first teams.
- DeepSeek's discount window expires. DeepSeek V4-Pro has carried a heavy promotional discount; if metered rates step up substantially after the promotional period, the price advantage narrows — though V4-Flash would still undercut GLM-5.2's metered rate by a wide margin.
- GLM publishes full Coding Plan pricing. If Zhipu publishes transparent Pro, Max, and Team tier pricing and relaxes the peak-hour quota multipliers, the flat plan becomes far easier to recommend for heavy and bursty teams, strengthening GLM-5.2's value case.
- A Western-hosted endpoint appears. Both models are hosted in China today. A first-party or reputable reseller endpoint hosted in the US or EU would remove the single biggest blocker for regulated enterprise buyers and could shift either model from "self-host only" to "viable hosted choice" for those teams.
- Tooling maturity for self-hosting. If open-source inference frameworks ship clean, fast first-class support for one model well ahead of the other, that practical advantage could tip self-hosting decisions independent of the benchmark and price story.
Absent those changes, our read stands: DeepSeek V4 for cost at scale, GLM-5.2 for peak reported coding capability and predictable flat billing.
Final verdict
DeepSeek V4 is our overall pick for most teams, but we want to be precise about why, because the popular framing — "the model with more benchmarks wins" — gets this wrong. DeepSeek V4 wins on the two things that compound: price (roughly ten times cheaper on input, sixteen times on output than GLM-5.2, with near-free cache hits) and verified breadth (80.6 SWE-bench Verified and 93.5 LiveCodeBench that GLM-5.2 does not report). It also wins on max output length and day-one self-hosting. At any serious token volume, that cost gap dwarfs everything else.
But GLM-5.2 is not the runner-up on capability — on the apples-to-apples ground, it is ahead. It leads SWE-bench Pro 62.1 to 55.4, the one coding suite both labs publish, ties GPQA Diamond, and tops the field on Terminal-Bench-style long-horizon tasks and AIME 2026 math. Add its flat-rate GLM Coding Plan and its first-class coding-agent integration, and GLM-5.2 is the better choice for a heavy individual coder who values predictable billing and peak agentic quality over raw per-token cost.
So the verdict is genuinely split: DeepSeek V4 for cost-at-scale, GLM-5.2 for peak reported coding capability and flat billing. We give the overall nod to DeepSeek V4 because price is the constraint that bites every month for most teams — but if your bottleneck is coding quality on the hardest agentic suites, GLM-5.2 has the stronger published numbers. And once more, for both: every benchmark here is vendor self-reported and awaiting independent verification.

Frequently asked questions
Is GLM-5.2 or DeepSeek V4 better for coding?
On the one coding suite both vendors publish, SWE-bench Pro, GLM-5.2 leads with a self-reported 62.1 against DeepSeek V4's 55.4. DeepSeek V4 reports broader coverage — 80.6 SWE-bench Verified and 93.5 LiveCodeBench — that GLM-5.2 does not surface. So GLM-5.2 has the stronger head-to-head coding number, while DeepSeek V4 has been measured against more benchmarks. All figures are vendor self-reported.
Which is cheaper, GLM-5.2 or DeepSeek V4?
DeepSeek V4 is dramatically cheaper. V4-Flash costs $0.14 per million input tokens and $0.28 output, versus GLM-5.2's $1.40 input and $4.40 output — roughly ten times cheaper on input and sixteen times on output. Even DeepSeek V4-Pro undercuts GLM-5.2 about three to five times. GLM-5.2's counter is a flat GLM Coding Plan from about $18 per month for predictable billing.
Did GLM-5.2 actually publish benchmark numbers?
Yes. Zhipu published an official benchmark table alongside the mid-June 2026 release on z.ai and Hugging Face: SWE-bench Pro 62.1, Terminal-Bench 2.1 81.0 (82.7 best harness), AIME 2026 99.2, GPQA Diamond 91.2, and HLE with tools 54.7, among others. It simply chose a coding-and-reasoning-heavy suite rather than SWE-bench Verified or LiveCodeBench. The numbers are vendor self-reported.
Are GLM-5.2 and DeepSeek V4 benchmarks independently verified?
No. At the time of writing, both leaderboards are vendor self-reported and have not been confirmed by a neutral third-party harness. Self-reported scores across the industry tend to run a few points optimistic, and benchmark contamination is a live concern. Treat both tables as directional vendor claims rather than settled fact.
Are both models really open source?
Both ship their weights under an MIT license, which permits free commercial use, redistribution, fine-tuning, and self-hosting. But neither releases its full training code and data recipe, so they are open-weight rather than fully open-source — the community cannot reproduce the training run from scratch. DeepSeek V4 released weights on day one; GLM-5.2's downloadable weights arrived the week after launch.
What is the context window and max output of each?
Both have a 1 million token context window. On output, DeepSeek V4 leads with a 384K max output ceiling, while GLM-5.2 maxes at 128K (131K in Claude Code tests). For tasks that generate very long single responses — large refactors, full document drafts — DeepSeek V4's longer output ceiling is the practical advantage.
Can I self-host GLM-5.2 and DeepSeek V4?
Yes, both are MIT-licensed and downloadable. DeepSeek V4 shipped day-one weights and Huawei Ascend inference, removing NVIDIA dependency for compatible deployments; V4-Flash (284B/13B active) needs INT4 or INT8 quantization to fit a single high-end GPU, while V4-Pro FP16 wants enterprise clusters. GLM-5.2's 753B MoE weights arrived the week after launch and also require substantial hardware for full-precision serving.
Which model works better with coding agents like Claude Code?
GLM-5.2 advertises explicit drop-in support for Claude Code, Cline, Kilo Code, OpenClaw, Goose, and Roo, which makes it the easier swap into an existing agentic workflow. DeepSeek V4 works through an OpenAI-compatible endpoint and integrates broadly, but it is less explicitly tuned for these specific coding-agent harnesses. For agent-first workflows, GLM-5.2 has the smoother path.
Do GLM-5.2 and DeepSeek V4 have data-residency concerns?
Both APIs are hosted in China, which raises data-residency and compliance questions for regulated Western buyers such as US Federal or EU healthcare. Self-hosting the MIT-licensed weights sidesteps the API entirely and is the usual path for organizations with strict residency requirements. Neither vendor offers a first-party Western-hosted endpoint, so a third-party reseller is typically required for hosted use under those constraints.
Should I choose DeepSeek V4 or GLM-5.2 for a production startup?
For most production startups shipping at volume, DeepSeek V4 is the default because the cost advantage compounds every month and its verified-benchmark breadth gives broad confidence. Choose GLM-5.2 instead if a single heavy coder's predictable flat bill matters more than per-token cost, if you want the strongest reported agentic coding capability, or if first-class coding-agent integration is central to your workflow.
What is the overall verdict on GLM-5.2 vs DeepSeek V4?
It is a close, split decision. DeepSeek V4 takes the overall pick because price is decisive at volume — roughly ten times cheaper input, sixteen times cheaper output — and it adds the broadest verified coding coverage. GLM-5.2 wins the one head-to-head coding suite (SWE-bench Pro 62.1 vs 55.4), ties GPQA Diamond, and offers flat-rate billing plus deeper coding-agent integration. Pick on your constraint: cost at scale points to DeepSeek V4, peak reported coding capability with predictable billing points to GLM-5.2.
Last compared: June 2026. All pricing and benchmark figures were pulled directly from vendor sources (z.ai and Hugging Face for GLM-5.2; deepseek.com and api-docs.deepseek.com for DeepSeek V4) and are vendor self-reported. This comparison contains no affiliate links.
Our Verdict
DeepSeek V4 takes the overall pick for most teams because its price is decisive at volume — V4-Flash runs at roughly one-tenth the input cost and one-sixteenth the output cost of GLM-5.2 — and it backs that with the broadest verified coding coverage (80.6 SWE-bench Verified, 93.5 LiveCodeBench). But this is a close, split decision, not a blowout: GLM-5.2 actually leads on the one suite both vendors report, SWE-bench Pro (62.1 vs 55.4), essentially ties on GPQA Diamond (91.2 vs 90.1), and wins on predictable flat-rate billing through the GLM Coding Plan plus a deeper coding-agent ecosystem. Pick DeepSeek V4 when token volume and raw cost dominate; pick GLM-5.2 when you want the strongest reported agentic coding capability, a flat monthly bill, and tight Claude Code / Cline integration. All benchmark figures here are vendor self-reported and not yet independently verified.
Choose GLM-5.2
Zhipu AI open-weight coding flagship: 753B MoE (~40B active), 1M context, MIT license, headline SWE-bench Pro 62.1 (vendor self-reported); GLM Coding Plan from around $18 per month or $1.40 in / $4.40 out per million tokens.
Try GLM-5.2 →Choose DeepSeek V4
Chinese open-source flagship: 1.6T MoE (49B active), 1M context, 80.6% SWE-bench Verified, MIT license — at one-fifth the price of Claude Opus 4.7
Try DeepSeek V4 →Frequently Asked Questions
Is GLM-5.2 better than DeepSeek V4?
DeepSeek V4 takes the overall pick for most teams because its price is decisive at volume — V4-Flash runs at roughly one-tenth the input cost and one-sixteenth the output cost of GLM-5.2 — and it backs that with the broadest verified coding coverage (80.6 SWE-bench Verified, 93.5 LiveCodeBench). But this is a close, split decision, not a blowout: GLM-5.2 actually leads on the one suite both vendors report, SWE-bench Pro (62.1 vs 55.4), essentially ties on GPQA Diamond (91.2 vs 90.1), and wins on predictable flat-rate billing through the GLM Coding Plan plus a deeper coding-agent ecosystem. Pick DeepSeek V4 when token volume and raw cost dominate; pick GLM-5.2 when you want the strongest reported agentic coding capability, a flat monthly bill, and tight Claude Code / Cline integration. All benchmark figures here are vendor self-reported and not yet independently verified.
Which is cheaper, GLM-5.2 or DeepSeek V4?
GLM-5.2 is priced at $1.4 in / $4.4 out per M tokens. DeepSeek V4 is priced at $0.14 in / $0.28 out per M tokens (free plan available). Check the pricing comparison section above for a full breakdown.
What are the main differences between GLM-5.2 and DeepSeek V4?
The key differences span across 15 features we compared. For SWE-bench Pro (head-to-head, both vendors report), GLM-5.2 offers 62.1 while DeepSeek V4 offers 55.4. For GPQA Diamond, GLM-5.2 offers 91.2 while DeepSeek V4 offers 90.1. For SWE-bench Verified, GLM-5.2 offers Not reported while DeepSeek V4 offers 80.6. See the full feature comparison table above for all details.