Claude Fable 5 vs DeepSeek V4: Peak Closed Frontier vs Ultra-Cheap Open MIT (2026)


Fable 5 tops the Artificial Analysis index by a wide margin — but its output costs ~178x more than DeepSeek V4-Flash. Open MIT vs closed frontier: split verdict.

Feature Comparison
| Feature | Claude Fable 5 | DeepSeek V4 |
|---|---|---|
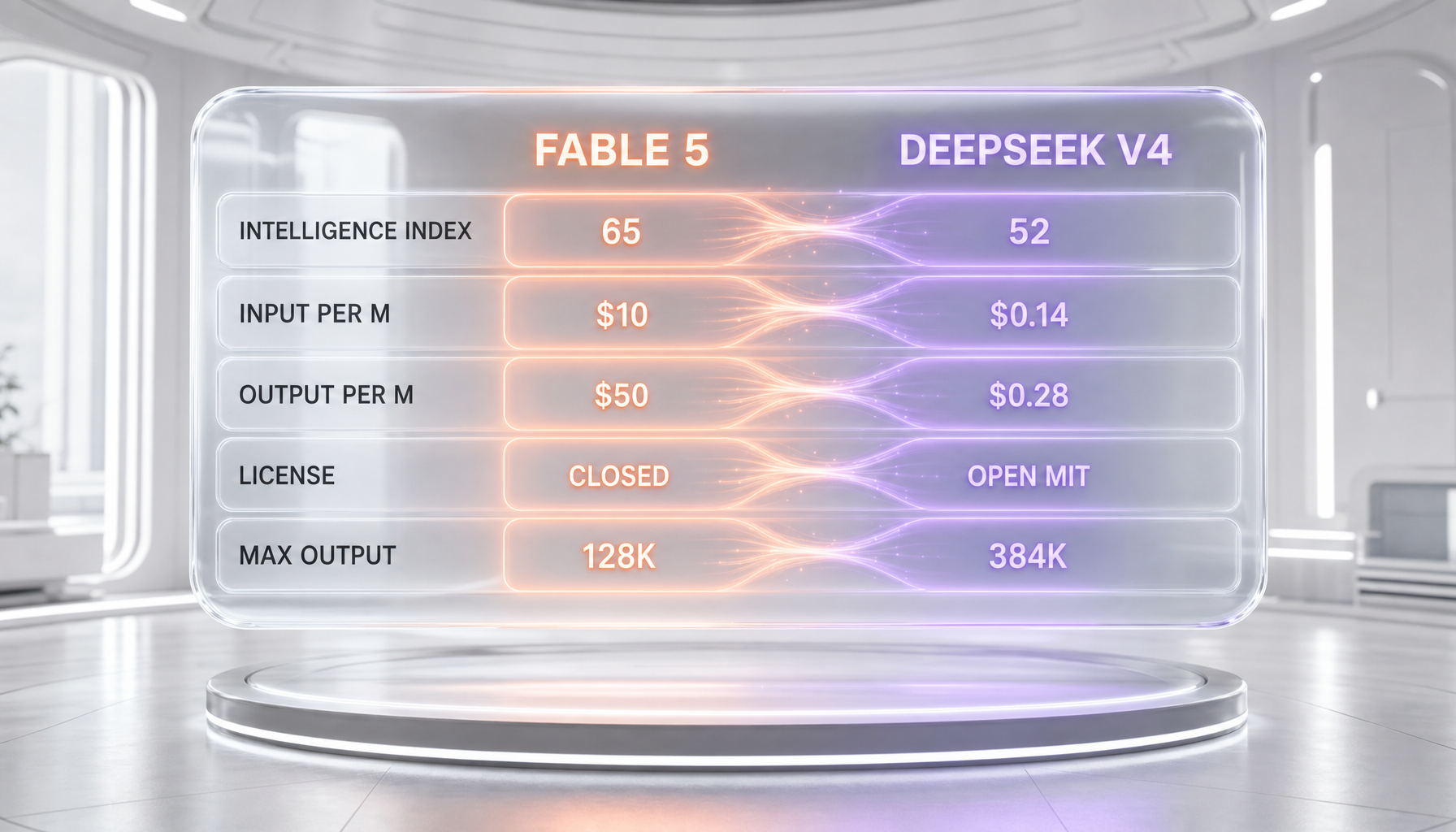
| AA Intelligence Index (Artificial Analysis, same evaluator) | 65, ranked number one of 152 | 52 (V4-Pro, max reasoning) |
| Agentic coding benchmark | Roughly 80.3% SWE-bench Pro, the harder track (early third-party) | 80.6% SWE-bench Verified, the standard track (DeepSeek reports) |
| GDPval-AA Elo (agentic knowledge work) | 1932 (Artificial Analysis) | Not listed |
| Input price (per million tokens) | $10.00 (verified) | Flash $0.14, Pro $0.435 (verified) |
| Output price (per million tokens) | $50.00 (verified) | Flash $0.28, Pro $0.87 (verified) |
| License / openness | Closed, API and cloud only | Open weights, MIT license |
| Self-hostable | No | Yes, incl. Huawei Ascend |
| Context window | 1,000,000 tokens (verified) | 1,000,000 tokens (verified) |
| Max output tokens | 128K | 384K |
| Zero-data-retention option | No (Covered Model, 30-day retention) | Yes, via self-hosting |
| Managed Western compliance | US-hosted, plus AWS, Vertex AI, Microsoft Foundry | China-hosted API (or self-host) |
| Refusal handling | Documented refusals with automatic Opus 4.8 fallback, refused requests not billed | Deployment-defined: hosted moderation or self-managed policy |
Pricing Comparison
Claude Fable 5
DeepSeek V4
Detailed Comparison
Claude Fable 5 and DeepSeek V4 mark the two extremes of frontier AI in 2026. Claude Fable 5 is Anthropic's most capable widely released model, generally available since June 9, 2026, closed and API-only, priced at 10 dollars per million input tokens and 50 dollars per million output tokens, with a 1,000,000-token context window, always-on adaptive thinking, and an optional fallback to Claude Opus 4.8 when its safety classifiers decline a request. DeepSeek V4 is the Chinese open-weight flagship, MIT-licensed on Hugging Face, with hosted pricing from 0.14 dollars input and 0.28 dollars output per million tokens — which makes Fable 5's output roughly 178 times more expensive. On the Artificial Analysis Intelligence Index, the one independent evaluator scoring both, Fable 5 ranks number one of 152 models, leading the index by a wide margin while DeepSeek V4-Pro trails well behind. Best for maximum capability, agentic coding, and US-hosted compliance: Claude Fable 5. Best for cost, open weights, and self-hosting: DeepSeek V4.
Quick Verdict
This is a split verdict by use case — and the split here is wider than any matchup we have published. We put Claude Fable 5 into our own production stack the day it went generally available, we have run DeepSeek V4 through its hosted API since spring, and we pulled every price below directly from each vendor's own pages in June 2026. These two models are not fighting for the same budget line. One is the most expensive widely available frontier API on the market; the other is the cheapest hosted flagship we track, and you can download its weights for free. Here is the short version.
- Best for raw frontier capability: Claude Fable 5. It tops the Artificial Analysis Intelligence Index — ranked number one of 152 models — while DeepSeek V4-Pro in maximum reasoning mode ranks well behind.
- Best for agentic coding: Claude Fable 5. Early third-party trackers put it at roughly 80.3 percent on SWE-bench Pro, the harder coding benchmark, far ahead of Claude Opus 4.8 at 69.2 percent. DeepSeek reports 80.6 percent on the easier SWE-bench Verified track — a strong number, but not the same test.
- Best for cost: DeepSeek V4, by the widest margin in frontier AI. V4-Flash output at 0.28 dollars per million tokens is roughly 178 times cheaper than Fable 5 output at 50 dollars. Even V4-Pro at 0.87 dollars is about 57 times cheaper.
- Best for open weights and self-hosting: DeepSeek V4. The weights ship under an MIT license and run on your own hardware, including Huawei Ascend chips. Fable 5 is closed, API-only, and cannot be self-hosted.
- Best for US-hosted compliance: Claude Fable 5 — with one caveat. It is a designated Covered Model with mandatory 30-day data retention and no zero-data-retention option, so buyers who need absolute data control may actually be pushed toward self-hosting DeepSeek V4.
Bottom line: if your workload needs the strongest widely available model — and each call is valuable enough to justify 50 dollars per million output tokens — Claude Fable 5 is the pick. If token cost, open weights, or data sovereignty drive your decision, DeepSeek V4 delivers a remarkable share of frontier quality at a price that changes what is buildable. We did not crown a single winner, because at a 178-times price gap the use case decides everything.
At a Glance
Before the detail, here is the side-by-side that frames everything below. All pricing in this table was fetched directly from each vendor's own pages in June 2026. Every benchmark figure is attributed to its source.
| Dimension | Claude Fable 5 | DeepSeek V4 |
|---|---|---|
| Vendor / origin | Anthropic (US) | DeepSeek (China) |
| License | Closed, API and cloud only | Open weights, MIT license |
| Released | June 9, 2026 (GA) | April 2026 |
| Input price (per million tokens) | $10 (verified) | Flash $0.14, Pro $0.435 (verified) |
| Output price (per million tokens) | $50 (verified) | Flash $0.28, Pro $0.87 (verified) |
| Cache-hit input (per million tokens) | Not broken out at launch | Flash $0.0028, Pro $0.003625 (verified) |
| Context window | 1,000,000 tokens (verified) | 1,000,000 tokens (verified) |
| Max output | 128K tokens | 384K tokens |
| AA Intelligence Index | Number one of 152, leads by a wide margin (Artificial Analysis) | Trails well behind for V4-Pro max reasoning (Artificial Analysis) |
| Agentic coding | Roughly 80.3 percent SWE-bench Pro (early third-party) | 80.6 percent SWE-bench Verified (DeepSeek reports) |
| Thinking | Adaptive thinking, always on | Three modes: Non-Think, Think High, Think Max |
| Self-hostable | No | Yes, including Huawei Ascend chips |
| Data retention | Covered Model: 30-day retention, no zero-data-retention option | China-hosted API, or self-host with full control |
Overview of Each Model
Claude Fable 5
Claude Fable 5 is Anthropic's most capable widely released model, generally available since June 9, 2026 on the Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry. It sits a full tier above Claude Opus 4.8 — Anthropic's Opus-tier flagship — and is priced accordingly at 10 dollars per million input tokens and 50 dollars per million output tokens, double Opus 4.8 on both sides. The spec sheet is built for long-horizon agentic work: a 1,000,000-token context window, up to 128K output tokens per request, and adaptive thinking that is always on — it is the only thinking mode the model supports, with an effort parameter to control depth. On the Artificial Analysis Intelligence Index it debuted at number one of 152 models, leading the composite by a wide margin, and early third-party trackers report roughly 80.3 percent on SWE-bench Pro, a result that towers over every other model on that harder benchmark. Two design choices define it beyond raw capability. First, safety classifiers can decline certain requests, and the API ships a fallback mechanism that can retry a refused request on Claude Opus 4.8 automatically. Second, it is a designated Covered Model carrying 30-day data retention with no zero-data-retention option. It is closed and cannot be self-hosted. For the full breakdown, see our Claude Fable 5 review.
DeepSeek V4
DeepSeek V4 is the Chinese open-weight flagship, shipped in April 2026 in two sizes: V4-Pro, a 1.6-trillion-parameter mixture-of-experts model with about 49 billion parameters active per token, and V4-Flash, a 284-billion-parameter model with about 13 billion active. Both carry a 1,000,000-token context window with up to 384K tokens of output — three times Fable 5's ceiling — and both ship their weights under an MIT license on Hugging Face that permits free commercial use, redistribution, and modification. The training code and data recipe are not released, so this is open weights rather than fully open source. DeepSeek reports 80.6 percent on SWE-bench Verified for V4-Pro, and Artificial Analysis ranks V4-Pro well behind the leaders on its Intelligence Index in maximum reasoning mode. The engineering is what makes the price possible: a Hybrid Attention design pairing Compressed Sparse Attention with Heavily Compressed Attention slashes inference compute and KV-cache footprint, three built-in thinking modes let you dial cost against quality per request, and the model runs day-one on Huawei Ascend hardware. The hosted API is OpenAI-compatible and absurdly cheap — V4-Flash output costs 0.28 dollars per million tokens, and cache-hit input is 0.0028 dollars. DeepSeek is also consolidating its lineup around this generation: the older deepseek-chat and deepseek-reasoner endpoints retire on July 24, 2026, with V4-Flash replacing both. Our full DeepSeek V4 review covers the architecture and licensing in depth.
Pricing Compared: The Widest Gap in Frontier AI
We have compared a lot of models on this site, and no matchup comes close to this price spread. Every number below was fetched directly from each vendor's own pricing pages in June 2026 — Anthropic's model documentation for Fable 5, DeepSeek's API pricing docs for V4.
| Tier | Input (per million tokens) | Output (per million tokens) | Cache-hit input (per million tokens) |
|---|---|---|---|
| Claude Fable 5 | $10.00 | $50.00 | Not broken out at launch |
| DeepSeek V4-Pro | $0.435 | $0.87 | $0.003625 |
| DeepSeek V4-Flash | $0.14 | $0.28 | $0.0028 |
Run the arithmetic and the numbers stop feeling like a comparison and start feeling like a category error. On output tokens — the line that dominates real agentic spend — Fable 5 at 50 dollars is roughly 178 times the cost of V4-Flash at 0.28 dollars, and about 57 times the cost of V4-Pro at 0.87 dollars. On input, Fable 5 at 10 dollars runs about 71 times V4-Flash and about 23 times V4-Pro. For context, when we compared Claude Opus 4.8 against DeepSeek V4 the gap was roughly 90 times; Fable 5 doubles Opus pricing and pushes the spread to the widest we have ever measured between two current frontier models.
Two nuances keep this honest. First, Fable 5 uses the tokenizer Anthropic introduced with Opus 4.7, which produces roughly 30 percent more tokens for the same text than older Claude tokenizers — so the effective cost per word of the work you send it can run higher than the sticker price suggests. Second, there is a small mercy in the billing design: when Fable 5's safety classifiers refuse a request before any output is generated, you are not billed for it, and Anthropic's fallback credit refunds the prompt-cache cost of retrying on another model. Thoughtful — but it does not move the needle on a 178-times gap.
On DeepSeek's side, the fine print is almost comically favorable. Cache-hit input at 0.0028 dollars per million tokens means a stable system prompt in a tool loop costs effectively nothing, and the 384K output ceiling means you are not forced to paginate long generations. The one honest caveat: self-hosting the weights is free in license terms but not in hardware — full-precision V4-Pro needs enterprise GPU clusters, and even V4-Flash wants quantization to fit a single high-end card. For most teams the hosted API is the relevant price, and that price is two orders of magnitude under Fable 5.
Benchmarks Compared
Cross-lab benchmark comparisons are a minefield, and this one has an extra trap: the two vendors report different coding benchmarks that look interchangeable but are not. We discipline this the same way we always do — lean on the one independent evaluator that scores both models with the same battery, attribute everything else, and refuse to fill blanks with guesses.
| Benchmark | Claude Fable 5 | DeepSeek V4 | Like-for-like? |
|---|---|---|---|
| AA Intelligence Index (Artificial Analysis) | Number one of 152, leads by a wide margin | Well behind (V4-Pro, max reasoning) | Yes — same evaluator |
| SWE-bench Pro (harder agentic coding) | Roughly 80.3 percent (early third-party) | Not reported | No counterpart |
| SWE-bench Verified (standard agentic coding) | Not reported separately at launch | 80.6 percent (DeepSeek reports) | No counterpart |
| GDPval-AA Elo (agentic knowledge work) | 1932 (Artificial Analysis) | Not listed | No counterpart |
| Output speed (Artificial Analysis) | 59.4 tokens per second | Not listed comparably | No clean counterpart |
The cleanest signal is the Artificial Analysis Intelligence Index, because it is one evaluator running one battery on both models: Claude Fable 5 holds the number-one rank of 152 models and leads by a wide margin, while DeepSeek V4-Pro in maximum reasoning mode ranks well behind. Worth noting for fairness in both directions: Artificial Analysis evaluates Fable 5 in its maximum-effort configuration with the Opus 4.8 fallback enabled, so the number reflects the model as Anthropic intends it to be deployed, safety net included.
Now the coding trap. DeepSeek's 80.6 percent and Fable 5's roughly 80.3 percent look like a photo finish — until you notice they are different tests. DeepSeek reports SWE-bench Verified; Fable 5's figure is SWE-bench Pro, a substantially harder benchmark on which Claude Opus 4.8 — itself the previous leader — scores 69.2 percent, GPT-5.5 scores 58.6 percent, and Gemini 3.1 Pro scores 54.2 percent, per the same early third-party trackers. Scoring 80.3 percent on Pro is a dramatically stronger result than 80.6 percent on Verified. We flag this explicitly because we expect plenty of lazier comparisons to put those two numbers side by side as if they were equivalent. They are not, and the honest reading is that Fable 5 is meaningfully ahead on agentic coding.
On GDPval-AA, Artificial Analysis's Elo-style track for agentic knowledge work, Fable 5 posts 1932 — ahead of Claude Opus 4.8 at 1890 and GPT-5.5 at 1769. DeepSeek V4 is not listed on that track, so we leave the cell blank rather than invent a head-to-head. One genuine weakness in Fable 5's column: latency. Artificial Analysis measures time to first token at roughly 95 seconds in the max-effort configuration it tests, because adaptive thinking is always on and cannot be disabled. This is a model that thinks before it speaks, every time, and you pay for that in seconds as well as dollars.
Architecture and Design Philosophy
Strip away the pricing and you find two opposite theories of what a frontier model should be.
Claude Fable 5 is closed, so Anthropic discloses behavior rather than internals — and the disclosed behavior is distinctive. Adaptive thinking is the only mode the model supports: it applies whenever the thinking parameter is unset, disabling it is not supported, and depth is steered through an effort parameter rather than a token budget. The raw chain of thought is never returned — by default thinking blocks come back empty, with a summarized view available on request — which matters if your tooling expects to inspect reasoning traces. At launch it supports Anthropic's full agentic toolkit: task budgets, the memory tool, context editing, compaction, and vision. The model is positioned explicitly for the most demanding reasoning and long-horizon agentic work, and our early hands-on use backs the positioning: it plans more carefully than Opus 4.8, holds long multi-step tasks together with fewer dropped threads, and verifies its own work before declaring it done.
DeepSeek V4 is the opposite philosophy — radical transparency at the architecture level, because the weights and a technical report are public. It is a mixture-of-experts family trained on roughly 33 trillion tokens: V4-Pro at 1.6 trillion total parameters with about 49 billion active per token, V4-Flash at 284 billion with about 13 billion active. The headline innovation is Hybrid Attention — Compressed Sparse Attention at four-times compression combined with Heavily Compressed Attention at 128-times compression — which is what makes a 1,000,000-token context affordable to serve at these prices. It swaps AdamW for the Muon optimizer, serves experts in FP4 with most other weights in FP8, and bakes three reasoning modes directly into the model: Non-Think for cheap fast calls, Think High, and Think Max for the hardest problems. Where Fable 5 gives you one always-on thinking behavior tuned by Anthropic, DeepSeek hands you the dial.
The practical upshot: Fable 5 is a sealed, self-verifying premium agent you rent; DeepSeek V4 is an inspectable, movable engine you can own. Neither philosophy is wrong. They price risk and control in opposite directions.
The Refusal Question and the Opus 4.8 Safety Net
Fable 5 ships with something no other frontier model has: an institutionalized plan B. Its safety classifiers can decline certain requests — early coverage notes they concentrate on areas like cybersecurity, biology, chemistry, and model distillation — and when that happens the Messages API does not throw an error. It returns a successful response with a refusal stop reason and tells you which classifier declined. From there, Anthropic built a paved road: a fallbacks parameter, in beta on the Claude API and Claude Platform on AWS, retries the request server-side on another Claude model — typically Claude Opus 4.8 — and SDK middleware for TypeScript, Python, Go, Java, and C# does the same client-side on any platform. You are not billed for a request refused before output, and a fallback credit refunds the prompt-cache cost of the switch.
We read this two ways, and both seem true. Charitably: it is the most honest refusal design we have seen — refusals are explicit, machine-readable, and recoverable, instead of silent quality degradation. Skeptically: it is an admission that the strongest publicly available model will sometimes decline work that its own sibling will then perform, and your architecture has to account for that. Anthropic is transparent about the structure: Claude Mythos 5, a restricted variant that shares Fable 5's capabilities without the safety classifiers, exists for approved customers in Project Glasswing — invitation-only, no self-serve access. The model you can buy is the classifier-wrapped one.
DeepSeek V4's answer to all of this is simpler: it is an open-weight model, and what it will or will not do is ultimately a deployment decision. The hosted API applies DeepSeek's own moderation; self-hosters control their own policy stack. For some buyers that flexibility is the entire point. For others — particularly anyone operating under Western compliance regimes — a vendor-managed safety layer with documented refusal semantics is a feature they would rather not own themselves.
Data Retention, Sovereignty, and Compliance
This is the section where the usual closed-versus-open story gets genuinely interesting, because Fable 5 carries a compliance wrinkle its own predecessors do not.
Claude Fable 5 is a designated Covered Model. Concretely: API traffic to it carries 30-day data retention, and it is not available under zero-data-retention agreements. For most teams that is a footnote. For a specific class of buyer — legal, defense-adjacent, anyone whose contracts mandate zero retention — it is disqualifying, and those teams cannot simply pay more to make it go away. Claude Opus 4.8, one tier down, remains the strongest Anthropic model available under standard retention arrangements. Beyond that wrinkle, Fable 5's compliance story is the familiar strong one: US-hosted by Anthropic, available through AWS, Vertex AI, and Microsoft Foundry, from a US vendor with mature enterprise paperwork.
DeepSeek V4 splits into two completely different compliance profiles. The hosted API runs in China, which is a hard stop for US Federal work, much of EU healthcare, and plenty of corporate policies regardless of how good the price is. The MIT-licensed weights invert that completely: self-host V4 on your own infrastructure and no token ever leaves your network — a stronger data-control posture than any closed API can offer, including Fable 5's. The strange punchline of this matchup is that the premium closed model is the one with a mandatory retention window, while the ultra-cheap open model is the one that can guarantee zero retention — provided you bring your own GPUs and own your own safety stack.
Total Cost of Ownership
Per-token prices are abstract until you multiply them by a real workload, so here is the arithmetic that decides architectures. A pipeline producing one billion output tokens a month costs about 50,000 dollars on Claude Fable 5 at list price. The same volume costs roughly 870 dollars on DeepSeek V4-Pro and about 280 dollars on V4-Flash. That is not a budgeting difference; it is the difference between a workload that needs a vice-president's signature and one that fits on a team card. Add the tokenizer effect — roughly 30 percent more tokens for the same text than older Claude tokenizers — and Fable 5's effective cost per unit of work stretches further still.
The self-hosted path changes the units rather than the conclusion. DeepSeek's weights are free under MIT, but full-precision V4-Pro demands enterprise GPU clusters, and V4-Flash needs INT4 or INT8 quantization to run on a single high-end card. Self-hosting trades the API meter for capital expenditure, MLOps headcount, and your own safety and moderation stack. It pays off for steady, very-high-volume workloads and for organizations where data sovereignty is non-negotiable; it does not pay off for spiky or modest usage, where the hosted API — still two orders of magnitude under Fable 5 — is the rational baseline.
The pattern we expect most sophisticated teams to land on is not either-or. It is routing: Fable 5 for the small fraction of tasks where being right the first time is worth 50 dollars per million tokens — deep multi-file refactors, high-stakes reasoning, long-horizon agent runs — and DeepSeek V4 for the bulk tier underneath, where 0.28 dollars per million output tokens makes near-unlimited iteration free in practice. At a 178-times spread, even routing 5 percent of traffic to the premium model and 95 percent to the cheap one keeps total spend under a tenth of an all-Fable bill.
How We Tested
Honesty about methodology matters most in exactly this kind of cross-lab, cross-country comparison, so here is precisely what is hands-on and what is research, as of June 10, 2026.
We moved Claude Fable 5 into our own production stack on launch day, June 9, 2026 — including the agentic coding and content workflows where we previously ran Claude Opus 4.8 daily — so our observations about its planning depth, self-verification, and latency are first-hand but early: one day of production use at the time of writing, not weeks. We have run DeepSeek V4 through its hosted API since spring on coding and reasoning prompts, including all three thinking modes, but we have not stood up a self-hosted V4 cluster. We have not yet run weeks of controlled, identical-task benchmarking of these two models against each other. For that reason, every number in this piece is attributed: Artificial Analysis for the Intelligence Index, GDPval-AA, and speed figures; early third-party benchmark trackers for Fable 5's SWE-bench Pro result; DeepSeek's own reporting for SWE-bench Verified. All pricing was fetched directly from Anthropic's model documentation and DeepSeek's API pricing docs in June 2026 — never from secondhand summaries. Where a like-for-like number does not exist, the cell says so.
Winner by Category
A single overall winner would be dishonest at a 178-times price gap, because the two models answer different questions. Here is who wins what.
- Best for raw frontier capability: Claude Fable 5. Number one of 152 on the Artificial Analysis Intelligence Index, leading by a wide margin, while DeepSeek V4-Pro trails well behind.
- Best for agentic coding: Claude Fable 5. Roughly 80.3 percent on SWE-bench Pro per early third-party trackers — a harder test than the SWE-bench Verified track where DeepSeek reports 80.6 percent.
- Best for agentic knowledge work: Claude Fable 5. GDPval-AA Elo of 1932 on Artificial Analysis, ahead of Opus 4.8 at 1890; DeepSeek is not listed on that track.
- Best for cost: DeepSeek V4, overwhelmingly. Roughly 178 times cheaper on output against V4-Flash, and about 57 times against V4-Pro.
- Best for open weights and self-hosting: DeepSeek V4. MIT-licensed downloadable weights with Huawei Ascend support; Fable 5 cannot be self-hosted at all.
- Best for managed Western compliance: Claude Fable 5 — US-hosted with AWS, Vertex AI, and Microsoft Foundry options — though its Covered Model status means 30-day retention with no zero-retention option.
- Best for absolute data control: DeepSeek V4, self-hosted. No closed API, Fable 5 included, can match weights running entirely inside your own network.
- Best for long outputs: DeepSeek V4. A 384K output ceiling versus 128K for Fable 5; both carry a 1,000,000-token context window.
- Best for latency-sensitive work: DeepSeek V4 with thinking off. Fable 5's always-on adaptive thinking pushes time to first token to roughly 95 seconds in the max-effort configuration Artificial Analysis tests; V4's Non-Think mode answers fast and cheap.
Pros and Cons
Claude Fable 5 — Pros
- The most capable widely released model on the market: number one of 152 on the Artificial Analysis Intelligence Index, leading by a wide margin.
- Dominant agentic coding: roughly 80.3 percent on SWE-bench Pro per early third-party trackers, far ahead of Opus 4.8's 69.2 percent on the same test.
- Leads agentic knowledge work with a 1932 GDPval-AA Elo on Artificial Analysis.
- 1,000,000-token context window with always-on adaptive thinking and effort control built for long-horizon agent runs.
- Documented refusal semantics with an automatic fallback to Claude Opus 4.8, refusal-before-output requests not billed, and fallback credit on the switch.
- US-hosted with availability across the Claude API, AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry from day one.
Claude Fable 5 — Cons
- The most expensive widely available frontier API: 10 dollars input and 50 dollars output per million tokens — roughly 178 times DeepSeek V4-Flash on output.
- Closed and API-only: no weights, no self-hosting, no sovereignty option.
- Covered Model status imposes 30-day data retention with no zero-data-retention option at any price.
- Always-on adaptive thinking cannot be disabled, and time to first token runs roughly 95 seconds in the max-effort configuration Artificial Analysis tests.
- Safety classifiers will decline some legitimate-adjacent work, and the launch-day SWE-bench Pro figure is early and third-party rather than independently settled.
- The Opus 4.7-generation tokenizer produces roughly 30 percent more tokens for the same text, inflating effective cost beyond the sticker price.
DeepSeek V4 — Pros
- The cheapest hosted flagship we track: V4-Flash at 0.14 dollars input and 0.28 dollars output per million tokens, with cache hits at 0.0028 dollars.
- MIT-licensed open weights on Hugging Face — free commercial use, redistribution, fine-tuning, and self-hosting.
- Strong real-world coding at a reported 80.6 percent SWE-bench Verified, within striking distance of closed flagships costing two orders of magnitude more.
- 1,000,000-token context with a 384K output ceiling, three times Fable 5's maximum output.
- Three built-in thinking modes — Non-Think, Think High, Think Max — let you tune cost against quality per request.
- Day-one Huawei Ascend support and an OpenAI-compatible API remove both chip and integration lock-in.
DeepSeek V4 — Cons
- Trails Fable 5 by a wide margin on the independent Artificial Analysis Intelligence Index.
- Hosted API runs in China — a hard stop for US Federal, much of EU healthcare, and many corporate compliance regimes.
- Open weights, not open source: the training code and data recipe are not released, so the run cannot be reproduced.
- Self-hosting demands serious hardware — enterprise GPU clusters for full-precision V4-Pro, quantization even for V4-Flash on a single card — plus your own safety and moderation stack.
- No counterpart results on the harder agentic benchmarks Fable 5 reports, including SWE-bench Pro and GDPval-AA, so its ceiling there is unproven.
When to Pick Each
When to pick Claude Fable 5
Pick Fable 5 when the marginal quality of the answer is worth more than the tokens it costs. That means deep agentic coding — multi-hour, multi-file runs where its SWE-bench Pro lead and self-verifying behavior translate directly into fewer broken builds — plus high-stakes reasoning, research synthesis, and long-horizon agent workflows that lesser models drop halfway through. Pick it if you are a Western enterprise that needs US hosting and major-cloud procurement paths, and 30-day retention is acceptable under your policies. And pick it if your volume profile is modest but your error cost is high: at low volumes, the absolute dollar difference shrinks while the capability gap does not. One architectural note from our own day-one deployment: build for the refusal case. The fallback to Claude Opus 4.8 is well-designed and cheap to wire up, and any serious Fable 5 integration should treat it as part of the model, not an edge case.
When to pick DeepSeek V4
Pick DeepSeek V4 when cost, volume, or sovereignty is the binding constraint — which, at these prices, covers most production AI workloads in existence. Batch processing, retrieval pipelines, classification, summarization at scale, agent loops that iterate hundreds of times: V4-Flash makes all of it effectively free compared to any closed flagship, and V4-Pro covers the harder middle tier at 0.87 dollars output. Pick it if open weights matter — for fine-tuning on proprietary data, for redistribution inside products, or for the simple leverage of never being locked to a vendor's pricing decisions. And pick it, self-hosted, if absolute data control is mandatory: weights inside your own network beat any retention policy, including Fable 5's mandatory 30 days. The trade you accept is a wide Intelligence Index gap, an unproven ceiling on the hardest agentic benchmarks, and ownership of your own safety stack.
Final Verdict
Split verdict — and the cleanest illustration yet that frontier AI has forked into two different products. Claude Fable 5 is the strongest widely available model in the world right now: number one of 152 on the Artificial Analysis Intelligence Index, leading by a wide margin over DeepSeek V4-Pro, roughly 80.3 percent on SWE-bench Pro per early trackers, 1932 on GDPval-AA, with a designed-in Opus 4.8 safety net and US-hosted enterprise paperwork. DeepSeek V4 is the most aggressive price-and-openness play in the industry: MIT-licensed weights, 80.6 percent reported on SWE-bench Verified, a 384K output ceiling, and hosted output tokens that cost roughly 178 times less than Fable 5's. One model maximizes capability per call; the other maximizes capability per dollar, and the distance between them on both axes is the widest we have measured.
We did not crown an overall winner because the use case decides everything here. If you need the best model money can buy and the economics of your problem absorb 50 dollars per million output tokens, buy Fable 5 — there is currently nothing stronger you can actually access. If you need volume, weights, or sovereignty, DeepSeek V4 is not a compromise; it is the correct tool, and for many workloads the only economically sane one. The most rational architecture we see is both: route the brutal 5 percent to Fable 5 and the bulk 95 percent to V4, and let the 178-times spread fund the premium calls. All benchmark figures here are attributed to Artificial Analysis, early third-party trackers, or vendor reports; only the pricing is fetch-verified directly from each vendor.
If you are weighing the rest of the frontier field, we also ran Anthropic's Opus tier head-to-head with OpenAI's flagship in Claude Opus 4.8 vs GPT-5.5, with Google's in Claude Opus 4.8 vs Gemini 3.1 Pro, and against its own predecessor in Claude Opus 4.8 vs Claude Opus 4.7 — useful context for where Fable 5's fallback model sits. The Claude Opus 4.8 review covers that model in full.
Frequently Asked Questions
Is Claude Fable 5 better than DeepSeek V4?
On capability, yes. Claude Fable 5 ranks number one of 152 models on the Artificial Analysis Intelligence Index, leading by a wide margin over DeepSeek V4-Pro, and early third-party trackers put it at roughly 80.3 percent on SWE-bench Pro, a harder benchmark than the SWE-bench Verified track where DeepSeek reports 80.6 percent. But DeepSeek V4 costs roughly 178 times less per output token and ships MIT-licensed open weights you can self-host, so the better choice depends entirely on whether you are optimizing for capability or for cost and control.
How much more expensive is Claude Fable 5 than DeepSeek V4?
It is the widest price gap in frontier AI. On output tokens, Claude Fable 5 at 50 dollars per million is roughly 178 times the cost of DeepSeek V4-Flash at 0.28 dollars and about 57 times V4-Pro at 0.87 dollars. On input, Fable 5 at 10 dollars per million runs about 71 times V4-Flash at 0.14 dollars and about 23 times V4-Pro at 0.435 dollars. All prices were fetched directly from each vendor's pricing documentation in June 2026.
What happens when Claude Fable 5 refuses a request?
The Messages API returns a successful response with a refusal stop reason and identifies which safety classifier declined. Anthropic provides a fallbacks parameter, in beta on the Claude API and Claude Platform on AWS, that automatically retries the request on another Claude model such as Claude Opus 4.8, plus SDK middleware for TypeScript, Python, Go, Java, and C# that does the same client-side. You are not billed for a request refused before any output is generated, and a fallback credit refunds the prompt-cache cost of switching models.
Is DeepSeek V4 really open source?
It is open weights, not fully open source. DeepSeek V4 ships its model weights under an MIT license on Hugging Face, which allows free commercial use, redistribution, modification, and fine-tuning. However, the training code and data recipe are not released, so the community cannot reproduce the training run from scratch. You can download, self-host, and adapt the model freely — you just cannot rebuild it.
Can I self-host either model?
Only DeepSeek V4. Its MIT-licensed weights are downloadable and run on your own hardware, including native day-one support for Huawei Ascend chips, though full-precision V4-Pro requires enterprise GPU clusters and V4-Flash needs INT4 or INT8 quantization to fit a single high-end card. Claude Fable 5 is closed and available only through the Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry — it cannot be self-hosted at any price.
What are the context window and output limits for each model?
Both models carry a 1,000,000-token context window by default. The output ceilings differ sharply: Claude Fable 5 supports up to 128K output tokens per request, while DeepSeek V4 supports up to 384K output tokens on both V4-Pro and V4-Flash — three times Fable 5's maximum, which matters for long single-pass generations.
Which model is better for agentic coding?
Claude Fable 5, clearly, with one caveat about benchmark labels. Early third-party trackers report roughly 80.3 percent on SWE-bench Pro — the harder coding benchmark, where Claude Opus 4.8 scores 69.2 percent and GPT-5.5 scores 58.6 percent. DeepSeek's reported 80.6 percent is on SWE-bench Verified, an easier track, so the two numbers are not comparable despite looking nearly identical. For high-volume coding where cost dominates, DeepSeek V4 remains extremely attractive; for the hardest agentic work, Fable 5 leads.
What does Covered Model status mean for Claude Fable 5 data retention?
Claude Fable 5 is designated a Covered Model by Anthropic, which means API traffic to it carries mandatory 30-day data retention and the model is not available under zero-data-retention agreements. Organizations whose contracts or regulations require zero retention cannot use Fable 5 regardless of budget — Claude Opus 4.8 remains Anthropic's strongest model available under standard retention arrangements, and self-hosted DeepSeek V4 offers full data control on your own infrastructure.
What are the DeepSeek V4 tiers and thinking modes?
DeepSeek V4 ships in two sizes. V4-Pro is a 1.6-trillion-parameter mixture-of-experts model with about 49 billion parameters active per token, priced at 0.435 dollars input and 0.87 dollars output per million tokens. V4-Flash is a 284-billion-parameter model with about 13 billion active, priced at 0.14 dollars input and 0.28 dollars output. Both support three thinking modes — Non-Think, Think High, and Think Max — and DeepSeek retires its older deepseek-chat and deepseek-reasoner endpoints on July 24, 2026, with V4-Flash replacing both.
Is Claude Fable 5 the same as Claude Mythos 5?
They are closely related but not the same offering. Claude Mythos 5 shares Claude Fable 5's capabilities without the safety classifiers, and it is available only in limited release to approved customers through Anthropic's Project Glasswing — invitation-only, with no self-serve access. Claude Fable 5 is the generally available model: the same capability tier, wrapped in safety classifiers, with the documented refusal and fallback behavior.
Which model should I use for high-volume production workloads?
For pure volume, DeepSeek V4 — and it is rarely close. One billion output tokens a month costs about 50,000 dollars on Claude Fable 5, roughly 870 dollars on V4-Pro, and about 280 dollars on V4-Flash. The pattern we recommend is routing: send the small fraction of genuinely hard, high-value tasks to Fable 5 and everything bulk to DeepSeek V4. At a 178-times output price spread, even a 5 percent premium-tier share keeps total spend at a fraction of an all-Fable bill.
When were these models released and is this comparison current?
Claude Fable 5 became generally available on June 9, 2026, and DeepSeek V4 shipped in April 2026. This comparison was last updated June 10, 2026, with all pricing fetched directly from Anthropic's model documentation and DeepSeek's API pricing docs at that time, and every benchmark figure attributed to Artificial Analysis, early third-party trackers, or the vendors' own reports.

Our Verdict
Split verdict by use case — the widest capability-versus-cost spread we have measured between two current frontier models. Claude Fable 5 is the strongest widely available model: number one of 152 on the Artificial Analysis Intelligence Index at 65 versus 52 for DeepSeek V4-Pro, roughly 80.3% on SWE-bench Pro per early third-party trackers, and 1932 on GDPval-AA, with a designed-in Opus 4.8 fallback and US hosting. DeepSeek V4 wins everything economic: output at $0.28 per million tokens (V4-Flash) is roughly 178 times cheaper than Fable 5's $50, the weights ship under an MIT license, output reaches 384K tokens, and self-hosting offers data control no closed API can match — Fable 5 is a Covered Model with mandatory 30-day retention. No single overall winner: best for peak capability, agentic coding, and managed US compliance is Claude Fable 5; best for cost, open weights, and self-hosted sovereignty is DeepSeek V4. Only the pricing is fetch-verified; benchmarks are attributed.
Choose Claude Fable 5
Anthropic's most capable widely released model — the public, safety-classified Mythos-class frontier tier.
Try Claude Fable 5 →Choose DeepSeek V4
Chinese open-source flagship: 1.6T MoE (49B active), 1M context, 80.6% SWE-bench Verified, MIT license — V4-Pro input costs about one-eleventh of Claude Opus 4.7
Try DeepSeek V4 →Frequently Asked Questions
Is Claude Fable 5 better than DeepSeek V4?
Split verdict by use case — the widest capability-versus-cost spread we have measured between two current frontier models. Claude Fable 5 is the strongest widely available model: number one of 152 on the Artificial Analysis Intelligence Index at 65 versus 52 for DeepSeek V4-Pro, roughly 80.3% on SWE-bench Pro per early third-party trackers, and 1932 on GDPval-AA, with a designed-in Opus 4.8 fallback and US hosting. DeepSeek V4 wins everything economic: output at $0.28 per million tokens (V4-Flash) is roughly 178 times cheaper than Fable 5's $50, the weights ship under an MIT license, output reaches 384K tokens, and self-hosting offers data control no closed API can match — Fable 5 is a Covered Model with mandatory 30-day retention. No single overall winner: best for peak capability, agentic coding, and managed US compliance is Claude Fable 5; best for cost, open weights, and self-hosted sovereignty is DeepSeek V4. Only the pricing is fetch-verified; benchmarks are attributed.
Which is cheaper, Claude Fable 5 or DeepSeek V4?
Claude Fable 5 is priced at $10 in / $50 out per M tokens. DeepSeek V4 is priced at $0.14 in / $0.28 out per M tokens (free plan available). Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Fable 5 and DeepSeek V4?
The key differences span across 12 features we compared. For AA Intelligence Index (Artificial Analysis, same evaluator), Claude Fable 5 offers 65, ranked number one of 152 while DeepSeek V4 offers 52 (V4-Pro, max reasoning). For Agentic coding benchmark, Claude Fable 5 offers Roughly 80.3% SWE-bench Pro, the harder track (early third-party) while DeepSeek V4 offers 80.6% SWE-bench Verified, the standard track (DeepSeek reports). For GDPval-AA Elo (agentic knowledge work), Claude Fable 5 offers 1932 (Artificial Analysis) while DeepSeek V4 offers Not listed. See the full feature comparison table above for all details.