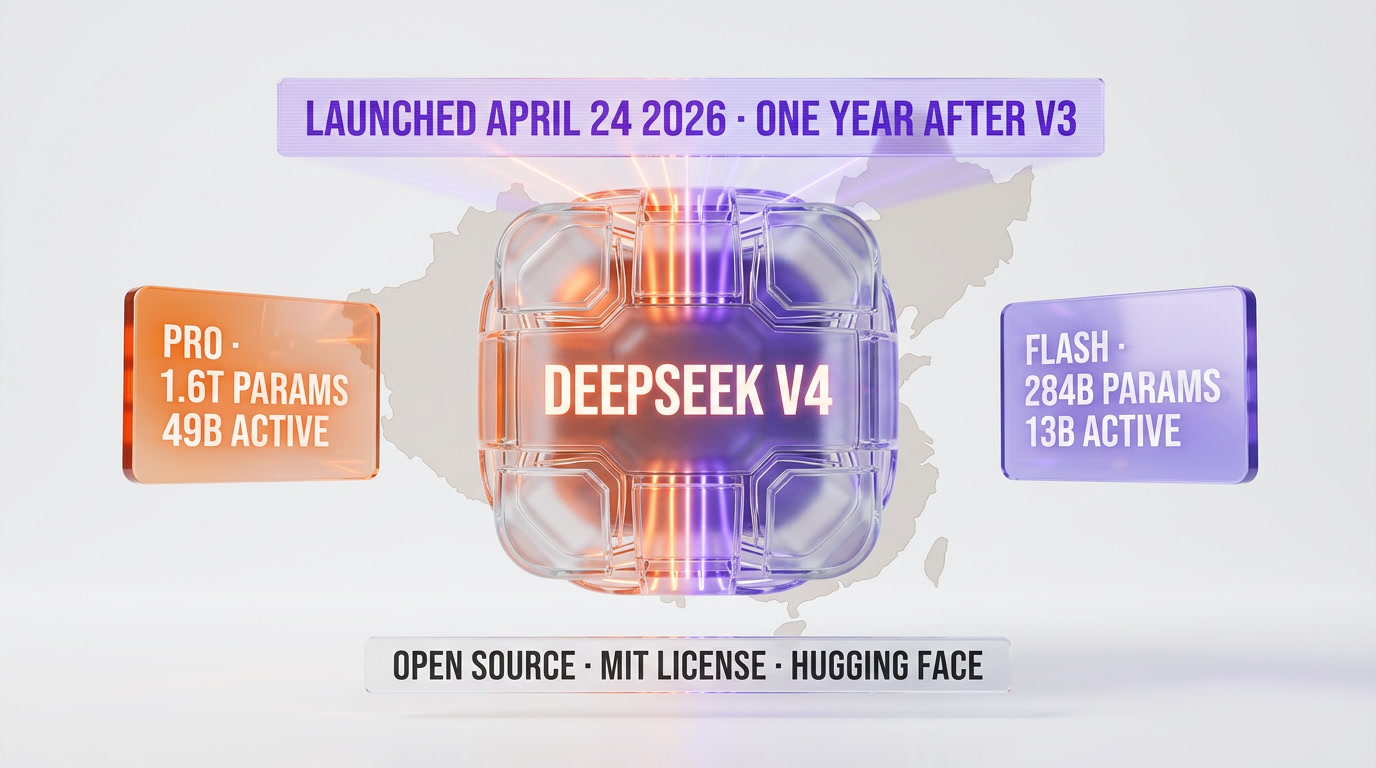
DeepSeek V4 launched officially on April 24, 2026, exactly one year after DeepSeek V3 shocked Silicon Valley. Two preview variants: V4-Pro (1.6T total / 49B active params) and V4-Flash (284B total / 13B active), both open-sourced on Hugging Face under MIT license. The breakthrough: Hybrid Attention — combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) — cuts single-token FLOPs to 27% and KV cache to 10% vs V3.2, with 1M-token context as default. V4-Flash costs $0.14 per million input tokens, $0.28 per million output. V4-Pro: $1.74 in, $3.48 out. DeepSeek now trails GPT-5.5 and Gemini 3.1 Pro by roughly 3-6 months — at a fraction of the price, with open weights.
Our methodology: why we researched this instead of testing it
We publish in two voices at ThePlanetTools. Voice 1 is "we tested" — hands-on reviews, API keys deployed, real workflows. Voice 2 is "we researched" — compiled analysis when the story is about official specs, launch facts, or ecosystem moves. This is Voice 2.
We haven't run the DeepSeek-V4 API ourselves yet. Instead, this article compiles what DeepSeek published and what credible third parties verified within the first 24 hours of the April 24 launch. Our primary sources:
- DeepSeek official API docs — the canonical launch note at
api-docs.deepseek.com/news/news260424with pricing, architecture summary, and preview availability. - Hugging Face model cards —
deepseek-ai/DeepSeek-V4-Proanddeepseek-ai/DeepSeek-V4-Flash, both published April 24 with the full tech report PDF, benchmark tables, and MIT license. - Simon Willison — independent testing via OpenRouter, published the same day, including SVG generation probes on both variants and price comparison to GPT-5.4 Nano.
- Al Jazeera and Bloomberg — strategic context, China AI positioning, and frontier-lab comparisons.
Where DeepSeek's self-reported benchmarks and third-party tests disagree, we flag it. Where numbers are absent, we say so. We prioritize what you can verify today over what sounds impressive.
April 24, 2026: the launch details
We previewed this release in our "DeepSeek V4 is imminent" piece — the rumor mill had circulated the trillion-parameter and open-weights story for weeks. The actual launch hit slightly different from the leaked details: DeepSeek split the release into two variants (Pro and Flash), the architecture headline is Hybrid Attention (not just scaled parameters), and the 1M context is default rather than a premium tier.
On the morning of April 24, 2026 (Beijing time), DeepSeek quietly dropped two model cards on Hugging Face and updated its API documentation. No press release, no keynote — the same stealth rhythm that defined the V3 launch in January 2025. Within six hours, Simon Willison had already tested both variants via OpenRouter. Within twelve, Bloomberg and Al Jazeera had full analysis pieces live.
The launch packaged two distinct preview models under the V4 banner:
- DeepSeek-V4-Pro — the flagship, 1.6 trillion total parameters with 49 billion active on any given forward pass. Mixture-of-Experts architecture, 1M-token context, MIT license, open weights.
- DeepSeek-V4-Flash — the efficient tier, 284 billion total parameters with 13 billion active. Same architecture family, same 1M context, same MIT license.
Both models use mixed FP4 + FP8 precision (MoE expert parameters at FP4, the rest at FP8). Both ship with the tech report DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence as a PDF on the Pro repo.
The pricing DeepSeek posted the same day:
| Model | Input (per million tokens) | Output (per million tokens) | Context |
|---|---|---|---|
| DeepSeek-V4-Pro | $1.74 | $3.48 | 1M tokens |
| DeepSeek-V4-Flash | $0.14 | $0.28 | 1M tokens |
| GPT-5.5 (reference) | ~$2.50 | ~$10.00 | 400K tokens |
| Claude Opus 4.7 (reference) | $15.00 | $75.00 | 1M tokens |
V4-Flash at $0.14 per million input tokens undercuts GPT-5.5 Nano's equivalent tier. V4-Pro at $1.74 input / $3.48 output is the cheapest frontier-class model available as of launch day — and it's open weights. You can download the checkpoint and run it locally if you have the hardware.
For the anniversary symbolism, DeepSeek chose April 24 — not the January 20 V3 anniversary — which suggests the timing was tactical rather than sentimental. OpenAI had launched GPT-5.5 twenty-four hours earlier, and Anthropic's Claude Opus 4.7 had been out for barely two weeks. DeepSeek walked into the busiest frontier-launch week of 2026 and posted the lowest price sheet in the room.
Hybrid Attention: the real innovation
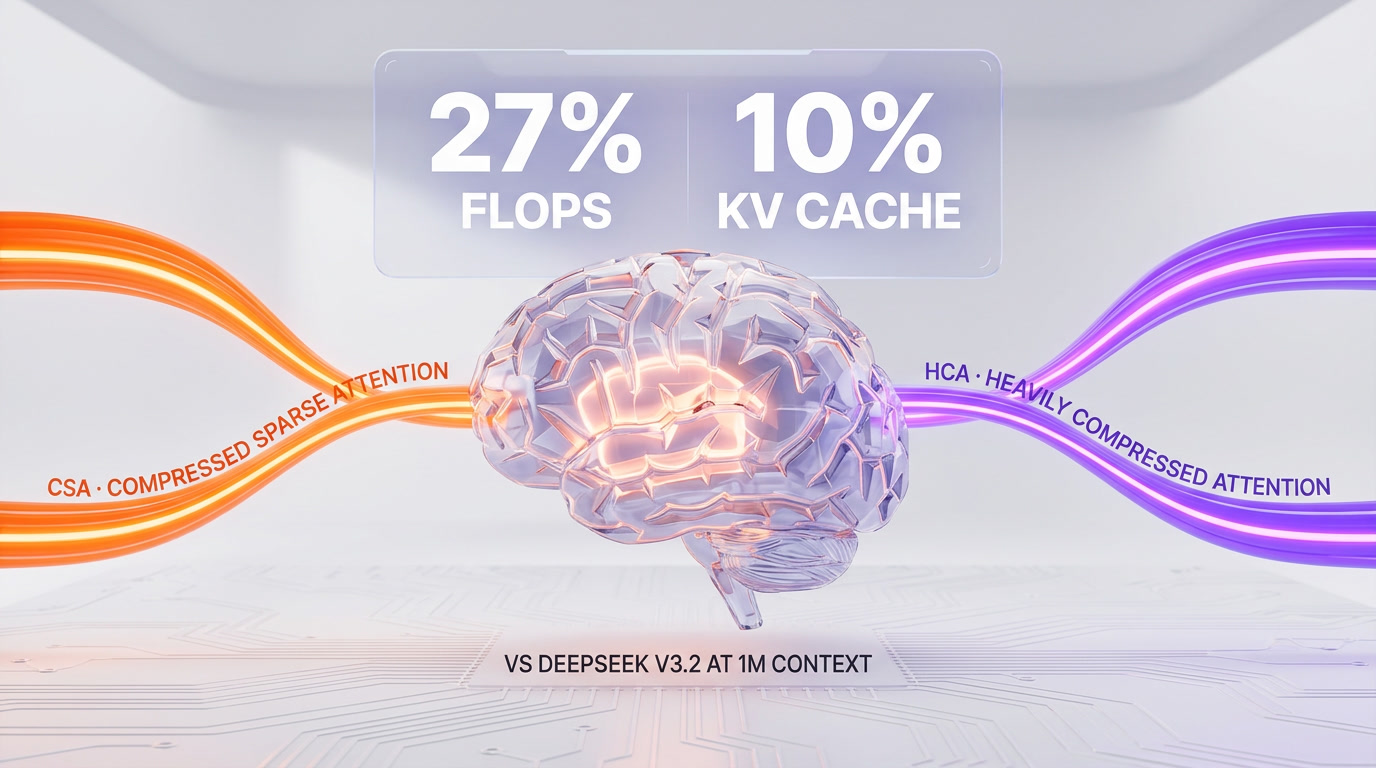
Every frontier model lab has spent 2025 fighting the same enemy: the quadratic cost of attention at long context. DeepSeek's V4 tech report names its answer Hybrid Attention, and the architecture section is the most important page in the document.
Hybrid Attention combines two complementary mechanisms:
- Compressed Sparse Attention (CSA) — operates on a token-wise compressed representation. Instead of every token attending to every other token, CSA routes attention through a sparse compressed map, preserving local fidelity and selective global reach.
- Heavily Compressed Attention (HCA) — aggressively downsamples the key-value space at long ranges, trading fine-grained recall for dramatic efficiency gains on the tail of the context window.
The two mechanisms run in parallel across different layers. The result, according to the tech report:
- Single-token inference at 1M context: 27% of V3.2's FLOPs (Pro) — roughly a 3.7x speedup.
- KV cache footprint: 10% of V3.2 (Pro) — a 10x memory reduction at the million-token boundary.
- V4-Flash pushes further: ~10% FLOPs, 7% KV cache vs V3.2 at 1M context, per the model card.
Those numbers matter for three reasons. First, they make 1M-token context economically viable — previous open models could technically handle 1M but the cost per query made it pointless. Second, they push the efficiency frontier that labs like Anthropic and Google have been advancing in closed ecosystems into open weights. Third, they enable genuinely new workflows: entire codebases in a single prompt, multi-document legal analysis, long-form agentic runs without aggressive context compression.
DeepSeek also stacks two other architectural additions on top of Hybrid Attention:
- Manifold-Constrained Hyper-Connections (mHC) — a reinforcement of residual connections that stabilizes signal propagation across the very deep layer stacks required for a 1.6T MoE.
- Muon Optimizer — the same second-order-adjacent optimizer family that's been quietly outperforming AdamW in 2025 research. DeepSeek claims faster convergence and better training stability.
The tech report doesn't ablate these additions against Hybrid Attention, so we don't know how much each contributes. But the composite package is the first time we've seen a credible frontier-class open model ship with all three innovations in production.
1M context as default: what changes

DeepSeek's launch copy contains one sentence that changes the competitive landscape: "1M context is now the default across all official DeepSeek services." No premium tier, no opt-in flag, no surcharge. Every query can reach a million tokens.
To translate that: 1M tokens is roughly 750,000 English words, or the entire codebase of a medium-sized open source project (think React 19 or the Next.js App Router source), or a 1,500-page legal filing. The practical implications:
- Whole-repo coding — you can paste a 300-file TypeScript monorepo into the prompt and ask for a refactor. Previous open models forced you to chunk, embed, and retrieve. DeepSeek removes that friction. For agent-style workflows similar to what Claude Code does with its internal context strategy, V4 gives the open ecosystem a shot at parity.
- Long-document RAG becomes optional — if the document fits in context, you don't need a retrieval pipeline at all. You lose some efficiency, but you avoid the entire class of "the RAG retrieved the wrong chunk" bugs.
- Agentic runs stay coherent — current agent stacks burn context on tool calls and observations. At 1M, a multi-hour agent can keep its entire trace in-window without aggressive summarization that tends to drop detail.
Two honest caveats. First, attention is not uniformly strong across a 1M window — every frontier model shows some "lost in the middle" degradation. DeepSeek's own MRCR 1M score is 83.5 for Pro (a strong number, but not perfect). Second, think modes with larger budgets (Think Max) require a 384K-token context window minimum, which means they consume context budget that your actual query would otherwise use.
For comparison, ChatGPT through GPT-5.5 currently caps at 400K tokens on the consumer tier. Claude Opus 4.7 offers 1M context but at $15/$75 per million tokens — roughly 9x V4-Pro's input price and 22x its output price. Google's Gemini 3.1 Pro has 1M context but locks tight rate limits on that tier.
Efficiency gains vs V3.2: the receipts
The raw efficiency claims deserve unpacking, because they're the numbers Silicon Valley is going to obsess over for the next six months.
DeepSeek V3.2 (the December 2025 checkpoint) was already a respectably efficient MoE. The V4 tech report benchmarks Hybrid Attention against V3.2 at matched context lengths:
| Metric at 1M context | DeepSeek-V4-Pro | DeepSeek-V4-Flash |
|---|---|---|
| Single-token FLOPs (vs V3.2) | 27% | ~10% |
| KV cache footprint (vs V3.2) | 10% | 7% |
| Total parameters | 1.6T | 284B |
| Active parameters per forward pass | 49B | 13B |
A 3.7x FLOPs reduction on Pro and roughly 10x on Flash translates directly to inference-time latency and cost. For agentic coding workflows — the category Qwen 3.6 has been aggressively targeting — this is the difference between "viable in production" and "impressive demo."
KV cache footprint matters differently. At a million tokens of context, V3.2's KV cache could easily consume tens of gigabytes of GPU memory per request. Cutting that to 10% means a single H100 can serve many more concurrent 1M-context requests, which drives per-token pricing down. DeepSeek's $0.14 input price on Flash is not a loss-leader — it's what the new architecture makes economically sustainable.
The subtle cost: aggressive compression loses some information. The MRCR (Multi-Round Causal Reasoning) 1M score is where you'd see degradation. Pro scores 83.5 MMR and Flash scores 78.7. Those are strong numbers, but not the best in class. Claude Opus 4.7, per Anthropic's internal benchmarks (which we can't independently verify), reportedly sits in the high 80s on comparable long-context tasks.
Benchmarks: how V4 stacks against the frontier

DeepSeek's self-reported benchmarks — these are from the model card and tech report, not independent tests — put V4-Pro-Max (maximum thinking budget) as follows:
| Benchmark | DeepSeek-V4-Pro-Max | DeepSeek-V4-Flash-Max | Category |
|---|---|---|---|
| MMLU-Pro (EM) | 87.5 | 86.2 | Knowledge & reasoning |
| GPQA Diamond (Pass@1) | 90.1 | 88.1 | Graduate-level science |
| SimpleQA-Verified (Pass@1) | 57.9 | 34.1 | Factual recall |
| LiveCodeBench (Pass@1) | 93.5 | 91.6 | Coding |
| Codeforces (Rating) | 3206 | 3052 | Competitive programming |
| IMOAnswerBench (Pass@1) | 89.8 | 88.4 | Olympiad math |
| MRCR 1M (MMR) | 83.5 | 78.7 | Long context |
| CorpusQA 1M (ACC) | 62.0 | 60.5 | Long-context QA |
DeepSeek's positioning from the launch copy: "Performance rivaling the world's top closed-source models." Al Jazeera's read: V4-Pro "beats all rival open models for maths and coding" and trails only Gemini 3.1 Pro in world knowledge. Simon Willison's more conservative read: DeepSeek's own charts show V4-Pro trailing GPT-5.4 and Gemini 3.1 Pro by "approximately 3 to 6 months" on reasoning — and V4 was benchmarked against GPT-5.4, not the fresher GPT-5.5 that shipped April 23.
The honest summary: V4-Pro is the best open-weights model as of April 24, 2026. It's not the best model period. But given that it costs roughly 5-10% of Claude Opus 4.7 per token and ships with open weights, the question isn't "is it the absolute best?" — it's "is it good enough at this price?" For most workloads, the answer is yes.
V4-Flash vs V4-Pro: which one should you actually use?
DeepSeek shipped two variants for a reason — they target different cost/capability profiles.
Use V4-Flash ($0.14 / $0.28 per million tokens) when:
- You're running high-volume API calls where per-token cost dominates (customer support, classification, routing, light summarization).
- You need fast responses for interactive UX — Flash has lower latency because fewer active parameters per forward pass.
- You're doing coding tasks that don't require elite reasoning — Flash's LiveCodeBench score of 91.6 is already above most production needs.
- You can afford Think Max mode's context overhead (384K tokens reserved) because your queries are short.
Use V4-Pro ($1.74 / $3.48 per million tokens) when:
- You need absolute best-in-class reasoning on hard problems — GPQA Diamond at 90.1 is frontier territory.
- You're building complex agentic workflows where the model has to plan, tool-use, and self-correct across many steps.
- You need better factual recall — SimpleQA-Verified at 57.9 vs Flash's 34.1 is a 24-point gap that matters on open-ended questions.
- Your 1M-context queries need the better MRCR performance (83.5 vs 78.7).
Both models support three reasoning modes: Non-Think (fast intuitive), Think High (conscious analysis), and Think Max (maximum reasoning, requires ≥384K context). Think Max is where the benchmark numbers above come from — those are not the base non-thinking outputs.
The China AI strategic play
The launch context is almost as important as the specs. April 24, 2026, sits at an unusual crossroads:
- DeepSeek V3 anniversary — the R1 and V3 releases in January 2025 were dubbed "AI's Sputnik moment" by Marc Andreessen and triggered a $1 trillion selloff in US AI stocks. One year later, DeepSeek is reminding the market it's still here.
- GPT-5.5 launched April 23 — OpenAI dropped its agentic super-app model 24 hours earlier. V4 effectively competes for the same news cycle.
- Claude Opus 4.7 recent — Anthropic's flagship, optimized for coding, had shipped weeks earlier at premium pricing.
- Chinese AI is consolidating — Alibaba's Qwen 3.6 shipped recently with open source parity on coding; Google's Gemma 4 went open; DeepSeek V4 raises the open-source frontier bar again.
Reporting from Bloomberg and the Financial Times in the weeks before launch placed DeepSeek in active investment talks with Tencent and Alibaba at a valuation reportedly near $40 billion. Those talks remained unconfirmed as of the launch day, but the signal is clear: Chinese tech giants are lining up to back the country's most visible open-source AI lab.
There's also a geopolitical layer the pure-spec discussion tends to skip. Multiple jurisdictions — US states, Australia, Taiwan, South Korea, Denmark, Italy — have at various points restricted DeepSeek's official hosted services on privacy and national-security grounds. The MIT license and open weights matter here: even in jurisdictions that ban the hosted API, teams can self-host V4 on infrastructure they control. That's a substantial differentiator versus closed APIs where the restriction is terminal.
Open source vs closed: what V4 proves
The most important non-technical claim the V4 launch makes is the one it doesn't spell out: an open-weights model can land within 3-6 months of the closed frontier at single-digit percent of the cost. That's the argument that reshapes the market.
Consider the pricing gap on output tokens for a 1M-context query:
- Claude Opus 4.7: $75.00 per million output tokens.
- GPT-5.5 (standard tier, approximate): $10.00 per million output.
- DeepSeek V4-Pro: $3.48 per million output.
- DeepSeek V4-Flash: $0.28 per million output.
If your workload doesn't require the last 5% of capability, V4-Flash at 1/270th the price of Opus 4.7 output is economically irresistible. That math is why ChatGPT Enterprise customers, Claude API teams, and even Google Cloud Vertex deployments are going to have explicit conversations about "DeepSeek fallback" tiers in Q2 2026.
The closed labs' counterargument has always been the same: "Our models do things theirs can't." That was largely true in 2024, mostly true in 2025, and is becoming harder to sustain in 2026. V4-Pro at 90.1 on GPQA Diamond is genuinely frontier. V4-Flash at LiveCodeBench 91.6 is deployable-for-production coding performance. The capability gap is narrowing even as the price gap widens.
For open-source foundation model progress more broadly, V4 sits alongside Gemma 4, Qwen 3.6, and the earlier R1/V3 line as evidence that the "only closed labs can do frontier" thesis has decisively cracked.
What developers should do this week
A few concrete actions if you build with AI models and V4 is now on your radar:
- Benchmark V4-Flash on your classification and routing workloads. At $0.14 input / $0.28 output per million tokens, the price is low enough that even modest quality parity flips the economics of light-touch LLM use.
- Test V4-Pro on complex coding agents. The LiveCodeBench 93.5 and Codeforces 3206 rating are in the same territory as Claude Opus 4.7. If it works for your real repos, the cost savings compound quickly.
- Try 1M context for whole-repo tasks — one query, one answer, no RAG. See where recall breaks. The MRCR 83.5 score suggests reliable retrieval across most of the window but not all of it.
- Consider self-hosting V4-Flash. 284B total / 13B active on FP4+FP8 fits on a serious GPU cluster. For regulated workloads or data-sovereignty concerns, the MIT license and open weights are decisive.
- Plan for the pricing reset. If V4-Flash's $0.14 input holds up in independent testing, every closed lab will be pressured to match within 90 days. Don't lock into 12-month commits at current rates.
One caveat: preview models have caveats. DeepSeek labeled both V4 variants as preview releases. Expect API stability improvements, potential price adjustments, and likely a V4-Pro-Max or reasoning-specialized variant in Q3 2026. The launch-week numbers are real but not necessarily permanent.
What we don't know yet
Fact transparency matters. Here's what's still unclear as of launch day:
- Independent long-horizon benchmarks. Simon Willison tested SVG generation in the first 24 hours; broader academic benchmarks (HELM, MT-Bench hard mode, SWE-bench Verified) haven't published V4 scores yet. We'll update when independent runs land.
- Rate limits on the hosted API. DeepSeek hasn't published explicit tier limits. History suggests they'll evolve rapidly in the first weeks.
- Fine-tuning availability. MIT-licensed weights mean you can fine-tune locally. Whether DeepSeek will offer a hosted fine-tuning API, or whether Hugging Face integrations make LoRA training practical at this parameter count, is still open.
- Tencent and Alibaba investment status. The reported $40B valuation and 20% stake talks remain unconfirmed publicly. Announcements could come any week.
- Whether OpenAI, Anthropic, and Google respond. GPT-5.5 just launched. Claude Opus 4.7 is fresh. Google's Gemini 3.2 is rumored for May. The frontier battle doesn't pause for a quarter.
Frequently asked questions
When did DeepSeek V4 launch?
DeepSeek V4 launched officially on April 24, 2026, as a preview release. Both the V4-Pro (1.6T total / 49B active parameters) and V4-Flash (284B total / 13B active) variants went live on Hugging Face the same day under the MIT license, with the official API documentation updated simultaneously at api-docs.deepseek.com. The launch came exactly one year after DeepSeek's V3 release that triggered a $1 trillion US AI stocks selloff in January 2025.
What is Hybrid Attention in DeepSeek V4?
Hybrid Attention is DeepSeek V4's core architectural innovation. It combines two mechanisms running in parallel: Compressed Sparse Attention (CSA), which operates on token-wise compressed representations for efficient selective attention, and Heavily Compressed Attention (HCA), which aggressively downsamples the key-value space at long ranges. Together they cut single-token FLOPs to 27% and KV cache to 10% of V3.2 at 1M-token context, making million-token context economically viable for the first time in open-weights models.
How much does DeepSeek V4 cost through the API?
DeepSeek V4-Flash costs $0.14 per million input tokens and $0.28 per million output tokens. V4-Pro costs $1.74 per million input tokens and $3.48 per million output tokens. Both tiers include 1M-token context at no extra cost. For reference, Claude Opus 4.7 charges $15.00 per million input and $75.00 per million output tokens — making V4-Pro roughly 9x cheaper on input and 22x cheaper on output, and V4-Flash roughly 270x cheaper on output than Opus 4.7.
What is the difference between DeepSeek V4-Pro and V4-Flash?
V4-Pro has 1.6 trillion total parameters with 49 billion active per forward pass, delivering frontier-class reasoning (GPQA Diamond 90.1, LiveCodeBench 93.5, MRCR 1M 83.5). V4-Flash has 284 billion total with 13 billion active, optimized for low latency and cost (LiveCodeBench 91.6, MRCR 1M 78.7). Use Flash for high-volume API calls, interactive UX, and most coding tasks. Use Pro for hardest reasoning, complex agentic workflows, and better factual recall (SimpleQA-Verified 57.9 vs Flash's 34.1).
Is DeepSeek V4 open source?
Yes. Both DeepSeek-V4-Pro and DeepSeek-V4-Flash ship with open weights under the MIT license on Hugging Face (deepseek-ai/DeepSeek-V4-Pro and deepseek-ai/DeepSeek-V4-Flash). MIT is one of the most permissive licenses available, allowing commercial use, modification, and redistribution. The complete tech report (DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence) is also published as a PDF. You can download the checkpoints and self-host if you have the hardware.
What is the 1M context window in DeepSeek V4?
DeepSeek V4 supports 1 million tokens of context by default on all official services — no premium tier, no opt-in flag, no surcharge. One million tokens equals roughly 750,000 English words or an entire medium-sized codebase (for example React 19 or the Next.js App Router source). Hybrid Attention makes this economically viable: at 1M context, V4-Pro uses only 27% of V3.2's FLOPs per token and 10% of V3.2's KV cache footprint. MRCR 1M benchmark: 83.5 MMR on Pro, 78.7 on Flash.
How does DeepSeek V4 compare to GPT-5.5 and Claude Opus 4.7?
DeepSeek V4-Pro benchmarks roughly 3-6 months behind GPT-5.5 and Gemini 3.1 Pro on reasoning per DeepSeek's own comparisons, but at a fraction of the price. On GPQA Diamond (90.1), LiveCodeBench (93.5), and Codeforces (rating 3206), V4-Pro is in the same band as Claude Opus 4.7. The clear win is cost: V4-Pro output is roughly 22x cheaper than Opus 4.7 output and 2.9x cheaper than GPT-5.5 output. V4-Flash at $0.28 per million output tokens is in a different pricing category entirely from closed frontier models.
What are the reasoning modes in DeepSeek V4?
DeepSeek V4 models support three reasoning modes. Non-Think gives fast intuitive responses for latency-sensitive tasks. Think High activates conscious logical analysis for harder queries. Think Max is maximum reasoning effort and requires at least a 384K-token context window to operate — which means it consumes context budget that your query would otherwise use. The headline benchmark numbers (MMLU-Pro 87.5, GPQA Diamond 90.1, LiveCodeBench 93.5) come from the Max thinking modes, not the Non-Think baseline.
Is DeepSeek V4 safe to use given China-based origins?
The hosted DeepSeek API is subject to the same privacy and national-security scrutiny that led several jurisdictions — US states, Australia, Taiwan, South Korea, Denmark, Italy — to restrict DeepSeek's services after 2025. However, V4 ships with MIT-licensed open weights on Hugging Face. Teams in restricted jurisdictions, or teams with data-sovereignty requirements, can self-host the models on infrastructure they control. Self-hosting V4-Flash (284B total / 13B active) is feasible on a serious GPU cluster and eliminates data-transmission concerns entirely.
Can DeepSeek V4 replace Claude Code or ChatGPT for coding?
For most coding workloads, yes — at a fraction of the cost. V4-Pro scores LiveCodeBench 93.5 and Codeforces 3206 rating, putting it near Claude Opus 4.7. V4-Flash at LiveCodeBench 91.6 covers most production coding needs. The 1M context lets you paste whole repositories into a single prompt without RAG. Caveats: mature agentic tooling around Claude Code and ChatGPT (harness, memory, tool calls) is still ahead. V4 is a drop-in model replacement for many use cases but not an end-to-end agent replacement yet — though that gap is closing fast with the open ecosystem around the MIT-licensed weights.
Are Tencent and Alibaba investing in DeepSeek?
As of the V4 launch on April 24, 2026, credible reporting from Bloomberg and the Financial Times places DeepSeek in active talks with Tencent and Alibaba at a valuation reportedly near $40 billion. Neither deal has been publicly confirmed. DeepSeek founder Liang Wenfeng has not commented publicly on the investor process. The signal regardless of outcome: Chinese tech giants are strategically aligning behind the country's most visible open-source AI lab, which has implications for competitive positioning versus OpenAI, Anthropic, and Google.
What are the efficiency gains of DeepSeek V4 versus V3.2?
At 1M-token context, DeepSeek V4-Pro uses only 27% of V3.2's FLOPs per inference token — roughly a 3.7x speedup — and 10% of V3.2's KV cache footprint, a 10x memory reduction. V4-Flash pushes further: approximately 10% of V3.2's FLOPs and 7% of its KV cache at the same context length. These gains come from the Hybrid Attention architecture (CSA + HCA), Manifold-Constrained Hyper-Connections (mHC) that stabilize residual signal propagation, and the Muon Optimizer for faster training convergence.



