In the race to make AI inference faster, one company has taken an approach so radical it sounds like science fiction: build a single chip the size of an entire silicon wafer. Cerebras Systems, with its Wafer-Scale Engine, has shattered every inference speed record in existence and is redefining what "real-time AI" means. While GPU-based systems from NVIDIA struggle to push past 10-15 tokens per second on large language models, Cerebras routinely delivers thousands of tokens per second -- fast enough that the bottleneck shifts from the hardware to how quickly a human can read.
In March 2026, Cerebras announced a landmark partnership with AWS to bring its inference technology to Amazon Bedrock, signaling that wafer-scale inference is no longer a niche experiment -- it is becoming cloud infrastructure. This review covers everything developers, AI engineers, and technical decision-makers need to know: architecture, pricing, speed benchmarks, competitor comparisons, and practical guidance for integrating Cerebras Inference into production workloads.
What Is Cerebras Inference?
Cerebras Inference is an AI inference service powered by the Cerebras CS-3 system, which runs on the WSE-3 (Wafer-Scale Engine 3) -- the largest chip ever built. The WSE-3 is a single 300mm silicon wafer manufactured on TSMC's 5nm process, containing 4 trillion transistors, 900,000 AI-optimized compute cores, and 44 GB of on-chip SRAM connected by an internal fabric running at 21 petabytes per second of memory bandwidth.
The key innovation is that the entire model fits in on-chip SRAM. Traditional GPU-based inference requires shuttling model weights back and forth between external HBM (high-bandwidth memory) and compute cores -- a process that creates a memory bandwidth bottleneck. Cerebras eliminates this bottleneck entirely. With 44 GB of SRAM directly on the chip, models up to that size run with near-zero memory latency.
For larger models like Llama 3.1 405B, Cerebras uses a disaggregated inference architecture that separates the prefill phase (processing the input prompt) from the decode phase (generating output tokens). The prefill runs on hardware optimized for bulk computation, while the decode runs on the WSE-3's SRAM-rich architecture. This specialization is what enables Cerebras to hit 969 tokens per second on a 405-billion-parameter model -- a number that was considered physically impossible on GPUs just two years ago.
Cerebras Inference is accessed via a standard OpenAI-compatible API, supports popular open-source models (Llama, Mistral, DeepSeek, Qwen, and more), and is available through both direct access at cloud.cerebras.ai and, starting in 2026, through Amazon Bedrock.

Key Features in 2026
Record-Breaking Speed
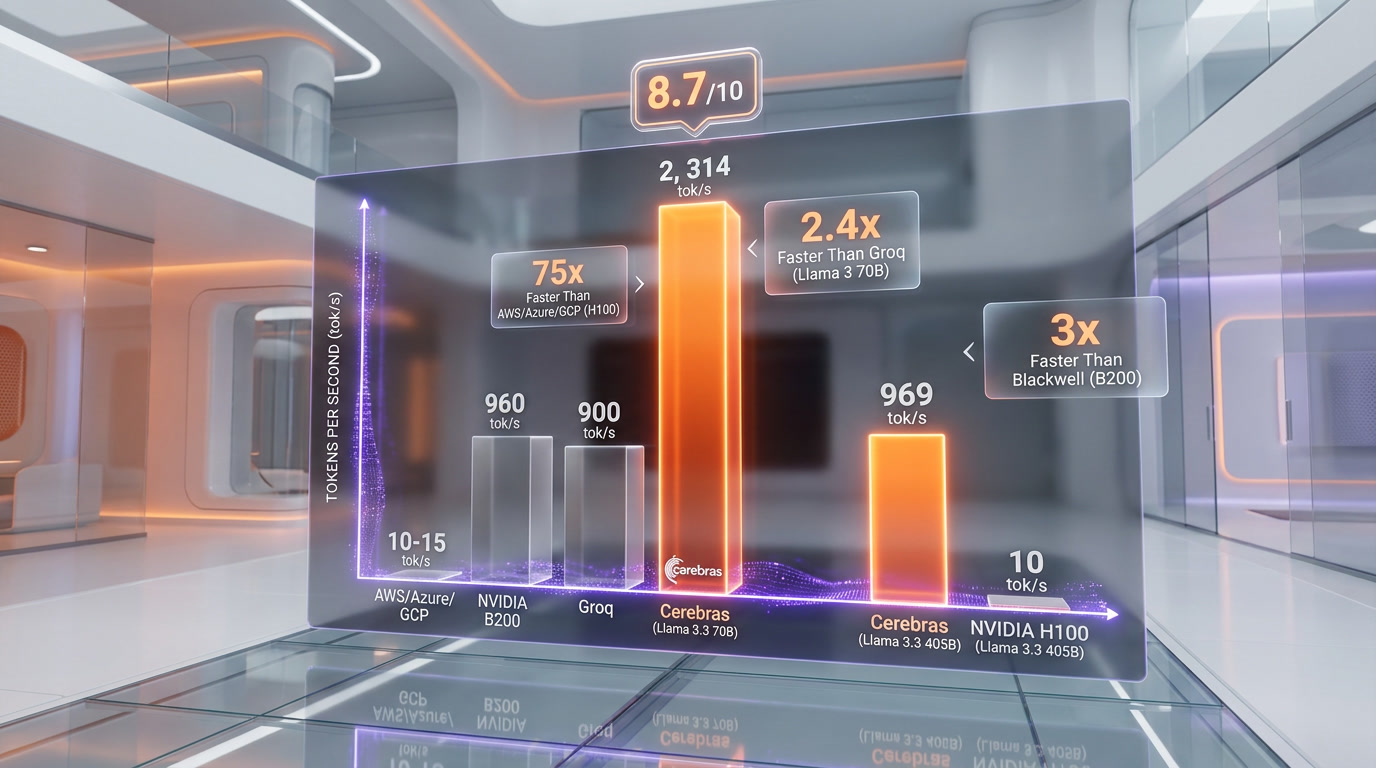
Cerebras Inference is, by independent measurement, the fastest AI inference platform in the world. Here are the verified benchmarks as of early 2026:
- Llama 3.1 8B: 1,800 tokens per second (2.4x faster than Groq)
- Llama 3.3 70B: 2,314 tokens per second (confirmed by Artificial Analysis)
- Llama 3.1 405B: 969 tokens per second (75x faster than major hyperscalers)
- GPT-OSS 120B: 2,700+ tokens per second (3x faster than NVIDIA Blackwell B200)
- Qwen3 Coder 480B: 2,000 tokens per second
To put these numbers in context: GPU-based clusters from AWS, Azure, or GCP typically deliver 10-15 tokens per second on a 405B parameter model. Cerebras delivers 969. Operations that take a minute on GPU infrastructure complete in seconds on Cerebras.
WSE-3 Architecture
The WSE-3 is the hardware foundation that makes these speeds possible. Key specifications:
- Die Size: 46,255 mm2 (an entire 300mm wafer)
- Transistors: 4 trillion (19x more than NVIDIA B200)
- Compute Cores: 900,000 AI-optimized cores
- On-Chip SRAM: 44 GB
- Memory Bandwidth: 21 PB/s (petabytes per second)
- Peak AI Performance: 125 petaflops
- Process Node: TSMC 5nm
- Compute vs. NVIDIA B200: 28x more compute per chip
The WSE-3 delivers twice the performance of its predecessor, the WSE-2, at the same power draw and the same price -- a remarkable generational improvement.
AWS Partnership and Amazon Bedrock Integration
On March 13, 2026, AWS and Cerebras announced a collaboration to bring Cerebras's inference technology to Amazon Bedrock. This is a major milestone for the company. The solution deploys in AWS data centers and combines:
- AWS Trainium servers optimized for the prefill phase
- Cerebras CS-3 systems optimized for the decode phase
- Elastic Fabric Adapter (EFA) networking for low-latency communication
The disaggregated architecture is expected to increase output generation speed by 5x compared to existing Bedrock inference. AWS is the first cloud provider for Cerebras's disaggregated inference solution. The service will support open-source LLMs and Amazon Nova models on Cerebras hardware, with availability expected in the coming months.
OpenAI-Compatible API
Cerebras Inference uses a standard OpenAI-compatible API, meaning you can swap Cerebras into any existing OpenAI SDK integration by changing the base URL and API key. This dramatically lowers the integration barrier -- you do not need to learn a new SDK or rewrite your application code.
Broad Model Support
Cerebras supports a wide range of open-source models, including:
- Meta Llama 3.1 (8B, 70B, 405B) and Llama 3.3 70B
- Mistral and Mixtral models
- DeepSeek R1 and distilled variants
- Qwen3 Coder 480B
- GLM-4 variants
- OpenAI GPT-OSS models
Developer Tools: Cerebras Code
Cerebras offers Cerebras Code Pro ($50 per month) and Cerebras Code Max ($200 per month) -- developer-focused plans designed for high-volume AI-assisted coding. These plans include discounted per-token pricing for uninterrupted agentic coding sessions, where inference speed directly translates to developer productivity. Companies like Cognition (makers of the Devin AI coding agent) use Cerebras specifically because agentic coding workflows are bottlenecked by inference speed.
Pricing Breakdown
Cerebras uses a pay-per-token model with prices varying by model size. A free tier is available for experimentation, and enterprise contracts offer volume discounts.
| Plan / Tier | Price | Details |
|---|---|---|
| Free Tier | $0 | Access to all Cerebras-powered models; community support; rate-limited |
| Pay-Per-Token (Developer) | From $0.10 per million tokens tokens | $10 minimum deposit; pay as you go; all models available |
| Cerebras Code Pro | $50 per month | High-volume AI coding; discounted token pricing; designed for agentic sessions |
| Cerebras Code Max | $200 per month | Maximum throughput for professional AI coding; priority access |
| Enterprise | Custom (flat monthly) | Flexible 3, 6, or 12-month contracts; volume discounts; dedicated support |
Per-Model Token Pricing
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| Llama 3.1 8B | $0.10 | $0.10 |
| Llama 3.1 70B | $0.60 | $0.60 |
| Llama 3.1 405B | $6.00 | $12.00 |
| GLM-4 variants | Up to $2.38 | Up to $2.38 |
| Other models | Varies ($0.10 - $6.00) | Varies ($0.10 - $12.00) |
Note: Prices vary up to 24x across models. The Llama 3.1 8B at $0.10 per million tokens is among the cheapest inference APIs available anywhere. The 405B model at $6/$12 per million tokens is premium-priced but delivers 75x the speed of GPU alternatives at comparable or lower cost when factoring in time-to-completion.
Pros and Cons -- Our Honest Take
Pros
- Fastest inference on the planet. No other provider comes close for throughput on large models. 969 tokens per second on a 405B model is not marketing -- it is independently verified.
- Eliminates the memory bottleneck. By storing models in on-chip SRAM with 21 PB/s bandwidth, Cerebras avoids the HBM bandwidth wall that limits GPU inference.
- OpenAI-compatible API. Drop-in replacement for existing OpenAI SDK integrations. Minimal code changes required.
- AWS Bedrock integration coming. Enterprise teams already using AWS can access Cerebras speed without managing custom infrastructure.
- Free tier available. You can test Cerebras inference at no cost before committing.
- Developer-focused plans. Cerebras Code Pro and Max are specifically designed for AI-assisted coding workflows where speed is the bottleneck.
- Competitive pricing on small models. $0.10 per million tokens for Llama 3.1 8B is among the lowest prices in the market.
Cons
- Premium pricing on large models. Llama 3.1 405B at $6/$12 per million tokens is significantly more expensive than GPU-based providers like Together AI or DeepInfra on a per-token basis. You pay for speed.
- Open-source models only. Cerebras does not offer proprietary models like GPT-4, Claude, or Gemini. You are limited to open-weight models.
- No fine-tuning service. As of March 2026, Cerebras Inference is focused on serving pre-trained models. If you need to fine-tune, you must do so elsewhere and then deploy on Cerebras.
- Limited ecosystem maturity. Compared to AWS SageMaker, Google Vertex AI, or Azure ML, Cerebras's platform is narrower in scope -- it does inference extremely well but does not offer a full ML pipeline.
- Availability constraints. Cerebras hardware is not as widely distributed as NVIDIA GPUs. The AWS partnership will improve this, but full Bedrock availability is still months away.
- Not the latency king. While Cerebras dominates throughput (tokens per second), Groq can offer lower first-token latency for certain workloads. For voice and real-time chat applications where time-to-first-token matters more than bulk throughput, Groq may be preferable.
Who Should Use Cerebras Inference?
- AI coding agent developers. Agentic coding tools like Devin and Cursor benefit enormously from fast inference. Every saved second compounds across thousands of LLM calls per coding session.
- Real-time AI applications. Chatbots, copilots, and assistants that need to feel instant benefit from 2,000+ tokens per second response generation.
- Batch processing at scale. If you are processing millions of documents, summarizing datasets, or running inference pipelines, Cerebras's throughput turns hours-long jobs into minutes.
- Startups building on open-source models. If your stack is built on Llama, Mistral, or DeepSeek, Cerebras gives you the fastest serving layer available.
- Enterprises already on AWS. The upcoming Bedrock integration means you can access Cerebras speed within your existing AWS environment, with AWS billing and security controls.
- Teams where developer productivity is bottlenecked by inference. If your engineers are waiting on LLM responses during development, Cerebras Code Pro/Max can dramatically reduce wait times.
Who Should NOT Use Cerebras Inference?
- Teams using proprietary models. If your application depends on GPT-4, Claude, or Gemini, Cerebras cannot serve these models. You need the respective provider's API.
- Budget-constrained projects using large models. If cost per token is your primary concern and you are running 405B-class models, GPU-based providers like Together AI or DeepInfra offer lower per-token prices (at much slower speeds).
- Full ML pipeline needs. If you need training, fine-tuning, experiment tracking, model registry, and serving in one platform, look at AWS SageMaker, Google Vertex AI, or Azure ML.
- Applications where first-token latency matters most. For voice AI or real-time conversational agents where the first token must arrive in under 100ms, Groq's architecture may offer lower latency for smaller models.
- Teams that need on-premises deployment. Cerebras inference is a cloud service. If you need to run inference in your own data center due to data sovereignty requirements, you would need to purchase CS-3 hardware directly (which costs millions).
Cerebras vs Competitors
| Feature | Cerebras Inference | Groq | Together AI | Fireworks AI |
|---|---|---|---|---|
| Architecture | Wafer-Scale Engine (WSE-3) | LPU (Language Processing Unit) | GPU clusters (NVIDIA) | GPU clusters (optimized kernels) |
| Speed (Llama 70B class) | ~2,314 tokens per second | ~300-400 tokens per second | ~917 tokens per second | ~747 tokens per second |
| Speed (405B+ class) | 969 tokens per second | Not available at this scale | Available but slower | Available but slower |
| First-Token Latency | Low (optimized for throughput) | Very low (latency king) | Moderate | Very low (0.17s) |
| Pricing (Llama 8B, per 1M tokens) | $0.10 | $0.05 - $0.11 | $0.10 - $0.20 | $0.10 - $0.20 |
| Pricing (Llama 70B, per 1M tokens) | $0.60 | $0.59 - $0.79 | $0.54 - $0.88 | $0.70 - $0.90 |
| Free Tier | Yes | Yes (rate-limited) | Yes ($5 credit) | Yes (limited) |
| API Compatibility | OpenAI-compatible | OpenAI-compatible | OpenAI-compatible | OpenAI-compatible |
| Cloud Integration | AWS Bedrock (coming 2026) | Standalone API | Standalone API | Standalone API |
| Model Support | Llama, Mistral, DeepSeek, Qwen, GPT-OSS | Llama, Mistral, Gemma, Whisper | Llama, Mistral, DeepSeek, Qwen, SDXL | Llama, Mistral, multimodal models |
| Best For | Maximum throughput; agentic coding; batch processing | Lowest latency; real-time voice and chat | Balanced speed/cost; reliable GPU inference at scale | Structured output; function calling; multimodal |
| Funding (2026) | $2.6B total; $23B valuation | $640M+ total; NVIDIA licensing deal | $400M+ total | $250M+ total |

What's New in March 2026
- AWS Partnership Announced (March 13, 2026). The most significant news this month. AWS will bring Cerebras CS-3 systems into its data centers and offer Cerebras-powered inference through Amazon Bedrock. The disaggregated inference architecture -- Trainium for prefill, CS-3 for decode -- is expected to be 5x faster than existing Bedrock inference. This is the first time Cerebras hardware will be available through a major cloud provider, marking a pivotal shift from niche to mainstream.
- Cerebras Beats Blackwell. Benchmark results published in early 2026 show the CS-3 achieving 2,700+ tokens per second on GPT-OSS 120B, compared to just 900 tokens per second on NVIDIA's latest Blackwell B200 GPU. This 3x speed advantage on a frontier model underscores that wafer-scale computing is not just a theoretical advantage -- it delivers measurable superiority in production workloads.
- $1 Billion Funding Round. In February 2026, Cerebras raised $1 billion in new funding, bringing total fundraising to $2.6 billion and the company's valuation to approximately $23 billion. This capital will fund the AWS deployment and continued hardware R&D.
- Qwen3 Coder 480B Support. Cerebras added support for Alibaba's Qwen3 Coder 480B model, achieving 2,000 tokens per second -- making it the fastest platform for large coding models.
- OpenAI, Mistral, and Cognition as Customers. Cerebras confirmed that OpenAI, Cognition (Devin), and Mistral use Cerebras infrastructure for their most demanding inference workloads, particularly agentic coding where speed is the binding constraint.
Tips for Getting the Most Out of Cerebras Inference
- Start with the free tier. Test speed differences against your current provider with real workloads before committing. The performance gap is most noticeable on larger models (70B+).
- Use the OpenAI-compatible API for easy migration. If your codebase already uses the OpenAI SDK, switching to Cerebras is a two-line change: update the base URL and API key. No rewrite needed.
- Match model size to your use case. Llama 3.1 8B at $0.10 per million tokens tokens is extremely cheap and fast. Do not default to the 405B model unless your task genuinely requires that level of reasoning capability.
- Use Cerebras for agentic workflows. Multi-step AI agents that make dozens or hundreds of LLM calls per task benefit most from Cerebras's throughput. The time savings compound with each sequential call.
- Benchmark against Groq for latency-sensitive tasks. If your application prioritizes time-to-first-token (voice AI, real-time chat), test both Cerebras and Groq. Cerebras wins on throughput; Groq may win on first-token latency.
- Watch for the Bedrock launch. If you are on AWS, wait for the Bedrock integration rather than setting up a separate Cerebras account. You will get the speed advantage with AWS billing, IAM, and security controls.
- Use batch processing for cost efficiency. For non-real-time workloads like document summarization or data extraction, batching requests can optimize your token spend.
- Consider Cerebras Code Pro for development. At $50 per month, Code Pro is cheaper than many AI coding subscriptions and gives you the fastest inference available for agentic coding sessions.
- Monitor the model catalog. Cerebras regularly adds new open-source models. Check the inference docs for the latest supported models, especially after major open-source releases from Meta, Mistral, or Alibaba.
- Factor in total cost of speed. Cerebras's per-token price on large models is higher than GPU alternatives, but the total cost of a task may be lower when you account for reduced compute time, fewer timeout retries, and faster development cycles.
Frequently Asked Questions
How fast is Cerebras Inference compared to NVIDIA GPUs?
Dramatically faster. On Llama 3.1 405B, Cerebras delivers 969 tokens per second compared to 10-15 tokens per second on typical GPU clusters -- roughly 75x faster. On smaller models like Llama 3.3 70B, Cerebras hits 2,314 tokens per second. On GPT-OSS 120B, Cerebras achieves 2,700+ tokens per second versus 900 on NVIDIA's latest Blackwell B200.
What is the WSE-3 chip?
The WSE-3 (Wafer-Scale Engine 3) is the largest chip ever built. It occupies an entire 300mm silicon wafer -- 46,255 mm2 of silicon containing 4 trillion transistors and 900,000 AI-optimized compute cores. It has 44 GB of on-chip SRAM with 21 petabytes/second of internal bandwidth. This architecture eliminates the memory bottleneck that limits GPU inference.
Is Cerebras Inference compatible with the OpenAI API?
Yes. Cerebras provides an OpenAI-compatible API. If your application uses the OpenAI Python SDK, you can switch to Cerebras by changing the base URL and API key. No other code changes are required.
How does Cerebras compare to Groq?
Cerebras is the throughput champion (most tokens per second), while Groq is the latency champion (fastest time-to-first-token). Cerebras outperforms Groq by approximately 6x on frontier LLMs and 2.4x on Llama 3.1 8B. For bulk processing and agentic workflows, Cerebras is faster. For voice AI and real-time chat where first-token latency is critical, Groq may be preferable.
What models does Cerebras support?
Cerebras supports a broad range of open-source models including Meta Llama 3.1 and 3.3 (8B, 70B, 405B), Mistral and Mixtral variants, DeepSeek R1, Qwen3 Coder 480B, GLM-4, and OpenAI GPT-OSS models. The catalog is regularly updated as new open-source models are released. Proprietary models (GPT-4, Claude, Gemini) are not available.
Can I use Cerebras through AWS?
Starting in 2026, yes. AWS and Cerebras announced a partnership on March 13, 2026, to bring Cerebras-powered inference to Amazon Bedrock. The service is expected to launch in the coming months, using a disaggregated architecture with Trainium for prefill and CS-3 for decode.
Is there a free tier?
Yes. Cerebras offers a free tier with access to all supported models and community support. It is rate-limited but sufficient for testing and experimentation. To access the full-speed pay-per-token tier, you need to deposit a minimum of $10 through the billing tab at cloud.cerebras.ai.
How much does Cerebras Inference cost?
Prices range from $0.10 per million tokens for Llama 3.1 8B to $6/$12 per million input/output tokens for Llama 3.1 405B. The price spread across models is up to 24x. Smaller models are among the cheapest inference APIs available; larger models are premium-priced to reflect the speed advantage.
What is disaggregated inference?
Disaggregated inference separates the two phases of LLM inference -- prefill (processing the input) and decode (generating output tokens) -- and runs each on hardware optimized for that specific task. Cerebras's AWS deployment uses Trainium chips for prefill and CS-3 systems for decode, allowing each phase to run at peak efficiency.
Who uses Cerebras Inference in production?
Notable customers include OpenAI, Cognition (makers of Devin, the AI coding agent), and Mistral. These companies use Cerebras for their most demanding inference workloads, particularly agentic coding and high-throughput model serving where GPU speed is insufficient.
Can I fine-tune models on Cerebras?
As of March 2026, Cerebras Inference focuses on serving pre-trained models. Fine-tuning must be done on external infrastructure (e.g., AWS SageMaker, Google Vertex, or your own GPU cluster), after which the fine-tuned model can potentially be deployed on Cerebras for inference.
Is Cerebras only for large enterprises?
No. The free tier and pay-per-token pricing (starting at $0.10 per million tokens tokens with a $10 minimum deposit) make Cerebras accessible to individual developers and startups. The Cerebras Code Pro plan at $50 per month is priced competitively with other AI coding tools. Enterprise contracts are available for high-volume users but are not required.