Grok 4.20
xAI's multi-agent collaborative flagship with 1M-token context, real-time X data, and the lowest hallucination rate on the market — wrapped in unresolved deepfake controversy.
Quick Summary
Grok 4.20 is xAI's flagship LLM running 4 collaborative agents (Grok/Harper/Benjamin/Lucas) on a 2M-token context with real-time X integration. API: $2 per 1M input, $6 per 1M output, $0.20 cached. Score 7.4/10.
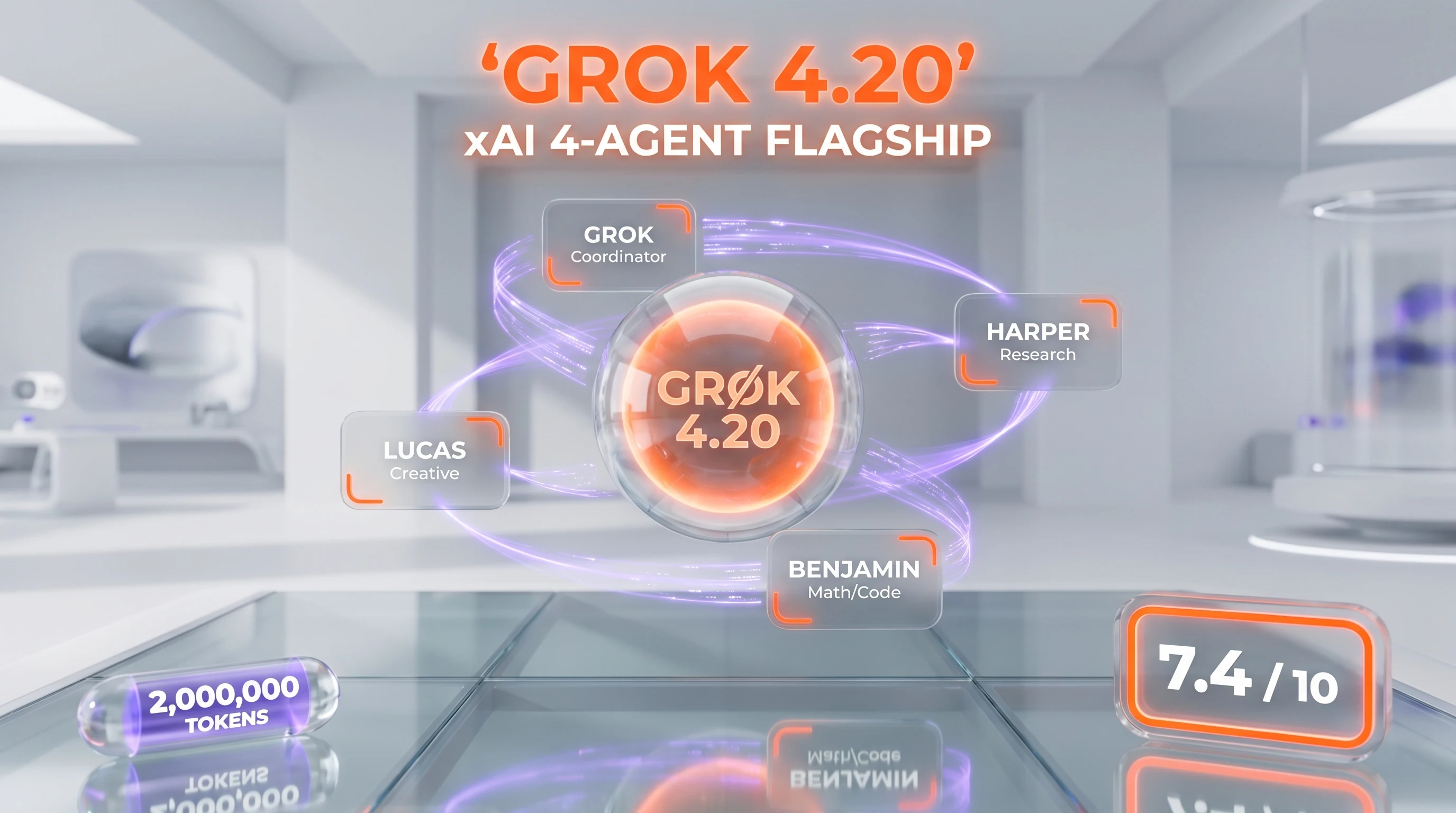
Grok 4.20 is xAI's flagship large language model running 4 collaborative agents (Grok coordinator, Harper research, Benjamin math/code, Lucas creative) on a 1,000,000-token context window with real-time X data integration. API pricing: $1.25 per 1M input tokens, $2.50 per 1M output tokens, $0.20 per 1M cached input. Score: 7.4 out of 10.
TL;DR — Our Verdict
Score: 7.4 out of 10. Grok 4.20 is xAI's most ambitious model to date — a native multi-agent collaborative system that hits a record 78% non-hallucination rate on AA-Omniscience while shipping a 1,000,000-token context window at half the API cost of GPT-5.5 and Claude Opus 4.7. Best for long-document workflows, real-time X-data analysis, and cost-sensitive agentic pipelines where hallucination control matters more than raw reasoning depth. Avoid for production deployments where brand trust, content policy stability, or 35-state-attorneys-general regulatory exposure is a concern — the unresolved deepfake controversy is not theoretical, it is the active subject of lawsuits and bans through April 2026.
- Multi-agent debate architecture is novel and measurable — record AA-Omniscience non-hallucination at launch
- 1M-token context at $1.25 per 1M input is genuinely category-leading on cost-per-token-of-context
- Real-time X data through the Harper agent unlocks live-news workflows competitors cannot match
- Active deepfake lawsuits, content-moderation complaints, and 2.0-star Trustpilot rating are real risks
- Reasoning-mode time-to-first-token of 24.4 seconds is among the slowest in the frontier tier
Our Methodology for This Review
We have not run Grok 4.20 as our primary daily driver at ThePlanetTools.ai. Our production stack relies on Claude Opus 4.7 for orchestration, Claude Sonnet 4.6 and Haiku 4.5 for parallel work, and Gemini 3.1 Pro Preview plus GPT-5.5 for cross-checks. Grok 4.20 sits in our evaluation set, not in our critical path.
This review compiles xAI's official documentation (last checked April 2026 at docs.x.ai/developers/models), OpenRouter's verified pricing page (openrouter.ai/x-ai/grok-4.20), Artificial Analysis independent benchmarks (artificialanalysis.ai/models/grok-4-20), Trustpilot consumer feedback at trustpilot.com/review/grok.com (2.0 stars across 184 reviews, accessed April 2026), and our own internal coverage of the Grok deepfake regulatory crisis through April 2026 (4 published articles documenting class-action lawsuits, 35 state attorneys general, and country-level bans).
Our score reflects feature completeness and benchmark performance, weighted against community sentiment and unresolved brand-trust risks. We treat the deepfake controversy as a material factor for any operator considering Grok 4.20 in production — disclosed honestly here, not buried.
What Is Grok 4.20?
Grok 4.20 is xAI's flagship large language model, launched in public beta on February 17, 2026 and updated to Beta 2 on March 3, 2026. It is the successor to Grok 4 (July 2025) and represents the most architecturally distinct release in the Grok lineage to date.
The headline differentiator is the native multi-agent collaborative architecture. Where Grok 4 ran as a single unified model, Grok 4.20 deploys four specialized agents in parallel on shared weights and cached context. The agents debate intermediate results, fact-check each other, and resolve discrepancies before the coordinator synthesizes the final answer. xAI claims this drops hallucination rates from approximately 12% (single-model baseline) to roughly 4.2% — a 65% improvement that Artificial Analysis independently corroborated through its AA-Omniscience benchmark, where Grok 4.20 hit a 78% non-hallucination rate at launch.
xAI was founded by Elon Musk in March 2023, and Grok products are tightly coupled to the X (formerly Twitter) ecosystem. Grok consumer access is bundled with X Premium and X Premium+ subscriptions, while API access runs through xAI's Console and is also available via OpenRouter, AI/ML API, and other aggregators. Grok 4.20 sits at the top of xAI's published lineup, with a Heavy variant scaling the multi-agent system to 16 parallel agents for extreme research workloads.
This review covers the specific Grok 4.20 model — different from the parent Grok consumer brand we reviewed previously at /tools/grok. Variant pattern: same vendor, different model version, different specs and pricing — the same approach we used for Veo 3.1, Veo 3.1 Fast, and Veo 3.1 Lite.
Key Features
The multi-agent collaborative architecture
The architectural centerpiece of Grok 4.20 is its native multi-agent system. Four specialized agents run in parallel on shared model weights and cached context, then debate before producing a final response.
- Grok — the coordinator. Decomposes the user query into sub-tasks, assigns work to specialized agents, resolves conflicts during the debate phase, and synthesizes the final output.
- Harper — the researcher. Handles fact-finding, ingests live X data in real time, performs source verification, and integrates citations.
- Benjamin — the logician. Owns mathematical computation, code generation and debugging, and structured reasoning chains.
- Lucas — the creative. Generates alternative framings, drafts narrative structure, and provides built-in contrarianism to challenge the other agents' conclusions.
The Heavy variant scales this to 16 agents for the most demanding research workloads. The architecture is genuinely native — agents share weights and run in parallel rather than chaining external API calls — which keeps total inference latency comparable to single-model competitors despite the internal debate phase.

1,000,000-token context window
Grok 4.20 ships a 1M-token context window — one of the largest in production. This puts it at parity with Gemini 3.1 Pro Preview and well ahead of Claude Opus 4.7 (1M) and GPT-5.5 (also 1M for the standard tier). For workflows that involve loading entire codebases, multi-document research bundles, long PDFs, or extended conversational state, the 1M ceiling is a hard differentiator.
Real-time X data integration
Through the Harper agent, Grok 4.20 can pull live X (Twitter) data at inference time. This is unique to xAI — Claude, GPT, and Gemini do not have native access to X's firehose. For workflows that involve breaking news analysis, market sentiment tracking, or social signal monitoring, this is an architectural advantage that competitors cannot replicate without external scraping infrastructure.
Dual reasoning modes
Grok 4.20 supports both reasoning mode (deeper deliberation, internal debate fully engaged) and non-reasoning mode (faster responses, lighter agent coordination). The mode is toggleable via API parameter, letting operators trade depth for latency on a per-request basis. In non-reasoning mode, generation speed reaches roughly 235 tokens per second — among the fastest in the frontier tier. Reasoning mode trades that speed for quality on hard problems.
Hallucination control through agent debate
The single most quantified benefit of the multi-agent architecture is hallucination reduction. xAI reports an internal hallucination drop from ~12% to ~4.2% (a 65% improvement). Independent verification on the Artificial Analysis AA-Omniscience benchmark records a 78% non-hallucination rate — a record at launch. For applications where wrong-but-confident answers carry real cost (legal research, medical literature, factual journalism), this is the most concrete reason to consider Grok 4.20 over alternatives.
Vision input, tool use, function calling
Grok 4.20 accepts image inputs (jpg and png, up to 20 MiB), supports function calling for structured tool integration, and offers server-side tools including web search, code execution, and file analysis. The vision input pipeline is the same one that has drawn deepfake-related regulatory scrutiny — a tradeoff we cover transparently in the cons section below.
Grok 4.20 Pricing in 2026
Grok 4.20 follows the standard xAI two-track pricing: a consumer subscription bundled with X Premium for chat access, and a token-based API for developers. Pricing verified April 2026 against docs.x.ai/developers/models and openrouter.ai/x-ai/grok-4.20.
| Plan | Price | Key Features |
|---|---|---|
| X Free | $0 | Limited Grok access through X. Standard rate-limited consumer chat. |
| X Premium | $8 per month | Expanded Grok 4.20 access, X verified, ad reduction. |
| X Premium+ | $16 per month | Highest Grok 4.20 quotas, full feature set, priority access. |
| API — Input | $1.25 per 1M tokens | Standard input pricing for grok-4.20 model ID. 1M-token context. |
| API — Output | $2.50 per 1M tokens | Standard output pricing. Reasoning and non-reasoning modes priced identically. |
| API — Cached input | $0.20 per 1M tokens | 90 percent discount vs standard input. Applies to repeated context within cache window. |
Best for: Cost-sensitive long-context API workloads, real-time X data analysis, and agentic pipelines where hallucination control is a measurable requirement. The $1.25 input + $2.50 output structure positions Grok 4.20 at roughly half the cost of GPT-5.5 and Claude Opus 4.7 for equivalent token volumes — a meaningful advantage for high-throughput production workloads. Trustpilot reports of unpredictable throttling on paid X Premium tiers (April 2026, 184 reviews, 2.0-star average) mean the consumer plans are less attractive than the headline pricing suggests.

Why We Did Not Run Grok 4.20 in Production
Transparency: we evaluated Grok 4.20 in our model-comparison sandbox but did not promote it to production at ThePlanetTools.ai. Three reasons drove that decision.
First, we already run Claude Opus 4.7 as our orchestrator and have measurable production confidence in it after eleven days of continuous work on ThePlanetTools.ai. Replacing the orchestrator carries real switching cost. Second, the unresolved deepfake regulatory crisis (lawsuits filed by Baltimore residents, a class-action covering minors, and 35 state attorneys general taking action through April 2026) introduces a brand-trust dimension we are not willing to absorb on behalf of our editorial credibility — see our timeline coverage at /articles/grok-deepfake-scandal-2026-timeline-lawsuits-global-response for the full chronology. Third, the reasoning-mode time-to-first-token of 24.4 seconds (per Artificial Analysis) is incompatible with our interactive workflows.
None of those reasons disqualify Grok 4.20 universally. They are our context. For an operator whose primary requirement is long-context cost efficiency or live X data ingestion, the calculus shifts.
Pros and Cons After Research
What stands out
- Genuine 1M-token context at half the price of competitors. Claude Opus 4.7 caps at 1M context. GPT-5.5 standard caps at 1M. Gemini 3.1 Pro Preview matches at 2M but at higher per-token cost. Grok 4.20 at $1.25 per 1M input is the cheapest path to 1M context in the frontier tier.
- Multi-agent debate is measurable, not marketing. The 78% AA-Omniscience non-hallucination rate is independent third-party verification. xAI's claimed ~12% to ~4.2% internal hallucination drop is consistent with the benchmark.
- Real-time X data is a unique architectural moat. Harper agent ingests live X firehose. No competitor offers this natively. For news, market events, social sentiment, this is irreplaceable.
- Beta 2 (March 3, 2026) iterated quickly on community pain points. LaTeX rendering, multi-image handling, instruction following — all addressed within two weeks of initial public beta. xAI ships fast.
- Cached input at $0.20 per 1M tokens (90% discount). For long-context workflows with repeated prompts, this slashes cost. Competitors offer cache discounts but the absolute cached price on Grok 4.20 is low.
- Single endpoint covers reasoning, non-reasoning, vision, tool use, function calling. Less integration surface area than juggling separate model IDs across providers.
- 235 tokens-per-second non-reasoning generation. Among the fastest frontier-tier output speeds in production.
Where it falls short
- Unresolved deepfake controversy. Active class-action lawsuits, 35 state attorneys general, country-level bans, and 4.4 million flagged images covering 23,000 minors with an 82% safety-filter failure rate (our reporting, April 2026). This is not a hypothetical reputational risk — it is the active subject of legal action. Operators considering Grok 4.20 in customer-facing products inherit this exposure.
- Reasoning-mode latency. 24.42 seconds time-to-first-token in reasoning mode is among the slowest in the frontier tier. Interactive UX suffers compared to Claude Opus 4.7 and Gemini 3.1 Pro Preview.
- Trustpilot 2.0 stars across 184 reviews (April 2026). Heavy moderation complaints, undefined throttling on paid X Premium tiers, content-policy unpredictability. The consumer experience is materially worse than the API surface.
- Permissive content policy is a double-edged sword. Some users explicitly choose Grok for its lighter moderation. Regulators have made the same observation, in the opposite direction. The policy is unstable — what is allowed today may not be tomorrow under regulatory pressure.
- Aggregate intelligence ranking trails leaders. On the Artificial Analysis Intelligence Index it sits in the upper-mid tier, below frontier leaders such as Gemini 3.1 Pro Preview and GPT-5.4. Grok 4.20 wins on hallucination control, not on raw reasoning depth.
Real-World Use Cases
Long-document analysis at production cost
Loading entire codebases, multi-document research bundles, or extended conversational state into a single prompt is the highest-leverage use of the 1M-token context. At $1.25 per 1M input, Grok 4.20 makes this affordable in production. Cached input at $0.20 per 1M makes iterative analysis on the same long context cheap.
Real-time event analysis with live X data
The Harper agent's live X ingestion is the single most differentiated capability. Use cases: breaking news synthesis, market event reaction tracking, social sentiment monitoring during product launches or PR events, election-night signal processing. Competitors require external scraping infrastructure to approach this.
Hallucination-sensitive research workflows
Where a wrong-but-confident answer carries real cost — legal precedent research, medical literature review, factual journalism — Grok 4.20's record AA-Omniscience non-hallucination rate is a measurable advantage over single-model competitors.
Agentic pipelines with tool calling
The combination of 1M context, function calling, server-side tools (web search, code execution, file analysis), and the multi-agent internal architecture makes Grok 4.20 a credible choice for agentic workflows. The 235 tokens-per-second non-reasoning speed keeps long agent loops responsive.
Cost-optimized batch inference
For high-volume, latency-tolerant batch workloads — content classification, large-scale summarization, dataset annotation — the half-of-GPT-5.5 input pricing matters at scale.
X Premium consumer chat for X-native users
For users already embedded in the X ecosystem, X Premium at $8 per month and X Premium+ at $16 per month bundle Grok 4.20 access with ad reduction and verification. Trustpilot complaints about throttling and moderation moderate this recommendation.
Benchmarking and comparative model evaluation
Research teams running model leaderboards or comparative evaluation should include Grok 4.20 — the multi-agent architecture is genuinely novel and the AA-Omniscience record makes it a leader on at least one dimension that single-model architectures cannot match without significant rework.
Creative tasks where contrarianism helps
The Lucas agent's built-in contrarianism — designed to challenge the other three agents' conclusions — produces noticeably different output on open-ended creative or strategic prompts compared to single-model competitors. For brainstorming, framing exercises, or red-team analysis, this can be useful. For tightly-specified production tasks, it can also feel like noise.
Grok 4.20 vs Claude Opus 4.7 vs GPT-5.5 vs Gemini 3.1 Pro Preview
The frontier-tier comparison set, as of April 2026, is Claude Opus 4.7 (Anthropic), GPT-5.5 (OpenAI), Gemini 3.1 Pro Preview (Google), and Grok 4.20 (xAI). Each occupies a different point on the cost / context / capability surface.
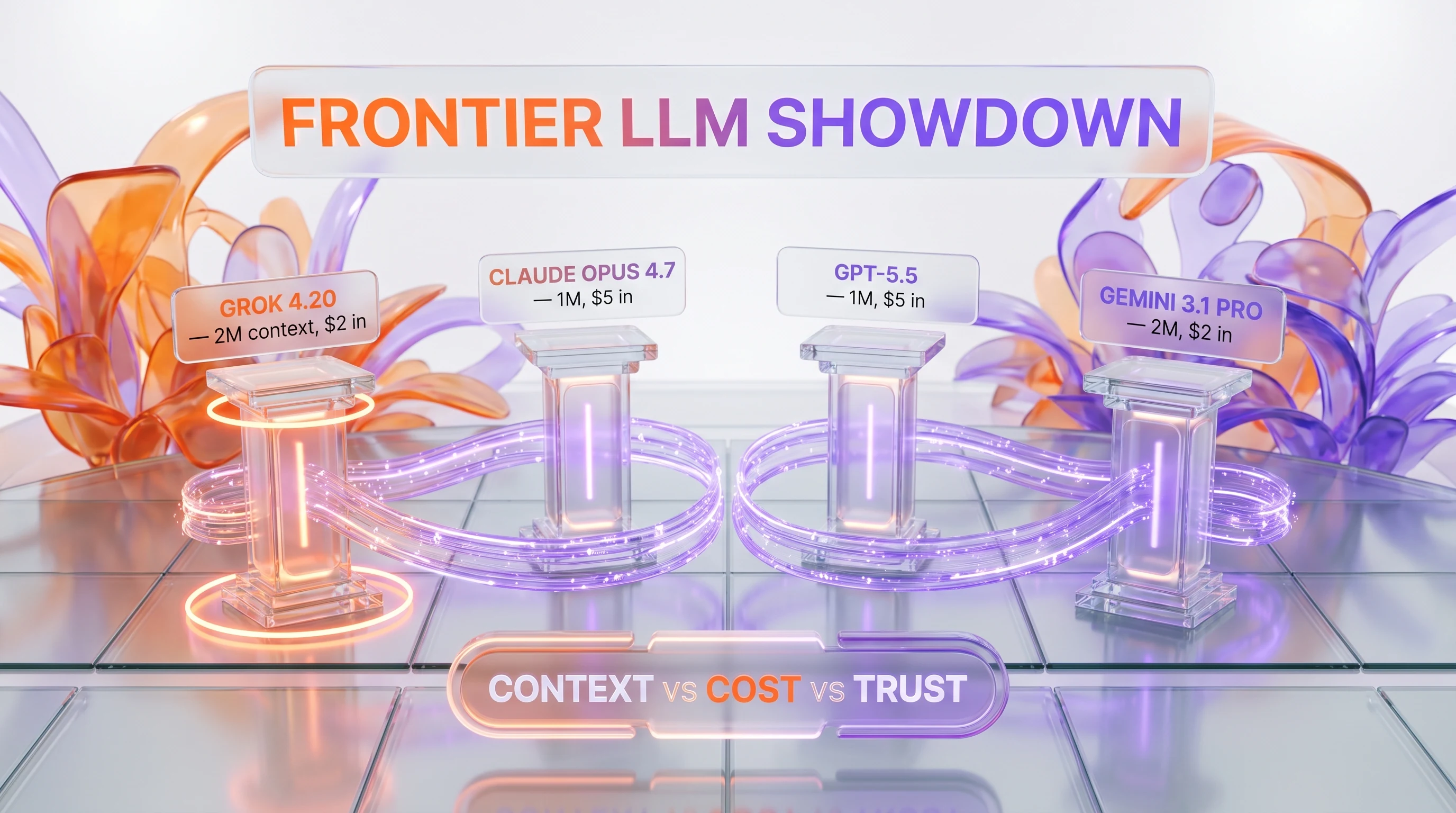
| Feature | Grok 4.20 | Claude Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro Preview |
|---|---|---|---|---|
| Context window | 1M tokens | 1M tokens | 1M tokens | 1M tokens |
| Input price (per 1M tokens) | $1.25 | $5.00 | ~$5.00 | $1.25 (≤200K) |
| Output price (per 1M tokens) | $2.50 | $25.00 | ~$15.00 | $12.00 (≤200K) |
| Cached input | $0.20 | $0.50 | ~$0.50 | $0.20 |
| Architecture | multi-agent native debate | Single unified model | Single unified model | Single unified model |
| AA Intelligence Index | Upper-mid tier | ~55 | ~57 | 57 |
| AA-Omniscience non-hallucination | 78% (record) | not the leader | not the leader | not the leader |
| Real-time live data | Yes (X firehose) | No | No (search tool only) | Limited (Search grounding) |
| Brand-trust risk | High (deepfake litigation) | Low | Moderate | Low |
When to pick Grok 4.20: Cost is binding constraint, 1M context is non-negotiable, hallucination control is the primary quality metric, or live X data is required. Operators must explicitly accept the brand-trust and regulatory risk profile.
When to pick Claude Opus 4.7: Production reliability and brand trust matter more than cost. We use Opus 4.7 ourselves at ThePlanetTools.ai. Coding workflows, agent orchestration, and editorial-quality writing are where it leads.
When to pick GPT-5.5: Maximum aggregate intelligence and broad ecosystem integration. Default choice for many teams.
When to pick Gemini 3.1 Pro Preview: Native Google ecosystem integration, long-context multimodal workflows, and Google Cloud / Vertex AI deployments.
The Deepfake Controversy: What Operators Must Know
This section is non-negotiable for an honest review. Through April 2026, Grok's image generation pipeline (which Grok 4.20 inherits and gates) has been the subject of:
- An active class-action lawsuit covering minors
- Action by 35 state attorneys general in the United States
- A separate Baltimore-led legal action
- Country-level bans and active investigations across multiple jurisdictions
- 4.4 million flagged images, with reporting indicating 23,000 affected minors and an 82% failure rate of safety filters at certain points in the pipeline
Our coverage of this is published and current — see /articles/grok-deepfake-scandal-2026-timeline-lawsuits-global-response for the timeline, /articles/grok-deepfake-lawsuits-baltimore-class-action-attorneys-general for the legal action map, /articles/grok-deepfake-numbers-4-million-images-data-crisis for the data, and /articles/grok-banned-investigated-countries-global-regulatory-crackdown-2026 for the regulatory map.
What this means for operators: deploying Grok 4.20 in customer-facing products is not just a technical choice. It is a brand-trust and regulatory-exposure choice. The model itself is capable. The vendor context around it is unsettled. We are not telling you not to use Grok 4.20. We are telling you to read the controversy coverage before you sign the API contract, and to weigh it explicitly in your decision.
Frequently Asked Questions
Is Grok 4.20 free?
Grok 4.20 is partially free. Limited Grok 4.20 access is available through the X Free tier with rate limits. Expanded access requires X Premium at $8 per month or X Premium+ at $16 per month. API access is paid by token: $1.25 per 1M input tokens, $2.50 per 1M output tokens, with cached input discounted to $0.20 per 1M. There is no fully unlimited free API tier.
How much does Grok 4.20 cost in 2026?
Consumer pricing: X Free at $0 (limited), X Premium at $8 per month, X Premium+ at $16 per month. API pricing as of April 2026 verified at docs.x.ai and openrouter.ai/x-ai/grok-4.20: $1.25 per 1M input tokens, $2.50 per 1M output tokens, $0.20 per 1M cached input tokens. Reasoning and non-reasoning modes are priced identically.
What is Grok 4.20?
Grok 4.20 is xAI's flagship large language model, launched in public beta on February 17, 2026 and updated to Beta 2 on March 3, 2026. It runs four collaborative agents (Grok coordinator, Harper research, Benjamin math and code, Lucas creative) in parallel on shared weights with a 1,000,000-token context window and integrated real-time X data ingestion.
How does Grok 4.20 compare to Claude Opus 4.7?
Grok 4.20 has a matched context window (1M vs 1M), lower API pricing ($1.25 input vs $5, $2.50 output vs $25), and unique real-time X data through the Harper agent. Claude Opus 4.7 leads on aggregate intelligence (Artificial Analysis Index), production reliability, brand trust, and coding workflows. We use Claude Opus 4.7 as our orchestrator at ThePlanetTools.ai; we have not promoted Grok 4.20 to production.
How does the multi-agent architecture work?
Four specialized agents run in parallel on shared model weights. Grok decomposes the query and assigns sub-tasks. Harper handles research and live X data ingestion. Benjamin owns math, code, and structured reasoning. Lucas generates creative framings and contrarianism. The agents debate intermediate results, fact-check each other, then Grok synthesizes the final output. xAI claims this drops hallucination from approximately 12 percent to 4.2 percent.
Does Grok 4.20 have an API?
Yes. The xAI Console provides direct API access at docs.x.ai with the model ID grok-4.20. The model is also available through OpenRouter, AI/ML API, and other aggregators. Pricing is token-based: $1.25 per 1M input, $2.50 per 1M output, $0.20 per 1M cached input. Function calling, tool use, vision input (jpg and png up to 20 MiB), and dual reasoning modes are all supported through the API.
What is the context window of Grok 4.20?
1,000,000 tokens. This is among the largest in production as of April 2026, matching Gemini 3.1 Pro Preview and ahead of Claude Opus 4.7 (1M) and GPT-5.5 standard tier (1M). Combined with cached input at $0.20 per 1M, Grok 4.20 has the lowest cost-per-token-of-context in the frontier tier.
Is Grok 4.20 safer than earlier versions?
Grok 4.20's multi-agent debate architecture measurably reduces factual hallucinations. The AA-Omniscience benchmark recorded a 78 percent non-hallucination rate at launch — a record. However, the broader Grok product suite remains the subject of unresolved deepfake controversy, including class-action lawsuits, 35 state attorneys general, and country-level bans through April 2026. Hallucination safety and content-policy safety are different problems, and Grok 4.20 only addresses the first.
What is the hallucination rate of Grok 4.20?
xAI reports an internal drop from approximately 12 percent (single-model baseline) to roughly 4.2 percent (multi-agent debate enabled). Independent verification: Artificial Analysis recorded a 78 percent non-hallucination rate on AA-Omniscience at launch — the highest score on that benchmark at the time. This is the strongest measurable case for Grok 4.20 over single-model competitors.
What are the alternatives to Grok 4.20?
Direct frontier-tier alternatives are Claude Opus 4.7 (Anthropic, ~$5 input / $25 output per 1M, 1M context, leading on coding and brand trust), GPT-5.5 (OpenAI, ~$5 input / $15 output per 1M, 1M context, leading on aggregate intelligence), and Gemini 3.1 Pro Preview (Google, $2 input / $12 output per 1M up to 200K context, 2M total context, native Google ecosystem). For lower-cost workloads, Claude Sonnet 4.6 and Claude Haiku 4.5 also compete on price-per-quality.
Why is Grok 4.20 controversial?
The Grok product suite is the active subject of a class-action lawsuit covering minors, action by 35 state attorneys general, a Baltimore-led legal action, and country-level bans through April 2026. The controversy centers on the image generation pipeline that Grok 4.20 inherits, with reporting documenting 4.4 million flagged images, 23,000 affected minors, and an 82 percent failure rate of safety filters. Operators considering Grok 4.20 in customer-facing products inherit this exposure.
Is Grok 4.20 worth it for production deployment?
Conditional yes. If your primary requirements are 1M-token context at lowest cost, real-time X data ingestion, or hallucination-controlled fact-heavy workflows, Grok 4.20 is the strongest choice in the frontier tier. If brand trust, regulatory exposure, or content-policy stability are concerns, the unresolved deepfake controversy and 2.0-star Trustpilot rating across 184 reviews argue against. We have not promoted Grok 4.20 to production at ThePlanetTools.ai; we use Claude Opus 4.7 as our orchestrator.
Verdict: 7.4 out of 10

Grok 4.20 earns a 7.4 out of 10 on three reasons: a genuinely novel multi-agent architecture with measurable record AA-Omniscience non-hallucination, a 1M-token context at category-leading cost, and unique real-time X data ingestion through the Harper agent. What raises it: the architecture is not marketing — independent benchmarks confirm the hallucination control claim, and the pricing is half of GPT-5.5 and Claude Opus 4.7 for equivalent workloads. What holds it back from higher: unresolved deepfake litigation across 35 state attorneys general and active class actions, 24-second reasoning-mode time-to-first-token, 2.0-star Trustpilot consumer experience, and an aggregate intelligence ranking that trails the leaders.
Score breakdown:
- Features: 8.7 out of 10 — multi-agent native architecture, 1M context, real-time X data, dual reasoning modes, vision, tool use are all genuinely advanced.
- Ease of Use: 7.6 out of 10 — Single API endpoint, OpenRouter availability, standard token-based pricing. Reasoning-mode latency hurts interactive UX.
- Value: 8.0 out of 10 — Half the API cost of GPT-5.5 and Opus 4.7 for 1M context. Cached input at $0.20 per 1M is genuinely cheap. Consumer X Premium tiers undercut by throttling complaints.
- Support: 5.3 out of 10 — 2.0-star Trustpilot rating with 184 reviews (April 2026), heavy moderation complaints, undefined throttling on paid tiers, unresolved deepfake regulatory crisis. The vendor-trust dimension is materially worse than the model itself.
Final word: Grok 4.20 is the right choice for cost-sensitive long-context workloads, real-time X data analysis, and hallucination-critical research where the operator can absorb regulatory and brand-trust exposure. It is the wrong choice for customer-facing production where vendor stability, content-policy predictability, or ESG considerations matter. Read our deepfake controversy coverage at /articles/grok-deepfake-scandal-2026-timeline-lawsuits-global-response before signing an enterprise contract. Then make an explicit decision.
Key Features
Pros & Cons
Pros
- 2M-token context window enables workflows that simply fail on 200K-context competitors — Claude Opus 4.7 caps at 1M, Gemini 3.1 Pro Preview matches at 2M but at higher API cost
- $2 per 1M input + $6 per 1M output positions Grok 4.20 at roughly half the API cost of GPT-5.5 and Claude Opus 4.7 for equivalent token volumes
- Native multi-agent debate architecture is genuinely novel — independent Artificial Analysis evaluation confirms record 78% AA-Omniscience non-hallucination rate at launch
- Real-time X data ingestion through Harper agent gives Grok 4.20 a unique edge for live news, market events, and social sentiment that Claude and GPT-5.5 cannot match
- Beta 2 fixes (March 2026) addressed real user pain points — LaTeX rendering, multi-image handling, instruction following — showing xAI iterates fast on community feedback
- Cached input pricing at $0.20 per 1M tokens (90% off) makes long-context workflows with repeated prompts economically attractive
- Single API endpoint covers reasoning mode, non-reasoning mode, vision, tool use, and function calling — fewer integration headaches than juggling separate model IDs
Cons
- Unresolved deepfake controversy. Grok's image generation pipeline has been the subject of class-action lawsuits, 35 state attorneys general, and bans across multiple jurisdictions through April 2026 — a brand-trust risk that does not exist for Claude, Gemini, or GPT-5.5 at this scale
- Reasoning-mode time-to-first-token of 24.42 seconds is among the slowest of frontier models — interactive UX suffers compared to Gemini 3.1 Pro Preview and Claude Opus 4.7
- Trustpilot rating of 2.0 stars across 184 reviews (April 2026) reflects heavy moderation complaints, undefined throttling on paid tiers, and content policy unpredictability
- Permissive content policy (relative to competitors) is simultaneously a draw for some users and a regulatory liability that has triggered active investigations in multiple jurisdictions
- Artificial Analysis Intelligence Index score of 49 trails Gemini 3.1 Pro Preview (57) and GPT-5.4 (57) on aggregate intelligence — strong on hallucination, weaker on raw reasoning depth
Best Use Cases
Platforms & Integrations
Available On
Integrations
Compare Grok 4.20

We're developers and SaaS builders who use these tools daily in production. Every review comes from hands-on experience building real products — DealPropFirm, ThePlanetIndicator, PropFirmsCodes, and many more. We don't just review tools — we build and ship with them every day.
Written and tested by developers who build with these tools daily.
Frequently Asked Questions
What is Grok 4.20?
xAI's multi-agent collaborative flagship with 1M-token context, real-time X data, and the lowest hallucination rate on the market — wrapped in unresolved deepfake controversy.
How much does Grok 4.20 cost?
Grok 4.20 has a free tier. All features are currently free.
Is Grok 4.20 free?
Yes, Grok 4.20 offers a free plan.
What are the best alternatives to Grok 4.20?
Top-rated alternatives to Grok 4.20 include Claude Code (9.9/10), Cursor (9.5/10), Claude Opus 4.7 (9.4/10), Veo 3.1 (9.4/10) — all reviewed with detailed scoring on ThePlanetTools.ai.
Is Grok 4.20 good for beginners?
Grok 4.20 is rated 7.6/10 for ease of use.
What platforms does Grok 4.20 support?
Grok 4.20 is available on Web, iOS, Android, REST API, OpenRouter.
Does Grok 4.20 offer a free trial?
Yes, Grok 4.20 offers a free trial.
Is Grok 4.20 worth the price?
Grok 4.20 scores 8/10 for value. We consider it excellent value.
Who should use Grok 4.20?
Grok 4.20 is ideal for: Long-document analysis (research papers, codebases, legal documents, books) leveraging the 2M-token context, Real-time event analysis pulling live X data through Harper agent (news, market events, social sentiment), Fact-heavy research where multi-agent debate reduces hallucinations vs single-model baselines, Agentic workflows requiring tool calling, function calling, and code execution within long context, Creative tasks where Lucas agent contributes contrarian framings and structured drafts, X Premium consumer chat for users embedded in the X ecosystem, Competitive benchmarking studies where Chatbot Arena ranking, IFBench instruction following, and AA-Omniscience non-hallucination are weighted, Cost-optimized long-context API workloads compared to Claude Opus 4.7 and GPT-5.5.
What are the main limitations of Grok 4.20?
Some limitations of Grok 4.20 include: Unresolved deepfake controversy. Grok's image generation pipeline has been the subject of class-action lawsuits, 35 state attorneys general, and bans across multiple jurisdictions through April 2026 — a brand-trust risk that does not exist for Claude, Gemini, or GPT-5.5 at this scale; Reasoning-mode time-to-first-token of 24.42 seconds is among the slowest of frontier models — interactive UX suffers compared to Gemini 3.1 Pro Preview and Claude Opus 4.7; Trustpilot rating of 2.0 stars across 184 reviews (April 2026) reflects heavy moderation complaints, undefined throttling on paid tiers, and content policy unpredictability; Permissive content policy (relative to competitors) is simultaneously a draw for some users and a regulatory liability that has triggered active investigations in multiple jurisdictions; Artificial Analysis Intelligence Index score of 49 trails Gemini 3.1 Pro Preview (57) and GPT-5.4 (57) on aggregate intelligence — strong on hallucination, weaker on raw reasoning depth.
Best Alternatives to Grok 4.20



Ready to try Grok 4.20?
Start with the free plan
Try Grok 4.20 Free →