Mistral Large 3
Mistral AI's open-weight 675B-MoE multimodal flagship — 256K context, Apache 2.0, EU-sovereign at $0.50 per 1M input tokens.
Quick Summary
Mistral Large 3 is Mistral AI's open-weight multimodal flagship, a 675B/41B-active Mixture-of-Experts model with a 256K context window, native vision, and an Apache 2.0 license. La Plateforme pricing is $0.50 per 1M input tokens and $1.50 per 1M output tokens. Score 8.5/10.

Mistral Large 3 is Mistral AI's open-weight multimodal flagship: a 675B-parameter Mixture-of-Experts model with 41B active parameters per token, a 256K context window, native vision, and an Apache 2.0 license. La Plateforme pricing is $0.50 per 1M input tokens and $1.50 per 1M output tokens. Score: 8.5 out of 10.
TL;DR — Our Verdict
Score: 8.5 out of 10. Mistral Large 3 (v25.12, API id mistral-large-2512) is the strongest fully open-weight European LLM in 2026: 675B-parameter MoE with 41B active, 256K context, native multimodality, and the rare Apache 2.0 license. It is best for GDPR-conscious enterprises and teams that want self-hostable weights on a single 8xH100 node without revenue clauses. Avoid it as your daily driver if you need state-of-the-art reasoning or sub-second TTFT — Claude Opus 4.7, GPT-5.5, and DeepSeek V4 still pull ahead on Intelligence Index and latency.
- ✅ Apache 2.0 open weights, no revenue threshold, redistribution and fine-tuning allowed
- ✅ Native multimodal (vision fused into the model) + 256K context + EU-sovereign hosting
- ❌ Slower than peers — ~47-50 t/s output, 11s+ TTFT on La Plateforme
- ❌ Intelligence Index ranks in the lower tier — well behind the frontier, trailing reasoning-tuned DeepSeek V4 and closed flagships GPT-5.5 / Opus 4.7
Our Methodology for This Review
We have not yet run Mistral Large 3 in a sustained production workload at ThePlanetTools — our production stack currently runs on Claude Opus 4.7 and Sonnet 4.6 for cost and quality reasons. This review compiles Mistral's official documentation (docs.mistral.ai/models/mistral-large-3-25-12, last checked April 2026), the Hugging Face model card for mistralai/Mistral-Large-3-675B-Instruct-2512, the Artificial Analysis benchmark suite (Intelligence Index, output speed, TTFT, pricing), the Mistral 3 launch announcement on mistral.ai/news/mistral-3, and community signal from Reddit r/LocalLLaMA plus LMArena leaderboards. Pricing is taken directly from La Plateforme via docs.mistral.ai and cross-checked against OpenRouter's listing for mistralai/mistral-large-2512. Our 8.5 out of 10 score weights feature completeness, license terms, multimodality, and price-per-token, and discounts the per-token throughput where it lags peers.
What Is Mistral Large 3?
Mistral Large 3 is the December 2025 v25.12 flagship of Mistral AI, the Paris-based AI lab founded in 2023 by former Meta AI and DeepMind researchers Arthur Mensch, Guillaume Lample, and Timothée Lacroix. It is the third generation of the Mistral Large line and the first to ship as a fully open-weight flagship under the permissive Apache 2.0 license — a major shift from Mistral Large 2's Mistral Research License (MRL), which limited commercial redistribution.
Architecturally, Mistral Large 3 is a granular sparse Mixture-of-Experts (MoE) model with 675B total parameters and 41B active per forward pass. A vision encoder of roughly 2.5B parameters is fused directly into the architecture rather than bolted on as a separate model, making images, PDFs, charts, and layout-aware OCR first-class inputs. Mistral describes the design as "single-node deployable" — meaning the full 675B weights fit on one 8xH100 80GB or equivalent node when quantized to FP8 or NVFP4.
The model is positioned at the top of a wider Mistral 3 family that shipped over the first months of 2026: Mistral Small 4 (hybrid instruct/reasoning/coding), Devstral 2 (agentic coding), Voxtral (text-to-speech in nine languages), Magistral (reasoning variants), Leanstral (formal proof verification), OCR 3, Mistral Moderation 2, and the Forge enterprise custom training platform. This release cadence is part of why Mistral retains its position as the European reference lab even as US labs and DeepSeek dominate the headlines.
Key Features
Granular Mixture-of-Experts at 675B / 41B active
The MoE design is the engineering decision that defines Mistral Large 3. Total parameters of 675B put it in the same scale band as DeepSeek V3 0324 (671B), DeepSeek V4, and Llama 4 Maverick, while the 41B active footprint per token means inference cost is closer to a 41B dense model than a 675B one. The "granular" qualifier refers to a high number of small experts (rather than a few large ones) and a top-k routing strategy chosen for both quality and single-node deployability.
Native multimodal — vision fused into the architecture
The vision encoder is approximately 2.5B parameters, fused into the model rather than added as a separate stage. In practice this matters for two reasons: first, Mistral Large 3 handles images and PDFs as first-class inputs without requiring a separate Pixtral-style call; second, the model can perform layout-aware document understanding — extracting structured data from invoices, scanned forms, charts, and diagrams in the same call as text reasoning. This is the same first-class multimodality posture that GPT-5.5 and Gemini 3.1 Pro adopt, and it is rare in the open-weight category.

256K-token context window
The 256K context window covers roughly 384 pages of standard text. It is currently at the upper end of the open-weight category — DeepSeek V4 ships with 128K, Llama 4 with 256K-1M depending on variant, and Qwen 3.6 with 256K. For long-document workloads (multi-PDF analysis, full codebase reasoning, lengthy legal contracts) Mistral Large 3 is competitive with the best of its class.
Function calling, structured outputs, tool use
La Plateforme exposes function calling, structured outputs, JSON mode, and a built-in tool catalogue (web search, code interpreter, image generation in Le Chat) via the mistral-large-2512 model id. The OpenAI-compatible API surface keeps migration friction low for teams already using GPT or Anthropic SDKs.
Apache 2.0 — the license differentiator
Apache 2.0 is the single biggest reason to evaluate Mistral Large 3 over its peers. It allows commercial use, redistribution, fine-tuning, and proprietary derivative works without revenue thresholds. Llama 4's Community License sets a 700M monthly active user ceiling and requires Meta brand attribution. DeepSeek V4 ships under MIT (similarly permissive), but DeepSeek's data and supply chain provenance remain a sticking point for some enterprises. For European regulated industries, the combination of Apache 2.0 + EU sovereignty is hard to beat.
Open-weight distribution and quantizations
Hugging Face hosts the full model family: Mistral-Large-3-675B-Instruct-2512 (FP8 native), -BF16 for evaluation, -NVFP4 for NVIDIA Hopper/Blackwell deployment, -Eagle for speculative decoding, and a -Base-2512 base model for fine-tuning research. RedHatAI, Unsloth, and the Mistral team itself maintain the official quantizations.
EU-sovereign hosting via Mistral AI Studio
Mistral AI Studio is Mistral's enterprise platform with EU data residency by default. For GDPR-conscious customers and EU AI Act-aligned procurement, this addresses one of the most common blocker objections to US-hosted closed models. AWS Bedrock and Azure AI Foundry also offer Mistral Large 3 in their EU regions for cross-cloud deployment.
Mistral Large 3 Pricing in 2026
Mistral exposes Mistral Large 3 in two distinct ways: token-based API pricing on La Plateforme (and major cloud marketplaces), and consumer subscriptions for Le Chat. Pricing was verified directly via WebFetch on docs.mistral.ai/models/mistral-large-3-25-12 and mistral.ai/pricing on April 2026.
| Plan | Price | Key Features |
|---|---|---|
| Le Chat — Free | $0 | Basic access to Le Chat consumer app, model selection limited, daily limits apply |
| Le Chat — Pro | $14.99 per month | Higher daily limits, priority access, Le Chat full feature set |
| Le Chat — Team | $24.99 per user per month | Collaboration, shared workspaces, admin controls |
| La Plateforme — Mistral Large 3 input | $0.50 per 1M input tokens | mistral-large-2512, function calling, structured outputs, 256K context, EU residency available |
| La Plateforme — Mistral Large 3 output | $1.50 per 1M output tokens | Standard inference, batch and fine-tuning available, OpenAI-compatible API |
| Self-hosted (Apache 2.0) | Free download | Hugging Face weights (FP8, BF16, NVFP4, Eagle), full commercial use under Apache 2.0 |
| Enterprise — Mistral AI Studio / Forge | Custom pricing | Private deployments, custom training (Forge), EU sovereignty, SLAs, dedicated support |

For context, OpenRouter lists Mistral Large 3 (mistralai/mistral-large-2512) at the same $0.50 input and $1.50 output rate, with Fireworks and Together AI broadly aligned. This makes Mistral Large 3 markedly cheaper than Claude Opus 4.7 ($5/$25 per MTok) and GPT-5.5, and roughly in the same band as DeepSeek V4 Pro discount tier ($0.435/$0.87 per MTok until May 31 2026 promo) and Llama 4 hosted inference.
Best for: European enterprises that need GDPR-resident hosting, regulated industries that want Apache 2.0 redistribution rights, and teams that intend to fine-tune or self-host on a single GPU node.
Benchmarks and Performance
On the Artificial Analysis Intelligence Index, Mistral Large 3 ranks in the lower tier, well behind the frontier — its edge is licensing, sovereignty, and deployment rather than raw reasoning rank. On the eight-language MMLU variant, it reaches roughly 85.5% accuracy, with MMLU-Pro reportedly in the low eighties, indicating robust reasoning under harder conditions. On the LMArena leaderboard, the model debuts at #2 in the open-source non-reasoning category and #6 overall in the open-weight category with an Elo around 1418.
The flip side: throughput. Mistral Large 3 generates output at ~47-50 tokens per second on La Plateforme, which is below the median of 50.5 t/s for its class on Artificial Analysis. Time-to-first-token sits around 11.30 seconds (with some measurements going as high as 31s under load) — substantially slower than the 2.42-second category median. For latency-sensitive products this is a real cost: a streaming chat experience that feels snappy on Claude Sonnet 4.6 will feel sluggish on Mistral Large 3 unless you front it with prompt caching and aggressive prefetching.
SimpleQA factual accuracy reportedly lands around 23.8%, lower than peer reasoning-tuned models. In practice this means Mistral Large 3 will hallucinate on long-tail factual queries more often than DeepSeek V4 or Magistral. Pair it with grounded retrieval (RAG) for any factually-sensitive use case rather than relying on parametric memory.
Pros and Cons After Research
What we liked
- Apache 2.0 license is a serious differentiator. Commercial use, redistribution, and fine-tuning are allowed with no revenue thresholds — a clean win over Llama 4's 700M MAU clause and Mistral's previous MRL releases.
- Open weights at flagship scale. A 675B/41B-active MoE on a single 8xH100 node is realistic for serious enterprises, not just hyperscalers, and the FP8/NVFP4/Eagle variants make production deployment easier.
- Native multimodal architecture. Fusing the 2.5B vision encoder into the model lets Mistral Large 3 handle PDFs, charts, and OCR as first-class inputs without a separate vision stage — cleaner than bolt-on vision pipelines.
- 256K context window is competitive with closed flagships. Long-document and codebase workloads that previously required Claude Opus 4.7 or GPT-5.5 can run on Mistral Large 3 at a fraction of the price.
- Pricing of $0.50 / $1.50 per 1M tokens beats most closed mid-tier models. For products that previously sat on Claude Sonnet 4.6 or GPT-5 mini, Mistral Large 3 is a credible cheaper alternative.
- EU-sovereign hosting by default. Mistral AI Studio keeps data resident in Europe, which addresses GDPR and EU AI Act objections better than US-hosted alternatives.
- Cross-cloud availability reduces lock-in. AWS Bedrock, Azure AI Foundry, IBM watsonx, OpenRouter, Fireworks, and Together AI all expose Mistral Large 3 with the same API contract.
Where it falls short
- Throughput trails peers. ~47-50 tokens per second on La Plateforme is below the median for open-weight non-reasoning models, and time-to-first-token of 11s+ feels sluggish on chat workloads. DeepSeek V4 Flash and Llama 4 hosted inference are noticeably faster.
- Intelligence Index ranks in the lower tier, well behind the frontier. Reasoning-tuned models like DeepSeek V4 and closed flagships GPT-5.5 and Claude Opus 4.7 are clearly ahead on hard reasoning tasks.
- SimpleQA factual accuracy ~23.8%. The model hallucinates confidently on long-tail facts more often than peer non-reasoning models. RAG grounding is mandatory for factual workloads.
- No dedicated reasoning variant inside the Large 3 family. Magistral covers reasoning separately, but it is positioned mid-tier rather than as a "Large 3 thinking" mode — a gap versus GPT-5.5's reasoning effort scale or Anthropic's extended thinking.
- Single-node still means 8xH100 80GB or equivalent. "Single-node deployable" is technically true but out of reach for individual developers or small teams without API budget.
Real-World Use Cases
GDPR-conscious European enterprises
Mistral AI Studio's EU residency by default makes Mistral Large 3 a defensible choice for healthcare, public sector, financial services, and any organisation under stricter data protection regimes. Procurement teams that previously rejected GPT-5.5 or Claude Opus 4.7 on data residency grounds can route workloads through Mistral without compromising on a 256K context flagship.
Self-hosted commercial deployment under Apache 2.0
The Apache 2.0 license unlocks scenarios that Llama 4 cannot serve: commercial redistribution above 700M MAU, fine-tuning and reselling, embedding into proprietary products without attribution clauses. Defense, government, and large-scale consumer products with strict licensing requirements gain an open-weight flagship option for the first time.
Long-document analysis at 256K tokens
Legal contracts, financial filings (10-K, 10-Q), regulatory submissions, and full codebases fit into a single context window without chunking. The native multimodal layer also handles diagrams, charts, and scanned forms in the same call.
Multimodal document extraction pipelines
Insurance, banking, and operations workflows that previously stitched together OCR + GPT-4 calls can collapse into a single Mistral Large 3 request. Invoices with logos and tables, scanned forms with checkboxes, charts with embedded numbers — all handled in one inference.
Multilingual European content workflows
85.5% on the eight-language MMLU variant and strong native French, German, Italian, Spanish, Portuguese, Dutch, and Polish coverage make Mistral Large 3 a credible alternative to GPT-5.5 for European customer support, content localisation, and multilingual RAG.
Open-weight fine-tuning research
The Mistral-Large-3-675B-Base-2512 base model is published on Hugging Face under Apache 2.0, giving researchers a flagship-scale base they can fine-tune freely. The Forge platform offers managed custom training for enterprises that want to avoid the GPU operations cost.
Cost-sensitive migration off closed mid-tier models
Products that ran on Claude Sonnet 4.6 ($3/$15 per MTok) or GPT-4o-class models can move to Mistral Large 3 at $0.50/$1.50 per MTok with 256K context and multimodal support. The throughput hit is real, but for non-real-time workloads (batch summarisation, document analysis, async agents) the savings are substantial.
Cross-cloud redundancy without prompt rewrites
The same mistral-large-2512 model id and OpenAI-compatible API contract is exposed on La Plateforme, AWS Bedrock, Azure AI Foundry, IBM watsonx, OpenRouter, Fireworks, and Together AI. Multi-cloud deployments avoid lock-in without rewriting prompts per provider.
Mistral Large 3 vs Qwen 3.6 vs DeepSeek V4 vs Llama 4
Inside the Tier 2 open-weight LLM bracket, four models matter: Mistral Large 3, Qwen 3.6, DeepSeek V4, and Llama 4. Each one optimises for a different axis.
| Feature | Mistral Large 3 | DeepSeek V4 (Pro) | Llama 4 Maverick | Qwen 3.6 |
|---|---|---|---|---|
| Total / active params | 675B / 41B active | 1.6T / 49B active | ~400B / ~17B active | ~480B / ~35B active |
| License | Apache 2.0 | MIT | Llama 4 Community License (700M MAU clause) | Apache 2.0 / Tongyi Qianwen |
| Context window | 256K | 128K | 256K-1M (variant-dependent) | 256K |
| Native multimodal | Yes (fused vision encoder) | Limited | Yes (variant-dependent) | Yes |
| Hosted price ($/1M in / $/1M out) | $0.50 / $1.50 | $0.435 / $0.87 (promo) | ~$0.27 / $0.85 (Together) | ~$0.40 / $1.20 |
| EU sovereignty | Yes (default) | Via OpenRouter only | Via partners | Via partners |
| Reasoning specialist sibling | Magistral (separate) | DeepSeek R2 | None official | Qwen 3.6 Thinking |
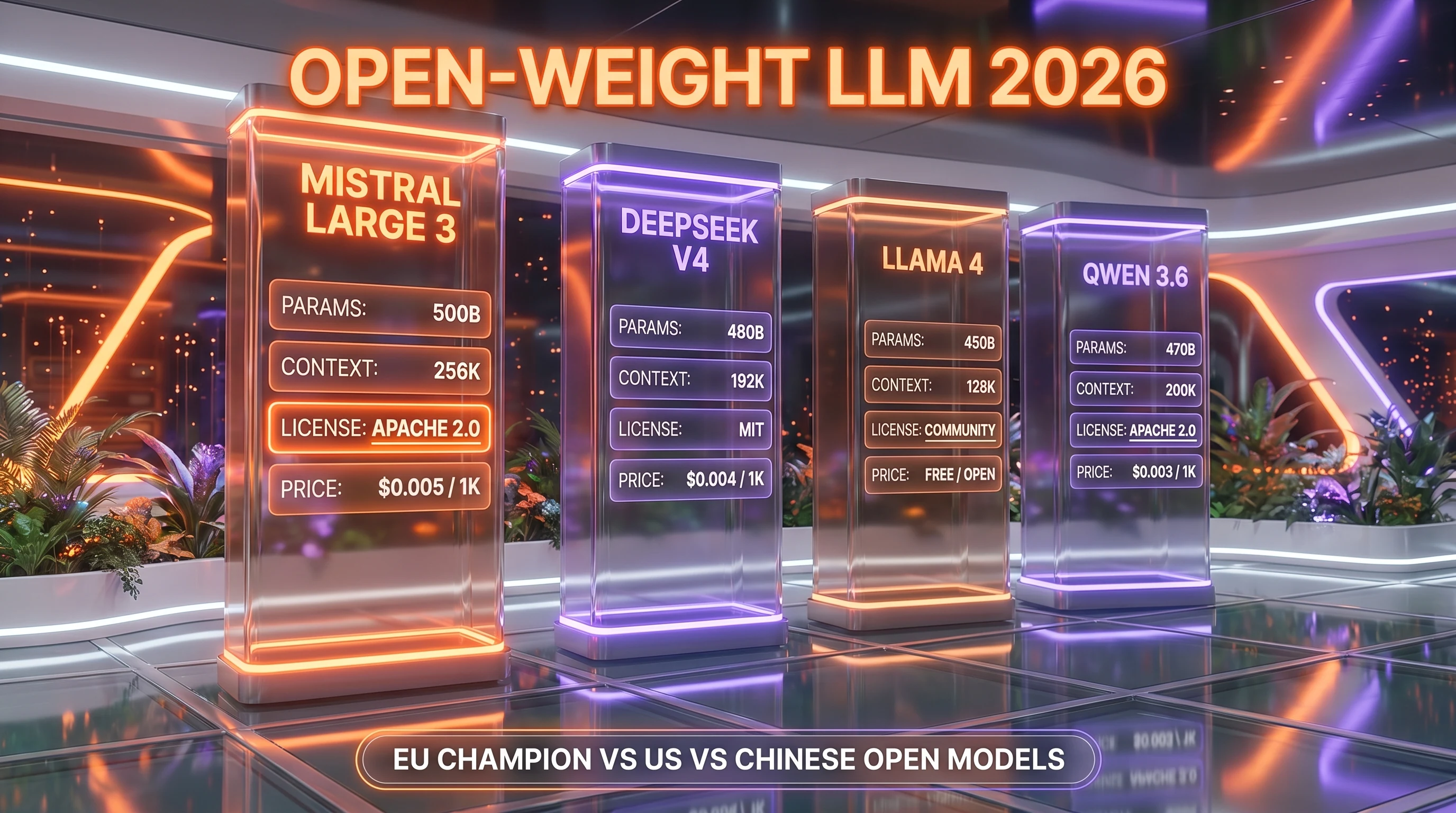
When to pick Mistral Large 3: you need EU residency, Apache 2.0 redistribution, native multimodal, and a 256K context window. When to pick DeepSeek V4: you need state-of-the-art reasoning and the highest Intelligence Index in the open-weight category. When to pick Llama 4: you need lowest hosted price and you fit under the 700M MAU clause. When to pick Qwen 3.6: you need a strong reasoning sibling (Qwen 3.6 Thinking) and Chinese-language workloads.
Frequently Asked Questions
Is Mistral Large 3 free?
Yes and no. The model weights are free to download from Hugging Face under the Apache 2.0 license, which permits commercial use, redistribution, and fine-tuning. However, running inference at flagship scale typically requires an 8xH100 80GB or equivalent node, which is not free. Hosted inference on La Plateforme is paid: $0.50 per 1M input tokens and $1.50 per 1M output tokens. Le Chat (Mistral's consumer app) has a Free tier with daily limits.
How much does Mistral Large 3 cost in 2026?
On La Plateforme and OpenRouter, Mistral Large 3 (model id mistral-large-2512) costs $0.50 per 1M input tokens and $1.50 per 1M output tokens, verified April 2026. Le Chat consumer plans are $14.99 per month for Pro and $24.99 per user per month for Team. Self-hosted is free under Apache 2.0. Mistral AI Studio enterprise pricing is custom.
What is Mistral Large 3?
Mistral Large 3 (v25.12) is Mistral AI's December 2025 flagship large language model: a 675B-parameter granular Mixture-of-Experts model with 41B active parameters per token, a 256K context window, native multimodality (a 2.5B vision encoder fused into the architecture), and an Apache 2.0 license. It is positioned as Mistral's strongest general-purpose model and the European reference open-weight flagship of 2026.
How does Mistral Large 3 compare to DeepSeek V4?
DeepSeek V4 (1.6T total / 49B active) is ahead on the Artificial Analysis Intelligence Index and reasoning benchmarks, with stronger SWE-bench and LiveCodeBench scores. Mistral Large 3 is ahead on Apache 2.0 license terms (vs DeepSeek's MIT, similarly permissive but with data provenance concerns for some enterprises), EU sovereignty by default, and native multimodal handling of PDFs and OCR. Pricing is comparable: $0.50/$1.50 vs DeepSeek V4 Pro discount $0.435/$0.87 per MTok.
Is Mistral Large 3 GDPR compliant?
Mistral AI Studio offers EU data residency by default — data does not leave European infrastructure unless you explicitly opt in to other regions. AWS Bedrock and Azure AI Foundry also expose Mistral Large 3 in EU regions. For full GDPR compliance you still need to sign a Data Processing Addendum (DPA) with Mistral or your cloud provider, configure data retention policies, and ensure your application layer respects user rights. Mistral AI is itself a French company headquartered in Paris under EU law.
Does Mistral Large 3 support function calling?
Yes. La Plateforme exposes function calling, structured outputs, JSON mode, and a built-in tool catalogue (web search, code interpreter via Le Chat, image generation) for the mistral-large-2512 model id. The OpenAI-compatible API surface keeps migration friction low for teams already using GPT or Anthropic SDKs.
What is the context window of Mistral Large 3?
256K tokens, equivalent to roughly 384 pages of standard text. This is currently among the longest in the open-weight category, matching Qwen 3.6 and Llama 4's standard variant, ahead of DeepSeek V4's 128K, and competitive with closed flagships like Claude Opus 4.7 and GPT-5.5.
Is Mistral Large 3 multimodal?
Yes, natively. The vision encoder (~2.5B parameters) is fused directly into the architecture rather than bolted on as a separate model. This means images, PDFs, charts, scanned forms, and layout-aware OCR are first-class inputs handled in the same call as text reasoning. It is one of the few open-weight flagship models with first-class multimodality.
What license does Mistral Large 3 use?
Apache 2.0. This permits commercial use, redistribution, fine-tuning, and proprietary derivative works without revenue thresholds. It is a major shift from Mistral Large 2's Mistral Research License (MRL), which restricted commercial redistribution. Apache 2.0 is more permissive than Llama 4's Community License (which has a 700M monthly active user clause and brand attribution requirements).
Where can I run Mistral Large 3?
Mistral Large 3 is available on Mistral AI Studio (EU residency), La Plateforme (Mistral's API), Amazon Bedrock, Azure AI Foundry, IBM watsonx.ai, Modal, OpenRouter, Fireworks AI, Together AI, and Hugging Face (for self-hosted weights including FP8, BF16, NVFP4, and Eagle speculative decoding variants). Single-node self-hosting requires an 8xH100 80GB or equivalent node.
Who founded Mistral AI?
Mistral AI was founded in 2023 in Paris by Arthur Mensch (CEO, former DeepMind), Guillaume Lample (Chief Scientist, former Meta AI lead on LLaMA), and Timothée Lacroix (CTO, former Meta AI). The company is positioned as the European reference AI lab and has raised multiple billion-dollar rounds from European and US investors. It is the most prominent EU-headquartered foundation model lab as of April 2026.
Is Mistral Large 3 worth it for my project?
Mistral Large 3 is worth it if you need EU residency, Apache 2.0 redistribution rights, native multimodal handling, or self-hosted flagship-scale weights. It is also a strong cost-saver versus closed flagships at $0.50/$1.50 per MTok. It is not the right pick if your workload needs state-of-the-art reasoning (DeepSeek V4 or closed flagships are ahead), low-latency real-time chat (TTFT of 11s+ is too slow), or high factual accuracy on long-tail queries (SimpleQA ~23.8% is below peers — pair with RAG).
Verdict: 8.5 out of 10

Mistral Large 3 earns an 8.5 out of 10 on three things its peers cannot match together: a genuinely permissive Apache 2.0 license at flagship scale, native multimodality fused into the architecture, and EU-sovereign hosting by default. The 256K context window and $0.50/$1.50 per MTok pricing make it a credible cost-saver versus closed mid-tier models. What holds it back from a higher score is throughput (~47-50 t/s and 11s+ TTFT lag the open-weight median), the absence of a dedicated reasoning variant inside the Large 3 family, and SimpleQA factual accuracy that falls below peer non-reasoning models.
Score breakdown:
- Features: 8.8 out of 10 — 256K context, native multimodal, Apache 2.0, function calling, 12+ deployment surfaces
- Ease of Use: 8.0 out of 10 — OpenAI-compatible API and Hugging Face weights are straightforward, but single-node self-hosting still requires 8xH100
- Value: 9.2 out of 10 — $0.50/$1.50 per MTok is excellent, and Apache 2.0 self-hosting is a unique unlock for regulated industries
- Support: 7.8 out of 10 — strong documentation and active Hugging Face presence, but Mistral's enterprise support footprint is smaller than AWS, Azure, or Anthropic in 2026
Final word: If you are a European enterprise, a regulated industry, or a team that needs Apache 2.0 redistribution rights at flagship scale, Mistral Large 3 is the open-weight LLM to evaluate first in 2026. If you are a US consumer product chasing the highest Intelligence Index or sub-second latency, you will be better served by Claude Opus 4.7, GPT-5.5, or DeepSeek V4. Mistral's bet is that the European AI champion angle and Apache 2.0 unlock are worth the throughput trade-off — for the right workload, that bet pays off.
Key Features
Pros & Cons
Pros
- Apache 2.0 license unlocks commercial redistribution, fine-tuning, and self-hosting with no revenue thresholds — a sharp differentiator versus Llama 4 Community License (700M MAU clause) and Mistral's older MRL-licensed releases
- Open weights at 675B/41B-active MoE on a single node make on-prem deployment realistic for serious enterprises, not just hyperscalers
- Native multimodal architecture (vision encoder fused into the model) handles PDFs, charts, and OCR as first-class inputs without bolting on a separate vision pipeline
- 256K-token context window matches GPT-5.5 and Claude Opus 4.7 territory while staying open-weight and EU-hosted
- La Plateforme pricing of $0.50 per 1M input tokens and $1.50 per 1M output tokens beats most closed mid-tier models on raw cost
- EU-sovereign hosting by default on Mistral AI Studio addresses GDPR and EU AI Act concerns better than US-hosted alternatives
- Cross-cloud availability on AWS Bedrock, Azure AI Foundry, IBM watsonx, OpenRouter, Fireworks, and Together AI reduces lock-in risk
Cons
- Output speed of ~47-50 tokens per second is below the open-weight median, and time-to-first-token around 11-31 seconds is markedly slower than DeepSeek V4 or Llama 4 hosted inference
- Artificial Analysis Intelligence Index of 23 is above average but trails reasoning-tuned competitors like DeepSeek V4 (~32-34 range) and is well behind closed flagships like Claude Opus 4.7 and GPT-5.5
- SimpleQA factual accuracy reportedly around 23.8% — confident hallucinations on long-tail facts are more frequent than peer non-reasoning open-weight models
- No dedicated reasoning variant inside the Large 3 family at launch (Magistral covers reasoning separately, but it is positioned mid-tier rather than as a Large 3 thinking mode)
- Single-node deployment story still assumes 8xH100 80GB or equivalent — out of reach for individual developers or small teams without API budget
Best Use Cases
Platforms & Integrations
Available On
Integrations
Compare Mistral Large 3

We're developers and SaaS builders who use these tools daily in production. Every review comes from hands-on experience building real products — DealPropFirm, ThePlanetIndicator, PropFirmsCodes, and many more. We don't just review tools — we build and ship with them every day.
Written and tested by developers who build with these tools daily.
Frequently Asked Questions
What is Mistral Large 3?
Mistral AI's open-weight 675B-MoE multimodal flagship — 256K context, Apache 2.0, EU-sovereign at $0.50 per 1M input tokens.
How much does Mistral Large 3 cost?
Mistral Large 3 has a free tier. Premium plans start at $0.5/month.
Is Mistral Large 3 free?
Yes, Mistral Large 3 offers a free plan. Paid plans start at $0.5/month.
What are the best alternatives to Mistral Large 3?
Top-rated alternatives to Mistral Large 3 include Claude Code (9.9/10), Cursor (9.5/10), Claude Opus 4.7 (9.4/10), Veo 3.1 (9.4/10) — all reviewed with detailed scoring on ThePlanetTools.ai.
Is Mistral Large 3 good for beginners?
Mistral Large 3 is rated 8/10 for ease of use.
What platforms does Mistral Large 3 support?
Mistral Large 3 is available on La Plateforme API, Mistral AI Studio, Amazon Bedrock, Azure AI Foundry, Hugging Face, OpenRouter, Fireworks AI, Together AI, IBM watsonx.ai, Modal, Self-hosted.
Does Mistral Large 3 offer a free trial?
Yes, Mistral Large 3 offers a free trial.
Is Mistral Large 3 worth the price?
Mistral Large 3 scores 9.2/10 for value. We consider it excellent value.
Who should use Mistral Large 3?
Mistral Large 3 is ideal for: GDPR-conscious European enterprises building LLM features that must keep data resident in the EU, Self-hosted deployments on a single 8xH100 or 8xMI300X node thanks to the 41B-active MoE design, Long-context document workloads (legal contracts, financial filings, multi-PDF research) up to 256K tokens, Multimodal extraction pipelines: invoices, scanned forms, diagrams, and charts handled natively without a separate vision model, Multilingual customer support and content workflows across French, German, Italian, Spanish, and other European languages, Open-weight fine-tuning under Apache 2.0 for regulated industries (healthcare, public sector, defense) where redistribution rights matter, Cost-sensitive inference at $0.50/$1.50 per 1M tokens for products that previously sat on closed Mid-tier models, Cross-cloud redundancy via Bedrock + Azure + watsonx + OpenRouter without rewriting prompts.
What are the main limitations of Mistral Large 3?
Some limitations of Mistral Large 3 include: Output speed of ~47-50 tokens per second is below the open-weight median, and time-to-first-token around 11-31 seconds is markedly slower than DeepSeek V4 or Llama 4 hosted inference; Artificial Analysis Intelligence Index of 23 is above average but trails reasoning-tuned competitors like DeepSeek V4 (~32-34 range) and is well behind closed flagships like Claude Opus 4.7 and GPT-5.5; SimpleQA factual accuracy reportedly around 23.8% — confident hallucinations on long-tail facts are more frequent than peer non-reasoning open-weight models; No dedicated reasoning variant inside the Large 3 family at launch (Magistral covers reasoning separately, but it is positioned mid-tier rather than as a Large 3 thinking mode); Single-node deployment story still assumes 8xH100 80GB or equivalent — out of reach for individual developers or small teams without API budget.
Best Alternatives to Mistral Large 3



Ready to try Mistral Large 3?
Start with the free plan
Try Mistral Large 3 Free →