RunPod
The GPU cloud platform built for AI � pods, serverless endpoints, and instant clusters at up to 80% less than AWS.
Quick Summary
RunPod is a GPU cloud platform with on-demand pods, serverless endpoints (FlashBoot <2s cold starts), and multi-node clusters across 31 regions. Scored 8.9/10. From $0.18/hr spot, zero egress fees, per-second billing.

What Is RunPod?
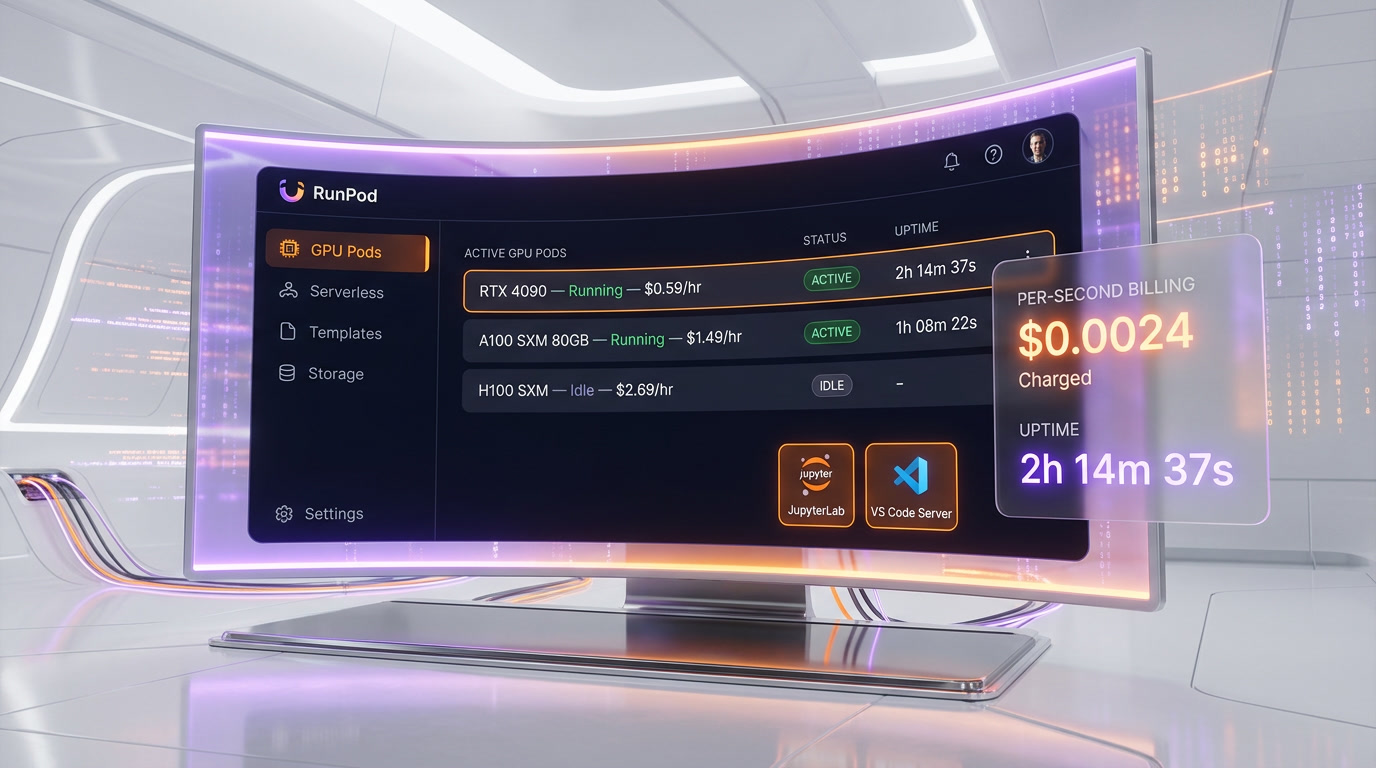
RunPod is a GPU cloud platform purpose-built for AI workloads, offering on-demand GPU pods, serverless GPU endpoints, and instant multi-node clusters across 31 global regions. Founded in 2022 by Zhen Wang, RunPod has grown to serve over 300,000 developers and hit $120M ARR in January 2026. The platform provides access to 30+ GPU models — from the RTX 2000 at $0.24 per hr to the B200 at $4.99 per hr — with per-second billing and zero egress fees, making it one of the most cost-effective alternatives to AWS, GCP, and Azure for AI training and inference. We scored it 8.9 out of 10.
We scored RunPod 8.9 out of 10 in our testing, with standout marks for value (9.3 out of 10) and features (9.2 out of 10).
What separates RunPod from traditional cloud providers is its singular focus on GPU compute for AI. While AWS and GCP offer GPU instances as one product among hundreds, RunPod builds its entire platform around the GPU developer experience. The result is faster deployment (pods launch in seconds), simpler pricing (no hidden fees, no reserved instances required for good rates), and purpose-built tooling for AI workflows including serverless auto-scaling, FlashBoot cold starts under two seconds, and a hub marketplace for one-click model deployment.
RunPod operates two cloud tiers: Community Cloud, which aggregates GPUs from distributed data centers worldwide at the lowest prices, and Secure Cloud, which runs exclusively in Tier 3/4 enterprise-grade data centers with SOC 2 Type II certification. This dual-tier model lets hobbyists and researchers access affordable compute while giving enterprises the compliance and reliability guarantees they require.
GPU Pricing at a Glance
| GPU | VRAM | On-Demand | Spot |
|---|---|---|---|
| RTX 2000 | 16 GB | $0.24 per hr | $0.18 per hr |
| RTX 4090 | 24 GB | $0.59 per hr | $0.50 per hr |
| RTX 5090 | 32 GB | $0.89 per hr | $0.76 per hr |
| A100 SXM | 80 GB | $1.49 per hr | $1.22 per hr |
| H100 SXM | 80 GB | $2.69 per hr | — |
| H200 SXM | 141 GB | $3.59 per hr | $3.05 per hr |
| B200 | 180 GB | $4.99 per hr | $4.24 per hr |
All compute is billed per-second with zero egress fees. Full pricing breakdown with all 30+ GPU models below.
RunPod is built for AI researchers, ML engineers, startups, and indie developers who need GPU compute without AWS-level complexity or pricing. It’s also the go-to platform for AI artists running Stable Diffusion and creative AI workloads.
Our Experience with RunPod
We used RunPod extensively for fine-tuning Llama models on A100 80GB instances, running Stable Diffusion inference on RTX 4090 pods, and deploying serverless endpoints for production image generation. In every case, RunPod delivered 60–70% cost savings versus equivalent AWS instances, with pods launching in under three minutes from signup, scale-to-zero serverless billing, and sub-2-second cold starts via FlashBoot. The per-second billing and zero egress fees make development workflows genuinely cheaper — you pay only for the seconds you compute, with no minimum hourly charges.
Core Features
GPU Pods
GPU Pods are RunPod's core compute product — on-demand GPU instances that launch in seconds with pre-configured environments. Each pod comes with a web terminal, JupyterLab, VS Code Server, and SSH access. You can choose from 30+ GPU models, select your preferred Docker template (PyTorch, TensorFlow, Stable Diffusion, or custom images), attach network volumes for persistent storage, and start working immediately.
Pods are available in two configurations: On-Demand pods run continuously until you stop them, while Spot pods run at reduced prices but can be interrupted when demand is high. On-Demand pods are ideal for production inference and time-sensitive training, while Spot pods work well for fault-tolerant batch processing and experimentation where interruptions are acceptable.
The template system is a significant productivity feature. RunPod maintains a library of pre-configured Docker images for common AI frameworks and models. Instead of spending hours configuring CUDA drivers, PyTorch versions, and model dependencies, you select a template and launch. Custom templates can be saved and shared across your team.
Serverless Endpoints
RunPod Serverless lets you deploy AI models as auto-scaling API endpoints that scale to zero when idle and scale up automatically when requests arrive. This is the product that competes directly with AWS Lambda, Modal, and Banana — but with GPU support and significantly lower pricing. You deploy a Docker container with your model, configure scaling parameters, and RunPod handles the rest.
The serverless platform supports two worker types: Flex Workers handle burst traffic and scale dynamically based on request volume, while Active Workers run continuously at a 40% discount for predictable, steady-state workloads. This dual-worker model lets you optimize costs by running a baseline of Active Workers for your typical traffic and adding Flex Workers to handle spikes.
FlashBoot
FlashBoot is RunPod's proprietary cold start optimization that achieves sub-2-second cold starts for 95% of serverless requests. Cold starts are the Achilles heel of serverless GPU compute — on competing platforms, spinning up a GPU instance with a loaded model can take 30-90 seconds. FlashBoot solves this through aggressive model caching, pre-warmed GPU pools, and optimized container initialization.
In practice, FlashBoot makes RunPod Serverless viable for latency-sensitive applications like real-time image generation, live video processing, and interactive AI features where users cannot wait 60 seconds for a cold GPU to initialize. This is a genuine competitive advantage — most competing serverless GPU platforms still struggle with cold starts measured in tens of seconds.
Instant Clusters
Instant Clusters allow you to provision multi-node GPU clusters with InfiniBand interconnect for distributed training jobs. You can scale up to 64 H100 GPUs in a single cluster with high-bandwidth inter-node communication, making it possible to train large language models and other compute-intensive workloads without managing the networking infrastructure yourself.
Cluster provisioning is handled through the web console or API — you specify the GPU type, node count, and networking requirements, and RunPod assembles the cluster. This is a dramatically simpler experience than configuring equivalent multi-node training on AWS (which requires VPC setup, placement groups, EFA adapters, and significant DevOps expertise). The tradeoff is less flexibility in network topology and instance customization compared to building your own cluster on a major cloud provider.
RunPod Hub
RunPod Hub is a marketplace of pre-packaged AI models and applications that can be deployed with one click. The hub includes popular open-source models like Stable Diffusion XL, Llama variants, Whisper, and various LoRA adapters. Each listing includes a pre-configured Docker template, recommended GPU specifications, and estimated costs per request.
For teams that want to deploy AI models without building custom inference pipelines, RunPod Hub eliminates the DevOps overhead entirely. Select a model, choose your GPU, and deploy — the endpoint is live and serving requests within minutes. The hub also serves as a distribution channel for model creators who want to monetize their work through RunPod's marketplace.
GPU Pods Pricing
RunPod's GPU pricing varies by GPU model and cloud tier. Community Cloud offers the lowest prices from distributed data centers, while Secure Cloud runs in enterprise-grade facilities with higher reliability and compliance certifications. All prices are per GPU per hour, billed by the second.
Community Cloud Pricing
Featured GPUs
| GPU | VRAM | On-Demand (per hr) | Spot (per hr) |
|---|---|---|---|
| RTX 5090 | 32 GB | $0.89 | $0.76 |
| H100 SXM | 80 GB | $2.69 | $2.09 |
| H200 SXM | 141 GB | $3.59 | $3.05 |
| B200 | 180 GB | $4.99 | $4.24 |
Latest Gen NVIDIA
| GPU | VRAM | On-Demand (per hr) | Spot (per hr) |
|---|---|---|---|
| RTX 2000 | 16 GB | $0.24 | $0.18 |
| L4 | 24 GB | $0.39 | $0.32 |
| RTX PRO 4500 | 32 GB | $0.54 | $0.46 |
| RTX 4090 | 24 GB | $0.59 | $0.50 |
| RTX 6000 | 48 GB | $0.77 | $0.63 |
| L40S | 48 GB | $0.86 | $0.71 |
| H100 PCIe | 80 GB | $2.39 | — |
| H100 NVL | 94 GB | $3.07 | $2.61 |
| H200 NVL | 143 GB | $3.39 | $2.88 |
Previous Gen NVIDIA
| GPU | VRAM | On-Demand (per hr) | Spot (per hr) |
|---|---|---|---|
| RTX A4000 | 16 GB | $0.25 | $0.19 |
| RTX A5000 | 24 GB | $0.27 | $0.20 |
| A40 | 48 GB | $0.40 | $0.20 |
| RTX 3090 | 24 GB | $0.46 | $0.34 |
| RTX A6000 | 48 GB | $0.49 | $0.40 |
| A100 PCIe | 80 GB | $1.39 | — |
| A100 SXM | 80 GB | $1.49 | $1.22 |
AMD
| GPU | VRAM | On-Demand (per hr) | Spot (per hr) |
|---|---|---|---|
| MI300X | 192 GB | $1.99 | $1.51 |
Secure Cloud Pricing
| GPU | VRAM | On-Demand (per hr) |
|---|---|---|
| RTX 4090 | 24 GB | $0.59 |
| L40S | 48 GB | $0.79 |
| A100 SXM | 80 GB | $1.64 |
| H100 SXM | 80 GB | $3.29 |
| H200 SXM | 141 GB | $4.49 |
| B200 SXM | 180 GB | $5.99 |
Note: All prices are billed per second. There is no minimum hourly charge — a 15-minute session on an H100 costs exactly one quarter of the hourly rate. Spot instances on Community Cloud offer 20-30% savings over on-demand pricing but can be interrupted during periods of high demand.

Serverless Pricing
Serverless pricing follows a per-second model with two worker tiers. Flex Workers charge only while actively processing requests, while Active Workers run continuously at a 40% discount — ideal for steady-state production workloads.
| GPU | VRAM | Flex Worker (per sec) | Active Worker (per sec) |
|---|---|---|---|
| RTX 4090 PRO | 24 GB | $0.00019 | $0.00013 |
| L40S | 48 GB | $0.00032 | $0.00022 |
| A100 80GB | 80 GB | $0.00076 | $0.00060 |
| H100 SXM | 80 GB | $0.00116 | $0.00093 |
| H200 SXM | 141 GB | $0.00155 | $0.00124 |
Serverless endpoints include zero egress fees — there is no charge for data transferred out of RunPod, unlike AWS which charges $0.09 per GB for data egress. For inference workloads that generate large outputs (images, video, audio), this alone can save hundreds of dollars per month compared to equivalent AWS deployments.
Storage Costs
RunPod offers two storage types for persistent data. Network Volumes provide shared NVMe-backed storage accessible across multiple pods in the same region, priced at $0.07 per GB per month. Container Disk provides temporary local storage attached to individual pods at $0.04 per GB per month — faster than network volumes but destroyed when the pod is terminated.
For serverless endpoints, storage is included in the per-second worker pricing up to 20 GB. Additional storage is available at $0.07 per GB per month. Data ingress is free, and data egress is free — a significant cost advantage over AWS and GCP where egress charges can add 10-30% to total cloud costs for data-intensive AI workloads.
The practical recommendation is to use Network Volumes for datasets, model weights, and checkpoints that persist across sessions, and Container Disk for temporary scratch space during training runs. For large datasets (100+ GB), downloading directly from cloud storage (S3, GCS, or Hugging Face Hub) at the start of each session can be more cost-effective than maintaining permanent network volumes.
API and Developer Experience
RunPod provides a Python SDK and a GraphQL API for programmatic access to all platform features. The SDK covers pod management (create, start, stop, terminate), serverless endpoint deployment, template management, and real-time monitoring. The GraphQL API exposes the same functionality for teams using other languages or building custom integrations.
The developer experience is streamlined compared to AWS or GCP. Launching a GPU pod programmatically takes four lines of Python code. Deploying a serverless endpoint requires a Dockerfile, a handler function that processes requests, and a deployment command. There is no IAM policy configuration, no VPC setup, no subnet management — the complexity that makes AWS GPU deployments a multi-day DevOps project is simply absent.
That said, RunPod's ecosystem is narrower than AWS. There are no built-in databases, caching layers, message queues, CI/CD pipelines, or monitoring dashboards beyond the basic real-time metrics. If your AI pipeline needs a PostgreSQL database, a Redis cache, or a Kafka stream, you will need to provision those services from other providers and integrate them yourself. For pure GPU compute, this simplicity is a feature. For teams building complete AI platforms, the missing infrastructure components require additional engineering effort.
Security and Compliance
RunPod's Secure Cloud tier is SOC 2 Type II certified, meaning it has been independently audited for security controls, availability, and data handling procedures. Data at rest is encrypted with AES-256, and data in transit is encrypted with TLS 1.2+. GDPR compliance is supported for European customers with data processing agreements available on request.
Community Cloud, by contrast, does not carry the same compliance certifications. GPUs on Community Cloud are hosted in distributed data centers with varying physical security standards. For development, experimentation, and non-sensitive workloads, Community Cloud is perfectly fine. For production workloads involving personal data, healthcare information, or financial data, Secure Cloud is the appropriate choice.
RunPod supports SSH key authentication for pod access, API key-based authentication for programmatic access, and two-factor authentication for web console login. Network isolation between pods is enforced at the hypervisor level, and pods on Secure Cloud run in dedicated environments with no resource sharing between customers.

Who Should Use RunPod?
RunPod is ideal for AI researchers and ML engineers who need GPU compute without AWS-level complexity. If you are fine-tuning language models, training image generation models, or running inference workloads, RunPod delivers the GPU power you need at 60-80% less than AWS with a setup process that takes minutes instead of hours.
Startups building AI products benefit from RunPod's serverless endpoints for production inference — the combination of auto-scaling, FlashBoot cold starts, zero egress fees, and per-second billing makes it possible to serve AI features in production without over-provisioning expensive GPU infrastructure. The cost savings compared to AWS SageMaker or GCP Vertex AI can be the difference between a viable unit economy and an unsustainable burn rate.
Hobbyists and independent developers running Stable Diffusion, LLM inference, or personal AI projects will find Community Cloud pricing accessible — an RTX 4090 at $0.59 per hr is cheaper than buying the card and paying for electricity in many markets. The one-click templates for popular models eliminate the setup friction that makes self-hosting impractical for non-DevOps users.
RunPod is not the best choice for enterprises requiring comprehensive cloud infrastructure (databases, networking, CDN, CI/CD) from a single provider. Teams locked into AWS or GCP ecosystems with existing commitments, compliance requirements, and organizational tooling may find the cost savings insufficient to justify managing a separate cloud provider for GPU compute alone.
RunPod vs the Competition
RunPod vs AWS (EC2 P5 / SageMaker)
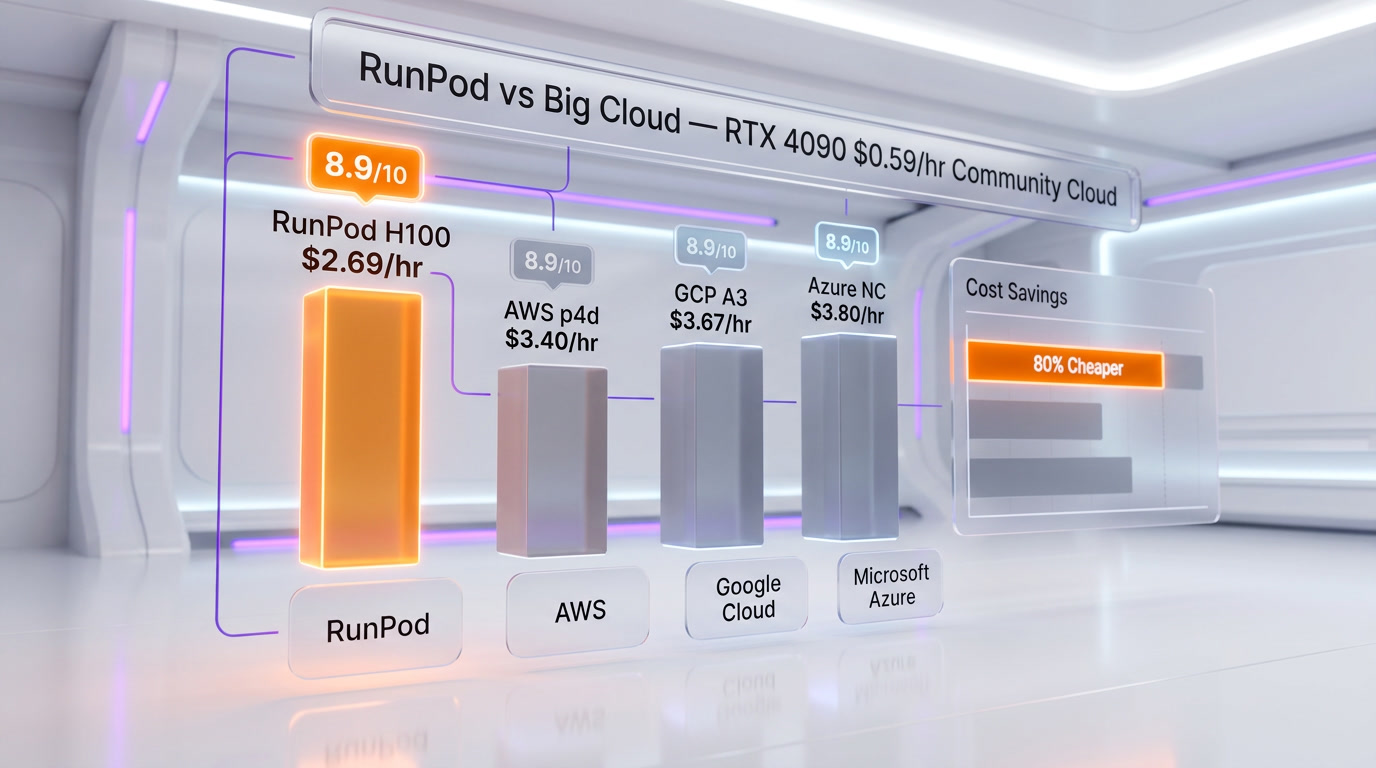
AWS offers the broadest GPU selection and deepest ecosystem, but at 2-4x RunPod's pricing. An H100 on AWS costs $6-8/hr compared to $2.69 per hr on RunPod Community Cloud. AWS wins on compliance certifications, global infrastructure, and integrated services. RunPod wins on price, simplicity, and time-to-deployment. For teams that need only GPU compute and already handle their own data infrastructure, RunPod is the clear value choice. For enterprises requiring HIPAA, FedRAMP, or ISO 27001 certification with integrated AWS services, stay with AWS.
RunPod vs Lambda Labs
Lambda Labs is the closest direct competitor, offering GPU cloud at similar price points ($2.49 per hr for H100 on-demand). Lambda has a stronger managed infrastructure offering with Lambda Stack for on-premises deployments and a tighter focus on enterprise customers. RunPod differentiates with serverless endpoints (Lambda has no equivalent), Community Cloud pricing (which undercuts Lambda on consumer GPUs), and FlashBoot cold start optimization. For pure on-demand GPU pods, the two are comparable. For serverless inference, RunPod has no peer at this price point.
RunPod vs Vast.ai
Vast.ai operates a pure marketplace model where GPU owners list spare compute capacity. Prices can be lower than RunPod Community Cloud for off-peak GPUs, but availability is unpredictable, hardware quality varies, and there are no compliance certifications. RunPod offers a more reliable and structured experience with consistent hardware, managed templates, and Secure Cloud for enterprise workloads. Choose Vast.ai for maximum cost savings on batch jobs where reliability is not critical. Choose RunPod for a balanced approach to price and reliability.
Referral Program
RunPod offers a referral program that credits both the referrer and the new user. When someone signs up through your referral link, they receive credits toward their first GPU usage, and you earn credits applied to your account. The program is available to all registered users through the RunPod dashboard. For teams and creators who regularly recommend GPU cloud services, the referral credits can offset a meaningful portion of compute costs.
What Could Be Better
- Community Cloud availability is inconsistent. Popular GPUs like the A100 80GB and H100 frequently show as unavailable on Community Cloud during peak hours. You may need to wait, switch regions, or upgrade to Secure Cloud to get the GPU you need when you need it.
- Spot instances can be interrupted. Long training jobs on Spot pods risk interruption without warning. RunPod provides checkpointing guidance, but the responsibility for saving state falls entirely on the user. For multi-day training runs, On-Demand or Active Workers are safer choices.
- Network storage performance can bottleneck. Network Volumes are convenient for persistent data but slower than local NVMe for large sequential reads. Data-intensive training jobs benefit from downloading datasets to Container Disk at the start of each session rather than streaming from Network Volumes.
- No built-in infrastructure services. RunPod is pure GPU compute. There are no databases, caching layers, message queues, or CI/CD pipelines. Teams building complete AI platforms need to source and integrate these components from other providers.
- Documentation occasionally lags features. New features and pricing changes sometimes reach the platform before the documentation is updated. The Discord community fills this gap, but official docs should be the authoritative source.
- Limited geographic presence for Secure Cloud. While Community Cloud spans 31 regions, Secure Cloud availability is concentrated in North America and Europe. Teams requiring low-latency GPU inference in Asia-Pacific or South America may find limited options on the enterprise tier.
Bottom Line
RunPod has carved out a dominant position in the GPU cloud market by doing one thing exceptionally well: making GPU compute accessible, affordable, and simple. The platform's pricing — 60-80% below AWS for equivalent hardware — is not a promotional gimmick but a structural advantage built on efficient infrastructure and a focused product scope. Per-second billing, zero egress fees, and no minimum commitments make RunPod the most developer-friendly GPU cloud platform available in 2026.
The serverless offering with FlashBoot cold starts under two seconds is a genuine differentiator. No other platform at this price point delivers sub-2-second cold starts for GPU inference, making RunPod Serverless viable for production applications where latency matters. The dual Flex/Active worker model provides cost optimization flexibility that competing serverless GPU platforms do not offer.
The limitations are real but well-defined. Community Cloud availability fluctuates, network storage is not the fastest, and RunPod does not try to be a complete cloud platform. If you need databases, CDN, and managed Kubernetes alongside your GPU compute, AWS or GCP remain the integrated choice. But if your primary need is GPU compute for AI training and inference — and you want to spend your budget on GPUs rather than cloud provider margins — RunPod is the platform to use.
For AI startups, independent researchers, and any team that measures cloud costs against runway, RunPod is not just a cost optimization — it is a competitive advantage. The difference between paying $8 per hr and $2.69 per hr for an H100 compounds into thousands of dollars per month, and those savings translate directly into more experiments, more training runs, and faster iteration toward production-ready AI.
Frequently Asked Questions
What is RunPod?
RunPod is a GPU cloud platform for AI workloads offering on-demand GPU pods, serverless GPU endpoints, and multi-node clusters. It provides 30+ GPU models across 31 regions with per-second billing and pricing 60-80% below major cloud providers like AWS, GCP, and Azure.
How much does an H100 cost on RunPod?
An H100 SXM 80GB costs $2.69 per hr on Community Cloud (on-demand) or $2.09 per hr as a Spot instance. On Secure Cloud, the H100 SXM is priced at $3.29 per hr. All prices are billed per second with no minimum hourly charges.
What is the difference between Community Cloud and Secure Cloud?
Community Cloud aggregates GPUs from distributed data centers worldwide at the lowest prices but without enterprise compliance certifications. Secure Cloud runs in Tier 3/4 data centers with SOC 2 Type II certification, AES-256 encryption, and guaranteed availability. Community Cloud is ideal for development and research; Secure Cloud is designed for production and compliance-sensitive workloads.
What is FlashBoot?
FlashBoot is RunPod's proprietary cold start optimization for serverless endpoints. It achieves sub-2-second cold starts for 95% of requests through aggressive model caching, pre-warmed GPU pools, and optimized container initialization. This makes RunPod Serverless viable for latency-sensitive production applications.
Does RunPod charge for data egress?
No. RunPod does not charge for data egress (outbound data transfer). Both ingress and egress are free across all products — pods, serverless endpoints, and storage. This is a significant cost advantage over AWS, which charges $0.09 per GB for data egress.
Can I use RunPod for model training?
Yes. RunPod supports distributed training through Instant Clusters with up to 64 H100 GPUs connected via InfiniBand. Single-GPU and multi-GPU pod configurations support training with PyTorch, TensorFlow, JAX, and other frameworks through pre-configured templates.
Is RunPod secure enough for production?
RunPod Secure Cloud is SOC 2 Type II certified with AES-256 encryption at rest, TLS 1.2+ in transit, and GDPR compliance support. For production workloads requiring enterprise-grade security, Secure Cloud provides the necessary certifications and infrastructure guarantees. Community Cloud is recommended only for development and non-sensitive workloads.
How does RunPod compare to AWS for GPU compute?
RunPod is 60-80% cheaper than AWS for equivalent GPU instances, offers simpler deployment with no VPC or IAM configuration, and charges zero egress fees. AWS offers broader infrastructure services, more compliance certifications (HIPAA, FedRAMP), and deeper integration with the AWS ecosystem. Choose RunPod for focused GPU compute at the best price; choose AWS for enterprise-grade integrated cloud infrastructure.
Key Features
Pros & Cons
Pros
- GPU pricing 60-80% cheaper than AWS/GCP — RTX 4090 from $0.59/hr, H100 SXM from $2.69/hr on Community Cloud
- Per-second billing on all compute with zero egress or ingress fees
- FlashBoot serverless cold starts under 2 seconds for 95% of requests
- 30+ GPU models available across 31 global regions including RTX 5090, H200, B200, H100, A100, MI300X
- Instant Clusters for multi-node training — up to 64 H100s with InfiniBand
- RunPod Hub marketplace with one-click deployment of popular AI models
- SOC 2 Type II certified with AES-256 encryption and GDPR compliance
Cons
- Community Cloud GPU availability fluctuates � popular GPUs can be hard to get
- Spot instance model means pods can be interrupted during long training jobs
- Network storage performance can be slower than local NVMe
- No built-in databases, caching, or CI/CD � external services needed
- Documentation occasionally outdated for newer features
Best Use Cases
Platforms & Integrations
Available On
Integrations
Active Deals for RunPod
$5 Free Credit + $10 Bonus on First Deposit
Sign up via our referral link and get $5 in free GPU credits instantly, plus a $10 bonus when you make your first deposit of $10 or more. Access RunPod's full GPU cloud with no minimum commitment.

We're developers and SaaS builders who use these tools daily in production. Every review comes from hands-on experience building real products — DealPropFirm, ThePlanetIndicator, PropFirmsCodes, and many more. We don't just review tools — we build and ship with them every day.
Written and tested by developers who build with these tools daily.
Frequently Asked Questions
What is RunPod?
The GPU cloud platform built for AI � pods, serverless endpoints, and instant clusters at up to 80% less than AWS.
How much does RunPod cost?
RunPod costs $0.18/month.
Is RunPod free?
No, RunPod starts at $0.18/month.
What are the best alternatives to RunPod?
Top-rated alternatives to RunPod include Claude Code (9.9/10), Cursor (9.5/10), Claude Opus 4.7 (9.4/10), Veo 3.1 (9.4/10) — all reviewed with detailed scoring on ThePlanetTools.ai.
Is RunPod good for beginners?
RunPod is rated 8.8/10 for ease of use.
What platforms does RunPod support?
RunPod is available on Web, Linux, macOS, Windows.
Does RunPod offer a free trial?
Yes, RunPod offers a free trial.
Is RunPod worth the price?
RunPod scores 9.3/10 for value. We consider it excellent value.
Who should use RunPod?
RunPod is ideal for: Fine-tuning LLMs on high-VRAM GPUs, Deploying serverless inference APIs with auto-scaling, Running Stable Diffusion and AI image generation, Distributed model training across multi-node clusters, Speech-to-text processing with Whisper at scale, Rapid AI prototyping with pre-built templates, Running open-source LLM inference with vLLM or Ollama, Batch processing computer vision workloads.
What are the main limitations of RunPod?
Some limitations of RunPod include: Community Cloud GPU availability fluctuates � popular GPUs can be hard to get; Spot instance model means pods can be interrupted during long training jobs; Network storage performance can be slower than local NVMe; No built-in databases, caching, or CI/CD � external services needed; Documentation occasionally outdated for newer features.
Best Alternatives to RunPod



Ready to try RunPod?
Start your free trial
Try RunPod Free →