
The Atlantic’s "AI Watchdog" project reported in mid-June 2026 that it had identified four large datasets of songs — together holding more than 20 million tracks — circulating within the AI-development community. According to The Atlantic, the collections include catalog music that "is not supposed to be free," and they represent only a portion of the audio that developers can access to train music-generating models. The report does not prove that any specific company used any specific dataset, and none of the related copyright lawsuits against Suno or Udio had been decided on the merits as of June 2026.
For the people who actually use AI music tools — the songwriters, podcasters, video editors, and indie producers prompting Suno or Udio every day — the question underneath the investigation is blunt: which songs trained the model I’m building on, and does that expose me to anything? This article walks through exactly what The Atlantic reported, what it did and did not claim, the legal backdrop of the Suno and Udio copyright litigation, and what creators can reasonably take away while the courts work through it. We are reporting the investigation and the public record — we are not accusing anyone.
What The Atlantic actually found
The reporting comes from journalist Alex Reisner, who has documented AI training-data collections for The Atlantic across a series of investigations now grouped under the "AI Watchdog" banner. According to The Atlantic and reporting that summarized it — Music Business Worldwide, Music Ally, and Digital Music News — the investigation describes four "giant datasets" of recordings being shared among AI developers.
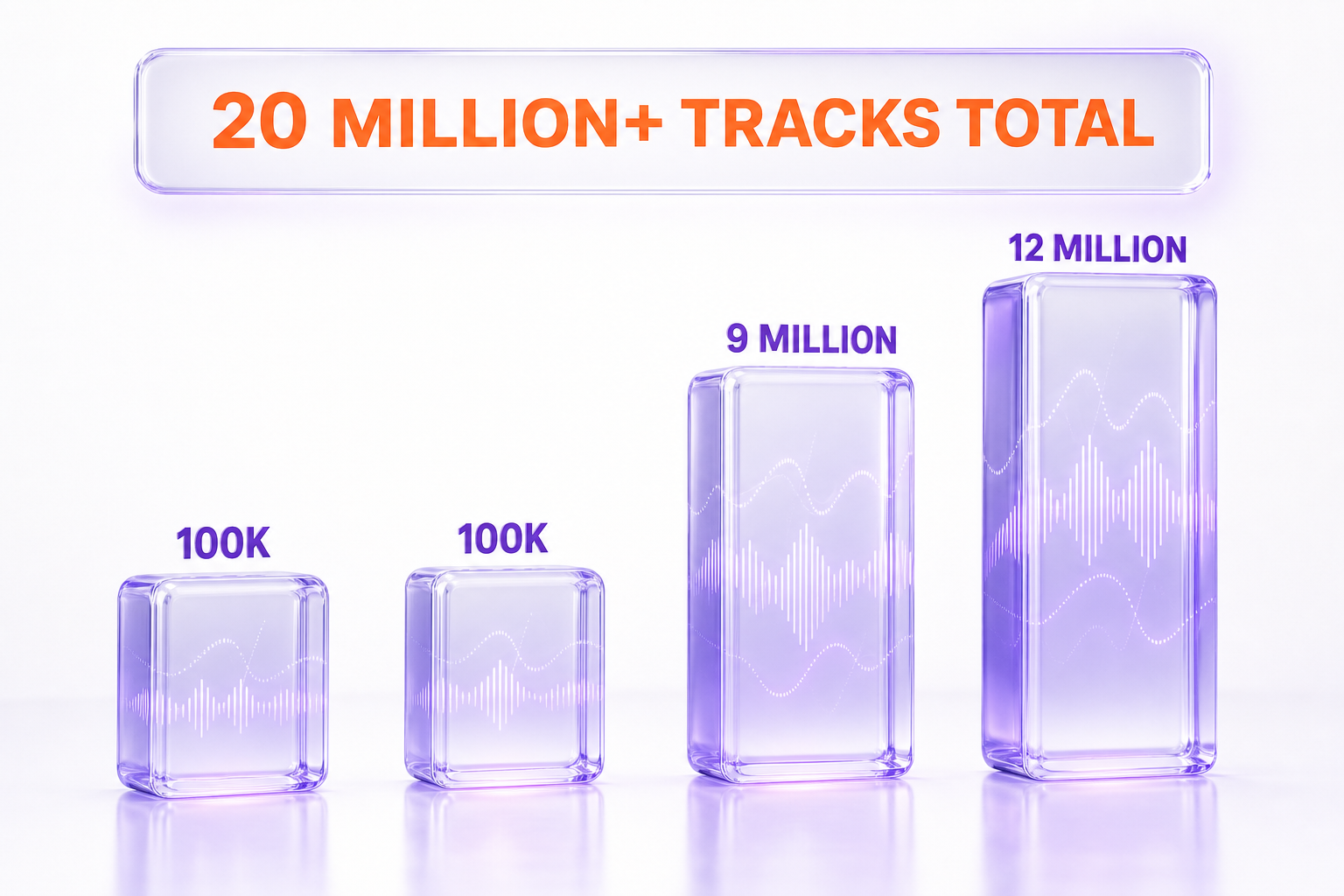
The reported scale, per those summaries, breaks down roughly as follows:
- Two smaller datasets of around 100,000 recordings each.
- One large dataset of roughly 12 million tracks.
- One large dataset of roughly 9 million tracks.
That adds up to more than 20 million recordings across the four collections. Reisner is quoted describing why the count matters: "Companies often claim to use only content that is freely available online, but the datasets reveal the quantity of downloadable music that developers can access even though it is not supposed to be free," according to the summaries of his reporting. In other words, the story is less about any single track and more about the sheer volume of commercial, copyrighted music that sits inside redistributable research datasets.
The Atlantic also reported that the datasets are searchable, and that one of them contained hundreds of entries tied to a single well-known recording artist — an illustration, in the reporting, of how thoroughly mainstream catalog music can appear inside collections nominally framed as research material. We are relaying that as a finding attributed to The Atlantic, not as an independent claim of our own.
What the report does not say
This is the part that matters most for a fair reading, so it is worth stating plainly. As of June 2026, the investigation as reported:
- Does not name a single AI company as having trained on a specific dataset. Music Ally specifically noted that the article "does not specify which particular AI companies have utilized them." The datasets are identifiable; their downstream use is not pinned to a named product in the reporting.
- Does not constitute a court finding. Nothing in the investigation has been adjudicated. It is journalism, not a judicial ruling.
- Does not, on its own, establish that anyone broke the law. Whether downloading and training on this material is lawful is precisely the unresolved question now in front of US courts.
Treat the investigation as a map of what exists in the wild, not a verdict on who used what. That framing keeps the facts intact without overreaching.
Why this matters if you use Suno or Udio
Most of our audience does not develop foundation models — they prompt them. So the relevant question is not "did a lab break a rule," it is "what does this mean for the track I just generated for a client video?" Three practical realities sit underneath the headlines.
First, output is downstream of training, but they are legally distinct. The investigation is about inputs — what music went into training corpora. Your exposure as a user is usually about outputs — whether a generated track is too close to an existing song, and what license your tool grants you. A messy training-data story does not automatically make every output infringing, and a clean license on the output does not automatically resolve the training question. They are separate layers, and conflating them is the most common mistake in this debate.
Second, distributors are starting to gate on provenance. Over the past year, some distribution platforms have begun making eligibility decisions based on where a track’s underlying model sourced its training data — a shift we covered when Udio’s training-data sourcing surfaced in the Sony Music litigation. For a working creator, that means a track’s lineage can quietly become a distribution problem, not just an abstract legal one.
Third, the licensed-versus-unlicensed split is hardening. The market is bifurcating into tools that are operating without comprehensive major-label licenses and are in active litigation, and tools positioning around partnership and licensing language — a contrast visible in the arrival of products like ElevenLabs’ ElevenMusic. If you are building anything commercial, that distinction increasingly determines which model is safe to depend on.

The legal backdrop: a timeline (as of June 2026)
The investigation lands on top of nearly two years of litigation. Here is the public record, dated and attributed. Statuses below are ongoing as of June 2026; none of the unsettled claims has been decided on the merits.
June 2024 — the RIAA sues Suno and Udio
On June 24, 2024, the Recording Industry Association of America (RIAA) announced lawsuits on behalf of Universal Music Group, Sony Music Entertainment, and Warner against the two leading AI music generators, Suno and Udio (operated by Uncharted Labs). Per the RIAA’s own announcement, the Suno case was filed in the US District Court for the District of Massachusetts and the Udio case in the Southern District of New York. The labels allege the services copied "decades" of sound recordings without permission to train their models. These are allegations by the plaintiffs; they have not been adjudicated.
October 2025 — Universal settles with Udio
According to lawsuit-tracking reporting, Universal Music Group settled with Udio on October 29, 2025, with terms that reportedly included a compensatory payment, a planned joint "walled-garden" AI music platform slated for 2026, and an opt-in framework for UMG artists. This was a settlement between two parties — it did not produce a ruling on the underlying legal questions.
Late 2025 — Warner settles
Warner reportedly settled and dismissed its claims against Suno on November 25, 2025 (reported terms included a multi-million-dollar payment, a licensing partnership, and Suno acquiring the concert-listings service Songkick from Warner), and reached a reported license deal with Udio in late 2025. Where exact dates or terms are not publicly confirmed, we have flagged them as reported rather than stating them as settled fact. (We covered Suno’s broader trajectory — including its $400M raise at a $5.4B valuation mid-lawsuit — separately.)
Ongoing — Sony keeps litigating
As of June 2026, Sony Music remains in active litigation against both Suno and Udio, having declined to join the UMG settlement, per the lawsuit trackers. Reporting indicates UMG and Sony also sought to add tens of thousands of additional recordings — reportedly more than 61,000 — to the case against Suno, which Suno opposed. A fair-use ruling has been reported as expected during the summer of 2026, with a trial reportedly anticipated later in the year.
July 2026 — Suno’s fair-use hearing
Suno is defending on fair-use grounds, arguing that training a generative model on copyrighted recordings is a transformative use under 17 U.S.C. § 107. A key summary-judgment hearing is reported as scheduled for July 2026 before Judge Denise Casper in the District of Massachusetts — a proceeding that could shape the legal standard for AI music training. Until a court rules, the fair-use question is genuinely open.
Udio’s acknowledgment about sourcing
In its defense, Udio has acknowledged using publicly available online audio to assemble training material while disputing that doing so constitutes infringement, according to reporting on the Sony Music v. Udio filings. That acknowledgment is significant because it moves part of the fight from "does the output look like a real song" to "how was the input acquired in the first place" — the same provenance question The Atlantic’s dataset map raises. We are characterizing this as Udio’s reported filing position, not as an admission of wrongdoing.
Independent artists are not covered by the major-label deals
Separately, independent artists filed class-action litigation against Suno and Udio beginning around October 2025, reported as active and at an early stage. This is an important nuance: the major-label settlements resolve the majors’ claims, but they do not speak for independent rights holders, whose own claims continue on a separate track.

Is it legal to train AI on this music? The honest answer
The honest answer in June 2026 is: that is exactly what the courts have not yet decided. The central legal battle is whether training a generative model on copyrighted recordings without a license qualifies as fair use. AI developers generally argue the use is transformative and non-expressive; rights holders generally argue it is wholesale commercial copying that competes directly with the works it ingested. No US court had resolved that question for AI music as of June 2026, and the reported July 2026 Suno hearing is one of the proceedings expected to start providing an answer.
Two layers make music harder than text. A single recorded track typically bundles a sound recording copyright (often held by a label) and a separate musical composition copyright (often held by publishers and songwriters), with mechanical and performance rights layered on top. Where a text dispute may involve one rights holder per work, a music dispute can involve two or more per track — across catalogs of millions of recordings. That structure is why the numbers in The Atlantic’s map (more than 20 million tracks) translate into an unusually large combinatorial exposure surface.
There is also a third potential layer when training audio is pulled from a platform: the platform’s own terms of service governing automated downloading. That is a contract question distinct from copyright, and it is part of why the provenance of training audio — not just its similarity to outputs — has become a central front in these cases.
A note on "research" datasets
It is worth understanding why large music datasets exist at all. Academic and open-source machine-learning communities have long assembled and shared audio collections for research — some openly documented, others passed around with little public paper trail. The Atlantic’s reporting, as summarized by the trade press, distinguishes between collections with public documentation and ones without. The recurring tension is that a dataset framed as research material can still contain large quantities of commercially released, copyrighted music, and once it circulates it is difficult to control how it is reused. The investigation’s contribution is to quantify how much commercial catalog actually sits inside these collections — a fact the broader debate often hand-waves past.
We are deliberately not republishing dataset names, download locations, or artist-by-artist breakdowns here. The newsworthy, decision-relevant fact for our readers is the scale and the provenance question — more than 20 million tracks, much of it commercial catalog, circulating among developers — not a how-to for accessing the material.
What creators should actually do right now
None of this is a reason to panic, and none of it is legal advice — for anything commercial or high-stakes, talk to a lawyer. But there are sober, practical moves a working creator can make while the courts sort out the law.
- Read your tool’s license and indemnification terms. What rights does the platform grant you over generated tracks, and does it indemnify you if an output is challenged? That contract is your most direct protection, independent of the training-data debate.
- Treat provenance as a procurement question for commercial work. Before you build a paid product or client deliverable on a given model, factor in whether the vendor is in active litigation and what its licensing posture is.
- Keep your prompts and project records. If a track’s originality is ever questioned, documentation of how you generated it is useful.
- Watch the July 2026 proceedings. A ruling on training-stage fair use — either way — will materially change the risk picture for everyone building on these tools.
- Know the licensed alternatives exist. If your work cannot tolerate provenance ambiguity, tools positioning around licensing deals are part of the landscape worth evaluating.
What would change this picture
This story is still developing, so it is worth naming the events that would move it. A court ruling upholding training-stage fair use for music would meaningfully de-risk the unlicensed tier. A comprehensive licensing settlement between the remaining label plaintiffs and Suno or Udio would collapse much of the current uncertainty. Conversely, a definitive ruling that platform-sourced acquisition is independently unlawful — regardless of fair use — would harden provenance into the dominant axis of the whole debate. And further investigative reporting could expand the map beyond the four datasets already described. As of June 2026, none of those had occurred, and that is precisely why every claim here is dated and attributed.
Frequently asked questions
What did The Atlantic find about AI music training data?
According to The Atlantic’s "AI Watchdog" reporting by Alex Reisner in mid-June 2026, as summarized by Music Business Worldwide and Music Ally, the investigation identified four large datasets of recordings being shared among AI developers — together holding more than 20 million tracks. The reported breakdown is roughly two collections of about 100,000 recordings each, one of roughly 12 million, and one of roughly 9 million. The reporting frames these as a portion of the copyrighted music developers can access, not as proof that any specific company used any specific dataset.
Is it legal to train AI on scraped or copyrighted music?
As of June 2026 this is unresolved. The core question — whether training a generative model on copyrighted recordings without a license is fair use — has not been decided by any US court for AI music. Developers generally argue the use is transformative; rights holders generally argue it is commercial copying that competes with the original works. A reported summary-judgment hearing in the Suno case was scheduled for July 2026. Until a court rules, the legality of the practice remains an open question, not a settled fact.
Were Suno and Udio sued, and by whom?
Yes. On June 24, 2024, the RIAA announced lawsuits on behalf of Universal Music Group, Sony Music Entertainment, and Warner against Suno (filed in the District of Massachusetts) and Udio (filed in the Southern District of New York), alleging copyright infringement in training the models. These are allegations brought by the plaintiffs; the central legal questions have not been adjudicated on the merits as of June 2026.
Did the record labels settle with Suno and Udio?
Partly. Universal Music Group reportedly settled with Udio on October 29, 2025, and Warner reportedly settled with Suno on November 25, 2025, plus reached a reported license deal with Udio in late 2025. However, Sony Music remained in active litigation against both companies as of June 2026, and independent artists filed separate class actions beginning around October 2025 that the major-label settlements do not cover. Some specific terms remain reported rather than publicly confirmed.
Did Udio admit to scraping music for training?
According to reporting on the Sony Music v. Udio filings, Udio acknowledged using publicly available online audio to assemble training material, while disputing that doing so constitutes infringement. This is characterized as Udio’s reported filing position within active litigation, not an admission of wrongdoing and not a court finding. No court had ruled on whether the practice was lawful as of June 2026.
Does this investigation prove which AI tool used which dataset?
No. As reported, the investigation maps datasets that exist and circulate among developers, but it does not pin a specific dataset to a specific named AI product. Music Ally noted the article does not specify which AI companies utilized the collections. The datasets are identifiable; their downstream use by named tools is not established in the reporting. It should be read as a map of what exists, not a verdict on who used what.
What does this mean for me if I use Suno or Udio?
Your day-to-day exposure as a user is mostly about outputs and licenses, which are legally distinct from the training-input question the investigation raises. Practical steps: read your tool’s license and indemnification terms, treat provenance as a procurement factor for commercial work, keep records of how you generated tracks, and watch the reported July 2026 fair-use proceedings, which could change the risk picture. This is general information, not legal advice — consult a lawyer for high-stakes commercial use.
Why is AI music copyright harder than AI text copyright?
A single recorded track typically bundles a sound recording copyright and a separate musical composition copyright, often held by different entities, with mechanical and performance rights layered on top. A text dispute usually involves one rights holder per work; a music dispute can involve two or more per track across catalogs of millions of recordings. With more than 20 million tracks reportedly inside the datasets The Atlantic mapped, that structure produces an unusually large combinatorial exposure surface.
What is the difference between a training-data question and an output question?
The training-data (input) question is whether the music used to build a model was lawfully obtained and used — the issue The Atlantic’s dataset map and the lawsuits center on. The output question is whether a generated track is too similar to an existing song and what license the user receives. They are separate legal layers: a messy input story does not automatically make every output infringing, and a clean output license does not automatically resolve the input question.
When will there be a definitive ruling?
No date is guaranteed. A summary-judgment hearing in the Suno case was reported as scheduled for July 2026 before Judge Denise Casper in the District of Massachusetts, and a fair-use ruling has been reported as expected during summer 2026, with a possible trial later in the year. Those proceedings could begin to set a legal standard for AI music training, but as of June 2026 the question remains undecided and the situation should be treated as developing.



