Claude Opus 4.8 vs Gemini 3.1 Pro: Coding Crown vs Best Value (2026)


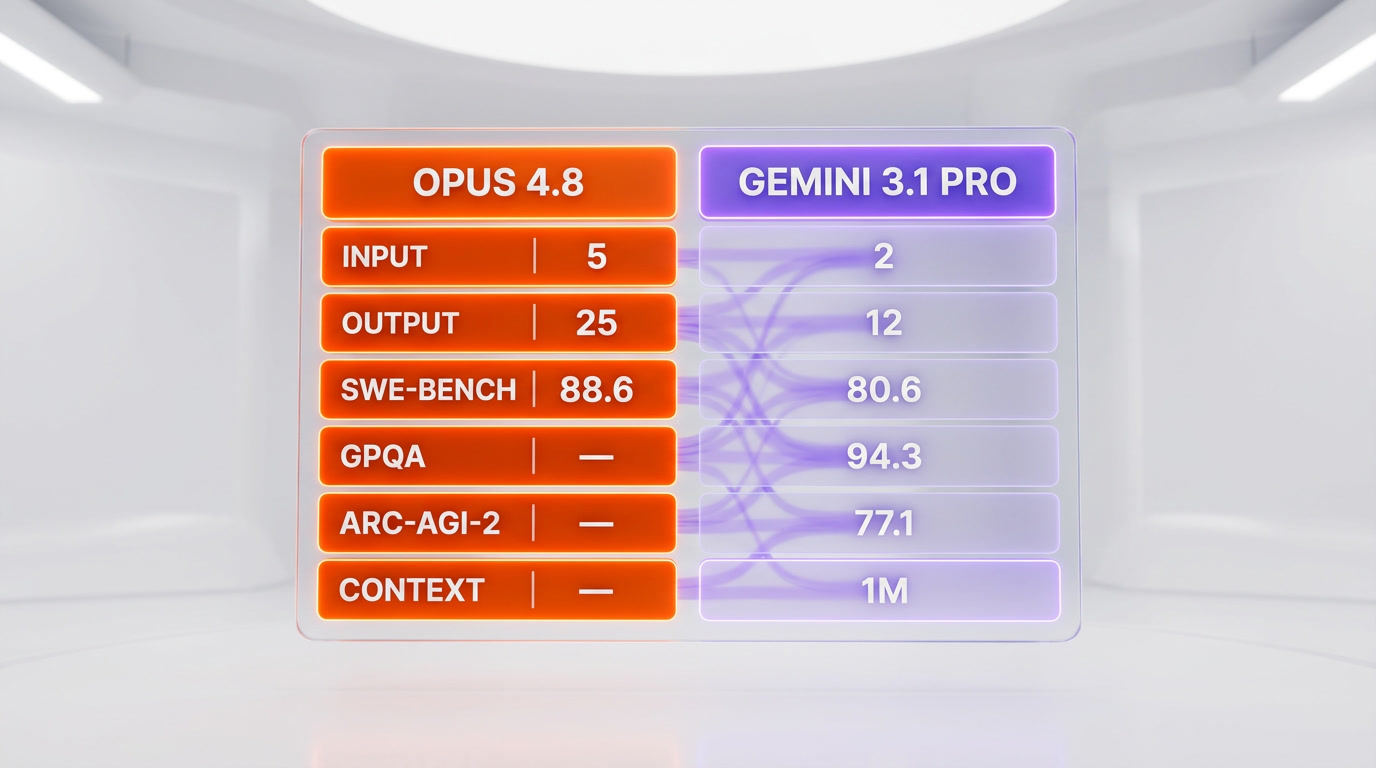
Opus 4.8 reports 88.6% SWE-bench; Gemini 3.1 Pro confirms 1M context and is 2.5x cheaper at $2 per million input. Which flagship wins for your team?

Feature Comparison
| Feature | Claude Opus 4.8 | Gemini 3.1 Pro Preview |
|---|---|---|
| Standard input price (per million tokens) | $5 | $2 (up to 200K), $4 (above 200K) |
| Standard output price (per million tokens) | $25 | $12 (up to 200K), $18 (above 200K) |
| SWE-bench Verified (coding) | 88.6% (Anthropic-reported, not independently verified) | 80.6% (single attempt, official model card) |
| GPQA Diamond (reasoning) | Not reported for Opus 4.8 | 94.3% (no tools, model card) |
| ARC-AGI-2 (abstract reasoning) | Not reported for Opus 4.8 | 77.1% (ARC Prize Verified) |
| Computer use (Online-Mind2Web) | 84% (Anthropic-reported) | Not reported on this benchmark |
| Confirmed context window | Not declared by Anthropic | 1M input / 64K output |
| Availability status | Generally available | Preview (GA expected later 2026) |
| Ecosystem reach | Broad cross-platform / cloud marketplace availability | Gemini API, Vertex AI, Gemini app, NotebookLM |
| Overall value for most teams | Strong coding specialist | Better-value generalist (price + context + reasoning) |
Pricing Comparison
Claude Opus 4.8
Gemini 3.1 Pro Preview
Detailed Comparison
Claude Opus 4.8 vs Gemini 3.1 Pro is a comparison between Anthropic's coding-and-agent flagship and Google DeepMind's reasoning-and-context flagship. Opus 4.8 (released May 28, 2026) costs $5 per million input tokens and $25 per million output tokens, and Anthropic reports a press-relayed SWE-bench Verified score of 88.6%. Gemini 3.1 Pro (model card dated February 19, 2026) confirms a 1M-token input context with 64K-token output, an officially reported SWE-bench Verified score of 80.6% on a single attempt, and verified pricing of $2 per million input tokens and $12 per million output tokens — roughly 2.5 times cheaper. If you need the strongest agentic coding model, Opus 4.8 leads on its own benchmark; if you need the best published reasoning scores, a confirmed 1M context, and the lower bill, Gemini 3.1 Pro wins. We compared published benchmarks, specs, and vendor-confirmed pricing rather than running a controlled head-to-head.
Disclosure: ThePlanetTools.ai has no affiliation with Anthropic or Google DeepMind. We are not paid to recommend either model, and there are no affiliate links in this comparison. Last compared: May 2026. Benchmark figures are attributed to their source, and where one vendor's numbers are press-relayed rather than independently verified, we flag it.
TL;DR: The Quick Verdict
We compared two flagship models that are built for different jobs, so a single "winner" hides more than it reveals. Here is the short version before the detail.
- Best for agentic coding: Claude Opus 4.8. Anthropic reports an 88.6% SWE-bench Verified result and an 84% Online-Mind2Web computer-use score. The headline coding number is the highest on the table — with the caveat that it is press-relayed and not independently verified.
- Best for published reasoning, context, and price: Gemini 3.1 Pro. Its official model card reports 94.3% on GPQA Diamond and 77.1% on ARC-AGI-2, confirms a 1M-token input window, and its pricing is vendor-confirmed at roughly 2.5 times cheaper than Opus 4.8.
- Best overall value for most teams: Gemini 3.1 Pro. When we weight what is actually verifiable — confirmed pricing, a confirmed context window, and officially reported reasoning scores — Gemini carries more proven ground. Opus 4.8 takes the coding crown on its own benchmark, but that benchmark is the one number we could not independently confirm.
This is a genuine split decision, not a fence-sit. If your workload is agentic software engineering, Opus 4.8 is the model to beat. For almost everything else — long-context analysis, hard reasoning, and budget-sensitive scale — Gemini 3.1 Pro is the smarter default.
Opus 4.8 vs Gemini 3.1 Pro at a Glance
Before the section-by-section breakdown, here is the headline comparison. Every number below is attributed to its source, and we mark the one case where a figure is press-relayed rather than independently verified.
| Dimension | Claude Opus 4.8 | Gemini 3.1 Pro | Edge |
|---|---|---|---|
| Vendor | Anthropic | Google DeepMind | Tie |
| Released / model card | May 28, 2026 | February 19, 2026 | Tie |
| Standard input price (per million tokens) | $5 | $2 (up to 200K), $4 (above 200K) | Gemini |
| Standard output price (per million tokens) | $25 | $12 (up to 200K), $18 (above 200K) | Gemini |
| SWE-bench Verified | 88.6% (Anthropic-reported, not independently verified) | 80.6% (single attempt, official model card) | Opus (see source caveat) |
| GPQA Diamond | Not reported for Opus 4.8 | 94.3% (no tools, model card) | Gemini (only one with a published score) |
| ARC-AGI-2 | Not reported for Opus 4.8 | 77.1% (ARC Prize Verified) | Gemini (only one with a published score) |
| Computer use | 84% Online-Mind2Web (Anthropic-reported) | Not reported on this benchmark | Opus (only one with a published score) |
| Confirmed context window | Not declared by Anthropic | 1M tokens input / 64K output | Gemini |
| Reasoning controls | Fast Mode (2.5x faster, higher price) | 3-level thinking system + new "Medium" level | Tie |
| Status | Generally available | Preview (GA expected later 2026) | Opus |
The single most important row to read carefully is SWE-bench Verified. Both numbers measure the same benchmark, which makes them comparable in principle — but the sources are not equal in confidence. We explain that asymmetry in detail below.
Claude Opus 4.8 in One Paragraph
Claude Opus 4.8 is Anthropic's flagship model, announced on May 28, 2026, and positioned squarely at software engineering and autonomous agents. Anthropic prices it at $5 per million input tokens and $25 per million output tokens, with an optional Fast Mode that runs about 2.5 times faster at $10 per million input and $50 per million output. Anthropic's launch table reports a SWE-bench Verified result of 88.6%, a SWE-bench Pro result of 69.2%, a Terminal-Bench 2.1 result of 74.6%, and an 84% score on Online-Mind2Web for computer use. We hold those coding numbers at arm's length: they are relayed from Anthropic's announcement and have not been independently verified by a third party, and Anthropic does not assert independent verification on the page. Notably, Anthropic does not declare a context window for Opus 4.8, so we do not state one.
Gemini 3.1 Pro in One Paragraph
Gemini 3.1 Pro is Google DeepMind's flagship reasoning model, documented in an official model card dated February 19, 2026. It confirms a 1M-token input context with 64K tokens of output — one of the largest confirmed windows in any frontier model. The model card reports strong reasoning scores: 94.3% on GPQA Diamond with no tools, 77.1% on ARC-AGI-2 under ARC Prize Verified conditions, and 44.4% on Humanity's Last Exam with no tools (rising to 51.4% with search and code). On coding, the card reports 80.6% on SWE-bench Verified on a single attempt. Gemini 3.1 Pro adds a three-level thinking system with a new "Medium" reasoning level, and ships across the Gemini API, Vertex AI, the Gemini app, and NotebookLM. It is currently in preview, with general availability expected later in 2026. Its pricing, which we confirmed directly on Google's vendor pages, is $2 per million input tokens and $12 per million output tokens up to 200K context, rising to $4 and $18 above that.
Benchmarks: What We Can Compare, and What We Cannot
This is where a lazy comparison would line up every number it could find and declare a winner. We will not do that, because most of these benchmarks were not run on both models. Here is the honest breakdown.
SWE-bench Verified: the one true head-to-head (with a source caveat)
SWE-bench Verified is the only benchmark on the table that both vendors report, which makes it the only genuinely comparable coding number we have. Opus 4.8 is reported at 88.6%; Gemini 3.1 Pro is reported at 80.6% on a single attempt. On the surface, that is an eight-point coding lead for Opus 4.8.
But the two figures do not carry equal confidence. Gemini's 80.6% comes from Google DeepMind's official model card, with the "single attempt" condition stated explicitly — a conservative, well-defined measurement. Opus 4.8's 88.6% comes from Anthropic's launch announcement, is press-relayed, and has not been independently verified, and Anthropic does not state the attempt conditions on the page the way the Gemini card does. So while the benchmark is like-for-like, the sourcing is not. We read this as: Opus 4.8 probably leads on agentic coding, but we would want third-party confirmation of the exact margin before treating 88.6% as gospel.
Reasoning: Gemini publishes scores Anthropic did not report
Gemini 3.1 Pro's model card reports 94.3% on GPQA Diamond (graduate-level science, no tools) and 77.1% on ARC-AGI-2 (abstract reasoning, ARC Prize Verified). These are strong numbers. The honest framing, however, is that Anthropic did not publish equivalent GPQA Diamond or ARC-AGI-2 figures for Opus 4.8, so we cannot oppose them directly. We can only say that Gemini publishes strong reasoning scores that Anthropic did not report for Opus 4.8 — which is a real point in Gemini's favor for buyers who care about documented reasoning performance, but not proof that Opus 4.8 would score lower.
Computer use: Opus reports a score Gemini did not
The mirror image is computer use. Opus 4.8 reports 84% on Online-Mind2Web, a browser-and-screen agent benchmark, and Gemini 3.1 Pro does not report a figure on that benchmark. Again, this is "where each was measured," not a head-to-head. It tells us Opus 4.8 is being marketed hard as a computer-use agent, and that Anthropic is confident enough to publish a number — but it is not evidence that Gemini would do worse.
How to read this section: only SWE-bench Verified compares both models on the same test. GPQA Diamond, ARC-AGI-2, and Humanity's Last Exam are Gemini-only on this table; Online-Mind2Web is Opus-only. Treat the non-overlapping scores as each vendor's chosen showcase, not as a direct contest.
Pricing: Gemini Is Confirmed Cheaper
Pricing is the cleanest win in this comparison because we confirmed every number directly on the vendor pages rather than trusting a summary. We fetched Anthropic's announcement for Opus 4.8 and both Google pricing pages (the Gemini API docs and the Vertex AI pricing page) for Gemini 3.1 Pro. The two Google pages agree with each other, which gives us high confidence.
| Tier | Claude Opus 4.8 | Gemini 3.1 Pro |
|---|---|---|
| Input, standard (per million tokens) | $5 | $2 up to 200K context, $4 above 200K |
| Output, standard (per million tokens) | $25 | $12 up to 200K context, $18 above 200K |
| Faster / priority option | Fast Mode: $10 input, $50 output (about 2.5x faster) | Priority tier available at a premium; Batch tier available cheaper ($1 input, $6 output up to 200K) |
At the standard tier and under 200K tokens of context, Gemini 3.1 Pro is roughly 2.5 times cheaper than Opus 4.8 on both input and output. Even above 200K tokens, where Gemini's price steps up to $4 input and $18 output, it remains below Opus 4.8's flat $5 and $25. Opus 4.8's Fast Mode, at $10 input and $50 output, widens the gap further — that mode buys speed, not savings. For any workload that processes large volumes of tokens, the price difference compounds quickly, and it favors Gemini by a clear margin.
We want to be explicit about one thing: earlier figures for Gemini's pricing were circulating only from a research summary, not from Google's own pages. We did not rely on that. We confirmed $2 input and $12 output (up to 200K), and $4 input and $18 output (above 200K), directly on Google's vendor pricing pages. We never assert a price we cannot pull from the vendor.
Context Window and Reasoning Controls
Context window is one of the few hard specs where the two models diverge cleanly. Gemini 3.1 Pro confirms a 1M-token input window with 64K tokens of output on its official model card. Anthropic does not declare a context window for Opus 4.8 on the announcement, so we will not invent one — if you need a guaranteed long-context model today, Gemini is the only one of the two that publishes the number.
On reasoning controls, both models give you a knob. Opus 4.8's lever is Fast Mode, which trades a higher price for roughly 2.5 times the speed. Gemini 3.1 Pro's lever is its three-level thinking system, now with an additional "Medium" reasoning level that sits between fast-and-cheap and slow-and-thorough. The two approaches solve different problems: Anthropic's is about latency, Google's is about how much the model deliberates before answering. Neither is strictly better; it depends on whether your bottleneck is wall-clock speed or reasoning depth.
Ecosystem and Availability
Where you can run each model matters as much as how it scores. Gemini 3.1 Pro is available across the Gemini API, Vertex AI, the Gemini consumer app, and NotebookLM, which means a team already inside Google Cloud can adopt it with almost no new plumbing. That ecosystem reach — especially Vertex AI for enterprise governance and NotebookLM for research workflows — is a genuine advantage for Google-centric organizations.
The trade-off is status. Gemini 3.1 Pro is still in preview, with general availability expected later in 2026, so teams with strict production-stability requirements may hesitate. Opus 4.8, by contrast, is generally available now. If "is it GA?" is a hard gate for your procurement, Opus 4.8 clears it today and Gemini 3.1 Pro does not yet.
Winner Per Category
Because these models are built for different jobs, the most useful way to pick is by use case rather than by an overall score.
- Best for agentic software engineering: Claude Opus 4.8. It posts the highest SWE-bench Verified figure on the table and publishes a strong computer-use score. If autonomous coding agents are your core workload, this is the model to beat — just keep the source caveat on the 88.6% in mind.
- Best for hard reasoning and science: Gemini 3.1 Pro. With 94.3% on GPQA Diamond and 77.1% on ARC-AGI-2 from its official model card, it is the only one of the two publishing top-tier reasoning numbers.
- Best for long-context work: Gemini 3.1 Pro. A confirmed 1M-token input window beats an undeclared one every time.
- Best for cost-sensitive scale: Gemini 3.1 Pro. Vendor-confirmed pricing roughly 2.5 times below Opus 4.8 is decisive for high-volume workloads.
- Best for production stability today: Claude Opus 4.8. It is generally available; Gemini 3.1 Pro is still in preview.
- Best for Google-native teams: Gemini 3.1 Pro. Native Vertex AI, the Gemini app, and NotebookLM integration is hard to beat if you already live in Google Cloud.
Pros and Cons of Each
Claude Opus 4.8
Pros
- Highest reported SWE-bench Verified score on the table at 88.6%
- Publishes a strong 84% computer-use score on Online-Mind2Web
- Generally available now, no preview caveat
- Fast Mode option for latency-sensitive workloads
Cons
- Headline coding benchmark is press-relayed and not independently verified
- No declared context window on the announcement
- Roughly 2.5 times more expensive than Gemini per token at standard tier
- No published GPQA Diamond or ARC-AGI-2 reasoning scores to compare
Gemini 3.1 Pro
Pros
- Confirmed 1M-token input context with 64K output
- Strong, officially documented reasoning scores (GPQA Diamond 94.3%, ARC-AGI-2 77.1%)
- Vendor-confirmed pricing roughly 2.5 times cheaper than Opus 4.8
- Deep Google ecosystem: Vertex AI, Gemini app, NotebookLM, three-level thinking
Cons
- Still in preview, with general availability expected later in 2026
- Lower reported SWE-bench Verified score than Opus 4.8 (80.6% single attempt)
- No published computer-use score to compare against Opus 4.8's 84%
- Pricing steps up above 200K tokens of context ($4 input, $18 output)
When to Pick Each Model
When to pick Claude Opus 4.8
Choose Opus 4.8 if agentic software engineering is the heart of your workload and you want the model with the highest reported coding benchmark, you need a generally available model today rather than a preview, and you value a strong published computer-use score for browser-and-screen automation. The honest caveat: you are betting partly on a press-relayed 88.6% that has not been independently verified, so run your own evaluation on your codebase before committing budget.
When to pick Gemini 3.1 Pro
Choose Gemini 3.1 Pro if you need a confirmed 1M-token context for long-document or large-codebase analysis, you care about documented reasoning performance on GPQA Diamond and ARC-AGI-2, your bill matters and you want roughly 2.5 times lower token costs, or you already operate inside Google Cloud and want native Vertex AI, Gemini app, and NotebookLM access. The trade-off is that it is still in preview, so production teams with strict stability gates should plan around general availability later in 2026.
How We Compared
We did not run a controlled head-to-head benchmark of both models on identical hardware and prompts — there is no such test here, and we will not pretend there is. Instead, we compared published benchmarks, official specs, and vendor-confirmed pricing. We have hands-on experience with Claude Opus 4.8 in our own coding workflow, which informs our read on its agentic behavior, but our experience with Gemini 3.1 Pro is lighter, so we lean on its official model card for performance claims rather than our own testing.
For pricing, we fetched the vendor pages directly: Anthropic's announcement for Opus 4.8, and both Google's Gemini API pricing docs and the Vertex AI pricing page for Gemini 3.1 Pro. For benchmarks, we attribute every figure to its source and flag the one case — Opus 4.8's SWE-bench Verified score — where the number is press-relayed rather than independently verified. Where only one model reports a benchmark, we say so rather than inventing an opponent's score. This is a specs-and-published-results comparison done transparently, not a marketing scoreboard.
A Real-World Cost Example
Per-token prices are abstract until you run them against a real workload, so here is a concrete illustration. Imagine an agentic coding pipeline that processes 50 million input tokens and produces 10 million output tokens in a month — a realistic figure for a team running automated code-review and refactoring agents at scale.
On Claude Opus 4.8 at the standard tier, that workload costs 50 million input tokens at $5 per million, which is $250, plus 10 million output tokens at $25 per million, which is $250 — a total of $500 for the month. On Gemini 3.1 Pro, assuming the work stays under 200K tokens of context per call, the same volume costs 50 million input tokens at $2 per million, which is $100, plus 10 million output tokens at $12 per million, which is $120 — a total of $220. That is a difference of $280 a month, or roughly 56% lower spend on Gemini, for the same token volume.
Two caveats keep this honest. First, if your context routinely exceeds 200K tokens, Gemini's price steps up to $4 input and $18 output, narrowing — but not closing — the gap. Second, raw price is not the same as value: if Opus 4.8's higher reported coding accuracy means fewer failed agent runs and less human cleanup, the cheaper model per token can end up costing more in engineering time. The point of the example is not that cheaper always wins, but that the price gap is large enough to matter and should be weighed against the coding-accuracy claim rather than ignored.
Switching Costs and Lock-In
If you are choosing between these two as a primary model, the practical friction of switching deserves a mention. Both expose standard chat-completion-style APIs, so the raw integration work is comparable. The real lock-in is ecosystem, not syntax. Gemini 3.1 Pro pulls you toward Google Cloud: Vertex AI for governance and deployment, the Gemini app for end users, and NotebookLM for research. If your organization already runs on Google Cloud, that gravity is a feature, and adoption is low-friction. If you do not, it is a consideration — you are buying into Google's surfaces to get the full benefit.
Opus 4.8 is more portable in the sense that Anthropic's models are widely available across third-party platforms and cloud marketplaces, so you are less tied to a single cloud. For teams that deliberately avoid hyperscaler lock-in, that neutrality is worth something. Neither model imposes punishing switching costs at the API level; the decision is mostly about which ecosystem you want to lean into, and whether the confirmed price advantage and context window of Gemini outweigh the coding-accuracy claim and current general availability of Opus 4.8.
The Final Verdict
If you came for a single name, here it is: for most teams, Gemini 3.1 Pro is the better default in May 2026 — and for one specific job, agentic coding, Opus 4.8 is the model to beat.
The reasoning is about what is verifiable. Gemini 3.1 Pro wins the dimensions we could confirm with hard evidence: a 1M-token context window on its official model card, top-tier reasoning scores documented by Google DeepMind, and pricing we pulled straight from Google's vendor pages at roughly 2.5 times below Opus 4.8. Opus 4.8 leads on the one benchmark both vendors report — SWE-bench Verified, 88.6% to 80.6% — but that 88.6% is the single number on this entire comparison that we could not independently verify, and Anthropic does not assert verification. We are not going to crown an overall winner on a figure we cannot confirm.
So the verdict is split and honest: pick Opus 4.8 for autonomous coding agents and computer-use automation, where it posts the strongest reported numbers and is generally available today. Pick Gemini 3.1 Pro for hard reasoning, long-context analysis, Google-ecosystem workflows, and budget-sensitive scale — which is to say, for most teams, most of the time. There is no fake tie here and no invented winner; there is a coding specialist and a better-value generalist, and which one wins is entirely a function of your workload.
Related Reading
If you are weighing this generation against the last one, our earlier head-to-head of Claude Opus 4.7 vs Gemini 3.1 Pro shows how the matchup has shifted. For the launch context behind the newer model, see our breakdown of what Claude Opus 4.8 changed for Claude Code, and for where Gemini 3.1 Pro is pushing hardest, read our coverage of Google's Deep Research Max on Gemini 3.1 Pro.
Frequently Asked Questions
What is Claude Opus 4.8?
Claude Opus 4.8 is Anthropic's flagship AI model, announced on May 28, 2026, and aimed at software engineering and autonomous agents. It is priced at $5 per million input tokens and $25 per million output tokens, with an optional Fast Mode at $10 input and $50 output that runs about 2.5 times faster. Anthropic reports a SWE-bench Verified score of 88.6%, though that figure is press-relayed and not independently verified.
What is Gemini 3.1 Pro?
Gemini 3.1 Pro is Google DeepMind's flagship reasoning model, documented in an official model card dated February 19, 2026. It confirms a 1M-token input context with 64K-token output, reports 94.3% on GPQA Diamond and 77.1% on ARC-AGI-2, and is priced at $2 per million input tokens and $12 per million output tokens up to 200K context. It is available on the Gemini API, Vertex AI, the Gemini app, and NotebookLM, and is currently in preview.
Which model is better at coding, Opus 4.8 or Gemini 3.1 Pro?
On the one benchmark both vendors report — SWE-bench Verified — Opus 4.8 leads at 88.6% versus Gemini 3.1 Pro's 80.6% on a single attempt. That points to Opus 4.8 being the stronger agentic coding model. The caveat is that Opus 4.8's number is press-relayed and not independently verified, while Gemini's comes from an official model card, so we would want third-party confirmation before treating the exact margin as final.
Which model is cheaper?
Gemini 3.1 Pro is clearly cheaper. We confirmed directly on Google's vendor pages that it costs $2 per million input tokens and $12 per million output tokens up to 200K context, versus Opus 4.8's $5 input and $25 output. That makes Gemini roughly 2.5 times cheaper at the standard tier, and it remains below Opus 4.8 even above 200K tokens, where Gemini steps up to $4 input and $18 output.
What is SWE-bench Verified and why does it matter here?
SWE-bench Verified is a benchmark that measures how well a model resolves real software-engineering issues from open-source repositories. It matters in this comparison because it is the only benchmark both Anthropic and Google DeepMind report for these two models, making it the single genuinely like-for-like coding number available. Opus 4.8 is reported at 88.6% and Gemini 3.1 Pro at 80.6% on a single attempt.
What is GPQA Diamond, and does Opus 4.8 have a score?
GPQA Diamond is a benchmark of graduate-level science questions designed to be hard to answer without genuine reasoning. Gemini 3.1 Pro's model card reports 94.3% with no tools. Anthropic did not publish a GPQA Diamond score for Opus 4.8, so the two cannot be compared directly on this benchmark — Gemini simply publishes a strong number that Anthropic did not report for Opus 4.8.
How big is each model's context window?
Gemini 3.1 Pro confirms a 1M-token input window with 64K tokens of output on its official model card. Anthropic does not declare a context window for Opus 4.8 in its announcement, so we do not state one. If a guaranteed long-context window is a requirement, Gemini 3.1 Pro is the only one of the two that publishes the figure.
Can I run Gemini 3.1 Pro on Vertex AI?
Yes. Gemini 3.1 Pro is available on Vertex AI, as well as the Gemini API, the Gemini consumer app, and NotebookLM. For enterprise teams already inside Google Cloud, Vertex AI access means adoption with minimal new infrastructure. Note that the model is still in preview, with general availability expected later in 2026.
What is NotebookLM and how does it relate to Gemini 3.1 Pro?
NotebookLM is Google's research and note-synthesis product, and it is one of the surfaces where Gemini 3.1 Pro is available. That matters for the comparison because it extends Gemini's reach beyond raw API access into a ready-made research workflow — an ecosystem advantage Opus 4.8 does not match on Google's surfaces.
Why can't you just declare one overall winner?
Because the two models are built for different jobs and most benchmarks were not run on both. Only SWE-bench Verified compares them like-for-like, and that one figure for Opus 4.8 is press-relayed rather than independently verified. We give Opus 4.8 the agentic-coding crown and Gemini 3.1 Pro the edge on reasoning, context, price, and overall value — a split decision based on what we can actually verify, not an invented tie.
Is Gemini 3.1 Pro's pricing confirmed or just reported?
Confirmed. We did not rely on the figures that were circulating from a research summary. We fetched both of Google's vendor pricing pages — the Gemini API docs and the Vertex AI pricing page — and they agree: $2 per million input tokens and $12 per million output tokens up to 200K context, rising to $4 and $18 above that. We never publish a price we cannot pull directly from the vendor.
Which model should most teams choose in 2026?
For most teams, Gemini 3.1 Pro is the better default thanks to its confirmed 1M context, documented reasoning scores, and roughly 2.5 times lower pricing. The exception is teams whose core workload is agentic software engineering, where Opus 4.8's higher reported coding benchmark and current general availability make it the model to beat — provided you validate its performance on your own codebase given the source caveat on its headline number.

Our Verdict
Split decision. For agentic software engineering, Claude Opus 4.8 leads on the one benchmark both vendors report (SWE-bench Verified 88.6% vs 80.6%) and is generally available today — but that 88.6% is press-relayed and not independently verified. For most other teams, Gemini 3.1 Pro is the better overall value: it wins the dimensions we could confirm with hard evidence — a 1M-token context window, top-tier published reasoning scores (GPQA Diamond 94.3%, ARC-AGI-2 77.1%), and vendor-confirmed pricing roughly 2.5 times cheaper than Opus 4.8. Best for agentic coding: Opus 4.8. Best for reasoning, context, and price: Gemini 3.1 Pro.
Choose Claude Opus 4.8
Anthropic's flagship model for agentic coding, computer use, and multi-agent orchestration.
Try Claude Opus 4.8 →Choose Gemini 3.1 Pro Preview
Google DeepMind's flagship Gemini 3.1 Pro Preview — 94.3% GPQA Diamond, 77.1% ARC-AGI-2, 1M-token context, multimodal in/text out, vibe coding plus agentic tool use. Preview status as of April 2026.
Try Gemini 3.1 Pro Preview →Frequently Asked Questions
Is Claude Opus 4.8 better than Gemini 3.1 Pro Preview?
Split decision. For agentic software engineering, Claude Opus 4.8 leads on the one benchmark both vendors report (SWE-bench Verified 88.6% vs 80.6%) and is generally available today — but that 88.6% is press-relayed and not independently verified. For most other teams, Gemini 3.1 Pro is the better overall value: it wins the dimensions we could confirm with hard evidence — a 1M-token context window, top-tier published reasoning scores (GPQA Diamond 94.3%, ARC-AGI-2 77.1%), and vendor-confirmed pricing roughly 2.5 times cheaper than Opus 4.8. Best for agentic coding: Opus 4.8. Best for reasoning, context, and price: Gemini 3.1 Pro.
Which is cheaper, Claude Opus 4.8 or Gemini 3.1 Pro Preview?
Claude Opus 4.8 is priced at $5 in / $25 out per M tokens. Gemini 3.1 Pro Preview is priced at $2 in / $12 out per M tokens. Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Opus 4.8 and Gemini 3.1 Pro Preview?
The key differences span across 10 features we compared. For Standard input price (per million tokens), Claude Opus 4.8 offers $5 while Gemini 3.1 Pro Preview offers $2 (up to 200K), $4 (above 200K). For Standard output price (per million tokens), Claude Opus 4.8 offers $25 while Gemini 3.1 Pro Preview offers $12 (up to 200K), $18 (above 200K). For SWE-bench Verified (coding), Claude Opus 4.8 offers 88.6% (Anthropic-reported, not independently verified) while Gemini 3.1 Pro Preview offers 80.6% (single attempt, official model card). See the full feature comparison table above for all details.