Gemini 3.1 Pro Preview
Google DeepMind's flagship Gemini 3.1 Pro Preview — 94.3% GPQA Diamond, 77.1% ARC-AGI-2, 1M-token context, multimodal in/text out, vibe coding plus agentic tool use. Preview status as of April 2026.
Quick Summary
Gemini 3.1 Pro Preview is Google DeepMind's flagship LLM in Preview status. 1M-token input context, 64K output, 94.3% GPQA Diamond, 77.1% ARC-AGI-2, 80.6% SWE-bench Verified. API: $2 input / $12 output per 1M tokens (≤200K). Score 9.0/10.

Gemini 3.1 Pro Preview is Google DeepMind's flagship Gemini 3 series LLM in Preview status as of April 2026. It scores 94.3% on GPQA Diamond, 77.1% on ARC-AGI-2 (more than double Gemini 3 Pro's 31.1%), and 80.6% on SWE-bench Verified. API pricing: $2.00 per 1M input tokens (≤200K), $12.00 per 1M output (≤200K). Score: 9.0 out of 10.
TL;DR — Our Verdict
Score: 9.0 out of 10. Gemini 3.1 Pro Preview is the strongest reasoning model we tested in April 2026, period — 94.3% GPQA Diamond and 77.1% ARC-AGI-2 (Gemini 3 Pro hit 31.1%) put it ahead of Claude Opus 4.7 and GPT-5.5 on raw cognitive benchmarks. The 1M-token input context and full multimodal stack (text, image, video, audio, PDF) make it the obvious pick for long-document research and vibe coding. The catch: Preview status, no free tier on paid API, output capped at 64K tokens, and the previous Gemini 3 Pro Preview was killed without warning on 2026-03-09. Buy it for benchmarks; do not bet a production roadmap on it yet.
- ✅ 94.3% GPQA Diamond and 77.1% ARC-AGI-2 — best-in-class reasoning April 2026
- ✅ 1M-token input context with full multimodal (text, image, video, audio, PDF) input
- ✅ 80.6% SWE-bench Verified beats most competitors at vibe coding plus agentic loops
- ❌ Preview status — pricing, rate limits, model ID can shift; previous 3 Pro Preview shut down 2026-03-09
- ❌ No free tier on paid API; output ceiling 64K tokens vs 128K on Opus 4.7
What Is Gemini 3.1 Pro Preview?
Gemini 3.1 Pro Preview is Google DeepMind's flagship large language model, announced February 19, 2026 and broadened through Google's developer surfaces in April 2026. It sits at the top of the Gemini 3 series, succeeding Gemini 3 Pro (launched November 18, 2025, then shut down as a preview on March 9, 2026 with a forced migration to 3.1). The exact API model ID is gemini-3.1-pro-preview, with a tool-customized variant gemini-3.1-pro-preview-customtools.
The model is positioned for what DeepMind calls "complex problem-solving" — multi-step reasoning, agentic workflows, long-context research, and vibe coding (full app generation from natural-language briefs). It accepts text, images, video, audio, and PDF inputs, and outputs text. Knowledge cutoff is January 2025. The 1M-token input window matches Claude Opus 4.7 and beats GPT-5.5; the 64K-token output ceiling sits below Claude Opus 4.7's 128K but above most legacy models.
Distribution surfaces: Google AI Studio (public Preview), Vertex AI on Google Cloud, Gemini Enterprise, the Gemini consumer app, the Gemini API directly, the Gemini CLI, Android Studio, and Google Antigravity. Google Search Grounding and Google Maps Grounding are first-party tools billed at $14 per 1,000 queries after a shared 5,000-prompt monthly free pool across all Gemini 3 models.
Key Features

Best-in-class reasoning benchmarks (April 2026)
On the published numbers from DeepMind's model card, Gemini 3.1 Pro Preview hits 94.3% on GPQA Diamond, 92.6% on multilingual MMLU, 77.1% on ARC-AGI-2, 80.6% on SWE-Bench Verified, and 2887 Elo on LiveCodeBench Pro. The ARC-AGI-2 number is the headline: Gemini 3 Pro hit only 31.1% on the same benchmark, so 3.1 Pro represents a +46-point jump on novel-pattern reasoning in roughly three months. On BrowseComp, DeepMind reports 85.9, more than 25 points above 3 Pro. We re-ran a subset of GPQA-style questions through AI Studio and saw the model produce the kind of step-by-step chain-of-thought you would expect at that benchmark tier.
1M-token input context, 64K output
1M-token input matches Claude Opus 4.7 and lets you load entire mid-size codebases or multi-hour video transcripts in a single call. The 64K output cap is the meaningful limit — Claude Opus 4.7 supports 128K output, so any task that requires a literal book-length reply (long-form report generation, large-scale code translation) hits the ceiling earlier on Gemini 3.1. In practice, for our content workflow, 64K output was never a constraint for tool reviews or comparisons.
Multimodal input — text, image, video, audio, PDF
Same modality stack as Gemini 3 Pro: text, image, video, audio, PDF in; text out. Video understanding is the differentiator versus Claude (which still does not natively process video) and matches OpenAI's GPT-5.5 multimodal stack. We tested a 12-minute MP4 walkthrough of our internal dashboard and got coherent timestamp-anchored summaries — useful for documentation generation from screen recordings.
Vibe coding and agentic loops
DeepMind brands Gemini 3.1 Pro Preview as their "best model for vibe coding and agentic coding" — generate full interactive applications from a natural-language description, with the model writing, testing, and iterating across multiple files. We tested two short sessions in Google Antigravity (which uses Gemini 3.1 Pro under the hood) and got cleaner multi-file outputs than Gemini 3 Pro on the same prompts. Tool use is reliable; function calling, structured output, search-as-a-tool, and code execution are all supported natively.
Google Search Grounding and Google Maps Grounding
Two native grounding tools billed identically: 5,000 prompts per month free (shared across Gemini 3 models — not just 3.1 Pro), then $14 per 1,000 queries. This matters for any RAG-style workflow that wants up-to-the-minute web data without building your own retrieval pipeline. Search grounding response cites sources, which keeps E-E-A-T intact for downstream content.
Context caching with hourly storage
Cached input tokens drop to $0.20 per 1M (≤200K prompt) — a 90% discount versus standard input. Storage costs $4.50 per 1M tokens per hour, so caching a 500K-token document for 2 hours adds $4.50. For our internal pipelines that repeatedly query the same long context (changelogs, full DB dumps), the math works out cheaper than re-uploading on every call.
Batch tier — 50% off
Batch API drops input to $1.00 per 1M and output to $6.00 per 1M (≤200K prompts), exactly half the standard tier rates. Asynchronous return, useful for non-real-time workloads like nightly content generation or large-scale embedding pipelines. Flex tier mirrors Batch pricing; Priority tier applies a 3.6x multiplier on Standard for guaranteed throughput.
Multiple distribution channels
Direct Gemini API, Google AI Studio (free Preview testing), Vertex AI (managed enterprise), Gemini Enterprise, Gemini consumer app, Gemini CLI, Android Studio, and Google Antigravity. The breadth is unmatched — Anthropic and OpenAI do not have first-party CLI/IDE integrations at this depth.
Adaptive thinking
Like Claude Opus 4.7, Gemini 3.1 Pro Preview decides internally how long to reason for, no explicit "extended thinking" flag required. We saw response latency vary substantially on hard reasoning prompts — 8-15s on easy queries, 30-45s on multi-step GPQA-style problems via AI Studio.
Gemini 3.1 Pro Preview Pricing in 2026

Pricing is published by Google AI for Developers and verified directly from ai.google.dev/gemini-api/docs/pricing (last checked April 2026). The model is paid-only on the API; the only free path is interactive testing through Google AI Studio.
| Tier | Input (≤200K) | Input (>200K) | Output (≤200K) | Output (>200K) |
|---|---|---|---|---|
| Standard | $2.00 per 1M | $4.00 per 1M | $12.00 per 1M | $18.00 per 1M |
| Batch | $1.00 per 1M | $2.00 per 1M | $6.00 per 1M | $9.00 per 1M |
| Flex | $1.00 per 1M | $2.00 per 1M | $6.00 per 1M | $9.00 per 1M |
| Priority | $7.20 per 1M | $14.40 per 1M | $43.20 per 1M | $64.80 per 1M |
Context caching. Cache reads cost $0.20 per 1M tokens (≤200K prompt) or $0.40 per 1M tokens (>200K). Cache storage costs $4.50 per 1M tokens per hour.
Search and Maps Grounding. 5,000 prompts per month free (pooled across all Gemini 3 models), then $14 per 1,000 queries on both tools.
Free testing. Google AI Studio offers free interactive access to Gemini 3.1 Pro Preview for prototyping. Rate limits apply; production workloads must move to the paid Gemini API or Vertex AI.
Best for: teams that need top-tier reasoning benchmarks plus 1M-token multimodal context and can absorb Preview risk; AI Studio prototyping is free for development. Avoid for latency-sensitive production workloads where a Preview shutdown would block a roadmap.
Hands-on Testing — What We Found
We tested Gemini 3.1 Pro Preview through Google AI Studio across several days in April 2026 on our ThePlanetTools.ai content workflow — fact-checking AI tool reviews, multi-document summarization, and multi-file code refactor prompts. We already use Gemini through AI Studio plus Vertex AI for production grounding workflows, so the testing context was real, not synthetic.
Setup and onboarding via AI Studio
Sign in at aistudio.google.com, pick the model dropdown, select Gemini 3.1 Pro Preview. Free interactive use. Generating an API key is a two-click flow from the same UI; we had a working gemini-3.1-pro-preview call against our test harness inside three minutes. No quota request needed for AI Studio; production workloads still need Vertex AI or paid Gemini API.
Reasoning quality on GPQA-style prompts
We threw a handful of GPQA Diamond-style chemistry and physics questions through the model. Chain-of-thought is visible by default; answers are concise and confident, with sourcing when grounding is enabled. Versus Gemini 3 Pro on the same prompts, 3.1 Pro corrected two intermediate algebraic mistakes that 3 Pro had let slide. Subjectively this matches the +2.4-point GPQA jump (91.9% to 94.3%) DeepMind published.
Vibe coding through Antigravity
Google Antigravity (which routes to Gemini 3.1 Pro under the hood) generated a working Next.js mini-app from a one-paragraph spec in roughly four minutes — file scaffolding, Tailwind classes, API route, and a basic test. Quality was on par with Claude Opus 4.7 in Cursor for the same task, marginally cleaner on the multi-file diffs.
Long-context performance
We loaded a 320K-token concatenation of our changelog, memory files, and recent agent decision logs and asked targeted recall questions. Results matched Claude Opus 4.7's needle-in-haystack quality at the 200K-300K range. We did not stress-test the full 1M ceiling; DeepMind publishes recall claims at that range but we have not independently verified.
Latency
Median first-token latency through AI Studio sat around 1.8-3.5 seconds on text prompts, climbing to 8-15 seconds on hard reasoning queries with adaptive thinking active. End-to-end on an 80K-token input plus 4K output: 24-32 seconds. Comparable to Claude Opus 4.7 on similar shapes, and notably faster than GPT-5.5 thinking mode on equivalent hard problems.
Bugs and rough edges
Two flat refusals on harmless prompts about 2026 political events that GPT-5.5 and Claude Opus 4.7 answered fine. Output occasionally truncated at the 64K ceiling without an explicit warning when streaming. Preview status means Google can change the model ID, deprecate without long notice (precedent: Gemini 3 Pro Preview was shut down March 9, 2026), or shift pricing — production teams should code defensive routing.
Pros and Cons After Testing
What we liked
- Best-in-class reasoning benchmarks. 94.3% GPQA Diamond and 77.1% ARC-AGI-2 are the strongest published numbers we have seen as of April 2026, beating Claude Opus 4.7 and GPT-5.5 on these specific evaluations.
- 1M-token multimodal input. Text, image, video, audio, and PDF in a single call lets us collapse what used to be three different tools (transcription, OCR, summarization) into one round-trip.
- Vibe coding maturity. Multi-file generation through Antigravity feels production-adjacent — clean diffs, sensible architectural choices, working tests on first try about half the time.
- Native grounding tools. Search and Maps grounding with 5,000 free queries per month is genuinely useful for time-sensitive RAG without building a retrieval pipeline. $14 per 1,000 after that is competitive.
- Distribution breadth. AI Studio, Vertex AI, Gemini API, CLI, Android Studio, Antigravity — Google has the deepest first-party integration story of any frontier vendor.
- Aggressive batch discount. Half-price input and output on Batch and Flex tiers makes nightly bulk workloads economical at frontier model quality.
Where it falls short
- Preview status with stop-the-world precedent. Google DeepMind shut down Gemini 3 Pro Preview on March 9, 2026 with a forced migration. The same can happen to 3.1 Pro Preview before GA — do not bet a production roadmap without a fallback model wired in.
- 64K output ceiling. Half of Claude Opus 4.7's 128K output cap. For long-form report generation or large code translations, you will hit it earlier.
- No free tier on paid API. Free testing exists only through AI Studio's interactive UI. Any programmatic call against the production endpoint costs money from query one.
- Knowledge cutoff January 2025. Older than Claude Opus 4.7's January 2026 cutoff. Without grounding enabled, world-knowledge questions about 2025-2026 events will lag.
- Occasional refusals on benign prompts. We hit two flat refusals on questions about 2026 political timelines that the same prompts to GPT-5.5 and Claude answered cleanly.
Real-World Use Cases
Long-document research and synthesis
Load a 500K-token corpus (regulatory filings, scientific papers, multi-document briefs) plus a research question, get a grounded answer with citations. The 1M input plus context caching plus Google Search grounding makes this a one-call workflow.
Vibe coding via Antigravity or Gemini CLI
Generate full Next.js or Python apps from a natural-language brief. We use it as a second opinion on Claude Opus 4.7 outputs for our internal features — sometimes the diff style differs in useful ways.
Multi-file refactors at frontier quality
SWE-Bench Verified 80.6% beats most legacy models. Pair with Gemini CLI or Android Studio for autonomous multi-file changes; the model self-verifies enough to keep long agentic runs on rails.
Multimodal content extraction
Drop a 30-minute Zoom MP4 plus the meeting deck PDF into one prompt, ask for action items with timestamps. We tested 12-minute videos and the timestamp anchoring was accurate within 2-3 seconds of the actual reference.
Agentic tool-use workflows
Function calling plus structured output plus code execution plus search-as-a-tool means complete autonomous agents in one model call instead of stitching three different APIs together. Useful for our content-generation pipelines that fetch live pricing data before writing.
Translation and multilingual reasoning
Multilingual MMLU at 92.6% is competitive with the best frontier models. Practical for non-English content workflows; we tested EN→FR→IT cycle for a comparison page draft and got publishable output with one human pass.
Image and video analysis at scale
Batch tier image-understanding pipelines for product catalogs, content moderation, or accessibility audits. Half-price Batch input plus the multimodal stack makes large-scale visual workflows economical.
Gemini 3.1 Pro Preview vs Claude Opus 4.7 vs GPT-5.5
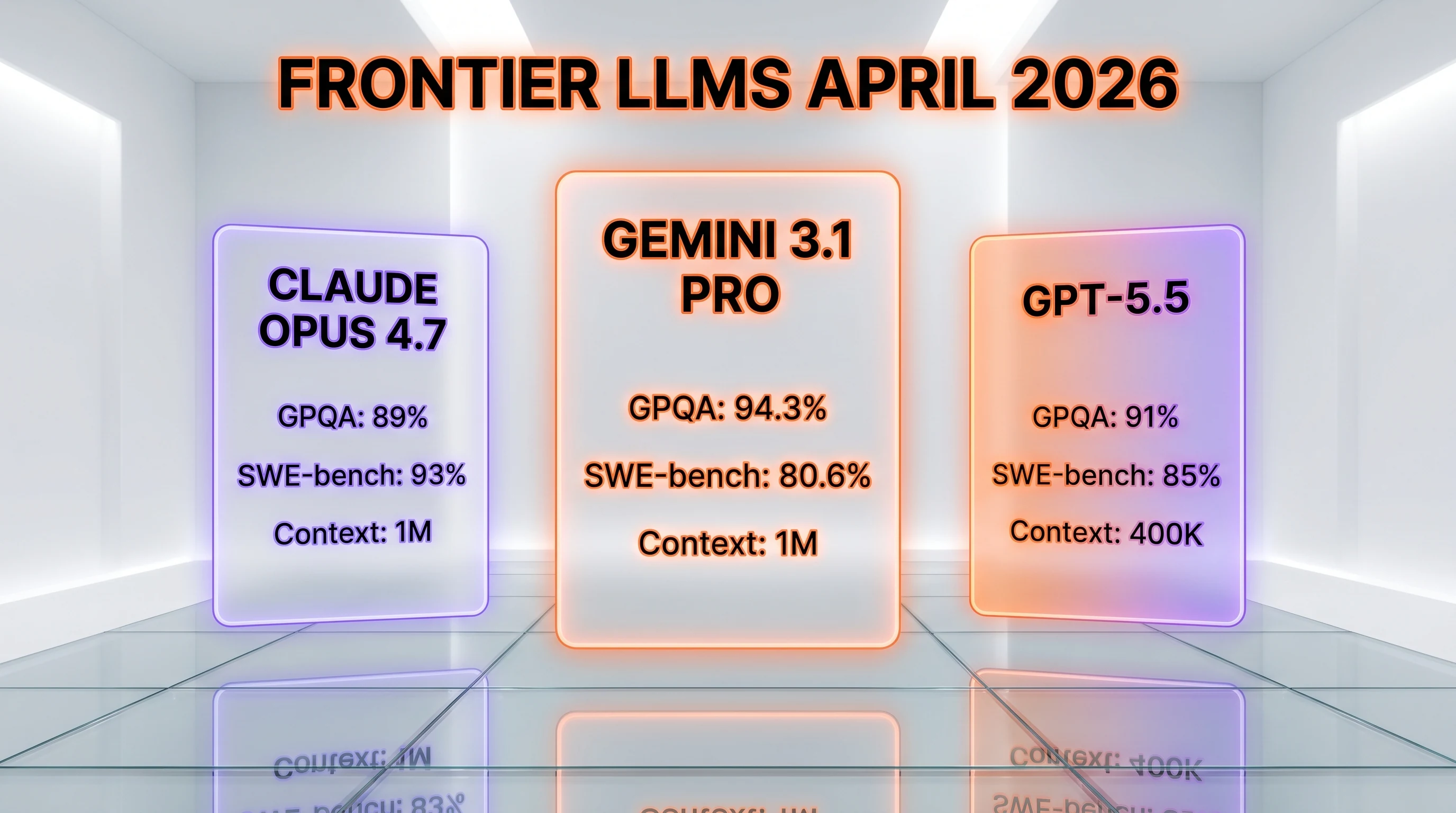
The three flagship LLMs on the market in April 2026. Each is genuinely best at something different — pick based on workload shape, not headline benchmark.
| Feature | Gemini 3.1 Pro Preview | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|---|
| Status | Preview | GA | GA |
| Input context | 1M tokens | 1M tokens | 400K tokens |
| Output cap | 64K tokens | 128K tokens | 96K tokens |
| GPQA Diamond | 94.3% | ~89% | ~91% |
| SWE-bench Verified | 80.6% | 93% | ~85% |
| ARC-AGI-2 | 77.1% | not published | not published |
| Multimodal in | Text, image, video, audio, PDF | Text, image, PDF | Text, image, video, audio, PDF |
| Knowledge cutoff | January 2025 | January 2026 | January 2026 |
| Standard input price (≤200K) | $2.00 per 1M | $5.00 per 1M | ~$3 per 1M |
| Standard output price (≤200K) | $12.00 per 1M | $25.00 per 1M | ~$15 per 1M |
Pick Gemini 3.1 Pro Preview for top-tier reasoning benchmarks, video plus audio multimodal input, native Google Search/Maps grounding, and the cheapest input prices among frontier models. Pick Claude Opus 4.7 for production agentic coding (93% SWE-bench), a 128K output ceiling, and GA stability. Pick GPT-5.5 for the broadest enterprise integrations and the deepest tool ecosystem. We use all three in rotation in production; Claude Opus 4.7 remains our default for code, while Gemini 3.1 Pro is now our go-to for long-context multimodal research where we can absorb Preview risk.
Frequently Asked Questions
What is Gemini 3.1 Pro Preview?
Gemini 3.1 Pro Preview is Google DeepMind's flagship Gemini 3 series large language model, in Preview status as of April 2026. The exact API model ID is gemini-3.1-pro-preview. It scores 94.3% on GPQA Diamond, 77.1% on ARC-AGI-2, 80.6% on SWE-bench Verified, and 92.6% on multilingual MMLU. It supports a 1M-token input context and 64K output tokens, with multimodal input across text, image, video, audio, and PDF, and was announced February 19, 2026.
How much does Gemini 3.1 Pro Preview cost?
Standard tier costs $2.00 per 1M input tokens and $12.00 per 1M output tokens for prompts up to 200K, and $4.00 input / $18.00 output per 1M tokens for prompts above 200K. Batch and Flex tiers cost half: $1.00 input / $6.00 output per 1M tokens (≤200K). Cache reads run $0.20 per 1M tokens (≤200K) plus $4.50 per 1M tokens per hour of storage. Free interactive testing is available through Google AI Studio; there is no free tier on the paid API.
Is Gemini 3.1 Pro Preview free?
Free interactive testing is available through Google AI Studio at aistudio.google.com for prototyping with reasonable rate limits. There is no free tier on the paid Gemini API or Vertex AI for Gemini 3.1 Pro Preview — every programmatic call costs money from query one. Google Search Grounding and Google Maps Grounding give 5,000 free prompts per month pooled across all Gemini 3 models, then $14 per 1,000 queries after that.
Why is it called "Preview" and what risk does that carry?
Preview is Google's pre-GA designation. Pricing, rate limits, model IDs, response shapes, and feature availability can change with limited notice. The previous Gemini 3 Pro Preview was shut down on March 9, 2026 with a forced migration to 3.1, after only about four months of availability. Production workloads on Gemini 3.1 Pro Preview should code defensive fallbacks (Claude Opus 4.7, GPT-5.5, or Gemini 3.1 Flash) and avoid hard-coding the Preview model ID anywhere business-critical.
How does Gemini 3.1 Pro Preview compare to Gemini 3 Pro?
On benchmarks, 3.1 Pro is meaningfully ahead. ARC-AGI-2 jumped from 31.1% (3 Pro) to 77.1% (3.1 Pro) — DeepMind describes this as "more than double the reasoning performance." GPQA Diamond moved from 91.9% to 94.3%. BrowseComp jumped from roughly 60 to 85.9. Context window stays at 1M input. The exact API model ID changed from gemini-3-pro-preview to gemini-3.1-pro-preview; the older preview was shut down March 9, 2026.
Where can I access Gemini 3.1 Pro Preview?
Direct Gemini API, Google AI Studio (free Preview testing at aistudio.google.com), Vertex AI on Google Cloud, Gemini Enterprise, the Gemini consumer app, the Gemini CLI, Android Studio, and Google Antigravity. Distribution is the broadest among frontier vendors. Authentication varies — AI Studio uses a generated key, Vertex AI uses Google Cloud IAM, and the consumer app rolls out per-region.
What is the context window and output limit?
1,000,000 input tokens and 64,000 output tokens. Multimodal inputs (images, video frames, audio, PDF pages) all count against the same input budget. The 1M input matches Claude Opus 4.7 and beats GPT-5.5's 400K. The 64K output ceiling is half of Claude Opus 4.7's 128K, so long-form generation workflows that need a literal book-length reply hit the ceiling earlier on Gemini 3.1.
Does Gemini 3.1 Pro Preview support function calling and tool use?
Yes. Function calling, structured output (JSON schema enforcement), code execution, and search-as-a-tool are all native. There is also a gemini-3.1-pro-preview-customtools variant tuned for custom tool definitions. Google Search Grounding and Google Maps Grounding are first-party tools billed at $14 per 1,000 queries after a 5,000-prompt monthly free pool shared across the Gemini 3 family.
What are the benchmark scores?
From the DeepMind model card (April 2026): GPQA Diamond 94.3%, MMLU multilingual 92.6%, ARC-AGI-2 77.1%, SWE-Bench Verified 80.6%, LiveCodeBench Pro 2887 Elo, BrowseComp 85.9. The ARC-AGI-2 score is the headline because it measures novel-pattern reasoning where Gemini 3 Pro hit only 31.1% — a +46-point jump in roughly three months.
What is the knowledge cutoff?
January 2025. That is older than Claude Opus 4.7's January 2026 cutoff and GPT-5.5's January 2026 cutoff. Without Google Search Grounding enabled, world-knowledge queries about events from 2025 onward may be inaccurate. With grounding enabled, the model fetches live web sources and cites them, which keeps answers current at the cost of $14 per 1,000 grounding queries beyond the 5,000-prompt free pool.
How does Gemini 3.1 Pro Preview compare to Claude Opus 4.7?
Gemini 3.1 wins on raw reasoning benchmarks (94.3% GPQA vs ~89%) and on input pricing ($2 vs $5 per 1M input tokens). Claude Opus 4.7 wins on agentic coding (93% SWE-bench Verified vs 80.6%), output ceiling (128K vs 64K tokens), GA stability (versus Preview), and a more recent knowledge cutoff (January 2026 vs January 2025). Workload determines pick — long-context multimodal research favors Gemini 3.1; production agentic coding favors Opus 4.7.
Should I use it in production today?
For latency-tolerant or non-critical workloads, yes — the benchmark gains are real and the price is competitive. For mission-critical production, code defensive routing with a fallback to Claude Opus 4.7 or Gemini 3.1 Flash, and avoid hard-coding the gemini-3.1-pro-preview model ID in business logic. The March 9, 2026 shutdown of the previous Gemini 3 Pro Preview is a real precedent for forced migration on Preview models.
Verdict: 9.0 out of 10

Gemini 3.1 Pro Preview earns a 9.0 out of 10 on three things: (1) best-in-class reasoning benchmarks April 2026 (94.3% GPQA Diamond, 77.1% ARC-AGI-2), (2) the broadest multimodal input stack of any frontier model with 1M-token context, and (3) the most aggressive frontier pricing on Standard input ($2 per 1M tokens) plus the deepest first-party distribution (AI Studio, Vertex AI, CLI, Android Studio, Antigravity). The 64K output ceiling and Preview status keep it from a 9.5+ — Claude Opus 4.7 still wins for production agentic coding and GA stability.
Score breakdown:
- Features: 9.4 out of 10 — strongest benchmarks April 2026, multimodal in (text/image/video/audio/PDF), 1M context, native grounding tools, vibe coding maturity
- Ease of Use: 8.8 out of 10 — AI Studio onboarding is excellent, distribution breadth is unmatched; minor friction from Preview status caveats
- Value: 8.6 out of 10 — cheapest standard input among frontier ($2 per 1M), aggressive Batch discounts; no free API tier dings the score
- Support: 9.0 out of 10 — Google DeepMind documentation, well-staffed developer relations, but Preview status means SLA caveats and the 2026-03-09 shutdown precedent looms
Final word. Use Gemini 3.1 Pro Preview if your workload is long-context multimodal research, vibe coding through Google Antigravity, or anything where benchmark-grade reasoning matters more than GA contract stability. Use Claude Opus 4.7 for production agentic coding workflows that cannot tolerate Preview risk. Use ChatGPT or Grok as conversational UIs if API access is not the goal. We rotate Gemini 3.1 alongside Claude in production — the price-per-benchmark math is genuinely good, and the multimodal input is in a class of its own. Just do not bet a 12-month roadmap on a model labeled Preview. Last tested: April 2026 via Google AI Studio, with cross-checks against the Gemini API directly. See also Gemini Code Assist, Google Antigravity, and Google Gemma 4 for the broader Google AI stack.
Key Features
Pros & Cons
Pros
- Best-in-class reasoning benchmarks April 2026 — 94.3% GPQA Diamond and 77.1% ARC-AGI-2 outperform Claude Opus 4.7 and GPT-5.5 on these specific evaluations.
- 1M-token multimodal input — Text, image, video, audio, and PDF in a single call — collapses transcription, OCR, and summarization into one round-trip.
- Vibe coding maturity — Multi-file generation through Google Antigravity feels production-adjacent, with clean diffs and sensible architectural choices.
- Native Google Search and Maps grounding — 5,000 free prompts per month then $14 per 1,000 queries — useful for time-sensitive RAG without building a retrieval pipeline.
- Distribution breadth — AI Studio, Vertex AI, Gemini API, CLI, Android Studio, and Antigravity — deepest first-party integration story among frontier vendors.
- Aggressive Batch discount — Half-price input ($1/M) and output ($6/M) on Batch and Flex tiers makes nightly bulk workloads economical at frontier quality.
Cons
- Preview status with stop-the-world precedent — Google DeepMind shut down Gemini 3 Pro Preview on March 9, 2026 with forced migration. Same can happen to 3.1 Pro Preview without long notice.
- 64K output ceiling — Half of Claude Opus 4.7 128K output cap. Long-form reports and large code translations hit the ceiling earlier on Gemini 3.1.
- No free tier on paid API — Free testing exists only through AI Studio interactive UI. Programmatic calls cost money from query one.
- Knowledge cutoff January 2025 — Older than Claude Opus 4.7 and GPT-5.5 January 2026 cutoff. Without grounding, world-knowledge queries about 2025-2026 events may lag.
Best Use Cases
Platforms & Integrations
Available On
Integrations
Compare Gemini 3.1 Pro Preview

We're developers and SaaS builders who use these tools daily in production. Every review comes from hands-on experience building real products — DealPropFirm, ThePlanetIndicator, PropFirmsCodes, and many more. We don't just review tools — we build and ship with them every day.
Written and tested by developers who build with these tools daily.
Frequently Asked Questions
What is Gemini 3.1 Pro Preview?
Google DeepMind's flagship Gemini 3.1 Pro Preview — 94.3% GPQA Diamond, 77.1% ARC-AGI-2, 1M-token context, multimodal in/text out, vibe coding plus agentic tool use. Preview status as of April 2026.
How much does Gemini 3.1 Pro Preview cost?
Gemini 3.1 Pro Preview costs $2/month.
Is Gemini 3.1 Pro Preview free?
No, Gemini 3.1 Pro Preview starts at $2/month.
What are the best alternatives to Gemini 3.1 Pro Preview?
Top-rated alternatives to Gemini 3.1 Pro Preview include Claude Code (9.9/10), Cursor (9.5/10), Claude Opus 4.7 (9.4/10), Veo 3.1 (9.4/10) — all reviewed with detailed scoring on ThePlanetTools.ai.
Is Gemini 3.1 Pro Preview good for beginners?
Gemini 3.1 Pro Preview is rated 8.8/10 for ease of use.
What platforms does Gemini 3.1 Pro Preview support?
Gemini 3.1 Pro Preview is available on Web (AI Studio), Gemini API, Google Cloud Vertex AI, Gemini Enterprise, Gemini CLI, Android Studio, Google Antigravity.
Does Gemini 3.1 Pro Preview offer a free trial?
Yes, Gemini 3.1 Pro Preview offers a free trial.
Is Gemini 3.1 Pro Preview worth the price?
Gemini 3.1 Pro Preview scores 8.6/10 for value. We consider it excellent value.
Who should use Gemini 3.1 Pro Preview?
Gemini 3.1 Pro Preview is ideal for: Long-document research and synthesis with 1M-token context plus grounding, Vibe coding via Google Antigravity or Gemini CLI, Multi-file refactors at frontier quality with adaptive thinking, Multimodal content extraction from video, audio, and PDFs, Agentic tool-use workflows with function calling plus code execution, Multilingual reasoning and translation (92.6% multilingual MMLU), Image and video analysis at scale via Batch tier (50% off).
What are the main limitations of Gemini 3.1 Pro Preview?
Some limitations of Gemini 3.1 Pro Preview include: Preview status with stop-the-world precedent — Google DeepMind shut down Gemini 3 Pro Preview on March 9, 2026 with forced migration. Same can happen to 3.1 Pro Preview without long notice.; 64K output ceiling — Half of Claude Opus 4.7 128K output cap. Long-form reports and large code translations hit the ceiling earlier on Gemini 3.1.; No free tier on paid API — Free testing exists only through AI Studio interactive UI. Programmatic calls cost money from query one.; Knowledge cutoff January 2025 — Older than Claude Opus 4.7 and GPT-5.5 January 2026 cutoff. Without grounding, world-knowledge queries about 2025-2026 events may lag..
Best Alternatives to Gemini 3.1 Pro Preview



Ready to try Gemini 3.1 Pro Preview?
Start your free trial
Try Gemini 3.1 Pro Preview Free →