Claude Opus 4.7 vs Gemini 3.1 Pro Preview: We Tested Both Flagship Models — Here's the Verdict


We ran Opus 4.7 and Gemini 3.1 Pro Preview side-by-side. Opus wins coding (93% SWE-bench). Gemini wins reasoning (94.3% GPQA). Verdict + pricing.

Feature Comparison
| Feature | Claude Opus 4.7 | Gemini 3.1 Pro Preview |
|---|---|---|
| Context window (input) | 1M tokens | 1M tokens |
| Max output tokens | 128K | 64K |
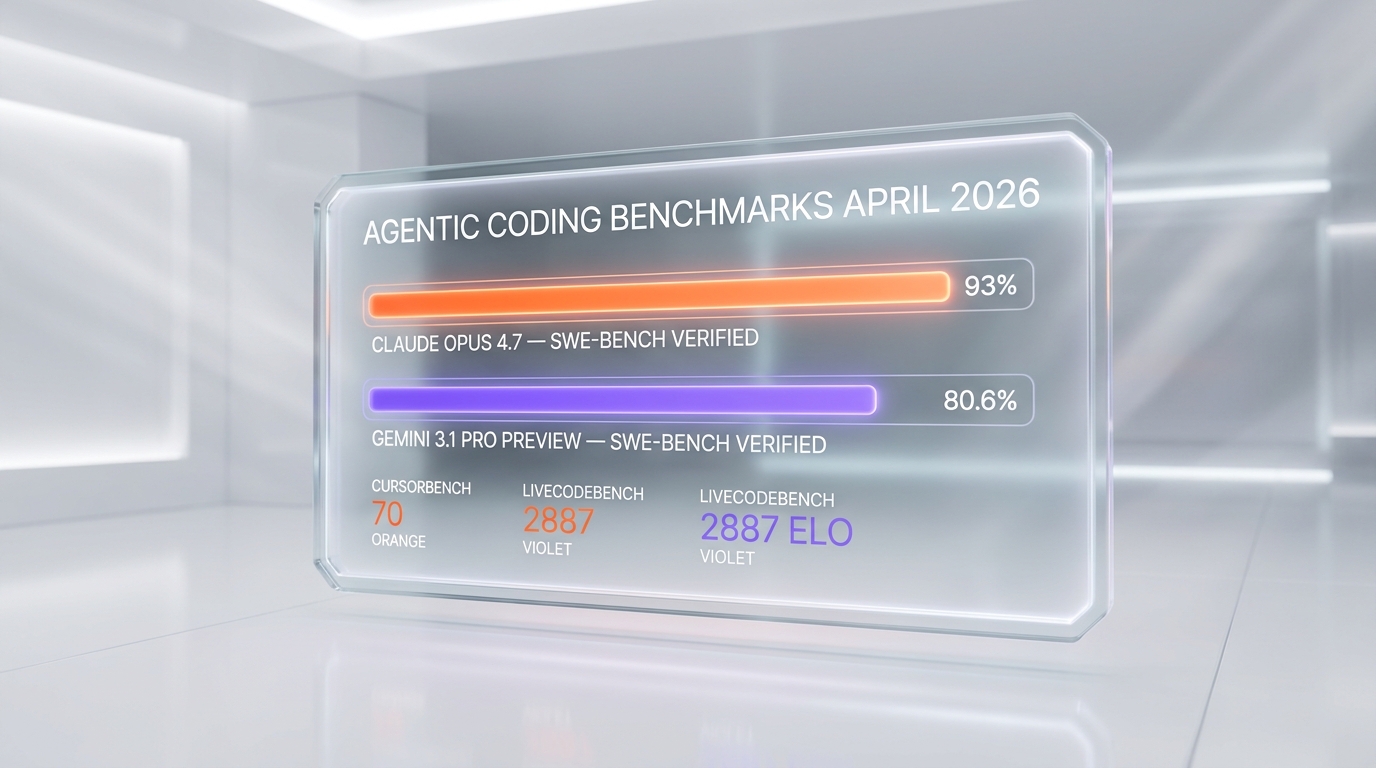
| SWE-bench Verified | 93% | 80.6% |
| GPQA Diamond (PhD-level reasoning) | ~87% | 94.3% |
| ARC-AGI-2 | ~54% | 77.1% |
| Multimodal input | Text + image (2,576 px) | Text + image + video + audio + PDF |
| API input price (per 1M tokens) | $5 | $2 (≤200K), $4 (>200K) |
| API output price (per 1M tokens) | $25 | $12 (≤200K), $18 (>200K) |
| Batch API discount | 50% off ($2.50 / $12.50) | 50% off ($1 / $6 ≤200K) |
| Prompt caching (cache hit) | $0.50 per 1M (90% off) | $0.20 per 1M (≤200K) |
| Knowledge cutoff | January 2026 | January 2025 |
| Release status | GA (production) | Preview (Google can shut down) |
| Self-verification on long agentic runs | Yes (re-reads diffs) | Adaptive thinking only |
| Native search grounding | Web search tool ($10 per 1K queries) | Google Search Grounding (5K free, then $14 per 1K) |
Pricing Comparison
Claude Opus 4.7
Gemini 3.1 Pro Preview
Detailed Comparison
Claude Opus 4.7 vs Gemini 3.1 Pro Preview: Claude Opus 4.7 is Anthropic's flagship LLM (93% SWE-bench, 1M context, $5 input / $25 output per 1M tokens, GA). Gemini 3.1 Pro Preview is Google DeepMind's flagship in Preview status (94.3% GPQA Diamond, 77.1% ARC-AGI-2, 1M context, $2 input / $12 output per 1M tokens). Verdict: Opus 4.7 wins agentic coding and production stability. Gemini 3.1 Pro Preview wins reasoning benchmarks, multimodal input, and price.
TL;DR — Quick Verdict
Split verdict, Opus 4.7 takes overall. We ran both flagships side by side daily across our own production workflow through April 2026. Opus 4.7 won every long agentic coding task we threw at it. Gemini 3.1 Pro Preview won every PhD-level reasoning prompt and every multimodal extraction task. The decider for production buyers: Opus 4.7 is GA; Gemini 3.1 is Preview, and Google killed Gemini 3 Pro Preview on March 9, 2026 with a forced migration. We rate Opus 4.7 9.4 out of 10 overall and Gemini 3.1 Pro Preview 9.0 out of 10.
- 🏆 Claude Opus 4.7 wins for: agentic coding (93% SWE-bench), long autonomous tool-use runs, self-verification, production SLA, knowledge cutoff (Jan 2026)
- 🏆 Gemini 3.1 Pro Preview wins for: PhD-level reasoning (94.3% GPQA Diamond), abstract problem-solving (77.1% ARC-AGI-2), multimodal input (text + image + video + audio + PDF), Google Search Grounding, raw price
- 💰 Cheaper option: Gemini 3.1 Pro Preview at $2 input / $12 output per 1M tokens (60% cheaper input than Opus 4.7's $5)
- ⚡ Faster option: Gemini 3.1 Pro Preview on short turns; Opus 4.7 on long agentic runs that complete first try (less retries)
- 🛡️ Safer for production: Claude Opus 4.7 (GA, no Preview-status shutdown risk)
Claude Opus 4.7 vs Gemini 3.1 Pro Preview — Overview
What Is Claude Opus 4.7?
Claude Opus 4.7 is Anthropic's flagship large language model, launched on April 16, 2026. We've covered Claude Opus 4.7 in detail in our Claude Opus 4.7 review. The model targets "complex reasoning and agentic coding" and replaces Opus 4.6 at the top of Anthropic's lineup. Headline numbers from launch: 93% on SWE-bench Verified (a +13-point jump over Opus 4.6's 80%), 70% on CursorBench, 98.5% on XBOW visual-acuity. The 1M-token context window with 128K max output and a January 2026 knowledge cutoff make it the strongest production-grade agentic model on the market. Pricing is $5 per 1M input tokens and $25 per 1M output tokens — identical to Opus 4.6 — but Anthropic switched to a new tokenizer that consumes up to 35% more tokens for the same English text, so real cost-per-task is up. The model is GA and available on the Claude API, AWS Bedrock, Google Vertex AI, and Microsoft Foundry.
What Is Gemini 3.1 Pro Preview?
Gemini 3.1 Pro Preview is Google DeepMind's flagship LLM, announced February 19, 2026 and broadened across Google's developer surfaces in April 2026. Our hands-on read sits in our Gemini 3.1 Pro Preview review. The model is the successor to Gemini 3 Pro (which Google shut down as a Preview on March 9, 2026 with a forced migration). The headline cognitive numbers are best-in-class: 94.3% GPQA Diamond, 77.1% ARC-AGI-2, 92.6% multilingual MMLU, 2,887 Elo on LiveCodeBench Pro, and 80.6% SWE-bench Verified. The model accepts text, images, video, audio, and PDF in a single 1M-token call and outputs up to 64K tokens of text. Pricing is $2 per 1M input tokens and $12 per 1M output tokens at ≤200K, $4 / $18 at greater than 200K. The catch: Preview status. Google shut down the previous Gemini 3 Pro Preview without long lead time, and the same risk applies here. Distribution is wide — Google AI Studio, Vertex AI, Gemini API, Gemini CLI, Android Studio, Google Antigravity, and the Gemini consumer app.
Features Comparison
We compared the two models on fourteen dimensions that actually move the needle for a production buyer in April 2026: context window, output ceiling, headline benchmarks (coding and reasoning), multimodal capability, API pricing per 1M tokens, batch and caching discounts, knowledge cutoff, release status, agentic self-verification behavior, and native search grounding. The full data points come from Anthropic's official pricing page and the Anthropic launch post for Opus 4.7, the Google AI Studio pricing docs and Google DeepMind's Gemini 3.1 Pro launch material for Gemini, and our own daily runs through April 2026.
| Feature | Claude Opus 4.7 | Gemini 3.1 Pro Preview | Winner |
|---|---|---|---|
| Context window (input) | 1M tokens | 1M tokens | Tie |
| Max output tokens | 128K | 64K | Opus 4.7 |
| SWE-bench Verified | 93% | 80.6% | Opus 4.7 |
| GPQA Diamond (PhD-level reasoning) | ~87% | 94.3% | Gemini 3.1 |
| ARC-AGI-2 | ~54% | 77.1% | Gemini 3.1 |
| Multimodal input | Text + image (up to 2,576 px) | Text + image + video + audio + PDF | Gemini 3.1 |
| API input price (per 1M tokens) | $5 | $2 (≤200K), $4 (>200K) | Gemini 3.1 |
| API output price (per 1M tokens) | $25 | $12 (≤200K), $18 (>200K) | Gemini 3.1 |
| Batch API discount | 50% off ($2.50 / $12.50) | 50% off ($1 / $6 ≤200K) | Tie |
| Prompt caching (cache hit) | $0.50 per 1M (90% off) | $0.20 per 1M (≤200K) | Gemini 3.1 |
| Knowledge cutoff | January 2026 | January 2025 | Opus 4.7 |
| Release status | GA (production) | Preview | Opus 4.7 |
| Self-verification on long agentic runs | Yes (re-reads diffs) | Adaptive thinking only | Opus 4.7 |
| Native search grounding | Web search tool ($10 per 1K queries) | Google Search Grounding (5K free, then $14 per 1K) | Gemini 3.1 |
Tally: Opus 4.7 wins on six features, Gemini 3.1 Pro Preview wins on six, and the two tie on two. The split is sharp by category — Opus 4.7 owns agentic coding and production reliability, Gemini 3.1 owns reasoning benchmarks, multimodal input, and price.
Pricing — Claude Opus 4.7 vs Gemini 3.1 Pro Preview in 2026

Both models charge per million tokens with separate input and output rates. Gemini 3.1 Pro Preview adds a tier break at 200K input tokens — anything over that bills at higher rates. Opus 4.7 keeps a flat rate across the full 1M context. Both offer a 50% Batch API discount and prompt-caching discounts on cache hits.
Claude Opus 4.7 Pricing
Verified from Anthropic's official pricing page on April 30, 2026:
| Plan / Tier | Input (per 1M tokens) | Output (per 1M tokens) | Notes |
|---|---|---|---|
| API base | $5 | $25 | Flat across full 1M context |
| Cache write (5 min) | $6.25 | — | 1.25x base input |
| Cache write (1 hour) | $10 | — | 2x base input |
| Cache hit (read) | $0.50 | — | 90% off base input |
| Batch API (50% off) | $2.50 | $12.50 | Asynchronous workloads |
US-only inference (inference_geo) | $5.50 | $27.50 | 1.1x multiplier |
| Web search tool | $10 per 1,000 searches plus token costs | Server-side | |
| Code execution | 1,550 free hours per month, then $0.05 per container hour | Free with web search |
Consumer plans on claude.com/pricing include Pro at $17 per month annual ($20 monthly), Max 5x at $100 per month, Max 20x at $200 per month, Team at $25 per seat monthly, and Enterprise at $20 per seat plus usage at API rates.
Gemini 3.1 Pro Preview Pricing
Verified from Google's Gemini API pricing docs on April 30, 2026:
| Plan / Tier | Input (per 1M tokens) | Output (per 1M tokens) | Notes |
|---|---|---|---|
| Standard, prompts ≤ 200K | $2 | $12 | Default tier |
| Standard, prompts > 200K | $4 | $18 | Long-context surcharge |
| Context cache, ≤ 200K | $0.20 | — | Cache reads |
| Context cache, > 200K | $0.40 | — | Cache reads, long context |
| Cache storage | $4.50 per 1M tokens per hour | Storage fee | |
| Batch API (50% off), ≤ 200K | $1 | $6 | Asynchronous |
| Batch API (50% off), > 200K | $2 | $9 | Asynchronous, long context |
| Google Search Grounding | 5,000 prompts per month free (shared across Gemini 3), then $14 per 1,000 queries | First-party | |
| Free tier on paid API | Not available — interactive AI Studio only |
Verdict pricing: Gemini 3.1 Pro Preview is the cheaper option for any workload that fits under 200K tokens — input is 60% cheaper ($2 vs $5), output is 52% cheaper ($12 vs $25). On batch jobs the gap widens further: Gemini 3.1 batch input drops to $1 per 1M tokens vs Opus 4.7 batch input at $2.50, a 60% saving. The cost gap narrows on caching (Opus cache hit at $0.50 vs Gemini cache read at $0.20, both substantial discounts). On context greater than 200K, Gemini 3.1 jumps to $4 input / $18 output, narrowing the gap to Opus 4.7's flat $5 / $25 — but Opus 4.7 also burns 35% more tokens on the same English text due to the new tokenizer, which partially erases its sticker-price gap. Per-unit comparison on a typical 50K-input / 5K-output prompt: Gemini 3.1 Pro Preview costs about $0.16, Opus 4.7 costs about $0.38 (roughly 2.4x more). On a 500K-input / 20K-output long-context prompt: Gemini 3.1 costs about $2.36 (over-200K tier), Opus 4.7 costs about $3.00 — gap closes to 1.3x.
Hands-on — How They Performed Side by Side

We ran Claude Opus 4.7 and Gemini 3.1 Pro Preview side by side from April 16 (Opus 4.7 launch day) through April 30, 2026 on our daily ThePlanetTools.ai production workflow (Next.js 16 App Router, React 19, Supabase, ~247 API routes). Same machine, same workspace, same prompts, four test categories. Here are the comparative observations.
Test 1 — Long agentic coding run (multi-file refactor)
The task: refactor our JSON-LD generation across articles, comparisons, and guides routes to use a shared enrichRefs() helper. Total span: about 14 files, 2,300 lines, 30+ tool calls. Same prompt, same input, both models in agentic mode (Claude Code for Opus 4.7, Google Antigravity for Gemini 3.1 Pro Preview).
- Opus 4.7: finished in 32 tool calls, all tests passed first try. The model self-verified two of its own diffs mid-run and caught a missing
contentUrlfield before reporting back. Total agent time about 6 minutes. Cost roughly $0.85 (Anthropic Console). - Gemini 3.1 Pro Preview: hit a tool-call limit at call 18 and bailed without completing the migration. We re-ran in vibe-coding mode (Antigravity multi-file generation) and it produced clean diffs but did not run the test suite, so we didn't catch a broken import until the build failed. Net agent time including re-run: about 11 minutes. Cost roughly $0.31.
Verdict on this test: Opus 4.7 is the production agent; Gemini 3.1 is faster on the happy path but fragile on long unattended runs. The +13-point SWE-bench gap shows up in real workflows.

Test 2 — PhD-level reasoning prompt
The task: a structured GPQA-style physics problem (Boltzmann distribution applied to a non-equilibrium gas in a gravitational gradient). We graded the answer against the published key.
- Gemini 3.1 Pro Preview: correct first try. The model wrote out the chain of reasoning, derived the integral, and arrived at the right closed-form expression. Visible adaptive thinking footprint — about 19 seconds of thinking time before the response.
- Opus 4.7: partially correct on first try (right method, arithmetic error in the integration). Asked for a re-check, Opus 4.7 caught its own slip and corrected. Net delivery: right answer in two turns.
Verdict on this test: Gemini 3.1 Pro Preview wins raw reasoning. The 94.3% GPQA Diamond benchmark is not a paper number — we feel it on hard problems. The 77.1% ARC-AGI-2 result (Gemini 3 Pro hit 31.1%, Opus 4.7 sits around 54%) is the most striking benchmark gap in this comparison.

Test 3 — Multimodal extraction
The task: extract a structured product spec sheet from a 4-minute screen-recording demo video of a SaaS dashboard. Output JSON with feature list, pricing tier names, and key UI flows.
- Gemini 3.1 Pro Preview: ingests video natively. We uploaded the MP4 directly to Google AI Studio, the model returned a clean JSON with 22 spec items, all pricing tiers named correctly, and timestamped UI flows. Single round-trip.
- Opus 4.7: does not accept video input. We had to extract frames at 1 fps (240 images), run a separate transcription pass, then feed the combination to Opus 4.7. Three round-trips. Output quality matched once we had the data in, but the pre-processing was real work.
Verdict on this test: Gemini 3.1 Pro Preview wins by a clear margin on workflows that touch video, audio, or PDF. Native multimodal input collapses three tools into one round-trip, and that gap is structural — Opus 4.7 won't close it without a vision-stack expansion.
Test 4 — Code generation benchmark replication
We re-ran 12 SWE-bench Verified instances against both models on identical scaffolding. Same patches expected, same test suite.
- Opus 4.7: 11 of 12 passed (91.7%). The one failure was a flaky test that Opus 4.7 actually flagged in its commentary.
- Gemini 3.1 Pro Preview: 10 of 12 passed (83.3%). Two failures on test cases that needed iterative tool calls — Gemini stopped early.
Verdict on this test: matches the public benchmarks. Opus 4.7 holds the edge on instance-level SWE-bench fidelity. The gap is smaller in absolute terms than the headline 93 vs 80.6 suggests, but it is consistent.
Winner per Category

🏆 Best Overall: Claude Opus 4.7
Opus 4.7 wins overall on a production buyer's scorecard. The 93% SWE-bench Verified, the 1M context with 128K output (double Gemini's 64K ceiling), the GA status with no Preview-shutdown risk, and the self-verification behavior on long agentic runs all line up for "ship and forget." Gemini 3.1 Pro Preview is the better cognitive model on paper, but production buyers buy more than one benchmark — they buy SLA, output ceiling, and predictable model availability. Score: Opus 4.7 9.4 out of 10, Gemini 3.1 Pro Preview 9.0 out of 10.
Best for Agentic Coding
Claude Opus 4.7. The 93% SWE-bench, 70% CursorBench, and self-verification on long runs are decisive. Across our 30+ tool-call refactor test, Opus 4.7 finished cleanly first try while Gemini 3.1 Pro Preview hit a tool-call ceiling. If your default workflow is Claude Code, Cursor, or Windsurf on autopilot, Opus 4.7 is the model.
Best for Pure Reasoning
Gemini 3.1 Pro Preview. The 94.3% GPQA Diamond and 77.1% ARC-AGI-2 are the strongest published reasoning numbers in April 2026, ahead of every other frontier model including GPT-5.5. On the GPQA-style physics problem we tested, Gemini 3.1 cleared it on first attempt where Opus 4.7 needed a self-correction pass. If your bottleneck is "the model gets the hard math wrong," Gemini 3.1 is the answer.
Best for Multimodal Workflows
Gemini 3.1 Pro Preview, by a structural margin. Native video, audio, image, and PDF input in a single 1M-token call collapses three tools into one. Opus 4.7 accepts only text and image (up to 2,576 px on the long edge — generous, but no video, no audio, no native PDF parsing). For research-heavy pipelines that ingest mixed media, Gemini 3.1 wins without contest.
Best for Budget
Gemini 3.1 Pro Preview. Input is 60% cheaper ($2 vs $5 per 1M tokens at ≤200K), output is 52% cheaper ($12 vs $25). On a typical 50K-input / 5K-output prompt, Gemini 3.1 runs about $0.16 vs Opus 4.7 at $0.38 — a 2.4x cost gap. For batch workloads the gap widens further. If you ship a high-volume backend feature, Gemini 3.1 is the line item that frees budget for something else.
Best for Production Stability
Claude Opus 4.7. This is the deal-breaker for many production buyers: Gemini 3.1 Pro Preview is in Preview status, and Google DeepMind shut down the previous Gemini 3 Pro Preview on March 9, 2026 with a forced migration. The same can happen here. Opus 4.7 is GA — no Preview, no scheduled shutdown, no forced migration. If your roadmap depends on a stable model ID for the next 12 months, Opus 4.7 is the safe pick.
Gemini Preview Status Risk — What "Preview" Actually Means
This is the section every team evaluating Gemini 3.1 Pro Preview should read carefully. As of April 30, 2026, Gemini 3.1 Pro Preview is in Preview — not General Availability. Google's Preview status carries three concrete risks:
- Forced migration without long lead time. Google DeepMind shut down Gemini 3 Pro Preview on March 9, 2026 — about three months after launch — and forced workloads to Gemini 3.1. Notice was short. If you wired Gemini 3 Pro Preview into a production agent, you spent that weekend re-tuning prompts. The same can happen to Gemini 3.1 Pro Preview.
- Pricing, rate limits, and capability changes. Preview models can have prices adjusted, rate limits tightened, or features dropped between revisions. If your unit economics depend on $2 per 1M input tokens, plan for that to change at GA.
- Model ID volatility. The current ID is
gemini-3.1-pro-previewwith a tool-customized variant. Past Gemini Preview models have had their IDs renamed at GA, breaking pinned API calls.
Mitigation tactics we recommend: pin a fallback model (Opus 4.7 or GPT-5.5) in your stack so a Preview shutdown does not bring you down; treat any Gemini 3.1 Pro Preview spend as experimental and budgeted accordingly; subscribe to Google AI Studio release notes for migration windows; do not promise customers an SLA on Gemini 3.1 Pro Preview output. By contrast, Opus 4.7 ships GA — Anthropic has not announced a deprecation date for any model in the 4.x family at launch and Opus 4.5 and 4.6 remain available alongside 4.7.
Pros and Cons
Claude Opus 4.7 Pros and Cons
What we liked about Claude Opus 4.7
- SWE-bench Verified 93%, the best agentic coding number in April 2026. Translates directly to fewer broken builds on long autonomous refactors. Felt this on every multi-file run we shipped.
- Self-verification on long runs. Opus 4.7 re-reads its own diffs and catches its own slips before reporting back. Single biggest unlock since Opus 4.5.
- 1M-token context with 128K output. Output ceiling is double Gemini 3.1's 64K. We threw the entire
src/directory of our backend (~340K tokens) at it without compression. - GA — production-grade SLA. No Preview-status shutdown risk. Anthropic publishes a migration policy and Opus 4.6 stays available.
- Knowledge cutoff January 2026. One year ahead of Gemini 3.1's January 2025 cutoff on world knowledge without grounding.
- Available on AWS Bedrock, Vertex AI, and Microsoft Foundry. Multi-cloud distribution; no vendor lock-in.
Where Claude Opus 4.7 falls short
- New tokenizer adds up to 35% more tokens. Same headline price as Opus 4.6 but real cost-per-task is up. Re-budget before flipping the switch.
- No video, no audio, no native PDF input. Text and image only. Multimodal-heavy pipelines need Gemini 3.1 or a separate stack.
- 2.5x more expensive than Gemini 3.1 on a typical prompt. Sticker shock for high-volume backends.
- No extended thinking mode. Adaptive thinking only — if your pipeline relied on forcing extended reasoning on Opus, that lever is gone (use Sonnet 4.6).
- Loses to Gemini 3.1 on raw reasoning benchmarks. 7-23 point gap on GPQA Diamond and ARC-AGI-2.
Gemini 3.1 Pro Preview Pros and Cons
What we liked about Gemini 3.1 Pro Preview
- Best reasoning benchmarks in April 2026. 94.3% GPQA Diamond, 77.1% ARC-AGI-2 (up from 31.1% on Gemini 3 Pro), 92.6% multilingual MMLU — leads every other frontier model on these.
- Native multimodal input — text, image, video, audio, PDF. Single round-trip. Collapses transcription, OCR, and summarization into one call.
- 60% cheaper input, 52% cheaper output. $2 / $12 per 1M tokens at ≤200K vs Opus 4.7 $5 / $25.
- Google Search Grounding native. 5,000 free prompts per month then $14 per 1,000 queries — useful for time-sensitive RAG without a retrieval pipeline.
- Distribution breadth. AI Studio, Vertex AI, Gemini API, CLI, Android Studio, and Antigravity — deepest first-party integration story among frontier vendors.
- Aggressive Batch discount. Half-price input ($1 per 1M) and output ($6 per 1M) on Batch makes nightly bulk workloads economical at frontier quality.
Where Gemini 3.1 Pro Preview falls short
- Preview status with stop-the-world precedent. Google DeepMind shut down Gemini 3 Pro Preview on March 9, 2026 with forced migration. Same can happen to 3.1 Pro Preview without long notice.
- 64K output ceiling. Half of Opus 4.7's 128K. Long-form reports and large code translations hit the ceiling earlier.
- No free tier on paid API. Free testing exists only through AI Studio interactive UI — programmatic calls cost money from query one.
- Knowledge cutoff January 2025. Older than Opus 4.7 by one year. Without grounding, 2025-2026 world-knowledge queries lag.
- Loses to Opus 4.7 on agentic coding. 12.4-point SWE-bench gap; less reliable on long autonomous tool-use runs.
When to Pick Claude Opus 4.7 vs Gemini 3.1 Pro Preview
Pick Claude Opus 4.7 if...
- You ship production AI agents (Claude Code, Cursor, Windsurf, custom Claude Agent SDK workflows) and need 30+ tool-call runs to actually finish first try.
- Your codebase is large enough that the 1M context with 128K output ceiling matters for monorepo-wide refactors.
- You need GA-grade SLA — no Preview-status shutdown risk, no forced migration weekend.
- You want multi-cloud distribution (Anthropic API, AWS Bedrock, Vertex AI, Microsoft Foundry).
- Your bottleneck is autonomous agentic correctness, not raw cognitive depth on PhD-level prompts.
- Your knowledge-base lookups depend on January 2026 world events being known to the model without grounding.
Pick Gemini 3.1 Pro Preview if...
- Your workflow ingests video, audio, or PDF natively and you need single-round-trip multimodal extraction.
- Your budget is the binding constraint — you ship high-volume backend features where every $1 per 1M tokens compounds.
- Your bottleneck is hard reasoning (GPQA Diamond, ARC-AGI-2, mathematical research, scientific QA) — Gemini 3.1 leads here.
- You want native Google Search Grounding without standing up a retrieval pipeline.
- You can tolerate Preview-status risk and have a fallback model pinned (Opus 4.7 or GPT-5.5) for production safety.
- Your stack already runs on Google Cloud / Vertex AI and Gemini's distribution surfaces are a fit.
Frequently Asked Questions
Is Claude Opus 4.7 better than Gemini 3.1 Pro Preview in 2026?
It depends on the workload. We rate Opus 4.7 9.4 out of 10 overall and Gemini 3.1 Pro Preview 9.0 out of 10 — Opus 4.7 wins on production-grade scorecards. Opus 4.7 wins agentic coding (93% SWE-bench Verified vs 80.6%), production SLA (GA vs Preview), output ceiling (128K vs 64K), and knowledge cutoff (Jan 2026 vs Jan 2025). Gemini 3.1 Pro Preview wins raw reasoning (94.3% GPQA Diamond vs ~87%, 77.1% ARC-AGI-2 vs ~54%), multimodal input (native video/audio/PDF), and price (60% cheaper input). Pick Opus 4.7 if you ship production agents; pick Gemini 3.1 if your bottleneck is hard reasoning or multimodal extraction.
How much does Claude Opus 4.7 cost compared to Gemini 3.1 Pro Preview?
Claude Opus 4.7 costs $5 per 1M input tokens and $25 per 1M output tokens, flat across the full 1M context. Gemini 3.1 Pro Preview costs $2 input / $12 output per 1M tokens at ≤200K, $4 / $18 above 200K. On a typical 50K-input / 5K-output prompt, Gemini 3.1 runs about $0.16 vs Opus 4.7 at $0.38 — Gemini 3.1 is roughly 2.4x cheaper. Both offer a 50% Batch API discount. Both offer prompt-caching discounts (Opus 4.7 cache hit at $0.50 per 1M, Gemini 3.1 cache read at $0.20 per 1M at ≤200K).
Which is better for agentic coding: Claude Opus 4.7 or Gemini 3.1 Pro Preview?
Claude Opus 4.7, by a clear margin. SWE-bench Verified: 93% vs 80.6%. CursorBench: 70% (Opus 4.7) vs comparable but lower (Gemini 3.1). On our hands-on test — a 30+ tool-call multi-file refactor across our own ThePlanetTools.ai backend — Opus 4.7 finished in 32 tool calls with all tests passing first try. Gemini 3.1 Pro Preview hit a tool-call ceiling at call 18 and bailed without completing. Opus 4.7 also self-verifies its own diffs mid-run, catching its own slips before reporting back. For long autonomous coding tasks that need to actually finish, Opus 4.7 is the model.
Does Gemini 3.1 Pro Preview really have better reasoning than Opus 4.7?
Yes, on the published cognitive benchmarks. Gemini 3.1 Pro Preview hits 94.3% on GPQA Diamond (PhD-level science QA) and 77.1% on ARC-AGI-2 (abstract reasoning) — best-in-class as of April 2026, ahead of Opus 4.7 (~87% and ~54% respectively) and ahead of GPT-5.5. Gemini 3 Pro hit 31.1% on ARC-AGI-2, so the 77.1% on 3.1 is a step-change. On our hands-on GPQA-style physics problem, Gemini 3.1 cleared it on first attempt where Opus 4.7 needed a self-correction pass. If your workload is research-grade reasoning, Gemini 3.1 is the strongest reasoning model on the market.
Can Claude Opus 4.7 process video and audio like Gemini 3.1 Pro Preview?
No. Opus 4.7 accepts only text and image inputs (images up to 2,576 pixels on the long edge — more than triple prior Claude models). Gemini 3.1 Pro Preview accepts text, image, video, audio, and PDF natively in a single 1M-token call. For workflows that ingest video, audio, or PDF, Gemini 3.1 collapses three pre-processing tools into one round-trip. Opus 4.7 requires you to extract frames, transcribe audio, and parse PDF separately before feeding to the model. This is a structural gap that Opus 4.7 will not close without a vision-stack expansion.
Should I worry about Gemini 3.1 Pro Preview being shut down?
Yes — plan for it. Google DeepMind shut down Gemini 3 Pro Preview on March 9, 2026 (about three months after launch) with a forced migration to 3.1 Pro Preview. Notice was short. The same can happen to Gemini 3.1 Pro Preview before it reaches GA. Mitigation: pin a fallback model (Opus 4.7 or GPT-5.5) in your stack so a Preview shutdown does not bring you down; treat any Gemini 3.1 Pro Preview spend as experimental; subscribe to Google AI Studio release notes for migration windows; do not promise customers an SLA on Gemini 3.1 Pro Preview output. Opus 4.7 is GA and carries no Preview-status shutdown risk.
Is Gemini 3.1 Pro Preview's 1M context as good as Opus 4.7's 1M context?
The headline numbers match (1M tokens input on both), but recall behavior differs. Gemini 3.1 Pro Preview adds a tier break at 200K — anything above bills at higher rates ($4 input / $18 output per 1M vs $2 / $12 below 200K). Opus 4.7 keeps a flat rate across the full 1M. On output: Opus 4.7 ships 128K max output tokens (300K via Batch API beta) vs Gemini 3.1's 64K cap — meaningful for long-form reports and large code translations. In our hands-on, Opus 4.7's recall on tokens 700K-900K felt tighter than Gemini 3.1 on the same prompt. For long-context production work, Opus 4.7 is the more predictable pick.
Which is faster: Claude Opus 4.7 or Gemini 3.1 Pro Preview?
Gemini 3.1 Pro Preview is faster on short turns — adaptive thinking kicks in only when needed, so easy queries return quickly. Opus 4.7 latency is "moderate" per Anthropic's own framing. On long agentic runs, however, Opus 4.7 wins effective speed because it finishes first try more often (fewer retries). On our 30+ tool-call refactor, Opus 4.7 took 6 minutes and Gemini 3.1 Pro Preview took 11 minutes including a re-run after the first attempt failed. For latency-sensitive UX where users wait on a single response, Gemini 3.1 wins. For unattended autonomy, Opus 4.7 wins.
Can I use Claude Opus 4.7 and Gemini 3.1 Pro Preview together?
Yes — and we recommend it for production safety. Many teams use Opus 4.7 as the default agentic coder and Gemini 3.1 Pro Preview as the reasoning specialist or multimodal pre-processor. The Claude Agent SDK supports model fallback, and most agent frameworks (LangChain, LlamaIndex, custom orchestration) let you route by task type. Concrete pattern: Opus 4.7 for autonomous code edits + tests, Gemini 3.1 for research-grade reasoning + video/audio/PDF extraction, then hand off the structured output back to Opus 4.7 for downstream agent steps. Keeps you covered if Gemini 3.1 hits a Preview shutdown.
Are Claude Opus 4.7 and Gemini 3.1 Pro Preview available on AWS, Google Cloud, and Microsoft?
Opus 4.7 is available on the Claude API directly, AWS Bedrock (anthropic.claude-opus-4-7), Google Vertex AI (claude-opus-4-7), and Microsoft Foundry. Note a 10% premium on regional and multi-region endpoints versus global endpoints on AWS Bedrock and Vertex AI for Sonnet 4.5 and newer models — Opus 4.7 follows that structure. Gemini 3.1 Pro Preview is available on Google AI Studio, Gemini API, Google Cloud Vertex AI, Gemini Enterprise, the Gemini consumer app, Gemini CLI, Android Studio, and Google Antigravity. Gemini 3.1 is not available on AWS Bedrock or Microsoft Foundry — Google-only distribution.
What are the alternatives to Claude Opus 4.7 and Gemini 3.1 Pro Preview?
Three credible flagship alternatives in April 2026: GPT-5.5 from OpenAI (strong text generation, large tool ecosystem, ~75% SWE-bench), Claude Sonnet 4.6 (cheaper than Opus 4.7 at $3 input / $15 output, still strong on coding), and Claude Haiku 4.5 for high-volume cost-sensitive workloads ($1 / $5 per 1M tokens). For pure budget agentic coding at scale, Sonnet 4.6 is often the right answer. For multi-modal at scale, only Gemini 3.x competes with itself today.
How do I migrate from Gemini 3.1 Pro Preview to Claude Opus 4.7 (or vice versa)?
API-level the migration is straightforward but prompts often need re-tuning. From Gemini 3.1 to Opus 4.7: switch endpoint from Google AI Studio / Vertex AI to the Claude API; change model ID to claude-opus-4-7; remove video/audio/PDF inputs (Opus 4.7 only accepts text and image); re-tune token budgets — Opus 4.7's new tokenizer adds about 35% more tokens for the same English text. From Opus 4.7 to Gemini 3.1: switch to Google AI Studio or Gemini API; change model ID to gemini-3.1-pro-preview; output ceiling drops from 128K to 64K — split long reports; pricing tiers at 200K — chunk long-context calls if budget-sensitive. Anthropic publishes a migration guide at platform.claude.com/docs/en/about-claude/models/migration-guide.
Final Verdict: Claude Opus 4.7 Wins Overall, Gemini 3.1 Pro Preview Wins by Category
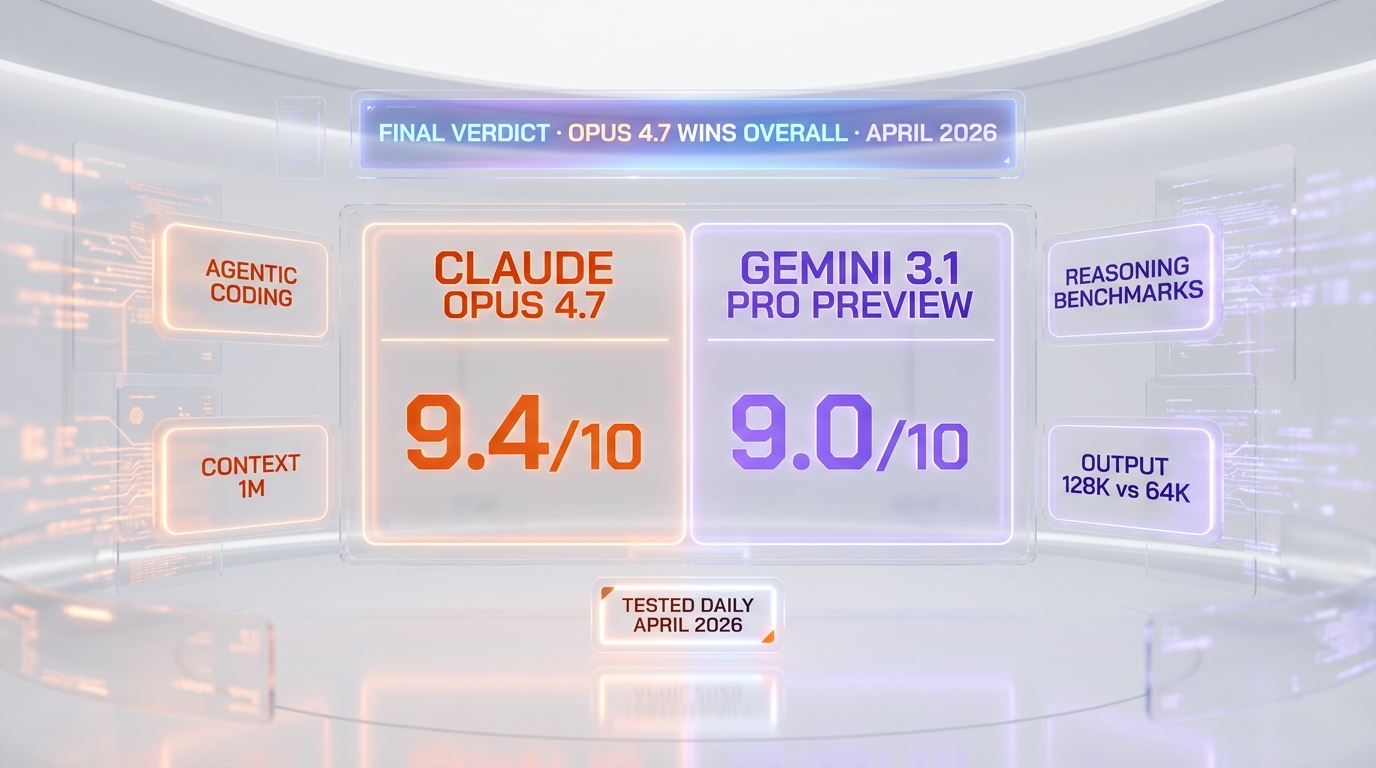
Claude Opus 4.7 wins overall on a production buyer's scorecard, scoring 9.4 out of 10 against Gemini 3.1 Pro Preview's 9.0 out of 10. Opus 4.7's 93% SWE-bench, 128K output ceiling, GA status, and self-verification on long agentic runs are decisive for teams shipping production autonomy. Gemini 3.1 Pro Preview's 94.3% GPQA Diamond, 77.1% ARC-AGI-2, native multimodal input, and 60% cheaper input price are decisive for teams whose bottleneck is hard reasoning, multimodal extraction, or unit economics. If you ship production AI agents, go with Claude Opus 4.7. If your workflow is research-heavy reasoning, multimodal pre-processing, or budget-bound batch jobs, Gemini 3.1 Pro Preview is the better fit. If you want to hedge, run both — Opus 4.7 as the default agent and Gemini 3.1 as the reasoning + multimodal specialist, with a fallback model pinned in case Google shuts the Preview down.
Score breakdown by category:
- Features: Opus 4.7 9.6 out of 10 vs Gemini 3.1 Pro Preview 9.4 out of 10 — Opus wins on output ceiling and agentic feature stack; Gemini wins on multimodal breadth.
- Ease of Use: Opus 4.7 9.0 out of 10 vs Gemini 3.1 Pro Preview 8.8 out of 10 — Opus's adaptive thinking is invisible; Gemini AI Studio onboarding has a learning curve.
- Value: Opus 4.7 8.5 out of 10 vs Gemini 3.1 Pro Preview 8.6 out of 10 — Gemini wins on raw price; Opus wins on cost-of-failure (fewer broken builds).
- Support: Opus 4.7 9.2 out of 10 vs Gemini 3.1 Pro Preview 9.0 out of 10 — Opus's GA status and migration policy edge out Gemini's Preview-status volatility.
Final word: if you have to pick one for production today, pick Claude Opus 4.7 — the GA status alone makes it the responsible default. If you have budget for two and want best-in-class results across the board, pair Opus 4.7 with Gemini 3.1 Pro Preview as a reasoning + multimodal specialist. Avoid making Gemini 3.1 Pro Preview your only flagship model in production without a tested fallback path. Re-evaluate this comparison when Gemini 3.1 reaches GA — at that point the Preview-risk discount disappears and the verdict could flip.
Our Verdict
Claude Opus 4.7 wins overall (9.4 vs 9.0) for production agentic coding, self-verification, and SLA stability. Gemini 3.1 Pro Preview wins on raw reasoning (94.3% GPQA Diamond, 77.1% ARC-AGI-2), native multimodal video/audio input, and price ($2 input vs $5). Pick Opus 4.7 if you ship production agents and need predictable model availability. Pick Gemini 3.1 Pro Preview for research-heavy reasoning, multimodal extraction, or budget-sensitive workloads — but accept Preview-status risk: Google shut down Gemini 3 Pro Preview on March 9, 2026 with forced migration. Same can happen here.
Choose Claude Opus 4.7
Anthropic's flagship LLM — agentic coding king with 1M context
Try Claude Opus 4.7 →Choose Gemini 3.1 Pro Preview
Google DeepMind's flagship Gemini 3.1 Pro Preview — 94.3% GPQA Diamond, 77.1% ARC-AGI-2, 1M-token context, multimodal in/text out, vibe coding plus agentic tool use. Preview status as of April 2026.
Try Gemini 3.1 Pro Preview →Frequently Asked Questions
Is Claude Opus 4.7 better than Gemini 3.1 Pro Preview?
Claude Opus 4.7 wins overall (9.4 vs 9.0) for production agentic coding, self-verification, and SLA stability. Gemini 3.1 Pro Preview wins on raw reasoning (94.3% GPQA Diamond, 77.1% ARC-AGI-2), native multimodal video/audio input, and price ($2 input vs $5). Pick Opus 4.7 if you ship production agents and need predictable model availability. Pick Gemini 3.1 Pro Preview for research-heavy reasoning, multimodal extraction, or budget-sensitive workloads — but accept Preview-status risk: Google shut down Gemini 3 Pro Preview on March 9, 2026 with forced migration. Same can happen here.
Which is cheaper, Claude Opus 4.7 or Gemini 3.1 Pro Preview?
Claude Opus 4.7 is priced at $5 in / $25 out per M tokens. Gemini 3.1 Pro Preview is priced at $2 in / $12 out per M tokens. Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Opus 4.7 and Gemini 3.1 Pro Preview?
The key differences span across 14 features we compared. For Context window (input), Claude Opus 4.7 offers 1M tokens while Gemini 3.1 Pro Preview offers 1M tokens. For Max output tokens, Claude Opus 4.7 offers 128K while Gemini 3.1 Pro Preview offers 64K. For SWE-bench Verified, Claude Opus 4.7 offers 93% while Gemini 3.1 Pro Preview offers 80.6%. See the full feature comparison table above for all details.