GPT-5.5 vs DeepSeek V4: Closed Frontier vs Open-Weight Cost (2026)


GPT-5.5 leads the AA Intelligence Index ~55 vs 44 and SWE-bench 88.7% vs 80.6% — but DeepSeek V4 is 100x cheaper and open-weight. Split verdict by use case.

Feature Comparison
| Feature | GPT-5.5 | DeepSeek V4 |
|---|---|---|
| AA Intelligence Index (Artificial Analysis, same evaluator) | About 55 | About 44 (V4-Pro max reasoning) |
| SWE-bench Verified | About 88.7% (Artificial Analysis run) | 80.6% (DeepSeek reports) |
| Output price (per million tokens) | 30 dollars | Flash 0.28 dollars, Pro 0.87 dollars |
| Input price (per million tokens) | 5 dollars | Flash 0.14 dollars, Pro 0.435 dollars |
| License | Closed, API and ChatGPT only | Open weights, MIT license |
| Self-hostable | No | Yes, incl. Huawei Ascend |
| Context window | 1,050,000 tokens | 1,000,000 tokens |
| Western data residency / compliance | US-hosted, regional residency endpoints | China-hosted API (or self-host) |
| Agentic tool stack on by default | Yes (functions, web/file search, code interpreter, computer use, MCP) | Tool calling + JSON mode; framework support lands post-launch |
| Reasoning control granularity | Five-level effort scale (none/low/medium/high/xhigh) | Three thinking modes (Non-Think/Think High/Think Max) |
Pricing Comparison
GPT-5.5
DeepSeek V4
Detailed Comparison
GPT-5.5 and DeepSeek V4 are the two flagship large language models compared here, and they sit at opposite ends of the same frontier. GPT-5.5 is OpenAI's closed, US-hosted top model, launched April 23, 2026, priced at 5 dollars per million input tokens and 30 dollars per million output tokens. DeepSeek V4 is the open-weight Chinese flagship from DeepSeek, shipped under an MIT license on Hugging Face, with a hosted API tier — V4-Flash at 0.14 dollars input and 0.28 dollars output per million tokens, V4-Pro at 0.435 dollars input and 0.87 dollars output. On the one independent evaluator that scores both the same way, Artificial Analysis, GPT-5.5 leads the Artificial Analysis Intelligence Index at roughly 55 versus 44 for DeepSeek V4-Pro, and on SWE-bench Verified GPT-5.5 leads roughly 88.7 percent against DeepSeek's reported 80.6 percent. DeepSeek V4 is dramatically cheaper and can be downloaded and self-hosted; GPT-5.5 is the stronger model on raw capability, agentic tooling, computer use, and Western data residency. Best for raw frontier capability, agentic coding, and US-hosted compliance: GPT-5.5. Best for cost, open weights, and self-hosting: DeepSeek V4.
Quick Verdict
This is a split verdict by use case, not a single overall winner. We ran both models side-by-side through their hosted APIs, pulled the pricing directly from each vendor's own pages, and added our own hands-on observations from using both on coding and reasoning prompts. We have not run weeks of controlled, identical-task benchmarking of both models against each other, so where we lean on numbers we attribute them. The honest summary is that these two models are not really fighting for the same buyer. Here is the short version.
- Best for raw frontier capability: GPT-5.5. On the Artificial Analysis Intelligence Index — the one composite both models are scored on by the same evaluator — GPT-5.5 sits at roughly 55, while DeepSeek V4-Pro in its maximum reasoning mode scores about 44.
- Best for agentic coding: GPT-5.5. It leads SWE-bench Verified by roughly 8 points (about 88.7 percent versus DeepSeek's reported 80.6 percent) and ships a full agentic tool stack — function calling, web search, file search, code interpreter, computer use, and MCP — on by default.
- Best for cost: DeepSeek V4, and it is not close. V4-Flash output at 0.28 dollars per million tokens is over 100 times cheaper than GPT-5.5 output at 30 dollars. Even V4-Pro at 0.87 dollars output is roughly 34 times cheaper.
- Best for open weights and self-hosting: DeepSeek V4. The weights ship under an MIT license and run on your own hardware, including Huawei Ascend chips. GPT-5.5 is closed and API-only.
- Best for Western data residency and compliance: GPT-5.5. It is hosted by OpenAI in the US with regional data-residency endpoints. DeepSeek's API is hosted in China, which is a non-starter for many regulated buyers unless self-hosted.
Bottom line: if you need the strongest closed model and can pay for it — or you need US-hosted compliance — pick GPT-5.5. If you are cost-constrained, want to own your weights, or need to self-host for sovereignty reasons, DeepSeek V4 gives you frontier-adjacent quality at a fraction of the price. We did not crown a single winner because the two models optimize for different things.
At a Glance
Before the detail, here is the side-by-side that frames everything below. All pricing in this table was fetched directly from each vendor's pricing page in June 2026. All benchmark figures are attributed to their source.
| Dimension | GPT-5.5 | DeepSeek V4 |
|---|---|---|
| Vendor and origin | OpenAI (US) | DeepSeek (China) |
| License | Closed, API and ChatGPT only | Open weights, MIT license |
| Released | April 23, 2026 | April 24, 2026 |
| Input price (per million tokens) | 5 dollars (verified) | Flash 0.14 dollars, Pro 0.435 dollars (verified) |
| Output price (per million tokens) | 30 dollars (verified) | Flash 0.28 dollars, Pro 0.87 dollars (verified) |
| Cache-read input (per million tokens) | 0.50 dollars (verified) | Flash 0.0028 dollars, Pro 0.0036 dollars (verified) |
| Context window | 1,050,000 tokens (verified) | 1,000,000 tokens (verified) |
| AA Intelligence Index | About 55 (Artificial Analysis) | About 44 for V4-Pro max reasoning (Artificial Analysis) |
| SWE-bench Verified | About 88.7 percent (OpenAI reports) | 80.6 percent (DeepSeek reports) |
| Self-hostable | No | Yes, including Huawei Ascend chips |
| Data residency | US, plus regional residency endpoints | China-hosted API, or self-host anywhere |
Overview of Each Model
GPT-5.5
GPT-5.5 is OpenAI's flagship reasoning model, launched April 23, 2026, and it is the company's first fully retrained base model since GPT-4.5 rather than a quarterly tuning pass. It carries a 1,050,000-token context window with up to 128K output tokens, and it tops the Artificial Analysis Intelligence Index at roughly 55. OpenAI reports 58.6 percent on the harder SWE-bench Pro variant and 41.4 percent on Humanity's Last Exam, and the model leads SWE-bench Verified at roughly 88.7 percent on the Artificial Analysis run. Its defining trait is the agentic tool stack: function calling, structured outputs, web search, file search, code interpreter, computer use, and MCP client support are all available by default, alongside a five-level reasoning effort scale (none, low, medium, high, xhigh) that is the most granular reasoning control of any frontier model we tested in 2026. Pricing is 5 dollars per million input tokens and 30 dollars per million output, with prompt caching at a 90 percent discount (0.50 dollars per million cached input tokens). It is closed and available only through OpenAI's API, ChatGPT Plus, Pro, Business, and Enterprise, and Codex. In our hands-on use, the standout is reliability and tool orchestration rather than a giant leap in raw reasoning over its predecessor. For the full breakdown, see our GPT-5.5 review.
DeepSeek V4
DeepSeek V4 is the Chinese open-weight flagship, shipped April 24, 2026 in two sizes: V4-Pro, a 1.6-trillion-parameter mixture-of-experts model with about 49 billion parameters active per token, and V4-Flash, a 284-billion-parameter model with about 13 billion active. Both carry a 1,000,000-token context window with up to 384K tokens of output, and both ship under an MIT license that permits free commercial use, redistribution, and modification of the weights — although the training code and data recipe are not released, so this is open weights rather than fully open source. DeepSeek reports 80.6 percent on SWE-bench Verified for V4-Pro, and Artificial Analysis scores V4-Pro at roughly 44 on its Intelligence Index in maximum reasoning mode, well above the median for open-weight models of similar size. The architecture is genuinely novel rather than just bigger: a Hybrid Attention design combining Compressed Sparse Attention and Heavily Compressed Attention cuts inference compute and KV-cache footprint sharply versus the previous generation, and three built-in thinking modes — Non-Think, Think High, and Think Max — let you dial cost against quality per request. It is the first major Chinese frontier model with day-one inference on Huawei Ascend hardware, and the hosted API is OpenAI-compatible. The headline, though, is price: V4-Flash output sits at 0.28 dollars per million tokens. Our full DeepSeek V4 review covers the architecture and licensing in more depth.
Pricing Compared
This is where the two models diverge most violently, and it is the single most important thing to understand about this matchup. We fetched every number below directly from each vendor's pricing page in June 2026.
| Tier | Input (per million tokens) | Output (per million tokens) | Cache read (per million tokens) |
|---|---|---|---|
| GPT-5.5 (standard) | 5.00 dollars | 30.00 dollars | 0.50 dollars |
| GPT-5.5 (Batch API, 50 percent off) | 2.50 dollars | 15.00 dollars | 0.25 dollars |
| GPT-5.5 (long-context tier, above 272K tokens) | 10.00 dollars | 45.00 dollars | 1.00 dollar |
| DeepSeek V4-Flash | 0.14 dollars | 0.28 dollars | 0.0028 dollars |
| DeepSeek V4-Pro | 0.435 dollars | 0.87 dollars | 0.0036 dollars |
Run the arithmetic and the gap is staggering. On output tokens, the comparison most people care about because output dominates real agentic spend, GPT-5.5 at 30 dollars is roughly 107 times the cost of V4-Flash at 0.28 dollars, and roughly 34 times the cost of V4-Pro at 0.87 dollars. On input tokens, GPT-5.5 at 5 dollars is about 36 times V4-Flash and about 11 times V4-Pro. Even GPT-5.5's Batch API discount and its aggressive prompt caching — a cache read at 0.50 dollars per million tokens is genuinely cheap by frontier standards — cannot close a gap of that magnitude.
Two nuances worth flagging honestly. First, GPT-5.5 has a long-context surcharge above 272K input tokens that lifts input to 10 dollars and output to 45 dollars per million, which changes the unit economics of million-token agentic runs significantly and is easy to miss in the docs. Second, a self-hosted DeepSeek deployment is not free. The API prices above are the cheap path; running V4-Pro yourself in full precision requires enterprise GPU clusters, and even V4-Flash needs INT4 or INT8 quantization to fit on a single high-end consumer card. The open weights buy you control and remove per-token billing, but they shift cost into hardware and operations. For most teams, the hosted DeepSeek API is the relevant comparison, and there GPT-5.5 simply costs two orders of magnitude more per output token.
Benchmarks Compared
Benchmarks across two different labs are a minefield, because vendors pick favorable evaluations and report them their own way. We discipline this by leaning on the one independent evaluator that scores both models the same way — Artificial Analysis — and treating vendor-reported figures as attributed claims, not verified facts.
| Benchmark | GPT-5.5 | DeepSeek V4 | Like-for-like? |
|---|---|---|---|
| AA Intelligence Index (Artificial Analysis) | About 55 | About 44 (V4-Pro, max reasoning) | Yes — same evaluator |
| SWE-bench Verified | About 88.7 percent (Artificial Analysis run) | 80.6 percent (DeepSeek reports) | Same benchmark, different harness |
| SWE-bench Pro | 58.6 percent (OpenAI reports) | Not reported the same way | No clean counterpart |
| Humanity's Last Exam | 41.4 percent (OpenAI reports) | Not reported comparably | No clean counterpart |
| Output speed (Artificial Analysis) | Listed comparably | Listed comparably | Same evaluator |
| Context window | 1,050,000 tokens | 1,000,000 tokens | Effectively tied |
The cleanest signal is the Artificial Analysis Intelligence Index, because it is one evaluator running the same battery on both: GPT-5.5 at roughly 55 versus V4-Pro at about 44, a clear double-digit lead. On SWE-bench Verified, GPT-5.5's roughly 88.7 percent on the Artificial Analysis run leads DeepSeek's self-reported 80.6 percent by about 8 points, and the direction is consistent with the independent Intelligence Index. We will not pretend that 8-point gap is exact, because the SWE-bench figures come from different evaluation harnesses, but the two independent-and-attributed signals point the same way.
Where GPT-5.5 has no clean DeepSeek counterpart we report — SWE-bench Pro and Humanity's Last Exam — we note that DeepSeek did not report them the same way rather than invent a head-to-head. It is worth being honest about the other side too: V4-Pro's 80.6 percent on SWE-bench Verified is remarkable for an open-weight model, landing within roughly 8 points of a closed frontier flagship, which is the entire reason this comparison is interesting. The numbers we do have say clearly that GPT-5.5 is the stronger model on capability, and that DeepSeek V4 is far closer than its price would suggest.
Architecture and What Is Actually Different
It is tempting to treat two frontier models as interchangeable black boxes that you poke through an API, but the engineering underneath shapes how they behave, what they cost to run, and where they can be deployed. The two could hardly be more different in philosophy.
GPT-5.5 is a closed model, so OpenAI discloses behavior rather than internals. What it surfaces is a product-level capability set built for agentic work: the full tool stack on by default, a five-level reasoning effort scale, three runtime variants (GPT-5.5 base, GPT-5.5 Pro for deeper reasoning, and GPT-5.5 Thinking in ChatGPT), and three execution modes — Batch at 50 percent off, Flex at a different service level, and Priority at higher cost. OpenAI also notes the model is more token-efficient than its predecessor, biasing toward shorter responses and small workable changes, which softens the per-task impact of the higher rate card. Snapshot pinning at gpt-5.5-2026-04-23 gives production teams reproducibility. The trade-offs are real: there is no fine-tuning on the GPT-5.5 base model at launch, the long-context surcharge above 272K tokens is steep, and the ChatGPT Plus rate limits drew loud pushback at launch.
DeepSeek V4 is the opposite — fully transparent at the architecture level because the weights and a technical report ship publicly. It is a mixture-of-experts model: V4-Pro carries 1.6 trillion total parameters with about 49 billion active per token, V4-Flash carries 284 billion total with about 13 billion active, both trained on roughly 33 trillion tokens. The headline innovation is a Hybrid Attention design that combines Compressed Sparse Attention, at four-times compression, with Heavily Compressed Attention, at 128-times compression, to make a 1,000,000-token context affordable to serve. DeepSeek reports this cuts inference compute to a small fraction of the previous generation and shrinks the KV cache dramatically. It also swaps the usual AdamW optimizer for Muon for faster, more stable training, serves experts in FP4 with most other parameters in FP8 to save memory, and bakes three reasoning modes directly into the model rather than bolting them on as a separate API. This is why DeepSeek V4 can be both frontier-adjacent in quality and two orders of magnitude cheaper on output: the efficiency is engineered in, not just priced in.
The practical upshot is that GPT-5.5 gives you a polished, deeply integrated agent you cannot inspect or move, while DeepSeek V4 gives you an inspectable, movable model that you operate yourself. Neither philosophy is wrong; they serve different risk and cost profiles.
Total Cost of Ownership
Per-token price is the headline, but the real economics depend on volume, caching, and whether you self-host. Here is how to think about it without overstating the case in either direction.
For the hosted-API path, the gap is so large that for high-volume workloads it changes what is buildable. A pipeline that processes, say, a billion output tokens a month costs about 30,000 dollars on GPT-5.5 at standard pricing, around 15,000 dollars with the Batch API discount, roughly 870 dollars on DeepSeek V4-Pro, and about 280 dollars on V4-Flash. Those are not small percentage differences; they are different orders of magnitude, and they decide whether an idea is economically viable at all. Prompt caching narrows the input side meaningfully — GPT-5.5 cache reads at 0.50 dollars per million tokens are genuinely cheap, and DeepSeek's cache hits at 0.0028 dollars are almost free — but output dominates agentic spend, and there GPT-5.5 has no answer to DeepSeek's pricing.
For the self-hosted path, the calculus flips from per-token billing to capital and operations. DeepSeek's open weights remove the API meter entirely, but you pay in hardware: full-precision V4-Pro requires enterprise GPU clusters, and even V4-Flash needs INT4 or INT8 quantization to fit on a single high-end consumer card. For a team with steady, predictable, very high volume and the operational maturity to run model infrastructure, self-hosting V4 can be the cheapest option of all and the only one that guarantees data never leaves your premises. For a team with spiky or modest volume, the hosted DeepSeek API is the sensible comparison — and it is still two orders of magnitude cheaper on output than GPT-5.5. The honest conclusion is that DeepSeek wins on cost in every scenario; the only question is by how much and at what operational price.
How We Tested
Honesty about methodology matters more in a cross-lab, cross-country comparison than almost anywhere else. Here is exactly what is hands-on and what is research.
We ran both models through their hosted APIs on coding and reasoning prompts to confirm they behave as documented — GPT-5.5's tool stack, reasoning-effort scale, and snapshot pinning, and DeepSeek V4's three thinking modes and OpenAI-compatible endpoint. Those behavioral observations are first-hand. What we have not done is stand up a self-hosted V4-Pro cluster, or run weeks of controlled, identical-task benchmarking of both models against each other on a private suite. For that reason, every capability claim that rests on numbers is attributed to its source — Artificial Analysis for the independent index and the SWE-bench Verified run, and OpenAI or DeepSeek for their own self-reported figures. We pulled all pricing by fetching each vendor's pricing page directly rather than trusting secondhand summaries. Where we could not verify a like-for-like number, we said so and left the cell uncommitted. That is the standard we hold ourselves to, and it is the only honest way to compare a closed US model against an open Chinese one.
Winner by Category
A single overall winner would be dishonest here, because these models are tuned for different buyers. Here is who wins what.
- Best for raw frontier capability: GPT-5.5. It sits at roughly 55 on the Artificial Analysis Intelligence Index, ahead of V4-Pro at about 44.
- Best for agentic coding: GPT-5.5. It leads SWE-bench Verified by roughly 8 points and ships the full agentic tool stack — function calling, web search, code interpreter, computer use, and MCP — on by default.
- Best for cost: DeepSeek V4. Two orders of magnitude cheaper per output token on the hosted API, and roughly 107 times cheaper on V4-Flash output specifically.
- Best for open weights and self-hosting: DeepSeek V4. MIT-licensed downloadable weights, with native Huawei Ascend support; GPT-5.5 cannot be self-hosted at all.
- Best for Western data residency and compliance: GPT-5.5. US-hosted with regional residency endpoints; DeepSeek's hosted API runs in China.
- Best for long-context work: Near-tie, edge to GPT-5.5 on raw size (1,050,000 versus 1,000,000 tokens), though DeepSeek allows up to 384K output tokens and GPT-5.5 adds a steep surcharge above 272K input.
- Best for granular reasoning control: GPT-5.5. Its five-level effort scale is the most granular of any frontier model we tested; DeepSeek offers three thinking modes.
Pros and Cons
GPT-5.5 — Pros
- Tops the Artificial Analysis Intelligence Index at roughly 55, ahead of DeepSeek V4-Pro at about 44.
- Leads agentic coding on the comparable benchmark: roughly 88.7 percent SWE-bench Verified versus 80.6 percent reported for DeepSeek V4-Pro.
- Complete agentic tool stack on by default — function calling, structured outputs, web search, file search, code interpreter, computer use, and MCP.
- US-hosted with regional data-residency endpoints — clears Western compliance bars DeepSeek's China-hosted API cannot.
- Five-level reasoning effort scale (none, low, medium, high, xhigh), the most granular reasoning control we tested in 2026.
- Prompt caching at a 90 percent discount (0.50 dollars per million cached input tokens) plus Batch mode at 50 percent off.
GPT-5.5 — Cons
- Costs two orders of magnitude more per output token than DeepSeek's hosted API — 30 dollars output per million versus 0.28 to 0.87 dollars.
- Closed model: no self-hosting, no weights, no sovereignty option.
- Long-context surcharge above 272K input tokens (10 dollars input, 45 dollars output per million) is buried in the docs and changes million-token economics.
- No fine-tuning on the GPT-5.5 base model at launch; tuned production variants must stay on the previous generation.
- ChatGPT Plus rate-limit regression at launch drew the loudest pushback from existing subscribers.
DeepSeek V4 — Pros
- Frontier-adjacent capability at open weights: about 44 on the Artificial Analysis Intelligence Index and a reported 80.6 percent SWE-bench Verified, within roughly 8 points of GPT-5.5 on coding.
- Dramatically cheaper hosted API — V4-Flash output at 0.28 dollars per million tokens is over 100 times cheaper than GPT-5.5 output.
- MIT-licensed weights downloadable from Hugging Face for free commercial use, redistribution, and modification.
- Self-hostable for full data sovereignty, with day-one support on Huawei Ascend chips that removes NVIDIA dependency.
- 1,000,000-token context with up to 384K output tokens, plus three built-in reasoning modes to tune cost against quality.
- Near-free cache-hit input pricing at 0.0028 dollars per million tokens for V4-Flash, which makes stable-prompt RAG and tool loops almost cost-free.
DeepSeek V4 — Cons
- Trails GPT-5.5 on the independent Intelligence Index, about 44 versus roughly 55, and on reported SWE-bench Verified, 80.6 versus roughly 88.7 percent.
- Hosted API runs in China, a non-starter for US Federal, EU healthcare, and many regulated buyers without a Western reseller.
- Open weights, not open source: training code and data recipe are not released, so the run cannot be fully reproduced.
- Self-hosting requires serious hardware — full-precision V4-Pro needs enterprise GPU clusters, and V4-Flash needs quantization to fit a single high-end card.
- Open-source inference frameworks take time to land first-class V4 support, and the Think-mode protocol is more complex to integrate than the previous generation.
When to Pick Each
When to pick GPT-5.5
Pick GPT-5.5 when capability and integration matter more than per-token cost. If you are doing serious agentic coding, computer-use automation, or multi-step task decomposition on the OpenAI stack, it is the stronger model on every comparable benchmark, and its tool stack and five-level reasoning control give you fine-grained leverage that DeepSeek does not match out of the box. Pick it if you are a Western enterprise with data-residency or compliance obligations, because US hosting and regional residency endpoints clear bars DeepSeek's China-hosted API cannot. And pick it if your workload is moderate in volume but high in value, where paying 30 dollars per million output tokens for the best result is a rounding error against engineer time. If you live inside ChatGPT, Codex, or the Responses API, GPT-5.5 is the natural default.
When to pick DeepSeek V4
Pick DeepSeek V4 when cost, control, or sovereignty dominate. If you are running high-volume inference where token spend is the binding constraint, a two-orders-of-magnitude cheaper API changes what is economically viable — and V4-Flash at 0.28 dollars output makes use cases that are simply unaffordable on GPT-5.5 routine. Pick it if you need to own your weights: the MIT license lets you self-host, fine-tune, and redistribute, and the Huawei Ascend support means you are not locked to a single chip vendor. Pick it if you are operating where Chinese hosting is acceptable or where self-hosting is mandatory for data sovereignty. You give up a measurable slice of frontier capability, the agentic tool stack, and the Western compliance story, but you get most of the quality at a tiny fraction of the price.
Final Verdict
This is a split verdict by use case, tilted toward GPT-5.5 on capability and toward DeepSeek V4 on cost and openness. On the one independent evaluator that scores both — Artificial Analysis — GPT-5.5 sits at roughly 55 versus about 44 for DeepSeek V4-Pro, and it leads the comparable SWE-bench Verified figure by roughly 8 points. It is the stronger model, the more deeply integrated one for agentic work, and the only one that clears Western data-residency requirements. DeepSeek V4, in return, costs over 100 times less per output token on its hosted API at the Flash tier, ships MIT-licensed open weights you can self-host, and lands within striking distance of the frontier — a genuinely remarkable result for an open model that shipped one day after GPT-5.5.
We did not crown a single overall winner because the two models are not really competing for the same buyer. If you need the best closed model, the strongest agentic coding, or US-hosted compliance, the answer is GPT-5.5. If you are cost-constrained, want to own your weights, or need to self-host for sovereignty, the answer is DeepSeek V4. Both answers are correct — for different people. All benchmark numbers here are vendor-reported or drawn from the Artificial Analysis index; only the pricing is fetch-verified directly from each vendor.
If you are weighing GPT-5.5 against other frontier models, we also ran it head-to-head with Anthropic's flagship in Claude Opus 4.8 vs GPT-5.5. And for the deep dive on each model on its own, see our full GPT-5.5 review and DeepSeek V4 review.
Frequently Asked Questions
Is GPT-5.5 better than DeepSeek V4?
On capability, yes. GPT-5.5 tops the Artificial Analysis Intelligence Index at roughly 55 versus about 44 for DeepSeek V4-Pro, and it leads SWE-bench Verified by roughly 8 points, about 88.7 percent to 80.6 percent. But DeepSeek V4 is over 100 times cheaper per output token and is open-weight and self-hostable, so the better choice depends on whether you are optimizing for capability or for cost and control.
How much cheaper is DeepSeek V4 than GPT-5.5?
Dramatically. On output tokens, DeepSeek V4-Flash at 0.28 dollars per million is roughly 107 times cheaper than GPT-5.5 at 30 dollars per million, and V4-Pro at 0.87 dollars is about 34 times cheaper. On input tokens, V4-Flash at 0.14 dollars is about 36 times cheaper than GPT-5.5 at 5 dollars. All prices were fetched directly from each vendor's pricing page in June 2026.
Is DeepSeek V4 open source?
It is open weights, not fully open source. DeepSeek V4 ships its model weights under an MIT license on Hugging Face, allowing free commercial use, redistribution, and modification. However, the training code and data recipe are not released, so the community cannot fully reproduce the training run. You can self-host and fine-tune the model, but you cannot rebuild it from scratch. GPT-5.5, by contrast, is fully closed.
Can I self-host DeepSeek V4 or GPT-5.5?
You can self-host DeepSeek V4 because its weights are MIT-licensed and downloadable, including native support for Huawei Ascend chips. You cannot self-host GPT-5.5 — it is a closed model available only through OpenAI's API, ChatGPT, and Codex. Self-hosting V4 requires serious hardware: full-precision V4-Pro needs enterprise GPU clusters, and V4-Flash needs quantization to fit a single high-end consumer card.
What is the context window for each model?
GPT-5.5 ships a 1,050,000-token context window with up to 128K output tokens, with a surcharge tier above 272K input tokens. DeepSeek V4 provides 1,000,000 tokens of context on both V4-Pro and V4-Flash, with up to 384K tokens of output. The two are effectively tied on raw context length, with GPT-5.5 slightly larger on input and DeepSeek larger on output.
Which model is better for coding?
GPT-5.5 leads on every comparable coding signal. It scores roughly 88.7 percent on SWE-bench Verified on the Artificial Analysis run against DeepSeek's reported 80.6 percent, adds 58.6 percent on the harder SWE-bench Pro that DeepSeek does not report the same way, and ships a full agentic tool stack on by default. DeepSeek V4 is still strong and far cheaper, which makes it attractive for high-volume coding where cost dominates over the last few points of capability.
Is DeepSeek V4 safe to use for a Western company?
It depends on your data-residency rules. DeepSeek's hosted API runs in China, which keeps many regulated buyers — US Federal, EU healthcare — from adopting it without a Western reseller. The MIT-licensed open weights let you sidestep this by self-hosting the model on your own infrastructure anywhere in the world. If compliance is the concern and you cannot self-host, GPT-5.5's US hosting and regional residency endpoints are the safer default.
How do the two models score on independent benchmarks?
The cleanest independent signal is the Artificial Analysis Intelligence Index, which scores both with the same battery: GPT-5.5 sits at roughly 55, while DeepSeek V4-Pro in maximum reasoning mode scores about 44. That clear lead is consistent with the SWE-bench Verified figures, where GPT-5.5's roughly 88.7 percent leads DeepSeek's reported 80.6 percent. We treat the SWE-bench numbers as attributed claims because they come from different evaluation harnesses.
What are the different DeepSeek V4 tiers?
DeepSeek V4 ships in two sizes. V4-Pro is a 1.6-trillion-parameter mixture-of-experts model with about 49 billion parameters active per token, priced at 0.435 dollars input and 0.87 dollars output per million tokens. V4-Flash is a 284-billion-parameter model with about 13 billion active, priced at 0.14 dollars input and 0.28 dollars output. Both carry a 1,000,000-token context window, and both support three reasoning modes — Non-Think, Think High, and Think Max.
Does GPT-5.5 have a cheaper mode?
Yes, two cost levers. The Batch API offers a 50 percent discount for asynchronous workloads, bringing GPT-5.5 to 2.50 dollars input and 15 dollars output per million tokens. Prompt caching drops repeated input to 0.50 dollars per million tokens on cache reads. Even with both applied, however, GPT-5.5 remains far more expensive per output token than DeepSeek V4's hosted API.
Which should I choose for a high-volume production workload?
For pure high volume where token cost is the binding constraint, DeepSeek V4 is usually the rational choice — a two-orders-of-magnitude cheaper API makes workloads viable that GPT-5.5 cannot support economically. Choose GPT-5.5 instead when each call is high-value, when you need the strongest agentic coding and tool integration, or when Western data residency is mandatory. Many teams run both: GPT-5.5 for the hardest tasks, DeepSeek V4 for everything bulk.
When were these models released and is this comparison current?
GPT-5.5 launched April 23, 2026, and DeepSeek V4 shipped April 24, 2026 — one day apart. This comparison was last updated in June 2026, with all pricing fetched directly from each vendor's pricing page at that time and all benchmark figures attributed to Artificial Analysis or to each vendor's own reports.
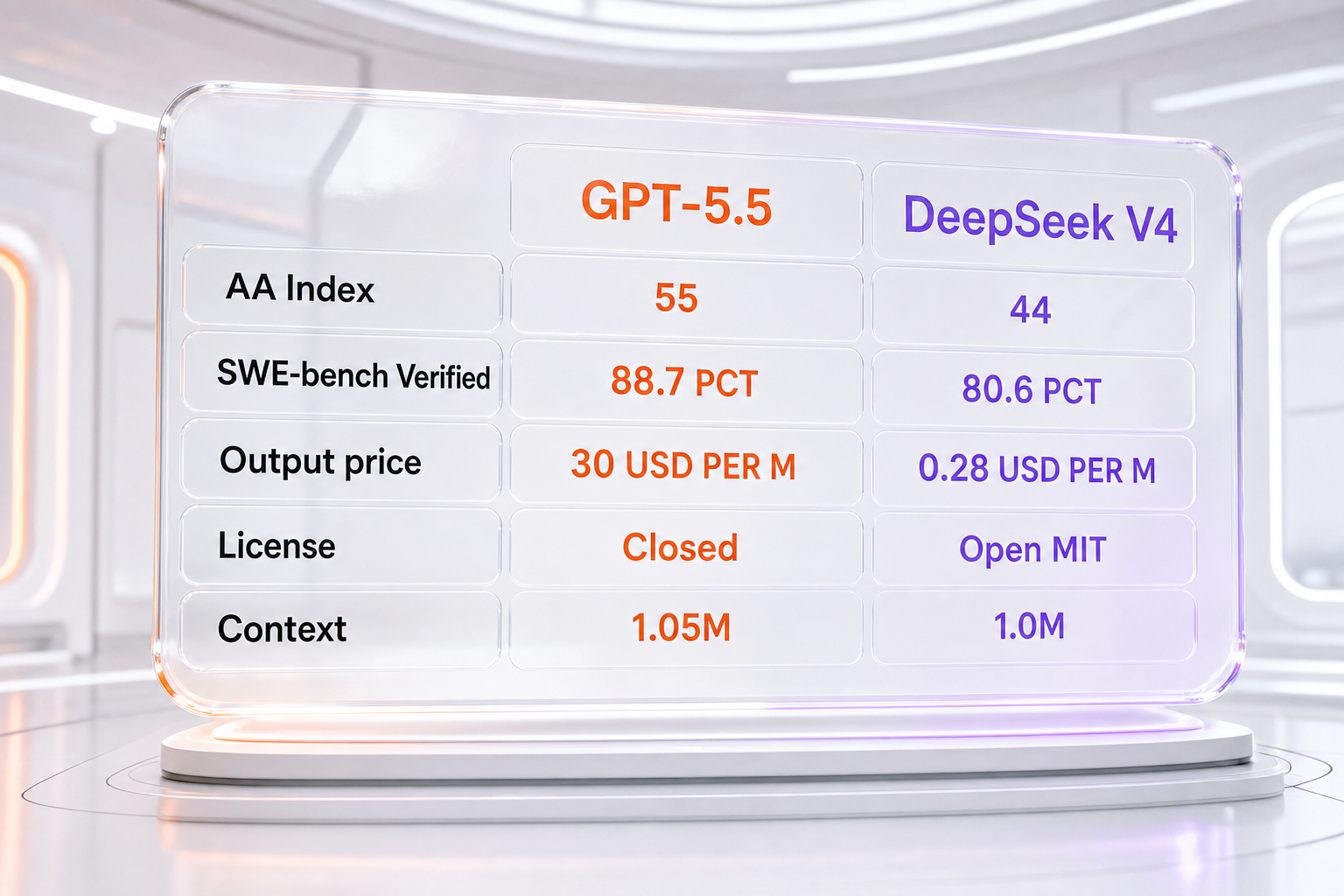

Our Verdict
Split verdict by use case. GPT-5.5 wins raw capability and agentic coding — it leads the Artificial Analysis Intelligence Index roughly 55 to 44 and SWE-bench Verified roughly 88.7 percent to 80.6 percent. DeepSeek V4 wins cost, open weights, and self-hosting by a landslide: V4-Flash output at 0.28 dollars per million tokens is over 100 times cheaper than GPT-5.5 output at 30 dollars. No single overall winner — pick GPT-5.5 for the strongest closed model and US-hosted compliance, DeepSeek V4 for cost, sovereignty, and downloadable MIT-licensed weights.
Choose GPT-5.5
OpenAI's first fully retrained base model since GPT-4.5 — agentic, faster, and double the API price.
Try GPT-5.5 →Choose DeepSeek V4
Chinese open-source flagship: 1.6T MoE (49B active), 1M context, 80.6% SWE-bench Verified, MIT license — at one-fifth the price of Claude Opus 4.7
Try DeepSeek V4 →Frequently Asked Questions
Is GPT-5.5 better than DeepSeek V4?
Split verdict by use case. GPT-5.5 wins raw capability and agentic coding — it leads the Artificial Analysis Intelligence Index roughly 55 to 44 and SWE-bench Verified roughly 88.7 percent to 80.6 percent. DeepSeek V4 wins cost, open weights, and self-hosting by a landslide: V4-Flash output at 0.28 dollars per million tokens is over 100 times cheaper than GPT-5.5 output at 30 dollars. No single overall winner — pick GPT-5.5 for the strongest closed model and US-hosted compliance, DeepSeek V4 for cost, sovereignty, and downloadable MIT-licensed weights.
Which is cheaper, GPT-5.5 or DeepSeek V4?
GPT-5.5 is priced at $5 in / $30 out per M tokens. DeepSeek V4 is priced at $0.14 in / $0.28 out per M tokens (free plan available). Check the pricing comparison section above for a full breakdown.
What are the main differences between GPT-5.5 and DeepSeek V4?
The key differences span across 10 features we compared. For AA Intelligence Index (Artificial Analysis, same evaluator), GPT-5.5 offers About 55 while DeepSeek V4 offers About 44 (V4-Pro max reasoning). For SWE-bench Verified, GPT-5.5 offers About 88.7% (Artificial Analysis run) while DeepSeek V4 offers 80.6% (DeepSeek reports). For Output price (per million tokens), GPT-5.5 offers 30 dollars while DeepSeek V4 offers Flash 0.28 dollars, Pro 0.87 dollars. See the full feature comparison table above for all details.