Claude Opus 4.8 vs GPT-5.5: Output Cost and SWE-bench Pro Compared (2026)


Opus 4.8 leads SWE-bench Pro (69.2% vs 58.6%) and is cheaper on output; GPT-5.5 wins declared 1M context and web tasks. A split, attributed verdict.

Feature Comparison
| Feature | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|
| API output price (per million tokens) | $25.00 (verified) | $30.00 (OpenAI reports) |
| API input price (per million tokens) | $5.00 (verified) | $5.00 (OpenAI reports) |
| SWE-bench Pro (agentic coding, like-for-like) | 69.2% (Anthropic reports) | 58.6% (OpenAI reports) |
| Terminal-Bench (different versions — not comparable) | 74.6% on v2.1 (Anthropic reports) | 82.7% on v2.0 (OpenAI reports) |
| Computer use — Online-Mind2Web | 84% (Anthropic reports) | No matching verified figure |
| GDPval (economic-value work) | Not reported | 84.9% (OpenAI reports) |
| BrowseComp Pro (web navigation) | Not reported | 90.1% (OpenAI reports) |
| Declared API context window | Not declared in announcement | 1,000,000 tokens (400K in Codex) |
| Knowledge cutoff | Not stated in announcement | December 2025 (OpenAI reports) |
| Ecosystem / distribution | Anthropic API, claude.ai, Claude Code | ChatGPT, Codex, OpenAI API |
Pricing Comparison
Claude Opus 4.8
GPT-5.5
Detailed Comparison
Claude Opus 4.8 and GPT-5.5 are the two flagship frontier large language models being compared here. Claude Opus 4.8 is Anthropic's top model, announced May 28, 2026, priced at $5 per million input tokens and $25 per million output tokens. GPT-5.5 is OpenAI's first fully retrained base model since GPT-4.5, launched April 23, 2026, priced at $5 per million input tokens and $30 per million output tokens. On the one benchmark both vendors report the same way — SWE-bench Pro — Anthropic reports 69.2 percent for Opus 4.8 versus OpenAI's reported 58.6 percent for GPT-5.5. Opus 4.8 is cheaper on output and leads agentic coding on that like-for-like benchmark; GPT-5.5 reports a larger declared API context window and stronger results on the web and economic-value tasks where each was separately measured. Best for agentic coding and output-cost control: Opus 4.8. Best for broad declared context and web-task breadth inside the OpenAI ecosystem: GPT-5.5.
TL;DR — Quick Verdict
This is a split verdict, tilted by category rather than a single overall winner. We compared the published benchmarks and specifications of Claude Opus 4.8 and GPT-5.5 side-by-side, pulled the pricing directly from each vendor's pages, and added our own hands-on observations on Opus 4.8 (we use it daily) — scoped, because we have not run weeks of controlled side-by-side benchmarking of both models ourselves. Where the two vendors measure the same benchmark the same way, Opus 4.8 leads agentic coding; where they measure different things, we refuse to fabricate a head-to-head. Here is the short version.
- Best for agentic coding: Claude Opus 4.8. On SWE-bench Pro — the one coding benchmark both vendors report comparably — Anthropic reports 69.2 percent for Opus 4.8 versus OpenAI's reported 58.6 percent for GPT-5.5. That is a like-for-like gap of roughly 10 points.
- Best for output-cost control: Claude Opus 4.8. Output is $25 per million tokens versus $30 per million for GPT-5.5 standard — about 17 percent cheaper on output. Input is identical at $5 per million on both.
- Best for declared context and web tasks: GPT-5.5. OpenAI reports a 1,000,000-token API context window (400,000 in Codex) and strong results on BrowseComp Pro and GDPval — the broad-knowledge-work and web-navigation tasks.
- Best for ecosystem reach: GPT-5.5. ChatGPT, Codex, and the OpenAI API surface area remain the widest distribution in spring 2026.
- Computer use: Anthropic reports Opus 4.8 ahead of GPT-5.5 on computer-use tasks, scoring 84 percent on Online-Mind2Web. We could not find a matching independently published GPT-5.5 number to verify the head-to-head, so treat the "ahead of GPT-5.5" framing as Anthropic's claim, not a verified result.
The honest caveat up front: nearly every benchmark below is vendor-reported and press-relayed, not independently verified. Two of the most-quoted coding numbers — Terminal-Bench — were measured on different versions (2.1 for Opus 4.8, 2.0 for GPT-5.5) and are not directly comparable. We flag every one of these inline. Treat the verdict as "directionally correct on the comparable data, transparent about the rest."
Claude Opus 4.8 vs GPT-5.5 — Overview
What Is Claude Opus 4.8?
Claude Opus 4.8 is Anthropic's flagship large language model, announced on May 28, 2026. We cover it in depth in our Claude Opus 4.8 review. Anthropic positions it for agentic coding, computer use, and multi-agent orchestration — the same flagship slot Opus 4.7 occupied, with the headline improvements concentrated in long-horizon agentic reliability and computer-use accuracy. We walked through the launch in detail in our Claude Opus 4.8 launch breakdown. API pricing is $5 per million input tokens and $25 per million output tokens. There is also a Fast Mode that runs at roughly 2.5x the speed for $10 per million input and $50 per million output tokens — useful when latency, not unit cost, is the constraint. Anthropic did not declare a context-window figure in the launch announcement, so we do not assert one here. We pulled the pricing directly from Anthropic's official Opus 4.8 announcement page on May 29, 2026; it is verified. The benchmark numbers below come from the same announcement and the press coverage relaying Anthropic's table, and Anthropic's own page does not publish every figure in the body text — so we attribute and flag them as not independently verified. We have used Opus 4.8 daily as our default agent model since launch; the qualitative behavior we describe later (it pushes back on weak plans, catches its own mistakes) matches what a staff engineer is quoted saying on Anthropic's page, but our observations are anecdotal, not a controlled benchmark.
What Is GPT-5.5?
GPT-5.5 is OpenAI's flagship general-purpose model, launched on April 23, 2026 (codenamed "Spud" during training). See our full GPT-5.5 review for the detail. It is OpenAI's first fully retrained base model since GPT-4.5 — every release from 5.0 through 5.4 was a post-training iteration on the same foundation, while 5.5 rebuilt that foundation from scratch. We covered the launch and OpenAI's agentic super-app strategy in our GPT-5.5 launch coverage. API pricing is $5 per million input tokens and $30 per million output tokens for the standard model; GPT-5.5 Pro, the deeper-reasoning variant, runs at $30 per million input and $180 per million output. OpenAI reports a 1,000,000-token API context window, with a 400,000-token window inside Codex, and a knowledge cutoff of December 2025. Sourcing note: OpenAI's official GPT-5.5 announcement page returned an HTTP 403 to our direct fetch on May 29, 2026, so we could not verify these figures on the source page itself. The numbers we cite for GPT-5.5 come from OpenAI's reporting as relayed through secondary coverage (Decrypt and others) — we attribute them to "OpenAI reports" throughout and flag them as not fetch-verified. We did not want to silently present a 403-blocked page as if we had read it.
How We Compared Them — and What We Did Not Do
Transparency on method matters more than usual here, because the headline numbers are a minefield. Here is exactly what we did and did not do.
- Pricing: fetched directly from each vendor. Opus 4.8 pricing is verified against Anthropic's official announcement page (May 29, 2026). GPT-5.5 pricing is from OpenAI's reporting relayed through coverage, because the OpenAI page returned a 403 to our fetch.
- Benchmarks: we only declare a winner when both vendors report the same benchmark, same version. That happens exactly once in the comparable set: SWE-bench Pro. Everywhere else, we present each model's number as "where it was measured" and decline to fabricate a head-to-head.
- Terminal-Bench: Opus 4.8's figure is on Terminal-Bench 2.1; GPT-5.5's is on Terminal-Bench 2.0. Different versions of the harness are not directly comparable, so we do not name a winner on Terminal-Bench. (Anthropic's own page footnotes a GPT-5.5 Terminal-Bench 2.1 figure of 83.4 percent, which differs again from the 82.7 percent on 2.0 floating around the coverage — another reason to treat Terminal-Bench cross-model claims with suspicion.)
- Hands-on: our qualitative notes on Opus 4.8 come from daily production use. We have not run a controlled, equal-conditions head-to-head of both models for weeks, so we do not present hands-on "winners." Where we describe behavior, we scope it to what we observed.
- Disclosure: we have no affiliate relationship with Anthropic or OpenAI. There are no sponsored links on this page. Both vendor links below are plain reference links.
Features and Benchmarks Comparison
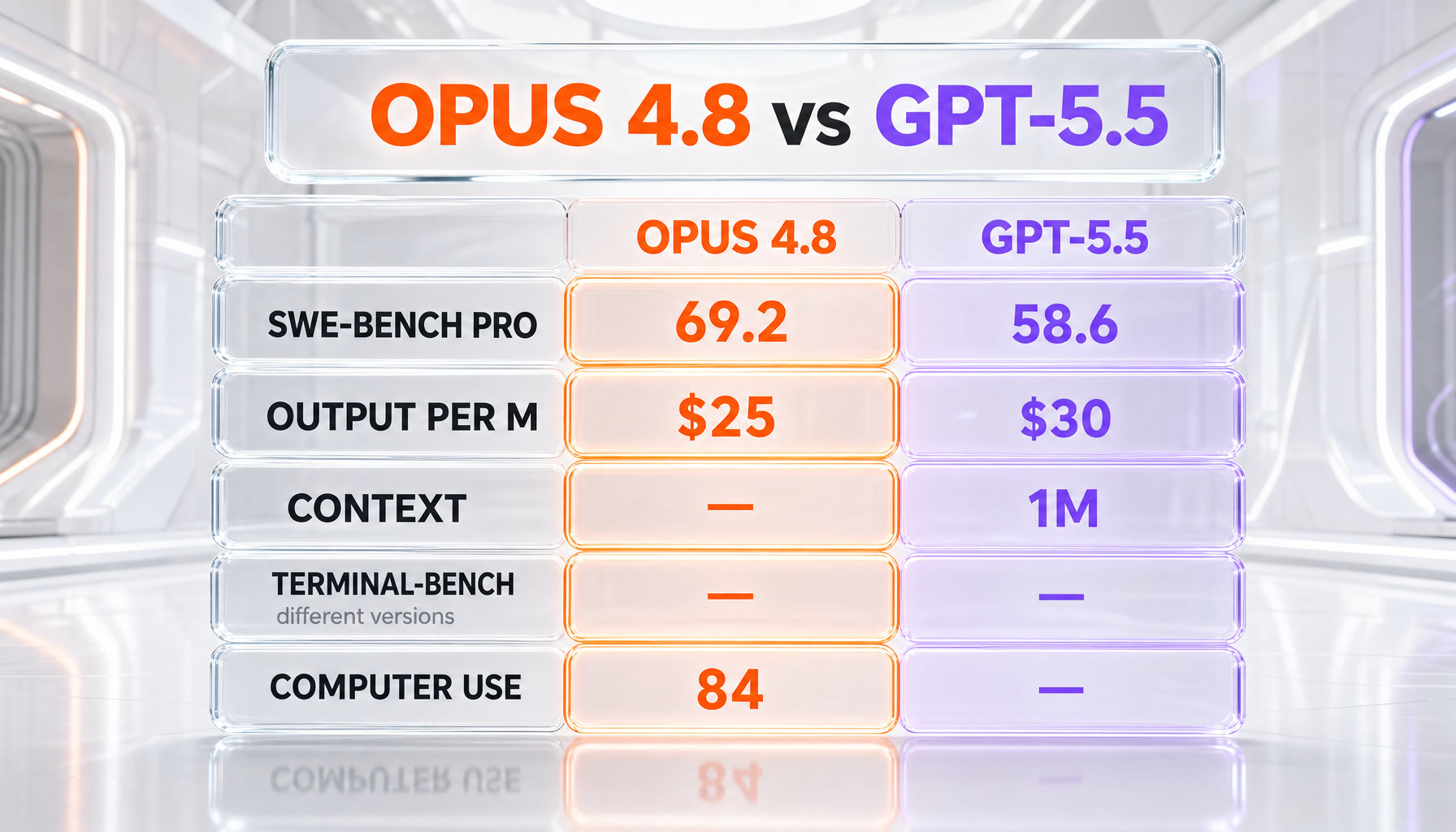
The table below lists every dimension we could verify or attribute. Read the "Winner" column carefully: it says "Tie / not comparable" wherever the two vendors measured different things or different benchmark versions. Those are not cop-outs — they are the honest read. Every benchmark figure is vendor-reported and press-relayed unless stated otherwise.
| Feature | Claude Opus 4.8 | GPT-5.5 | Winner |
|---|---|---|---|
| API input price (per million tokens) | $5.00 (verified) | $5.00 (OpenAI reports) | Tie |
| API output price (per million tokens) | $25.00 (verified) | $30.00 (OpenAI reports) | Claude Opus 4.8 |
| Fast / faster tier | Fast Mode: 2.5x speed, $10 / $50 per million (verified) | Not the same construct (Pro variant: $30 / $180 per million) | Tie / not comparable |
| SWE-bench Pro (agentic coding) | 69.2% (Anthropic reports) | 58.6% (OpenAI reports) | Claude Opus 4.8 |
| Terminal-Bench | 74.6% on version 2.1 (Anthropic reports) | 82.7% on version 2.0 (OpenAI reports) | Tie / not comparable (different versions) |
| SWE-bench Verified | 88.6% (Anthropic reports) | Not reported the same way | Where measured (Opus only) |
| Computer use — Online-Mind2Web | 84% (Anthropic reports) | No matching verified figure found | Where measured (Opus only) |
| GDPval (economic-value work) | Not reported | 84.9% (OpenAI reports) | Where measured (GPT-5.5 only) |
| BrowseComp Pro (web navigation) | Not reported | 90.1% (OpenAI reports) | Where measured (GPT-5.5 only) |
| Declared API context window | Not declared in announcement | 1,000,000 tokens (OpenAI reports; 400,000 in Codex) | GPT-5.5 (declared) |
| Knowledge cutoff | Not stated in announcement | December 2025 (OpenAI reports) | Where stated (GPT-5.5) |
| Computer use as a capability | Yes (a launch focus) | Yes | Tie |
| Ecosystem / distribution | Anthropic API, claude.ai, Claude Code | ChatGPT, Codex, OpenAI API | GPT-5.5 |
Synthesis: the only clean, like-for-like benchmark win in this table is SWE-bench Pro, and Opus 4.8 takes it by about 10 points (69.2 percent versus 58.6 percent, both vendor-reported). Opus 4.8 also wins output pricing outright at $25 versus $30 per million tokens. GPT-5.5 wins on declared context window (1M versus undeclared) and is the only model with published GDPval and BrowseComp Pro figures. Terminal-Bench looks like a GPT-5.5 win at a glance (82.7 versus 74.6), but the versions differ (2.0 versus 2.1), so we score it "not comparable" — and we would rather under-claim than mislead. Anthropic's computer-use lead claim rests on an Online-Mind2Web figure (84 percent) with no matching GPT-5.5 number we could verify, so it stays a claim.
Pricing — Claude Opus 4.8 vs GPT-5.5 in 2026
Pricing is the cleanest part of this comparison because we pulled it from the vendors directly. Both models share the same headline input rate of $5 per million tokens. The divergence is on output and on the "go faster" tiers. We verified Opus 4.8 pricing against Anthropic's official announcement page on May 29, 2026; GPT-5.5 pricing comes from OpenAI's reporting (the OpenAI page itself returned a 403 to our fetch, so we flag it).
Claude Opus 4.8 Pricing
| Tier | Input (per million tokens) | Output (per million tokens) | Notes |
|---|---|---|---|
| Standard API | $5.00 | $25.00 | Verified on Anthropic's Opus 4.8 page |
| Fast Mode | $10.00 | $50.00 | About 2.5x the speed, double the unit price |
GPT-5.5 Pricing
| Tier | Input (per million tokens) | Output (per million tokens) | Notes |
|---|---|---|---|
| GPT-5.5 standard API | $5.00 | $30.00 | OpenAI reports (page returned 403 to our fetch) |
| GPT-5.5 Pro API | $30.00 | $180.00 | Deeper-reasoning variant; OpenAI reports |
Pricing verdict: Claude Opus 4.8 is the cheaper model on output-heavy workloads — $25 per million output tokens versus $30 per million for GPT-5.5 standard, about 17 percent cheaper on output, with identical $5 input. On a representative agentic call of 50,000 input tokens and 5,000 output tokens, Opus 4.8 standard costs about $0.375 ($5 times 0.05 input plus $25 times 0.005 output) and GPT-5.5 standard costs about $0.40 ($5 times 0.05 plus $30 times 0.005) — Opus 4.8 is roughly 6 percent cheaper on that mix, widening as output share grows. If you need raw speed, Opus 4.8 Fast Mode doubles the unit price to $10 / $50 per million for about 2.5x throughput. GPT-5.5 Pro, by contrast, is a different product (deeper reasoning) at $30 / $180 per million, not a speed tier — so we do not compare Fast Mode against Pro as like-for-like. One thing neither vendor's headline tells you: per-token rates are not per-task cost. Tokenizer differences and response verbosity move the real bill, and we did not run a controlled token-accounting test across both models, so we will not claim a per-task winner beyond the rate-card math above.
Hands-On Notes — Scoped to Opus 4.8
We owe you honesty about the limits of this section. We use Claude Opus 4.8 daily as our default agent model on a Next.js and Supabase content pipeline. We have not run weeks of controlled, equal-conditions side-by-side testing of GPT-5.5 on the same harness. So this is not a "we tested both for a month" section — it is "here is what we observed using Opus 4.8 in production, scoped to that." Take it as qualitative color on one model, not a head-to-head result.
What stands out on Opus 4.8 in daily use: it pushes back on weak plans before executing, and it catches its own mistakes mid-task more often than the 4.x models we used before — which lines up with the staff-engineer quote on Anthropic's announcement page ("noticeably better judgment, catches its own mistakes, pushes back when a plan isn't sound"). On long agentic runs — 30 or more tool calls in our content pipeline — it finishes more often without a "done" claim that turns out to be a broken build. That reliability-on-long-runs property is the single reason it is our default. On computer-use style tasks (clicking through a vendor pricing page to extract structured data), it has been solid, which is consistent with Anthropic's emphasis on computer use at launch and its reported 84 percent on Online-Mind2Web — but again, that is one model's number, not a head-to-head we ran.
What we cannot tell you from our own use: whether GPT-5.5 would beat Opus 4.8 on those same tasks. We have not run that test under controlled conditions. The published benchmarks suggest Opus 4.8 leads on the one comparable coding benchmark (SWE-bench Pro) and GPT-5.5 leads on web and economic-value tasks where it was separately measured — and that is as far as the evidence honestly takes us.
Winner per Category

Best for Agentic Coding: Claude Opus 4.8
On SWE-bench Pro — the one coding benchmark both vendors report comparably — Anthropic reports 69.2 percent for Opus 4.8 versus OpenAI's reported 58.6 percent for GPT-5.5, a like-for-like gap of about 10 points. In our own daily use, Opus 4.8's completion reliability on long autonomous runs is the property that matters most for unattended pipelines. If your primary workload is multi-step agentic coding, Opus 4.8 is the pick on the evidence we can stand behind.
Best for Output-Cost Control: Claude Opus 4.8
Output is $25 per million tokens versus $30 per million for GPT-5.5 standard — about 17 percent cheaper, with identical $5 input. For content generation, long-form synthesis, and any output-heavy workload, that gap compounds. This is verified pricing, not a benchmark estimate.
Best for Declared Context Window: GPT-5.5
OpenAI reports a 1,000,000-token API context window (400,000 inside Codex). Anthropic did not declare a context figure for Opus 4.8 in its announcement, so we cannot compare absolute windows — and we will not invent an Opus number to make the row look balanced. If a large declared context window is a hard requirement, GPT-5.5 is the model that publishes one.
Best for Web and Economic-Value Tasks: GPT-5.5
GPT-5.5 is the only model here with published GDPval (84.9 percent, economic-value knowledge work) and BrowseComp Pro (90.1 percent, web navigation) figures. Opus 4.8 did not report these, so this is "where each was measured," not a head-to-head win — but if your workload is heavy on web navigation or broad knowledge work, GPT-5.5 has the published evidence on its side.
Best for Ecosystem and Distribution: GPT-5.5
ChatGPT, Codex, and the OpenAI API remain the widest distribution surface in spring 2026. If you live in the OpenAI ecosystem — Codex for coding, ChatGPT for everything else — GPT-5.5 is the path of least resistance. Opus 4.8 reaches you through the Anthropic API, claude.ai, and Claude Code, which is plenty for engineering teams but narrower for general consumer use.
Computer Use: Opus 4.8 (Anthropic's Claim)
Anthropic reports Opus 4.8 ahead of GPT-5.5 on computer-use tasks, with 84 percent on Online-Mind2Web. We could not find a matching independently published GPT-5.5 figure to verify that head-to-head, so we present it as Anthropic's claim. In our own use, Opus 4.8's computer-use behavior has been reliable — but that is anecdotal, not a benchmark we ran against GPT-5.5.
Pros and Cons
Claude Opus 4.8 Pros and Cons
What we like about Claude Opus 4.8
- Leads the one comparable coding benchmark. SWE-bench Pro at a reported 69.2 percent versus GPT-5.5's reported 58.6 percent — about 10 points, like-for-like.
- Cheaper on output. $25 per million output tokens versus $30 per million for GPT-5.5 standard (verified pricing), with identical $5 input.
- Completion reliability on long agentic runs. In our daily use it finishes 30-plus-tool-call tasks without false "done" claims more consistently than prior models — the reason it is our default agent.
- Better judgment in practice. It pushes back on weak plans and catches its own mistakes, matching the staff-engineer quote on Anthropic's page.
- Fast Mode option. When latency matters more than unit cost, 2.5x speed is available at $10 / $50 per million tokens.
Where Claude Opus 4.8 falls short
- No declared context window. Anthropic did not publish a context figure in the announcement, so you cannot compare it against GPT-5.5's declared 1M on paper.
- Benchmarks are vendor-reported, not independently verified. Anthropic's own page does not publish every figure in the body, and the comparison table is press-relayed.
- Narrower consumer distribution. Strong for engineering teams via API and Claude Code, but it does not match ChatGPT's consumer reach.
- Fast Mode doubles the unit price. The speed tier costs $10 / $50 per million — the savings versus GPT-5.5 evaporate if you run everything in Fast Mode.
GPT-5.5 Pros and Cons
What we like about GPT-5.5
- First fully retrained base since GPT-4.5. The "Spud" foundation is a multi-month rebuild, not a quarterly post-training tweak — future point releases inherit a stronger starting point.
- Large declared context window. OpenAI reports 1,000,000 tokens on the API (400,000 in Codex).
- Strong web and economic-value benchmarks. Reported 90.1 percent on BrowseComp Pro and 84.9 percent on GDPval — the published evidence for web-heavy and broad knowledge work.
- Widest ecosystem. ChatGPT, Codex, and the OpenAI API are the broadest distribution surface in spring 2026.
- Recent knowledge cutoff. OpenAI reports December 2025, current at launch.
Where GPT-5.5 falls short
- More expensive on output. $30 per million output tokens versus $25 per million for Opus 4.8 standard — about 20 percent more on output-heavy workloads.
- Behind on the comparable coding benchmark. OpenAI's reported 58.6 percent on SWE-bench Pro trails Opus 4.8's reported 69.2 percent.
- Announcement page was not fetch-verifiable. OpenAI's GPT-5.5 page returned a 403 to our direct fetch, so its figures here are relayed through secondary coverage, not read from the source.
- Pro variant is steep. GPT-5.5 Pro at $30 / $180 per million is a heavy premium for deeper reasoning.
When to Pick Claude Opus 4.8 vs GPT-5.5
Pick Claude Opus 4.8 if...
- Your primary workload is agentic coding — Opus 4.8 leads the one comparable benchmark, SWE-bench Pro, by about 10 reported points.
- You run output-heavy workloads and want the cheaper rate — $25 per million output versus $30 per million.
- You run long unattended agentic pipelines where completion reliability matters more than raw speed.
- Computer-use accuracy is central and you are comfortable relying on Anthropic's reported lead until independent numbers land.
- You work primarily through the API, claude.ai, or Claude Code.
Pick GPT-5.5 if...
- You need a large, declared context window — OpenAI publishes 1,000,000 tokens on the API.
- Your workload is web-navigation or broad economic-value knowledge work, where GPT-5.5 has published BrowseComp Pro and GDPval figures.
- You live in the OpenAI ecosystem — ChatGPT, Codex, and the OpenAI API.
- You want OpenAI's most recently rebuilt base model, retrained from scratch since GPT-4.5.
- Consumer reach and distribution breadth matter more than the output-token rate.
Frequently Asked Questions
Is Claude Opus 4.8 better than GPT-5.5 in 2026?
It depends on the workload, and we refuse to fake a single overall winner. On the one coding benchmark both vendors report the same way — SWE-bench Pro — Anthropic reports 69.2 percent for Opus 4.8 versus OpenAI's reported 58.6 percent for GPT-5.5, so Opus 4.8 leads agentic coding by about 10 points. Opus 4.8 is also cheaper on output ($25 versus $30 per million tokens). GPT-5.5 reports a larger declared context window (1,000,000 tokens) and stronger BrowseComp Pro and GDPval results for web and economic-value tasks. Best for agentic coding and output cost: Opus 4.8. Best for declared context and web breadth: GPT-5.5.
How much do Claude Opus 4.8 and GPT-5.5 cost?
Both share a $5 per million input token rate. Output diverges: Claude Opus 4.8 is $25 per million output tokens and GPT-5.5 standard is $30 per million, making Opus 4.8 about 17 percent cheaper on output. Opus 4.8 also offers a Fast Mode at roughly 2.5x speed for $10 input and $50 output per million tokens. GPT-5.5 Pro, a deeper-reasoning variant, runs at $30 input and $180 output per million. Opus 4.8 pricing is verified against Anthropic's official page; GPT-5.5 pricing is reported by OpenAI (its page returned a 403 to our direct fetch).
Which is better for agentic coding: Claude Opus 4.8 or GPT-5.5?
Claude Opus 4.8, on the comparable evidence. SWE-bench Pro is the one coding benchmark both vendors report the same way, and Anthropic reports 69.2 percent for Opus 4.8 versus OpenAI's reported 58.6 percent for GPT-5.5. In our own daily use, Opus 4.8's reliability on long agentic runs (30-plus tool calls) is the property that makes it our default agent model. We did not run a controlled head-to-head against GPT-5.5, so we lean on the comparable benchmark plus our scoped hands-on experience rather than claiming a tested win.
Why don't you compare Claude Opus 4.8 and GPT-5.5 on Terminal-Bench?
Because the two figures were measured on different versions of the benchmark. Opus 4.8's reported 74.6 percent is on Terminal-Bench 2.1, while GPT-5.5's reported 82.7 percent is on Terminal-Bench 2.0. Different harness versions are not directly comparable, so declaring a winner would be misleading. To make it worse, Anthropic's own page footnotes a GPT-5.5 Terminal-Bench 2.1 figure of 83.4 percent — a third number — which is exactly why we treat cross-model Terminal-Bench claims with caution and score that row "not comparable."
Which has the larger context window: Claude Opus 4.8 or GPT-5.5?
GPT-5.5, on declared figures. OpenAI reports a 1,000,000-token API context window for GPT-5.5 (400,000 inside Codex). Anthropic did not declare a context-window figure for Claude Opus 4.8 in its launch announcement, so we cannot state an Opus 4.8 number — and we will not invent one. If a large, published context window is a hard requirement, GPT-5.5 is the model with the public number.
Does Claude Opus 4.8 really beat GPT-5.5 at computer use?
Anthropic says so, and reports 84 percent on the Online-Mind2Web computer-use benchmark, framing Opus 4.8 as ahead of GPT-5.5. We could not find a matching, independently published GPT-5.5 Online-Mind2Web figure to verify that head-to-head, so we present it as Anthropic's claim rather than a confirmed result. In our daily use, Opus 4.8's computer-use behavior has been reliable, but that is anecdotal and not a controlled comparison against GPT-5.5.
Are the benchmark numbers in this comparison independently verified?
No, and we want to be upfront about it. Nearly every benchmark here is vendor-reported and press-relayed: Anthropic's figures for Claude Opus 4.8 (SWE-bench Pro 69.2 percent, SWE-bench Verified 88.6 percent, Terminal-Bench 2.1 74.6 percent, Online-Mind2Web 84 percent) and OpenAI's figures for GPT-5.5 (Terminal-Bench 2.0 82.7 percent, GDPval 84.9 percent, SWE-bench Pro 58.6 percent, BrowseComp Pro 90.1 percent). The only fully verified data in this comparison is Opus 4.8 pricing, which we fetched directly from Anthropic. GPT-5.5 figures are relayed through coverage because OpenAI's page returned a 403 to our fetch.
Can I switch from Claude Opus 4.8 to GPT-5.5 (or vice versa) easily?
API-level switching is straightforward — both expose chat-style endpoints with similar message structures. Production migration takes work: GPT-5.5 uses OpenAI's API conventions and Codex tooling, while Claude Opus 4.8 uses Anthropic's Messages API and Claude Code. Function-calling shapes differ slightly. If your stack sits behind an abstraction layer like the Vercel AI SDK, LangChain, or LiteLLM, switching is largely a config change. If you call vendor APIs directly, budget one to three days of integration rework per service.
Do Claude Opus 4.8 and GPT-5.5 work together in the same agent?
Yes — multi-model routing is a common production pattern. A typical split: route agentic coding and long-horizon reasoning steps through Claude Opus 4.8 (it leads SWE-bench Pro and is cheaper on output), and route web-navigation or broad knowledge-work steps through GPT-5.5 (stronger published BrowseComp Pro and GDPval figures, larger declared context). Frameworks like the Vercel AI SDK and LangChain make cost-aware routing by workload type practical, which for many teams beats single-vendor purity.
Is GPT-5.5 faster than Claude Opus 4.8?
We do not have a controlled latency benchmark across both models, so we will not claim a speed winner. What we can say from the pricing pages: Claude Opus 4.8 offers an explicit Fast Mode at roughly 2.5x speed for double the unit price ($10 input, $50 output per million tokens), which is a deliberate speed lever GPT-5.5 standard does not expose the same way. GPT-5.5 Pro is a deeper-reasoning variant, not a speed tier. If latency is your constraint, Opus 4.8 Fast Mode is the clearer published option.
Which model has a more recent knowledge cutoff?
GPT-5.5, by what is published. OpenAI reports a December 2025 knowledge cutoff for GPT-5.5. Anthropic did not state a knowledge cutoff for Claude Opus 4.8 in its launch announcement, so we cannot compare the two directly. For workloads that depend on the freshest training data, GPT-5.5 has the published cutoff; for everything else, both models are recent enough that retrieval or web tools usually matter more than the base cutoff date.
What are the alternatives to Claude Opus 4.8 and GPT-5.5?
If the frontier premium on either model is too steep, three alternatives are worth a look in 2026: a cheaper Anthropic Sonnet-class model for non-frontier coding at a lower output rate; Google's Gemini Pro line for high-volume retrieval work with a large context window; and an open-weights model for on-premises or sovereignty-sensitive deployments. For most production agentic-coding work, though, the real choice in this niche is between Claude Opus 4.8 and GPT-5.5 — the two flagship models this comparison covers. See our LLM coverage for the broader field.
Final Verdict — A Split Decision by Category
After comparing the published benchmarks and pricing of Claude Opus 4.8 and GPT-5.5 side-by-side — and adding our scoped hands-on experience with Opus 4.8 — our verdict is split by category, tilted toward Opus 4.8 on the dimensions we can verify like-for-like. Claude Opus 4.8 is the pick for agentic coding and output-cost control: it leads the one comparable coding benchmark (SWE-bench Pro, a reported 69.2 percent versus 58.6 percent) and is about 17 percent cheaper on output ($25 versus $30 per million tokens, verified pricing). GPT-5.5 is the pick for declared context window and web-task breadth: OpenAI publishes a 1,000,000-token API context window and stronger BrowseComp Pro and GDPval figures, and it carries the widest ecosystem.
We deliberately did not crown a single overall winner, because the evidence does not support one honestly. The Terminal-Bench numbers were measured on different versions (2.1 versus 2.0) and are not comparable; Anthropic's computer-use lead rests on a single reported figure with no verified GPT-5.5 counterpart; and we have not run a controlled head-to-head ourselves. What we can stand behind: on the one like-for-like coding benchmark, Opus 4.8 leads; on verified pricing, Opus 4.8 is cheaper on output; and on declared context plus published web benchmarks, GPT-5.5 is ahead. If your work is agentic coding on a budget, choose Claude Opus 4.8. If your work leans on large context windows and web navigation inside the OpenAI ecosystem, choose GPT-5.5. For most teams, the smart move is cost-aware routing — Opus 4.8 for coding and output-heavy steps, GPT-5.5 for web and broad knowledge-work steps. For more detail, see our full reviews of Claude Opus 4.8 and GPT-5.5, and the prior-generation matchup in our Claude Opus 4.7 vs GPT-5.5 comparison.
Our Verdict
Split verdict by category, tilted toward Claude Opus 4.8 on the dimensions we can verify like-for-like. On SWE-bench Pro — the one coding benchmark both vendors report the same way — Anthropic reports 69.2% for Opus 4.8 versus OpenAI's reported 58.6% for GPT-5.5, so Opus 4.8 leads agentic coding by about 10 points, and it is about 17% cheaper on output ($25 versus $30 per million tokens, verified pricing). GPT-5.5 wins on declared context window (1,000,000 tokens versus undeclared) and on published web and economic-value benchmarks (BrowseComp Pro 90.1%, GDPval 84.9%). We did not crown a single overall winner: Terminal-Bench figures were measured on different versions (2.1 versus 2.0) and are not comparable, Anthropic's computer-use lead rests on a single reported figure with no verified GPT-5.5 counterpart, and we ran no controlled head-to-head. Best for agentic coding and output cost: Claude Opus 4.8. Best for large declared context and web tasks: GPT-5.5. All benchmark numbers are vendor-reported and press-relayed; only Opus 4.8 pricing is fetch-verified.
Choose Claude Opus 4.8
Anthropic's flagship model for agentic coding, computer use, and multi-agent orchestration.
Try Claude Opus 4.8 →Choose GPT-5.5
OpenAI's first fully retrained base model since GPT-4.5 — agentic, faster, and double the API price.
Try GPT-5.5 →Frequently Asked Questions
Is Claude Opus 4.8 better than GPT-5.5?
Split verdict by category, tilted toward Claude Opus 4.8 on the dimensions we can verify like-for-like. On SWE-bench Pro — the one coding benchmark both vendors report the same way — Anthropic reports 69.2% for Opus 4.8 versus OpenAI's reported 58.6% for GPT-5.5, so Opus 4.8 leads agentic coding by about 10 points, and it is about 17% cheaper on output ($25 versus $30 per million tokens, verified pricing). GPT-5.5 wins on declared context window (1,000,000 tokens versus undeclared) and on published web and economic-value benchmarks (BrowseComp Pro 90.1%, GDPval 84.9%). We did not crown a single overall winner: Terminal-Bench figures were measured on different versions (2.1 versus 2.0) and are not comparable, Anthropic's computer-use lead rests on a single reported figure with no verified GPT-5.5 counterpart, and we ran no controlled head-to-head. Best for agentic coding and output cost: Claude Opus 4.8. Best for large declared context and web tasks: GPT-5.5. All benchmark numbers are vendor-reported and press-relayed; only Opus 4.8 pricing is fetch-verified.
Which is cheaper, Claude Opus 4.8 or GPT-5.5?
Claude Opus 4.8 is priced at $5 in / $25 out per M tokens. GPT-5.5 is priced at $5 in / $30 out per M tokens. Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Opus 4.8 and GPT-5.5?
The key differences span across 10 features we compared. For API output price (per million tokens), Claude Opus 4.8 offers $25.00 (verified) while GPT-5.5 offers $30.00 (OpenAI reports). For API input price (per million tokens), Claude Opus 4.8 offers $5.00 (verified) while GPT-5.5 offers $5.00 (OpenAI reports). For SWE-bench Pro (agentic coding, like-for-like), Claude Opus 4.8 offers 69.2% (Anthropic reports) while GPT-5.5 offers 58.6% (OpenAI reports). See the full feature comparison table above for all details.