Claude Sonnet 5 vs GPT-5.5: Anthropic Mid-Tier vs OpenAI Flagship (2026)


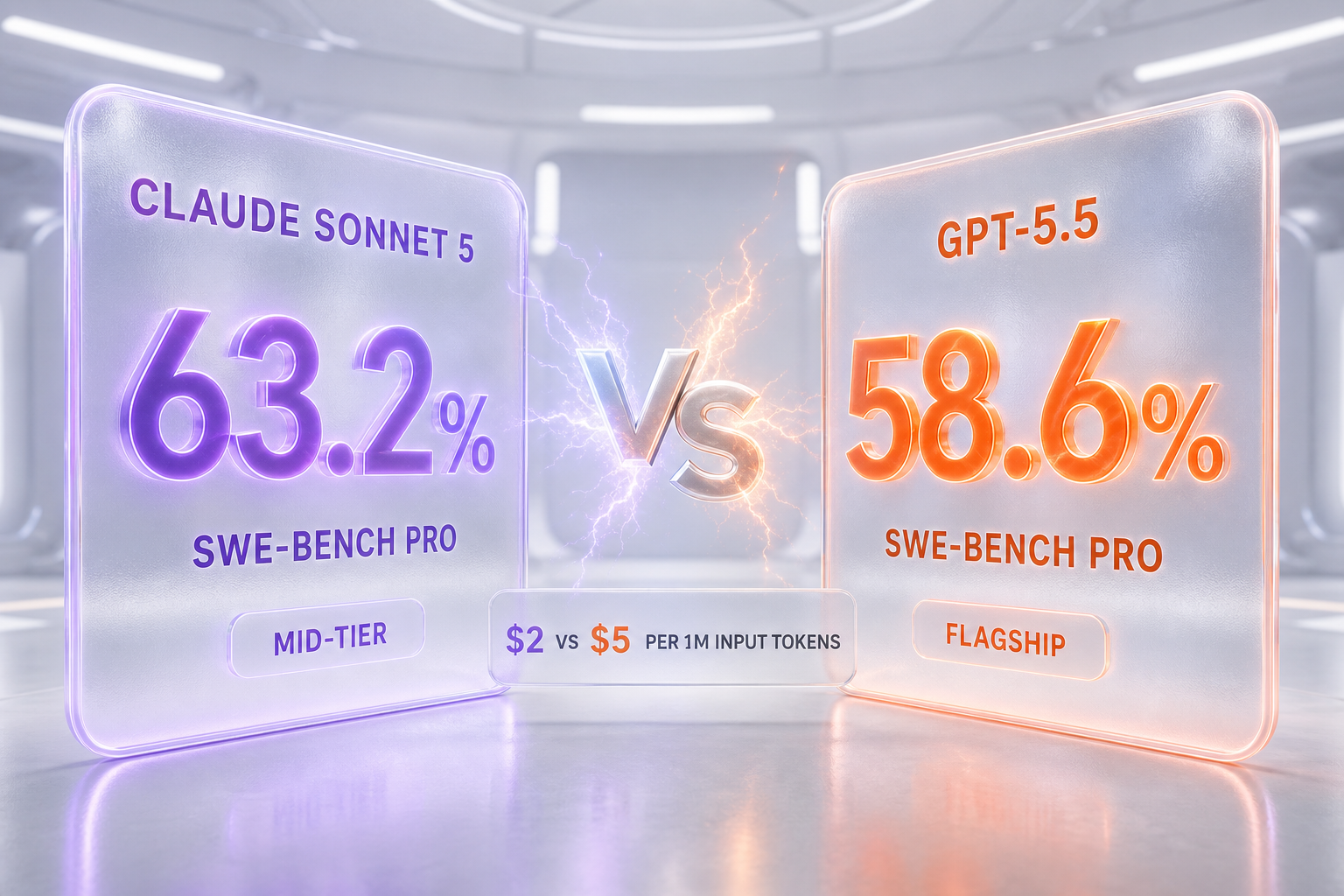
Claude Sonnet 5 leads GPT-5.5 on SWE-bench Pro (63.2% vs 58.6%) and costs less, but GPT-5.5 holds the SWE-bench Verified crown. Our 2026 verdict.
Feature Comparison
| Feature | Claude Sonnet 5 | GPT-5.5 |
|---|---|---|
| SWE-bench Pro (shared coding benchmark) | 63.2% | 58.6% |
| SWE-bench Verified (OpenAI headline) | Not directly compared | 88.7% (ranked #1) |
| Documented computer use / terminal | OSWorld-Verified 81.2% | Terminal-Bench 2.0 82.7% (different test) |
| Input price per 1M tokens | $2 intro / $3 standard | $5.00 |
| Output price per 1M tokens | $10 intro / $15 standard | $30.00 |
| Context window | 1M tokens | 1.05M tokens |
| Reasoning-effort control | Extended thinking | 5-level scale (none to xhigh) |
| Model tier | Anthropic mid-tier (below Opus 4.8) | OpenAI flagship (retrained base) |
| Ecosystem and distribution | Claude Code, default on Claude.ai | ChatGPT, Codex, Responses API, MCP |
Pricing Comparison
Claude Sonnet 5
GPT-5.5
Detailed Comparison
Claude Sonnet 5 and GPT-5.5 are both built for agentic coding, but they sit at opposite ends of their makers' lineups: Sonnet 5 is Anthropic's mid-tier model, while GPT-5.5 is OpenAI's flagship. On the one benchmark we can line up head-to-head on the same scale — SWE-bench Pro — Claude Sonnet 5 leads 63.2% to GPT-5.5's 58.6%, and it costs far less at 2 dollars per million input tokens introductory against GPT-5.5's 5 dollars. GPT-5.5 answers with the SWE-bench Verified crown, an OpenAI-reported 88.7% that ranked first at launch, plus the broader ChatGPT and Codex ecosystem. In short: Sonnet 5 is the better-value pick and wins the shared benchmark; GPT-5.5 wins its own headline benchmark and ecosystem reach.
Quick Verdict
If you want the single sentence: pick Claude Sonnet 5 when value, the one shared coding benchmark, and documented computer use matter most; pick GPT-5.5 when you want the SWE-bench Verified leader, the most granular reasoning control, or you are already living inside the OpenAI ecosystem. This is close, but it has a narrow winner.
On SWE-bench Pro — the only benchmark both models report on the same scale — Sonnet 5 posts 63.2% against GPT-5.5's 58.6%, a 4.6-point edge to the cheaper, mid-tier model. That is the headline surprise here: Anthropic's mid-tier Sonnet 5 edges OpenAI's flagship on the harder, contamination-resistant coding benchmark while charging roughly half to a third of the price. GPT-5.5 is not beaten across the board, though. It holds the SWE-bench Verified crown at an OpenAI-reported 88.7% (first place at launch), topped the Artificial Analysis Intelligence Index, exposes a five-level reasoning-effort scale no Claude model matches, and reaches far more users through ChatGPT and Codex. So the two lead on different coding benchmarks, and price plus positioning become the tiebreaker.
- Best shared-benchmark coding: Claude Sonnet 5 (63.2% vs 58.6% on SWE-bench Pro)
- Best headline benchmark: GPT-5.5 (88.7% on SWE-bench Verified, ranked first at launch — a different test we do not line up against Pro)
- Best price and value: Claude Sonnet 5 (2 dollars input and 10 dollars output per million tokens introductory, against GPT-5.5's 5 dollars and 30 dollars)
- Best documented computer use: Claude Sonnet 5 (81.2% on OSWorld-Verified, which GPT-5.5 does not report)
- Best reasoning control and ecosystem: GPT-5.5 (five-level effort scale, ChatGPT, ChatGPT's Codex, Responses API, MCP)
- Narrow overall winner: Claude Sonnet 5 — it wins the shared benchmark and price as a mid-tier model against a flagship, so it is the better buy for most teams
How We Compared Them
Honesty first. We have limited first-day hands-on time with Claude Sonnet 5, which launched on June 30, 2026, and our assessment of GPT-5.5 is research-led — we have not run GPT-5.5 as a daily production driver at ThePlanetTools. So this is not a "we ran both side by side for a month" piece. It is a structured comparison built on each vendor's published benchmarks and pricing pages, the public SWE-bench Pro leaderboard, and the limited hands-on signal we have on the Anthropic side.
Two rules shaped the numbers below. First, we place two figures head to head only when both models are measured on the same benchmark and the same scale. That matters more than usual here, because the two vendors lead with different coding benchmarks. GPT-5.5's headline number is SWE-bench Verified (an OpenAI-reported 88.7%, first place at launch), while our locked Claude Sonnet 5 figures center on SWE-bench Pro and OSWorld-Verified. SWE-bench Pro and SWE-bench Verified are not the same test — Pro is the newer, harder, contamination-resistant version — so we never mix a Verified score against a Pro score. In practice, the one clean side-by-side capability number is SWE-bench Pro: 63.2% for Sonnet 5 (Anthropic's system card) against 58.6% for GPT-5.5 (the SWE-bench Pro leaderboard, where GPT-5.5 sits just below Claude Opus 4.7's 64.3% and well under Claude Opus 4.8's 69.2%). Both are best-available figures, not a referee's independent rerun, so read the 4.6-point gap as each side's own measured number rather than a neutral scorecard.
Second, we verified pricing directly from each vendor's own pricing documentation rather than from search snippets — OpenAI's developer pricing page for GPT-5.5 and Anthropic's API pricing for Sonnet 5 — and confirmed both were current at the time of writing. Where a benchmark exists for only one model — GPT-5.5's 88.7% SWE-bench Verified, its 82.7% on Terminal-Bench 2.0, and 93.6% on GPQA Diamond, or Sonnet 5's 81.2% on OSWorld-Verified — we describe it as single-sided and refuse to invent a matching number for the other side. Sonnet 5's OSWorld-Verified and GPT-5.5's Terminal-Bench 2.0 both touch "agentic" work, but they are different tests (one is graphical computer use, the other command-line workflows), so we report each on its own rather than pretending they are comparable. That keeps the comparison defensible rather than tidy.
Meet Both Models
Claude Sonnet 5 — Anthropic's mid-tier workhorse
Claude Sonnet 5 is Anthropic's mid-tier model, released June 30, 2026, and described by Anthropic as its most agentic midsize model — built to plan, drive browsers and terminals, and run across multi-step tasks. It sits below the Claude Opus 4.8 flagship and replaces Claude Sonnet 4.6 as the default workhorse. Its headline is agentic performance at a mid-tier price: 63.2% on SWE-bench Pro, about 91% of Opus 4.8's 69.2%, and 81.2% on OSWorld-Verified for computer use. It is closed — you reach it through the Claude API (model id claude-sonnet-5), inside Claude Code, and as the default model on the free and Pro plans of Claude.ai. That last point matters for evaluation: the same model powering production agents is the one a free user chats with in the browser, so you can try the exact model before spending on the API. Its introductory price of 2 dollars per million input tokens and 10 dollars output runs through August 2026, then steps up to 3 dollars and 15 dollars on September 1, 2026.
GPT-5.5 — OpenAI's flagship, retrained from the ground up
GPT-5.5 is OpenAI's flagship general-purpose model, released April 23, 2026, and positioned as the first fully retrained base model since GPT-4.5 rather than another post-training iteration. That rebuild shows up in the launch numbers: OpenAI led with an 88.7% score on SWE-bench Verified — first place on that board — and GPT-5.5 climbed to the top tier of the Artificial Analysis Intelligence Index within a day of release. It also reports 82.7% on Terminal-Bench 2.0 (state of the art for command-line agentic workflows) and 93.6% on GPQA Diamond. It ships a 1,050,000-token context window, text-and-vision input with text output, and a distinctive five-level reasoning-effort scale (none, low, medium, high, xhigh) that gives developers finer cost-versus-depth control than any Claude model. Distribution is its other strength: GPT-5.5 powers ChatGPT across paid tiers, is built into Codex on every plan (with a 400,000-token context there), and is available through the Responses API and Chat Completions API with MCP tool support. Pricing is flagship-tier: 5 dollars per million input tokens, 0.50 dollars cached, and 30 dollars output, with a premium GPT-5.5 Pro variant priced far higher for the hardest reasoning.
Head-to-Head at a Glance
| Dimension | Claude Sonnet 5 | GPT-5.5 | Edge |
|---|---|---|---|
| SWE-bench Pro (shared benchmark) | 63.2% | 58.6% | Sonnet 5 (+4.6) |
| SWE-bench Verified (OpenAI headline) | Not directly compared | 88.7% (ranked #1) | GPT-5.5 |
| Documented computer use / terminal | OSWorld-Verified 81.2% | Terminal-Bench 2.0 82.7% | Different tests |
| Input price per 1M tokens | $2 intro / $3 standard | $5.00 | Sonnet 5 |
| Output price per 1M tokens | $10 intro / $15 standard | $30.00 | Sonnet 5 |
| Context window | 1M tokens | 1.05M tokens | Near tie |
| Reasoning-effort control | Extended thinking | 5-level scale (none to xhigh) | GPT-5.5 |
| Model tier | Anthropic mid-tier (below Opus 4.8) | OpenAI flagship (retrained base) | Context |
| Ecosystem and distribution | Claude Code, default on Claude.ai | ChatGPT, Codex, Responses API, MCP | GPT-5.5 |
The table splits about evenly, and that is the point. Sonnet 5 takes the shared coding benchmark, computer use, and both price rows; GPT-5.5 takes its own headline benchmark, reasoning-effort granularity, and ecosystem reach. The two near-tie on context window and model quality overall. Which column of "edge" matters more depends entirely on how you weigh a mid-tier price against a flagship's headline number and distribution.
Capability: What the Benchmarks Actually Say
The cleanest capability signal is SWE-bench Pro, the coding-agent benchmark both models appear on at the same scale. Anthropic's system card puts Sonnet 5 at 63.2%; the SWE-bench Pro leaderboard lists GPT-5.5 at 58.6%. The 4.6-point gap favors Sonnet 5 and is the widest apples-to-apples capability difference we could establish. Two caveats keep it honest. Both numbers are best-available figures we have not independently reproduced, so this is each side's own measured result rather than a neutral referee's. And a few points on a single benchmark rarely decide a real production choice on their own — throughput, reliability under load, and cost usually matter more once you are past the demo. Still, the direction is clear and a little surprising: on the harder, contamination-resistant coding benchmark, the mid-tier Claude model edges the OpenAI flagship.
GPT-5.5's strongest single claim is a different benchmark. OpenAI led its launch with an 88.7% score on SWE-bench Verified, taking first place on that board (ahead of the prior leader, Claude Opus 4.8). SWE-bench Verified is the more established, more saturated coding test, and 88.7% is near the top of it. We do not place a Sonnet 5 number beside it, because our locked Sonnet 5 benchmark set centers on SWE-bench Pro and OSWorld rather than Verified, and lining up two different benchmarks would be exactly the mixing we avoid. So treat GPT-5.5's Verified crown as a genuine, single-sided strength: it leads the field on the standard coding benchmark, even as it trails Sonnet 5 on the harder Pro variant. Reasonable engineers weight these two benchmarks differently, which is why "who is better at coding" honestly depends on which test you trust.
On computer use, the two again describe different tests. Sonnet 5 reports 81.2% on OSWorld-Verified, the benchmark that measures whether a model can operate real graphical software — clicking through dashboards, filling forms, extracting data from interfaces without an API. GPT-5.5 does not report an OSWorld-Verified figure; its comparable agentic number is Terminal-Bench 2.0 at 82.7%, a state-of-the-art result on command-line workflows. Because OSWorld (graphical) and Terminal-Bench (command-line) are not the same test, we do not line up 81.2% against 82.7% as a head-to-head. What we can say is that each model brings a documented, strong agentic number in its own lane — Sonnet 5 for graphical computer use, GPT-5.5 for terminal workflows. GPT-5.5 rounds out its single-sided suite with 93.6% on GPQA Diamond graduate-science reasoning. The takeaway: on the one clean shared benchmark, Sonnet 5 is ahead by a real but modest margin, while GPT-5.5 owns the standard Verified board and the broader benchmark spread.
Pricing: Where Claude Sonnet 5 Pulls Ahead
Price is the axis where these two diverge most, and it is Sonnet 5's strongest argument — a role reversal from Anthropic's flagship comparisons, where Claude usually costs more. Here the mid-tier Claude model is decisively cheaper than the OpenAI flagship. We verified both directly from vendor pricing pages.
| Cost dimension | Claude Sonnet 5 | GPT-5.5 |
|---|---|---|
| Input per 1M tokens | $2 introductory, $3 standard from September 1, 2026 | $5.00 |
| Cached input per 1M tokens | $0.20 introductory, $0.30 standard | $0.50 |
| Output per 1M tokens | $10 introductory, $15 standard | $30.00 |
| Long-context surcharge | None published at standard rate | Above 272K tokens: $10 input, $45 output per 1M |
| Batch / discount mode | Default model free on Claude.ai | Batch mode: $2.50 input, $15 output per 1M (50% off) |
Read the raw rates and Sonnet 5 undercuts GPT-5.5 by roughly two and a half times on input (2 dollars against 5 dollars) and three times on output (10 dollars against 30 dollars) during its introductory window. Even after Sonnet 5 steps up to standard pricing on September 1, 2026, it stays cheaper by about 1.7 times on input (3 dollars against 5 dollars) and two times on output (15 dollars against 30 dollars). GPT-5.5 also carries a long-context surcharge that Sonnet 5 does not advertise: prompts above 272,000 input tokens are billed at 10 dollars input and 45 dollars output per million, which materially changes the math on very large agentic runs. GPT-5.5 can close some of the gap with Batch mode, which halves its rate to 2.50 dollars input and 15 dollars output — but Batch is asynchronous, so it suits overnight pipelines rather than interactive agents.
Two honesty notes keep this from being a pure rout. First, cross-vendor token pricing is not perfectly one-to-one, because OpenAI and Anthropic use different tokenizers, so the real cost difference on your actual workload may not track the headline per-token ratio exactly — you should measure on your own prompts. Second, GPT-5.5 is a flagship and Sonnet 5 is a mid-tier model, so part of the price gap reflects a genuine tier difference in positioning, not pure inefficiency on OpenAI's side; if your workload specifically needs the SWE-bench Verified leader or the deepest reasoning effort, you are paying for a different product. Sonnet 5 still wins the price axis clearly, but "clearly" is not "for free."
Positioning, Reasoning Control, and Ecosystem
Capability and price are only part of the decision; where each model sits in its maker's lineup shapes the rest. Sonnet 5 is deliberately a mid-tier model — Anthropic reserves the top slice of hard, safety-sensitive work for Claude Opus 4.8 and positions Sonnet 5 as the high-volume default beneath it. GPT-5.5, by contrast, is OpenAI's flagship, the first fully retrained base since GPT-4.5, with a premium GPT-5.5 Pro variant above it for the hardest reasoning. So the honest framing is asymmetric: Sonnet 5 is punching above its tier on the shared benchmark and price, while GPT-5.5 carries flagship expectations — and the headline Verified score and Intelligence Index ranking to back them.
On reasoning control, GPT-5.5 has the more granular tooling. Its five-level effort scale (none, low, medium, high, xhigh) lets developers dial cost against depth per call, which is finer control than Sonnet 5's on-or-off extended thinking. That granularity is genuinely useful for cost-tuning long agent runs. On distribution, GPT-5.5's reach is broader: it powers ChatGPT across paid tiers, is embedded in Codex on every plan, and exposes the Responses API, Chat Completions API, and MCP tool support. Sonnet 5 answers with a tight, mature developer ecosystem of its own — Claude Code, the same Messages API and SDKs as prior Claude models (so adoption is a one-line model-string change), and default availability on Claude.ai's free and Pro plans, which shortens evaluation because non-technical stakeholders can try the exact production model in the browser. Both come with published documentation and system cards; neither has a jurisdiction or moderation asterisk of the kind that separates Western and non-Western labs. If ecosystem breadth and reasoning-effort granularity are your priorities, GPT-5.5 leads; if a lean migration path and free in-browser evaluation matter more, Sonnet 5 holds its own.
Multimodal Input and Vision
The two are close on multimodal input. Both accept text and image input — screenshots, diagrams, charts, and document pages — and both produce text output; neither ships native audio or video generation on these base models. For Sonnet 5, that vision path is load-bearing for its computer-use loop: parse a dashboard screenshot into structured data, then decide the next click, which ties directly to its 81.2% OSWorld-Verified result. GPT-5.5's vision reportedly improved on chart and diagram comprehension over prior OpenAI models, which supports its agentic and terminal work. For a screenshot-to-code or design-to-code workflow, both are set up to compete, and without running them on identical multimodal tasks we will not rank fidelity. The practical read: multimodal input is close to parity, and your choice should hinge on the coding, price, and ecosystem axes above rather than on vision.
Winner by Category
Best shared-benchmark coding: Claude Sonnet 5
On the one clean shared benchmark, Sonnet 5's 63.2% beats GPT-5.5's 58.6% on SWE-bench Pro, the harder, contamination-resistant coding test. If your priority is the best documented result on the benchmark where these two actually meet, Sonnet 5 has the edge — and it does it as a mid-tier model.
Best headline benchmark: GPT-5.5
GPT-5.5's 88.7% on SWE-bench Verified took first place on that board at launch, ahead of Claude Opus 4.8. Verified is the more standard coding benchmark, and GPT-5.5 leads it. We keep this separate from the Pro result rather than mixing the two, but on its own board GPT-5.5 is the champion.
Best price and value: Claude Sonnet 5
At 2 dollars input and 10 dollars output per million tokens introductory — roughly half to a third of GPT-5.5's 5 dollars and 30 dollars, and still cheaper at standard pricing — Sonnet 5 is decisively the better value, with no long-context surcharge to watch. For high-volume agentic workloads, this is the axis that most often decides the bill.
Best documented computer use: Claude Sonnet 5
Sonnet 5 publishes an 81.2% OSWorld-Verified score for graphical computer use, the test that measures operating real software without an API. GPT-5.5 reports strong terminal-agent numbers instead (82.7% on Terminal-Bench 2.0) but no OSWorld figure, so for documented graphical computer use Sonnet 5 is the safer, measured choice.
Best reasoning control and ecosystem: GPT-5.5
GPT-5.5's five-level reasoning-effort scale is the most granular cost-versus-depth control of the two, and its distribution through ChatGPT, Codex, the Responses API, and MCP reaches far more surfaces than Sonnet 5. If effort granularity and ecosystem breadth are central to your build, GPT-5.5 wins here.
Narrow overall winner: Claude Sonnet 5
Because Sonnet 5 wins the one shared benchmark, wins documented computer use, and wins price — all while being a mid-tier model against a flagship — it is the narrow overall pick for most teams. But it is narrow on purpose: if your priority is the SWE-bench Verified leader, the deepest reasoning-effort control, or the OpenAI ecosystem, GPT-5.5 is the rational choice without hesitation.
Pros and Cons of Each
Claude Sonnet 5
What stands out:
- Wins the one shared coding benchmark: 63.2% SWE-bench Pro against GPT-5.5's 58.6%, as a mid-tier model against a flagship
- Decisively cheaper: 2 dollars input and 10 dollars output per million tokens introductory, roughly half to a third of GPT-5.5, with no long-context surcharge
- Documented 81.2% OSWorld-Verified computer-use score for driving real graphical software
- Free to evaluate as the default model on Claude.ai's free and Pro plans before any API spend
- Lean migration: same Messages API and SDKs as prior Claude, so adoption is a one-line model-string change, plus Claude Code integration
Where it falls short:
- Does not hold the standard SWE-bench Verified crown — GPT-5.5 leads that board at 88.7%
- On-or-off extended thinking is less granular than GPT-5.5's five-level effort scale
- Introductory pricing rises to 3 dollars input and 15 dollars output on September 1, 2026
- Brand new (June 30, 2026 launch), so its long-run independent track record is still thin
- Smaller distribution surface than ChatGPT and Codex
GPT-5.5
What stands out:
- Holds the SWE-bench Verified crown at an OpenAI-reported 88.7%, first place at launch, and topped the Artificial Analysis Intelligence Index
- First fully retrained base since GPT-4.5 — a ground-up foundation, plus 82.7% on Terminal-Bench 2.0 and 93.6% on GPQA Diamond
- Five-level reasoning-effort scale (none to xhigh) — the most granular cost-versus-depth control of the two
- Broadest distribution: ChatGPT across tiers, Codex on every plan, Responses API, and MCP tool support
- Slightly larger 1.05M-token context window and Batch mode that halves API cost for overnight workloads
Where it falls short:
- Trails Sonnet 5 by 4.6 points on the harder SWE-bench Pro benchmark (58.6% vs 63.2%)
- Roughly two to three times more expensive per token than Sonnet 5, before any Batch discount
- Long-context surcharge above 272K tokens (10 dollars input, 45 dollars output per million) can surprise large agentic runs
- Publishes no OSWorld-Verified graphical computer-use score to match Sonnet 5's 81.2%
- Flagship-tier pricing means the premium GPT-5.5 Pro variant costs far more again for the hardest reasoning
When to Pick Which
Pick Claude Sonnet 5 if...
You want the best value in agentic coding and you trust the harder SWE-bench Pro benchmark. Sonnet 5 is the stronger default when your model bill is a real constraint, when you run high-volume coding or research agents where a two-to-three-times token-cost difference compounds into serious money, when documented graphical computer use (OSWorld) is central to your product, or when a lean migration path and free in-browser evaluation on Claude.ai shorten your rollout. It is also the pragmatic pick during the introductory pricing window through August 2026, when the gap to GPT-5.5's rate is at its widest. Reach up to Claude Opus 4.8 only for the hardest, most safety-sensitive slice above Sonnet 5.
Pick GPT-5.5 if...
You want the SWE-bench Verified leader, the most granular reasoning control, or you are already building on the OpenAI stack. GPT-5.5 is the better choice when the standard Verified benchmark and the Intelligence Index ranking are what you optimize for, when the five-level effort scale lets you tune cost against depth per call, when your workflow lives inside ChatGPT, Codex, or the Responses API with MCP tools, or when you need a flagship-positioned model with a premium Pro variant available above it. The caveats to weigh first: you will pay roughly two to three times more per token than Sonnet 5, and you should watch the long-context surcharge above 272,000 tokens. If those do not block you, the ecosystem and headline benchmark are strong reasons to stay.
Or consider a split stack
The two are not mutually exclusive. A common 2026 pattern is to route work by benchmark trust and budget: run Sonnet 5 for high-volume, cost-sensitive coding and computer-use execution where its Pro-benchmark edge and lower price earn their keep, and GPT-5.5 where the Verified-leading model, the reasoning-effort granularity, or the OpenAI ecosystem integration matter most. If you want to see how each stacks up against neighboring flagships, our Claude Opus 4.8 vs GPT-5.5, Claude Fable 5 vs GPT-5.5, and Kimi K2.7 vs GPT-5.5 comparisons cover the surrounding matchups.
Frequently Asked Questions
Is Claude Sonnet 5 or GPT-5.5 better for coding?
It depends on which benchmark you trust. On SWE-bench Pro, the harder and contamination-resistant test both models appear on at the same scale, Claude Sonnet 5 leads 63.2% to GPT-5.5's 58.6%, a 4.6-point edge. On SWE-bench Verified, the more standard test, GPT-5.5 leads with an OpenAI-reported 88.7% (first place at launch). We keep those two benchmarks separate rather than mixing them. For most value-conscious coding, Sonnet 5's shared-benchmark win plus lower price makes it the better practical choice; for the standard Verified crown and reasoning granularity, GPT-5.5 leads.
How much cheaper is Claude Sonnet 5 than GPT-5.5?
Claude Sonnet 5 charges 2 dollars per million input tokens and 10 dollars output introductory through August 31, 2026, then 3 dollars and 15 dollars from September 1, 2026. GPT-5.5 charges 5 dollars input, 0.50 dollars cached, and 30 dollars output per million tokens. So Sonnet 5 is roughly two and a half times cheaper on input and three times cheaper on output during its introductory window, narrowing to about 1.7 times and two times once it hits standard pricing. GPT-5.5's Batch mode can halve its rate to 2.50 dollars and 15 dollars for asynchronous workloads.
Why does GPT-5.5 win SWE-bench Verified but lose SWE-bench Pro?
They are different benchmarks. SWE-bench Verified is the established, more saturated coding test, where GPT-5.5 reports 88.7% and ranks first. SWE-bench Pro is a newer, harder, contamination-resistant version, where Claude Sonnet 5 reports 63.2% against GPT-5.5's 58.6%. A model can lead one and trail the other, which is exactly what happens here. We never place a Verified score against a Pro score, because they measure different things on different scales.
What is GPT-5.5's SWE-bench Pro score?
GPT-5.5 scores 58.6% on SWE-bench Pro according to the SWE-bench Pro leaderboard, where it sits just below Claude Opus 4.7's 64.3% and well under Claude Opus 4.8's 69.2%. Claude Sonnet 5 reports 63.2% on the same benchmark from Anthropic's system card, a 4.6-point lead. Both are best-available figures, not independently reproduced by our team.
Which model has the larger context window?
They are effectively tied. GPT-5.5 supports a 1,050,000-token context window, and Claude Sonnet 5 supports 1,000,000 tokens — a difference of about 5%, which almost never matters in practice. For very large multi-repository code or document analysis, GPT-5.5's marginally larger window is a slight edge, but both comfortably handle long agentic contexts.
Is Claude Sonnet 5 a flagship model like GPT-5.5?
No. Claude Sonnet 5 is Anthropic's mid-tier model, positioned below the Claude Opus 4.8 flagship as a high-volume default. GPT-5.5 is OpenAI's flagship, the first fully retrained base since GPT-4.5, with a premium GPT-5.5 Pro variant above it. That asymmetry is part of the story: Sonnet 5 edges the OpenAI flagship on the shared SWE-bench Pro benchmark and on price despite being a mid-tier model.
Does either model do computer use or browser automation?
Both target agentic work, but they publish different benchmarks. Claude Sonnet 5 reports 81.2% on OSWorld-Verified, the test for operating real graphical software — clicking dashboards, filling forms, extracting data without an API. GPT-5.5 reports 82.7% on Terminal-Bench 2.0 for command-line agentic workflows but does not publish an OSWorld figure. Because those are different tests, we do not compare the two scores directly. For documented graphical computer use, Sonnet 5 is the measured choice.
What reasoning controls does each model offer?
GPT-5.5 exposes a five-level reasoning-effort scale — none, low, medium, high, and xhigh — letting developers tune cost against depth per API call. Claude Sonnet 5 offers extended thinking, which is closer to an on-or-off control with a thinking budget. GPT-5.5's ladder is the more granular of the two, which is useful for cost-tuning long agent runs, though many teams settle at a medium setting for routine work with either model.
Does GPT-5.5 have a long-context pricing surcharge?
Yes. On OpenAI's pricing page, GPT-5.5 prompts above 272,000 input tokens are billed at a long-context rate of 10 dollars input and 45 dollars output per million tokens, double the standard input rate and 1.5 times the output rate. Claude Sonnet 5 does not advertise an equivalent surcharge at its standard rate. For very large agentic runs that cross that threshold, the surcharge meaningfully changes GPT-5.5's effective cost.
Are both models multimodal?
Both accept text and image input and produce text output. Neither of these base models generates native audio or video. Claude Sonnet 5's vision path feeds its computer-use loop (reading a dashboard screenshot, then acting), and GPT-5.5's vision reportedly improved on chart and diagram comprehension. On multimodal input the two are close to parity, so the decision usually comes down to coding benchmarks, price, and ecosystem rather than vision.
Should I switch from GPT-5.5 to Claude Sonnet 5 to save money?
Only after measuring on your own workload. Sonnet 5's per-token price is clearly lower — roughly half to a third of GPT-5.5 — and it wins the shared SWE-bench Pro benchmark, so for high-volume coding agents the savings and the benchmark both point its way. But you would be giving up GPT-5.5's SWE-bench Verified crown, its five-level reasoning-effort control, and the ChatGPT and Codex ecosystem. Cross-vendor tokenizers also make headline per-token ratios only an approximation, so run a representative evaluation on both before committing.
Which model is the better overall pick in 2026?
For most teams, Claude Sonnet 5 is the narrow overall pick: it wins the one shared benchmark (SWE-bench Pro), wins documented computer use, and wins price, all as a mid-tier model against a flagship. GPT-5.5 is the better pick when you specifically want the SWE-bench Verified leader, the deepest reasoning-effort control, or the OpenAI ecosystem. Neither is universally better — the two lead on different coding benchmarks, so your priorities and budget decide it.
Final Verdict

This comparison is close, and pretending it is a blowout would be dishonest. Claude Sonnet 5 is the narrow overall pick, and the reason is genuinely striking: Anthropic's mid-tier model edges OpenAI's flagship on the one benchmark both report on the same scale — SWE-bench Pro, 63.2% to 58.6% — while charging roughly half to a third of the price and publishing a documented computer-use score GPT-5.5 does not match. If your decision hinges on getting the best value in agentic coding from a model that leads the harder shared benchmark, Sonnet 5 is the answer.
But GPT-5.5 is not beaten across the board, and it holds the crown that most buyers recognize. Its 88.7% on SWE-bench Verified led that board at launch, it topped the Artificial Analysis Intelligence Index, it exposes a five-level reasoning-effort scale no Claude model matches, and it reaches far more users through ChatGPT and Codex. The two lead on different coding benchmarks — Verified for GPT-5.5, Pro for Sonnet 5 — so the honest question is which test you trust and how much a mid-tier price is worth against a flagship's headline number and distribution. For most teams, the shared-benchmark win plus the price advantage tips it to Sonnet 5; for anyone anchored to the Verified crown, the reasoning granularity, or the OpenAI ecosystem, GPT-5.5 earns every extra dollar. Measure both on your own workload, and let your actual priorities — not a single benchmark headline — make the call.
Last compared: July 2026. Claude Sonnet 5 launched June 30, 2026; GPT-5.5 launched April 23, 2026. Our Sonnet 5 assessment reflects limited first-day hands-on time plus Anthropic's published benchmarks; our GPT-5.5 assessment is research-led, as we have not run it as a production daily driver. Benchmark figures are vendor-reported or from the public SWE-bench Pro leaderboard and not independently reproduced by our team; SWE-bench Pro and SWE-bench Verified are different benchmarks and are never compared against each other. Pricing verified directly from OpenAI's and Anthropic's pricing pages at the time of writing.
Our Verdict
Claude Sonnet 5 is the narrow overall winner and the better value: as Anthropic's mid-tier model it edges OpenAI's flagship GPT-5.5 on the one benchmark both report on the same scale — SWE-bench Pro, 63.2% versus 58.6% — while costing roughly half to a third as much per token and publishing an 81.2% OSWorld-Verified computer-use score GPT-5.5 does not match. GPT-5.5 is not beaten across the board, though: it holds the SWE-bench Verified crown at an OpenAI-reported 88.7% (first place at launch), topped the Artificial Analysis Intelligence Index, and offers a five-level reasoning-effort scale plus the broader ChatGPT and Codex ecosystem. Because the two lead on different coding benchmarks, the decision comes down to which test you trust and whether a mid-tier price outweighs a flagship's headline number: most value-conscious teams should lean Claude Sonnet 5, while teams anchored to the Verified crown, reasoning granularity, or the OpenAI ecosystem should pick GPT-5.5.
Choose Claude Sonnet 5
Anthropic's most agentic midsize model — near-Opus 4.8 coding and computer use at $2 per million input tokens (introductory through August 2026).
Try Claude Sonnet 5 →Choose GPT-5.5
OpenAI's first fully retrained base model since GPT-4.5 — agentic, faster, and double the API price.
Try GPT-5.5 →Frequently Asked Questions
Is Claude Sonnet 5 better than GPT-5.5?
Claude Sonnet 5 is the narrow overall winner and the better value: as Anthropic's mid-tier model it edges OpenAI's flagship GPT-5.5 on the one benchmark both report on the same scale — SWE-bench Pro, 63.2% versus 58.6% — while costing roughly half to a third as much per token and publishing an 81.2% OSWorld-Verified computer-use score GPT-5.5 does not match. GPT-5.5 is not beaten across the board, though: it holds the SWE-bench Verified crown at an OpenAI-reported 88.7% (first place at launch), topped the Artificial Analysis Intelligence Index, and offers a five-level reasoning-effort scale plus the broader ChatGPT and Codex ecosystem. Because the two lead on different coding benchmarks, the decision comes down to which test you trust and whether a mid-tier price outweighs a flagship's headline number: most value-conscious teams should lean Claude Sonnet 5, while teams anchored to the Verified crown, reasoning granularity, or the OpenAI ecosystem should pick GPT-5.5.
Which is cheaper, Claude Sonnet 5 or GPT-5.5?
Claude Sonnet 5 is priced at $2 in / $10 out per M tokens (free plan available). GPT-5.5 is priced at $5 in / $30 out per M tokens. Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Sonnet 5 and GPT-5.5?
The key differences span across 9 features we compared. For SWE-bench Pro (shared coding benchmark), Claude Sonnet 5 offers 63.2% while GPT-5.5 offers 58.6%. For SWE-bench Verified (OpenAI headline), Claude Sonnet 5 offers Not directly compared while GPT-5.5 offers 88.7% (ranked #1). For Documented computer use / terminal, Claude Sonnet 5 offers OSWorld-Verified 81.2% while GPT-5.5 offers Terminal-Bench 2.0 82.7% (different test). See the full feature comparison table above for all details.