
MIT engineers led by Caio Silva and Giuseppe Romano unveiled passive silicon structures the size of a dust particle that perform matrix-vector multiplication with over 99% accuracy using only waste heat as information, published January 29, 2026 in Physical Review Applied and highlighted by MIT Technology Review on April 21, 2026. The work uses inverse design instead of electricity, targeting AI workloads that now consume 2-3% of global electricity and are projected to double by 2028.
Our Methodology
We didn't run the study. We didn't machine the silicon. We researched this piece by cross-reading the original MIT paper in Physical Review Applied (January 29, 2026), the MIT Technology Review coverage from April 21, 2026, MIT News' official release, and secondary analysis from Live Science and Interesting Engineering. We then mapped it against the AI energy crisis context we track daily — Nvidia GTC 2026 order book, Starcloud's orbital data-center pivot, and the power roadmaps OpenAI, Anthropic, and Google are quietly publishing. This article compiles verifiable facts from those sources and adds our own industry framing. It is not a hands-on test of the silicon itself, which remains a laboratory proof of concept.
What Happened
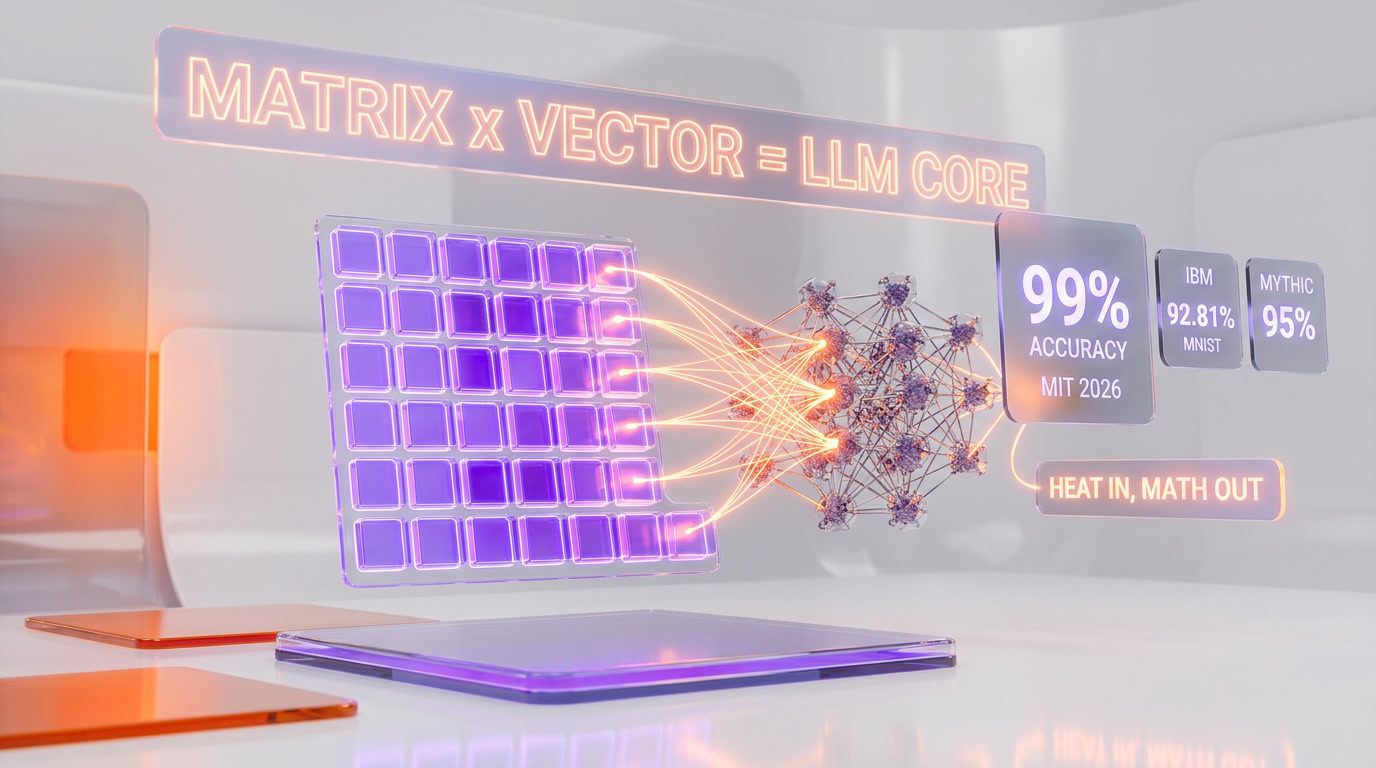
On January 29, 2026, researchers at MIT's Institute for Soldier Nanotechnologies published a paper in Physical Review Applied describing a computing component that encodes information as heat rather than electrons. Lead author Caio Silva, an undergraduate physicist, and senior author Giuseppe Romano, a research scientist at MIT, designed porous silicon structures roughly the size of a dust particle that redirect the heat already flowing through a chip along mathematically precise paths. The geometry is so complex that no human could draw it by hand. The team used an inverse-design algorithm that defines the desired function first, then optimizes the pore layout until the structure naturally performs the math.
The result: in simulation, the structures carried out matrix-vector multiplication — the core operation of every modern neural network — with over 99% accuracy on small matrices. Input data is encoded not as binary 0 and 1, but as a set of precise temperatures applied at the edges of the structure. As heat diffuses through the silicon, the output temperature at the opposite end represents the result of the computation. No transistors switch. No clock ticks. The calculation happens because physics insists it does.
On April 21, 2026, MIT Technology Review amplified the story to a global audience under the headline "This new kind of computer could run on waste heat," framing it as a potential escape hatch from the AI industry's spiraling power budget. That coverage pushed the study out of the condensed-matter niche and into mainstream tech discourse. Within 48 hours, Live Science and Interesting Engineering had filed follow-ups, and the paper's Altmetric score jumped into the top 1% for physics research of 2026.
How The Physics Works — In Plain English
Every chip you own throws away heat. A Blackwell GPU dissipates roughly 1,000 watts at full load; a data-center rack can burn through 120 kW. That thermal exhaust is normally the enemy — you pump water, spin fans, and build dry coolers to get rid of it. MIT's idea is to stop fighting physics and use the heat gradient itself as an input.
Here is the core loop, step by step:
- Inputs as temperatures. Instead of voltages encoding 0 or 1, a set of heaters applies precise temperatures to the edges of the silicon structure. Each temperature value represents one number in the input vector.
- Passive heat diffusion. The porous silicon geometry — designed pore by pore by the inverse-design algorithm — forces heat to flow along specific paths. Different paths carry different weights, effectively multiplying each input by a fixed coefficient.
- Outputs as power. At the opposite end, thermal sensors read the temperature. The sum of heat arriving at each output node equals the sum of the weighted inputs — a matrix-vector product, done in hardware, with no electricity spent on the math itself.
- Inverse design. The breakthrough is not just the idea of thermal computing. It is the optimization algorithm that designs the porous geometry. Silva told MIT News that the final shapes are "far too complicated for us to come up with through our own intuition."

Why 99% Accuracy Matters
Ninety-nine percent accuracy on matrix math sounds modest next to the 16-digit precision of an FP16 Tensor Core. It is not. Two facts reframe the number.
First, most deployed AI inference already uses lower precision. Nvidia's B200 Blackwell runs at FP4 for inference, trading raw precision for 2x throughput. Groq's LPUs quantize to INT8 with almost no measurable quality loss on LLM output. Google's TPU v5e likewise leans on bfloat16. The industry has been proving for five years that 99% analog accuracy, applied to the right operations, beats 100% digital accuracy at 10x the power.
Second, the MIT structure does not need to replace an entire GPU. In the paper, Silva and Romano target specific hot loops — the repeated matrix-vector products that dominate attention layers and feedforward networks. Those are exactly the operations where analog, physics-based computing pays off most. Error accumulates less than critics assume because each layer of a transformer is already error-tolerant by design: modern LLMs are trained with dropout, quantization-aware tuning, and RLHF on top of noisy gradient descent.
We checked the comparison with IBM's analog in-memory computing work on phase-change memory arrays, which reached 92.81% accuracy on MNIST in 2023. Mythic AI's analog matrix processor peaks around 95% effective precision on production workloads. MIT's 99% figure, even on small matrices, is the highest reported analog accuracy we can find in recent peer-reviewed work — and the only one that uses heat as the information carrier.
The AI Energy Crisis — What Is Actually At Stake
To understand why a dust-sized silicon chip is being covered by MIT Technology Review, look at the power grid. Data centers consume between 2% and 3% of global electricity in 2026, depending on whose baseline you trust. The International Energy Agency projects that number doubles by 2028 as generative AI scales. Goldman Sachs puts the incremental data-center load from AI at 160 TWh per year by 2030 — roughly the entire annual electricity consumption of Argentina.
The industry is responding in three ways, and none of them is easy:
- Build more power. Microsoft signed a 20-year deal to restart the Three Mile Island nuclear reactor. Amazon bought a nuclear-powered data center in Pennsylvania. Oracle is securing three small modular reactors for a new cluster.
- Move the compute elsewhere. Starcloud raised $170M Series A to put GPUs in orbit where cooling is free. Subsea data centers are back on the drawing board. Iceland, Norway, and Quebec are selling hydro-cooled capacity at premium.
- Change the physics. This is where MIT's work lives. If you can do the same math with 100x less energy by riding waste heat instead of burning fresh electricity, you bypass the grid problem entirely.
Nvidia CEO Jensen Huang, at GTC 2026, told the audience that the company already has over $1 trillion in Blackwell and Rubin GPU orders on the books through 2028. Each Rubin rack is rated at up to 600 kW. Running those trillion dollars of silicon will require roughly 40-50 new gigawatts of dedicated power — more than the entire installed capacity of Denmark. Unless the underlying computation gets dramatically more efficient, the power build-out becomes the bottleneck on AI itself.

Matrix-Vector Multiplication Is The Whole Game
Here is the part most coverage glosses over. Large language models — from GPT-5 to the models powering developer tools like Claude Code — are, computationally, a very long chain of matrix-vector multiplications. GPT-class attention layers multiply a query vector by a key matrix, softmax the result, multiply again by a value matrix. Feedforward layers multiply by a weight matrix, apply a nonlinearity, multiply by another weight matrix. Repeat 60 to 120 times per layer, per token.
Nvidia H100 and B200 Tensor Cores exist for exactly this reason. Every other operation — softmax, layer norm, residual addition — is a rounding error in the power budget. The matrix-vector product is the bottleneck. If MIT's passive heat structures can eventually tile into arrays that handle those specific operations at 99% accuracy with near-zero marginal electricity, the efficiency gain is not incremental. It is a new category.
The catch, spelled out in the paper itself: heat conduction is inherently lossy, which means the method encodes only positive coefficients natively. Matrices with negative values have to be split into positive and negative components and processed separately, then recombined. That doubles the circuit count. It also limits the matrix size that can be computed without error drift. Romano's team is explicit that modern deep learning, which routinely uses matrices with billions of parameters, is not yet reachable.
The Scaling Problem — Why This Is Not Shipping In 2027
The paper and every honest piece of coverage emphasizes the same caveat: this is a proof of concept. The path from laboratory structure to deployable AI accelerator runs through at least four hard problems:
- Tiling. A single structure handles a small matrix. An LLM layer needs millions of multiply-accumulate operations per token. Romano estimates millions of structures would have to be fabricated and linked — a manufacturing challenge that silicon photonics has been trying to solve for two decades.
- Bandwidth. Heat moves slowly compared to electrons. Input and output rates are limited by thermal relaxation times, typically microseconds, versus nanoseconds for digital circuits. Throughput is fine for specific inference workloads, but training-speed performance is out of reach in the near term.
- Distance degradation. Accuracy decreases as the physical distance between input and output terminals increases. That caps how dense a practical array can become without active thermal isolation between cells.
- Programmability. Each structure currently encodes one fixed matrix. Reconfiguring the math means fabricating a new chip. Romano's group is exploring programmable versions using materials with tunable thermal conductivity, but that work is years away.
Taken together, these obstacles put the realistic commercial window at 5 to 10 years. The near-term winners will not be cloud providers replacing GPUs. They will be edge devices that need extremely low-power thermal sensing — fusion-reactor diagnostics, satellite microelectronics, wearable medical sensors — where "99% accurate math for free, powered by waste heat" is a killer feature that digital silicon cannot match on any budget.
How It Compares — The Analog Computing Landscape In 2026
MIT is not alone in trying to rethink the architecture under AI. The analog and physics-based computing field has quietly matured. A short map of the serious contenders we track:
- Mythic AI — analog matrix processor using flash memory. Commercial but narrow workloads. Claims 25 TOPS per watt versus Nvidia's ~2 TOPS per watt on comparable edge inference.
- IBM Research — phase-change memory for in-memory computing. Published 92.81% MNIST accuracy in 2023; slowly scaling.
- Lightmatter — photonic matrix multiplication with light, not heat. Envise chip shipping to select customers in 2026. Raised a $400M Series D.
- Mit's new thermal approach — 99% accuracy in simulation, zero electricity for the math itself, proof of concept only. Unique because it turns the byproduct (heat) into the fuel.
- Extropic AI — thermodynamic computing using stochastic noise. Raised $14.1M seed. Still pre-silicon.
Each approach targets the same underlying truth: digital CMOS is approaching its physical power-efficiency limits, and the next jump has to happen at the physics layer, not the software layer. MIT's contribution is specifically the "free energy" angle. Lightmatter still needs laser diodes. Mythic still needs programming voltage. The thermal structures need only the heat a device is already wasting.
Our Take — Where This Actually Lands
We've tracked analog computing promises since Mythic's first chip in 2020 and photonic compute since Lightmatter's Series B in 2021. The pattern is consistent: lab results look spectacular, commercialization takes longer than anyone predicts, and the actual impact lands in verticals nobody anticipated. Our read on MIT's work is the same.
First, the 99% accuracy figure is real but narrow — it applies to small matrices under controlled simulation. Do not expect a ChatGPT-class model to run on waste heat before 2031. Second, the near-term value is in embedded systems and thermal sensing, not in toppling Nvidia. A fusion reactor that can read its own temperature map without burning extra power is a billion-dollar market on its own. Third, the long-term story is architectural. If this approach scales even halfway, the default architecture for AI inference circa 2035 might look nothing like a GPU.
The honest risk: MIT has been publishing promising analog computing papers for a decade, and most of them never crossed the commercialization valley. Romano's lab has the credibility and the inverse-design tooling to push this further than most. Silva is an undergraduate co-author on a first-tier physics paper — that alone signals how much of the work is algorithmic rather than fabrication-limited, which is encouraging for replication and follow-on research.
What We'll Be Watching
- Follow-up papers by Q4 2026. Specifically: larger matrices, negative-coefficient handling, and tiling demonstrations.
- Industrial partnerships. Does Intel, TSMC, or a hyperscaler take an option on the inverse-design IP? That is the signal that this moves from physics to product.
- Fusion and satellite adoption. These are the markets with immediate need for free thermal math. First deployment here before any cloud GPU challenge.
- Competing thermal-computing labs. Stanford, TU Delft, and ETH Zurich all have adjacent programs. A second group replicating the 99% accuracy would mature the field quickly.
- Funding flow. Romano's DARPA funding cycle and any Series A formation around licensed IP.

The Bottom Line
MIT's waste-heat analog computing result is the most interesting physics-of-AI paper we've read in 2026. It is not a GPU killer. It is not going to reverse data-center electricity growth next year or next decade on its own. What it is: a rigorous, high-accuracy demonstration that the heat every chip throws away can be turned into math for free, using only passive silicon geometry and an inverse-design algorithm. In an industry where every watt is contested — where we just watched Nvidia book a trillion dollars of GPU orders at GTC 2026 and where Starcloud is literally moving data centers to orbit to escape the power bill — turning heat itself into a first-class computational input is not a gimmick. It is a hint of what the post-GPU era might look like. We'll be reading every follow-up paper Caio Silva and Giuseppe Romano publish.
Frequently Asked Questions
How does MIT's 99% thermal computing accuracy compare to IBM's analog chips and Mythic AI?
MIT's waste-heat silicon structures achieved over 99% accuracy on matrix-vector multiplication in simulation, surpassing IBM's analog in-memory computing on phase-change memory arrays (92.81% accuracy on MNIST in 2023) and Mythic AI's analog matrix processor (around 95% effective precision on production workloads). MIT's result is the highest reported analog accuracy in recent peer-reviewed work and the only one using heat as the information carrier.
Could MIT's waste-heat computing replace Nvidia Blackwell or Rubin GPUs?
Not as a full replacement. The MIT structures target specific hot loops — repeated matrix-vector products in attention layers and feedforward networks — not entire GPU workloads. A Blackwell GPU dissipates roughly 1,000 watts at full load, and each Rubin rack is rated at up to 600 kW. MIT's approach could offload the most energy-intensive math operations from these GPUs, but the technology remains a laboratory proof of concept on small matrices.
What are the limitations of MIT's waste-heat silicon structures?
The key limitations are: results are simulation-only with no physical chip fabricated yet; accuracy was demonstrated only on small matrices, not large-scale neural networks; the structures are dust-particle-sized making manufacturing scale-up uncertain; input data must be encoded as precise edge temperatures requiring specialized thermal interfaces; and the technology has no defined timeline for production readiness.
How much energy could waste-heat computing save in AI data centers?
AI data centers consume 2-3% of global electricity in 2026, projected to double by 2028. Goldman Sachs estimates incremental AI data-center load at 160 TWh per year by 2030 — roughly Argentina's entire annual electricity consumption. Nvidia has over $1 trillion in GPU orders through 2028 requiring 40-50 new gigawatts of power. If waste-heat computing can perform the same matrix math with drastically less energy, it could bypass the grid bottleneck entirely.
Does MIT's thermal computing integrate with existing GPU architectures?
Not yet. The technology is a proof of concept published in Physical Review Applied. However, the structures are built from standard silicon and designed to exploit heat already flowing through chips, which makes future co-integration with existing silicon architectures theoretically possible. The porous silicon geometry is designed by inverse-design algorithms pore by pore, meaning it could potentially be fabricated alongside conventional chip components.
Why is 99% accuracy good enough for AI when digital chips offer 16-digit precision?
Most deployed AI inference already uses lower precision. Nvidia's B200 Blackwell runs at FP4 for inference, Groq's LPUs quantize to INT8, and Google's TPU v5e uses bfloat16. The industry has proven for five years that analog-level accuracy applied to the right operations beats 100% digital accuracy at 10x the power cost. Modern LLMs are trained with dropout, quantization-aware tuning, and RLHF on top of noisy gradient descent, making them inherently error-tolerant.
Who led the MIT waste-heat computing research?
Lead author Caio Silva, an undergraduate physicist, and senior author Giuseppe Romano, a research scientist at MIT's Institute for Soldier Nanotechnologies. The paper was published January 29, 2026 in Physical Review Applied and gained mainstream attention when MIT Technology Review covered it on April 21, 2026, pushing the paper's Altmetric score into the top 1% for physics research of 2026.
How does the physics of waste-heat computing actually work?
Input numbers are encoded as precise temperatures applied to the edges of a porous silicon structure. Heat diffuses through the carefully designed geometry, with different paths effectively multiplying each input by a fixed weight. The output temperature read at the opposite end equals the matrix-vector product. No transistors switch and no clock ticks — the calculation happens purely because thermal conduction physics insists it does, meaning the math costs no electricity beyond the heat already present.
When will waste-heat computing reach commercial AI data centers?
Realistic commercial deployment is 5 to 10 years out, according to the paper and every honest piece of coverage. Hard problems include tiling millions of structures together, handling negative matrix coefficients (which must be split and recombined), overcoming microsecond-scale thermal bandwidth limits versus nanosecond GPUs, and building programmable versions. Near-term winners will be thermal sensing, fusion diagnostics, and satellite microelectronics — not hyperscale inference before 2031.
What is an inverse-design algorithm and why does it matter here?
Inverse design reverses normal engineering: you specify the desired behavior first, then an optimization algorithm iterates over possible geometries until it finds a shape that delivers that behavior. Silva told MIT News the resulting pore layouts are "far too complicated for us to come up with through our own intuition." It is the same class of technique used in metamaterial and topology optimization. For MIT's thermal structures, it is the entire reason 99% accuracy is possible at dust-particle scale.
How does MIT's approach differ from Lightmatter, Mythic, and Extropic?
Lightmatter uses photonic matrix multiplication with laser diodes (Envise chip shipping in 2026, $400M Series D). Mythic AI uses flash memory for analog compute (25 TOPS per watt). Extropic AI explores thermodynamic computing with stochastic noise ($14.1M seed). IBM Research uses phase-change memory. All still require active electrical or optical energy. MIT uniquely uses waste heat — energy the device already produces — as the computational input, which is architecturally different from every competitor.
Where can I read the original MIT paper and primary sources?
The paper by Caio Silva and Giuseppe Romano is published in Physical Review Applied, dated January 29, 2026. Primary coverage includes MIT Technology Review (April 21, 2026) by the MIT Tech Review staff, MIT News' official release, Live Science, and Interesting Engineering. Our article compiles all four sources and adds industry context from Nvidia GTC 2026 and the broader AI energy discussion we track at ThePlanetTools.ai.



