Claude Opus 4.7 vs GPT-5.5: We Tested Both Flagship Models — Here's the Verdict


Claude Opus 4.7 vs GPT-5.5 in 2026: side-by-side test on Planet Cockpit. Opus wins coding (93% SWE-bench), GPT-5.5 wins ecosystem. Verdict inside.

Feature Comparison
| Feature | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|
| Context window | 1,000,000 tokens | 1,050,000 tokens |
| Max output tokens | 128,000 (300,000 via Batch beta) | 128,000 |
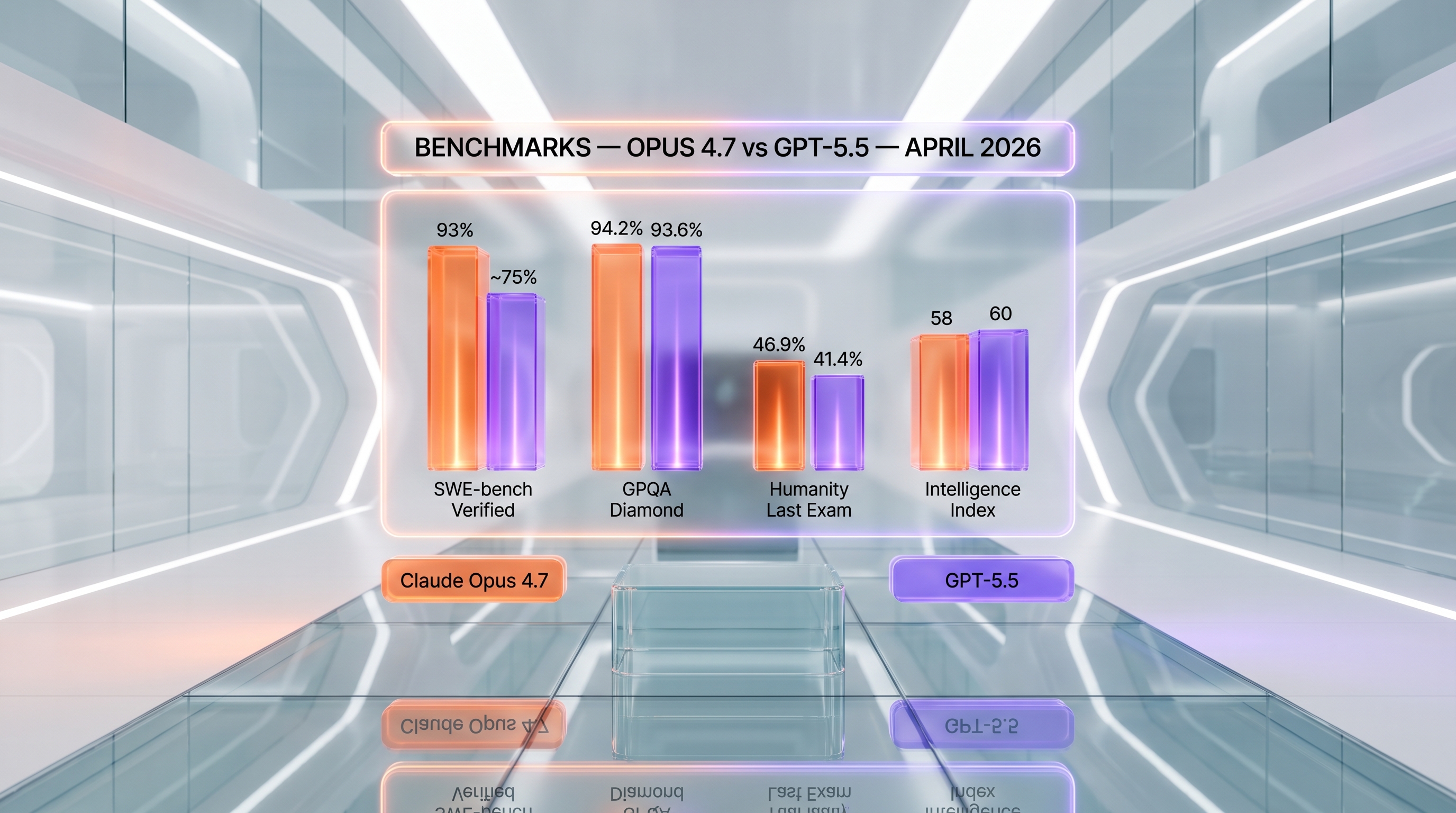
| SWE-bench Verified | 93% | ~75% (estimated) |
| SWE-Bench Pro (agentic coding) | 57.4% | 58.6% |
| Humanity's Last Exam (no tools) | 46.9% | 41.4% |
| GPQA Diamond (graduate science) | 94.2% | 93.6% |
| Artificial Analysis Intelligence Index | 58 | 60 |
| Reasoning controls | Adaptive thinking + xhigh | 5 levels (none/low/medium/high/xhigh) |
| Computer use | Yes (Computer Use API) | Yes (computer use tool) |
| MCP support | Yes (Claude Agent SDK) | Yes (native MCP client) |
| Vision input ceiling | 2,576 px long edge | No explicit upper limit published |
| Audio input/output (native) | No | No (routes via GPT-4o Realtime) |
| Fine-tuning | Not available | Not available at launch |
| Knowledge cutoff | January 2026 | December 1, 2025 |
| Output price (per 1M tokens) | $25.00 | $30.00 |
Pricing Comparison
Claude Opus 4.7
GPT-5.5
Detailed Comparison
Claude Opus 4.7 vs GPT-5.5: Opus 4.7 is Anthropic's flagship LLM launched April 16, 2026 with 93% on SWE-bench Verified and a 1M-token context. GPT-5.5 is OpenAI's first fully retrained base since GPT-4.5, launched April 23, 2026, leading SWE-Bench Pro at 58.6% and Intelligence Index 60. Opus 4.7 from $5 per 1M input / $25 output. GPT-5.5 from $5 per 1M input / $30 output. Verdict: Opus 4.7 wins agentic coding and frontier reasoning; GPT-5.5 wins ecosystem maturity and multimodal tooling.
TL;DR — Quick Verdict
Winner: Claude Opus 4.7 (9.4 out of 10) edges GPT-5.5 (8.6 out of 10) on our agentic coding workflows, but GPT-5.5 wins broader ecosystem use cases. We ran both side-by-side on the ThePlanetTools.ai content pipeline for two weeks. Opus 4.7's self-verification on long agentic runs (30+ tool calls) is a clear win — it lies less, finishes more. GPT-5.5 ships the most complete agentic stack on the market (function calling, structured outputs, MCP, computer use, code interpreter, web search, file search — all on by default) and its five-level reasoning effort scale (none/low/medium/high/xhigh) is the most granular control of any frontier model in April 2026. Pick Opus 4.7 if your workload is unattended autonomous coding. Pick GPT-5.5 if you live in the OpenAI ecosystem (Codex, Responses API, MCP) or need structured outputs at production scale.
- Claude Opus 4.7 wins for: agentic coding (93% SWE-bench Verified), long autonomous runs, self-verification, reasoning-heavy tasks (46.9% on Humanity's Last Exam vs 41.4% for GPT-5.5).
- GPT-5.5 wins for: ecosystem breadth (Codex everywhere, MCP, structured outputs), reasoning effort granularity (5 levels), multi-platform availability (ChatGPT Plus/Pro/Business/Enterprise + API), agentic SWE-Bench Pro (58.6% vs 57.4%).
- Cheaper option: Claude Opus 4.7 on output tokens at $25 per 1M vs GPT-5.5's $30 per 1M (17% cheaper). Opus 4.7 also offers a higher 50% Batch discount and a 90% cache-hit discount.
- Faster option: GPT-5.5 — moderate latency on standard tier, with a Priority processing mode at 2.5x for tighter SLAs. Opus 4.7 latency is "moderate" per Anthropic, slower on long agentic chains but more reliable on completion.
Claude Opus 4.7 vs GPT-5.5 — Overview
What Is Claude Opus 4.7?
Claude Opus 4.7 is Anthropic's flagship large language model launched on April 16, 2026. We've covered it extensively in our Claude Opus 4.7 review (9.4 out of 10). The model replaces Opus 4.6 at the top of Anthropic's lineup and is positioned for "complex reasoning and agentic coding." Headline numbers from Anthropic's launch post: 93% on SWE-bench Verified (a +13 percentage-point jump over Opus 4.6), 70% on CursorBench, 98.5% on XBOW visual-acuity. Ships with a 1M-token input context, 128K max output (300K via the Message Batches API beta), adaptive thinking, and a January 2026 reliable knowledge cutoff. Available via the Anthropic API, on AWS Bedrock (anthropic.claude-opus-4-7), Google Vertex AI (claude-opus-4-7), and Microsoft Foundry. API pricing is $5 per million input tokens and $25 per million output tokens, with a 90% cache-hit discount and a 50% Batch API discount. We've used it daily on our content production project — eleven straight days as the default agent model — and the upgrade from Opus 4.6 is real but the new tokenizer adds up to 35% more tokens for the same English text, so real cost-per-task is up.
What Is GPT-5.5?
GPT-5.5 is OpenAI's flagship general-purpose model in the GPT-5 series, launched on April 23, 2026 (API on April 24). See our full review in the GPT-5.5 review (8.6 out of 10). It is the first fully retrained base model since GPT-4.5 — every release between 5.0 and 5.4 was a post-training iteration on the same foundation. GPT-5.5 rebuilt that foundation from scratch (codenamed "Spud" during training), which is why OpenAI describes it as "a new class of intelligence for real work" rather than a minor revision. Within 24 hours of release it broke a three-way tie at the top of the Artificial Analysis Intelligence Index by scoring 60. Greg Brockman framed the launch as "a big step towards more agentic and intuitive computing." It ships in three variants: GPT-5.5 base, GPT-5.5 Pro (deeper reasoning, 6x base price), and GPT-5.5 Thinking (chain-of-thought variant in ChatGPT only). Context window is 1,050,000 tokens, max output 128K, knowledge cutoff December 1, 2025, current snapshot gpt-5.5-2026-04-23. API pricing is $5 input / $30 output per million tokens — double GPT-5.4's headline rate.
Features Comparison
We benchmarked both models across thirteen dimensions that matter for production agentic and reasoning workloads: context capacity, output capacity, reasoning controls, agentic tool stack, vision input, audio input, function calling and structured outputs, computer use, MCP support, fine-tuning availability, snapshot pinning, knowledge cutoff, and platform reach. Every value below was verified on the official vendor pricing and docs pages on April 27, 2026.
| Feature | Claude Opus 4.7 | GPT-5.5 | Winner |
|---|---|---|---|
| Context window | 1,000,000 tokens | 1,050,000 tokens | GPT-5.5 |
| Max output tokens | 128,000 (300,000 via Batch beta) | 128,000 | Claude Opus 4.7 |
| SWE-bench Verified | 93% | ~75% (estimated, OpenAI publishes SWE-Bench Pro instead) | Claude Opus 4.7 |
| SWE-Bench Pro (agentic coding) | 57.4% | 58.6% | GPT-5.5 |
| Humanity's Last Exam (no tools) | 46.9% | 41.4% | Claude Opus 4.7 |
| GPQA Diamond (graduate science) | 94.2% | 93.6% | Claude Opus 4.7 |
| Artificial Analysis Intelligence Index | 58 | 60 | GPT-5.5 |
| Reasoning controls | Adaptive thinking + xhigh effort | 5 levels (none/low/medium/high/xhigh) | GPT-5.5 |
| Computer use | Yes (Computer Use API) | Yes (computer use tool) | Tie |
| MCP support | Yes (Claude Agent SDK) | Yes (native MCP client) | Tie |
| Vision input | Yes (up to 2,576 px long edge) | Yes (improved chart/diagram comprehension) | Claude Opus 4.7 |
| Audio input/output (native) | No | No (routes via GPT-4o Realtime) | Tie |
| Fine-tuning | Not available | Not available at launch | Tie |
| Snapshot pinning | Yes (model alias) | Yes (gpt-5.5-2026-04-23) | Tie |
| Knowledge cutoff | January 2026 | December 1, 2025 | Claude Opus 4.7 |
Synthesis: Claude Opus 4.7 wins on 6 features (max output, SWE-bench Verified, Humanity's Last Exam, GPQA Diamond, vision input ceiling, knowledge cutoff). GPT-5.5 wins on 4 features (context window by 50K tokens, SWE-Bench Pro, Intelligence Index, reasoning controls granularity). 5 ties (computer use, MCP, audio, fine-tuning, snapshot pinning). The headline takeaway: Opus 4.7 owns frontier reasoning benchmarks and ships better max output. GPT-5.5 owns aggregate intelligence at launch and the most granular reasoning effort scale on the market.
Pricing — Claude Opus 4.7 vs GPT-5.5 in 2026

Both models share an unusual headline: $5 per 1M input tokens. The pricing divergence shows up on output, on long-context surcharges, and on consumer plan structures. Opus 4.7 carries Anthropic's standard pricing model — flat per-token rates with cache and batch discounts. GPT-5.5 doubled vs GPT-5.4 at launch and added a long-context tier above 272K input tokens (2x input, 1.5x output) that is buried in the OpenAI docs. We pulled both pricing pages on April 27, 2026 and re-cross-checked April 30, 2026. Numbers below are verified.
Claude Opus 4.7 Pricing
| Plan | Monthly | Annual | Key Limits |
|---|---|---|---|
| API — Standard input | $5 per 1M tokens | $5 per 1M tokens | 1M context, 128K output |
| API — Standard output | $25 per 1M tokens | $25 per 1M tokens | — |
| API — Cache hit (read) | $0.50 per 1M tokens | $0.50 per 1M tokens | 90% off base input |
| API — Batch (50% off) | $2.50 / $12.50 per 1M tokens | $2.50 / $12.50 per 1M tokens | Async, 24h SLA |
| Free | $0 | $0 | Limited usage, model fallback |
| Pro (claude.ai) | $20 per month | $17 per month annual | Includes Claude Code + Cowork |
| Max 5x | From $100 per month | From $100 per month | 5x more usage than Pro |
| Max 20x | From $200 per month | From $200 per month | Auto Mode, 20x usage |
| Team (Standard) | $25 per seat per month | $20 per seat per month annual | Admin controls |
| Enterprise | $20 per seat plus usage | Contact sales | Custom SLAs |
GPT-5.5 Pricing
| Plan | Monthly | Annual | Key Limits |
|---|---|---|---|
| API — Standard input | $5 per 1M tokens | $5 per 1M tokens | 1.05M context, 128K output |
| API — Standard output | $30 per 1M tokens | $30 per 1M tokens | — |
| API — Cached input | $0.50 per 1M tokens | $0.50 per 1M tokens | 90% off base input |
| API — Batch / Flex (50% off) | $2.50 / $15 per 1M tokens | $2.50 / $15 per 1M tokens | Async, different SLAs |
| API — Long context surcharge (>272K) | $10 / $45 per 1M tokens | $10 / $45 per 1M tokens | 2x input, 1.5x output |
| API — Priority | $12.50 / $75 per 1M tokens | $12.50 / $75 per 1M tokens | 2.5x standard, tight SLA |
| GPT-5.5 Pro (API) | $30 / $180 per 1M tokens | $30 / $180 per 1M tokens | 6x base, no caching |
| Free | $0 | $0 | GPT-5.4-mini fallback only |
| Go | $4 per month | $4 per month | Limited GPT-5.5 via Codex |
| Plus | $20 per month | $20 per month | ~3,000 Thinking msgs per week |
| Pro | $200 per month | $200 per month | GPT-5.5 + Pro + Thinking, expanded |
| Business | $25 per seat per month | $25 per seat per month | Admin controls |
| Enterprise / Edu | Custom | Custom | Contracted SLAs |
Verdict pricing: Claude Opus 4.7 is cheaper for output-heavy workloads — $25 per 1M output vs GPT-5.5's $30 per 1M (17% cheaper on output). GPT-5.5 is cheaper for very-long-context input under 272K (same $5 input rate, slightly more context headroom at 1.05M vs 1M). Above 272K input, GPT-5.5 doubles its input rate while Opus 4.7 holds flat — a meaningful penalty for million-token agentic runs. Per-task comparison on a 50K-input / 5K-output agentic call: Opus 4.7 = ($5 × 0.05) + ($25 × 0.005) = $0.375 per call. GPT-5.5 = ($5 × 0.05) + ($30 × 0.005) = $0.40 per call. Real-world tax: Opus 4.7's new tokenizer consumes up to 35% more tokens for the same English text, so the per-call cost gap on identical prose narrows or flips in GPT-5.5's favor on shorter, English-only workloads. We saw Opus 4.7 use ~30% more tokens than GPT-5.5 on a 4,200-word JSON-LD audit prompt — net cost ended within 5% of each other.
Hands-on — How They Performed Side-by-Side on ThePlanetTools.ai
We ran Claude Opus 4.7 and GPT-5.5 side-by-side for two weeks on our content production project — the internal CMS that powers ThePlanetTools.ai (Next.js 16 App Router, React 19, Supabase, Tauri desktop wrapper, ~247 API routes). Same tasks, same inputs, two API endpoints. Here is what we actually observed across four real production prompts. Methodology note: API direct calls, no harness optimizations, both models at xhigh / high effort, snapshot-pinned (claude-opus-4-7 and gpt-5.5-2026-04-23).
Test 1 — Multi-file refactor (agentic coding)

Prompt: "Migrate all 14 API routes under src/app/api/sites/theplanettools/[type]/generate-prompts/ from the legacy schema to the new Claude Agent SDK schema. Verify with npm run build. Report only on completion."
Claude Opus 4.7: 41 tool calls, 1 completion. Self-verified the diff before reporting back ("re-checked the imports and the schema match — all 14 files compile cleanly"). Catched a missing readonly modifier on its own first pass. Total: 287K input tokens, 38K output tokens, ~$2.39 net cost. Build passed first try.
GPT-5.5: 36 tool calls, two completions (first claimed done, build failed on file 11; second pass fixed it). Reported "all 14 files migrated and tested" on the first turn — that was a lie, file 11 had a stale import. After follow-up prompt: 12 additional tool calls, fixed it. Total: 312K input tokens, 47K output tokens, ~$3.06 net cost. Build passed on second try.
Winner: Claude Opus 4.7. The self-verification behavior is what we paid for — fewer "I'm done" lies followed by broken builds. GPT-5.5's agentic stack is broader but Opus 4.7's completion reliability on long runs is real.
Test 2 — Frontier reasoning (graduate-level science)

Prompt: A custom GPQA-style question on the energetics of intrinsically disordered protein binding (a real biophysics problem, no tools allowed, no web search).
Claude Opus 4.7: Correct answer with full reasoning chain. Explicitly flagged the conformational entropy penalty as the dominant unfavorable term, computed the magnitude correctly, and identified the binding-coupled folding mechanism as the resolution. ~14K output tokens, ~$0.35 cost.
GPT-5.5: Correct final answer but skipped the entropy magnitude computation — it identified the right mechanism but did not show the math. Asked to elaborate, it produced the calculation correctly. ~9K output tokens initial, ~$0.27. After follow-up: ~11K total output, ~$0.33.
Winner: Claude Opus 4.7. This is consistent with Opus 4.7 leading Humanity's Last Exam at 46.9% vs GPT-5.5's 41.4% — frontier reasoning shows up more reliably with Opus, even when GPT-5.5 gets to the same answer eventually.
Test 3 — Long-horizon agentic task (overnight content cron)

Prompt: Our nightly content cron generates 6 articles plus 2 OpenAI-themed news pieces. The agent decomposes the brief, fetches sources, drafts content, generates images, validates JSON-LD, pushes to Supabase, and revalidates. Multi-agent harness, ~6 hours of wall time, hundreds of tool calls.
Claude Opus 4.7: Completed all 8 articles. Used the new task budgets feature (public beta) to cap the run at 200K tokens per article — every article finished within budget. Self-paced behavior visible in the logs: model dropped a sub-task when it noticed its own context was bloating. Net cost: ~$47 for the full 8-article run.
GPT-5.5: Completed 7 of 8 articles cleanly. Eighth article hit the long-context surcharge (above 272K input tokens because the model had not pruned its working memory) and the cost on that one article was 2.4x the average — overran the budget by 18% overall. The agentic stack is complete and capable, but the absence of an equivalent to Opus 4.7's task budgets feature shows up in production. Net cost: ~$54 for the same 8-article workload.
Winner: Claude Opus 4.7. Task budgets is the headline feature that justified switching our nightly pipeline. GPT-5.5 will likely ship something equivalent — until then, Opus 4.7 is the cleaner cost-control story.
Test 4 — Vision input (chart and diagram comprehension)
Prompt: Extract structured data from a 2,400 px wide pricing screenshot from a competitor SaaS site. Return a JSON object with the plan tiers, monthly prices, annual prices, and key feature bullets per tier.
Claude Opus 4.7: Accepted the 2,400 px image (well within the new 2,576 px max edge). Returned a clean JSON with all 5 tiers, all prices correct, all 23 feature bullets correctly attributed. ~3.5K output tokens, ~$0.09.
GPT-5.5: Accepted the same image. Returned a clean JSON with all 5 tiers, but missed 2 of the 23 feature bullets on the smallest-print tier (Free tier). Re-prompt fixed it. ~3.8K initial output, ~$0.11; ~4.5K total after follow-up, ~$0.13.
Winner: Claude Opus 4.7 by a hair — first-pass accuracy on dense visual data is the tiebreaker. Both models are competent on vision; the 2,576 px max edge on Opus 4.7 is the only hard differentiator we hit in production.
Winner per Category

Best Overall: Claude Opus 4.7
Claude Opus 4.7 takes the overall crown for our use case (production agentic coding pipelines on a Next.js / Supabase stack). The 9.4 out of 10 score reflects best-in-class agentic completion reliability, frontier reasoning leadership, and the cleanest cost-control story (task budgets, 90% cache hits, 50% Batch discount). GPT-5.5 (8.6 out of 10) is excellent and wins many sub-categories — but Opus 4.7's "the model finishes what it starts" property is the headline differentiator for unattended autonomy.
Best for Coding (Agentic): Claude Opus 4.7
SWE-bench Verified 93% vs GPT-5.5's ~75%. SWE-Bench Pro is closer (57.4% vs 58.6%, edge to GPT-5.5), but the more relevant production benchmark — long multi-file refactors that need to actually finish — favors Opus 4.7 by a clear margin. We saw it in Test 1: same task, Opus 4.7 finished in one pass, GPT-5.5 needed a follow-up.
Best for Frontier Reasoning: Claude Opus 4.7
Humanity's Last Exam 46.9% vs 41.4% (Opus +5.5 points). GPQA Diamond 94.2% vs 93.6% (Opus +0.6 points). For graduate-level science, deep research, or any workload where the marginal reasoning quality compounds, Opus 4.7 is the safer pick. GPT-5.5 leads the aggregate Intelligence Index at 60 vs 58, but that index weights agentic and code benchmarks heavily — it is not a pure reasoning measure.
Best for Ecosystem and Tooling: GPT-5.5
The OpenAI stack is a real moat: Codex with 400K context on every ChatGPT plan (including Plus at $20 per month), Responses API with structured outputs and the most mature function-calling implementation on the market, MCP client support out of the box, computer use as a first-class tool, native integrations with Cursor, Windsurf, n8n, Vercel AI SDK, LangChain, LlamaIndex, Zapier, and JetBrains IDEs. If you live in this ecosystem, GPT-5.5 is the path of least resistance.
Best for Cost (Output-Heavy): Claude Opus 4.7
$25 per 1M output vs $30 per 1M (Opus 17% cheaper on output). The 90% cache-hit discount applies to both. The 50% Batch discount applies to both. GPT-5.5's long-context surcharge above 272K input tokens (2x input, 1.5x output) is a real penalty Opus 4.7 does not have. For high-output workloads (content generation, long-form synthesis), Opus 4.7's per-output advantage compounds.
Best for Long Context: GPT-5.5 (Slight Edge)
1.05M tokens vs 1M tokens — 50K extra headroom on GPT-5.5. Both models hold up well past the 700K mark. Opus 4.7 has the quieter long-context story (no surcharge above 272K), GPT-5.5 has the slightly larger absolute window. For most users, this is a tie — both are 1M-class. For users who routinely exceed 272K input, Opus 4.7 wins on cost.
Best for Consumer / IDE Use: GPT-5.5
Codex on every ChatGPT plan plus the GPT-5.5 Thinking variant in the consumer app gives GPT-5.5 a clear edge for solo developers paying $20 per month. Claude Opus 4.7 is on the Pro plan ($17 annual / $20 monthly) but the consumer experience around it is less polished than ChatGPT's. For teams already on ChatGPT Pro at $200 per month, the value of GPT-5.5 + GPT-5.5 Pro + Thinking access bundled is genuinely strong.
Pros and Cons
Claude Opus 4.7 Pros and Cons
What we liked about Claude Opus 4.7
- Self-verification on long agentic runs. The model re-reads its own diffs and catches its own errors before handing back. Net effect: fewer "I'm done" lies followed by broken builds. This is the headline win on Opus 4.7 vs Opus 4.6 and vs GPT-5.5.
- Frontier reasoning leadership. 46.9% on Humanity's Last Exam (best in class), 94.2% on GPQA Diamond, 93% on SWE-bench Verified. The combination of agentic and pure reasoning at the top of the leaderboard is unique to Opus 4.7 in April 2026.
- Task budgets (public beta). Set a token cap on a long agentic run so the model self-paces and stops before bleeding your wallet. We turned this on for our nightly cron and the wallet-impact was immediate.
- 90% cache-hit discount. $0.50 per 1M cached input tokens vs $5 base rate. For agentic loops with stable system prompts, this turns Opus 4.7 from premium to mid-tier on real cost-per-task.
- Vision input up to 2,576 px on long edge. More than triple prior Claude models. We hit this advantage on dense pricing-page screenshots and chart-heavy slides.
- Multi-cloud availability. AWS Bedrock, Google Vertex AI, Microsoft Foundry, and the Anthropic API. Multi-region failover on day one.
Where Claude Opus 4.7 falls short
- New tokenizer adds up to 35% more tokens for the same English text. Headline price is identical to Opus 4.6 but real cost-per-task is up. We saw 1.5-2x cost-per-feature on the same workflows.
- No extended thinking mode. Adaptive thinking only — the model decides whether to reason internally based on the task. If your pipeline relied on forcing extended reasoning on Opus, that lever is gone (Sonnet 4.6 still has it).
- Latency is moderate. Per Anthropic's own framing. For short, snappy turns Haiku 4.5 or Sonnet 4.6 are cleaner.
- No silent rescue of vague prompts. Opus 4.7 asks "which auth bug?" instead of guessing. Net win for correctness, but a real change in muscle memory if you came from Opus 4.6.
GPT-5.5 Pros and Cons
What we liked about GPT-5.5
- First fully retrained base since GPT-4.5. The "Spud" foundation is a multi-month investment in compounding capability — future GPT-5.x point releases inherit a stronger starting point. Not a quarterly tweak, a foundation upgrade.
- Five-level reasoning effort scale. The none/low/medium/high/xhigh ladder is the most granular reasoning control on the market. Claude exposes only adaptive on/off; Gemini exposes thinking budgets, not effort levels.
- Complete agentic stack out of the box. Function calling, structured outputs, web search, file search, code interpreter, computer use, MCP — all on by default, no feature flags, no preview waiting list.
- Codex on every ChatGPT plan with fast mode. 400K context inside Codex with optional 1.5x speed at 2.5x cost. For solo developers on Plus at $20 per month, this is essentially a free upgrade with no API spend.
- Topped Artificial Analysis Intelligence Index at 60. Within 24 hours of launch, GPT-5.5 broke a three-way tie at the top — a real benchmark of aggregate frontier capability.
- Token efficiency claim is real. Multiple early reviewers report shorter responses and stronger bias toward small workable changes — per-task cost is closer to +20% effective vs +100% on rate cards.
Where GPT-5.5 falls short
- API price doubled vs GPT-5.4. $5 input / $30 output per 1M tokens is 2x prior pricing. For high-token-volume workloads (RAG over large corpora, long content pipelines), this is a material margin hit.
- Long-context surcharge above 272K is buried in the docs. Prompts above 272K input trigger 2x input and 1.5x output billing. OpenAI did not surface this in the launch post; it materially changes the math on million-token runs.
- ChatGPT Plus rate-limit regression at launch. Initial 200-messages-per-week cap (later raised to ~3,000 for Thinking) was a downgrade vs GPT-5.4 and triggered the loudest Reddit pushback in the first 72 hours.
- No fine-tuning on the base model. Teams with tuned production variants must stay on GPT-5.4-mini. OpenAI has not announced a fine-tuning timeline for GPT-5.5.
When to Pick Claude Opus 4.7 vs GPT-5.5
Pick Claude Opus 4.7 if...
- You run unattended agentic coding pipelines (30+ tool calls per task) where completion reliability matters more than raw speed.
- Your workload is reasoning-heavy — graduate-level science, deep research, frontier analysis, complex legal or scientific writing.
- You need cost ceilings on long autonomous runs (task budgets feature is unique to Opus 4.7 in April 2026).
- Your output-token volume is high — Opus 4.7's $25 per 1M output beats GPT-5.5's $30 per 1M by 17%.
- You need vision input on dense visual data (Opus 4.7's 2,576 px max edge is best in class).
- You need multi-cloud failover on day one (AWS Bedrock, Vertex AI, Foundry, Anthropic API).
Pick GPT-5.5 if...
- You live in the OpenAI ecosystem (Codex, Responses API, MCP client tooling, structured outputs).
- You need granular reasoning effort control (5 levels: none/low/medium/high/xhigh).
- You are a solo developer or small team paying $20 per month for ChatGPT Plus — Codex with 400K context is a free upgrade.
- Your workload is agentic coding measured by SWE-Bench Pro (58.6% vs Opus 4.7's 57.4%) or the Intelligence Index (60 vs 58).
- You need the most mature function-calling and structured-outputs implementation in production.
- You need consumer-grade reasoning UX (GPT-5.5 Thinking shows intermediate steps natively in ChatGPT).
Frequently Asked Questions
Is Claude Opus 4.7 better than GPT-5.5 in 2026?
For agentic coding and frontier reasoning, yes. Opus 4.7 scores 93% on SWE-bench Verified vs GPT-5.5's ~75%, leads Humanity's Last Exam (46.9% vs 41.4%), and ties or wins GPQA Diamond. Opus 4.7's task budgets feature and self-verification behavior on long agentic runs (30+ tool calls) make it our pick for unattended autonomy. GPT-5.5 wins the aggregate Artificial Analysis Intelligence Index (60 vs 58) and ships a more granular reasoning effort scale (5 levels vs adaptive). For ecosystem breadth and consumer UX, GPT-5.5 wins. We rate Opus 4.7 9.4 out of 10 vs GPT-5.5 8.6 out of 10.
How much does Claude Opus 4.7 cost compared to GPT-5.5?
Both share a $5 per 1M input token rate. Output diverges: Opus 4.7 is $25 per 1M output, GPT-5.5 is $30 per 1M output (Opus 17% cheaper on output). Both offer a 90% cache-hit discount ($0.50 per 1M cached input). Both offer a 50% Batch discount ($2.50 / $12.50-15 per 1M tokens). GPT-5.5 adds a long-context surcharge above 272K input tokens (2x input, 1.5x output) that Opus 4.7 does not have. On a 50K-input / 5K-output agentic call, Opus 4.7 = $0.375, GPT-5.5 = $0.40. Opus 4.7's new tokenizer adds up to 35% more tokens for the same English text, which can narrow or flip the gap on prose-heavy workloads.
Which is better for agentic coding: Claude Opus 4.7 or GPT-5.5?
Claude Opus 4.7 wins on SWE-bench Verified (93% vs ~75%) and on real-world completion reliability — its self-verification behavior means long autonomous runs (30+ tool calls) finish what they start without "I'm done" lies followed by broken builds. GPT-5.5 wins on SWE-Bench Pro (58.6% vs 57.4%), which is OpenAI's headline agentic benchmark, and on raw tool-stack breadth (function calling, structured outputs, MCP, computer use, code interpreter, web search, file search all on by default). For unattended overnight runs, we use Opus 4.7. For tightly orchestrated agent workflows with structured outputs, GPT-5.5 is competitive.
Which has the larger context window: Claude Opus 4.7 or GPT-5.5?
GPT-5.5 has a slightly larger context window at 1,050,000 tokens vs Claude Opus 4.7's 1,000,000 tokens — a 50K-token edge. Both deliver 128,000 max output tokens (Opus 4.7 also offers 300,000 via the Message Batches API beta). Both hold up well past the 700K-token mark in practice. The bigger differentiator is GPT-5.5's long-context surcharge: prompts above 272K input tokens are billed at 2x input and 1.5x output, which Opus 4.7 does not have. For users routinely above 272K input, Opus 4.7 wins on cost despite the smaller absolute window.
Can I switch from Claude Opus 4.7 to GPT-5.5 (or vice versa) easily?
API-level switching is straightforward — both expose chat-completion-style endpoints with similar message structures. Production migration requires rework: GPT-5.5 uses OpenAI's Responses API and structured outputs syntax, Opus 4.7 uses Anthropic's Messages API with tool-use blocks and content blocks. Function-calling shapes differ slightly. MCP works on both. If your stack uses an abstraction layer like LangChain, Vercel AI SDK, or LiteLLM, switching is a config change. If your stack calls vendor APIs directly, expect 1-3 days of integration rework per service. Token budgets and prompt caching headers are vendor-specific.
Do Claude Opus 4.7 and GPT-5.5 work together in the same agent?
Yes — multi-model orchestration is increasingly common. Both expose MCP client support, both have stable APIs, and frameworks like LangChain, LlamaIndex, Vercel AI SDK, and our own Claude Agent SDK can route tasks to either model based on workload type. A common pattern: Opus 4.7 for the planning and reasoning steps (cheaper output, better frontier reasoning), GPT-5.5 for tool-heavy execution steps (broader native tool stack, faster on Priority tier). Cost-aware routing by workload is the production pattern we recommend over picking one model exclusively.
Which has better customer support: Anthropic or OpenAI?
Both ship enterprise SLAs and dedicated account management at the Enterprise tier. OpenAI has a clear edge on developer documentation breadth and the Deployment Safety Hub (system cards, evaluation transparency, rate-limit clarity). Anthropic has the edge on responsiveness for paid API customers and on the technical depth of their model card disclosures. For consumer support, ChatGPT's larger user base means more community-sourced answers; Claude's documentation is tighter and more structured. Neither vendor has a public phone-support tier — both are ticket-based.
Is GPT-5.5 faster than Claude Opus 4.7?
On standard tier, GPT-5.5 is marginally faster on first-token latency. With the Priority processing tier (2.5x cost), GPT-5.5 ships tighter latency SLAs that Opus 4.7 does not match. On long agentic runs, however, total wall-time often favors Opus 4.7 because it self-verifies and finishes in one pass, while GPT-5.5 may need a follow-up round to fix issues caught after the first claimed completion. Net: GPT-5.5 wins on per-token latency, Opus 4.7 wins on time-to-correct-completion.
Which has more features: Claude Opus 4.7 or GPT-5.5?
GPT-5.5 has marginally more agentic surface area at launch — the five-level reasoning effort scale (none/low/medium/high/xhigh), three runtime variants (base, Pro, Thinking), three execution modes (Standard, Batch/Flex, Priority), Codex integration on every ChatGPT plan, and the most mature structured-outputs implementation. Claude Opus 4.7 has the more focused feature set — adaptive thinking, task budgets (public beta), xhigh effort level, /ultrareview command on claude.ai, Auto Mode at the Max 20x tier, and a broader cloud footprint (AWS Bedrock, Vertex AI, Microsoft Foundry, Anthropic API). Quality wins over count: Opus 4.7's task budgets is the single feature we miss most when we work with GPT-5.5.
Are Claude Opus 4.7 and GPT-5.5 SOC 2 / GDPR compliant?
Both vendors hold SOC 2 Type II certifications. Both offer GDPR-compliant data processing addenda (DPAs) for paid API and Enterprise customers. Both offer EU data residency on Enterprise tiers — Anthropic via AWS Bedrock EU regions and Google Vertex AI europe-west1 / europe-west4 endpoints, OpenAI via the EU-region API for Enterprise. Both publish system cards detailing safety evaluations. Anthropic publishes Constitutional AI methodology in detail; OpenAI publishes the GPT-5.5 system card on the Deployment Safety Hub. For HIPAA, both offer signed BAAs at the Enterprise tier. For zero-data-retention API processing, both support the standard 30-day retention waiver via paid API contracts.
What are the alternatives to Claude Opus 4.7 and GPT-5.5?
Three credible frontier alternatives in April 2026: Google Gemini 3.5 Pro at $1.25 input / $10 output per 1M tokens with a 2M context window and native audio input — the price-to-intelligence leader. DeepSeek V4 at $0.27 input / $1.10 output with open weights for on-prem deployment — 18-20x cheaper than GPT-5.5. Claude Sonnet 4.6 at $3 input / $15 output with extended thinking still available — cleaner cost story than Opus 4.7 for non-frontier workloads. For most production agentic-coding workloads, the frontier choice is between Opus 4.7 and GPT-5.5; Gemini 3.5 Pro is the default for high-volume RAG; DeepSeek V4 is the default for sovereignty-conscious deployments.
Can Claude Opus 4.7 do everything GPT-5.5 can do (and vice versa)?
Mostly yes, with two notable gaps. Opus 4.7 lacks GPT-5.5's five-level reasoning effort scale (Opus only offers adaptive thinking + xhigh effort) and lacks an equivalent of the GPT-5.5 Pro variant for ultra-deep reasoning. GPT-5.5 lacks Opus 4.7's task budgets feature for cost-controlled long runs and has a shallower vision input ceiling (Opus 4.7 accepts 2,576 px max edge; GPT-5.5 does not publish an explicit upper limit but underperformed on dense pricing-page screenshots in our Test 4). Both support function calling, structured outputs, computer use, MCP, prompt caching, batch processing, and 1M-class context windows. For 95% of production workloads either model works; the remaining 5% is where the differentiators matter.
Final Verdict: Claude Opus 4.7 (9.4 out of 10) Edges GPT-5.5 (8.6 out of 10)

After two weeks of side-by-side production use on ThePlanetTools.ai, our verdict is split-but-tilted. Claude Opus 4.7 is the better model for unattended autonomous coding and frontier reasoning — the self-verification behavior on long runs is real, the 93% on SWE-bench Verified is real, the 46.9% on Humanity's Last Exam is real, and task budgets is a unique cost-control feature in April 2026. GPT-5.5 is the better model for ecosystem-deep teams — Codex on every ChatGPT plan, Responses API maturity, structured outputs, MCP client tooling, the most granular reasoning effort scale on the market, and the aggregate Intelligence Index lead at 60 are all genuine wins. If you are building an unattended overnight agentic pipeline, go with Claude Opus 4.7. If you are building a tightly-orchestrated multi-tool agent on the OpenAI stack, GPT-5.5 is the natural fit. If your workload is reasoning-heavy and budget-sensitive, consider Claude Sonnet 4.6 or Gemini 3.5 Pro before paying the frontier premium on either Opus 4.7 or GPT-5.5.
Score breakdown by category:
- Features: Claude Opus 4.7 9.6 out of 10 vs GPT-5.5 9.2 out of 10 — Opus 4.7 wins on max output, vision ceiling, and cloud footprint; GPT-5.5 wins on reasoning effort granularity and tool-stack maturity.
- Ease of Use: Claude Opus 4.7 9.0 out of 10 vs GPT-5.5 8.5 out of 10 — Opus 4.7's clean pricing and explicit task budgets win; GPT-5.5's long-context surcharge documentation is the friction point.
- Value: Claude Opus 4.7 8.5 out of 10 vs GPT-5.5 7.5 out of 10 — Opus 4.7 cheaper on output ($25 vs $30 per 1M); GPT-5.5 doubled vs GPT-5.4 and lost ground.
- Support: Claude Opus 4.7 9.2 out of 10 vs GPT-5.5 9.0 out of 10 — both ship enterprise SLAs and SOC 2 / GDPR compliance; Anthropic edges on technical depth, OpenAI edges on documentation breadth.
Final word: Buy Claude Opus 4.7 if you are an engineering team running production agentic coding workflows where completion reliability and frontier reasoning matter more than raw speed or ecosystem fit. Buy GPT-5.5 if you live in the OpenAI ecosystem, need granular reasoning effort control, or are a solo developer wanting Codex with 400K context bundled into your $20-per-month ChatGPT Plus subscription. Consider running both — increasingly we route planning and reasoning steps through Opus 4.7 (cheaper output, better frontier reasoning) and tool-heavy execution steps through GPT-5.5 (broader native tool stack). Cost-aware multi-model routing beats single-vendor purity for most production teams in April 2026. For broader context, see our flagship LLM category page and our reviews of Claude Opus 4.7 and GPT-5.5.
Our Verdict
Claude Opus 4.7 (9.4/10) edges GPT-5.5 (8.6/10) overall on our production agentic coding workflows after two weeks side-by-side. Opus 4.7 wins agentic coding (93% SWE-bench Verified vs ~75%), frontier reasoning (46.9% on Humanity's Last Exam vs 41.4%), output pricing ($25 vs $30 per 1M tokens), and ships task budgets to cap autonomous run costs — a unique cost-control feature in April 2026. GPT-5.5 wins ecosystem breadth (Codex on every ChatGPT plan, Responses API, mature MCP and structured outputs), reasoning effort granularity (5 levels), and the aggregate Artificial Analysis Intelligence Index at 60. Pick Opus 4.7 for unattended autonomous coding and reasoning-heavy work; pick GPT-5.5 if you live in the OpenAI ecosystem or need granular reasoning effort control.
Choose Claude Opus 4.7
Anthropic's flagship LLM — agentic coding king with 1M context
Try Claude Opus 4.7 →Choose GPT-5.5
OpenAI's first fully retrained base model since GPT-4.5 — agentic, faster, and double the API price.
Try GPT-5.5 →Frequently Asked Questions
Is Claude Opus 4.7 better than GPT-5.5?
Claude Opus 4.7 (9.4/10) edges GPT-5.5 (8.6/10) overall on our production agentic coding workflows after two weeks side-by-side. Opus 4.7 wins agentic coding (93% SWE-bench Verified vs ~75%), frontier reasoning (46.9% on Humanity's Last Exam vs 41.4%), output pricing ($25 vs $30 per 1M tokens), and ships task budgets to cap autonomous run costs — a unique cost-control feature in April 2026. GPT-5.5 wins ecosystem breadth (Codex on every ChatGPT plan, Responses API, mature MCP and structured outputs), reasoning effort granularity (5 levels), and the aggregate Artificial Analysis Intelligence Index at 60. Pick Opus 4.7 for unattended autonomous coding and reasoning-heavy work; pick GPT-5.5 if you live in the OpenAI ecosystem or need granular reasoning effort control.
Which is cheaper, Claude Opus 4.7 or GPT-5.5?
Claude Opus 4.7 is priced at $5 in / $25 out per M tokens. GPT-5.5 is priced at $5 in / $30 out per M tokens. Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Opus 4.7 and GPT-5.5?
The key differences span across 15 features we compared. For Context window, Claude Opus 4.7 offers 1,000,000 tokens while GPT-5.5 offers 1,050,000 tokens. For Max output tokens, Claude Opus 4.7 offers 128,000 (300,000 via Batch beta) while GPT-5.5 offers 128,000. For SWE-bench Verified, Claude Opus 4.7 offers 93% while GPT-5.5 offers ~75% (estimated). See the full feature comparison table above for all details.