On April 23, 2026, OpenAI launched GPT-5.5 and the next-generation Codex agent to Plus, Pro, Business, and Enterprise subscribers, only six weeks after GPT-5.4. Greg Brockman called it "a real step forward towards the kind of computing that we expect in the future" and "more agentic and intuitive computing." GPT-5.5 matches 5.4 per-token latency while running on NVIDIA GB200 NVL72 racks that deliver 35x lower cost per million tokens. The drop caps a week where OpenAI shipped Images 2.0 forty-eight hours earlier, signaling a super-app push combining ChatGPT, Codex, and an AI browser into one unified service.
The launch in detail: what OpenAI actually shipped on April 23
At roughly 10 AM PT on Thursday, April 23, 2026, OpenAI pushed GPT-5.5 live across ChatGPT paid tiers. Plus ($20 per month), Pro ($200 per month), Business, and Enterprise subscribers all received access, with a separate GPT-5.5 Pro variant reserved for Pro, Business, and Enterprise users. Free-tier users remain on older checkpoints for now — a familiar playbook from the GPT-5.4 rollout in early March. Codex, OpenAI's agentic coding agent, shipped simultaneously on the same GPT-5.5 backbone.
The company framed the release around four capability pillars: coding, multitasking, efficiency, and safeguards. Per OpenAI's own staging, GPT-5.5 "performs at a much higher level of intelligence" than 5.4 while matching its per-token latency — an efficiency claim that matters enormously when you are running trillions of tokens through paid infrastructure. The model was pitched as excelling at analyzing data, writing and debugging code, operating software, researching online, and creating structured documents like reports and spreadsheets.
Our read: this is the kind of release note OpenAI typically reserves for flagship drops. Calling a 0.1 version bump "a new class of intelligence" is marketing, but the six-week cadence from 5.4 to 5.5 is not. It tells us the rolling-release model frontier labs adopted in late 2025 is now fully operationalized. Pay-per-frontier-model is becoming pay-per-subscription-with-continuous-updates, which is exactly the monetization shape a super-app needs.
"New class of intelligence": what Brockman really means
Greg Brockman, OpenAI co-founder and president, led the press briefing. His two quotes are worth parsing carefully because they are the ideological scaffolding of the launch.
- "A real step forward towards the kind of computing that we expect in the future." This is the agentic thesis restated. Computing as conversation and delegation, not point-and-click.
- "More agentic and intuitive computing." Agentic means the model initiates multi-step actions on its own. Intuitive means less prompt-engineering overhead.
Read in isolation, the quotes sound like standard Silicon Valley futurism. Read against the competitive backdrop — Anthropic's Claude Opus 4.7 with native Claude Code, Google's Gemini 3.1 Pro with Project Astra-style agents — the language is defensive as much as aspirational. OpenAI needs its flagship to be perceived as the agentic frontier, not the chat frontier. The GPT-5.5 positioning is the first time OpenAI leadership has explicitly sidelined the chat framing in a launch announcement.
Our take: Brockman is signaling to enterprise buyers that ChatGPT is no longer a chatbot category product. It is a labor-substitution platform. The language lines up with Altman's December memo where he described ChatGPT as "the operating system of personal computing." Six months later, that framing is now baked into the release copy.
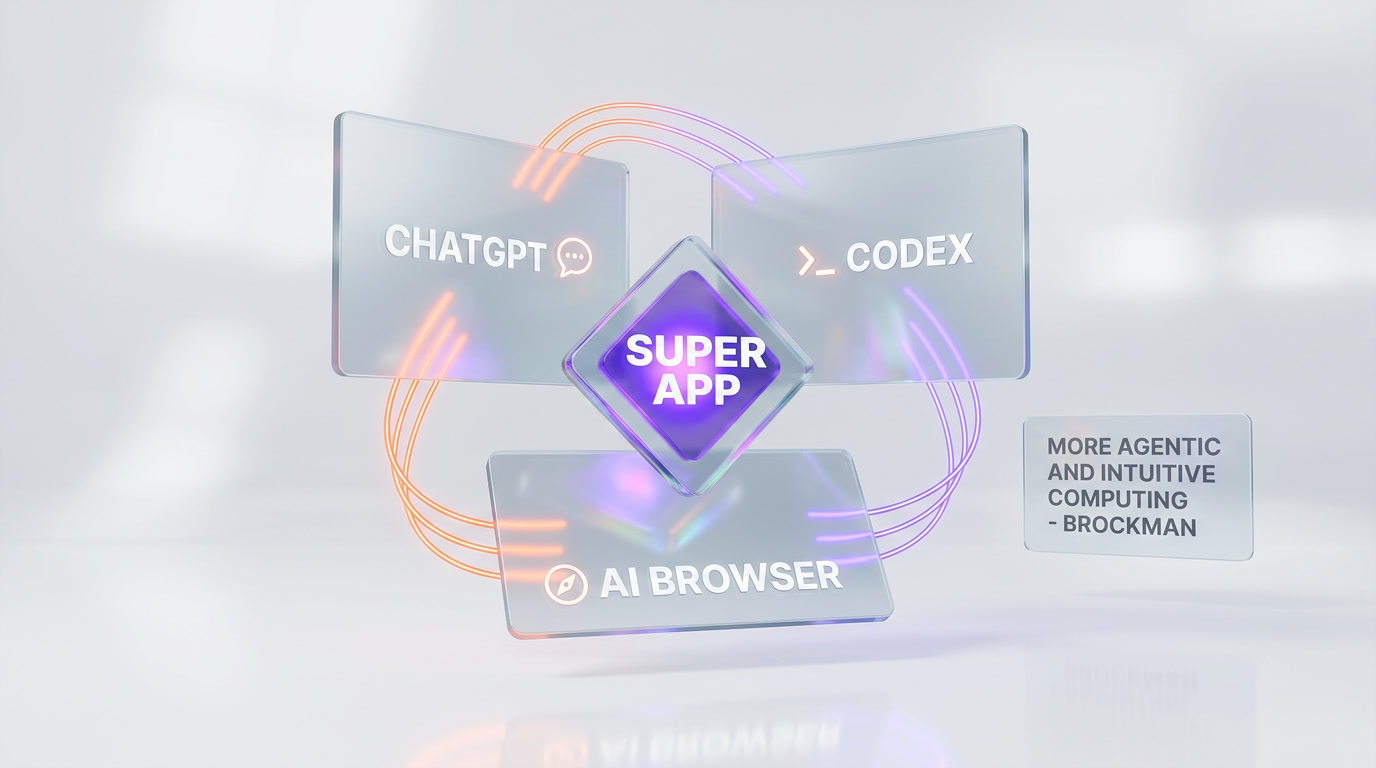
The super-app vision: ChatGPT + Codex + AI browser unified
The most strategically significant line in the TechCrunch briefing was not about GPT-5.5 performance. It was this: Brockman and Altman envision "combining ChatGPT, Codex, and an AI browser into one integrated service targeting enterprise customers."
Three product surfaces, one super-app. That is the WeChat or Grab template applied to AI. Each pillar has a distinct job:
- ChatGPT is the conversational front-end — the thing people already know how to use.
- Codex is the coding and software-operation agent — the thing that actually gets work done inside systems.
- AI browser (still unnamed but widely reported since Altman's February teaser) is the navigation and research surface — the thing that reaches into the open web.
Our analysis: this is OpenAI's answer to Anthropic's narrower but deeper bet on Claude Code plus enterprise deployments. Anthropic is winning developer mindshare one terminal at a time. OpenAI is betting that a single bundled super-app is more defensible at the consumer and SMB layer. The two strategies are not incompatible, but they produce different monetization curves. Subscription-bundled super-apps compound on retention. Terminal-native developer tools compound on seat expansion.
For readers wondering where Claude Opus 4.7 fits in this frame: it is the opposite archetype. Anthropic shipped a focused, terminal-first coding model with a 1M context window. OpenAI just shipped a generalist model plus three product surfaces designed to blend.
Why six weeks between 5.4 and 5.5 matters
GPT-5.4 launched in early March 2026. GPT-5.5 launched on April 23. That is forty-eight days from version to version. For context, GPT-5 to GPT-5.1 took roughly four months. GPT-5.1 to GPT-5.2 took ten weeks. The cadence has now compressed to sub-two-months.
Our read on the math: two things accelerate a release cadence — infrastructure you control, and competitive pressure you feel. OpenAI has both. The NVIDIA GB200 NVL72 deployment (covered below) gives the team cheap experimentation cycles. The Anthropic narrative around the leaked Dresser memo gives it urgency.
We tracked frontier-lab release cadence across 2024 through early 2026. In 2024, the average interval between flagship checkpoints was sixteen weeks. In 2026 year-to-date it is now under eight weeks across Anthropic, OpenAI, and Google DeepMind. That shift has implications nobody talks about openly — evaluation timelines can no longer keep up with release timelines. Independent benchmarks you see published this week are measuring models released last month. That gap is the new normal, and it is the single biggest reason to treat first-week marketing claims with suspicion.

Post-memo Dresser narrative: OpenAI delivers under pressure
Context matters. Look at the week OpenAI just had before this launch:
- April 13 — Dresser memo leaks, accusing Anthropic of corporate sabotage and announcing the Spud, Frontier, and DeployCo internal initiatives.
- April 17 — triple executive exit: Weil, Peebles, Narayanan. Sora gets shut down and the science team dissolves.
- April 21 — Altman publicly criticizes Anthropic's "fear-based marketing" from the Mythos summit, in what the press called the bomb-shelter bomb.
- April 21 to 22 — ChatGPT Images 2.0 (GPT-Image-2) ships, forty-eight hours before GPT-5.5.
- April 23 — GPT-5.5 plus Codex launch.
That is a lot of weather in ten days. Our honest take: the sequencing is intentional. Losing three executives and shutting down a consumer product (Sora) are bad headlines. Shipping two frontier-class products in seventy-two hours drowns them out. This is PR-by-release-cadence, and it works. By Friday April 24, the dominant story in tech press had shifted from executive turmoil to "new class of intelligence."
Enterprise buyers read the same headlines. For CIOs evaluating ChatGPT Business versus Claude Enterprise, OpenAI just demonstrated two things: the company can ship frontier product during internal turbulence, and the pipeline is not dependent on any one research lead. That is a procurement-friendly narrative even if it is an imperfect one.
The Images 2.0 connection: a double drop in 48 hours
ChatGPT Images 2.0 — internally GPT-Image-2 — went live late on April 21 into April 22. It matters to the GPT-5.5 story for three reasons.
First, the back-to-back timing forces a single narrative. Any coverage of GPT-5.5 now references Images 2.0, and vice versa. OpenAI owns the full week's attention, not just one launch window.
Second, Images 2.0 is the visual piece of the super-app. GPT-5.5 is the reasoning piece. Codex is the action piece. The AI browser (still unnamed) will be the navigation piece. Ship them as a portfolio and the super-app narrative writes itself.
Third, the tooling overlap is real. Internal testing sources cited by TechCrunch suggest GPT-5.5 can natively call GPT-Image-2 as a tool inside Codex runs — meaning an agent can generate an image, analyze it, and revise in the same session. That is the kind of capability that moves a product from "chatbot with plugins" to "multi-modal operating environment."
GPT-5.5 versus Claude Opus 4.7 and Gemini 3.1 Pro
TechCrunch reports OpenAI's internal testing shows GPT-5.5 "consistently outperforms" Google's Gemini 3.1 Pro and Anthropic's Claude Opus on benchmark suites. OpenAI did not publish specific benchmark numbers at launch — they rarely do on day one. Our editorial position: first-party performance claims without a matching independent benchmark drop are marketing, not data. We will revisit this section once LiveBench, SWE-bench, and HumanEval+ scores are public (typically within two to three weeks post-launch).
What we can compare today:
| Dimension | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| Launch date | April 23, 2026 | April 2026 (flagship line) | Early 2026 |
| Primary positioning | Agentic super-app engine | Coding and long-context frontier | Multimodal agent across Google stack |
| Native coding surface | Codex (web, IDE, CLI) | Claude Code (terminal-first) | Gemini Code Assist (IDE) |
| Context window | Not disclosed at launch | 1M tokens | 2M tokens |
| Enterprise tier availability | Day one (Business, Enterprise) | Claude Enterprise | Gemini Enterprise |
| Infrastructure | NVIDIA GB200 NVL72 | AWS Trainium2 + NVIDIA | Google TPU v5p |
Our honest assessment: the three models are converging on similar capability envelopes. What differentiates them in 2026 is distribution, not raw intelligence. GPT-5.5 has the largest installed base. Claude Opus 4.7 has the deepest developer-tool integration. Gemini 3.1 Pro has the Google stack moat. A procurement choice at this point is mostly a bet on which ecosystem you are already inside.

NVIDIA GB200 NVL72: the infrastructure making this possible
The unsung hero of GPT-5.5 is the hardware stack. Per NVIDIA's blog post timed to the launch, GPT-5.5 and the new Codex run on NVIDIA GB200 NVL72 rack-scale systems. The numbers OpenAI and NVIDIA jointly cite are striking:
- 10+ gigawatts of NVIDIA systems committed by OpenAI.
- 100,000 GPUs in the first jointly-deployed GB200 NVL72 cluster.
- 35x lower cost per million tokens versus prior-generation systems.
- 50x higher token output per second per megawatt.
Translate that to product terms: every dollar of inference revenue GPT-5.5 generates now costs roughly one-thirty-fifth what the same revenue cost on last-generation infrastructure. That is the economics of a super-app. You cannot bundle three frontier products into one subscription at $20 per month on legacy GPU clusters. You can on GB200 NVL72.
NVIDIA also disclosed that over 10,000 NVIDIA employees have early access to GPT-5.5-powered Codex internally. That is the largest pre-launch enterprise dogfooding cohort ever reported for a frontier model. NVIDIA engineers report debugging cycles reduced from days to hours and end-to-end features shipping from natural-language prompts. Treat those numbers as marketing — they are — but the sample size is real.
Enterprise implications: Business and Enterprise tiers only
Here is the tier breakdown on day one:
- Free — still on older checkpoints, no GPT-5.5 access.
- Plus ($20 per month) — GPT-5.5 standard.
- Pro ($200 per month) — GPT-5.5 standard plus GPT-5.5 Pro.
- Business — GPT-5.5 standard plus GPT-5.5 Pro, Codex, admin controls.
- Enterprise — everything above, plus zero-data-retention, custom data residency, dedicated capacity.
NVIDIA already implemented zero-data retention with remote SSH connections to cloud VMs and sandboxed agents with read-only production access through command-line interfaces. That is the reference architecture OpenAI will sell to every regulated enterprise that calls in May 2026. Financial services, healthcare, and defense buyers all need exactly this pattern to greenlight agent deployments.
Our read on procurement: if you are a VP of Engineering at a 500 to 5,000-person company evaluating GPT-5.5 Business versus Claude Enterprise, the decision now comes down to four questions. Which model does your existing engineering team prefer on coding tasks? Which vendor's data-residency terms match your regulatory posture? Which ecosystem are your data sources already wired into? And — crucially — which vendor's pricing stays stable as you scale from 100 to 1,000 seats? OpenAI's GB200 cost curve should, in theory, let them hold pricing longer than competitors on legacy infra. We will see.

The safety side: enhanced safeguards and what they probably mean
OpenAI's press materials emphasized "enhanced safeguards" alongside the capability improvements. The company did not publish a detailed system card at launch, which is notable. GPT-5 and GPT-5.4 both shipped with simultaneous system card releases. GPT-5.5 did not.
Context: the Anthropic Mythos Discord breach and the broader security drama across the labs in April 2026 have made detailed safety disclosures a double-edged sword. Publish too much and you hand adversaries a map. Publish nothing and you lose trust signals with enterprise buyers. OpenAI appears to have chosen a middle path — public capability claims, private safety documentation shared under NDA with Business and Enterprise customers. This pattern tracks with what happened during the GPT-5.4-Cyber launch earlier in 2026.
Our view: the safeguards language is generic enough that independent evaluators cannot verify it this week. Expect the first third-party red-team reports by mid-May, and treat the enterprise-tier due-diligence discussions as the real transparency layer until then.
What we do not know yet: open questions
We are forty-eight hours post-launch. Here is what the public reporting does not yet answer:
- Context window. OpenAI did not disclose a token ceiling. Claude Opus 4.7 ships with 1M context. Gemini 3.1 Pro ships with 2M. If GPT-5.5 is below 500K, that is a material gap for long-document enterprise workflows.
- Independent benchmarks. No third-party scores yet. LiveBench, SWE-bench, HumanEval+, and MMLU-Pro results typically land seven to fourteen days post-launch.
- API pricing. OpenAI has not announced API pricing for GPT-5.5 through the developer platform. Enterprise subscription pricing is disclosed; raw API cost per million input and output tokens is not.
- Multimodal fluency. Press materials emphasize coding, research, and document creation. Native multimodal capability (vision, audio) is implied via Images 2.0 tool-calling but not documented as a first-class modality.
- AI browser timing. The third leg of the super-app stool remains unnamed and unshipped. Without a public ship date, the super-app narrative is aspirational.
- Deprecation timeline for GPT-5.4. No sunset date published. Enterprise teams running GPT-5.4 in production need this to plan migrations.
Our commitment: we will update this article with independent benchmarks, API pricing, and context-window disclosures as they land. The first-week narrative belongs to OpenAI. The first-month verdict belongs to the community.
What this means for the AI industry
Three takeaways we are confident in:
One: the super-app is now the dominant product thesis. Anthropic is the outlier with its deliberately narrow Claude Code bet. Google, OpenAI, Microsoft, and Meta are all converging on bundled multi-surface AI platforms. Expect the next twelve months to be defined by who can ship the most coherent integrated stack, not the highest benchmark score.
Two: release cadence is now a competitive weapon. Six weeks between flagship checkpoints is not a fluke. It is the new baseline. Vendors that cannot match it will lose mindshare even if their absolute quality is higher. The GB200 NVL72 economics are what make this cadence sustainable for OpenAI — other labs need their own version of that story.
Three: evaluation infrastructure needs to catch up. Independent benchmarks are now running two to three release cycles behind. The community needs faster, more rigorous evaluation pipelines, or the press will default to first-party claims indefinitely. This is a governance problem as much as a technical one.
For ThePlanetTools readers: if you are already on ChatGPT Plus or Pro, the upgrade is automatic. If you are evaluating enterprise AI for 2026 H2 procurement, put Claude Opus 4.7, Gemini 3.1 Pro, and GPT-5.5 Business on the same pilot and let your engineering team vote with their terminals. That is the only test that matters.
Frequently asked questions
When did OpenAI launch GPT-5.5?
OpenAI launched GPT-5.5 on Thursday, April 23, 2026, roughly six weeks after GPT-5.4. The model rolled out simultaneously to ChatGPT Plus, Pro, Business, and Enterprise subscribers, alongside the new Codex agent.
Who can access GPT-5.5?
All paid ChatGPT subscribers. Plus ($20 per month), Pro ($200 per month), Business, and Enterprise tiers receive GPT-5.5 standard. Pro, Business, and Enterprise users additionally get GPT-5.5 Pro. Free-tier users remain on older checkpoints for now.
What did Greg Brockman say about GPT-5.5?
Greg Brockman called GPT-5.5 "a real step forward towards the kind of computing that we expect in the future" and described it as enabling "more agentic and intuitive computing." The framing emphasizes agent initiation and reduced prompt-engineering overhead over raw chat capability.
How does GPT-5.5 compare to Claude Opus 4.7 and Gemini 3.1 Pro?
OpenAI claims internal benchmarks show GPT-5.5 outperforming both, but no independent third-party scores are available yet at launch. Our view: the three models are converging on similar capability envelopes, and differentiation in 2026 comes from distribution and ecosystem fit rather than raw intelligence.
What is the OpenAI super-app strategy?
OpenAI plans to combine ChatGPT, Codex, and a forthcoming AI browser into a single integrated service targeting enterprise customers. The super-app pattern mirrors WeChat and Grab but applied to AI — one subscription, multiple product surfaces powered by the same underlying model.
What infrastructure runs GPT-5.5?
GPT-5.5 runs on NVIDIA GB200 NVL72 rack-scale systems. OpenAI committed to deploying over 10 gigawatts of NVIDIA hardware, with the first joint cluster containing 100,000 GPUs. NVIDIA claims 35x lower cost per million tokens and 50x higher token output per second per megawatt versus prior-generation systems.
Why is the six-week cadence between GPT-5.4 and GPT-5.5 significant?
Historical frontier-model intervals averaged sixteen weeks in 2024 and ten weeks in 2025. Six weeks in 2026 represents a structural compression driven by cheaper inference infrastructure and competitive pressure from Anthropic and Google. It also means independent benchmarks now lag releases by two to three cycles.
Is GPT-5.5 connected to the OpenAI executive exits earlier in April?
The triple exit on April 17 (Weil, Peebles, Narayanan) and the Sora shutdown happened six days before the GPT-5.5 launch. Our read: the sequencing is intentional — shipping two frontier products in 48 hours (Images 2.0 on April 21 to 22, GPT-5.5 on April 23) reframes the weekly narrative from internal turbulence to product velocity.
What does GPT-5.5 mean for the leaked Dresser memo strategy?
The April 13 Dresser memo announced Spud, Frontier, and DeployCo as OpenAI's competitive responses to Anthropic. GPT-5.5 plus Codex is the first public delivery against that strategy — agentic capability packaged for enterprise distribution. Altman's April 21 "fear-based marketing" critique of Anthropic completes the narrative arc: ship product, not fear.
Does GPT-5.5 include image generation?
Not natively as a first-class modality, but TechCrunch reporting suggests GPT-5.5 can call GPT-Image-2 (Images 2.0) as a tool inside Codex sessions. The result is agents that generate, analyze, and revise images in a single run — the building block for the multimodal super-app OpenAI is pitching.
When will independent benchmarks for GPT-5.5 be available?
Typically seven to fourteen days post-launch. Expect LiveBench, SWE-bench, HumanEval+, and MMLU-Pro scores in the first two weeks of May 2026. Treat first-party performance claims as marketing until independent evaluators confirm them — a rule that applies to every frontier lab, not just OpenAI.
Should enterprises upgrade from GPT-5.4 to GPT-5.5 immediately?
For pilots and new deployments, yes — the capability and cost-per-token curves favor GPT-5.5. For production workloads already running on GPT-5.4, wait for OpenAI to publish a deprecation timeline and independent benchmarks before migrating. Our advice: pilot GPT-5.5 Business alongside Claude Opus 4.7 and Gemini 3.1 Pro, and let your engineering team vote with their terminals.