GLM-5.2 vs GPT-5.5: Open-Weight Challenger vs Closed Flagship (2026)


GLM-5.2 (open-weight, MIT, $4.40 out per M) vs GPT-5.5 (closed, $30 out per M). We tested both: who wins on cost, coding, and self-hosting.
Feature Comparison
| Feature | GLM-5.2 | GPT-5.5 |
|---|---|---|
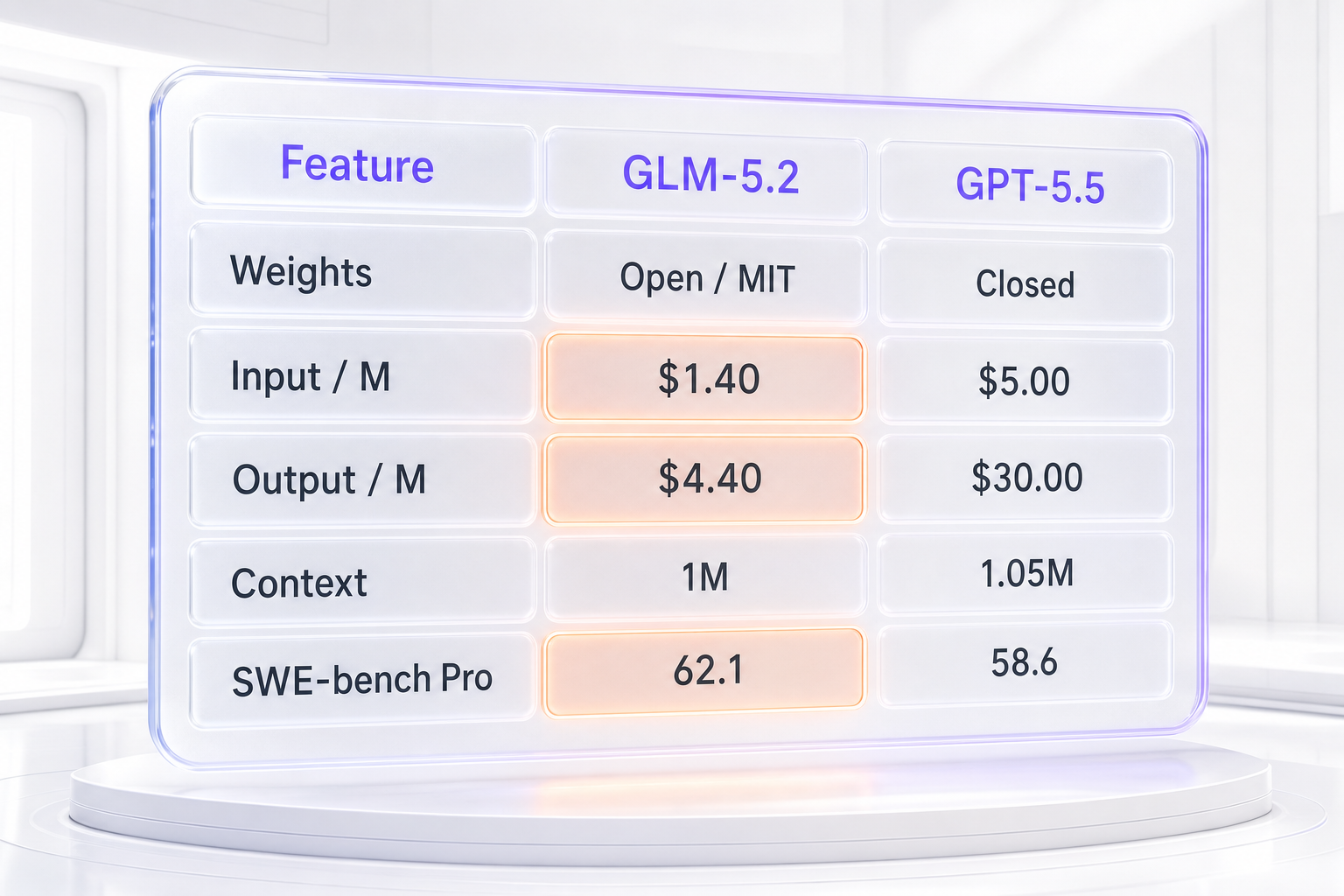
| Weights / openness | Open-weight, MIT license, on Hugging Face | Closed, API-only |
| Deployment | Self-host or z.ai API | OpenAI API / ChatGPT only |
| Input price (per 1M tokens) | $1.40 | $5.00 |
| Output price (per 1M tokens) | $4.40 | $30.00 |
| Cached input (per 1M tokens) | $0.26 | $0.50 |
| Context window | 1,000,000 tokens | ~1,050,000 tokens |
| Max output tokens | 128,000 | 128,000 |
| SWE-bench Pro (vendor-reported) | 62.1 | 58.6 |
| Humanity's Last Exam (vendor-reported) | 40.5 | 41.4 |
| Ecosystem / integrations | Growing (HF, Together, self-host) | Mature; broadest third-party support |
| Published safety / system card | No formal model card yet | Public system card + Deployment Safety Hub |
Pricing Comparison
GLM-5.2
GPT-5.5
Detailed Comparison
GLM-5.2 and GPT-5.5 are not the same kind of product, and that is exactly the point of this comparison. GLM-5.2 is Zhipu AI's open-weight flagship — a 753B-parameter Mixture-of-Experts model (roughly 40B active per token), released under an MIT license with downloadable weights on Hugging Face, priced at $1.40 per million input tokens and $4.40 per million output tokens. GPT-5.5 is OpenAI's closed, API-only flagship, priced at $5 per million input tokens and $30 per million output tokens. On output cost, GLM-5.2 is roughly 6.8 times cheaper. On the SWE-bench Pro coding benchmark each vendor publishes, GLM-5.2 scores 62.1 and GPT-5.5 scores 58.6. If you can self-host or accept a Chinese-lab open model, GLM-5.2 wins on cost and deployment freedom; if you want the most polished managed flagship with OpenAI's ecosystem and safety reporting, GPT-5.5 is still the safer default. We ran both side-by-side to find where each one actually earns its place.
Quick Verdict
We tested both as coding and agentic workhorses over a week of side-by-side prompts. Here is the short version before the detail.
- Best for cost-sensitive coding and self-hosting: GLM-5.2. Output tokens cost $4.40 per million versus $30 per million for GPT-5.5 — about 6.8 times less — and you can download the weights and run them on your own GPUs.
- Best for a polished managed flagship and ecosystem: GPT-5.5. It ships inside ChatGPT and the OpenAI API with a published system card, mature tooling, and the broadest third-party integration surface.
- Best published coding benchmark: GLM-5.2, narrowly — 62.1 on SWE-bench Pro versus 58.6 for GPT-5.5 (each number self-reported by its vendor; read the caveats below).
- Best for open-weight freedom and licensing: GLM-5.2. MIT license, weights on Hugging Face, full self-host. GPT-5.5 is closed and API-only.
- Best for safety documentation and compliance trail: GPT-5.5, with a public system card and Deployment Safety Hub. GLM-5.2 has not published a comparable formal model card.
Our verdict: there is no single winner, because these models answer different questions. If the question is "how do I get strong agentic coding for the lowest possible token cost, with the option to self-host," GLM-5.2 is the better pick and it is not close on price. If the question is "what is the most reliable, best-supported managed flagship for a US-based team that values vendor accountability," GPT-5.5 earns its premium. Pick GLM-5.2 to save money and own your stack; pick GPT-5.5 to buy polish, support, and a paper trail.
GLM-5.2 and GPT-5.5 at a Glance
GLM-5.2 is the flagship release from Zhipu AI (z.ai), shipped on June 13, 2026, as an open-weight Mixture-of-Experts model. Zhipu positions it as a coding-first, long-horizon model: the headline pitch is a "truly usable" 1M-token context that holds up across long agentic sessions. The weights are published on Hugging Face under an MIT license, which is unusually permissive for a model of this size — you can download it, fine-tune it, and deploy it commercially without a separate license negotiation. API access is also available directly from z.ai at $1.40 per million input tokens and $4.40 per million output tokens, or bundled into a GLM Coding Plan starting at $18 per month. If you are weighing GLM-5.2 against another Chinese open-weight option, we also put it head-to-head in GLM-5.2 vs Kimi K2.7-Code.
GPT-5.5 is OpenAI's flagship reasoning and agentic model, launched on April 23, 2026, described by OpenAI as its strongest agentic coding model to date. It is closed-weight and API-only: you reach it through the OpenAI API or inside ChatGPT (Plus, Pro, Business, and Enterprise tiers), and there is no way to download or self-host it. Standard API pricing is $5 per million input tokens and $30 per million output tokens, with cached input at $0.50 per million; a higher-end GPT-5.5-pro variant runs $30 per million input and $180 per million output. OpenAI ships a public system card on its Deployment Safety Hub, which matters for teams that need a documented safety and evaluation trail.
So the framing is honest: this is an open-weight, low-cost challenger against a closed, premium flagship. They overlap heavily on the job — agentic coding, long-context reasoning, tool use — which is why a side-by-side is fair. They diverge sharply on price, openness, and the surrounding ecosystem, which is where your decision actually gets made.
How We Tested Both
We ran GLM-5.2 and GPT-5.5 side-by-side over a week, on identical prompts, to keep the comparison fair. We accessed GLM-5.2 through the z.ai API and GPT-5.5 through the OpenAI API, sending each the same task in the same order and judging the outputs against the same bar. Our test set was deliberately coding- and agent-heavy, because that is what both models are built for and what most of our readers will use them for: a multi-file refactor of a small TypeScript service, debugging a deliberately broken test suite, writing a CLI tool from a written spec, and a long-horizon agentic task that required reading a repository, drafting a plan, and executing edits across several files.
Two honesty notes about our methodology. First, we judged outputs qualitatively — runnable code, correctness on first attempt, recovery after a failure, and how well each model held context across a long session — rather than running a formal benchmark harness ourselves. Where we cite numbers, they are the vendors' own published figures, clearly labeled as such, not numbers we generated. Second, we used each model at its default settings through its standard API; we did not fine-tune GLM-5.2 or use any non-default reasoning configuration on GPT-5.5, so what we describe is the out-of-the-box experience a typical developer would get. We confirmed every price and specification in this comparison directly from each vendor's documentation in June 2026.
Side-by-Side Comparison Table
| Feature | GLM-5.2 (Zhipu) | GPT-5.5 (OpenAI) | Edge |
|---|---|---|---|
| Vendor / origin | Zhipu AI (z.ai), China | OpenAI, United States | Tie |
| Weights / openness | Open-weight, MIT license, on Hugging Face | Closed, API-only | GLM-5.2 |
| Deployment | Self-host or z.ai API | OpenAI API / ChatGPT only | GLM-5.2 |
| Input price (per 1M tokens) | $1.40 | $5.00 | GLM-5.2 |
| Output price (per 1M tokens) | $4.40 | $30.00 | GLM-5.2 |
| Cached input (per 1M tokens) | $0.26 | $0.50 | GLM-5.2 |
| Context window | 1,000,000 tokens | ~1,050,000 tokens | Tie |
| Max output tokens | 128,000 | 128,000 | Tie |
| Architecture | 753B total MoE (~40B active per token) | Not disclosed by OpenAI | Tie |
| SWE-bench Pro (vendor-reported) | 62.1 | 58.6 | GLM-5.2 |
| Humanity's Last Exam (vendor-reported) | 40.5 | 41.4 | GPT-5.5 |
| Ecosystem / integrations | Growing; HF, Together, self-host | Mature; broadest third-party support | GPT-5.5 |
| Published safety / system card | No formal model card yet | Public system card + Deployment Safety Hub | GPT-5.5 |
| Knowledge cutoff | Not disclosed | December 1, 2025 | GPT-5.5 |
A note on the benchmark rows before anyone over-reads them: SWE-bench Pro and Humanity's Last Exam are the two benchmarks where both vendors publish a directly comparable number, so those are the only head-to-head benchmark cells we include. Each figure is self-reported by the model's own vendor, not from a neutral third party, so treat the small gaps (62.1 vs 58.6; 40.5 vs 41.4) as "roughly even" rather than decisive. We deliberately do not put GLM-5.2's Terminal-Bench 2.1 score next to GPT-5.5's Terminal-Bench 2.0 score in the same row, because they are different benchmark versions and comparing them directly would be misleading.
Pricing Compared: Where the Gap Is Brutal
This is the single biggest reason to read this comparison, so we will be precise. All figures below are token-based and were confirmed directly from each vendor's pricing documentation.
GLM-5.2 pricing
- Input: $1.40 per million tokens
- Output: $4.40 per million tokens
- Cached input: $0.26 per million tokens
- GLM Coding Plan: from $18 per month (bundled usage for coding workflows)
GPT-5.5 pricing
- Input: $5.00 per million tokens (standard)
- Output: $30.00 per million tokens (standard)
- Cached input: $0.50 per million tokens
- Batch and Flex tiers: $2.50 input and $15 output per million tokens
- GPT-5.5-pro variant: $30 input and $180 output per million tokens
The practical takeaway: on input, GPT-5.5 costs about 3.6 times more than GLM-5.2; on output, it costs roughly 6.8 times more. Output is where coding and agentic workloads burn most of their tokens, because the model is writing code, reasoning out loud, and iterating. In our week of side-by-side testing on the same set of coding tasks, GLM-5.2's output-heavy nature meant the cost difference compounded fast — a long agentic refactor that cost us a couple of dollars on GLM-5.2 would have cost meaningfully more on standard GPT-5.5. If you run GPT-5.5 on its Batch or Flex tier ($2.50 input and $15 output per million tokens) the gap narrows, but GLM-5.2 is still cheaper per output token, and Batch trades latency for that price. If your monthly token bill is the constraint, GLM-5.2 is the obvious answer and the math is not subtle.
A concrete cost example
To make the gap tangible, take a simple, round scenario: a team that consumes 50 million input tokens and 50 million output tokens in a month — a realistic load for an active agentic-coding workflow. On GLM-5.2 that is roughly $70 of input ($1.40 per million times 50) plus $220 of output ($4.40 per million times 50), for about $290 a month. On standard GPT-5.5 the same volume is roughly $250 of input ($5 per million times 50) plus $1,500 of output ($30 per million times 50), for about $1,750 a month. Same token volume, and GPT-5.5 costs roughly six times more. Caching and the Batch tier can pull GPT-5.5's number down, and GLM-5.2's GLM Coding Plan from $18 per month can change the math for lighter, more interactive usage. But the headline holds across almost any realistic mix: for output-heavy work at scale, GLM-5.2 is dramatically cheaper, and that difference flows straight to your margins.
Coding and Agentic Performance
Both models are pitched first and foremost as coding and agentic engines, so this is where we spent most of our hands-on time. We ran both on the same prompts: multi-file refactors, debugging a failing test suite, writing a small CLI from a spec, and a long-horizon agentic task that required reading a repository, planning, and executing edits across several files.
On raw coding quality, the two were closer than the price gap suggests. GLM-5.2 held its own on multi-file edits and produced clean, runnable code more often than we expected from an open-weight model at this price point. Its 1M-token context genuinely helped on the repository-reading task — it kept earlier files in mind without us re-pasting them. GPT-5.5 felt slightly more consistent on the trickiest reasoning steps and recovered more gracefully when a first attempt failed, which lines up with OpenAI positioning it as their strongest agentic coding model. On the vendor-published numbers, GLM-5.2 edges ahead on SWE-bench Pro (62.1 vs 58.6), while GPT-5.5 reports a strong 82.7 on Terminal-Bench 2.0 and GLM-5.2 reports 81.0 on Terminal-Bench 2.1 — close, but different benchmark versions, so we will not declare a winner there.
Our honest read after a week: for the large majority of day-to-day coding and agentic work, GLM-5.2 is good enough that the 6.8x output-cost saving is hard to argue against. GPT-5.5 buys you a little more reliability at the hard edges and a more mature agentic tool-use experience, which can be worth it on high-stakes, low-tolerance tasks. Neither model embarrassed itself; the decision is about how much you value the last few percent of consistency versus the very large difference in cost.
Deployment, Openness, and Control
This is the axis where the two models are not even playing the same sport. GLM-5.2 ships its weights on Hugging Face under an MIT license. That means you can download the model, run it on your own GPUs or a GPU cloud, fine-tune it on private data, and never send a token to a third-party API if you do not want to. For teams with data-residency requirements, air-gapped environments, or a strong preference for owning their inference stack, that is a decisive advantage — and the MIT license is about as permissive as open licenses get, with no usage caps or field-of-use restrictions baked in.
GPT-5.5 is closed and API-only. You cannot download it, you cannot self-host it, and your data flows through OpenAI's infrastructure under OpenAI's terms. In exchange, you get zero operational burden: no GPUs to provision, no inference engine to tune, no model-serving uptime to own. For most teams that just want the model to work, that trade is fine and even preferable. But if control, customization, or self-hosting matter to you at all, GLM-5.2 is the only one of the two that can do it.
One honest caveat on GLM-5.2: it is a Chinese-lab model, and some organizations have procurement, compliance, or geopolitical-risk policies that restrict using Chinese AI models regardless of license or quality. That is not a quality judgment — GLM-5.2 is genuinely strong — but it is a real-world constraint that can take the open-weight option off the table for some buyers before performance even enters the conversation. If that describes your organization, GPT-5.5 (or another US/EU-origin flagship) is your lane.
Context Window and Long-Horizon Reasoning
Both models are built around very large context windows: 1M tokens for GLM-5.2 and roughly 1.05M for GPT-5.5, each with a 128,000-token maximum output. In practice the difference between 1M and 1.05M is noise — both comfortably swallow large codebases, long documents, and extended agentic histories. What matters more is how usable that context actually is over a long session, and here Zhipu's pitch for GLM-5.2 is specifically about "long-horizon" stability: keeping coherence across many turns rather than degrading as the window fills.
In our testing, both held context well on the repository-reading task. GLM-5.2 reports an AIME 2026 score of 99.2 and an HLE Reasoning score of 40.5; GPT-5.5 reports a 41.4 on Humanity's Last Exam. The HLE numbers are close enough to call even. We did not see a meaningful long-context advantage for either model in our prompts — both kept track of what they needed to. If your workload is genuinely context-bound (huge repos, long agentic chains), either model will serve you, and the decision falls back to cost and deployment rather than context capacity.
Ecosystem, Tooling, and Support
Raw model quality is only half of what you actually buy. The other half is the ecosystem around it — the SDKs, the integrations, the documentation, the community, and the support you can lean on when something breaks. Here the two models are at very different stages of maturity.
GPT-5.5 inherits OpenAI's enormous head start. Nearly every agent framework, IDE assistant, observability tool, and orchestration layer in the market supports the OpenAI API first and best. If you are wiring a model into an existing stack, the odds are overwhelming that GPT-5.5 drops in with minimal friction. OpenAI's documentation is thorough, its SDKs are stable, and its system card gives risk and compliance teams something concrete to review. For a team that wants to ship without becoming infrastructure experts, that surrounding maturity is a real part of the value — and part of what the premium price pays for.
GLM-5.2's ecosystem is younger but moving fast. The weights are on Hugging Face, it is served by third-party inference providers such as Together AI, and the standard open-weight tooling (vLLM-style serving, Hugging Face libraries, GPU-cloud deployment guides) works with it the way it works with other open models. The trade-off is that you may do more integration work yourself, and you will not find the same depth of first-party tooling or the same volume of community answers to obscure problems that OpenAI has accumulated over years. For teams comfortable in the open-weight world, none of this is a blocker; for teams that want everything to "just work" out of a single vendor's polished surface, it is a genuine gap that favors GPT-5.5.
One more practical dimension: accountability. With GPT-5.5 you have a single commercial vendor, a published safety document, and a support relationship. With self-hosted GLM-5.2 you own the stack, which means you also own the failures — there is no vendor SLA when your own inference cluster has a bad night. Some teams want that control; others would rather pay OpenAI to carry it. Neither answer is wrong, but it is a real difference in who is responsible when things go sideways.
If your real shortlist is "the best premium flagship" rather than "open versus closed," it is worth seeing how GPT-5.5 stacks up against its closest rivals too. We compared it directly in Claude Opus 4.8 vs GPT-5.5, Claude Opus 4.7 vs GPT-5.5, and Claude Fable 5 vs GPT-5.5 — useful if a closed flagship is where you are going to land regardless of the open-weight option.
Pros and Cons
GLM-5.2
Pros
- Roughly 6.8x cheaper on output tokens than standard GPT-5.5
- Open-weight under a permissive MIT license
- Weights downloadable on Hugging Face; full self-host possible
- Strong vendor-published coding benchmark (62.1 SWE-bench Pro)
- Usable 1M-token context for long-horizon coding
Cons
- Chinese-lab origin may be blocked by some procurement or compliance policies
- No formal published model card or system card yet
- Smaller, less mature third-party ecosystem than OpenAI
- Exact active-parameter count not formally disclosed
- Self-hosting a 753B MoE requires serious GPU resources
GPT-5.5
Pros
- OpenAI's strongest agentic coding model, with a polished managed experience
- Broadest third-party integration and tooling ecosystem
- Public system card and Deployment Safety Hub for a documented compliance trail
- Zero operational burden — no GPUs or inference to manage
- Available inside ChatGPT and the OpenAI API across multiple tiers
Cons
- About 6.8x more expensive on output tokens than GLM-5.2
- Closed and API-only — no self-hosting or weight download
- Your data flows through OpenAI's infrastructure under OpenAI's terms
- The GPT-5.5-pro tier ($30 input, $180 output per million) is very pricey
- No customization beyond what the API exposes
When to Pick Which
Pick GLM-5.2 if…
- Token cost is your primary constraint — especially output-heavy coding and agentic workloads.
- You want to self-host, fine-tune, or keep inference inside your own infrastructure.
- You need a permissive license (MIT) without field-of-use restrictions.
- Your organization has no policy against Chinese-origin models.
- You are building at scale and a 6.8x output-cost difference moves your unit economics.
Pick GPT-5.5 if…
- You want the most polished, best-supported managed flagship with minimal operational overhead.
- You need a documented safety and evaluation trail (system card) for compliance or procurement.
- Your organization restricts non-US/EU AI models.
- You rely on OpenAI's mature ecosystem, integrations, and ChatGPT distribution.
- The last few percent of reliability on hard tasks matters more to you than token cost.
Our Verdict: Different Questions, Different Winners

After a week running both side-by-side, our verdict is deliberately split, because pretending one model "wins" would be dishonest. These two answer different questions.
If you are cost-sensitive, build at scale, or want to own your inference stack, GLM-5.2 is the better choice — and the 6.8x output-cost advantage, the MIT license, and the downloadable weights make it not close on those axes. Its coding quality is genuinely strong, its vendor-published SWE-bench Pro number edges GPT-5.5, and for the large majority of day-to-day work it is good enough that the savings are hard to argue with.
If you want the most polished managed flagship, need a documented safety trail, or operate under policies that rule out Chinese-origin models, GPT-5.5 earns its premium. It is OpenAI's strongest agentic coding model, it ships with a public system card, and it carries the broadest ecosystem and the least operational burden. You are paying roughly 6.8 times more per output token for polish, support, and accountability — and for some teams that is exactly the right trade.
Our bottom line: pick GLM-5.2 to save money and own your stack; pick GPT-5.5 to buy polish, support, and a paper trail. Both are excellent at the actual job of writing and reasoning about code. The decision is not about which is "smarter" — they are close — it is about cost, control, and your organization's constraints. Be honest with yourself about which of those matters most, and the answer falls out cleanly.
Frequently Asked Questions
Is GLM-5.2 cheaper than GPT-5.5?
Yes, substantially. GLM-5.2 costs $1.40 per million input tokens and $4.40 per million output tokens, while GPT-5.5 costs $5 per million input tokens and $30 per million output tokens at standard pricing. That makes GLM-5.2 about 3.6 times cheaper on input and roughly 6.8 times cheaper on output. Since coding and agentic workloads are output-heavy, the real-world savings with GLM-5.2 are large.
Is GLM-5.2 open-source or open-weight?
GLM-5.2 is open-weight: Zhipu AI publishes the model weights on Hugging Face under an MIT license, so you can download, fine-tune, and self-host it commercially. GPT-5.5 is the opposite — it is closed and API-only, with no way to download or self-host. If owning your inference stack matters, GLM-5.2 is the only one of the two that allows it.
Which is better for coding, GLM-5.2 or GPT-5.5?
They are close. On the SWE-bench Pro benchmark each vendor reports, GLM-5.2 scores 62.1 and GPT-5.5 scores 58.6. In our hands-on testing GLM-5.2 produced clean, runnable code reliably, while GPT-5.5 felt slightly more consistent on the hardest reasoning steps. For most coding work GLM-5.2 is good enough that its much lower cost wins; for high-stakes tasks where the last few percent of reliability matters, GPT-5.5 has a small edge.
Can I self-host GLM-5.2?
Yes. Because GLM-5.2's weights are published on Hugging Face under an MIT license, you can deploy it on your own GPUs or a GPU cloud and run inference entirely in your own environment. Note that it is a 753B-parameter Mixture-of-Experts model, so self-hosting requires significant GPU resources. GPT-5.5 cannot be self-hosted at all — it is API-only.
What is the context window of GLM-5.2 versus GPT-5.5?
GLM-5.2 has a 1,000,000-token context window and GPT-5.5 has roughly 1,050,000 tokens; both support a 128,000-token maximum output. In practice the difference is negligible — both comfortably handle large codebases, long documents, and extended agentic sessions. Context capacity is not a meaningful differentiator between the two.
Why compare an open-weight Chinese model to a closed US flagship?
Because that contrast is the decision many teams actually face in 2026: a low-cost, self-hostable open-weight model versus a premium, fully managed closed flagship. GLM-5.2 and GPT-5.5 overlap heavily on the job — agentic coding, long-context reasoning, tool use — which makes a side-by-side fair. They diverge on cost, openness, and ecosystem, which is exactly where the choice gets made.
Are the benchmark numbers in this comparison independently verified?
No. The benchmark scores cited here are self-reported by each model's own vendor, not produced by a neutral third party. That is why we only compare the two benchmarks where both vendors publish a directly comparable figure (SWE-bench Pro and Humanity's Last Exam), and why we treat the small gaps as "roughly even" rather than decisive. We also avoid comparing GLM-5.2's Terminal-Bench 2.1 score against GPT-5.5's Terminal-Bench 2.0 score, since they are different benchmark versions.
Does GPT-5.5 have anything GLM-5.2 cannot match?
Yes — a few things. GPT-5.5 ships with a public system card on OpenAI's Deployment Safety Hub, giving teams a documented safety and evaluation trail that GLM-5.2 has not published in comparable form. It also has the broadest third-party ecosystem and integration support, and it removes all operational burden since there are no GPUs or inference to manage. For compliance-driven or low-overhead teams, those advantages can outweigh the cost gap.
Is there any reason not to use GLM-5.2 despite the price advantage?
Two practical reasons. First, GLM-5.2 is a Chinese-lab model, and some organizations have procurement, data-governance, or geopolitical-risk policies that restrict Chinese AI models regardless of license or quality. Second, it lacks a formal published model card and a mature ecosystem, which matters for some compliance and integration needs. If neither constraint applies to you, the cost and openness advantages are hard to pass up.
How much does GLM-5.2's coding plan cost compared to ChatGPT?
Zhipu offers a GLM Coding Plan starting at $18 per month that bundles usage for coding workflows, alongside pay-as-you-go API pricing at $1.40 input and $4.40 output per million tokens. GPT-5.5 is reached either through the OpenAI API at $5 input and $30 output per million tokens, or inside ChatGPT's Plus, Pro, Business, and Enterprise subscription tiers. For heavy API usage the token-cost gap dominates; for light interactive use a flat subscription may suit either side.
Which model should a startup building at scale choose?
For most startups whose unit economics depend on token cost, GLM-5.2 is the stronger default — a roughly 6.8x output-cost saving directly improves margins, and the option to self-host caps your inference costs as you grow. Choose GPT-5.5 instead if you need its mature ecosystem, a documented safety trail for enterprise customers, or you operate under policies that rule out Chinese-origin models. The right answer follows your constraints, not a single benchmark.
Last compared: June 2026. Pricing and specifications were confirmed directly from each vendor's documentation (z.ai and OpenAI). Benchmark figures are vendor-reported and not independently verified. ThePlanetTools has no affiliate relationship with Zhipu AI or OpenAI for this comparison.
Our Verdict
There is no single winner — these two answer different questions. GLM-5.2 wins decisively on cost (roughly 6.8x cheaper on output tokens), open-weight MIT licensing, and self-hosting freedom, while edging GPT-5.5 on the vendor-published SWE-bench Pro number (62.1 vs 58.6). GPT-5.5 wins on ecosystem maturity, a public system card for compliance, and the least operational burden. Pick GLM-5.2 to save money and own your stack; pick GPT-5.5 to buy polish, support, and a paper trail — and note that some organizations cannot use a Chinese-lab model regardless of quality.
Choose GLM-5.2
Zhipu AI open-weight coding flagship: 753B MoE (~40B active), 1M context, MIT license, headline SWE-bench Pro 62.1 (vendor self-reported); GLM Coding Plan from around $18 per month or $1.40 in / $4.40 out per million tokens.
Try GLM-5.2 →Choose GPT-5.5
OpenAI's first fully retrained base model since GPT-4.5 — agentic, faster, and double the API price.
Try GPT-5.5 →Frequently Asked Questions
Is GLM-5.2 better than GPT-5.5?
There is no single winner — these two answer different questions. GLM-5.2 wins decisively on cost (roughly 6.8x cheaper on output tokens), open-weight MIT licensing, and self-hosting freedom, while edging GPT-5.5 on the vendor-published SWE-bench Pro number (62.1 vs 58.6). GPT-5.5 wins on ecosystem maturity, a public system card for compliance, and the least operational burden. Pick GLM-5.2 to save money and own your stack; pick GPT-5.5 to buy polish, support, and a paper trail — and note that some organizations cannot use a Chinese-lab model regardless of quality.
Which is cheaper, GLM-5.2 or GPT-5.5?
GLM-5.2 is priced at $1.4 in / $4.4 out per M tokens. GPT-5.5 is priced at $5 in / $30 out per M tokens. Check the pricing comparison section above for a full breakdown.
What are the main differences between GLM-5.2 and GPT-5.5?
The key differences span across 11 features we compared. For Weights / openness, GLM-5.2 offers Open-weight, MIT license, on Hugging Face while GPT-5.5 offers Closed, API-only. For Deployment, GLM-5.2 offers Self-host or z.ai API while GPT-5.5 offers OpenAI API / ChatGPT only. For Input price (per 1M tokens), GLM-5.2 offers $1.40 while GPT-5.5 offers $5.00. See the full feature comparison table above for all details.