Claude Fable 5 vs GPT-5.5: Anthropic's Frontier Tier vs OpenAI's Flagship (2026)


Fable 5 reports 80.3% SWE-bench Pro vs 58.6% for GPT-5.5 — at twice the price ($10 vs $5 input, $50 vs $30 output per million). Our split 2026 verdict.

Feature Comparison
| Feature | Claude Fable 5 | GPT-5.5 |
|---|---|---|
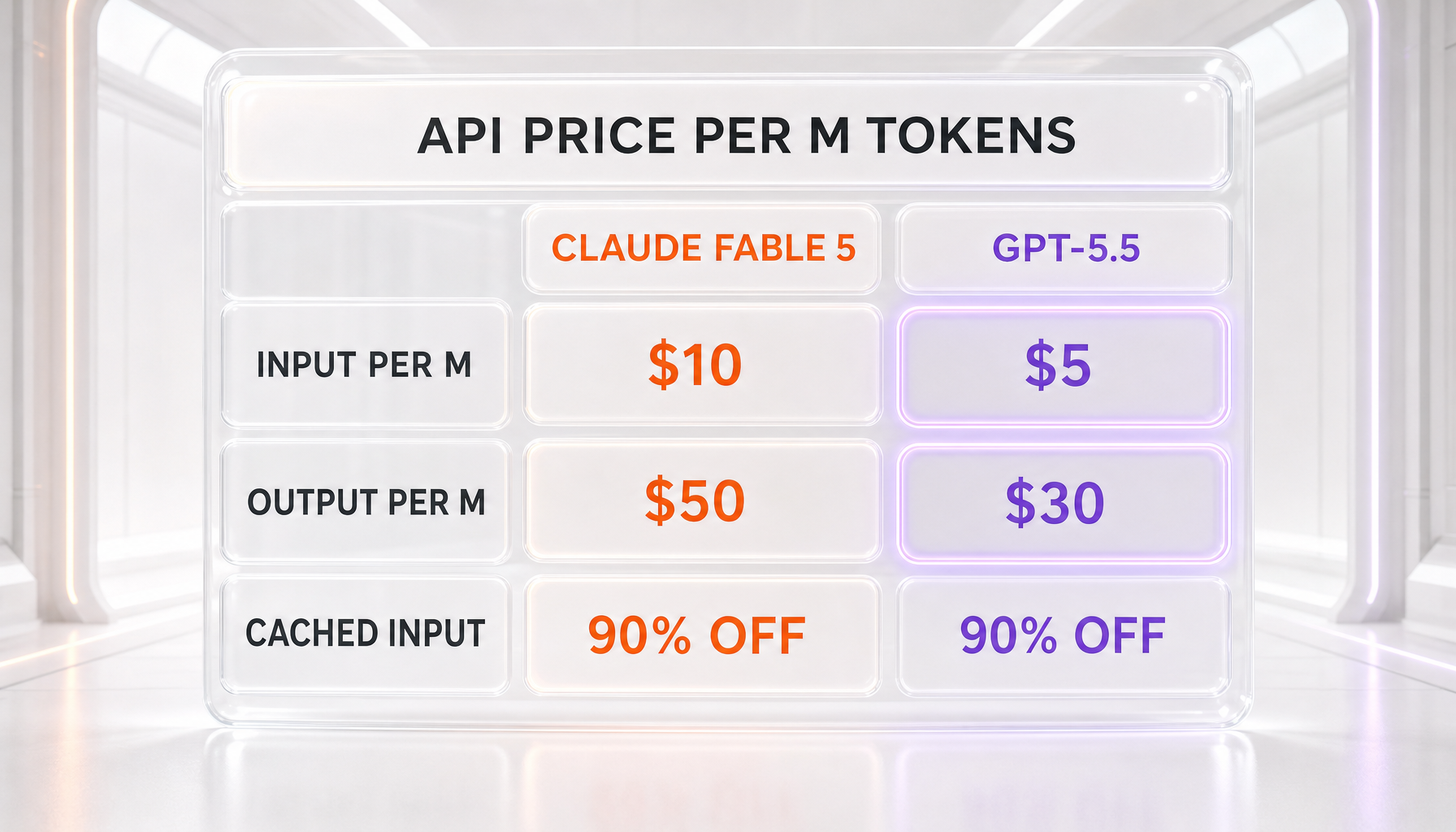
| API input price (per million tokens) | $10.00 (verified) | $5.00 (verified) |
| API output price (per million tokens) | $50.00 (verified) | $30.00 (verified) |
| SWE-bench Pro (agentic coding, like-for-like) | 80.3% (early third-party reports) | 58.6% (OpenAI reports) |
| SWE-bench Verified (different benchmark) | Not published the same way | 88.7% (OpenAI reports) |
| GDPval-AA (economic-value tasks, third-party) | ~1932 (Artificial Analysis, early) | Not in our verified set |
| Declared context window | 1,000,000 tokens (128K output) | 1,050,000 tokens (128K output) |
| Reasoning control | Adaptive thinking always on — no off switch | Five effort levels (none to xhigh) |
| Refusal and fallback handling | stop_reason refusal as HTTP 200, auto-fallback to Opus 4.8, refusals not billed | Standard API refusals |
| Data retention | Mandatory 30-day retention (Covered Model), no zero-data-retention option | Standard OpenAI API data controls |
| Prompt caching discount | 90% on cached input | 90% on cached input ($0.50 per million cached) |
| Agent toolkit | Effort parameter, task budgets (beta), memory tool, context editing, compaction | Function calling, structured outputs, web search, file search, code interpreter, computer use, MCP |
| Ecosystem / distribution | Claude API, Bedrock, Vertex AI, Microsoft Foundry, Claude Code, GitHub Copilot | ChatGPT, Codex, OpenAI API |
Pricing Comparison
Claude Fable 5
GPT-5.5
Detailed Comparison
Claude Fable 5 and GPT-5.5 are the two most capable frontier models from Anthropic and OpenAI being compared here. Claude Fable 5 is Anthropic's most capable widely released model, generally available June 9, 2026, priced at $10 per million input tokens and $50 per million output tokens with a 1,000,000-token context window. GPT-5.5 is OpenAI's flagship, launched April 23, 2026, priced at $5 per million input tokens and $30 per million output tokens with a reported 1,050,000-token context. On SWE-bench Pro — the one agentic coding benchmark reported the same way for both — early third-party coverage puts Fable 5 at 80.3 percent versus OpenAI's reported 58.6 percent for GPT-5.5. Fable 5 leads raw capability; GPT-5.5 wins price and ecosystem. Best for the hardest agentic work: Claude Fable 5. Best for value, routine coding, and distribution: GPT-5.5.
Quick Verdict
This is a split verdict: Claude Fable 5 takes raw capability, GPT-5.5 takes value — and the price gap is too large to ignore. Fable 5 went generally available on June 9, 2026, and we moved it into our production stack the same day, running it side-by-side with GPT-5.5 — the model we have used daily since April — on the same tasks. That gives us roughly 48 hours of direct side-by-side use at the time of writing, not weeks, so we scope every hands-on claim accordingly and lean on attributed benchmarks where our own time is too short. We verified both models' pricing directly on the vendors' pages on June 10, 2026. Here is the short version.
- Best for the hardest agentic work: Claude Fable 5. On SWE-bench Pro — the one agentic coding benchmark where figures exist for both models on the same harness — early third-party coverage reports 80.3 percent for Fable 5 versus OpenAI's reported 58.6 percent for GPT-5.5. That is a 21.7-point gap on the like-for-like evidence.
- Best for price: GPT-5.5, by a mile. At $5 per million input and $30 per million output tokens (verified), it costs half of Fable 5's $10 input rate and 40 percent less than its $50 output rate (verified). A representative agentic call is nearly twice as expensive on Fable 5.
- Best on SWE-bench Verified: GPT-5.5, where measured. OpenAI officially reports 88.7 percent on SWE-bench Verified — a different, older benchmark than SWE-bench Pro. Fable 5 has no published Verified figure the same way, so this is a one-sided data point, not a head-to-head.
- Best for production failure handling: Claude Fable 5. Refusals come back as a clean HTTP 200 with stop_reason refusal, the fallbacks parameter auto-retries on Claude Opus 4.8, and refused-before-output requests are not billed. Anthropic says fallbacks trigger in less than 5 percent of sessions.
- Best for compliance flexibility: GPT-5.5. Fable 5 is a Covered Model with mandatory 30-day data retention and no zero-data-retention option; GPT-5.5 runs under OpenAI's standard API data controls.
- Best for ecosystem: GPT-5.5. ChatGPT, Codex, and the OpenAI API remain the widest distribution surface in 2026 — though Fable 5 launched day-one on Bedrock, Vertex AI, Microsoft Foundry, and GitHub Copilot, which is unusually broad for an Anthropic flagship.
The honest caveat up front: Fable 5's headline benchmark numbers — SWE-bench Pro around 80.3 percent and a GDPval-AA score near 1932 — do not appear on Anthropic's own announcement page. They come from early third-party coverage relaying launch materials, and they are not yet independently reproduced. We attribute every figure to its exact benchmark and source below, and we flag the SWE-bench Pro versus SWE-bench Verified confusion explicitly, because it is the single most misleading comparison floating around this matchup.
Claude Fable 5 vs GPT-5.5 — Overview
What Is Claude Fable 5?
Claude Fable 5 is Anthropic's most capable widely released model, generally available since June 9, 2026, with a rolling rollout through June 22. We review it in depth in our Claude Fable 5 review (our score: 9.6 out of 10). It sits in its own tier above Claude Opus 4.8 — the first public model of Anthropic's Mythos class, the capability tier that previously lived behind the invitation-only Project Glasswing program. Mythos 5, the same underlying model with some safeguards lifted, stays reserved for vetted cybersecurity professionals; Fable 5 is the public, safety-classified version. API pricing is $10 per million input tokens and $50 per million output tokens — double Claude Opus 4.8 on both sides — which we verified directly on Anthropic's announcement page on June 10, 2026. Per Anthropic's API documentation it runs a 1,000,000-token context window with up to 128,000 output tokens, adaptive thinking that is always on and cannot be disabled, and a production-grade refusal design: declined requests return stop_reason refusal as a clean HTTP 200, an optional fallbacks parameter auto-retries on Claude Opus 4.8, and you are not billed for requests refused before output. It is also a Covered Model: all traffic carries a mandatory 30-day retention window with no zero-data-retention option. We walked through the launch in our Claude Fable 5 launch coverage.
What Is GPT-5.5?
GPT-5.5 is OpenAI's flagship general-purpose model, launched April 23, 2026, and the company's first fully retrained base model since GPT-4.5 — every release from 5.0 through 5.4 was a post-training iteration on the same foundation, while 5.5 (codenamed Spud during training) rebuilt it from scratch. See our full GPT-5.5 review (our score: 8.6 out of 10) and our GPT-5.5 launch coverage for the detail. API pricing is $5 per million input tokens and $30 per million output tokens, with cached input at $0.50 per million and Batch mode at half price — all of which we verified directly on OpenAI's API pricing docs on June 10, 2026. OpenAI reports a 1,050,000-token context window with 128,000 max output tokens, a five-level reasoning effort scale from none to xhigh, and a complete agentic tool stack on by default: function calling, structured outputs, web search, file search, code interpreter, computer use, and MCP client support. Its headline coding number is an officially reported 88.7 percent on SWE-bench Verified; on the harder SWE-bench Pro, OpenAI's reported figure is 58.6 percent — and keeping those two benchmarks separate is essential to comparing it honestly against Fable 5.
How We Compared Them — and What We Did Not Do
Method transparency matters more than usual here, because Fable 5 is about 24 hours old at the time of writing and the benchmark discourse around this matchup is already a mess. Here is exactly what we did and did not do.
- Pricing: fetched directly from both vendors on June 10, 2026. Fable 5's $10 input and $50 output per million tokens is verified against Anthropic's official announcement; GPT-5.5's $5 input and $30 output per million is verified against OpenAI's API pricing documentation. Both are fully verified — no relayed figures this time.
- Benchmarks: we only declare a winner where both models have figures on the same benchmark, same harness. That happens once in the public set: SWE-bench Pro. Fable 5's 80.3 percent comes from early third-party coverage relaying launch materials — it is not on Anthropic's announcement page, and we flag it as early and not independently reproduced. GPT-5.5's 58.6 percent on the same benchmark is OpenAI's reported figure.
- SWE-bench Verified versus SWE-bench Pro: these are different benchmarks. GPT-5.5's officially reported 88.7 percent is on Verified, the older suite; Fable 5 has no published Verified figure the same way. We never cross-compare a Verified score against a Pro score, and we flag anyone who does.
- Hands-on: we have run Fable 5 on live client work since its GA on June 9 — roughly 48 hours side-by-side with GPT-5.5 on the same production tasks at the time of writing. That is enough for qualitative first impressions, not for a controlled benchmark, and we scope every observation below accordingly. GPT-5.5 has been in our daily rotation since April, so our experience there is deeper.
- Disclosure: we have no affiliate relationship with Anthropic or OpenAI. There are no sponsored links on this page.
Features and Benchmarks Comparison
The table below lists every dimension we could verify or attribute. Read the Winner column carefully: it says where a result is one-sided ("where measured") or genuinely tied, and every benchmark figure carries its source. Pricing rows are fetch-verified on both sides; benchmark rows are vendor-reported or early third-party, as labeled.
| Feature | Claude Fable 5 | GPT-5.5 | Winner |
|---|---|---|---|
| API input price (per million tokens) | $10.00 (verified) | $5.00 (verified) | GPT-5.5 |
| API output price (per million tokens) | $50.00 (verified) | $30.00 (verified) | GPT-5.5 |
| SWE-bench Pro (agentic coding, like-for-like) | 80.3% (early third-party reports) | 58.6% (OpenAI reports) | Claude Fable 5 |
| SWE-bench Verified (different benchmark) | Not published the same way | 88.7% (OpenAI reports) | Where measured (GPT-5.5 only) |
| GDPval-AA (economic-value tasks, third-party) | ~1932 (Artificial Analysis, early) | Not in our verified set | Where measured (Fable 5 only) |
| Declared context window | 1,000,000 tokens | 1,050,000 tokens (OpenAI reports) | Tie (within 5 percent) |
| Max output tokens | 128,000 | 128,000 (OpenAI reports) | Tie |
| Reasoning control | Adaptive thinking always on — no off switch, raw chain of thought never returned | Five effort levels (none to xhigh) | GPT-5.5 (flexibility) |
| Refusal and fallback handling | stop_reason refusal as HTTP 200, auto-fallback to Claude Opus 4.8, refusals not billed | Standard API refusals | Claude Fable 5 |
| Data retention | Mandatory 30-day retention (Covered Model), no zero-data-retention option | Standard OpenAI API data controls | GPT-5.5 |
| Prompt caching | 90% discount on cached input | 90% discount ($0.50 per million cached) | Tie |
| Long-context surcharge | Not stated in launch materials | Above 272,000 input tokens: double input rate, 1.5x output (OpenAI docs) | Not comparable (one undisclosed) |
| Agent toolkit | Effort parameter, task budgets (beta), memory tool, context editing, compaction | Function calling, structured outputs, web search, file search, code interpreter, computer use, MCP | Tie (different strengths) |
| Knowledge cutoff | Not stated in launch materials | December 1, 2025 (OpenAI reports) | Where stated (GPT-5.5) |
| Ecosystem / distribution | Claude API, Bedrock, Vertex AI, Microsoft Foundry, Claude Code, GitHub Copilot | ChatGPT, Codex, OpenAI API | GPT-5.5 (consumer reach) |
Synthesis: the one clean, like-for-like benchmark win in this table is SWE-bench Pro, and Fable 5 takes it by 21.7 reported points (80.3 percent versus 58.6 percent) — with the caveat that Fable 5's figure is early third-party coverage, not yet independently reproduced. GPT-5.5 wins both verified pricing rows outright, at half the input rate and 40 percent less on output. The 88.7 percent everyone quotes for GPT-5.5 is on SWE-bench Verified, a different benchmark where Fable 5 has no published number — it does not cancel out the Pro gap, and the Pro gap does not cancel it out either. Context windows are effectively tied. Fable 5's refusal-and-fallback design is the strongest production failure-handling story either vendor has shipped; its mandatory 30-day retention is the price you pay for it.
Pricing — Claude Fable 5 vs GPT-5.5 in 2026
Pricing is the cleanest part of this comparison: both rate cards are fetch-verified on the vendors' own pages as of June 10, 2026, and the gap is stark. Fable 5 costs double on input and two thirds more on output. The question is not whether GPT-5.5 is cheaper — it is, decisively — but whether Fable 5's capability premium is worth paying on your specific workload.
Claude Fable 5 Pricing
| Tier | Input (per million tokens) | Output (per million tokens) | Notes |
|---|---|---|---|
| Standard API | $10.00 | $50.00 | Verified on Anthropic's announcement page, June 10, 2026 |
| Prompt caching | 90% discount on cached input | — | Plus a 1.1x multiplier on US-only inference |
No free plan and no free trial at the API level — you pay per token from the first call. Refusal economics partially offset the premium: requests refused before output are not billed, and a fallback credit refunds the prompt-cache cost of switching to Claude Opus 4.8 when the fallbacks parameter fires.
GPT-5.5 Pricing
| Tier | Input (per million tokens) | Output (per million tokens) | Notes |
|---|---|---|---|
| Standard API | $5.00 | $30.00 | Verified on OpenAI's API pricing docs, June 10, 2026 |
| Cached input | $0.50 | — | 90% discount, verified |
| Batch mode | $2.50 | $15.00 | Half price, verified |
| Long-context tier | Double input rate above 272,000 input tokens | 1.5x output rate | Per OpenAI docs — changes million-token run economics |
Pricing verdict: GPT-5.5 wins on price, full stop. On a representative agentic call of 50,000 input tokens and 5,000 output tokens, Fable 5 costs about $0.75 at the rate card ($10 times 0.05 input plus $50 times 0.005 output) versus about $0.40 for GPT-5.5 ($5 times 0.05 plus $30 times 0.005) — Fable 5 is nearly twice as expensive on that mix, and the gap holds as output share grows. Two softeners are worth modeling before you conclude: both models discount cached input by 90 percent, so long-running agents with stable system prompts close some of the gap; and OpenAI's long-context surcharge above 272,000 input tokens (double input, 1.5x output) means a true million-token GPT-5.5 run costs more than its headline rate suggests, while Anthropic's launch materials state no equivalent surcharge for Fable 5 — we will not assert one either way. Rate cards are also not per-task costs: tokenizer differences and response verbosity move the real bill, and 48 hours is not enough side-by-side time for us to publish a controlled token-accounting comparison, so we stick to the verified rate-card math above.
Hands-On Notes — 48 Hours Side-by-Side, Scoped Honestly
We owe you precision about what this section is and is not. Claude Fable 5 went GA on June 9, 2026; we had it running on live client work within hours, side-by-side with GPT-5.5 on the same tasks in our Next.js and Supabase content pipeline. At the time of writing that is roughly 48 hours of direct comparison — enough for sharp first impressions, nowhere near enough for a controlled benchmark. GPT-5.5 has been in our daily rotation since its April launch, so our baseline there is months deep. Take everything below as scoped, qualitative observation.
Where Fable 5 stood out immediately: on the hardest work — a multi-file refactor across our validation scripts and a long-horizon agent run with heavy tool use — it reached correct results with fewer human interventions than GPT-5.5 on the same tasks. It held coherence deeper into long-context runs, with fewer cases of losing track of state it had actually been given. The always-on adaptive thinking shows: it pauses, plans, and self-corrects mid-task in a way that feels closer to a senior engineer reviewing their own diff than a fast pair programmer. This lines up with the early benchmark picture (80.3 percent SWE-bench Pro, early third-party) without proving it — 48 hours is anecdote, not evidence.
Where GPT-5.5 held its ground: on routine tasks — content transforms, structured extraction, everyday coding — the outcome gap was small to invisible, and GPT-5.5's bias toward small workable changes kept diffs tight and reviewable. Its five-level effort scale is a genuine operational advantage: dialing reasoning to none for cheap bulk calls is something Fable 5 simply cannot do, because adaptive thinking has no off switch. And at half the input price, every task where GPT-5.5 ties is a task where it wins on cost.
What we saw of the fallback mechanism: one security-adjacent prompt in our test set triggered Fable 5's classifier; with the fallbacks parameter set, the request retried on Claude Opus 4.8 and returned a usable answer with stop_reason visible — no exception, no user-facing failure, no charge for the refused attempt. That single observation is consistent with Anthropic's claim that fallbacks fire in less than 5 percent of sessions, and the engineering of it — a refusal as a clean HTTP 200 — is the most production-minded safety design we have used to date.
What we cannot tell you yet: latency under controlled conditions, per-task token economics across both models, and whether Fable 5's early benchmark lead reproduces independently. We will update this comparison as our side-by-side time accumulates and as third-party harnesses publish Fable 5 runs.
Winner per Category

Best for the Hardest Agentic Work: Claude Fable 5
On SWE-bench Pro — the one agentic coding benchmark with same-harness figures for both models — early third-party coverage reports 80.3 percent for Fable 5 versus OpenAI's reported 58.6 percent for GPT-5.5, a 21.7-point gap. Anthropic also reports Fable 5 as the first model to break 90 percent on Hex's core analytics benchmark and the top scorer on Cognition's FrontierCode and Hebbia's Finance Benchmark. In our first 48 hours, the hardest multi-file and long-horizon tasks needed fewer human interventions on Fable 5. If your workload is the kind of work you would assign to your most senior engineer, Fable 5 is the pick on the evidence available — early as it is.
Best for Price and Value: GPT-5.5
This one is not close. GPT-5.5 costs $5 per million input tokens against Fable 5's $10, and $30 per million output against $50 — both rate cards fetch-verified on June 10, 2026. Batch mode halves GPT-5.5's prices again ($2.50 input, $15 output per million). A representative agentic call runs nearly twice as expensive on Fable 5. Unless your tasks demonstrably need the frontier tier, GPT-5.5 delivers more outcome per dollar.
Best on SWE-bench Verified: GPT-5.5, Where Measured
OpenAI officially reports 88.7 percent for GPT-5.5 on SWE-bench Verified, the older and most widely quoted coding suite. Fable 5 has no published Verified figure the same way, so this is a one-sided data point — we will not pretend it is a head-to-head win, and we equally will not let it be erased by the Pro gap. If your mental model of coding ability is calibrated to Verified-style tasks (real GitHub issues, contained scope), GPT-5.5 has the strongest published number in this matchup.
Best for Production Failure Handling: Claude Fable 5
Fable 5's refusal design is the best production safety engineering either vendor has shipped: declines come back as stop_reason refusal on a clean HTTP 200 rather than an error, the fallbacks parameter auto-retries on Claude Opus 4.8 (triggering in less than 5 percent of sessions per Anthropic), refused-before-output requests are not billed, and a fallback credit refunds the prompt-cache cost of the model switch. For unattended agents in production, that is the difference between a logged event and a paged engineer. GPT-5.5 handles refusals as standard API responses with no equivalent mechanism.
Best for Compliance Flexibility: GPT-5.5
Fable 5 is a Covered Model: mandatory 30-day retention on all traffic, human access logged, deletion after 30 days in almost all cases — and no zero-data-retention option, full stop. For some legal and regulatory postures that is an immediate disqualifier, regardless of capability. GPT-5.5 runs under OpenAI's standard API data controls without an equivalent model-tier retention mandate. If zero-data-retention language is in your contracts, GPT-5.5 is the only one of these two you can currently deploy.
Best for Ecosystem and Distribution: GPT-5.5
ChatGPT, Codex, and the OpenAI API remain the widest distribution surface in AI. GPT-5.5 reaches consumers, prosumers, and developers through one stack with the most mature tooling around it. The caveat worth noting: Fable 5 launched day-one on the Claude API, Amazon Bedrock, Vertex AI, Microsoft Foundry, and GitHub Copilot — for enterprise cloud procurement, Anthropic has never been this broadly available this fast. Consumer reach still belongs to OpenAI.
Pros and Cons
Claude Fable 5 Pros and Cons
What we like about Claude Fable 5
- Leads the one like-for-like coding benchmark. SWE-bench Pro at a reported 80.3 percent versus GPT-5.5's reported 58.6 percent — a 21.7-point gap, attributed to early third-party coverage.
- Fewer human interventions on the hardest work. In our first 48 hours side-by-side, deep multi-file refactors and long-horizon agent runs completed correctly more often without help.
- Best-in-class refusal and fallback engineering. Refusals as clean HTTP 200s, auto-fallback to Claude Opus 4.8, refused requests not billed, fallback credit on the switch.
- 1,000,000-token context that holds up. Coherence stayed strong deeper into long runs than GPT-5.5 in our early testing, with 128,000 output tokens per request.
- Unusually broad enterprise launch. Day-one availability on Bedrock, Vertex AI, Microsoft Foundry, and GitHub Copilot alongside the Claude API.
Where Claude Fable 5 falls short
- Double the price of GPT-5.5 on input, two thirds more on output. $10 and $50 per million tokens versus $5 and $30 — the premium only pays off on genuinely frontier workloads.
- Benchmarks are early and not independently reproduced. The 80.3 percent SWE-bench Pro and ~1932 GDPval-AA figures come from early third-party coverage, not Anthropic's own announcement page.
- Adaptive thinking cannot be turned off. No reasoning-free mode for cheap bulk calls, and the raw chain of thought is never returned.
- Mandatory 30-day retention with no zero-data-retention option. The Covered Model policy is a hard blocker for some compliance postures.
- No free plan or trial at the API level. You pay from the first token.
GPT-5.5 Pros and Cons
What we like about GPT-5.5
- Half the input price, 40 percent lower output price. $5 and $30 per million tokens, verified — with Batch mode halving it again to $2.50 and $15.
- Strongest published SWE-bench Verified figure in this matchup. An officially reported 88.7 percent on the older, widely calibrated suite.
- Granular reasoning control. Five effort levels from none to xhigh — including fully off, which Fable 5 cannot do.
- Complete agentic tool stack by default. Function calling, structured outputs, web search, file search, code interpreter, computer use, and MCP support out of the box.
- Widest ecosystem. ChatGPT, Codex, and the OpenAI API, plus a reported 1,050,000-token context window and a December 2025 knowledge cutoff.
Where GPT-5.5 falls short
- Far behind on the like-for-like agentic benchmark. OpenAI's reported 58.6 percent on SWE-bench Pro trails Fable 5's reported 80.3 percent by 21.7 points.
- No equivalent refusal-fallback mechanism. Refusals are standard API responses; there is no auto-retry on a sibling model and no refusal billing relief.
- Long-context surcharge above 272,000 input tokens. Double input rate and 1.5x output changes the economics of true million-token runs.
- Needed more supervision on our hardest tasks. In our first 48 hours side-by-side, deep multi-file work required more human course correction than Fable 5 — scoped, anecdotal, two days of data.
When to Pick Claude Fable 5 vs GPT-5.5
Pick Claude Fable 5 if...
- Your workload is genuinely frontier — long-horizon agents, deep multi-file migrations, senior-level analysis — where the reported 21.7-point SWE-bench Pro gap and our early hands-on both point the same way.
- You run unattended agents in production and want refusals handled as clean HTTP 200s with auto-fallback to Claude Opus 4.8 instead of hard failures.
- You already run an Anthropic stack — Claude Code, the Messages API — and want the strongest top tier on it.
- You procure through AWS Bedrock, Vertex AI, or Microsoft Foundry and want day-one frontier availability there.
- A mandatory 30-day retention window is acceptable to your compliance team.
Pick GPT-5.5 if...
- Price-performance is the deciding factor — half the input rate, 40 percent lower output rate, and Batch mode at half again.
- Your coding workload looks like SWE-bench Verified tasks (contained, well-specified issues), where GPT-5.5's officially reported 88.7 percent is the strongest published number here.
- You need reasoning fully off for cheap high-volume calls — the none-to-xhigh effort scale is the most flexible control in this matchup.
- Zero-data-retention language is in your contracts — Fable 5's Covered Model policy rules it out.
- You live in the OpenAI ecosystem: ChatGPT distribution, Codex, and the broadest consumer reach.
Frequently Asked Questions
Is Claude Fable 5 better than GPT-5.5 in 2026?
On raw capability, the early evidence says yes; on value, no — and we refuse to fake a single overall winner. On SWE-bench Pro, the one agentic coding benchmark where both models have figures reported the same way, early third-party coverage puts Claude Fable 5 at 80.3 percent versus OpenAI's reported 58.6 percent for GPT-5.5. But GPT-5.5 costs half as much on input ($5 versus $10 per million tokens) and 40 percent less on output ($30 versus $50), and it posts 88.7 percent on SWE-bench Verified, a different benchmark where Fable 5 has no published figure. Best for the hardest agentic work: Claude Fable 5. Best for price, ecosystem, and routine coding value: GPT-5.5.
How much do Claude Fable 5 and GPT-5.5 cost?
Claude Fable 5 costs $10 per million input tokens and $50 per million output tokens — we verified this directly on Anthropic's announcement page on June 10, 2026. GPT-5.5 costs $5 per million input tokens and $30 per million output tokens, with cached input at $0.50 per million and Batch mode at half price — we verified this directly on OpenAI's API pricing docs the same day. At the rate card, Fable 5 is double on input and two thirds more on output. Both models offer a 90 percent prompt-caching discount on input, which softens the gap on long-running agents with stable system prompts.
Which is better for agentic coding: Claude Fable 5 or GPT-5.5?
Claude Fable 5, on the comparable evidence — with one important nuance. On SWE-bench Pro, the harder, contamination-resistant agentic benchmark, early third-party coverage reports 80.3 percent for Fable 5 versus OpenAI's reported 58.6 percent for GPT-5.5 — a 21.7-point gap. On SWE-bench Verified, a different and older suite, OpenAI officially reports 88.7 percent for GPT-5.5 while Fable 5 has no published figure the same way. In our first 48 hours running both on the same production tasks, Fable 5 needed fewer human interventions on the hardest multi-file work. For routine coding, GPT-5.5 at half the price is the pragmatic pick.
Why do GPT-5.5's SWE-bench numbers look both higher and lower than Fable 5's?
Because they come from two different benchmarks that share a name. SWE-bench Verified is the older, widely quoted suite of real GitHub issues — OpenAI officially reports 88.7 percent for GPT-5.5 there. SWE-bench Pro is a newer, harder, contamination-resistant evaluation — OpenAI's reported GPT-5.5 figure there is 58.6 percent, and early third-party coverage puts Claude Fable 5 at 80.3 percent. Comparing a Verified score against a Pro score is meaningless, which is why we attribute every figure to its exact benchmark and only declare a winner where both models were measured on the same one.
Is Claude Fable 5 worth double the price of GPT-5.5?
Only if your workload actually hits the frontier. On a representative agentic call of 50,000 input and 5,000 output tokens, Fable 5 costs about $0.75 at the rate card versus about $0.40 for GPT-5.5 — nearly double per task. That premium pays off where the capability gap is real: the hardest long-horizon agent runs, deep multi-file migrations, and senior-level analytical work, where early benchmarks and our first side-by-side days both point to Fable 5. For routine generation, summarization, and everyday coding, GPT-5.5 delivers most of the outcome at roughly half the cost, and a hybrid routing setup is the rational middle path.
Which has the larger context window: Claude Fable 5 or GPT-5.5?
They are effectively tied on declared figures. Claude Fable 5 runs a 1,000,000-token context window with up to 128,000 output tokens per request, per Anthropic's API documentation. OpenAI reports 1,050,000 tokens for GPT-5.5, also with 128,000 max output. The 5 percent difference is negligible in practice. One operational detail matters more: OpenAI applies a long-context surcharge above 272,000 input tokens (double the input rate, 1.5 times the output rate), while Anthropic's launch materials we reviewed do not state an equivalent surcharge for Fable 5 — we will not assert one either way, so check the rate card before running true million-token jobs.
What happens when Claude Fable 5 refuses a request?
You get a clean, costless decline instead of a crash. Fable 5 ships with safety classifiers that decline some cybersecurity and biology requests; a refusal returns stop_reason refusal as a normal HTTP 200, not an error. If you set the fallbacks parameter, the request automatically retries on Claude Opus 4.8, so end users never see a hard failure — Anthropic says fallbacks trigger in less than 5 percent of sessions and more than 95 percent involve no fallback at all. You are not charged for a request refused before output, and a fallback credit refunds the prompt-cache cost of switching models. GPT-5.5 handles refusals as standard API responses without an equivalent auto-fallback mechanism.
Can I turn off Claude Fable 5's adaptive thinking?
No. Adaptive thinking is the only mode Fable 5 ships with — it is always on, there is no extended-thinking toggle, and the raw chain of thought is never returned (you can request summarized output instead). You can shape depth with the effort parameter and cap spend with task budgets, but you cannot disable reasoning outright. GPT-5.5 takes the opposite approach: a five-level reasoning effort scale from none to xhigh, so you can run it with reasoning fully off for cheap, fast calls. If granular reasoning control matters to your integration, GPT-5.5 is the more flexible of the two.
What is the data retention difference between Claude Fable 5 and GPT-5.5?
Claude Fable 5 is a Covered Model under Anthropic's Mythos-class policy: all traffic carries a mandatory 30-day retention window, with human access logged and deletion after 30 days in almost all cases — and there is no zero-data-retention option. That is a hard blocker for some compliance postures. GPT-5.5 runs under OpenAI's standard API data controls, which do not impose an equivalent mandatory retention tied to the model tier. If your legal team requires zero-data-retention guarantees, GPT-5.5 is currently the only one of these two that can even enter that conversation.
Can Claude Fable 5 and GPT-5.5 work together in the same stack?
Yes, and a split stack is arguably the rational setup in mid-2026. A practical routing pattern: send the hardest long-horizon agent runs, deep multi-file migrations, and senior-level analysis to Claude Fable 5 (it leads the like-for-like SWE-bench Pro figure), and send routine coding, summarization, and high-volume generation to GPT-5.5 (half the input price, 40 percent lower output price). Abstraction layers like the Vercel AI SDK, LangChain, or LiteLLM make cost-aware routing by task type a config exercise rather than a rewrite — and Fable 5's own fallback mechanism already normalizes the multi-model mindset.
What are the alternatives to Claude Fable 5 and GPT-5.5?
The most obvious alternative sits between them: Claude Opus 4.8 at $5 per million input and $25 per million output tokens — cheaper than both on output, with a reported 69.2 percent on SWE-bench Pro that beats GPT-5.5's reported figure on that benchmark while costing half of Fable 5. Google's Gemini 3.1 Pro line remains the value play for high-volume retrieval work, and open-weights models cover sovereignty-sensitive deployments. If you want the full picture of the tier below this one, see our Claude Opus 4.8 vs GPT-5.5 comparison.
Final Verdict — Capability vs Value, a True Split
After 48 hours of side-by-side use, fetch-verified pricing on both sides, and a hard look at the attributed benchmark record, our verdict is a genuine split — not a diplomatic one. Claude Fable 5 is the most capable model we have used, and the one like-for-like benchmark (SWE-bench Pro, a reported 80.3 percent versus 58.6 percent) plus our early hands-on both support it — but the figure is early, third-party, and not yet independently reproduced, and the model costs double GPT-5.5 on input with a mandatory 30-day retention policy attached. GPT-5.5 is the value and ecosystem pick: half the input price, 40 percent lower output, the strongest published SWE-bench Verified figure (88.7 percent, a different benchmark), reasoning you can switch off, and OpenAI's distribution. Our standalone reviews score them 9.6 and 8.6 out of 10 respectively — capability against value, in numbers.
We did not crown a single overall winner because the evidence does not support one honestly: Fable 5's lead rests on early figures and 48 hours of anecdote, and GPT-5.5's price advantage is real but cannot buy the top of the capability curve. If your work is the hardest 10 percent — pick Claude Fable 5 and pay for it. If your work is the other 90 percent — pick GPT-5.5 and bank the difference. For most teams the rational endgame is routing: Fable 5 for frontier tasks, GPT-5.5 for volume, with Claude Opus 4.8 — at $5 input and $25 output per million tokens — as the strong middle option we compare in our Claude Opus 4.8 vs GPT-5.5 comparison. For the full picture of each model, see our Claude Fable 5 review, our GPT-5.5 review, and our Claude Opus 4.8 review.
Our Verdict
A true split verdict: capability versus value. On SWE-bench Pro — the one agentic coding benchmark with same-harness figures for both models — early third-party coverage reports 80.3% for Claude Fable 5 versus OpenAI's reported 58.6% for GPT-5.5, a 21.7-point gap, and in our first 48 hours running both side-by-side on the same production tasks, Fable 5 needed fewer human interventions on the hardest multi-file and long-horizon work. But GPT-5.5 wins price decisively — $5 input and $30 output per million tokens versus $10 and $50, both fetch-verified June 10, 2026 — posts the strongest published SWE-bench Verified figure (88.7%, a different benchmark where Fable 5 has no number), offers reasoning that can be switched fully off, and avoids Fable 5's mandatory 30-day Covered Model retention. Best for the hardest agentic work and production failure handling (refusals as HTTP 200 with auto-fallback to Opus 4.8): Claude Fable 5. Best for price, compliance flexibility, and ecosystem: GPT-5.5. Fable 5's benchmark lead is early and not independently reproduced; we scope it accordingly. No single overall winner — route frontier tasks to Fable 5 and volume to GPT-5.5.
Choose Claude Fable 5
Anthropic's most capable widely released model — the public, safety-classified Mythos-class frontier tier.
Try Claude Fable 5 →Choose GPT-5.5
OpenAI's first fully retrained base model since GPT-4.5 — agentic, faster, and double the API price.
Try GPT-5.5 →Frequently Asked Questions
Is Claude Fable 5 better than GPT-5.5?
A true split verdict: capability versus value. On SWE-bench Pro — the one agentic coding benchmark with same-harness figures for both models — early third-party coverage reports 80.3% for Claude Fable 5 versus OpenAI's reported 58.6% for GPT-5.5, a 21.7-point gap, and in our first 48 hours running both side-by-side on the same production tasks, Fable 5 needed fewer human interventions on the hardest multi-file and long-horizon work. But GPT-5.5 wins price decisively — $5 input and $30 output per million tokens versus $10 and $50, both fetch-verified June 10, 2026 — posts the strongest published SWE-bench Verified figure (88.7%, a different benchmark where Fable 5 has no number), offers reasoning that can be switched fully off, and avoids Fable 5's mandatory 30-day Covered Model retention. Best for the hardest agentic work and production failure handling (refusals as HTTP 200 with auto-fallback to Opus 4.8): Claude Fable 5. Best for price, compliance flexibility, and ecosystem: GPT-5.5. Fable 5's benchmark lead is early and not independently reproduced; we scope it accordingly. No single overall winner — route frontier tasks to Fable 5 and volume to GPT-5.5.
Which is cheaper, Claude Fable 5 or GPT-5.5?
Claude Fable 5 is priced at $10 in / $50 out per M tokens. GPT-5.5 is priced at $5 in / $30 out per M tokens. Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Fable 5 and GPT-5.5?
The key differences span across 12 features we compared. For API input price (per million tokens), Claude Fable 5 offers $10.00 (verified) while GPT-5.5 offers $5.00 (verified). For API output price (per million tokens), Claude Fable 5 offers $50.00 (verified) while GPT-5.5 offers $30.00 (verified). For SWE-bench Pro (agentic coding, like-for-like), Claude Fable 5 offers 80.3% (early third-party reports) while GPT-5.5 offers 58.6% (OpenAI reports). See the full feature comparison table above for all details.