
Claude Fable 5 is Anthropic’s most capable widely released model, launched June 9, 2026, in a new tier that sits above Opus. It is priced at $10 per million input tokens and $50 per million output tokens — double Claude Opus 4.8 — with a 1M token context window and up to 128K output tokens. It is generally available on the Claude API, AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry. The launch is notable for its timing: Anthropic released its most powerful model just days after publicly warning the industry about the dangers of recursive self-improvement.
This is the biggest model release of the year so far, and it arrives wrapped in an unusually sharp contradiction. We cover AI tooling every day at ThePlanetTools.ai, and we run our own agent pipelines on frontier Claude models — so we read this launch on two levels at once: what the model can do, and what it signals about where Anthropic thinks the frontier is heading.
What happened: Anthropic ships Fable 5 and Mythos 5
On June 9, 2026, Anthropic released two products built on the same underlying model: Claude Fable 5 (model ID claude-fable-5), the generally available version that ships with safety classifiers, and Claude Mythos 5 (claude-mythos-5), the same model without those classifiers, offered only in limited release through Project Glasswing. Fable 5 is described in Anthropic’s own documentation as "Anthropic’s most capable widely released model."
The two-product structure is the part most people will skim past, and it is the part that matters most. Fable and Mythos are not different models with different weights. They are the same frontier system split by how much safety scaffolding sits in front of it. Fable 5 is the public face — the Mythos-class model with classifiers attached. Mythos 5 is the raw version, gated behind invitation-only access for approved customers. Anthropic positions Mythos 5 as the successor to Claude Mythos Preview, the defensive-cybersecurity research preview it began rolling out earlier this year.
Fable 5 is generally available on the Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry, and it has also landed in GitHub Copilot. Mythos 5 is not self-serve: access runs through your Anthropic, AWS, or Google Cloud account team. If you do not have Glasswing access, Fable 5 is your ceiling — and for almost everyone, that is the point.

The headline specs
The raw numbers put Fable 5 clearly above the Opus line. Here is how the new tier compares to the model it sits on top of.
| Spec | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|
| Tier | New tier above Opus | Opus-tier flagship |
| Input price (per million tokens) | $10 | $5 |
| Output price (per million tokens) | $50 | $25 |
| Context window | 1M tokens | 1M tokens |
| Max output | 128K tokens | 128K tokens |
| Adaptive thinking | Always on (only mode) | Yes |
| Data retention | 30 days mandatory (Covered Model) | Standard / ZDR eligible |
| Availability | GA: API, AWS, Bedrock, Vertex, Foundry, Copilot | GA |
A few details deserve flags. The 1M context window uses the tokenizer introduced with Claude Opus 4.7, which means the same text produces roughly 30 percent more tokens than older models — so the effective cost runs higher than the headline rate suggests. Prompt caching offsets some of that, cutting costs by up to 90 percent on cached input. And the price is a real signal: at $10 input and $50 output, Fable 5 is the most expensive widely available Claude model, positioned for work where the marginal quality is worth a premium, not for high-volume everyday calls.

Why the timing is the story
The Fable 5 launch is controversial because of when it landed. According to coverage from outlets including TechCrunch and NBC, Anthropic shipped its most powerful model just days after urging major global AI labs to establish a coordinated "brake pedal" on frontier AI development, warning that systems are advancing so rapidly they may soon achieve recursive self-improvement.
That is the contradiction at the center of this release, and it is worth sitting with rather than rushing past. The same company that has spent years building its brand on safety, interpretability, and caution — the company now reportedly calling for an industry-wide pause mechanism on the most dangerous capabilities — has just released the most capable model it has ever made widely available. Per the reporting, Anthropic warned that frontier systems may soon reach the point of recursive self-improvement (RSI), the moment when an AI system becomes capable enough to meaningfully improve itself, compounding gains faster than humans can supervise.
The Mythos thread runs straight through this. Mythos started as a limited preview earlier this year, focused on cybersecurity, and per the coverage it was expanded last week to hundreds of critical-infrastructure organizations across 15 countries. The reporting also cites an external bug-bounty result that has been circulating: testers found "no universal jailbreaks in over 1,000 hours of testing." We are quoting that figure as reported, not as a number we have independently verified — and the distinction matters, because a model marketed as unbreakable invites exactly the scrutiny that proves or disproves the claim.
Is this hypocrisy or strategy? The charitable read — and the one we lean toward — is that Anthropic’s position is internally consistent even if it looks contradictory from the outside. The argument goes: if frontier models are going to be built regardless, the lab with the strongest safety practices should be the one at the frontier, shipping classifier-equipped Fable to the public while keeping the unclassified Mythos locked behind vetted access. The brake-pedal call is about coordination across labs, not unilateral disarmament. Whether that argument holds is the debate the whole industry is now having, out loud.

The benchmarks — read them as early signals
Early launch benchmarks reported by third parties put Claude Fable 5 around 80.3 percent on SWE-Bench Pro, versus 69.2 percent for Opus 4.8, 58.6 percent for GPT-5.5, and 54.2 percent for Gemini 3.1 Pro. A GDPval-AA score of roughly 1932 has also circulated. These are early, third-party numbers — not official Anthropic figures — and they should be read as directional rather than definitive.
We want to be careful here, because launch-week benchmarks are the most over-cited and least durable numbers in this industry. The framing that matters: every figure below is an early launch benchmark from third-party coverage, attributed accordingly. We have not re-run any of these ourselves, and we would treat anyone presenting them as settled fact with suspicion.
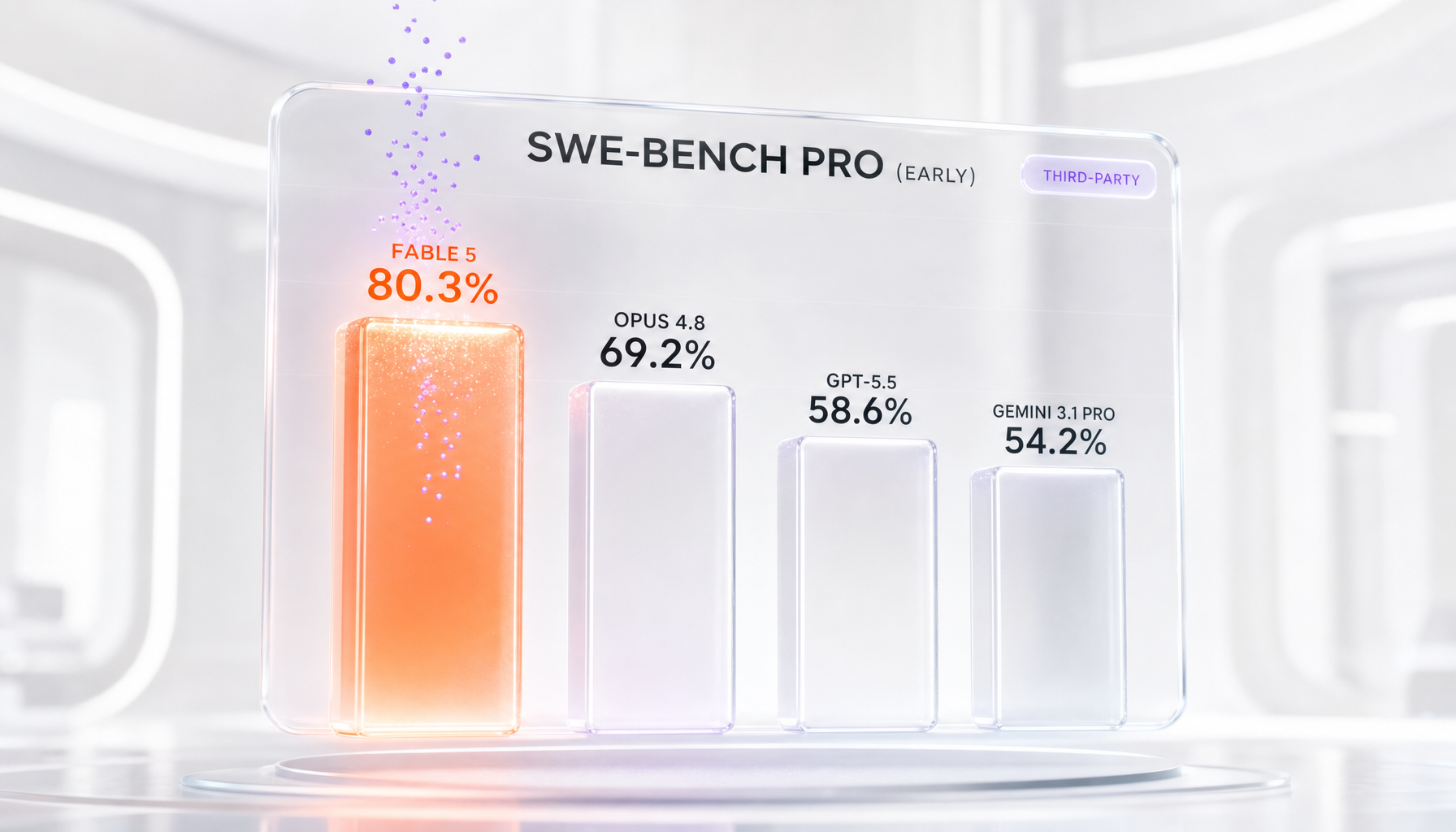
| Benchmark (early, third-party) | Claude Fable 5 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro | ~80.3% | 69.2% | 58.6% | 54.2% |
| GDPval-AA (score) | ~1932 | — | — | — |
The most interesting reactions are not the raw scores but the qualitative notes from early partners, as reported by TechCrunch. Hex said Fable 5 was the first model to reach 90 percent on its core analytics benchmark, praising its "strong judgement and attention to nuance." Rakuten’s line was blunter and, in its way, more telling: "the extra thinking pays for itself." That phrase captures the actual value proposition of a model in this tier. You are not paying double for a marginally higher leaderboard score — you are paying for the cases where deeper reasoning converts a near-miss into a correct, shippable result, which on long-horizon agentic work is where the real cost savings hide.
One anchor worth noting for our regular readers: the Opus 4.8 SWE-Bench Pro figure of 69.2 percent matches the data we have used in our own Opus 4.8 coverage, which gives us some confidence the comparison set is at least internally consistent. The Fable 5 delta of roughly 11 points over Opus 4.8 on that benchmark is large for a single generation — if it holds up under independent testing, it justifies the new tier.
How Fable 5 actually behaves in the API
Beyond price and benchmarks, Fable 5 changes how you build against it. These are not cosmetic differences — they reshape integration, billing, and error handling. The Messages API behavior here is specific to Fable 5 and Mythos 5; Opus, Sonnet, and Haiku are unchanged.
Refusals are a feature, not an error
This is the single most important thing for developers to internalize. Fable 5’s safety classifiers can decline a request on sensitive domains — cyber, bio, chemistry, and capability distillation among them. When that happens, the Messages API returns stop_reason: "refusal" as a successful HTTP 200 response, and the response names which classifier declined. It is not a 4xx error and should not be handled as one.
The fallback path is built in. A request Fable 5 refuses can usually be served by another Claude model: you pass the fallbacks parameter (in beta on the Claude API and Claude Platform on AWS) to have the API retry for you, or use the SDK middleware (available for TypeScript, Python, Go, Java, and C#) to retry from the client on any platform. Anthropic’s recommended fallback target is Claude Opus 4.8. On billing, you are not charged for a request that is refused before any output is generated, and when you retry on another model, "fallback credit" refunds the prompt-cache cost of switching.
The practical upshot is that for the overwhelming majority of real workloads, none of this is visible. The deferrals are rare — in normal product usage the vast majority of sessions run entirely on Fable 5, with the refusal-and-fallback machinery only engaging on the narrow band of sensitive prompts the classifiers are tuned to catch. You build the fallback once, and then mostly forget it exists.

Adaptive thinking, always on
Fable 5 has exactly one thinking mode: adaptive thinking, and it is always on. There is no extended-thinking toggle and no way to disable thinking — sending thinking: {"type": "disabled"} returns a 400 error. You control how deeply the model reasons with the effort parameter instead of a token budget.
The raw chain of thought is never returned. The thinking.display field defaults to "omitted", which returns thinking blocks with an empty thinking field; set display: "summarized" if you want readable summarized reasoning. In multi-turn conversations on the same model, you pass thinking blocks back unchanged. And the model drops a set of parameters developers are used to: there is no temperature, no top_p, and no budget_tokens. If your existing harness sets any of those, it needs adjusting before it will work against Fable 5.
Covered Model: 30-day retention, no ZDR
This is the constraint most likely to block enterprise adoption, and it is non-negotiable. Both Fable 5 and Mythos 5 are designated Covered Models, which carry mandatory 30-day data retention and are not available under zero data retention. Organizations that previously operated under ZDR agreements do not get an exemption here. For teams in regulated industries or with contractual data-handling commitments, this needs to be cleared with legal and compliance before Fable 5 goes anywhere near production data.
Supported features at launch round out the picture: the effort parameter, task budgets (beta, via the task-budgets-2026-03-13 header), the memory tool, tool-result clearing through context editing (beta), compaction, and vision. That is a full agentic toolkit — Fable 5 is clearly built to be the brain of long-running, autonomous agent systems, not just a chat endpoint.

Our early hands-on with Fable 5
Our early hands-on — honest first impressions, not a benchmark.
We put Fable 5 on real agentic missions as soon as it went live — we run our AI content and research pipelines on frontier Claude daily, so we had immediate, apples-to-apples reference points against Opus 4.8. The difference is something you feel before you can measure it. Where it shows up most is comprehension and coordination: Fable 5 holds a more accurate model of a complex, multi-step task, and it orchestrates a fleet of sub-agents noticeably better than Opus 4.8 does. We run an internal agent fleet (we call the setup ultracode), and the gap is clearest exactly there — in how Fable 5 manages, delegates to, and reconciles the work of multiple agents without losing the thread. On the kind of long-horizon, many-agent jobs that used to need babysitting, it drifts less and recovers better. We are framing this as an early impression, not a verdict — we have had it for days, not weeks — but the qualitative jump in orchestration is the most immediately obvious upgrade we have felt from a Claude release in a while.
We will reserve a real verdict for when we have run it across more of our production workload. But the early read aligns with what Rakuten reported: on the hard, agentic, long-running tasks, the extra reasoning earns its keep. For a chat box answering one-off questions, Opus 4.8 is the smarter spend. For an autonomous system coordinating many steps and many agents over a long horizon, Fable 5 is a different class of tool.
How Fable 5 fits the competitive picture
Fable 5’s arrival resets the top of the frontier-model market. On the early SWE-Bench Pro numbers, it opens a meaningful gap over both GPT-5.5 (58.6 percent) and Gemini 3.1 Pro (54.2 percent), and a smaller but real one over Anthropic’s own Opus 4.8 (69.2 percent). But the more useful way to think about it is by job, not by leaderboard.

- For most complex work: Claude Opus 4.8 remains the recommended default. It is half the price, it is ZDR-eligible, and Anthropic itself still points to it as the starting point for the most complex tasks. Fable 5 is the step up you take when Opus 4.8 leaves quality on the table.
- For long-horizon agentic systems: Fable 5 is the new ceiling. The combination of adaptive thinking always on, the full agent toolkit (memory tool, task budgets, compaction, context editing), and the orchestration quality we felt in testing makes it the natural brain for autonomous, multi-agent products.
- For defensive cybersecurity at the frontier: Mythos 5 — if you can get Glasswing access — is the unclassified version built for exactly that, and the reason the whole product line exists.
For readers building on Anthropic’s stack, the practical map is unchanged in shape but taller at the top: start with Claude or Claude Opus 4.8 for general and complex work, reach for Claude Code when you are coding in an agentic loop, watch Claude Mythos Preview as the research-grade thread that Mythos 5 now continues, and treat Fable 5 as the premium tier you graduate to when the work genuinely demands it.
Our take
Claude Fable 5 is the most consequential model release of the year, and not only because of the capability jump. It is the clearest statement yet of how Anthropic intends to operate at the frontier: ship the safety-wrapped version to everyone, keep the raw version behind vetted doors, and make the case — loudly, days before launch — that the industry needs a coordinated brake even as Anthropic itself presses the accelerator.
What would change our read? If independent testing fails to reproduce the early SWE-Bench Pro delta, the new tier and its doubled price get a lot harder to justify. If the "no universal jailbreaks" claim falls — and a model marketed that way will be attacked relentlessly — the entire Fable-versus-Mythos safety architecture comes into question. And if the recursive self-improvement warning turns out to have been positioning rather than genuine concern, the goodwill Anthropic has banked on being the careful lab takes a real hit. Those are the things we will be watching, and we will update this piece as the independent numbers and the security results come in.
What’s next
The immediate question is how fast the rest of the frontier responds. A roughly 11-point SWE-Bench Pro lead over the nearest competitor, if it holds, is the kind of gap that pulls a launch out of OpenAI and Google on a compressed timeline. The second question is adoption friction: the mandatory 30-day retention will keep some regulated enterprises on Opus 4.8 regardless of capability, and that constraint may matter more to Fable 5’s real-world footprint than any benchmark. The third is Mythos: as the unclassified model expands to more critical-infrastructure partners, the security community’s findings — jailbreaks attempted, jailbreaks found — will be the truest test of whether Anthropic’s safety story survives contact with the frontier it just shipped.
Claude Fable 5 FAQ
What is Claude Fable 5?
Claude Fable 5 (claude-fable-5) is Anthropic’s most capable widely released model, launched June 9, 2026. It sits in a new tier above Opus, built for the most demanding reasoning and long-horizon agentic work. It ships with a 1M token context window, up to 128K output tokens, and pricing of $10 per million input tokens and $50 per million output tokens.
How much does Claude Fable 5 cost?
Claude Fable 5 costs $10 per million input tokens and $50 per million output tokens — exactly double Claude Opus 4.8 at $5 input and $25 output. Prompt caching cuts costs by up to 90 percent. Note the model uses the Opus 4.7 tokenizer, so the same text produces roughly 30 percent more tokens than older models, which raises effective cost.
How is Claude Fable 5 different from Claude Opus 4.8?
Fable 5 is a tier above Opus 4.8. Early launch benchmarks reported by third parties put Fable 5 around 80.3 percent on SWE-Bench Pro versus 69.2 percent for Opus 4.8. Fable 5 costs twice as much ($10 input and $50 output versus $5 and $25), runs adaptive thinking always on with no disabled mode, never returns raw reasoning, and is a Covered Model with mandatory 30-day data retention. Opus 4.8 remains the recommended default for most complex work.
What is Claude Mythos 5 and how is it different from Fable 5?
Claude Mythos 5 (claude-mythos-5) shares Claude Fable 5’s exact capabilities but ships without the safety classifiers. It is not generally available — it is offered in limited release to approved customers through Project Glasswing, the successor to Claude Mythos Preview. Fable 5 is the generally available, classifier-equipped, Mythos-class model. Customers without Glasswing access use Fable 5.
Why does Claude Fable 5 sometimes refuse a request?
Fable 5 includes safety classifiers that can decline requests on sensitive domains such as cyber, bio, and chemistry. When it declines, the Messages API returns stop_reason "refusal" as a successful HTTP 200 response — not an error — and names the classifier that declined. You are not billed for a request refused before any output is generated, and the fallbacks parameter (beta) or SDK middleware can automatically retry on another model such as Claude Opus 4.8.
Does Claude Fable 5 support zero data retention?
No. Claude Fable 5 and Claude Mythos 5 are designated Covered Models, which carry mandatory 30-day data retention and are not available under zero data retention — even for enterprises that previously had ZDR. Teams with strict data-handling requirements need to account for this before adopting Fable 5.
Where can I use Claude Fable 5?
Claude Fable 5 is generally available as of June 9, 2026 on the Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry, plus GitHub Copilot. The API model ID is claude-fable-5. Claude Mythos 5 is limited to approved Project Glasswing customers and is not self-serve.
Is the timing of the Fable 5 launch controversial?
Yes. Per coverage from outlets including TechCrunch and NBC, Anthropic shipped its most powerful model just days after urging major global AI labs to establish a coordinated "brake pedal" on frontier development, warning that systems are advancing so fast they may soon reach recursive self-improvement. The tension between calling for restraint and releasing a frontier-tier model is the central story around the launch.
How does Claude Fable 5 handle reasoning and thinking output?
Adaptive thinking is the only thinking mode on Fable 5 and it is always on; sending thinking type "disabled" returns a 400 error. The raw chain of thought is never returned — thinking.display defaults to "omitted" — and you set display "summarized" for readable summaries. Fable 5 does not support temperature, top_p, or budget_tokens; you control depth with the effort parameter instead.
What benchmarks has Claude Fable 5 posted?
Treat all current numbers as early launch benchmarks from third-party coverage, not official Anthropic figures. TechCrunch-reported results include SWE-Bench Pro around 80.3 percent (versus 69.2 percent Opus 4.8, 58.6 percent GPT-5.5, and 54.2 percent Gemini 3.1 Pro) and a GDPval-AA score around 1932. Hex reported Fable 5 as the first model to hit 90 percent on its core analytics benchmark, and Rakuten said "the extra thinking pays for itself."
Editorial note: ThePlanetTools.ai has no affiliate or commercial relationship with Anthropic. Model IDs, pricing, context limits, availability, and API behavior in this article were verified against Anthropic’s official documentation on platform.claude.com on 2026-06-10. Benchmark figures and the launch-timing narrative are attributed to third-party coverage including TechCrunch and NBC and are presented as reported, not independently verified.



