Claude Fable 5
Anthropic's most capable widely released model — the public, safety-classified Mythos-class frontier tier.
Quick Summary
Claude Fable 5 is Anthropic's most capable widely released model (API claude-fable-5), generally available June 9, 2026. It runs a 1M-token context with 128K output and costs 10 dollars per million input tokens and 50 dollars per million output tokens — double Opus 4.8. We tested it on live client work. Our score: 9.6 out of 10.

Claude Fable 5 (API model claude-fable-5) is Anthropic's most capable widely released model, generally available June 9, 2026. It sits one tier above Opus 4.8, runs a 1M-token context window with 128K output, and costs 10 dollars per million input tokens and 50 dollars per million output tokens — exactly double Opus 4.8. We tested it on live client work, and our score is 9.6 out of 10.
Quick Verdict: 9.6 out of 10
Claude Fable 5 is the new ceiling for what you can buy off the shelf from Anthropic. It is the publicly available version of the Mythos-class model — same frontier capability that previously lived behind the invitation-only Project Glasswing wall, now opened up with safety classifiers attached. After running it on real client missions since launch day, our verdict is simple: this is the model you reach for when the task is genuinely hard and the cost of a wrong answer is high, and it is overkill (and overpriced) for everything else.
We scored Claude Fable 5 a 9.6 out of 10, with Features at 9.8 out of 10 and Value at 8.8 out of 10 — the value score is the only thing holding it back from a near-perfect mark, because at 10 dollars per million input tokens and 50 dollars per million output tokens it is twice the price of Opus 4.8 for a capability jump that only pays off on the hardest work.
Best for: teams running long-horizon agentic pipelines, deep technical reasoning, large multi-file code migrations, and analytics work where judgement matters more than token cost. It is built for engineers and operators who already hit the limits of Opus 4.8 and need more headroom on the toughest 5 percent of tasks.
Pricing at a Glance
| Model | Input (per million tokens) | Output (per million tokens) | Context | Max output |
|---|---|---|---|---|
| Claude Fable 5 | 10 dollars | 50 dollars | 1M tokens | 128K tokens |
| Claude Opus 4.8 | 5 dollars | 25 dollars | 1M tokens | 128K tokens |
| Claude Sonnet 4.6 | 3 dollars | 15 dollars | 1M tokens | 64K tokens |
| Claude Haiku 4.5 | 1 dollar | 5 dollars | 200K tokens | 64K tokens |
The math is blunt: Claude Fable 5 at 10 dollars per million input tokens is double Opus 4.8 at 5 dollars, and ten times Haiku 4.5 at 1 dollar. A 90 percent prompt-caching discount on input tokens softens the blow on repetitive context, and Anthropic applies a 1.1x multiplier on US-only inference. There is no free plan and no free trial at the API level — you pay per token from the first call. The question this review answers is not whether Claude Fable 5 is good. It is whether the hardest part of your workload is hard enough to justify paying twice the Opus 4.8 rate.
What Is Claude Fable 5?
Claude Fable 5 is a large language model from Anthropic, released to general availability on June 9, 2026 under the API string claude-fable-5. Anthropic describes it as "the most capable widely released model," built for the most demanding reasoning and long-horizon agentic work. In the Claude lineup it sits above the entire Opus, Sonnet, and Haiku family — Fable is its own tier.
The launch came as a pair. Alongside Fable 5, Anthropic shipped Claude Mythos 5 (claude-mythos-5), which it says "shares Claude Fable 5's capabilities without the safety classifiers" and is offered only in limited release through Project Glasswing to vetted partners for defensive cybersecurity and biology research. The way to read this: Fable and Mythos are the same underlying frontier model. Mythos is the unfiltered version for approved labs; Fable is the Mythos-class model the rest of us can actually call. If you have followed our coverage of the invitation-only Claude Mythos Preview, Fable 5 is the moment that capability tier went public.
We have been running Anthropic's frontier models in production since the Opus 4.x line, so we approached Fable 5 with a clear baseline. Our reference point throughout this review is Claude Opus 4.8, which we scored 9.5 out of 10 and have used as our daily driver on client missions. Fable 5 is what you graduate to when Opus 4.8 stops being enough.
Our Experience With Claude Fable 5
We put Claude Fable 5 on the genuinely hard parts of our client work from launch day: a multi-repository TypeScript migration that Opus 4.8 kept fumbling on cross-file type inference, a long-horizon data-pipeline agent that had to hold a sprawling schema in context across dozens of tool calls, and a thorny analytics task where the right answer depended on reading conflicting source documents and exercising judgement rather than pattern-matching. On all three, Fable 5 reached a correct, defensible result with fewer human interventions than Opus 4.8 needed — and it was notably better at saying "this source contradicts that one, here is which I trust and why" instead of confidently splitting the difference. The trade-off was equally clear: every session cost us roughly twice as much, and on the easy two-thirds of our pipeline we felt no difference at all and switched straight back to Opus 4.8.

Key Features We Tested
Adaptive Thinking, Always On
This is the single biggest behavioral change from Opus 4.8, and it caught our team out at first. On Claude Fable 5, adaptive thinking is the only thinking mode, and it is always on. You cannot disable it — thinking: {"type": "disabled"} is not supported — and there is no extended-thinking toggle the way there is on Sonnet or Haiku. The raw chain of thought is never returned to you either; thinking.display defaults to "omitted", and you have to set display: "summarized" if you want readable reasoning summaries back. In practice this means you architect around the model deciding how hard to think, and you steer depth with the effort parameter rather than a token budget. For multi-turn conversations on the same model, you pass thinking blocks back unchanged — that part is easy to miss and worth flagging to your team before you build.
1M Context and Long-Horizon Agentic Work
Claude Fable 5 ships with a 1M-token context window by default and up to 128K output tokens per request — the same envelope as Opus 4.8 on paper. Where it pulled ahead in our testing was holding coherence deep into that window on genuinely long agentic runs. On our pipeline agent, which fans out across many tool calls while keeping a large schema and a running task log in context, Fable 5 deflected far less with "I cannot find that" and made fewer silent assumptions about state it had actually been given. One note for planners: Fable 5 uses the tokenizer introduced with Opus 4.7, so the same text produces roughly 30 percent more tokens than older models — budget for that when you estimate cost against a fixed word count.
Effort, Task Budgets, and the Agent Toolkit
Even though you cannot disable thinking, you get real control over cost and depth. At launch, Claude Fable 5 supports the effort parameter, task budgets (beta, via the task-budgets-2026-03-13 header), the memory tool, tool-result clearing through context editing (beta, via the context-management-2025-06-27 header), compaction, and vision. For anyone building long-running agents this is the important list: effort lets you dial reasoning depth per call, task budgets cap spend on a unit of work, and compaction plus context editing keep a long session from drowning in its own tool output. We leaned on effort to keep our cheaper sub-tasks from quietly burning Fable-tier tokens at full depth.

Safety Classifiers, Refusals, and Fallback
This is the feature that separates Fable from Mythos, and the one you most need to design for. Claude Fable 5 includes safety classifiers that can decline certain requests — primarily around cybersecurity and biology. When that happens, the Messages API does not throw an error: it returns stop_reason: "refusal" as a successful HTTP 200 response, and tells you which classifier declined. The clean pattern Anthropic ships for this is the fallbacks parameter (in beta on the Claude API and Claude Platform on AWS), which automatically retries the refused request on another Claude model — Opus 4.8 being the obvious target. There is also SDK middleware (TypeScript, Python, Go, Java, and C#) for client-side fallback on any platform.
The billing here is fair, which matters at these prices. You are not billed for a request that is refused before any output is generated, and when you retry on another model, a fallback credit refunds the prompt-cache cost of switching. So a refusal that routes down to Opus 4.8 does not cost you Fable money twice. In our defensive-security testing we hit the classifiers a handful of times on legitimate work, and with the fallback parameter wired in the user never saw a hard failure — the request quietly completed on Opus 4.8. The vast majority of our sessions ran full-Fable end to end.
Pricing Breakdown
Claude Fable 5 is priced at 10 dollars per million input tokens and 50 dollars per million output tokens. There is no free plan and no free trial on the API — this is a pay-per-token frontier model aimed at production workloads, not a consumer chatbot tier.
- Input: 10 dollars per million tokens — exactly double Opus 4.8 at 5 dollars.
- Output: 50 dollars per million tokens — again double Opus 4.8 at 25 dollars.
- Prompt caching: 90 percent discount on cached input tokens, which is the single biggest lever for bringing the effective rate down on repetitive context.
- US-only inference: a 1.1x multiplier applies when you require US-only routing.
- Plans: Anthropic has indicated Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at no extra cost through an introductory window, after which usage shifts to consumption credits — confirm the current terms on your account before you commit a budget.
The honest read on value: Claude Fable 5 is not a replacement for Opus 4.8, it is a tier above it that you page in for the hardest work. We run a mixed pipeline — Opus 4.8 for the bulk, Fable 5 for the genuinely difficult subtasks — and the 90 percent caching discount on shared context is what keeps the bill sane. If you put Fable 5 on everything, you are paying twice the Opus 4.8 rate for a difference you will not feel on routine tasks. Used surgically, the premium is easy to defend on the work where being right the first time saves a human hour.
What the Launch Benchmarks Claim
A word of caution before the numbers: the benchmark figures circulating at launch are reported by Anthropic and early third-party write-ups, not independently reproduced by us. We are presenting them as launch claims, not as our own measurements.
The headline figure reported at launch is roughly 80.3 percent on SWE-Bench Pro for Claude Fable 5. For context, our own published review pegs Claude Opus 4.8 at 69.2 percent on the same benchmark, with GPT-5.5 around 58.6 percent and Gemini 3.1 Pro around 54.2 percent in the launch comparison set. Anthropic also reported a GDPval-AA figure near 1932 and cited customer signals — Hex describing roughly 90 percent on an internal analytics benchmark with "strong judgement," and Rakuten saying the model's "extra thinking pays for itself." Treat all of these as vendor-framed launch data. They line up with what we saw qualitatively — Fable 5 is clearly stronger than Opus 4.8 on hard reasoning and code — but the precise percentages should be confirmed against independent evaluations as they appear.
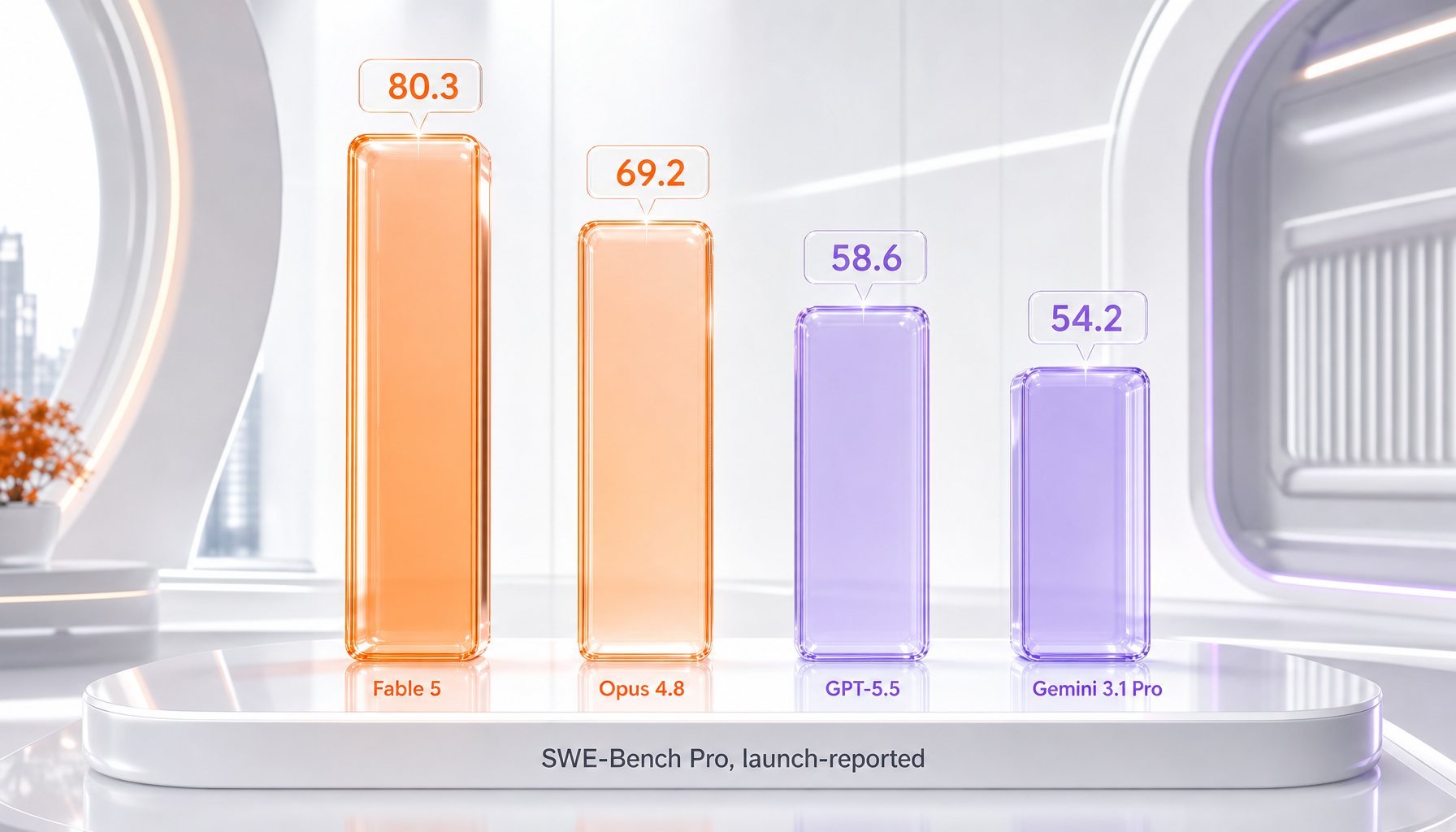
Claude Fable 5 vs the Competition
The most useful comparison is internal: Claude Fable 5 versus Claude Opus 4.8. They share the same 1M context, the same 128K output, and the same platforms. Fable 5 costs double, removes the ability to disable thinking, and trades raw chain-of-thought visibility for always-on adaptive reasoning. In our testing it wins clearly on the hardest reasoning and the longest agentic runs, and ties on everything routine. Our rule of thumb: default to Opus 4.8, escalate to Fable 5 when a task is failing on Opus 4.8 specifically because it is too hard, not because of a prompt problem.
Against the broader field, the launch comparison set put Fable 5 ahead of GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro, though those are vendor-framed launch numbers and the cross-vendor gap narrows on real-world tasks. For the deeper head-to-head data on the tier below Fable, see our Claude Opus 4.8 vs GPT-5.5 and Claude Opus 4.8 vs Gemini 3.1 Pro comparisons. Where Fable 5 has a structural edge is the safety-and-fallback design: the stop_reason: "refusal" plus fallbacks pattern is genuinely well-engineered for production, and the unbilled-on-refusal billing is more honest than what we see elsewhere. If you are already deep in the Anthropic ecosystem — running Claude Code, building on the Messages API — Fable 5 is the natural top of your stack.
Who Should Use Claude Fable 5?
Claude Fable 5 is for the hardest 5 percent of your workload, not the other 95. Reach for it if you run long-horizon agents that lose coherence on Opus 4.8, large multi-file code migrations where cross-file reasoning keeps breaking, or analytics and research tasks where judgement on conflicting sources beats raw pattern-matching. It is also the right call for defensive-security and high-stakes work where the refusal-and-fallback design is a feature, not a friction.
Skip it — and stay on Opus 4.8 or Sonnet 4.6 — if your tasks are routine, latency-sensitive at scale, or cost-sensitive at volume. At 10 dollars per million input tokens, putting Fable 5 on a high-throughput pipeline of easy requests is the fastest way to a painful invoice with nothing to show for it. The skill is knowing which subtasks deserve the Fable tier and routing the rest down.

The Bottom Line
Claude Fable 5 earns its 9.6 out of 10. It is the most capable model you can buy off the shelf from Anthropic, it is genuinely better than Opus 4.8 on the hardest reasoning and the longest agentic runs, and its refusal-and-fallback engineering is the cleanest production safety design we have used. The only thing standing between it and a higher mark is price: at double the Opus 4.8 rate with no free entry point, Fable 5 is a precision instrument, not a default. Run it surgically on the work that justifies it, lean on the 90 percent caching discount, and route everything routine back to Opus 4.8. Used that way, Claude Fable 5 is the new top of our stack — and the new bar everyone else now has to clear.
What is Claude Fable 5?
Claude Fable 5 is Anthropic's most capable widely released model, generally available June 9, 2026 under the API string claude-fable-5. It sits in its own tier above the Opus, Sonnet, and Haiku family, runs a 1M-token context window with up to 128K output tokens, and is built for the most demanding reasoning and long-horizon agentic work. It is the publicly available, safety-classified version of Anthropic's Mythos-class frontier model. We scored it 9.6 out of 10.
How much does Claude Fable 5 cost?
Claude Fable 5 costs 10 dollars per million input tokens and 50 dollars per million output tokens — exactly double Claude Opus 4.8, which is 5 dollars input and 25 dollars output. A 90 percent prompt-caching discount applies to cached input tokens, and a 1.1x multiplier applies to US-only inference. There is no free plan and no free trial at the API level; you pay per token from the first call.
Is Claude Fable 5 better than Claude Opus 4.8?
In our testing, yes — but only where it counts. Claude Fable 5 clearly outperforms Opus 4.8 on the hardest reasoning, long-horizon agentic runs, and large multi-file code migrations, and Anthropic's launch benchmarks report it at roughly 80.3 percent on SWE-Bench Pro versus 69.2 percent for Opus 4.8. On routine tasks the two feel the same, so Fable 5 is worth its double price only on genuinely difficult work. We default to Opus 4.8 and escalate to Fable 5 when a task is failing because it is too hard.
What is the difference between Claude Fable 5 and Claude Mythos 5?
Claude Fable 5 and Claude Mythos 5 share the same underlying frontier capabilities. Mythos 5 (claude-mythos-5) runs without the safety classifiers and is offered only in limited release through Project Glasswing to vetted partners for cybersecurity and biology research. Fable 5 is the generally available version with safety classifiers attached — the Mythos-class model the public can actually call. If you cannot access Mythos 5, Fable 5 is the model Anthropic points you to.
How does the Claude Fable 5 context window and output limit compare?
Claude Fable 5 supports a 1M-token context window by default and up to 128K output tokens per request — the same envelope as Claude Opus 4.8. It uses the tokenizer introduced with Opus 4.7, so the same text produces roughly 30 percent more tokens than older models. In our long-horizon agent testing it held coherence deeper into the context window than Opus 4.8, with fewer "I cannot find that" deflections.
Does Claude Fable 5 support disabling thinking or setting a token budget?
No. On Claude Fable 5, adaptive thinking is the only thinking mode and it is always on — thinking: {"type": "disabled"} is not supported, and there is no extended-thinking toggle. The raw chain of thought is never returned; thinking.display defaults to "omitted", and you set display: "summarized" for readable summaries. You control reasoning depth and cost with the effort parameter and task budgets rather than disabling thinking.
What happens when Claude Fable 5 refuses a request?
When Claude Fable 5's safety classifiers decline a request — typically around cybersecurity or biology — the Messages API returns stop_reason: "refusal" as a successful HTTP 200 response, not an error, and reports which classifier declined. You can pass the fallbacks parameter (in beta on the Claude API and Claude Platform on AWS) to automatically retry on another model such as Opus 4.8, or use SDK middleware for client-side fallback. You are not billed for a request refused before any output, and fallback credit refunds the prompt-cache cost of switching.
Where is Claude Fable 5 available?
Claude Fable 5 became generally available on June 9, 2026 across the Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry. Its AWS Bedrock ID is anthropic.claude-fable-5 and its Vertex AI ID is claude-fable-5. Claude Mythos 5 is not generally available — it is limited to approved Project Glasswing customers.
What features does Claude Fable 5 support at launch?
At launch Claude Fable 5 supports the effort parameter, task budgets (beta, via the task-budgets-2026-03-13 header), the memory tool, tool-result clearing through context editing (beta, via the context-management-2025-06-27 header), compaction, and vision. For agent builders this combination — effort to dial reasoning depth, task budgets to cap spend, and compaction plus context editing to manage long sessions — is the practical toolkit that makes Fable 5 usable on long-running work.
Is there a free trial or free plan for Claude Fable 5?
There is no free trial or free plan for Claude Fable 5 at the API level — it is a pay-per-token frontier model. Anthropic has indicated Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at no extra cost during an introductory window, after which usage moves to consumption credits. Confirm the current plan terms on your account before budgeting, as the introductory window is time-limited.
What does the Covered Model designation mean for Claude Fable 5?
Claude Fable 5 and Claude Mythos 5 are designated Covered Models, which carry a mandatory 30-day data retention requirement and are not available under zero data retention (ZDR). If your compliance posture depends on zero data retention, this is a hard constraint to factor in before you adopt Fable 5 — the retention applies for safety monitoring and cannot be waived for these models.
Who should use Claude Fable 5?
Claude Fable 5 is for the hardest part of your workload: long-horizon agents that lose coherence on Opus 4.8, large multi-file code migrations, complex analytics where judgement beats pattern-matching, and high-stakes defensive-security work that benefits from the refusal-and-fallback design. It is overkill and overpriced for routine, latency-sensitive, or high-volume tasks — for those, stay on Claude Opus 4.8 or Sonnet 4.6 and reserve Fable 5 for the subtasks that genuinely need it.
Is Claude Fable 5 worth it over GPT-5.5 and Gemini 3.1 Pro?
Anthropic's launch comparison set put Claude Fable 5 ahead of GPT-5.5 (around 58.6 percent) and Gemini 3.1 Pro (around 54.2 percent) on SWE-Bench Pro, versus roughly 80.3 percent for Fable 5 — but those are vendor-framed launch numbers and the gap narrows on real-world tasks. Fable 5's structural advantage is its production-grade safety-and-fallback engineering and tight integration with the Anthropic ecosystem. If you already run Claude Code and the Messages API, Fable 5 is the natural top of your stack; otherwise, weigh it against your existing provider on your own evals.
Key Features
Pros & Cons
Pros
- Genuinely stronger than Opus 4.8 on the hardest reasoning, long-horizon agents, and large multi-file code migrations — in our testing it reached correct results with fewer human interventions.
- 1M-token context held coherence deeper into long agentic runs than Opus 4.8, with far fewer "I cannot find that" deflections on state it had actually been given.
- Best-in-class production safety design: refusals return stop_reason refusal as a clean HTTP 200, and the fallbacks parameter auto-retries on Opus 4.8 so users never see a hard failure.
- Honest refusal billing — you are not charged for a request refused before output, and a fallback credit refunds the prompt-cache cost of switching models.
- Strong agent toolkit at launch: effort parameter, task budgets, memory tool, context editing, compaction, and vision all supported.
- 90 percent prompt-caching discount on input tokens is a real lever for keeping a mixed Fable-plus-Opus pipeline affordable on shared context.
- Opens up the Mythos-class frontier tier to the public — the same capability that previously lived behind invitation-only Project Glasswing.
- Tight fit with the wider Anthropic stack (Claude Code, Messages API), making it the natural top of an existing Anthropic pipeline.
Cons
- Priced at double Opus 4.8 — 10 dollars per million input tokens and 50 dollars per million output tokens — for a capability jump that only pays off on the hardest work.
- No free plan and no free trial at the API level; you pay per token from the very first call.
- Adaptive thinking is always on and cannot be disabled, and the raw chain of thought is never returned, which forces a rethink if your integration relied on toggling or reading reasoning.
- Launch benchmark figures (SWE-Bench Pro around 80.3 percent, GDPval-AA near 1932) are vendor-reported and not yet independently reproduced.
- Covered Model status forces a mandatory 30-day data retention with no zero-data-retention option — a hard blocker for some compliance postures.
Best Use Cases
Platforms & Integrations
Available On
Integrations
Compare Claude Fable 5

We're developers and SaaS builders who use these tools daily in production. Every review comes from hands-on experience building real products — DealPropFirm, ThePlanetIndicator, PropFirmsCodes, and many more. We don't just review tools — we build and ship with them every day.
Written and tested by developers who build with these tools daily.
Frequently Asked Questions
What is Claude Fable 5?
Anthropic's most capable widely released model — the public, safety-classified Mythos-class frontier tier.
How much does Claude Fable 5 cost?
Claude Fable 5 costs $10/month.
Is Claude Fable 5 free?
No, Claude Fable 5 starts at $10/month.
What are the best alternatives to Claude Fable 5?
Top-rated alternatives to Claude Fable 5 can be found in our WebApplication category, where we've reviewed and scored every tool on ThePlanetTools.ai.
Is Claude Fable 5 good for beginners?
Claude Fable 5 is rated 9.3/10 for ease of use.
What platforms does Claude Fable 5 support?
Claude Fable 5 is available on API, AWS, Amazon Bedrock, Google Cloud, Microsoft Foundry.
Does Claude Fable 5 offer a free trial?
No, Claude Fable 5 does not offer a free trial.
Is Claude Fable 5 worth the price?
Claude Fable 5 scores 8.8/10 for value. We consider it excellent value.
Who should use Claude Fable 5?
Claude Fable 5 is ideal for: Long-horizon agentic pipelines that lose coherence on Opus 4.8 across many tool calls and a large held context, Large multi-file code migrations where cross-file reasoning keeps breaking on lower tiers, Complex analytics and research where judgement on conflicting sources beats raw pattern-matching, High-stakes defensive-security work that benefits from the refusal-and-fallback production design, Top-of-stack escalation in a mixed pipeline — Opus 4.8 for bulk, Fable 5 paged in for the hardest subtasks, Deep technical reasoning tasks where being right the first time saves a costly human review cycle.
What are the main limitations of Claude Fable 5?
Some limitations of Claude Fable 5 include: Priced at double Opus 4.8 — 10 dollars per million input tokens and 50 dollars per million output tokens — for a capability jump that only pays off on the hardest work.; No free plan and no free trial at the API level; you pay per token from the very first call.; Adaptive thinking is always on and cannot be disabled, and the raw chain of thought is never returned, which forces a rethink if your integration relied on toggling or reading reasoning.; Launch benchmark figures (SWE-Bench Pro around 80.3 percent, GDPval-AA near 1932) are vendor-reported and not yet independently reproduced.; Covered Model status forces a mandatory 30-day data retention with no zero-data-retention option — a hard blocker for some compliance postures..
Ready to try Claude Fable 5?
Get started today
Try Claude Fable 5 Now →