Claude Opus 4.8 vs Claude Opus 4.7: Is the Same-Price Upgrade Worth It?


Claude Opus 4.8 vs 4.7: same $5/$25 price, but 4.8 wins SWE-bench Pro 69.2 vs 64.3, adds Fast Mode. Is the upgrade worth it? Verdict inside.

Feature Comparison
| Feature | Claude Opus 4.8 | Claude Opus 4.7 |
|---|---|---|
| Release date | May 28, 2026 | April 16, 2026 |
| Input price (per 1M tokens) | $5.00 | $5.00 |
| Output price (per 1M tokens) | $25.00 | $25.00 |
| SWE-bench Verified | 88.6% | 87.6% |
| SWE-bench Pro | 69.2% | 64.3% |
| Terminal-Bench 2.1 | 74.6% | 66.1% |
| Online-Mind2Web (web agent) | 84% | Not published in this table |
| Code-defect rate (self-review) | ~4x less likely to let flaws through | Baseline |
| Legal Agent Benchmark | First model above 10% all-pass | Below 10% all-pass |
| Fast Mode (2.5x speed) | Yes — $10 / $50 per 1M | No |
| Dynamic Workflows + effort controls | Yes (at launch) | No (added post-launch features differ) |
| Vision input ceiling | Not separately published at launch | 2,576 px long edge (~3.75 MP) |
Pricing Comparison
Claude Opus 4.8
Claude Opus 4.7
Detailed Comparison
Claude Opus 4.8 vs Claude Opus 4.7: Opus 4.8 is Anthropic's flagship coding and agent model launched May 28, 2026, scoring 88.6% on SWE-bench Verified, 69.2% on SWE-bench Pro, and 74.6% on Terminal-Bench 2.1. Opus 4.7 launched April 16, 2026 and scores 87.6%, 64.3%, and 66.1% on the same three benchmarks. Both cost the same: $5 per million input tokens and $25 per million output tokens. Opus 4.8 adds a 2.5x-speed Fast Mode and is about four times less likely to leave flaws in its own code. Verdict: pick Opus 4.8 for any new work — it is better across the board at the same price — and stay on 4.7 only if you have pinned it for production stability.
TL;DR — Quick Verdict
Winner: Claude Opus 4.8, at the same price as Opus 4.7. This is an intra-generation upgrade, not a new model class, and the honest framing is "is the upgrade worth it?" rather than "which one wins?" Because both models cost $5 per million input tokens and $25 per million output tokens, the upgrade is free on paper — you are not trading dollars for capability. On Anthropic's own comparison table, Opus 4.8 beats Opus 4.7 on all three benchmarks they list for both models: SWE-bench Verified (88.6% vs 87.6%), SWE-bench Pro (69.2% vs 64.3%), and Terminal-Bench 2.1 (74.6% vs 66.1%). It also adds a 2.5x-speed Fast Mode and reports roughly four times fewer flaws slipping past its own code review. We have used Opus 4.8 in our own workflow and the improvement on long agentic runs is real, though we have not run a controlled head-to-head against 4.7 ourselves.
- Claude Opus 4.8 wins for: any new project, agentic coding (SWE-bench Pro 69.2%), terminal and tool-use reliability (Terminal-Bench 2.1 74.6%), web-agent tasks (Online-Mind2Web 84%), self-review quality (~4x fewer code flaws), and speed-sensitive work via Fast Mode.
- Claude Opus 4.7 wins for: teams that have already pinned 4.7 in production and validated their pipeline against that exact version — stability and reproducibility beat a marginal benchmark bump in that scenario.
- Same price either way: $5 per million input tokens, $25 per million output tokens. The decision is about capability and stability, never cost.
- Honest caveat: the SWE-bench Verified gain is only one point (88.6% vs 87.6%) — marginal. The meaningful gains are on SWE-bench Pro (+4.9), Terminal-Bench 2.1 (+8.5), agentic reliability, and Fast Mode.
A note on the numbers: every benchmark in this comparison comes from the single comparison table Anthropic published for Opus 4.8, which lists both models side-by-side. That is the good news — the two scores come from the same source, the same harness, and the same evaluation run, so they are directly comparable in a way that cross-source benchmarks rarely are. The caveat: these figures are vendor-reported and press-relayed, and we have not seen them independently reproduced. Read them as Anthropic's claim, not as a neutral third-party result.
What each model is
Claude Opus 4.8
Claude Opus 4.8 is Anthropic's flagship model, launched May 28, 2026 — about 41 days after Opus 4.7. It is positioned as a coding and agentic-work model and ships with two notable launch features: a Fast Mode that runs at roughly 2.5x the speed of standard inference, and effort controls that let you dial how much reasoning effort the model spends on a task. Anthropic reports that Opus 4.8 is around four times less likely than Opus 4.7 to let flaws slip through in its own code, and that it is the first model to clear 10% all-pass on the Legal Agent Benchmark. It also leads on web-agent work, scoring 84% on Online-Mind2Web. Pricing is $5 per million input tokens and $25 per million output tokens for standard usage; Fast Mode is priced at $10 per million input and $50 per million output, which Anthropic frames as roughly three times cheaper than fast inference cost on previous models.
Claude Opus 4.7
Claude Opus 4.7 launched April 16, 2026 and was, until late May, Anthropic's most capable model. It is a strong agentic coder in its own right — on the same table Anthropic later published, it scores 87.6% on SWE-bench Verified, 64.3% on SWE-bench Pro, and 66.1% on Terminal-Bench 2.1. It also raised the bar on vision input, accepting images up to 2,576 pixels on the long edge (about 3.75 megapixels), more than three times the ceiling of earlier Claude models. Critically for this comparison, it costs exactly the same as Opus 4.8: $5 per million input tokens and $25 per million output tokens. Opus 4.7 is not a weak model that 4.8 replaces out of necessity — it is a recent flagship that 4.8 incrementally improves on.
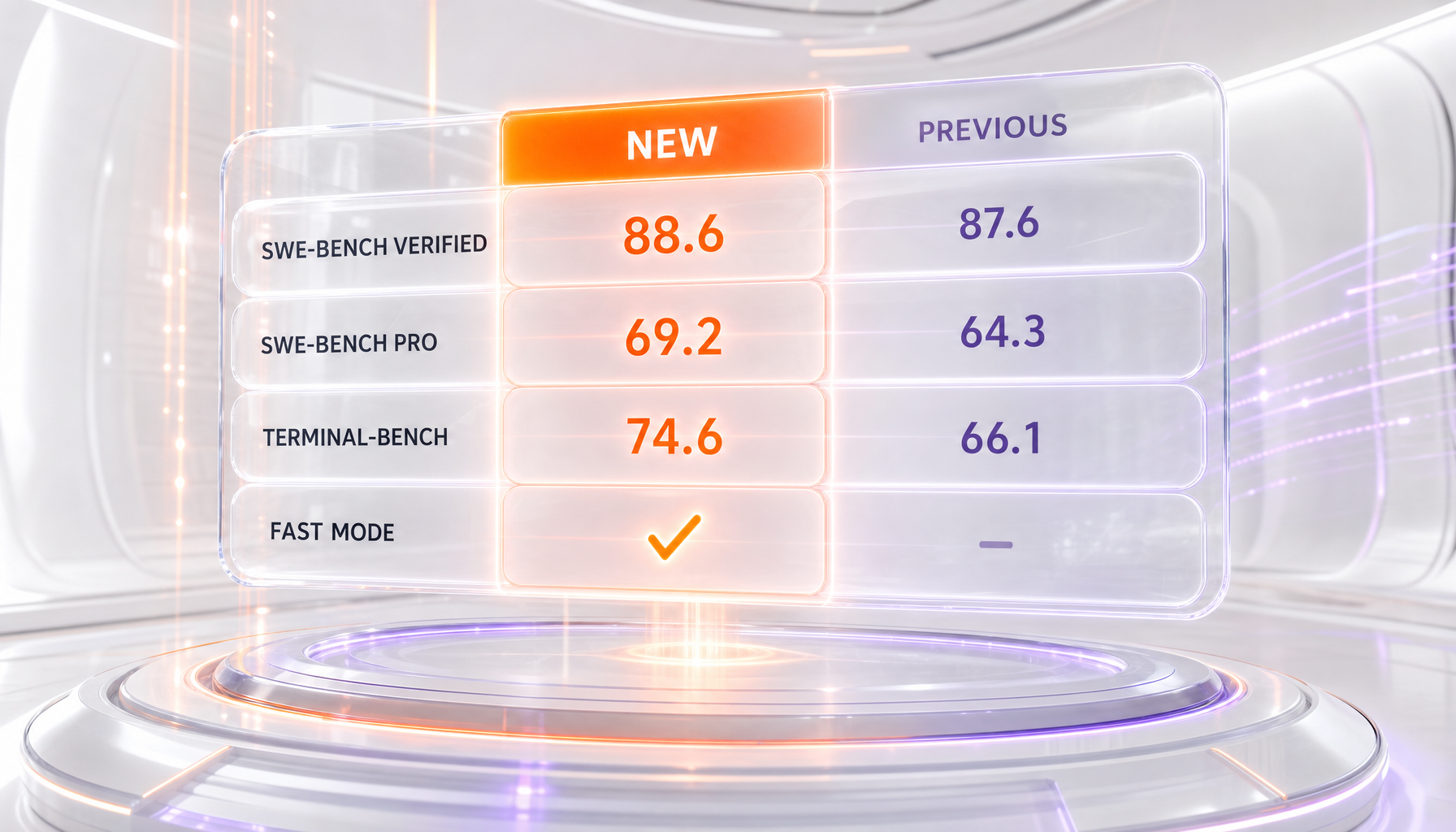
Claude Opus 4.8 vs Claude Opus 4.7: head-to-head
The table below pulls every figure from Anthropic's Opus 4.8 comparison table, so both columns are measured the same way. Where a value was not published for a model in that table, we say so rather than estimate.
| Feature | Claude Opus 4.8 | Claude Opus 4.7 | Winner |
|---|---|---|---|
| Release date | May 28, 2026 | April 16, 2026 | Tie |
| Input price (per 1M tokens) | $5.00 | $5.00 | Tie |
| Output price (per 1M tokens) | $25.00 | $25.00 | Tie |
| SWE-bench Verified | 88.6% | 87.6% | Opus 4.8 |
| SWE-bench Pro | 69.2% | 64.3% | Opus 4.8 |
| Terminal-Bench 2.1 | 74.6% | 66.1% | Opus 4.8 |
| Online-Mind2Web (web agent) | 84% | Not published in this table | Opus 4.8 |
| Code-defect rate (self-review) | ~4x less likely to let flaws through | Baseline | Opus 4.8 |
| Legal Agent Benchmark | First model above 10% all-pass | Below 10% all-pass | Opus 4.8 |
| Fast Mode (2.5x speed) | Yes — $10 / $50 per 1M | No | Opus 4.8 |
| Vision input ceiling | Not separately published at launch | 2,576 px long edge (~3.75 MP) | Tie |
Read the table and the pattern is obvious: Opus 4.8 wins or ties every row, and never loses one. The only places it does not clearly pull ahead are the ones where the two models are identical (price) or where Anthropic did not publish a directly comparable figure (vision ceiling, where 4.7 has a documented number and 4.8's launch materials did not restate one).
What the benchmarks actually measure
Three numbers carry most of the weight in this comparison, and they do not measure the same thing. Understanding what each one tests is the difference between thinking the upgrade is a rounding error and seeing where it genuinely matters.
SWE-bench Verified (88.6% vs 87.6%) is a curated set of real GitHub issues with human-verified solvability. It is the most widely cited coding benchmark, which is exactly why a one-point move here looks underwhelming — both models are already near the top of a saturated scale. When a benchmark is this close to its ceiling, a single point is roughly the noise floor. This is the figure we keep flagging as marginal, and we mean it: do not buy the upgrade on the strength of SWE-bench Verified alone.
SWE-bench Pro (69.2% vs 64.3%) raises the difficulty with longer, messier, more realistic engineering tasks where the model has to manage multi-file changes and ambiguous requirements. The scale is far from saturated, so the 4.9-point gain reflects real headroom being closed. For anyone running agents on production-grade codebases rather than tidy single-issue fixes, this is the benchmark that should move your decision.
Terminal-Bench 2.1 (74.6% vs 66.1%) tests the model as an operator in a real shell — running commands, reading output, recovering from errors, and chaining steps toward a goal. The 8.5-point jump is the largest of the three, and it maps directly onto agentic reliability: a model that drives a terminal better fails less often midway through an autonomous run. Combined with the reported ~4x reduction in code flaws slipping past self-review, this is the cluster of improvements that makes Opus 4.8 feel more dependable in practice, not just on a leaderboard.
The pattern is consistent: the easier, more saturated the benchmark, the smaller the gain; the harder and more agentic the task, the larger the gain. That is a healthy shape for an upgrade aimed at agentic and coding work — it tells you the improvements landed where the work is hard, not where the scoreboard was already maxed out.
Pricing comparison
This is the shortest section in the comparison because there is almost nothing to compare. Standard pricing is identical:
| Tier | Claude Opus 4.8 | Claude Opus 4.7 |
|---|---|---|
| Standard input (per 1M tokens) | $5.00 | $5.00 |
| Standard output (per 1M tokens) | $25.00 | $25.00 |
| Fast Mode input (per 1M tokens) | $10.00 | Not offered |
| Fast Mode output (per 1M tokens) | $50.00 | Not offered |
For standard usage, switching from Opus 4.7 to Opus 4.8 changes your bill by exactly zero. The one new lever is Fast Mode: it runs at about 2.5x the speed and costs $10 per million input tokens and $50 per million output tokens — double the standard rate, but Anthropic says that is roughly three times cheaper than fast inference was on previous models. You only pay the Fast Mode premium when you opt into it, so it does not affect the baseline comparison. If latency matters more than per-token cost for your workload, Fast Mode is a capability Opus 4.7 simply does not have. All prices are sourced directly from Anthropic's pricing and launch pages for each model.
How we tested, and what we did not test
We have used Opus 4.8 in our own internal content and agent workflows since it shipped, and our experience tracks with Anthropic's reliability claims: on long agentic runs with many tool calls, it backtracks and self-corrects more cleanly than the 4.7 builds we ran before it, and it leaves fewer half-finished states behind. That matches the "around four times less likely to let flaws through" figure, at least directionally.
Here is the honest scope of this comparison. We did not run a controlled, matched head-to-head of Opus 4.8 against Opus 4.7 on identical prompts with identical harnesses — so when we say 4.8 "feels" more reliable, that is hands-on impression, not a measured delta. The hard numbers in this article are Anthropic's, taken from the single comparison table they published for Opus 4.8. We trust that table for relative comparison because both models appear in it under the same methodology, but we flag clearly that the figures are vendor-reported and have not been independently reproduced. Where our hands-on experience and Anthropic's numbers point the same way, we say so; where we only have Anthropic's claim, we attribute it.
Winner by category
Best for new projects and greenfield work — Claude Opus 4.8
If you are starting something new, there is no argument: same price, higher scores on every comparable benchmark, plus Fast Mode and better self-review. Default to 4.8.
Best for agentic coding and terminal-heavy work — Claude Opus 4.8
The largest real gains are here: SWE-bench Pro climbs from 64.3% to 69.2% (+4.9 points) and Terminal-Bench 2.1 from 66.1% to 74.6% (+8.5 points). For agent loops that chain many tool calls, those are the numbers that move outcomes, far more than the one-point SWE-bench Verified bump.
Best for speed-sensitive workloads — Claude Opus 4.8 (Fast Mode)
Fast Mode at 2.5x speed is exclusive to 4.8. If you are latency-bound — interactive agents, live coding assistants, anything a human waits on — this is a capability 4.7 cannot match at any price.
Best for pinned, validated production pipelines — Claude Opus 4.7
This is the one honest win for the older model. If your production stack is pinned to Opus 4.7, your evals are green against that exact version, and stability is worth more to you than a marginal benchmark gain, there is no urgency to move. "If it is not broken" is a legitimate engineering position, and a one-point SWE-bench Verified improvement does not force a migration.
Best overall — Claude Opus 4.8
Across the board, at the same price, with a clean upgrade path. Opus 4.8 is the better model and the better default.
Pros and cons of each model
Claude Opus 4.8
Pros
- Wins all three head-to-head benchmarks at the same price as 4.7.
- Largest gains where they matter: SWE-bench Pro (+4.9) and Terminal-Bench 2.1 (+8.5).
- About 4x less likely to leave flaws in its own code on self-review.
- New Fast Mode at 2.5x speed — a capability 4.7 lacks entirely.
- Ships with Dynamic Workflows and effort controls at launch.
- First model to clear 10% all-pass on the Legal Agent Benchmark.
Cons
- SWE-bench Verified gain is only one point (88.6% vs 87.6%) — marginal.
- Benchmarks are vendor-reported and not independently reproduced.
- A version change can disrupt pipelines pinned and validated on 4.7.
- Fast Mode costs double the standard per-token rate.
Claude Opus 4.7
Pros
- Same price as 4.8 — still a genuinely strong flagship, not a budget option.
- Documented vision ceiling of 2,576 px long edge (~3.75 MP).
- Already battle-tested in production since April 2026.
- A safe, pinned target for pipelines that prize reproducibility.
Cons
- Loses every comparable benchmark to 4.8 — by a little or a lot.
- No Fast Mode and no 2.5x-speed option.
- Higher rate of letting code flaws through on self-review.
- No reason to choose it for new work given identical pricing.
When to pick Opus 4.8 vs Opus 4.7
Pick Claude Opus 4.8 when you are starting any new project, when your workload is agentic or terminal-heavy, when latency matters and Fast Mode helps, or when you simply want the best model at a price that has not changed. For the overwhelming majority of users, this is the answer.
Pick (or stay on) Claude Opus 4.7 when you have already pinned it in production, your evaluation suite is green against that exact version, and the cost of re-validating your pipeline outweighs a marginal benchmark improvement. This is a stability decision, not a capability one — and it is the only scenario where keeping 4.7 is the rational call.
How to migrate from Opus 4.7 to Opus 4.8
Because this is an intra-generation upgrade at the same price, migration is usually a one-line change rather than a project. In most setups you swap the model identifier and you are done — the API surface, pricing, and core behavior are unchanged. That simplicity is the whole point: there is no new billing model to model out and no new SDK to learn.
The discipline that does pay off is treating the swap like any other dependency bump. If you run an evaluation suite against your prompts, run it once on Opus 4.8 before you flip production traffic over. Models that score higher on aggregate benchmarks can still differ in tone, formatting, or edge-case behavior on your specific tasks, and a quick eval pass catches that. If you have prompts tuned tightly to 4.7's quirks, expect to retune a few of them — not because 4.8 is worse, but because it is different.
If you want the speed gains, Fast Mode is an opt-in choice you make per request or per route, so you can keep latency-sensitive paths on Fast Mode and leave cost-sensitive batch jobs on standard pricing. There is no reason to apply Fast Mode globally. And if you maintain a pinned, validated production pipeline on 4.7, the safest path is to bring up 4.8 in a parallel environment, mirror traffic, compare outputs, and promote it only once your evals are green — exactly the migration hygiene you would use for any model version change.
Frequently Asked Questions
Is Claude Opus 4.8 better than Claude Opus 4.7?
Yes, on Anthropic's own comparison table. Opus 4.8 beats Opus 4.7 on all three head-to-head benchmarks: SWE-bench Verified (88.6% vs 87.6%), SWE-bench Pro (69.2% vs 64.3%), and Terminal-Bench 2.1 (74.6% vs 66.1%). It also adds a 2.5x-speed Fast Mode and is reported to be about four times less likely to leave flaws in its own code. Because both models cost the same — $5 per million input tokens and $25 per million output tokens — Opus 4.8 is the better default for any new work. Note that the SWE-bench Verified gain is only one point, so the biggest real improvements are on SWE-bench Pro, Terminal-Bench, and agentic reliability.
Is the upgrade from Opus 4.7 to Opus 4.8 worth it?
For new work, yes — there is no cost to upgrading because standard pricing is identical, and Opus 4.8 scores higher on every comparable benchmark. The one situation where it may not be worth it is if you have pinned Opus 4.7 in production and validated your pipeline against that exact version; in that case, the value of stability can outweigh a marginal benchmark gain, and a one-point SWE-bench Verified improvement does not force a migration.
How much do Claude Opus 4.8 and Opus 4.7 cost?
Both cost exactly the same for standard usage: $5 per million input tokens and $25 per million output tokens. Opus 4.8 additionally offers a Fast Mode at $10 per million input tokens and $50 per million output tokens, which runs at about 2.5x the speed. Opus 4.7 does not offer a Fast Mode. So switching from 4.7 to 4.8 changes your standard bill by zero, and you only pay the Fast Mode premium if you opt into it.
What is the difference in SWE-bench Pro between Opus 4.8 and Opus 4.7?
On Anthropic's comparison table, Opus 4.8 scores 69.2% on SWE-bench Pro and Opus 4.7 scores 64.3% — a gain of 4.9 points. SWE-bench Pro measures agentic coding on harder, more realistic tasks than SWE-bench Verified, so this is one of the more meaningful gains in the upgrade. Both figures are vendor-reported and have not been independently reproduced.
What is Fast Mode in Claude Opus 4.8?
Fast Mode is a new option in Opus 4.8 that runs inference at roughly 2.5x the standard speed. It is priced at $10 per million input tokens and $50 per million output tokens — double the standard rate — which Anthropic describes as about three times cheaper than fast inference was on previous models. It is most useful for latency-sensitive workloads such as interactive agents and live coding assistants. Opus 4.7 has no equivalent feature.
Should I use Opus 4.8 or Opus 4.7 with Claude Code?
For Claude Code and similar agentic coding tools, Opus 4.8 is the stronger choice: its largest benchmark gains are on agentic coding (SWE-bench Pro +4.9) and terminal and tool use (Terminal-Bench 2.1 +8.5), which are exactly the workloads agentic coding tools exercise. The improved self-review behavior — about four times less likely to leave flaws through — also matters for long autonomous runs. The only reason to stay on 4.7 is a pinned, validated production setup.
Are the Opus 4.8 vs 4.7 benchmark numbers reliable?
They are directly comparable, but they are vendor-reported. Every figure here comes from the single comparison table Anthropic published for Opus 4.8, which lists both models under the same methodology and harness — so the relative comparison is sound in a way cross-source benchmarks usually are not. The caveat is that these are Anthropic's own numbers, press-relayed, and we have not seen them independently reproduced. Treat them as the vendor's claim rather than a neutral third-party result.
How much faster is Opus 4.8 than Opus 4.7?
At standard settings the two run at comparable speeds, but Opus 4.8 adds a Fast Mode that runs at about 2.5x the speed of standard inference. Opus 4.7 has no Fast Mode, so for latency-bound work Opus 4.8 can be meaningfully faster when you opt into Fast Mode — at $10 per million input tokens and $50 per million output tokens.
Does Opus 4.8 leave fewer bugs than Opus 4.7?
According to Anthropic, yes: Opus 4.8 is around four times less likely than Opus 4.7 to let flaws slip through in its own code on self-review. In our own hands-on use of Opus 4.8 on long agentic runs, it does backtrack and self-correct more cleanly than the 4.7 builds we ran before it, which is consistent with that claim — though we have not measured a controlled head-to-head ourselves.
When should I stay on Opus 4.7 instead of upgrading?
Stay on Opus 4.7 only if you have pinned it in production, your evaluation suite passes against that exact version, and re-validating your pipeline for a new model version costs more than the upgrade is worth. Because the SWE-bench Verified gain is just one point, there is no urgency to migrate a stable, validated system. For everything else — and especially new work — Opus 4.8 is the better choice at the same price.
How long after Opus 4.7 did Opus 4.8 launch?
Opus 4.8 launched May 28, 2026, about 41 days after Opus 4.7's April 16, 2026 release. That short gap is part of why this is an intra-generation upgrade rather than a new model class: the architecture and pricing are unchanged, and the improvements are incremental gains on coding, agentic reliability, and speed options.
Is the SWE-bench Verified difference between Opus 4.8 and 4.7 significant?
No — it is marginal. Opus 4.8 scores 88.6% and Opus 4.7 scores 87.6%, a difference of just one point. We call this out plainly because it is easy to overstate. The benchmarks that actually moved are SWE-bench Pro (+4.9) and Terminal-Bench 2.1 (+8.5), plus the agentic reliability and Fast Mode improvements. If your decision hinges only on SWE-bench Verified, the upgrade looks tiny; once you weigh the agentic and speed gains, it is clearly worthwhile — especially since it is free.
Related comparisons
- Claude Opus 4.7 vs GPT-5.5 — how the previous flagship stacks up against OpenAI's GPT-5.5.
- Claude Opus 4.7 vs Gemini 3.1 Pro Preview — Anthropic versus Google's frontier model.
- Claude Opus 4.7 vs Grok 4.3 — flagship coding model head-to-head with xAI.
- Need a faster, cheaper tier? See Claude Sonnet 4.6 for everyday work.
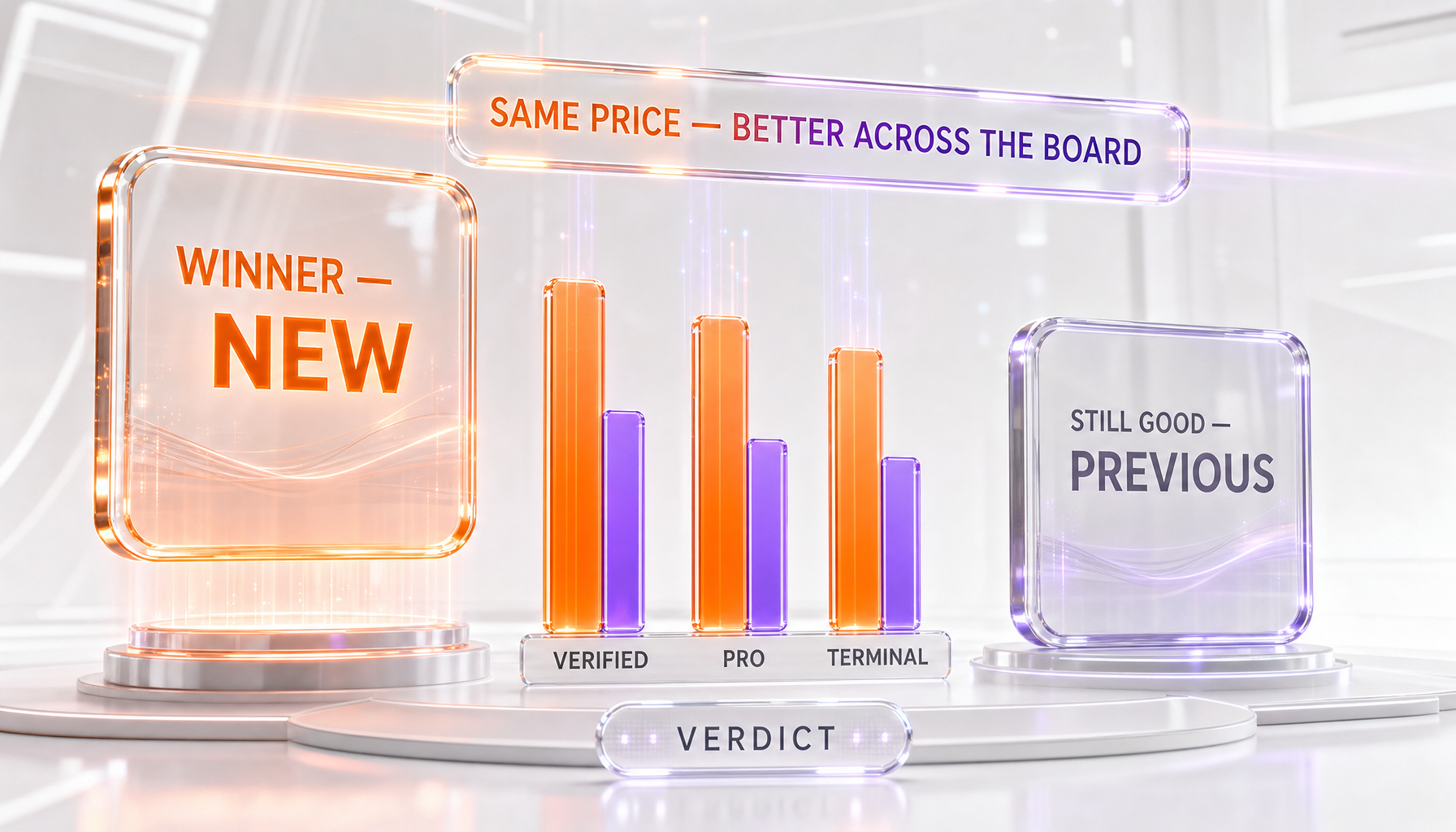
Final verdict
Claude Opus 4.8 is the better choice for any new work, and it costs exactly the same as Opus 4.7 — $5 per million input tokens and $25 per million output tokens. On Anthropic's own comparison table it wins all three head-to-head benchmarks (SWE-bench Verified 88.6% vs 87.6%, SWE-bench Pro 69.2% vs 64.3%, Terminal-Bench 2.1 74.6% vs 66.1%), and it adds Fast Mode plus a roughly 4x lower rate of letting flaws slip past its own code review. Be honest about the size of the gains: the SWE-bench Verified jump is only one point, so it is marginal. The real upgrade is on SWE-bench Pro (+4.9), Terminal-Bench (+8.5), agentic reliability, and the new Fast Mode option. Because the price is identical, there is no reason to start new projects on 4.7. The only case for staying on Opus 4.7 is if you have pinned it for production stability and your pipeline is validated against that exact version. Bottom line: Opus 4.8 for any new work — same price, better across the board; stay on 4.7 only if you have pinned it for production stability.
Disclosure: ThePlanetTools.ai has no affiliate relationship with Anthropic, and we earn nothing from your choice between these two models. We use Claude in our own workflows and we like it, but this comparison is written to be neutral — both Opus 4.8 and Opus 4.7 are graded on the same evidence, and the one honest win for 4.7 (pinned production stability) is stated as plainly as 4.8's advantages. Benchmark figures are Anthropic's own, taken from its Opus 4.8 comparison table and flagged as vendor-reported. Last compared: May 2026.
Our Verdict
Claude Opus 4.8 is the better choice for any new work, and it costs exactly the same as Opus 4.7 — $5 per million input tokens and $25 per million output tokens. On Anthropic's own comparison table it wins all three head-to-head benchmarks (SWE-bench Verified 88.6% vs 87.6%, SWE-bench Pro 69.2% vs 64.3%, Terminal-Bench 2.1 74.6% vs 66.1%), and it adds Fast Mode plus a roughly 4x lower rate of letting flaws slip past its own code review. Be honest about the size of the gains: the SWE-bench Verified jump is only one point, so it is marginal. The real upgrade is on SWE-bench Pro (+4.9), Terminal-Bench (+8.5), agentic reliability, and the new Fast Mode option. Because the price is identical, there is no reason to start new projects on 4.7. The only case for staying on Opus 4.7 is if you have pinned it for production stability and your pipeline is validated against that exact version. Bottom line: Opus 4.8 for any new work — same price, better across the board; stay on 4.7 only if you have pinned it for production stability.
Choose Claude Opus 4.8
Anthropic's flagship model for agentic coding, computer use, and multi-agent orchestration.
Try Claude Opus 4.8 →Choose Claude Opus 4.7
Anthropic's flagship LLM — agentic coding king with 1M context
Try Claude Opus 4.7 →Frequently Asked Questions
Is Claude Opus 4.8 better than Claude Opus 4.7?
Claude Opus 4.8 is the better choice for any new work, and it costs exactly the same as Opus 4.7 — $5 per million input tokens and $25 per million output tokens. On Anthropic's own comparison table it wins all three head-to-head benchmarks (SWE-bench Verified 88.6% vs 87.6%, SWE-bench Pro 69.2% vs 64.3%, Terminal-Bench 2.1 74.6% vs 66.1%), and it adds Fast Mode plus a roughly 4x lower rate of letting flaws slip past its own code review. Be honest about the size of the gains: the SWE-bench Verified jump is only one point, so it is marginal. The real upgrade is on SWE-bench Pro (+4.9), Terminal-Bench (+8.5), agentic reliability, and the new Fast Mode option. Because the price is identical, there is no reason to start new projects on 4.7. The only case for staying on Opus 4.7 is if you have pinned it for production stability and your pipeline is validated against that exact version. Bottom line: Opus 4.8 for any new work — same price, better across the board; stay on 4.7 only if you have pinned it for production stability.
Which is cheaper, Claude Opus 4.8 or Claude Opus 4.7?
Claude Opus 4.8 is priced at $5 in / $25 out per M tokens. Claude Opus 4.7 is priced at $5 in / $25 out per M tokens. Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Opus 4.8 and Claude Opus 4.7?
The key differences span across 12 features we compared. For Release date, Claude Opus 4.8 offers May 28, 2026 while Claude Opus 4.7 offers April 16, 2026. For Input price (per 1M tokens), Claude Opus 4.8 offers $5.00 while Claude Opus 4.7 offers $5.00. For Output price (per 1M tokens), Claude Opus 4.8 offers $25.00 while Claude Opus 4.7 offers $25.00. See the full feature comparison table above for all details.