Claude Fable 5 vs Grok 4.3: We Tested Anthropic's New Capability King vs the Cheapest Frontier Model


Fable 5 tops the Intelligence Index by a wide margin and posts 80.3% on SWE-Bench Pro; Grok 4.3 is 20x cheaper on output and markedly faster. Split verdict.

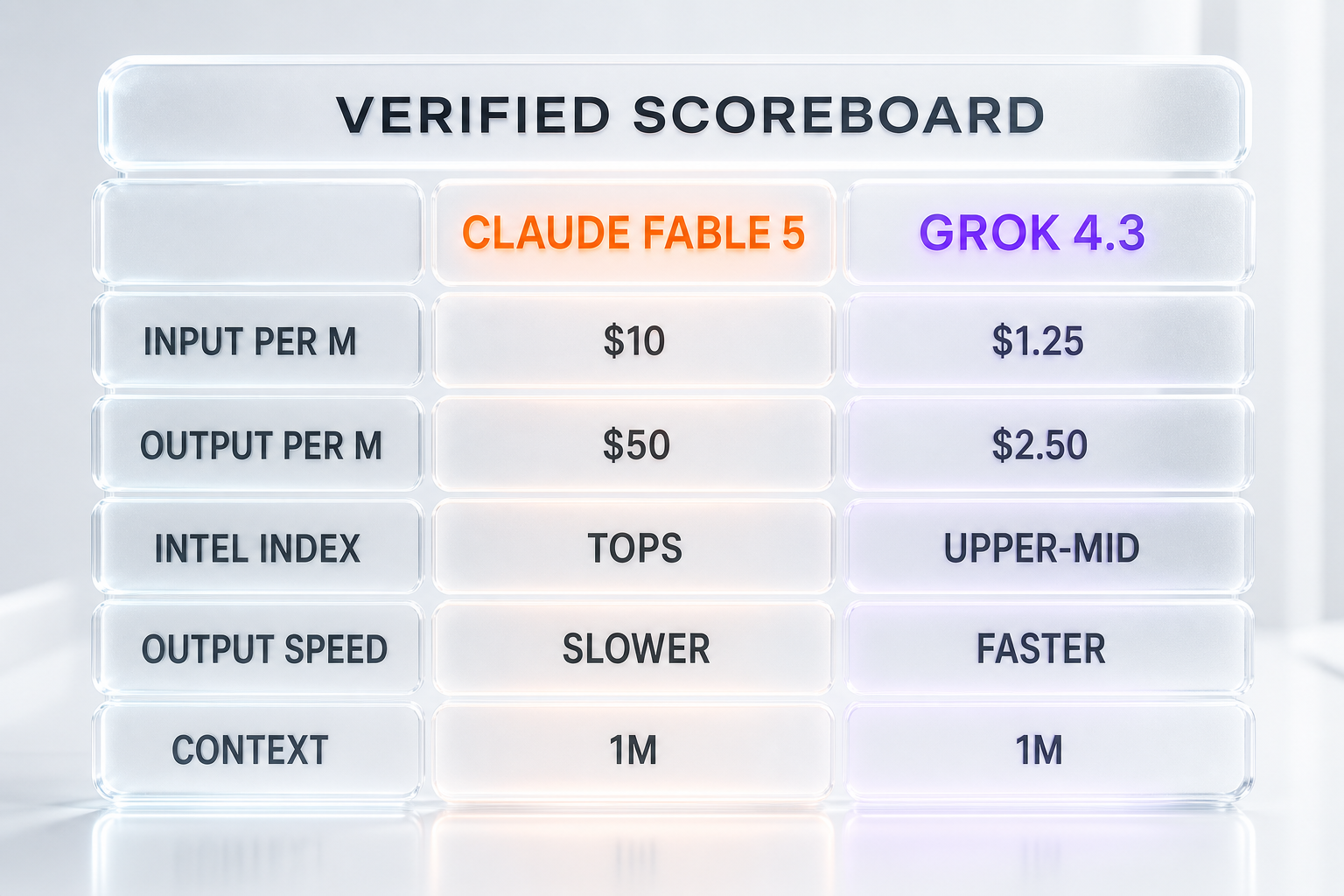
Feature Comparison
| Feature | Claude Fable 5 | Grok 4.3 |
|---|---|---|
| API input price (per million tokens) | $10.00 (verified) | $1.25 (verified) |
| API output price (per million tokens) | $50.00 (verified) | $2.50 (verified) |
| Artificial Analysis Intelligence Index | Tops the index | Upper-mid tier |
| SWE-Bench Pro | 80.3% (early reported) | No matching published figure |
| GDPval-AA agentic score | ~1,932 (early reported) | 1,500 (Artificial Analysis) |
| Output speed (Artificial Analysis) | Slower | Faster |
| Declared context window | 1,000,000 tokens | 1,000,000 tokens |
| Image input (vision) | Supported | Supported |
| Native file generation | Not offered | PPTX, PDF, XLSX in chat |
| Real-time data access | Web search and web fetch tools (per-search billing) | Real-time X data |
| API style | Anthropic Messages API | OpenAI-compatible REST API |
Pricing Comparison
Claude Fable 5
Grok 4.3
Detailed Comparison
Claude Fable 5 and Grok 4.3 are the two frontier large language models being compared here. Claude Fable 5 is Anthropic's most capable widely released model, generally available June 9, 2026 in a new tier above Opus, priced at $10 per million input tokens and $50 per million output tokens with a one million token context window and 128,000 output tokens. Grok 4.3 is xAI's cheapest frontier-tier model, launched April 30, 2026, priced at $1.25 per million input tokens and $2.50 per million output tokens, also with a one million token context window. On the Artificial Analysis Intelligence Index — the one independent benchmark scored the same way for both — Fable 5 tops the ranking, leading by a wide margin, while Grok 4.3 sits in the upper-mid tier. Grok 4.3 costs twenty times less on output tokens and runs substantially faster. We tested both: Fable 5 wins raw capability, agentic coding, and reasoning; Grok 4.3 wins cost, output speed, and real-time data access. There is no single overall winner — it is a split decision by workload.
Quick Verdict
We ran both models side-by-side in our own production workflow and against the published, like-for-like figures. Here is the short version, before the detail:
- Best for raw capability, agentic coding, and complex reasoning: Claude Fable 5. It tops the Artificial Analysis Intelligence Index, leading by a wide margin over Grok 4.3, and its reported 80.3 percent on SWE-Bench Pro is the highest figure any generally available model has posted.
- Best for cost per token: Grok 4.3 — and the gap is enormous. Output is $2.50 per million tokens versus $50 for Fable 5, twenty times cheaper, with input at $1.25 versus $10, eight times cheaper.
- Best for raw output speed: Grok 4.3, measured by Artificial Analysis as substantially faster than Fable 5 on output speed.
- Best for practical extras: Grok 4.3. Both models accept image input for vision and neither takes video, but Grok generates PPTX, PDF, and XLSX files directly in chat and carries real-time access to data from X — neither of which Fable 5 offers.
- Tie on context window: both declare one million tokens. Fable 5 caps output at 128,000 tokens per request; xAI does not publish a matching output figure for Grok 4.3.
- The honesty caveat: Fable 5 silently falls back to Claude Opus 4.8 on requests its safety classifiers flag in cybersecurity, biology, and chemistry — a unique behavior we explain below, because no other frontier model swaps itself out mid-request.
We did not crown a single overall winner, and we will explain exactly why in the methodology and the final verdict. The honest framing is this: if your bottleneck is capability on the hardest agentic and coding work, Fable 5 is the strongest model money can currently buy; if your bottleneck is cost or throughput, Grok 4.3 wins by one of the widest price margins we have ever measured between two frontier-tier models.
Claude Fable 5 vs Grok 4.3 — Overview
What Is Claude Fable 5?
Claude Fable 5 is Anthropic's most capable widely released model, generally available since June 9, 2026 under the API identifier claude-fable-5. It is the first public model in a new tier above Opus — Anthropic's Mythos-class research lineage opened to regular API customers — and it is priced accordingly at $10 per million input tokens and $50 per million output tokens, exactly double Claude Opus 4.8. The model runs a one million token context window with up to 128,000 output tokens per request, and adaptive thinking is always on: there is no toggle to disable reasoning, and the raw chain of thought is never returned. Early reported launch figures put it at 80.3 percent on SWE-Bench Pro — ahead of Opus 4.8 at 69.2 percent, GPT-5.5 at 58.6 percent, and Gemini 3.1 Pro at 54.2 percent — and the independent Artificial Analysis Intelligence Index already ranks it at the top, ahead of the field by a wide margin. Two operational details stand out: requests its safety classifiers flag in cybersecurity, biology, or chemistry are silently handled by Opus 4.8 through a server-side fallback, and Fable 5 is a Covered Model under Anthropic's usage policy, which means a mandatory 30-day data retention with no zero-data-retention option.
What Is Grok 4.3?
Grok 4.3 is xAI's frontier reasoning model, launched April 30, 2026 on the general API. Its headline is price: at $1.25 per million input tokens and $2.50 per million output tokens, it remains the cheapest model anywhere near frontier-tier capability in mid-2026. It ranks in the upper-mid tier on the Artificial Analysis Intelligence Index — well above the reasoning-model median — and Artificial Analysis measures it among the faster frontier-tier models tested on output speed. Where Grok 4.3 genuinely stands apart is practical breadth: it accepts text and image input for vision (not video — xAI routes video to its separate Grok Imagine API), generates PowerPoint, PDF, and Excel files directly in chat, and retains xAI's real-time access to data from X. Its API is OpenAI-compatible, so most existing SDK code runs against it unchanged, and it declares a one million token context window, matching Fable 5.
How We Compared Them — and What We Did Not Do
We moved part of our own production workflow to Fable 5 on its GA day and have run Grok 4.3 on comparable tasks since spring — coding, multi-file refactors, document drafting, and agentic pipeline runs. We cross-checked everything against published figures, and to keep this comparison honest, we separated what we could verify like-for-like from what we could not.
What is verified and comparable. Pricing for both models was fetched directly from the vendors' own documentation, not from third-party summaries: Anthropic's models documentation for Fable 5 and xAI's models documentation for Grok 4.3. The Artificial Analysis Intelligence Index (Fable 5 at the top, leading by a wide margin over Grok 4.3, which sits in the upper-mid tier) and the output-speed measurements were produced by the same independent evaluator using the same methodology for both models, which makes them genuinely like-for-like. The context window figures come straight from each vendor's docs.
What is reported but not fully comparable. Fable 5's SWE-Bench Pro figure of 80.3 percent and its GDPval-AA agentic score near 1,932 are launch numbers relayed by early third-party coverage and not yet independently reproduced — we flag them as early reported figures, not settled facts. Grok 4.3 has no published SWE-Bench Pro number at all, so that row is one-sided. Grok's GDPval-AA score of 1,500 comes from Artificial Analysis, so the GDPval-AA row pairs an early reported figure against an independently scored one — close to like-for-like, but not perfectly so, and we say that plainly. Both models accept image input for vision and neither accepts video, so vision is a tie; native file generation is a Grok feature Fable 5 does not have, so it is a differentiator rather than a scored contest.
What we refuse to do. We did not invent a single overall score, and we did not solder together numbers from different sources to manufacture a winner. Where a figure is vendor-reported, we say so. Where it is third-party, we name the third party. Where one model has no comparable number, we leave the cell honest rather than guess.
Features and Benchmarks Comparison
Here is the side-by-side. Pricing rows are fetch-verified from vendor docs; benchmark rows name their evaluator; one-sided claims are flagged as such.
| Feature | Claude Fable 5 | Grok 4.3 | Winner |
|---|---|---|---|
| API input price (per million tokens) | $10.00 (verified) | $1.25 (verified) | Grok 4.3 |
| API output price (per million tokens) | $50.00 (verified) | $2.50 (verified) | Grok 4.3 |
| Artificial Analysis Intelligence Index | Tops the index, leads by a wide margin | Upper-mid tier | Claude Fable 5 |
| SWE-Bench Pro | 80.3% (early reported) | No matching published figure | Claude Fable 5 (claim) |
| GDPval-AA agentic score | ~1,932 (early reported) | 1,500 (Artificial Analysis) | Claude Fable 5 |
| Output speed (Artificial Analysis) | Slower | Faster | Grok 4.3 |
| Declared context window | 1,000,000 tokens | 1,000,000 tokens | Tie |
| Image input (vision) | Supported | Supported | Tie |
| Native file generation | Not offered | PPTX, PDF, XLSX in chat | Grok 4.3 |
| Real-time data access | Web search and web fetch tools (per-search billing) | Real-time X data | Grok 4.3 (for X) |
| High-risk request handling | Silent fallback to Claude Opus 4.8 (cybersecurity, biology, chemistry) | No equivalent disclosed | Not comparable |
| Data retention policy | Covered Model — mandatory 30-day retention, no zero-data-retention option | Not addressed in xAI model docs | Not comparable |
| API style | Anthropic Messages API | OpenAI-compatible REST API | Tie (preference) |
The pattern is stark. Fable 5 takes the three capability rows; Grok 4.3 takes price, speed, native file generation, and real-time data; context and image-input vision are ties. Nobody runs the table — but the margins on each side are the widest we have measured in a frontier comparison this year.
Pricing — Claude Fable 5 vs Grok 4.3 in 2026
This is the widest pricing gap we have ever put in a comparison table between two frontier-tier models, and for many teams it will decide the question on its own. Both prices below were fetched directly from the vendors' own documentation.
Claude Fable 5 Pricing
Standard API pricing is $10 per million input tokens and $50 per million output tokens — exactly double Claude Opus 4.8, and Anthropic's most expensive current model. The full one million token context window is served at that rate, with output capped at 128,000 tokens per request. There is no free tier and no trial at the API level; you pay per token from the first call. The softeners are real, though: prompt caching discounts cached input by 90 percent, which matters enormously for agent workloads that re-read the same large context, and Anthropic does not bill requests its classifiers refuse before output — if the fallback to Opus 4.8 triggers, a fallback credit refunds the prompt-cache cost of switching models. Batch processing discounts also apply for asynchronous work.
Grok 4.3 Pricing
Grok 4.3 is $1.25 per million input tokens and $2.50 per million output tokens — a single flat frontier-tier rate with no premium speed mode to budget around, because the base model already runs at high output speed. The math against Fable 5 is brutal: input is eight times cheaper and output is twenty times cheaper. On a job that produces fifty million output tokens a month, that is the difference between roughly $125 on Grok 4.3 and $2,500 on Fable 5 — before any input costs. For agent fleets, bulk classification, and high-volume generation where token spend dominates, that gap compounds every single day.
The honest caveat cuts the other way: cheaper tokens are only cheaper if the model finishes the job in a comparable number of tokens and attempts. On the hardest agentic tasks — the work Fable 5 was built for — a model that completes correctly in one pass can beat a twenty-times-cheaper model that needs three passes plus human review. We work through that math below.
Hands-On Notes — What We Saw Running Both
We switched part of our production pipeline to Fable 5 the day it went generally available and have run Grok 4.3 on comparable tasks since spring. These are qualitative impressions, not lab measurements, and we flag them as such.
Coding and multi-file work. Fable 5 is the strongest coding model we have used, full stop. On long multi-file refactors it needed visibly fewer human interventions than Opus 4.8 — which was already our benchmark for reliability — and the reported 80.3 percent SWE-Bench Pro figure matches what we see in practice: hard tasks that used to need a second pass now mostly land in one. Grok 4.3 codes competently on well-scoped tasks, but in our use it degraded faster on very long-context coding runs, and it is more eager to declare success on work that has not actually been verified.
Speed and responsiveness. Grok 4.3 feels dramatically faster, and the Artificial Analysis numbers back that up — markedly higher output speed than Fable 5, measured on the same harness. Fable 5's always-on adaptive thinking adds latency on top for hard prompts. For interactive chat and high-throughput generation, Grok is the more responsive experience by a wide margin.
Documents and real-time data. This is Grok's clearest practical edge. Both models read images for vision and neither takes video, but asking Grok for a finished PPTX deck or XLSX model directly in chat, or leaning on its live access to data from X, are things Fable 5 cannot do natively. For analyst, research, and presentation workflows, Grok saves real time that no capability lead on Fable's side gives back.
Reliability and self-checking. Fable 5 inherits and sharpens the trait we trust most in the Claude line: it verifies its own edits and flags problems instead of papering over them. In reliability-critical pipelines, that personality difference matters as much as the benchmark gap. One operational note from real use: the silent fallback to Opus 4.8 on flagged topics never triggered in our ordinary coding and writing work, but teams in security research should know that the model answering them may sometimes not be Fable 5 — Anthropic surfaces this in the API response, and it is the right design, but it is something to monitor.
The Cost-Versus-Capability Math
Because price and capability pull in opposite directions harder here than in any pairing we have reviewed, the practical decision usually reduces to one question: does the cheaper model finish the same job for less total spend, or does its lower capability force enough retries to erase a twenty-times price advantage?
High-volume, well-scoped work. A pipeline that classifies, summarizes, or drafts at scale and produces fifty million output tokens a month costs about $125 on Grok 4.3 and about $2,500 on Fable 5. For routine work both models complete on the first pass, Fable 5's capability lead buys you nothing — the task does not stress capability — and Grok 4.3's saving is close to pure margin. This is the clearest case for Grok, and it is not subtle: a twenty-fold output gap is large enough that even doubling Grok's attempts on occasional failures leaves it far ahead.
The hardest agentic and coding work. Now invert it. On long autonomous refactors, deep reasoning chains, and agent runs where a wrong answer means a retry — or a silent bug that ships — the token price is a minority of the true cost. If Fable 5 finishes correctly in one pass where a cheaper model needs two or three attempts plus an engineer's review hour, the per-token premium disappears into the noise. Our hands-on experience says Fable 5 is exactly that model for the hardest tier of work: it is the reason Anthropic can charge double its own flagship and still look rational.
The middle ground. Most real systems live between those poles, and the routing pattern is the answer: send cheap, high-volume, low-stakes steps to Grok 4.3 and reserve Fable 5 for the steps where capability is the constraint. Fable 5's 90 percent prompt-caching discount makes the mixed pipeline cheaper than it looks on paper, because the expensive model's repeated context is mostly cache reads. Neither model has to win the whole pipeline — and at these prices, neither should.
Ecosystem, API, and Day-to-Day Workflow
Beyond the headline numbers, the two models slot into different ecosystems, and that shapes how they feel to build with.
Grok 4.3. The standout integration story is the OpenAI-compatible REST API: a large amount of existing SDK and tooling code runs against Grok with minimal rewiring, which is a genuinely lower switching cost for teams already built on that standard. Layer on real-time access to data from X, image input for vision, and native document generation, and Grok 4.3 reads as a fast, cheap, broadly capable generalist that drops into an existing stack in an afternoon. The trade-offs: xAI's documentation is thinner than Anthropic's, the model's knowledge cutoff is listed at November 2024 in xAI's own docs — older than you would expect for an April 2026 model, offset in practice by its real-time data access — and there is no published statement on several operational details Anthropic documents exhaustively.
Claude Fable 5. Fable 5 lives at the top of Anthropic's stack — the Messages API, Claude Code, and availability across AWS, Google Cloud Vertex AI, and Microsoft Foundry from day one. It ships with the most complete agent toolkit Anthropic has offered at launch: an effort parameter to trade depth against spend, task budgets to cap agentic loops, a memory tool, context editing, and compaction for long-running sessions. Two policies deserve eyes-open acceptance before you commit: adaptive thinking cannot be disabled and the raw chain of thought is never returned, which breaks integrations that relied on reading or toggling reasoning; and Covered Model status means a mandatory 30-day data retention with no zero-data-retention option — a hard blocker for some compliance postures, and a row Grok's documentation simply does not address either way.
If your codebase is OpenAI-shaped and you value drop-in compatibility and price, Grok 4.3 is the lower-friction adoption. If you are building serious multi-agent systems and want the deepest capability ceiling plus the orchestration primitives to match, Fable 5 is the platform built for it — at a price that assumes you mean it.
Winner per Category
Best for Raw Capability and Agentic Coding: Claude Fable 5
Top of the Artificial Analysis Intelligence Index, leading by a wide margin over Grok 4.3, the highest reported SWE-Bench Pro figure of any generally available model at 80.3 percent, and a GDPval-AA agentic score reported near 1,932 against Grok's 1,500. In our own work it needed fewer interventions than any model we have run. If capability on hard tasks is the constraint, this is the strongest option on the market.
Best for Cost: Grok 4.3
At $1.25 input and $2.50 output per million tokens, Grok 4.3 is eight times cheaper on input and twenty times cheaper on output than Fable 5. For token-dominated workloads, nothing anywhere near frontier capability comes close — this is the widest price gap in any comparison we have published.
Best for Output Speed: Grok 4.3
Markedly faster than Fable 5 on output speed on the same Artificial Analysis harness. For latency-sensitive interactive products, Grok is the more responsive default, and Fable 5's always-on thinking widens the gap on hard prompts.
Best for Documents and Real-Time Data: Grok 4.3
Direct PPTX, PDF, and XLSX generation in chat, plus real-time access to data from X, are features Fable 5 does not offer. Both models accept image input for vision and neither takes video, so this edge is about file generation and live data, not video. For analysts, researchers, and anyone shipping decks and spreadsheets, Grok wins this outright.
Best for Reliability-Critical Pipelines: Claude Fable 5
This one is qualitative and we flag it as such: in our hands-on use, Fable 5's self-verifying behavior — checking its own edits, refusing to declare unverified work done — made it the model we trust in pipelines where a silent error is expensive. Grok 4.3 is more eager to declare success, which is fine for volume work and riskier where correctness is the product.
Context Window: A Tie
Both vendors declare one million tokens. Fable 5 documents a 128,000-token output ceiling per request; xAI does not publish a matching output figure for Grok 4.3, so on the declared input specification this is a genuine tie.
Pros and Cons
Claude Fable 5 Pros and Cons
Pros: Tops the Artificial Analysis Intelligence Index, leading by a wide margin. Highest reported SWE-Bench Pro score of any generally available model at 80.3 percent. Strongest, most self-verifying coder in our hands-on use, with fewer human interventions than Opus 4.8. Full one million token context with 128,000-token output. Complete agent toolkit at launch: effort parameter, task budgets, memory tool, context editing, compaction. A 90 percent prompt-caching discount that makes mixed pipelines affordable. Refused requests are not billed, and the Opus 4.8 fallback returns a clean response instead of a hard failure.
Cons: Twenty times more expensive than Grok 4.3 on output ($50 versus $2.50 per million tokens) and eight times on input. Slower on output speed than Grok 4.3. No native file generation (PPTX, PDF, XLSX). Adaptive thinking cannot be disabled and raw chain of thought is never returned. Covered Model status forces a mandatory 30-day data retention with no zero-data-retention option. Launch benchmark figures (SWE-Bench Pro 80.3 percent, GDPval-AA near 1,932) are early reported numbers not yet independently reproduced.
Grok 4.3 Pros and Cons
Pros: Cheapest frontier-tier model at $1.25 input and $2.50 output per million tokens — twenty times cheaper than Fable 5 on output. Fast output speed on Artificial Analysis. Native PPTX, PDF, and XLSX generation in chat. Real-time X data access. Image input for vision. OpenAI-compatible API so most existing SDK code runs unchanged. One million token context window.
Cons: Trails Fable 5 by a wide margin on the like-for-like Artificial Analysis Intelligence Index and on the GDPval-AA agentic score (1,500 versus a reported 1,932). No published SWE-Bench Pro figure to compare against Fable 5's 80.3 percent. Knowledge cutoff listed at November 2024 in xAI's own docs. Long-context coding degraded faster in our use, and the model is more eager to declare success on unverified work. Documentation is thinner than Anthropic's, with no published statement on data retention in the model docs.
When to Pick Claude Fable 5 vs Grok 4.3
Pick Claude Fable 5 if...
- Your primary workload is the hardest tier of agentic coding, long multi-file refactors, or deep reasoning where capability is the binding constraint.
- You need the most self-verifying model available for pipelines where a silent error costs more than the tokens.
- You are already on Anthropic's stack and want the deepest model with the full agent toolkit — effort control, task budgets, memory, compaction — from day one.
- Per-token cost is secondary to getting the hardest work right the first time, and prompt caching covers your repeated context.
Pick Grok 4.3 if...
- Cost per token dominates your budget — agent fleets, bulk generation, high-volume classification — and a twenty-times output saving changes your unit economics.
- You need raw output speed for interactive or latency-sensitive products.
- Your work involves generating decks, PDFs, and spreadsheets directly in chat, or leaning on real-time data from X.
- You want real-time X data or an OpenAI-compatible endpoint that drops into existing SDK code with minimal rewiring.
Frequently Asked Questions
Is Claude Fable 5 better than Grok 4.3 in 2026?
It depends on the workload, and we refuse to fake a single overall winner. On the one independent benchmark scored the same way for both — the Artificial Analysis Intelligence Index — Fable 5 tops the ranking, leading by a wide margin over Grok 4.3, and its reported 80.3 percent on SWE-Bench Pro is the highest of any generally available model. So Fable 5 is clearly the stronger model on raw capability. Grok 4.3 is twenty times cheaper on output tokens ($2.50 versus $50 per million), substantially faster, and offers native file generation and real-time data from X that Fable 5 does not — though both accept image input for vision and neither accepts video. Best for capability: Fable 5. Best for cost, speed, and document workflows: Grok 4.3.
How much do Claude Fable 5 and Grok 4.3 cost?
Claude Fable 5 is $10 per million input tokens and $50 per million output tokens on the standard API, fetched from Anthropic's models documentation — exactly double Claude Opus 4.8. Grok 4.3 is $1.25 per million input tokens and $2.50 per million output tokens, fetched from xAI's models documentation. That makes Grok 4.3 eight times cheaper on input and twenty times cheaper on output. Fable 5 softens its premium with a 90 percent prompt-caching discount on cached input and does not bill requests its safety classifiers refuse before output.
Which is better for agentic coding: Claude Fable 5 or Grok 4.3?
Claude Fable 5, and it is not close on the published evidence. Its reported SWE-Bench Pro score of 80.3 percent leads Claude Opus 4.8 at 69.2 percent, GPT-5.5 at 58.6 percent, and Gemini 3.1 Pro at 54.2 percent, while Grok 4.3 has no matching published figure. Its GDPval-AA agentic score is reported near 1,932 against 1,500 for Grok 4.3 from Artificial Analysis. In our own production coding, Fable 5 needed fewer human interventions than any model we have run. Grok 4.3 codes well on scoped tasks but degraded faster on long-context work in our use.
Which is cheaper, Claude Fable 5 or Grok 4.3?
Grok 4.3, by the widest margin in any comparison we have published. Output tokens are $2.50 per million versus $50 for Fable 5 — twenty times cheaper — and input is $1.25 versus $10, eight times cheaper. On fifty million output tokens a month, that is roughly $125 on Grok 4.3 against $2,500 on Fable 5. The caveat is that cheaper tokens only save money if the model finishes the job in a comparable number of attempts, which on the hardest agentic work is exactly where Fable 5 pulls ahead.
Which model is faster, Claude Fable 5 or Grok 4.3?
Grok 4.3. Artificial Analysis measured it as substantially faster than Claude Fable 5 on output speed, using the same harness for both. Fable 5's adaptive thinking is always on and cannot be disabled, which adds further latency on hard prompts in exchange for reasoning depth. For latency-sensitive interactive products, Grok 4.3 is the more responsive choice by a wide margin.
Which has the larger context window: Claude Fable 5 or Grok 4.3?
They tie on the declared specification — both vendors list a one million token context window. Anthropic additionally documents a 128,000-token output ceiling per request for Fable 5 and notes that its tokenizer produces roughly 30 percent more tokens than pre-Opus 4.7 models on the same text, which matters for cost math. xAI does not publish a matching output-token figure for Grok 4.3, so on the published input specification this is a genuine tie.
What is Claude Fable 5's fallback to Opus 4.8, and does it affect this comparison?
Fable 5 ships with safety classifiers watching for requests that touch cybersecurity, biology and chemistry, or model distillation. When one trips, the response is handled by Claude Opus 4.8 instead, returned cleanly rather than as a hard failure, and a fallback credit refunds the prompt-cache cost of the switch. For ordinary coding, writing, and analysis work — everything we ran — it never triggered. It matters for two reasons: security-research teams may sometimes get Opus 4.8 answers, and some of Fable 5's most impressive launch numbers were produced by the unrestricted Mythos-class sibling you cannot buy. Grok 4.3 discloses no equivalent mechanism.
Does Grok 4.3 handle file generation and modalities that Claude Fable 5 cannot?
On file generation, yes. Grok 4.3 generates PowerPoint, PDF, and Excel files directly in chat, while Claude Fable 5 produces text rather than finished document files. On input modalities the two are level: both accept text and image input for vision, and neither accepts video — xAI handles video through its separate Grok Imagine API, not Grok 4.3. For analyst, research, and presentation workflows, Grok 4.3's native file generation is its clearest practical advantage, and no capability lead on Fable 5's side substitutes for it.
Are the benchmark numbers in this comparison independently verified?
Partly, and we separate them carefully. The Artificial Analysis Intelligence Index (Fable 5 at the top, leading by a wide margin over Grok 4.3, which sits in the upper-mid tier) and the output-speed figures come from Artificial Analysis, an independent evaluator using the same methodology for both models — genuinely like-for-like. Pricing was fetched directly from each vendor's documentation. Fable 5's SWE-Bench Pro 80.3 percent and GDPval-AA near 1,932 are launch figures relayed by early third-party coverage and not yet independently reproduced, and Grok 4.3 has no published SWE-Bench Pro number. Our hands-on notes are clearly flagged as qualitative.
Can I switch between Claude Fable 5 and Grok 4.3 easily?
The plumbing differs more than usual. Grok 4.3 exposes an OpenAI-compatible API, so SDK code written against that standard runs with minimal changes. Fable 5 uses Anthropic's Messages API and adds two integration constraints: adaptive thinking is always on with no disable option, and the raw chain of thought is never returned, so integrations that relied on toggling or reading reasoning need a rethink. Prompts and guardrails also need retuning either way — Fable 5 is cautious and self-checking while Grok 4.3 is faster to declare success, and that personality gap shows up in agent behavior more than any API difference.
Do Claude Fable 5 and Grok 4.3 work together in the same agent stack?
Yes, and at this price gap routing is the rational architecture. A common setup sends cheap, fast, high-volume steps — bulk drafting, classification, and document processing — to Grok 4.3, and reserves Claude Fable 5 for the hardest reasoning, long-context coding, and reliability-critical steps where its capability lead earns the twenty-times output premium. Fable 5's 90 percent prompt-caching discount keeps the expensive side affordable on repeated context. Because Grok exposes an OpenAI-compatible endpoint and Fable 5 uses the Anthropic API, a task-type router can dispatch to each cleanly.
What are the alternatives to Claude Fable 5 and Grok 4.3?
The obvious one is Claude Opus 4.8 itself — half Fable 5's price at $5 input and $25 output per million tokens, 69.2 percent on SWE-Bench Pro, and the model Fable 5 falls back to on flagged requests. See our Claude Opus 4.8 vs GPT-5.5 and Claude Opus 4.8 vs Gemini 3.1 Pro comparisons for how the Opus tier matches up against the other frontier flagships, and our Claude Opus 4.7 vs Grok 4.3 piece for how the previous Anthropic generation fared against this same Grok model. If cost decides, Grok 4.3 remains the cheapest frontier-tier option on the market; if capability decides, Fable 5 now leads everything.
Final Verdict — A Split Decision With the Widest Margins Yet
Claude Fable 5 and Grok 4.3 are not competing for the same buyer, and pretending one wins outright would be dishonest. On the one independent benchmark scored identically for both, the Artificial Analysis Intelligence Index, Fable 5 tops the ranking, leading by a wide margin over Grok 4.3. Its reported 80.3 percent on SWE-Bench Pro is the highest figure any generally available model has posted, and in our own production work it is simply the most capable model we have ever run. That lead is real, and it is why the capability crown goes to Fable 5.
But Grok 4.3's advantages are just as real and, for most workloads by volume, more decisive. It is twenty times cheaper on output tokens and eight times cheaper on input — the widest frontier price gap we have measured — runs substantially faster on the same independent harness, and ships native document generation plus real-time data from X that Fable 5 does not offer at any price. Context window is a tie at one million tokens on both vendors' published specs.
Best for raw capability, agentic coding, and reliability-critical work: Claude Fable 5. Best for cost, output speed, native file generation, and real-time data: Grok 4.3. If you can only run one and your work is the hardest tier of agentic coding, pay for Fable 5 and let prompt caching soften the bill. If your work is high-volume, latency-sensitive, or built on document generation and live data, Grok 4.3 is the better buy by a margin no other frontier model approaches. Many teams should run both and route by task. All pricing here is fetch-verified from vendor docs; like-for-like benchmarks are from Artificial Analysis; early reported launch figures are flagged as such.

Last compared: June 2026. Pricing fetched directly from Anthropic and xAI documentation. Intelligence Index and output-speed figures from Artificial Analysis. Fable 5's SWE-Bench Pro and GDPval-AA launch figures are early reported numbers relayed by third-party coverage, not yet independently reproduced, and are flagged as such throughout. We moved production work to Claude Fable 5 on its GA day and have tested Grok 4.3 on comparable tasks since spring; hands-on observations are qualitative.
Our Verdict
Split verdict by workload, with the widest margins we have measured between two frontier-tier models. The capability crown goes to Claude Fable 5: it tops the independent Artificial Analysis Intelligence Index, well ahead of Grok 4.3, its reported 80.3 percent on SWE-Bench Pro is the highest of any generally available model (early reported figure, flagged as such), and in our hands-on production use it needed fewer human interventions than any model we have run. The cost-and-speed crown goes to Grok 4.3 by an enormous margin: $1.25 input and $2.50 output per million tokens against $10 and $50 for Fable 5 — eight times cheaper on input, twenty times cheaper on output, both fetch-verified from vendor docs — plus a markedly higher output speed on the same Artificial Analysis harness, native PPTX/PDF/XLSX file generation, and real-time data from X that Fable 5 does not offer. Both models accept image input for vision and neither accepts video. Context window is a tie at one million tokens. We did not crown a single overall winner: best for raw capability, agentic coding, and reliability-critical pipelines is Claude Fable 5; best for cost, output speed, native file generation, and real-time data is Grok 4.3. Many teams should run both and route by task, using Fable 5's 90 percent prompt-caching discount to keep the expensive side affordable.
Choose Claude Fable 5
Anthropic's most capable widely released model — the public, safety-classified Mythos-class frontier tier.
Try Claude Fable 5 →Choose Grok 4.3
xAI's cheapest frontier reasoning model — $1.25/$2.50 per 1M tokens, 1M context, real-time X data and slide gen.
Try Grok 4.3 →Frequently Asked Questions
Is Claude Fable 5 better than Grok 4.3?
Split verdict by workload, with the widest margins we have measured between two frontier-tier models. The capability crown goes to Claude Fable 5: it tops the independent Artificial Analysis Intelligence Index, well ahead of Grok 4.3, its reported 80.3 percent on SWE-Bench Pro is the highest of any generally available model (early reported figure, flagged as such), and in our hands-on production use it needed fewer human interventions than any model we have run. The cost-and-speed crown goes to Grok 4.3 by an enormous margin: $1.25 input and $2.50 output per million tokens against $10 and $50 for Fable 5 — eight times cheaper on input, twenty times cheaper on output, both fetch-verified from vendor docs — plus a markedly higher output speed on the same Artificial Analysis harness, native PPTX/PDF/XLSX file generation, and real-time data from X that Fable 5 does not offer. Both models accept image input for vision and neither accepts video. Context window is a tie at one million tokens. We did not crown a single overall winner: best for raw capability, agentic coding, and reliability-critical pipelines is Claude Fable 5; best for cost, output speed, native file generation, and real-time data is Grok 4.3. Many teams should run both and route by task, using Fable 5's 90 percent prompt-caching discount to keep the expensive side affordable.
Which is cheaper, Claude Fable 5 or Grok 4.3?
Claude Fable 5 is priced at $10 in / $50 out per M tokens. Grok 4.3 is priced at $1.25 in / $2.5 out per M tokens (free plan available). Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Fable 5 and Grok 4.3?
The key differences span across 11 features we compared. For API input price (per million tokens), Claude Fable 5 offers $10.00 (verified) while Grok 4.3 offers $1.25 (verified). For API output price (per million tokens), Claude Fable 5 offers $50.00 (verified) while Grok 4.3 offers $2.50 (verified). For Artificial Analysis Intelligence Index, Claude Fable 5 offers Tops the index while Grok 4.3 offers Upper-mid tier. See the full feature comparison table above for all details.