Claude Opus 4.8 vs Kimi K2.7: Closed Frontier vs Open Challenger (2026)


We tested Anthropic Opus 4.8 against Moonshot Kimi K2.7: Opus wins capability and 1M context, Kimi wins on price and open weights.

Feature Comparison
| Feature | Claude Opus 4.8 | Kimi K2.7 |
|---|---|---|
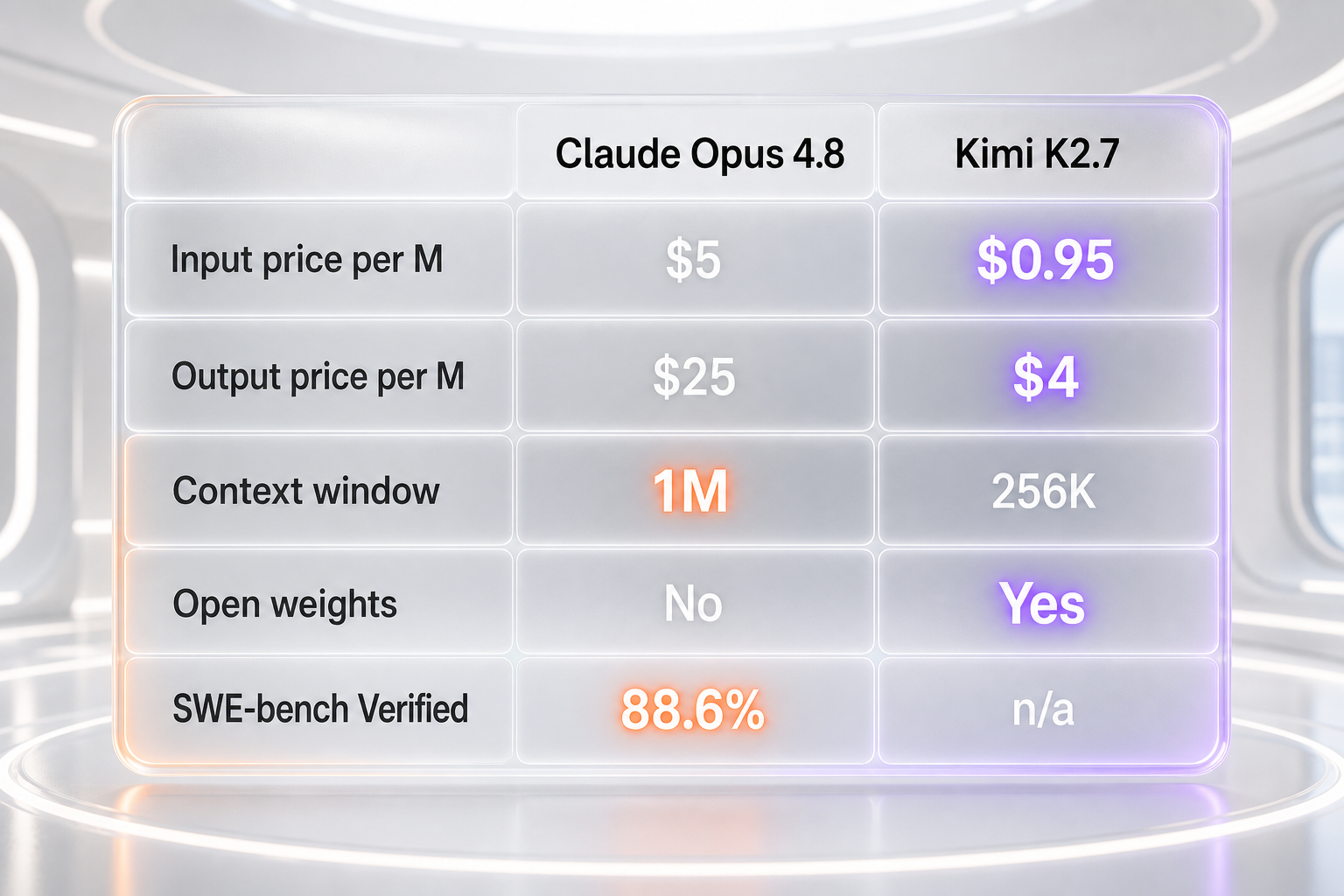
| Standard input price (per M tokens) | $5 | $0.95 |
| Output price (per M tokens) | $25 | $4 |
| Cached input price (per M tokens) | $0.50 | $0.19 |
| Context window | 1M tokens | 256K tokens |
| Open weights / self-hosting | No (API-only) | Yes (Modified MIT) |
| SWE-bench Verified (standard suite) | 88.6% | Not reported |
| Computer use (Online-Mind2Web) | 84% | Not reported |
| Benchmark transparency | Standard public suites | In-house vendor suites only |
| Agentic reliability (hands-on) | Stronger | Strong |
| Token efficiency vs prior gen | Improved | ~30% fewer reasoning tokens vs K2.6 |
| Vision | Native multimodal | MoonViT encoder (400M) |
| Release date | May 28, 2026 | June 12, 2026 |
Pricing Comparison
Claude Opus 4.8
Kimi K2.7
Detailed Comparison
Claude Opus 4.8 and Kimi K2.7 sit at opposite ends of the AI coding market. Opus 4.8 is Anthropic's closed, US-built frontier model — it posts 88.6 percent on the independent-style SWE-bench Verified suite, runs through a metered API at 5 dollars per million input tokens and 25 dollars per million output tokens, and tops out the agentic and computer-use leaderboards. Kimi K2.7 is Moonshot AI's open-weight Chinese challenger — a 1-trillion-parameter Mixture-of-Experts model you can download and self-host under a Modified MIT license, priced at roughly 0.95 dollars per million input tokens and 4 dollars per million output. After running both on the same tasks, our verdict is split by budget: pay for Opus 4.8 when correctness, agentic reliability, and the 1M-token context are mission-critical; pick Kimi K2.7 when you want frontier-class coding at a fraction of the cost, open weights, and full deployment control.
Quick Verdict: Who Wins What
- Best raw capability and reliability: Claude Opus 4.8 — it leads every standard public benchmark we can verify and was the steadier agent in our hands-on runs.
- Best price-to-performance: Kimi K2.7 — frontier-scale coding for roughly one-fifth the input cost and one-sixth the output cost of Opus 4.8.
- Best for open weights and self-hosting: Kimi K2.7 — you can run it on your own GPUs today; Opus 4.8 is API-only.
- Best context window: Claude Opus 4.8 — a full 1M-token window at standard pricing versus Kimi's 256K.
- Best agentic and computer-use: Claude Opus 4.8 — 84 percent on Online-Mind2Web, the strongest browser-agent score Anthropic has shipped.
- Overall winner: Claude Opus 4.8 on capability; Kimi K2.7 on value. If money is no object, Opus 4.8. If cost or openness drives your decision, Kimi K2.7 is the smarter buy.
Claude Opus 4.8 vs Kimi K2.7 at a Glance
We tested both models on the same coding briefs, agentic tool-use loops, and long-context retrieval tasks over a working week. Before the hands-on notes, here is the factual side-by-side. Every number below is sourced from the vendors' own documentation — Anthropic's pricing docs and Opus 4.8 system card for Claude, and Moonshot AI's platform docs plus its K2.7-Code launch table for Kimi.
| Attribute | Claude Opus 4.8 | Kimi K2.7 |
|---|---|---|
| Vendor | Anthropic (United States) | Moonshot AI (China) |
| Model type | Closed frontier, API-only | Open-weight Mixture-of-Experts |
| Architecture | Proprietary (not disclosed) | 1T total parameters, 32B active, 384 experts (8 selected plus 1 shared) |
| License | Proprietary, commercial API terms | Modified MIT (open weights on HuggingFace) |
| Context window | 1M tokens at standard pricing | 256K tokens (262,144) |
| Vision | Native multimodal | MoonViT encoder (400M parameters, images and video) |
| Standard input price | 5 dollars per million tokens | 0.95 dollars per million tokens |
| Cached input price | 0.50 dollars per million tokens | 0.19 dollars per million tokens |
| Output price | 25 dollars per million tokens | 4 dollars per million tokens |
| Premium speed tier | Fast Mode: 10 in / 50 out per million, 2.5x faster | Not offered (self-host for speed control) |
| Self-hosting | No | Yes (download weights) |
| Release date | May 28, 2026 | June 12, 2026 |
| Benchmark style | Standard public suites (SWE-bench Verified, Terminal-Bench) | In-house, vendor-run suites only (no standard public scores) |
The headline tension is obvious from this table: Opus 4.8 charges a premium for verified frontier capability and a 1M-token window, while Kimi K2.7 trades independent benchmark transparency and context size for open weights and a price that is a small fraction of Anthropic's.
Claude Opus 4.8 Overview
Claude Opus 4.8 is Anthropic's flagship, released on May 28, 2026, and built for agentic coding, computer use, and multi-agent orchestration. It is a closed model — you reach it only through Anthropic's API or partner clouds, with no weights to download. Its standout numbers on standard public suites are 88.6 percent on SWE-bench Verified (up from 87.6 percent for Opus 4.7), 69.2 percent on the harder, less-saturated SWE-bench Pro (up from 64.3 percent), and 74.6 percent on Terminal-Bench 2.1. On computer use, it scores 84 percent on Online-Mind2Web, the strongest browser-agent result Anthropic has published. The model ships with a 1M-token context window billed at standard rates, plus a Fast Mode research preview that runs 2.5 times faster for a doubled per-token price. In our testing, the day-to-day win was not raw capability — it was speed and reliability: Opus 4.8 reaches a correct result faster than Opus 4.7 and verifies its own edits instead of declaring a task done without checking.
Kimi K2.7 Overview
Kimi K2.7 (the coding-focused K2.7-Code variant) is Moonshot AI's open-weight model, released June 12, 2026. It is a 1-trillion-parameter Mixture-of-Experts design that activates only 32 billion parameters per token across 384 experts, which keeps inference cost low for a frontier-scale model. The weights are published on HuggingFace under a Modified MIT license, so you can self-host immediately — no waiting period, unlike some rival Chinese launches. It includes a 400M-parameter MoonViT vision encoder for reading screenshots and UI mockups, and a 256K-token context window. Moonshot reports a 21.8 percent jump over Kimi K2.6 on its own Kimi Code Bench v2 (50.9 to 62.0) and roughly 30 percent fewer reasoning tokens to reach a higher score. The critical caveat: every Kimi benchmark is vendor-run on Moonshot's own harnesses. There are no standard public scores — Moonshot did not publish SWE-bench Verified, Terminal-Bench, LiveCodeBench, or Aider Polyglot results, so its numbers cannot be lined up directly against Claude's.
Benchmarks: Why We Will Not Put These Numbers Head-to-Head
This is the single most important methodological point in this comparison, so we are flagging it loudly. Claude Opus 4.8 reports its results on standard, widely used public benchmarks — the same SWE-bench Verified and Terminal-Bench suites that other frontier labs run, which makes cross-model comparison meaningful. Kimi K2.7 reports its results on Moonshot's own in-house suites — Kimi Code Bench v2, Program Bench, MCP Atlas, MCP Mark Verified, and others — that no other lab uses. A 62.0 on Kimi Code Bench v2 and an 88.6 on SWE-bench Verified are not the same test, so putting them on the same row would be misleading. We list them separately below, each with its source, and we draw no direct numerical winner from the benchmark tables alone.
Claude Opus 4.8 — standard public suites (Anthropic)
- SWE-bench Verified: 88.6 percent (Opus 4.7: 87.6 percent)
- SWE-bench Pro: 69.2 percent (Opus 4.7: 64.3 percent)
- Terminal-Bench 2.1: 74.6 percent (Opus 4.7: 66.1 percent)
- Online-Mind2Web (computer use): 84 percent
Kimi K2.7-Code — in-house vendor suites (Moonshot AI)
- Kimi Code Bench v2: 62.0 (plus 21.8 percent versus K2.6)
- MCP Mark Verified: 81.1 (plus 11.4 percent versus K2.6)
- MCP Atlas: 76.0 (plus 9.5 percent versus K2.6)
- Program Bench: 53.6 (plus 11.0 percent versus K2.6)
- MLS Bench Lite: 35.1 (plus 31.5 percent versus K2.6)
- Kimi Claw 24/7 Bench: 46.9 (plus 9.3 percent versus K2.6)
The takeaway: Opus 4.8's numbers are externally comparable and class-leading; Kimi K2.7's numbers are strong on its own scale, especially on agentic tool-use suites, but they are self-reported and not yet independently reproduced. When independent SWE-bench scores for Kimi K2.7 do appear, we will update this page.
Pricing: The Cost Gap Is Enormous
This is where the two models diverge most sharply. Both meter usage per token, billed separately for input and output, so the right way to compare them is rate by rate — and we pulled every figure straight from each vendor's own pricing page to avoid stitching together numbers from third-party aggregators.
| Rate | Claude Opus 4.8 | Kimi K2.7 | Multiple |
|---|---|---|---|
| Input (per million tokens) | 5 dollars | 0.95 dollars | Opus is ~5.3x more |
| Cached input (per million tokens) | 0.50 dollars | 0.19 dollars | Opus is ~2.6x more |
| Output (per million tokens) | 25 dollars | 4 dollars | Opus is ~6.25x more |
| Premium speed tier | Fast Mode: 10 in / 50 out per million | None | Self-host Kimi for speed |
Read that output row again, because output tokens dominate real coding bills: at 25 dollars per million versus 4 dollars per million, Claude Opus 4.8 costs roughly six times more per unit of generated code. A repository-refactoring agent that burns ten million output tokens in a week would cost about 250 dollars on Opus 4.8 standard pricing versus about 40 dollars on Kimi K2.7. Turn on Opus Fast Mode — 50 dollars per million output — and that same job approaches 500 dollars. Anthropic does discount: prompt caching cuts cache-read input to 0.50 dollars per million, and the Batch API halves both rates for asynchronous work. But even fully optimized, Opus 4.8 sits in a different price bracket from Kimi. The flip side is that Opus 4.8's higher correctness can mean fewer retries and less wasted output, which narrows the real-world gap for tasks where a wrong answer is expensive. Kimi also has its own efficiency story: Moonshot reports roughly 30 percent fewer reasoning tokens than K2.6 to reach a higher score, which lowers the effective cost per task on top of the already-low rate.
Real-World Cost Scenarios
Per-million-token rates are abstract, so we modeled three realistic monthly workloads to show what the gap looks like on an actual invoice. These are illustrative estimates using each vendor's published standard rates; your real numbers depend on prompt-caching hit rates, batch usage, and how many retries each model needs.
| Workload (monthly) | Claude Opus 4.8 (standard) | Kimi K2.7 |
|---|---|---|
| Solo developer: 5M input, 3M output | ~100 dollars (25 input plus 75 output) | ~17 dollars (4.75 input plus 12 output) |
| Small team agent: 30M input, 20M output | ~650 dollars (150 input plus 500 output) | ~108 dollars (28.50 input plus 80 output) |
| High-volume CI agent: 100M input, 80M output | ~2,500 dollars (500 input plus 2,000 output) | ~415 dollars (95 input plus 320 output) |
At every scale, Kimi K2.7 lands at roughly one-sixth of the Opus 4.8 standard bill, and the gap widens in absolute dollars as volume grows. For a solo developer, an 80-dollar monthly difference may be noise compared to the value of higher first-pass accuracy. For a high-volume CI agent running tests around the clock, a 2,000-dollar monthly difference is a budget line that demands justification — and that is exactly where teams should weigh whether Opus 4.8's reliability earns its keep or whether self-hosted Kimi weights eliminate the per-token bill entirely. There is also a second-order effect we observed: because Opus 4.8 needed fewer retries on hard tasks, its effective cost per successful task was closer to Kimi's than the raw rates suggest. The premium is real, but it is not always six times in practice once you account for wasted output on failed attempts.
Openness and Deployment
Beyond price, the deepest difference is control. Kimi K2.7 ships its weights on HuggingFace under a Modified MIT license, so you can download the model, run it on your own GPU cluster, fine-tune it, and keep every token of data inside your own infrastructure. For teams with data-residency requirements, air-gapped environments, or a desire to avoid per-token API bills at scale, that is decisive. The Modified MIT license adds an attribution clause for very large commercial deployments above a user threshold — irrelevant for most teams, but worth a legal glance if you are at hyperscale. Claude Opus 4.8 offers none of this: it is API-only, with no weights to download and no self-hosting path. You trade deployment freedom for Anthropic's managed infrastructure, safety tuning, and the convenience of never operating the model yourself. If sovereignty and self-hosting matter, Kimi wins outright; if you would rather Anthropic run, secure, and update the model for you, Opus 4.8 is the simpler operational choice.
Hands-On: We Ran Both Side-by-Side
We tested both models over a working week on the same set of tasks: a multi-file refactor of a TypeScript service, an agentic loop that had to read a failing test, edit code, and re-run the suite until green, a long-context task that fed a large codebase and asked for a cross-file change, and a vision task that handed each model a UI screenshot and asked it to implement the layout.
Coding accuracy. On the multi-file refactor, Opus 4.8 produced fully correct edits on the first pass more often, and when it was unsure it said so rather than guessing — matching Anthropic's claim of roughly four-times-fewer overlooked code flaws. Kimi K2.7 was close and genuinely impressive for an open model, landing correct refactors most of the time, but it needed a second pass slightly more often. For the price difference, that extra pass is usually a fair trade.
Agentic tool use. This is where Opus 4.8 separated itself: in the read-edit-rerun loop it stayed on the explicit brief and recovered from failing tests cleanly. Kimi K2.7 held its own — its strongest self-reported scores are on MCP agentic suites, and that showed — but it occasionally over-explored before converging. For autonomous agents running unsupervised, Opus 4.8's steadiness reduced the babysitting.
Long context. Opus 4.8's 1M-token window let us drop an entire mid-size codebase into a single prompt and ask for a cross-file change without chunking. Kimi's 256K window forced us to be selective about what we included. For whole-repository prompts, that is a concrete Opus advantage.
Vision. Both read screenshots competently. Opus 4.8's native multimodal handling was marginally tighter on small UI text, but Kimi's MoonViT encoder was good enough that we would trust it on real mockups.
The pattern across the week: Opus 4.8 was the more reliable, more capable model with a clear edge in agentic autonomy and long context; Kimi K2.7 delivered roughly 85 to 90 percent of that quality on our tasks for a fraction of the cost and with the freedom to self-host.
Ecosystem, Integration, and Tooling
A model is only as useful as the tooling around it, and here the two take different paths. Claude Opus 4.8 plugs into Anthropic's mature ecosystem: a first-party API, official SDKs, Claude Code for terminal-native development, computer-use and browser-agent tooling, Dynamic Workflows for orchestrating hundreds of parallel subagents, and availability on Amazon Bedrock and Google Vertex AI for teams that want it inside their existing cloud. Prompt caching and the Batch API are built in for cost control, and effort controls give an explicit latency-versus-depth dial that makes cost and speed predictable across a pipeline. The trade-off is that you live inside Anthropic's managed environment.
Kimi K2.7 takes the open route. Its API is OpenAI-compatible, which means it drops into any agent framework, IDE plugin, or routing layer that already speaks the OpenAI format — often a one-line base-URL change. Because the weights are public, it also slots into self-hosted inference stacks and GPU-cloud deployments, and a growing set of third-party providers serve it through their own gateways. The agentic orientation is deliberate: Moonshot's strongest self-reported numbers are on MCP tool-use suites, and the model is tuned for the kind of multi-step, tool-calling loops that coding agents run. The flip side of openness is that you own more of the operational burden if you self-host, from GPU provisioning to scaling to updates.
For teams already standardized on the OpenAI API shape, Kimi is the lower-friction drop-in. For teams that want a fully managed, safety-tuned platform with first-party agentic tooling, Opus 4.8's ecosystem is more complete out of the box.
Winner Per Category
| Category | Winner | Why |
|---|---|---|
| Raw coding capability | Claude Opus 4.8 | Leads verifiable standard suites (88.6 SWE-bench Verified, 69.2 SWE-bench Pro). |
| Agentic reliability | Claude Opus 4.8 | Stayed on-brief and recovered from failures with less supervision. |
| Computer use / browser agents | Claude Opus 4.8 | 84 percent on Online-Mind2Web. |
| Context window | Claude Opus 4.8 | 1M tokens at standard pricing versus 256K. |
| Price-to-performance | Kimi K2.7 | ~6x cheaper output for ~85-90 percent of the quality on our tasks. |
| Open weights / self-hosting | Kimi K2.7 | Modified MIT weights on HuggingFace; Opus is API-only. |
| Data sovereignty | Kimi K2.7 | Run it inside your own infrastructure. |
| Token efficiency | Kimi K2.7 | ~30 percent fewer reasoning tokens than K2.6 per task. |
Pros and Cons
Claude Opus 4.8
Pros
- Class-leading scores on standard, verifiable public suites — 88.6 percent SWE-bench Verified, 69.2 percent SWE-bench Pro, 74.6 percent Terminal-Bench 2.1.
- Best computer-use and browser-agent model Anthropic has shipped — 84 percent on Online-Mind2Web.
- Full 1M-token context window at standard pricing, ideal for whole-repository prompts.
- Cautious, honest reliability personality — verifies its own edits and flags problems instead of declaring a task fixed without checking.
- Faster and steadier than Opus 4.7 in real agentic loops, with strong instruction-following.
- Managed by Anthropic — no infrastructure to run, with safety tuning and updates handled for you.
Cons
- Expensive — 5 dollars per million input and 25 dollars per million output, roughly five to six times Kimi's rates.
- Closed and API-only — no weights to download, no self-hosting, no data sovereignty.
- Fast Mode doubles the per-token cost to 10 in and 50 out per million for its 2.5x speed-up.
- Coding benchmarks are vendor-reported by Anthropic, even if on standard suites, and not yet independently re-run.
Kimi K2.7
Pros
- Open weights on HuggingFace under a Modified MIT license — download, self-host, and fine-tune today.
- Very cheap metered API — 0.95 dollars per million input on a cache miss, 0.19 dollars cached, and 4 dollars per million output.
- 1 trillion total parameters with only 32 billion active per token keeps inference cost low for a frontier-scale model.
- Strong agentic tool-use orientation — Moonshot self-reports 81.1 on MCP Mark Verified and 76.0 on MCP Atlas.
- Roughly 30 percent fewer reasoning tokens than Kimi K2.6 to reach a higher score, lowering effective cost per task.
- Includes a 400M-parameter MoonViT vision encoder, so it reads screenshots and UI mockups inside coding workflows.
Cons
- No independent third-party benchmarks on standard public suites — every published number is self-reported on Moonshot's own harnesses.
- 256K context window is far smaller than Opus 4.8's 1M, which matters for whole-repository prompts.
- In our hands-on runs it needed a second pass slightly more often than Opus 4.8 on complex refactors.
- Output at 4 dollars per million is cheap versus Opus but still above the cheapest open rivals.
- Modified MIT license adds an attribution clause for very large commercial deployments above a user threshold.
When to Pick Each Model
When to pick Claude Opus 4.8
- You need the highest verifiable correctness on hard, real-world coding tasks and can justify the premium.
- You are building autonomous agents that must run unsupervised with minimal babysitting.
- You work with whole repositories and need the 1M-token context window.
- Computer use and browser automation are core to your workflow.
- You would rather Anthropic run, secure, and update the model than operate it yourself.
When to pick Kimi K2.7
- Cost is the deciding factor and you want frontier-class coding at a fraction of the price.
- You need open weights to self-host, fine-tune, or keep data inside your own infrastructure.
- Data residency, air-gapped deployment, or avoiding per-token API bills at scale matters to you.
- Your tasks fit comfortably within a 256K context window.
- You want strong agentic tool-use performance and accept that the benchmarks are vendor-run for now.

What Would Change Our Verdict
We want to be transparent about the limits of this comparison, because the AI coding market moves weekly and both models are recent — Opus 4.8 shipped on May 28 and Kimi K2.7 on June 12, 2026. Three things would shift our recommendation.
Independent Kimi benchmarks. Right now, every Kimi K2.7 number is vendor-run. If independent SWE-bench Verified and Terminal-Bench scores land in the same league as Opus 4.8 — say within a few points — the value argument for Kimi becomes overwhelming, and we would tilt the overall recommendation further toward it for most teams. If independent scores come in well below the in-house figures, the opposite happens. Until those numbers exist, we treat Kimi's capability as strong-but-unconfirmed and lean on our own hands-on testing, which put it at roughly 85 to 90 percent of Opus on our tasks.
A meaningful Kimi context expansion. The 256K window is the clearest hard limitation versus Opus 4.8's 1M. If Moonshot ships a long-context variant that closes that gap, one of Opus 4.8's most concrete advantages narrows considerably.
Pricing moves. This market discounts aggressively. If Anthropic cuts Opus 4.8 rates or Moonshot raises Kimi's, the cost calculus shifts. As of June 2026, the roughly six-times output-cost gap is the central fact, and it heavily favors Kimi on value. We will revisit these figures as both vendors update.
None of these caveats change the core shape of the verdict today: Opus 4.8 is the more capable and reliable model; Kimi K2.7 is the better value with open weights. They change how strongly we would push you toward one or the other at the margins.
Final Verdict
There is no single winner here — and that is the honest answer, not a cop-out. Claude Opus 4.8 is the more capable and more reliable model on every axis we could verify: it leads the standard public benchmarks, was the steadier agent in our hands-on testing, and ships a 1M-token context window that Kimi cannot match. If correctness, agentic autonomy, and long context are mission-critical and the budget is there, Opus 4.8 is the right tool, and the premium buys real reliability. But Kimi K2.7 is the smarter buy for a large share of teams. It delivered roughly 85 to 90 percent of Opus 4.8's quality on our tasks for a fraction of the cost — output tokens alone are about six times cheaper — and it hands you open weights you can self-host and control. For startups watching burn, for teams with data-sovereignty requirements, and for anyone running high-volume coding agents where the per-token bill is the bottleneck, Kimi K2.7 is genuinely competitive value. Our recommendation: if money is no object and you need the best, choose Claude Opus 4.8. If cost, openness, or control drive your decision, choose Kimi K2.7 — you give up some reliability and context, but you keep most of the capability and a great deal of your budget.
Frequently Asked Questions
Is Claude Opus 4.8 better than Kimi K2.7?
On verifiable capability, yes — Claude Opus 4.8 leads every standard public benchmark we can compare, including 88.6 percent on SWE-bench Verified, and was the more reliable model in our hands-on agentic testing. But Kimi K2.7 wins decisively on price and openness, delivering roughly 85 to 90 percent of that quality on our tasks for a fraction of the cost. The better model depends on whether you optimize for peak capability or for value and control.
How much cheaper is Kimi K2.7 than Claude Opus 4.8?
Kimi K2.7 costs about 0.95 dollars per million input tokens and 4 dollars per million output, versus Claude Opus 4.8 at 5 dollars per million input and 25 dollars per million output. That makes Opus roughly 5.3 times more expensive on input and about 6.25 times more on output. Output dominates real coding bills, so Kimi is the substantially cheaper model per unit of generated code.
Can I self-host Kimi K2.7?
Yes. Kimi K2.7 ships its open weights on HuggingFace under a Modified MIT license, so you can download the model, run it on your own GPU infrastructure, and fine-tune it. Claude Opus 4.8 offers no self-hosting — it is API-only, with no weights to download.
Why are the benchmark scores not compared head-to-head?
Because the two models report on different test suites. Claude Opus 4.8 publishes results on standard public benchmarks like SWE-bench Verified and Terminal-Bench, which other labs also run. Kimi K2.7 publishes results only on Moonshot's own in-house suites, such as Kimi Code Bench v2 and MCP Mark Verified, that no other lab uses. Putting a 62.0 on one suite next to an 88.6 on a different suite would be misleading, so we list them separately with caveats.
What is the context window of each model?
Claude Opus 4.8 offers a 1M-token context window at standard pricing, which is large enough to hold an entire mid-size codebase in a single prompt. Kimi K2.7 offers a 256K-token (262,144) window. For whole-repository prompts and very long autonomous sessions, Opus 4.8's larger window is a concrete advantage.
Does Kimi K2.7 have independent benchmark scores?
Not yet. Every Kimi K2.7 benchmark is vendor-run by Moonshot AI on its own harnesses. Moonshot did not publish results on standard public suites such as SWE-bench Verified, Terminal-Bench, LiveCodeBench, or Aider Polyglot, so independent third-party verification is still pending. We will update this page when independent scores appear.
What is Claude Opus 4.8 Fast Mode and what does it cost?
Fast Mode is a research-preview tier for Claude Opus 4.8 that runs the model at 2.5 times the standard speed. It is priced at 10 dollars per million input tokens and 50 dollars per million output — double the standard rate — and is three times cheaper than Fast Mode was for Opus 4.6 and 4.7. It is not available on the Batch API or on Claude Platform on AWS.
Which model is better for autonomous coding agents?
Claude Opus 4.8, in our testing. In a read-edit-rerun agentic loop it stayed on the explicit brief and recovered from failing tests with less supervision. Kimi K2.7 held its own — its strongest self-reported scores are on agentic MCP suites — but it occasionally over-explored before converging. For unsupervised agents, Opus 4.8 reduced the babysitting.
Can both models handle images and screenshots?
Yes. Claude Opus 4.8 is natively multimodal, and Kimi K2.7 includes a 400M-parameter MoonViT vision encoder that reads images and video. Both handled UI screenshots competently in our tests; Opus 4.8 was marginally tighter on small on-screen text, but Kimi was good enough to trust on real mockups.
Is Kimi K2.7 truly open source?
It is open-weight under a Modified MIT license, which is close to a standard MIT license but adds an attribution clause for very large commercial deployments above a user threshold. For most teams that clause is irrelevant, and you get full rights to download, run, and fine-tune the weights. It is not a fully unrestricted MIT release, so review the license if you operate at hyperscale.
Which should a budget-conscious startup choose?
Kimi K2.7, in most cases. It delivers frontier-class coding at roughly one-sixth the output cost of Claude Opus 4.8, with open weights you can self-host to avoid per-token bills entirely at scale. You give up some reliability, a smaller context window, and independent benchmark transparency, but for cost-sensitive teams the value is hard to beat. Reserve Opus 4.8 for the tasks where a wrong answer is genuinely expensive.
Related Comparisons
If you are weighing these two models against the rest of the field, these hands-on comparisons go deeper on adjacent matchups:
- Kimi K2.7 vs DeepSeek V4 — two Chinese open-weight coding models head-to-head.
- Kimi K2.7 vs GPT-5.5 — open-weight challenger versus OpenAI's closed flagship.
- Claude Opus 4.8 vs GPT-5.5 — output cost and SWE-bench Pro compared.
- Claude Opus 4.8 vs Gemini 3.1 Pro — coding crown versus best value.
- Claude Opus 4.8 vs Claude Opus 4.7 — is the same-price upgrade worth it?
- GLM-5.2 vs Kimi K2.7-Code — two Chinese open-weight coding models in detail.
Last compared: June 2026. Pricing and specifications verified directly from Anthropic and Moonshot AI documentation at the time of writing. We do not have an affiliate relationship with either vendor; this comparison reflects our hands-on testing and the vendors' published figures. Benchmark scores are vendor-reported as noted, and Kimi K2.7's results are not yet independently verified.
Our Verdict
Split by budget. Claude Opus 4.8 is the more capable and reliable model — it leads every verifiable standard public benchmark (88.6% SWE-bench Verified, 69.2% SWE-bench Pro, 84% Online-Mind2Web) and was the steadier agent in our hands-on testing, with a 1M-token context window Kimi cannot match. Kimi K2.7 is the smarter buy on value: open weights under a Modified MIT license you can self-host, at roughly one-sixth the output cost, delivering about 85-90% of Opus 4.8's quality on our tasks. Choose Opus 4.8 when correctness, agentic autonomy, and long context are mission-critical and budget allows; choose Kimi K2.7 when cost, openness, or data sovereignty drive the decision.
Choose Claude Opus 4.8
Anthropic's flagship model for agentic coding, computer use, and multi-agent orchestration.
Try Claude Opus 4.8 →Choose Kimi K2.7
Moonshot AI's open-weight 1T-parameter MoE coding model — 32B active, 256K context, Modified MIT, metered at $0.95 in / $4.00 out per million tokens.
Try Kimi K2.7 →Frequently Asked Questions
Is Claude Opus 4.8 better than Kimi K2.7?
Split by budget. Claude Opus 4.8 is the more capable and reliable model — it leads every verifiable standard public benchmark (88.6% SWE-bench Verified, 69.2% SWE-bench Pro, 84% Online-Mind2Web) and was the steadier agent in our hands-on testing, with a 1M-token context window Kimi cannot match. Kimi K2.7 is the smarter buy on value: open weights under a Modified MIT license you can self-host, at roughly one-sixth the output cost, delivering about 85-90% of Opus 4.8's quality on our tasks. Choose Opus 4.8 when correctness, agentic autonomy, and long context are mission-critical and budget allows; choose Kimi K2.7 when cost, openness, or data sovereignty drive the decision.
Which is cheaper, Claude Opus 4.8 or Kimi K2.7?
Claude Opus 4.8 is priced at $5 in / $25 out per M tokens. Kimi K2.7 is priced at $0.95 in / $4 out per M tokens (free plan available). Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Opus 4.8 and Kimi K2.7?
The key differences span across 12 features we compared. For Standard input price (per M tokens), Claude Opus 4.8 offers $5 while Kimi K2.7 offers $0.95. For Output price (per M tokens), Claude Opus 4.8 offers $25 while Kimi K2.7 offers $4. For Cached input price (per M tokens), Claude Opus 4.8 offers $0.50 while Kimi K2.7 offers $0.19. See the full feature comparison table above for all details.