Claude Fable 5 vs Claude Opus 4.8: Is Twice the Price Worth It?


Fable 5 costs exactly double Opus 4.8 — $10 input, $50 output per million tokens. We ran both on the same pipelines. Who needs the upgrade, who doesn't.

Feature Comparison
| Feature | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|
| Positioning | New tier above Opus — most capable widely released | Opus-tier flagship |
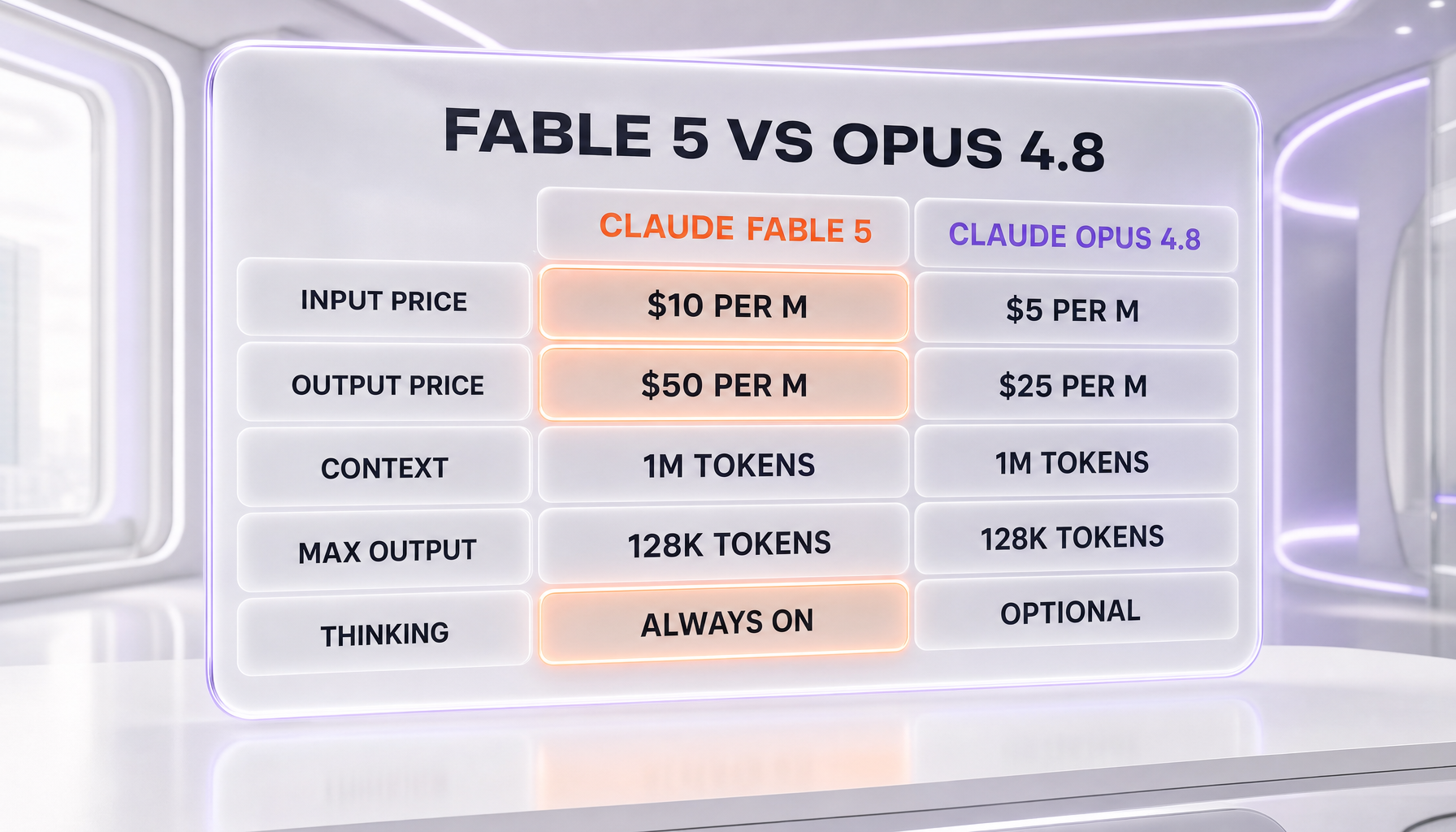
| Input price (per 1M tokens) | $10.00 | $5.00 |
| Output price (per 1M tokens) | $50.00 | $25.00 |
| Context window | 1M tokens | 1M tokens |
| Max output | 128K tokens | 128K tokens |
| Prompt caching | 90% discount on cache reads | 90% discount on cache reads |
| SWE-bench Pro | ~80.3% (early third-party runs) | 69.2% (Anthropic's launch table) |
| Adaptive thinking | Always on — cannot be disabled | Optional — can run without thinking |
| Fast Mode (~2.5x speed) | Not offered | Yes — $10 input, $50 output per 1M tokens |
| Frontier safety classifiers | Always active — cyber, bio, chemistry refusals | Standard safety stack |
| Data retention | 30-day minimum, Covered Model — no zero data retention | Standard controls, ZDR-compatible |
| General availability | June 9, 2026 | May 28, 2026 |
Pricing Comparison
Claude Fable 5
Claude Opus 4.8
Detailed Comparison
Claude Fable 5 vs Claude Opus 4.8: Fable 5 is Anthropic's most capable widely released model, a new tier above Opus, generally available since June 9, 2026 at $10 per million input tokens and $50 per million output tokens — exactly double Opus 4.8's $5 and $25. Both offer a 1M-token context window, 128K output, and a 90 percent prompt-caching discount. Fable 5 runs adaptive thinking always-on, ships with safety classifiers that can refuse cyber, bio, and chemistry requests, and requires 30-day data retention. Verdict: Fable 5 wins on raw capability and is worth double for your hardest agentic work; Opus 4.8 is the value winner, the right default for most workloads — and the model Anthropic's own integration pattern falls back to when Fable 5 refuses.
Quick Verdict
Winner: Claude Fable 5 on raw capability — but this is the rare comparison where the loser stays in your stack. Fable 5 is not an Opus upgrade; it is a new tier above Opus, the first model Anthropic has priced at a premium over its flagship since the Opus 4.5 era. The question is not "which model is better" — Anthropic itself answers that by calling Fable 5 its most capable widely released model. The question is whether the better model is worth exactly twice the bill, and the honest answer depends on which tenth of your workload you are looking at. We have been running Fable 5 against the same production pipelines we already run on Claude Opus 4.8 since it went GA on June 9, 2026, and the pattern is already clear: Fable 5 pulls ahead on the longest, hardest agentic runs, and Opus 4.8 remains more than good enough — at half the price — for nearly everything else.
- Claude Fable 5 wins for: maximum raw capability, the hardest long-horizon agentic work, multi-agent coordination, and any task where you were previously stacking retries on Opus 4.8 to get over the line. Early third-party runs put it around 80.3 percent on SWE-bench Pro — though those runs are not directly comparable to Anthropic's own 69.2 percent figure for Opus 4.8.
- Claude Opus 4.8 wins for: price — $5 input and $25 output per million tokens, exactly half of Fable 5 — plus thinking flexibility, a 2.5x Fast Mode, zero-data-retention compatibility, and no always-on frontier safety classifiers. It is also, literally, the recommended fallback when Fable 5 refuses a request.
- Same on both: 1M-token context window, 128K max output, the same Opus 4.7-generation tokenizer, and a 90 percent prompt-caching discount on cache reads.
- Honest caveat: Fable 5's headline benchmark numbers are early, third-party, and not independently reproduced. The capability gap is real in our hands-on use, but its exact size is not yet a settled fact.
A note on the numbers: the two models' benchmark figures in this comparison do not come from the same evaluation run. Opus 4.8's 69.2 percent SWE-bench Pro score comes from Anthropic's own launch comparison table, which we treated as our reference figure in our Opus 4.8 vs Opus 4.7 comparison. Fable 5's roughly 80.3 percent comes from early third-party launch-week runs under their own harnesses. Different sources, different harnesses — we present them side by side because they are the best available figures, but we will not pretend an 11-point delta measured across two different methodologies is a precise number. Pricing, context, retention, and thinking behavior, by contrast, are verified directly against Anthropic's platform documentation.
What each model is
Claude Fable 5
Claude Fable 5 went generally available on June 9, 2026 across the Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry. Anthropic describes it as its "most capable widely released model, for the most demanding reasoning and long-horizon agentic work" — wording that quietly creates a tier above Opus rather than replacing it. Three things define it operationally. First, the price: $10 per million input tokens and $50 per million output tokens, double Opus 4.8 on both sides, softened in practice by a 90 percent discount on prompt-cache reads. Second, adaptive thinking is always on — there is no way to disable it, and an API request that explicitly tries returns a 400 error. Third, it ships with always-active safety classifiers covering cyberoffense, biology, and chemistry risk: a request that trips them comes back as a clean HTTP 200 with a refusal stop reason rather than an answer. The "widely released" qualifier matters too — Claude Mythos 5, the same family without those classifiers, exists but is invitation-only through Anthropic's Project Glasswing program for approved defensive-security customers.
Claude Opus 4.8
Claude Opus 4.8 launched May 28, 2026 and was Anthropic's most capable model for all of twelve days. It remains the flagship of the Opus tier: $5 per million input tokens and $25 per million output tokens, a 1M-token context window, 128K max output, a reliable knowledge cutoff of January 2026, and the strongest published coding scores Anthropic had ever shipped — 88.6 percent on SWE-bench Verified and 69.2 percent on SWE-bench Pro on its own launch table. It offers what Fable 5 does not: flexibility. Thinking is adaptive but optional, so latency-sensitive routes can run without it. A Fast Mode runs at roughly 2.5x standard speed for $10 input and $50 output per million tokens. And it operates under Anthropic's standard data controls rather than Fable 5's stricter Covered Model regime. Nothing about Fable 5's launch makes Opus 4.8 worse — it is the same model we called the better-than-free upgrade two weeks ago, now recast as the value option.
Claude Fable 5 vs Claude Opus 4.8: head-to-head
Pricing, context, output, thinking, retention, and availability below are verified against Anthropic's platform documentation. Benchmark rows carry their source inline, because the two models' figures do not share a harness.
| Feature | Claude Fable 5 | Claude Opus 4.8 | Winner |
|---|---|---|---|
| Positioning | New tier above Opus — most capable widely released | Opus-tier flagship | Fable 5 |
| Input price (per 1M tokens) | $10.00 | $5.00 | Opus 4.8 |
| Output price (per 1M tokens) | $50.00 | $25.00 | Opus 4.8 |
| Context window | 1M tokens | 1M tokens | Tie |
| Max output | 128K tokens | 128K tokens | Tie |
| Prompt caching | 90% discount on cache reads | 90% discount on cache reads | Tie |
| SWE-bench Pro | ~80.3% (early third-party runs) | 69.2% (Anthropic's launch table) | Fable 5 (different harnesses) |
| Adaptive thinking | Always on — cannot be disabled | Optional — can run without thinking | Opus 4.8 (flexibility) |
| Fast Mode (~2.5x speed) | Not offered | Yes — $10 input, $50 output per 1M tokens | Opus 4.8 |
| Frontier safety classifiers | Always active — cyber, bio, chemistry refusals | Standard safety stack | Opus 4.8 (fewer refusal surfaces) |
| Data retention | 30-day minimum, Covered Model — no zero data retention | Standard controls, compatible with zero-data-retention agreements | Opus 4.8 |
| General availability | June 9, 2026 | May 28, 2026 | Tie |
Count the rows and Opus 4.8 wins more of them — price twice, flexibility, speed options, refusals, retention. That is exactly why this comparison is interesting: Fable 5 wins the one row that a top-tier buyer actually shops on, raw capability, and concedes nearly everything else. If the spec sheet were the whole story, nobody would pay double. The spec sheet is not the whole story.
What the benchmark numbers do and do not tell you
Three early signals define Fable 5's launch-week story, and all three need the same disclaimer: they are third-party, they are early, and none of them has been independently reproduced under a controlled, matched harness.
SWE-bench Pro, roughly 80.3 percent. This is the headline. SWE-bench Pro is the hard variant — longer, messier, multi-file engineering tasks that resist memorization — and it is far from saturated. Anthropic's own launch table put Opus 4.8 at 69.2 percent, which was itself a 4.9-point jump over Opus 4.7 just two weeks earlier. If the early Fable 5 runs hold up, an 11-point gap on the one coding benchmark with real headroom would be the largest single-generation jump on this scale we have tracked. The caveat cuts both ways, though: the 80.3 figure comes from third-party launch-week harnesses, not from the same evaluation run that produced Opus 4.8's 69.2, so the true delta could be meaningfully smaller — or larger. Treat the direction as solid and the magnitude as provisional.
GDPval-AA, roughly 1932. GDPval-AA is an Elo-style rating across economically valuable knowledge-work tasks — closer to "can this model do a day of real white-collar work" than to a coding puzzle. Early third-party scoring put Fable 5 around 1932, reported as the top of the table at launch. We give this one less weight than SWE-bench Pro: it is newer, methodologically less settled, and Elo-style numbers shift as more models get scored. It points the same direction as everything else, which is the main thing it is good for.
Hex's analytics benchmark, roughly 90 percent. Hex, the analytics platform, runs its own evaluation of models on real data-analysis workflows — SQL, notebooks, charts, interpretation. Early reporting put Fable 5 at roughly 90 percent, the strongest result Hex had published. This one matters because it is a third-party harness with no incentive to flatter Anthropic, and because analytics agents are exactly the kind of long-horizon, tool-heavy work Fable 5 is positioned for.
What we can verify ourselves is more modest and more boring: in our own pipelines, Fable 5 completed two long agentic refactors that Opus 4.8 had needed a retry on, and its intermediate reasoning on a gnarly multi-service debugging task was visibly more organized. That is one day of side-by-side use, not a benchmark. We flag it as exactly that.
Pricing: double, with one fascinating wrinkle
The list prices are clean: Fable 5 costs exactly twice Opus 4.8 on both sides of the meter.
| Tier | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|
| Standard input (per 1M tokens) | $10.00 | $5.00 |
| Standard output (per 1M tokens) | $50.00 | $25.00 |
| Prompt-cache reads | 90% discount | 90% discount |
| Fast Mode input (per 1M tokens) | Not offered | $10.00 |
| Fast Mode output (per 1M tokens) | Not offered | $50.00 |
Here is the wrinkle worth staring at: Fable 5's standard price is exactly Opus 4.8's Fast Mode price. Ten dollars input, fifty dollars output per million tokens buys you either Anthropic's most capable model at standard speed, or its value flagship at roughly 2.5x speed. That is a genuine fork in the road, not a footnote. If your bottleneck is intelligence — agent runs that fail, reasoning that falls short — the money goes to Fable 5. If your bottleneck is latency — humans waiting on an interactive agent — the same money buys more useful work from Opus 4.8 Fast Mode. Same line on the invoice, opposite philosophies.
Two more cost notes that change the real-world math. First, both models use the tokenizer Anthropic introduced with Opus 4.7, which produces roughly 30 percent more tokens than pre-4.7 models for the same text — so the Fable-to-Opus comparison is apples to apples, even if comparisons to older models are not. Second, the 90 percent prompt-caching discount applies to both, and it compounds differently at scale: a long-running agent with a large stable system prompt pays Fable 5's premium mostly on output tokens, which narrows the effective gap for cache-heavy workloads. A chatty, cache-cold workload pays the full double. Know which one you are. All prices are verified directly against Anthropic's platform documentation.
The refusal layer: when Fable 5 says no
This is the section that does not exist in most Fable 5 coverage, and it is the most operationally important difference between these two models. Fable 5 ships with always-active frontier safety classifiers covering cyberoffense, biological, and chemical risk. When a request trips them, the API does not return an error — it returns a normal HTTP 200 response with a refusal stop reason and a structured category telling you which classifier fired. Your code keeps running; your answer just is not there.
That design has a direct architectural consequence: every serious Fable 5 integration needs a fallback path, and the natural fallback is Claude Opus 4.8. The pattern is simple — detect the refusal stop reason, re-route the request to Opus 4.8, which runs Anthropic's standard safety stack without the frontier classifiers, and serve that answer instead. We built exactly this into our own pipeline on day one, after a security-adjacent code-review prompt — analyzing a dependency for vulnerability patterns, the defensive kind of work — came back refused on Fable 5 and answered cleanly on Opus 4.8. The classifiers are tuned for the frontier-risk edge, and like all classifiers they have false positives. If your work touches security research, infrastructure hardening, or biotech-adjacent topics even defensively, budget for a nonzero refusal rate on Fable 5.
This is also where Claude Mythos 5 fits into the picture. Mythos 5 is the same model family released without those classifiers — and it is not on the price list. It is invitation-only through Project Glasswing, Anthropic's program for approved customers doing defensive cybersecurity work, with no self-serve sign-up. For everyone else, the practical takeaway is blunt: Fable 5 and Opus 4.8 are not really an either-or. The premium model needs the value model standing behind it. Opus 4.8 is, quite literally, Fable 5's safety net.
Data retention: the compliance gap nobody puts in the headline
Fable 5 is designated a Covered Model under Anthropic's usage policies, and that brings a hard constraint: a mandatory 30-day minimum data-retention window, with no zero-data-retention option. If your organization has a zero-data-retention agreement with Anthropic — common in healthcare, legal, finance, and anything GDPR-sensitive with strict data-residency posture — Fable 5 does not currently fit inside it. Opus 4.8 operates under Anthropic's standard data controls and remains compatible with those arrangements.
For most startups and internal tooling this is a non-issue. For a regulated enterprise it can be fully disqualifying, regardless of how good the model is — which is why we list it as a category win for Opus 4.8 rather than a footnote. If your compliance team has ever said the words "retention exception," have that conversation before you route production traffic to Fable 5, not after.
How we tested, and what we did not test
We run Claude models in production daily — long agentic coding runs, content pipelines, research agents, and the multi-step tool-use workflows this site is built on. Opus 4.8 has been our default since its May 28 launch, and we documented that experience in our Opus 4.8 vs Opus 4.7 comparison. When Fable 5 went GA on June 9, we pointed the same pipelines at it: same prompts, same tools, same tasks, with the model identifier swapped and a refusal fallback added.
Here is the honest scope. At the time of writing we have one full day of side-by-side production use, not weeks, and we have not run a controlled, matched benchmark harness across both models ourselves. Our hands-on observations — Fable 5 completing runs Opus 4.8 retried, cleaner intermediate reasoning, one false-positive refusal on defensive security work — are real but anecdotal, and we label them as such. The hard numbers in this article are attributed where they came from: pricing, context, thinking behavior, retention, and availability are verified against Anthropic's platform documentation; Opus 4.8's benchmark scores come from Anthropic's own launch table; Fable 5's benchmark figures are early third-party launch-week results that have not been independently reproduced. Where our experience and the public numbers point the same way, we say so. Where we only have someone's claim, we name whose.
Winner by category
Best raw capability — Claude Fable 5
This is not close, and it is not supposed to be. Anthropic positions Fable 5 above its own flagship, early third-party benchmarks point the same direction, and our first day of production use agrees. If the question is "what is the most capable model I can buy from Anthropic today," the answer is Fable 5.
Best for long-horizon agentic work — Claude Fable 5
The hardest agent workloads — multi-hour runs, deep multi-file refactors, agent-coordinating-agents architectures — are exactly what "the most demanding reasoning and long-horizon agentic work" positioning is for. Always-on adaptive thinking costs you the option to skip reasoning, but on this class of task you were never going to skip it anyway.
Best value for production coding — Claude Opus 4.8
At 69.2 percent on SWE-bench Pro from Anthropic's own table, Opus 4.8 was the strongest published coding model in the world two weeks ago. It did not get worse. For the bulk of real engineering work, it remains the rational default at half the price.
Best for latency-sensitive workloads — Claude Opus 4.8
Fable 5 has no Fast Mode, and its always-on thinking adds latency by design. Opus 4.8 Fast Mode runs at roughly 2.5x standard speed — at exactly the dollars-per-token you would otherwise spend on Fable 5. If a human is waiting on the response, this category is not a contest.
Best for regulated and security-research workloads — Claude Opus 4.8
Zero-data-retention compatibility and no always-on frontier classifiers make Opus 4.8 the only one of the two that fits strict compliance regimes and false-positive-sensitive defensive security work. Mythos 5 exists for the latter, but unless Anthropic has invited you into Project Glasswing, it may as well not.
Best overall — Claude Fable 5, with a real caveat
The most capable widely released model wins the comparison; that is what the crown means. The caveat is that "best overall" and "best default" are different titles — and the default for most teams, most workloads, and most budgets is still Opus 4.8, with Fable 5 reserved for the work that earns its premium.
Pros and cons of each model
Claude Fable 5
Pros
- Anthropic's most capable widely released model — a tier above Opus, not an Opus refresh.
- Early third-party SWE-bench Pro runs around 80.3 percent, well clear of any published Opus 4.8 figure.
- Built for long-horizon agentic work and multi-agent coordination.
- Same 1M context, 128K output, and 90 percent cache-read discount as Opus 4.8 — the premium buys capability, not specs.
- Strong early third-party signals beyond coding: roughly 1932 on GDPval-AA and roughly 90 percent on Hex's analytics benchmark.
Cons
- Double the price: $10 input and $50 output per million tokens.
- Always-active safety classifiers can refuse cyber, bio, and chemistry requests — including defensive false positives — so it needs a fallback model.
- Covered Model status: mandatory 30-day retention, no zero-data-retention option.
- Adaptive thinking cannot be disabled, which adds cost and latency on simple tasks.
- Headline benchmarks are early, third-party, and not independently reproduced.
Claude Opus 4.8
Pros
- Half the price of Fable 5 — $5 input and $25 output per million tokens — for a model that led the world on published coding benchmarks two weeks ago.
- Fast Mode at roughly 2.5x speed for Fable 5's standard price — the better buy when latency is the bottleneck.
- Thinking is optional, so simple and latency-sensitive routes can skip it.
- Standard data controls, compatible with zero-data-retention agreements.
- No always-on frontier classifiers — and it is the natural fallback when Fable 5 refuses.
Cons
- No longer the capability ceiling — Fable 5 sits above it on every early signal.
- For the hardest agentic runs, may need retries where Fable 5 completes in one pass.
- 69.2 percent SWE-bench Pro is vendor-reported from Anthropic's launch table, not independently reproduced.
- No path to the frontier-classifier-free Mythos 5 tier — that program sits above the Fable line.
When to pick Fable 5 vs Opus 4.8
Pick Claude Fable 5 when the task is the bottleneck: agentic runs that fail or need retries on Opus 4.8, multi-hour autonomous coding sessions, agent-coordination architectures, frontier-difficulty reasoning, or any workload where one failed run costs more than the token premium. At a 90 percent cache-read discount, cache-heavy agent loops blunt much of the price gap — the hardest 10 percent of your work is usually also the most cacheable.
Pick Claude Opus 4.8 when price-performance is the bottleneck: the bulk of production coding, interactive and latency-sensitive agents (especially on Fast Mode), high-volume pipelines where doubling token cost doubles your bill, anything under a zero-data-retention agreement, and security-research or biotech-adjacent work where classifier false positives would hurt. And keep it wired in even if you go Fable-first — it is the fallback model by design.
How to upgrade — and why this one is not a one-line swap
When we covered the Opus 4.7 to 4.8 upgrade, the migration advice fit in a sentence: swap the model identifier, run your evals, done. Moving from Opus 4.8 to Fable 5 is genuinely different, and pretending otherwise is how teams get surprised in production. Three things change beyond the name string.
First, the bill doubles, so route selectively instead of globally. The pattern that works is a tiered router: Fable 5 for the task classes you have evidence it wins — your hardest agent runs, your longest-horizon work — and Opus 4.8 for everything else. Flipping a global default to Fable 5 doubles your spend on the 90 percent of traffic that did not need it.
Second, handle refusals before you see one. A Fable 5 refusal arrives as a successful response with a refusal stop reason, not an exception — code that only checks for errors will treat it as a normal answer with empty content. Detect the stop reason, log the category, and re-route to Opus 4.8. This is not optional hardening; it is part of the integration.
Third, clear the operational gates: thinking is always on, so latency-sensitive routes that ran Opus 4.8 thinking-free will get slower and costlier — keep those on Opus 4.8. And if your organization runs under a zero-data-retention agreement, stop here — Fable 5's 30-day Covered Model retention is currently incompatible, and that is a compliance conversation, not an engineering one. Run your eval suite on both models before moving traffic, exactly as you would for any version bump — except this time the eval is also measuring whether each task class earns the premium.
Frequently Asked Questions
Is Claude Fable 5 better than Claude Opus 4.8?
Yes, on capability — Anthropic explicitly positions Fable 5 as its most capable widely released model, a tier above Opus 4.8. Early third-party runs put Fable 5 around 80.3 percent on SWE-bench Pro versus the 69.2 percent Anthropic published for Opus 4.8, though those figures come from different harnesses and are not directly comparable. The trade-off is that Fable 5 costs exactly double — $10 per million input tokens and $50 per million output tokens versus $5 and $25 — runs always-on thinking, ships with frontier safety classifiers, and requires 30-day data retention. Better model, heavier terms.
How much more expensive is Claude Fable 5 than Opus 4.8?
Exactly twice the list price on both sides of the meter: Fable 5 costs $10 per million input tokens and $50 per million output tokens, while Opus 4.8 costs $5 and $25. Both models get a 90 percent discount on prompt-cache reads, so cache-heavy agent workloads with large stable system prompts feel a smaller effective gap than the headline doubling suggests. Cache-cold, high-volume workloads pay the full double.
What is Claude Fable 5's SWE-bench Pro score?
Early third-party launch-week runs put Claude Fable 5 at roughly 80.3 percent on SWE-bench Pro. That figure is not Anthropic-official and has not been independently reproduced, and it was not measured on the same harness as Opus 4.8's 69.2 percent, which comes from Anthropic's own launch comparison table. The direction — Fable 5 well ahead on the hardest coding benchmark — is consistent across every early signal, but treat the exact 11-point gap as provisional until matched-harness results exist.
Why does Claude Fable 5 refuse some requests that Opus 4.8 answers?
Fable 5 ships with always-active frontier safety classifiers covering cyberoffense, biological, and chemical risk, which Opus 4.8 does not run. When a request trips them, Fable 5 returns a refusal instead of an answer — and like all classifiers, they produce false positives, including on defensive work like vulnerability analysis or security code review. Opus 4.8 runs Anthropic's standard safety stack without that extra layer, which is why the same prompt can be refused by Fable 5 and answered cleanly by Opus 4.8.
What happens when Claude Fable 5 returns a refusal?
The API returns a normal HTTP 200 response with a refusal stop reason and a structured category indicating which classifier fired — it is not an error code, so code that only catches exceptions will miss it. The recommended integration pattern is to detect the refusal stop reason and re-route the request to Claude Opus 4.8, which handles the same prompt under Anthropic's standard safety stack. In practice, every production Fable 5 deployment should ship with an Opus 4.8 fallback path from day one.
Does Claude Fable 5 support zero data retention?
No. Fable 5 is designated a Covered Model, which carries a mandatory 30-day minimum data-retention window with no zero-data-retention option. Organizations with zero-data-retention agreements — common in healthcare, legal, finance, and strict GDPR postures — cannot currently fit Fable 5 inside them. Claude Opus 4.8 operates under Anthropic's standard data controls and remains compatible with those agreements, which makes it the only option of the two for strict compliance regimes.
Can I turn off thinking on Claude Fable 5?
No. Adaptive thinking is always on for Fable 5 — the model decides how much to think per request, and there is no off switch. An API request that explicitly tries to disable thinking returns a 400 error. Claude Opus 4.8 is more flexible: thinking is adaptive when enabled but can be omitted entirely, which keeps simple, latency-sensitive routes faster and cheaper. If you need a no-thinking mode, that route belongs on Opus 4.8.
What is Claude Mythos 5 and how is it different from Fable 5?
Claude Mythos 5 is the same model family as Fable 5 released without the frontier safety classifiers, offered at the same $10 and $50 per million token pricing — but it is not generally available. Access is invitation-only through Project Glasswing, Anthropic's program for approved customers doing defensive cybersecurity work, with no self-serve sign-up. For everyone outside that program, Fable 5 is the top of the accessible range, and Opus 4.8 is the fallback when its classifiers refuse.
Is Claude Fable 5 worth it for Claude Code?
For the hardest sessions, yes. Fable 5 is built for exactly the long-horizon agentic coding that Claude Code exercises — multi-hour autonomous runs, deep refactors, many chained tool calls — and that is where our own side-by-side use showed it completing runs Opus 4.8 needed retries on. For everyday Claude Code work, Opus 4.8 at half the price remains excellent, and its Fast Mode is the better pick when you are iterating interactively and waiting on responses. A sensible setup uses Opus 4.8 as the daily driver and reaches for Fable 5 on the sessions that keep failing.
Should I use Opus 4.8 Fast Mode or Fable 5 at the same price?
They cost the same — $10 per million input tokens and $50 per million output tokens — so the choice is purely about your bottleneck. If intelligence is the constraint (agent runs failing, reasoning falling short, hard multi-step tasks), spend the money on Fable 5's capability at standard speed. If latency is the constraint (interactive agents, live coding assistance, humans waiting), spend it on Opus 4.8 Fast Mode at roughly 2.5x speed. Same invoice line, opposite philosophies — and the fact that this fork exists at all is the most interesting pricing detail of the Fable 5 launch.
When did Claude Fable 5 launch?
Claude Fable 5 went generally available on June 9, 2026, across the Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry. That is twelve days after Claude Opus 4.8's May 28, 2026 launch — and unlike that release, which replaced Opus 4.7 at the same price, Fable 5 launched as a new premium tier above the Opus line at double the price, alongside the invitation-only Claude Mythos 5.
Who should stay on Claude Opus 4.8?
Most teams, for most work. Stay on Opus 4.8 if your budget is volume-sensitive, your workloads are interactive and latency-bound (Fast Mode is the strongest argument here), your organization requires zero data retention, or your work touches security research where classifier false positives would disrupt you. Opus 4.8 was the strongest published coding model in the world until June 9 and lost none of that capability — it just gained a bigger sibling. Reach for Fable 5 selectively, for the task classes where you can show it earns double.
Related comparisons
- Claude Opus 4.8 vs Claude Opus 4.7 — the same-price upgrade question, two weeks before Fable 5 changed the ceiling.
- Claude Opus 4.8 vs GPT-5.5 — how Anthropic's value flagship stacks up against OpenAI.
- Claude Opus 4.8 vs Gemini 3.1 Pro — coding crown versus Google's best value.
- Need a faster, cheaper tier than either? See Claude Sonnet 4.6 for everyday work, or Claude Opus 4.7 if you are pinned to the previous flagship.

Final verdict
Claude Fable 5 wins this comparison on the measure that defines a flagship matchup: it is the most capable widely released model Anthropic has ever shipped, a deliberate tier above Opus 4.8, and every early signal — third-party SWE-bench Pro runs around 80.3 percent, roughly 1932 on GDPval-AA, roughly 90 percent on Hex's analytics benchmark, and our own first day of side-by-side production use — points the same direction. But the verdict only makes sense as a split. Opus 4.8, at exactly half the price, wins value, latency (its Fast Mode costs precisely what Fable 5 standard costs), thinking flexibility, zero-data-retention compatibility, and freedom from frontier classifier refusals. The honest recommendation is not either-or: run Opus 4.8 as your default, route your hardest agentic work to Fable 5 where the premium provably pays for itself, and keep Opus 4.8 wired in as the fallback for Fable 5's refusals — because Anthropic's own integration pattern assumes you will. Pay double for the ceiling where you need the ceiling. Everywhere else, the value flagship is still a flagship.
Disclosure: ThePlanetTools.ai has no affiliate relationship with Anthropic, and we earn nothing from your choice between these two models. We use Claude models in our own production workflows daily — including both models compared here — and this comparison is written to be neutral: Fable 5's capability win and Opus 4.8's value, compliance, and refusal-fallback wins are stated with equal weight. Pricing, context, retention, and thinking behavior are verified against Anthropic's platform documentation; Opus 4.8 benchmark figures are Anthropic's own vendor-reported launch numbers; Fable 5 benchmark figures are early third-party launch-week results that have not been independently reproduced, and are labeled as such throughout. Last compared: June 2026.
Our Verdict
Claude Fable 5 wins on raw capability: it is Anthropic's most capable widely released model, a deliberate tier above Opus, and every early signal — including third-party SWE-bench Pro runs around 80.3 percent versus the 69.2 percent Anthropic published for Opus 4.8 — points the same way. Claude Opus 4.8 wins on value at exactly half the price ($5 input and $25 output per million tokens versus $10 and $50), keeps thinking optional, offers a 2.5x Fast Mode at Fable 5's standard price, remains compatible with zero-data-retention agreements, and is the recommended fallback when Fable 5's safety classifiers refuse a request. Run Opus 4.8 as the default, route the hardest agentic work to Fable 5 where the premium provably pays for itself, and keep Opus 4.8 wired in as Fable 5's safety net.
Choose Claude Fable 5
Anthropic's most capable widely released model — the public, safety-classified Mythos-class frontier tier.
Try Claude Fable 5 →Choose Claude Opus 4.8
Anthropic's flagship model for agentic coding, computer use, and multi-agent orchestration.
Try Claude Opus 4.8 →Frequently Asked Questions
Is Claude Fable 5 better than Claude Opus 4.8?
Claude Fable 5 wins on raw capability: it is Anthropic's most capable widely released model, a deliberate tier above Opus, and every early signal — including third-party SWE-bench Pro runs around 80.3 percent versus the 69.2 percent Anthropic published for Opus 4.8 — points the same way. Claude Opus 4.8 wins on value at exactly half the price ($5 input and $25 output per million tokens versus $10 and $50), keeps thinking optional, offers a 2.5x Fast Mode at Fable 5's standard price, remains compatible with zero-data-retention agreements, and is the recommended fallback when Fable 5's safety classifiers refuse a request. Run Opus 4.8 as the default, route the hardest agentic work to Fable 5 where the premium provably pays for itself, and keep Opus 4.8 wired in as Fable 5's safety net.
Which is cheaper, Claude Fable 5 or Claude Opus 4.8?
Claude Fable 5 is priced at $10 in / $50 out per M tokens. Claude Opus 4.8 is priced at $5 in / $25 out per M tokens. Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Fable 5 and Claude Opus 4.8?
The key differences span across 12 features we compared. For Positioning, Claude Fable 5 offers New tier above Opus — most capable widely released while Claude Opus 4.8 offers Opus-tier flagship. For Input price (per 1M tokens), Claude Fable 5 offers $10.00 while Claude Opus 4.8 offers $5.00. For Output price (per 1M tokens), Claude Fable 5 offers $50.00 while Claude Opus 4.8 offers $25.00. See the full feature comparison table above for all details.