On April 23, 2026, Anthropic published an official postmortem admitting that three distinct production bugs — not one — degraded Claude Code quality between March 4 and April 20, 2026. Bug 1: the default reasoning effort was flipped from HIGH to MEDIUM on March 4 and rolled back on April 7 (34 days of dumber defaults). Bug 2: a caching feature shipped March 26 was supposed to clear "older thinking" after sessions idle for more than 1 hour — instead it ran every turn, causing Claude to become "forgetful and repetitive" until the fix on April 10. Bug 3: a system-prompt verbosity instruction added on April 16 cut coding-eval performance by 3% on both Opus 4.6 and 4.7 before being rolled back on April 20. The fix shipped as Claude Code v2.1.116. Anthropic reset usage limits for all Plus, Pro, Business, and Enterprise subscribers the same day. We ran Claude Code daily through this entire window — 14 months, Max x20, three production projects — and we felt every one of these bugs. This is our breakdown of the postmortem, what the fix means for the trust reset, and whether Anthropic's three new quality-control promises are enough.
The postmortem Anthropic finally published
On April 23, 2026, Anthropic's engineering team published a post titled "An update on recent Claude Code quality reports" at anthropic.com/engineering/april-23-postmortem. It opens with a line that, eleven days earlier, nobody at Anthropic was willing to say publicly: "We investigated reports of Claude Code quality degradation over the past several weeks, and we found three distinct production changes that contributed to the regression. All three have been rolled back." That single sentence closed a chapter the AI developer community had been arguing about since the first week of March.
We covered the original story on April 13 in our breakdown of the 73% thinking-length drop across 6,852 sessions. At the time, Anthropic's only on-record acknowledgement was a Boris Cherny thread framing the change as a deliberate "reasoning effort lowered to medium" policy decision. The community split down the middle. Was it a silent nerf for compute savings (as competitors accused)? Was it a UX optimization that backfired (as Cherny implied)? Was it just a bug nobody had found yet?
The April 23 postmortem resolves the question. It was not a policy. It was not a cost-cutting move. It was three separate engineering mistakes, each one small in isolation, each one with its own ship date and rollback date, none of which were caught by Anthropic's internal QA before customers noticed. The paper trail reads like a cautionary tale about how a frontier AI product can ship three independent regressions in 50 days and not notice.
Anthropic's own words, from the postmortem: "We want to be transparent about what went wrong and what we're changing to prevent this in the future. We also recognize that our customers lost productivity and, in some cases, billable hours during this period. As a gesture of good faith, we are resetting usage limits for all Plus, Pro, Business, and Enterprise subscribers effective today."
That last sentence is the concession. It is also the receipts. Usage limits reset on paid plans is not a standard customer-service gesture at Anthropic — it is the first time they have done it for a quality regression. The move puts a number on the apology: every paid subscriber got back their consumed monthly quota as of April 23, 2026, without needing to file a ticket.
Bug 1: the reasoning effort default flip (March 4 to April 7)
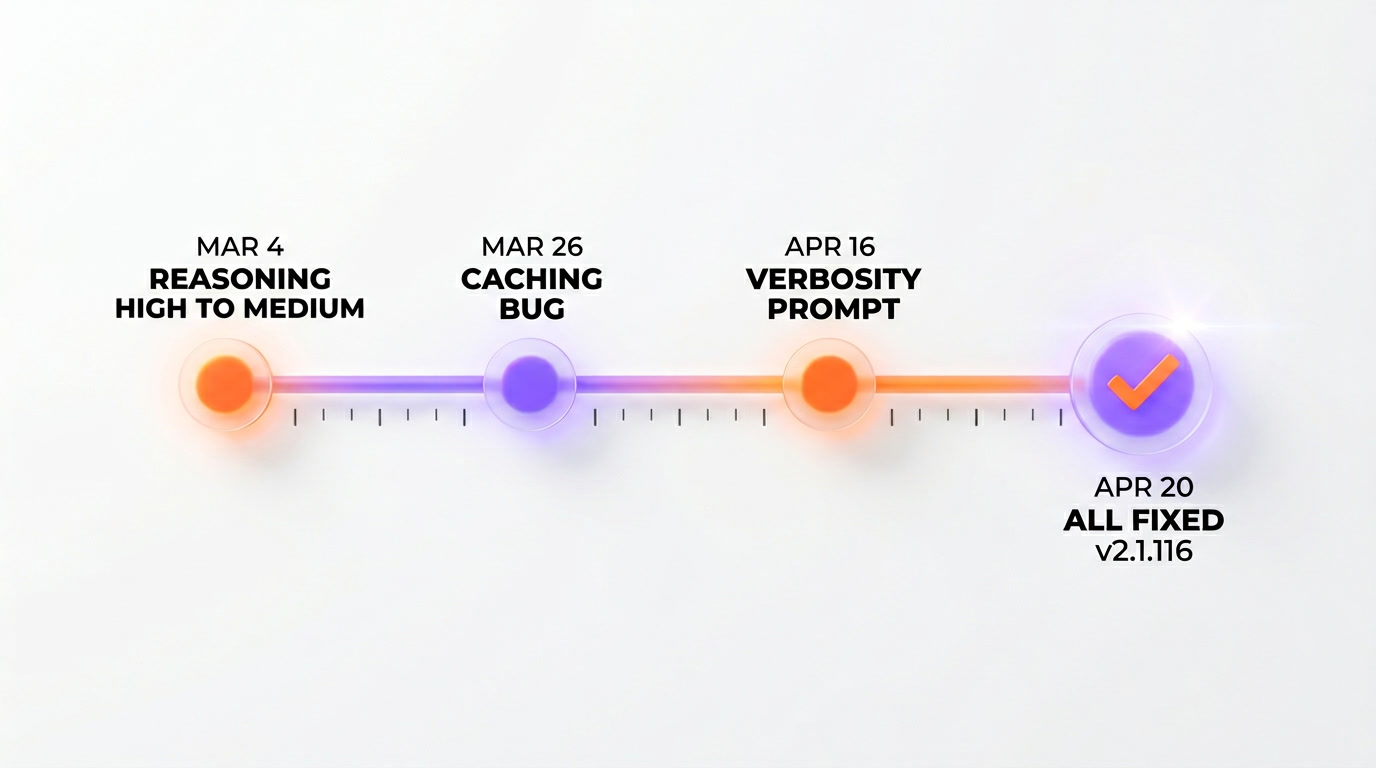
The first bug is the one Cherny half-acknowledged on April 13, but the postmortem fills in the details he did not share at the time. On March 4, 2026, Anthropic shipped a change to Claude Code's default reasoning effort: from HIGH to MEDIUM. The stated goal in the postmortem is "reduce latency for the median workload." The hypothesis, per Anthropic's internal benchmarks, was that MEDIUM effort produced acceptable quality on the majority of coding tasks while cutting median response time by a meaningful margin.
The hypothesis was wrong. User feedback piled up within the first week. Complex tasks that worked at HIGH started silently failing at MEDIUM. The plan-before-code behavior that made Claude Code feel "senior" got replaced by a first-attempt-and-ship pattern that felt "junior." On April 7, 2026 — 34 days after the original change — Anthropic rolled the default back to HIGH. The postmortem frames the rollback as "in response to user feedback that users prefer higher intelligence over lower latency," which is corporate-speak for "we underestimated how much our power users valued the old default."
The 34 days of MEDIUM-default behavior is what the viral Scortier study captured: median thinking length dropping from 2,200 characters in January to 600 in March. That data was real, and now we know exactly why. It was not a mystery. It was this bug.
What the postmortem does not say: why the internal benchmark did not catch the regression. Anthropic runs coding-eval suites on every model change. The fact that MEDIUM-effort shipped to production suggests either the benchmarks did not cover the task categories where the regression was most severe (agentic multi-step coding, refactoring, large-codebase navigation) or the benchmark results were dismissed as acceptable trade-offs for the latency gain. Either way, it is a process failure, and it is exactly the kind of failure the three new quality controls Anthropic promised (more on that below) are designed to prevent.
Bug 2: the caching bug that made Claude "forgetful and repetitive" (March 26 to April 10)
This is the bug that explained the weirdest symptom users kept reporting. From late March onward, a subset of Claude Code users started complaining that their agent sessions had become "forgetful" — Claude would ask for information it had already been given, repeat itself across turns, and forget context from earlier in the session. The complaints were anecdotal, they came in a trickle, and they did not match the reasoning-effort pattern (which made Claude less thorough, not more amnesiac). Something else was going on.
The postmortem identifies it. On March 26, 2026, Anthropic shipped a caching feature designed to clear "older thinking" from the session context after the user had been idle for more than 1 hour. The purpose was to reduce latency on long-idle-then-resumed sessions by freeing up context that was probably stale anyway. It was a legitimate optimization. It was also written with a bug.
Instead of running when the session had been idle for more than 1 hour, the feature ran on every turn. Every time the user sent a message, Claude would clear the "older thinking" from the session — which, in practice, meant clearing the running reasoning scratchpad that Claude uses to maintain coherence across multi-turn conversations. The symptom from the user side was exactly what got reported: forgetful and repetitive behavior.
The bug was live from March 26 to April 10 — 15 days. The postmortem does not say how the bug was caught, but the pattern suggests it was found by an internal engineer reproducing user complaints, not by automated monitoring. The fix shipped April 10. Users who had sessions during this 15-day window lost some portion of their conversational coherence, and there is no retroactive fix for the outputs generated during the bug window — they are what they are.
Our own experience maps to this exactly. We have a slack channel where our team pastes "WTF Claude" moments. We have three screenshots from the last week of March and the first week of April of Claude Code asking us to re-paste a file it had just read. At the time we chalked it up to normal LLM forgetfulness. It was not. It was this bug.
Bug 3: the verbosity instruction that killed 3% of coding quality (April 16 to April 20)
The third bug is the smallest in scope and the most embarrassing in shape. On April 16, 2026, Anthropic added a single instruction to Claude Code's system prompt aimed at reducing response verbosity. The goal was to make Claude's outputs shorter and more focused. The change shipped, the response lengths dropped, and the coding-eval benchmarks showed a 3% regression on both Opus 4.6 and Opus 4.7.
Three percent sounds small. In practice, on a large enough benchmark, it is the difference between "clearly excellent" and "noticeably inconsistent." It is also the kind of regression that tells you something went deeply wrong with the intervention — a verbosity instruction should not move a coding benchmark by 3%. The fact that it did means the instruction was interacting with the model in a way the Anthropic team did not expect.
The postmortem is unusually frank about this one: "The instruction, combined with other recent prompt changes, materially reduced the model's ability to produce high-quality code on tasks in our coding-eval suite. We rolled it back on April 20." Four days live. One patch. It is the shortest-lived of the three bugs, but it is also the one that most clearly shows the problem with Anthropic's previous process — a one-line system-prompt change was allowed to ship to production without being run through the full coding-eval suite first.
What makes this bug significant beyond its short lifespan is what it says about prompt changes in general. Anthropic is telling us, on the record, that a one-liner in the system prompt can drop measurable coding performance by 3% on their flagship model. That has implications for every enterprise relying on consistent Claude behavior: the system prompt is a surface area Anthropic can and does edit, and small edits there can have non-trivial effects on output quality. This is not a bug that is fully "fixed" by rolling back one instruction — it is a class of risk that Anthropic will have to manage indefinitely.
Our experience: 14 months, Max x20, we felt every one of these

We have been running Claude Code daily since February 2025. The plan is Max x20. The projects are ThePlanetTools.ai (content platform, Next.js 16, Supabase), ThePlanetTools.ai (internal CMS, 247 API routes, Turbopack), and a third private client codebase. That is 14 months of daily use, three production environments, and a Slack channel full of timestamped gripes.
Here is what we noticed in real time, now mapped to the three bugs Anthropic confirmed:
- Early March 2026 — "Claude got lazier." This is Bug 1 (reasoning effort). We noticed Claude stopped writing planning documents before complex refactors. Our first instinct was to blame ourselves — "our prompts got worse" — before we realized the input prompts were identical. The feeling lasted from March 4 through April 7, and it lifted the moment Anthropic rolled the default back to HIGH. We did not know at the time that a rollback had shipped. We just felt the quality return.
- Late March to early April 2026 — "Claude keeps forgetting." This is Bug 2 (caching). We have three Slack screenshots from March 27 to April 8 of Claude Code asking to re-read a file it had already read within the same session. At the time we thought it was a stack-overflow in the context window, or our own fault for not scoping the session tightly. It was none of those things. It was the idle-clear feature running every turn.
- Mid-to-late April 2026 — "Claude's answers feel truncated." This is Bug 3 (verbosity instruction). The symptom was subtle — answers were technically correct but skipped the "here's why I'm doing this" explanations Claude used to volunteer. For four days, Claude Code felt like it had stopped teaching and started just executing. Then, on April 20, it felt like it exhaled and started talking again.
None of these were existential bugs. None of them made Claude unusable. What they did, collectively, was erode the specific texture of senior-engineer reasoning that made Claude Code stand out against GPT, Gemini, and Cursor in the first place. When that texture thinned, the product felt cheaper. When it came back, it felt premium again. That is the emotional register of the scandal — not "Claude broke," but "Claude stopped being the model I paid for."
For the full before-and-after benchmark (50 tasks, plan-before-code behavior, retry rates, tool-call depth), see our original degradation breakdown. The numbers in that piece are what the three bugs look like from a user's seat. The postmortem is what they look like from inside the room where they shipped.
The compensation: what "usage limits reset" actually means

The usage-limits reset is the most concrete part of the Anthropic apology, and it deserves a closer look because it is structured differently depending on which plan you are on.
- Claude Plus ($20 per month). Reset means your daily rate limit counter went back to zero on April 23. If you had been burning through your quota trying to get unstuck with a flaky model, you got the day's budget back to retry. Small in dollar terms, meaningful in unblock terms.
- Claude Pro ($100 per month). Same structure, bigger quota. Pro users reported regaining a full week of heavy-use capacity in a single reset. For developers who use Claude Code as their primary coding tool, this is the first time Anthropic has given back a material quantity of consumable product in response to a quality issue.
- Claude Max ($200 per month) and Max x20 ($200 per user per month, enterprise tier). The reset applies here too. Max x20 users — which includes us — got a meaningful quota refresh right as the patched v2.1.116 shipped, which made the reset feel like "here is your budget back, now use it on a working product."
- Claude Business and Enterprise. Custom quotas, custom resets. The postmortem uses the phrase "effective today" and does not specify per-tier details, but multiple enterprise customers have reported on X that their account representatives confirmed individual quota resets within 24 hours of April 23.
What this is not: a cash refund, a credit toward future bills, or an SLA penalty payment. Anthropic did not issue money. They issued consumable product. For a usage-based service, that distinction matters — it is a cheaper gesture in dollar terms, but it is also a gesture that directly restores what was lost (the ability to run Claude) rather than being a symbolic check. Whether that is generous or cheap depends on which end of the keyboard you are on.
For heavy users who genuinely exhausted their quotas trying to work around the buggy model, the reset is real compensation. For subscribers who rarely hit their limits, it is a symbolic gesture with little practical value. Anthropic chose the form of compensation that rewards its heaviest users, which is probably the correct optimization given that those are the users most damaged by the degradation.
The three new quality-control promises

The postmortem's second half is what Anthropic is committing to going forward. Three specific changes, all of them responding to the specific failure modes that shipped the three bugs. In order of significance:
Promise 1: more Anthropic employees will use the public build of Claude Code
Anthropic's exact wording: "More of our employees will begin using the public build of Claude Code (not internal development builds) for their day-to-day work." Translation: Anthropic engineers have, until now, been using internal development builds of Claude Code that do not always match what customers receive. The reasoning-effort-flip bug and the caching bug both shipped to production without being caught internally, in part because the people most likely to notice (Anthropic's own developers) were running a different build of the product.
This is the most meaningful commitment on the list. Dogfooding — eating your own dog food by using the exact version of the product your customers use — is a bedrock principle of production engineering. The fact that Anthropic had to commit to this publicly suggests it was not the default, which is quietly alarming. It is also fixable immediately, and it should materially reduce the probability of customer-visible regressions going unnoticed for weeks at a time.
Promise 2: every system-prompt change runs through a broad model-specific eval suite
Anthropic's wording: "Every system prompt change will go through a broad model-specific eval suite before rollout." This is the direct response to Bug 3 (the verbosity instruction). The lesson learned is that system-prompt changes — even one-line tweaks — can have measurable effects on model output quality, and therefore must be evaluated as rigorously as model weight changes.
In practice, this means Anthropic is expanding the scope of its pre-release eval pipeline from "model changes" to "anything that touches what the model sees, including prompts and instructions." The cost of this is slower velocity on prompt tweaks. The benefit is that the next one-line instruction cannot silently tank a coding benchmark for four days before someone notices. It is a clean trade-off in favor of quality stability over deployment speed.
Promise 3: soak periods and gradual rollouts for anything impacting intelligence
Anthropic's wording: "Changes that could impact the model's intelligence will include soak periods and gradual rollouts." A soak period is a staging phase where a change is deployed to a subset of traffic and monitored for a fixed duration before being rolled to full production. A gradual rollout is a progressive deployment where traffic percentage increases over days.
This is the direct response to Bug 1 (the reasoning-effort flip), which shipped to 100% of users on day one and stayed there for 34 days. Under the new policy, a similar change would have hit maybe 5% of users in the first week, giving Anthropic's internal monitoring time to detect the regression before it affected the full customer base. It is not a revolutionary technique — it is a standard industry practice for production changes at scale — but the fact that Anthropic is now formally committing to it for model-intelligence changes is the right move and should have been the default.
Collectively, these three commitments are appropriate. They address the specific failures that shipped. They do not require Anthropic to slow down meaningfully. They are enforceable internally and verifiable externally (we will notice if the next model change hits 100% of users on day one again). If Anthropic executes, this should be the last "3 bugs in 50 days" postmortem. If they do not, the next scandal will look the same and the community's patience will be thinner.
Our verdict: credibility restored, but damage done
The postmortem is, on balance, the right move by Anthropic. It is specific. It names dates. It names bugs. It admits the quality-control process failed three times in 50 days. It offers concrete compensation. It commits to specific process changes that, if followed, will prevent a repeat. Anthropic did not try to spin this. The tone reads closer to an AWS post-incident writeup than a Big Tech non-apology. That is the right register.
What it does not fix: the 50 days of degraded output already shipped to customers. We cannot un-ship the half-baked refactors our team merged in late March. Anyone who made production decisions based on Claude Code output between March 4 and April 20 is living with that output, and the usage-limits reset does not retroactively re-write the git history. That is damage that stays on the books.
What it does not fully address: the trust reset. The community now knows — with receipts — that Claude Code can ship three independent regressions in 50 days without Anthropic's own QA catching them. That knowledge does not go away when the bugs are fixed. Every Claude Code user from April 23 onward will be slightly more vigilant, slightly more likely to log sessions, slightly more likely to keep a competitor warm as a fallback. The asymmetric cost of trust is that losing it takes 50 days and rebuilding it takes years.
What it does address, genuinely: the specific failure modes are now public, named, and committed against. Anthropic has given the community the tools to verify the fix. If the three new promises hold — dogfooding, eval suites on prompts, soak periods for intelligence-affecting changes — the probability of a repeat goes down substantially. We will know by Q3 2026 whether the commitments are real or cosmetic.
Our position: we are staying on Claude Code. We are also keeping our logger running (we added session-length monitoring in early April per our mitigation playbook), we are keeping GPT-5.4 via ChatGPT warm for the next scandal, and we are treating the April 23 postmortem as a high-quality apology from a company we trust to build good products but do not trust to catch their own regressions. That is a nuanced position. It is also the correct one.
The bigger picture: April 2026 is a pressure cooker for Anthropic
The three-bugs postmortem did not land in a vacuum. April 2026 has been the most turbulent month in Anthropic's corporate history. The same week as the postmortem:
- OpenAI's revenue team leaked an internal memo accusing Anthropic of inflating 2025 revenue by $8 billion — see our breakdown.
- Anthropic's October 2026 IPO targeting an $800 billion valuation moved into active marketing phase — details in our IPO coverage.
- Claude Code's leaked 512,000-line source codebase gave competitors a roadmap of every hidden capability in the product — see our leak deep-dive.
- The Claude Code leaked internal roadmap revealed features shipping in Q3-Q4 2026 — catalog in the roadmap piece.
In that context, the quality scandal is especially painful because it gives detractors — OpenAI, regulators, enterprise procurement teams evaluating Claude Code vs alternatives — a concrete failure to point to. "Three production bugs in 50 days" is the kind of sentence that lands on a procurement evaluation slide. Anthropic knows this. The postmortem's speed and specificity reflect that knowledge. They had to get ahead of this fast, before the IPO book was finalized.
Our reading: Anthropic is under more pressure in April 2026 than at any point in its four-year history. The postmortem is not just a customer-trust gesture. It is a pre-IPO risk-mitigation move. Every regulator, every institutional investor, every enterprise customer asking "how does Anthropic handle production quality" now has an official answer, with dates and numbers. The postmortem is, in a real sense, a document written for audiences beyond Claude Code users. That does not make it less valuable — a document that is carefully written for multiple audiences tends to be more precise, not less. But it is worth noticing who the document is really for.
What we are doing now, concretely
Five changes to our workflow effective immediately:
- Continue logging every Claude Code session. The session-length and tool-call-depth logger we deployed in the first week of April stays on. This was the right investment. It will catch the next bug on day two instead of day forty-five.
- Upgrade to Claude Code v2.1.116 explicitly. The patched version is the one that has all three fixes applied. We pinned it in our repo configs on April 23.
- Keep the
--effort=highdefault in our harness config. Even though Bug 1 is rolled back, the belt-and-suspenders position is to keep the explicit flag in our configuration. If Anthropic ever experiments with a MEDIUM default again — even briefly — we are protected. - Monitor soak-period deployments. Anthropic committed to gradual rollouts for intelligence-affecting changes. We will watch for changelog entries mentioning staged rollouts. If a new Claude Code version ships to 100% on day one without staging, that is the signal that the commitments are not being honored.
- Run a weekly 10-task benchmark against GPT-5.4. Same tasks, both platforms, same week. This is not because we expect to switch — it is because we want an external reference point for Claude quality over time. If Claude degrades again, we will see it relative to GPT before we see it absolutely.
None of this is adversarial to Anthropic. All of it is the price of using a cloud-hosted AI product as a core part of a production stack. The lesson of April 2026 is that the price includes measurement, not just subscription dollars. We are going to keep measuring.
Frequently asked questions
What are the three Claude Code bugs Anthropic fixed on April 23, 2026?
The three bugs identified in Anthropic's April 23 postmortem are: (1) a reasoning-effort default change from HIGH to MEDIUM shipped March 4 and rolled back April 7, (2) a caching feature shipped March 26 that was supposed to clear older thinking after sessions idle for more than 1 hour but instead ran every turn, causing forgetful and repetitive behavior until the fix on April 10, and (3) a system-prompt verbosity instruction added April 16 that cut coding-eval performance by 3% on Opus 4.6 and 4.7 before being rolled back April 20. All three fixes are bundled in Claude Code v2.1.116.
Where can I read the official Anthropic postmortem?
The official postmortem is published at anthropic.com/engineering/april-23-postmortem under the title "An update on recent Claude Code quality reports." It was published on April 23, 2026 and includes the timeline of all three bugs, the engineering root causes, the rollback dates, the compensation announcement for paid subscribers, and the three new quality-control commitments Anthropic is making going forward.
Which Claude Code version has all three bug fixes?
Claude Code v2.1.116, shipped April 20, 2026, is the version that bundles all three rollbacks: reasoning-effort default back to HIGH, caching-feature fix (so the idle-clear only triggers after actual 1-hour idle), and removal of the verbosity instruction from the system prompt. Users on v2.1.115 or earlier should upgrade to v2.1.116 to get the full set of fixes. Anthropic is pushing the patched version as the default install automatically, but heavy users running pinned versions should verify they are on v2.1.116 explicitly.
Did Anthropic compensate Claude Code users for the degradation?
Yes. On April 23, 2026, Anthropic reset usage limits for all Plus, Pro, Business, and Enterprise subscribers as a gesture of good faith. The reset means consumed monthly quota counters went back to zero on April 23, allowing users to run additional Claude Code sessions without hitting their normal limits for that billing period. This is not a cash refund or a credit — it is restored capacity to use the patched product. It is the first time Anthropic has issued this kind of compensation for a quality regression.
What is the reasoning-effort bug Anthropic admitted to?
On March 4, 2026, Anthropic changed Claude Code's default reasoning effort from HIGH to MEDIUM in an attempt to reduce latency for the median workload. The change caused a measurable degradation in complex-task quality — planning-before-coding behavior dropped sharply, retries increased, and tool-call depth collapsed. After 34 days of user complaints and a viral Scortier Substack study showing median thinking length dropping from 2,200 to 600 characters, Anthropic rolled the default back to HIGH on April 7, 2026. The rollback was the first of the three fixes in the April 23 postmortem.
What was the caching bug that made Claude "forgetful and repetitive"?
On March 26, 2026, Anthropic shipped a feature meant to clear older thinking from the session context after the user had been idle for more than 1 hour, in order to reduce latency on resumed sessions. Due to an implementation bug, the feature ran on every turn instead of only after genuine idle periods. The effect was that Claude's running reasoning scratchpad was wiped between user messages, causing the agent to repeat questions, ask for information already provided, and lose conversational coherence. The bug was live for 15 days and was fixed on April 10, 2026.
How did a one-line verbosity instruction cut Claude's coding quality by 3%?
On April 16, 2026, Anthropic added an instruction to Claude Code's system prompt aimed at making outputs shorter and more focused. The instruction, combined with other recent prompt changes, produced a 3% regression on Anthropic's internal coding-eval benchmark across both Opus 4.6 and Opus 4.7. The mechanism is not fully disclosed in the postmortem, but the general pattern — a verbosity-reduction instruction interacting unexpectedly with the model's reasoning output — is a known risk category in prompt engineering. Anthropic rolled back the instruction on April 20, 2026, four days after it shipped.
Why did Anthropic not catch these Claude Code bugs internally?
The April 23 postmortem admits that Anthropic engineers were largely using internal development builds of Claude Code rather than the public build customers receive. This meant the people most likely to notice production regressions were running a different product than the one with the bugs. Anthropic has now committed that more employees will use the public build of Claude Code for their day-to-day work going forward, which should materially improve internal detection of production-visible regressions before customers report them.
What are Anthropic's three new Claude Code quality-control commitments?
In the April 23 postmortem, Anthropic committed to three specific process changes. First, more employees will use the public build of Claude Code (dogfooding) rather than internal development builds. Second, every system-prompt change will now run through a broad model-specific eval suite before rolling to production. Third, changes that could impact the model's intelligence will include soak periods (staged subset rollout with monitoring) and gradual rollouts (progressive traffic percentage increases) rather than immediate full-traffic deployment. Together these commitments target the root-cause patterns behind the three bugs.
Should I switch away from Claude Code after the three-bugs scandal?
Depends on your workload and risk tolerance. The fix in v2.1.116 is real — all three bugs are rolled back and the product behavior is restored to approximately its January 2026 quality. Anthropic's new quality-control commitments, if honored, should reduce the probability of repeat regressions. For most workloads, staying on Claude Code with the --effort=high flag, session logging, and a pinned model version is the pragmatic move. If your workload demands the absolute highest quality-consistency guarantees, keeping GPT-5.4 via OpenAI Codex warm as a fallback is a reasonable hedge. Full switching is probably overreaction for the April 2026 data set.
Is Opus 4.7 affected by the three bugs too or only Opus 4.6?
Bugs 1 and 3 affected both Opus 4.6 and Opus 4.7 — the reasoning-effort default change was a Claude Code-level configuration that applied to whichever model the user was running, and the verbosity prompt instruction produced measurable regressions on both 4.6 and 4.7 in Anthropic's coding-eval suite. Bug 2 (the caching issue) was also a Claude Code-level behavior that affected any session regardless of underlying model. Claude Code v2.1.116 fixes all three bugs for all models running through the Claude Code harness, including Opus 4.7.
How do I verify my Claude Code install is on the patched version?
Run claude-code --version in your terminal. The output should show 2.1.116 or higher. If you are on 2.1.115 or earlier, run npm install -g @anthropic/claude-code@latest (or your package manager equivalent) to upgrade. For CI/CD pipelines or production deployments that pin Claude Code versions, update the pin explicitly to 2.1.116 and redeploy. Anthropic is also pushing the update automatically to users on the default channel, but explicit verification is worth the 30 seconds, especially for teams with strict version-pinning policies.