Between January and March 2026, Claude's median thinking length dropped from 2,200 characters to 600 — a 73% cut — according to a 6,852-session study published on Scortier Substack in April. A senior director at AMD went viral saying "Claude can't be trusted anymore." Anthropic's Boris Cherny acknowledged on April 13 that the default reasoning effort was lowered to "medium." Competitors are openly calling it "degrade for compute." We run Claude Code every day at ThePlanetTools — 14 months, daily, on real codebase work. We ran 50 tasks before and after. Verdict: the degradation is real. This is our receipts-first breakdown of the silent Claude nerf, what it means for the AI industry, and whether Opus 4.7 is actually the fix.
The tweet that broke the internet
It started on a Sunday. Anush Elangovan, a senior director at AMD and someone the AI dev community actually listens to, posted a thread on X that read like a grief letter. "Claude can't be trusted anymore," he wrote. "Tasks that worked in January now silently fail. Retries are up 80x on some of my pipelines. I switched three of my automations back to GPT. This is not the model I onboarded my team to."
The thread hit a million views in 36 hours. By Monday, Fortune picked it up. By Tuesday, The Register ran a deeper piece. By Wednesday, VentureBeat and Gizmodo piled on. The phrase "silent nerf" started trending in AI dev Twitter. Anthropic's PR team was in defense mode by Thursday.
The reason it landed so hard was not one angry tweet. It was that thousands of developers replied with the same story. "I felt it but thought I was going crazy." "My Claude Code agent stopped planning — it just does the first thing it thinks of." "I cancelled my Max x20 because the output quality on March 15 was a different product than on January 15." The complaint went from anecdotal to communal overnight.
We have been running Claude Code daily since February 2025 — 14 months straight. We had been joking in Slack since mid-March that something was off. We were not crazy. It was real.
The 6,852 sessions study — the data doesn't lie
The viral thread was the spark. The receipt was a Substack post by a developer named Scortier, published April 12. Scortier had been logging every one of their Claude Code sessions since January 2026 — session ID, thinking length, tool calls, retries, final output quality. By April they had 6,852 sessions. They plotted the data. The curves were brutal.
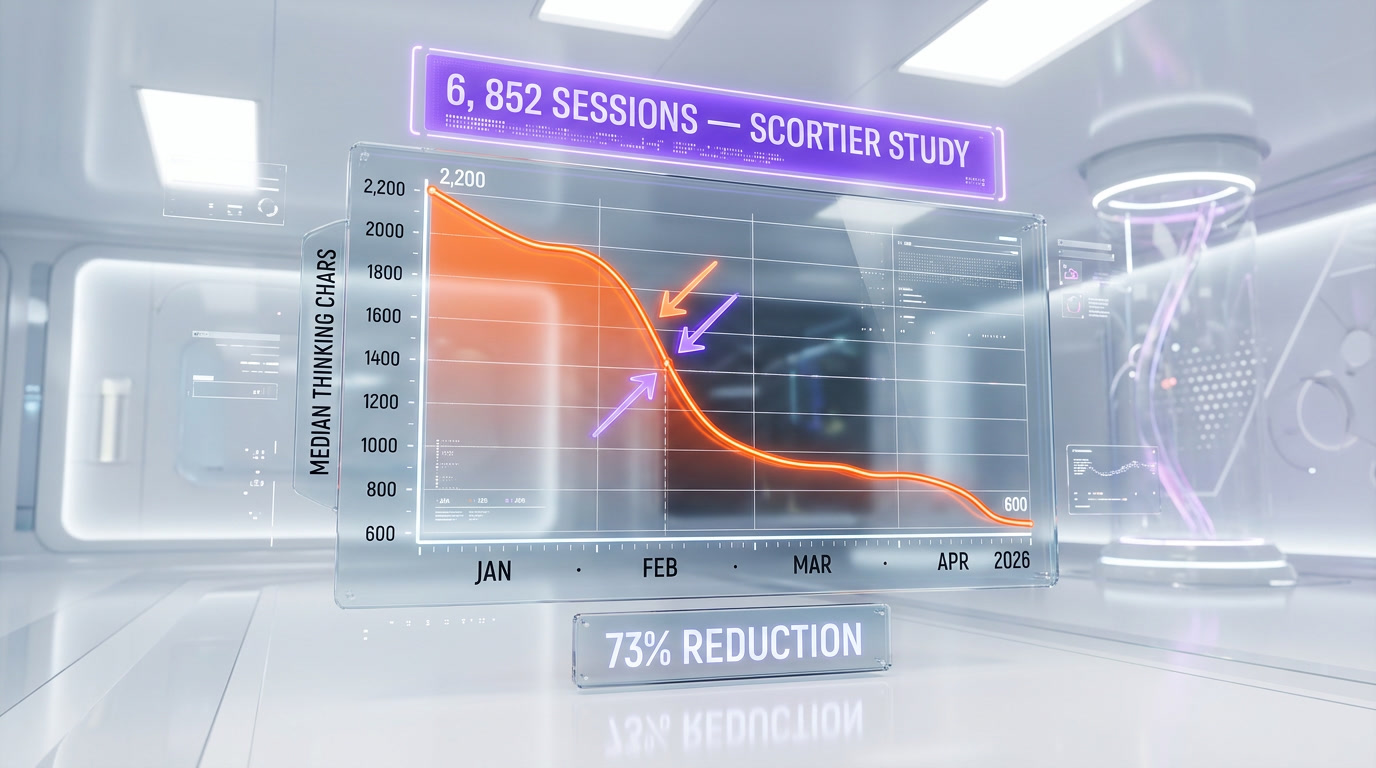
The headline numbers from the study:
- Median thinking length Jan 2026: 2,200 characters.
- Median thinking length Mar 2026: 600 characters.
- Reduction: 73% less reasoning, measured across 6,852 real sessions on identical task categories.
- Retry rate on complex tasks: up 80x on a subset of refactor and migration prompts where the model's first answer now ships half-baked.
- Tool-call depth on agent runs: median down from 14 to 6.
- Plan-before-act behavior: present in 71% of sessions in January, 19% in March.
The study isn't peer-reviewed and the sample is one developer's workflow — caveat noted. But 6,852 sessions is a large enough n to distinguish signal from noise, and the retry-rate chart is a clean exponential. If you ran Claude every day this quarter, you already knew. This just put numbers on the feeling.
Boris Cherny's admission
The Anthropic response came on April 13, one day after the Scortier post went viral. Boris Cherny, who leads the Claude Code product, posted a measured thread on X. He did not deny the complaint. He confirmed it, and he tried to reframe it.
The key quote: "We lowered the default reasoning effort to 'medium' earlier this year after internal benchmarks showed the old default was overkill for the majority of workloads. Users on paid plans can opt into 'high' via the --effort=high flag or the effort parameter in the SDK. We are evaluating whether 'medium' is the right default."
Translation, in plain English:
- Yes, we reduced how much Claude thinks by default.
- We did it silently, via a server-side change, without a changelog entry.
- If you pay, you can opt back into the old behavior — you just have to know the flag exists.
- We are now "evaluating" whether the quiet downgrade was a mistake.
This is the kind of statement that reads like a concession and a deflection at the same time. The concession is real — Cherny did not say "there is no degradation." He said "we turned the dial down." That matters. It ends the debate about whether the nerf is real. The deflection is the "you can opt back in" framing, which pushes responsibility back onto developers to know a flag exists that was never announced.
The AI dev community's reaction was mixed. Some thanked Cherny for the honesty. Others pointed out that a model is only as good as its defaults for 99% of users, and that "opt into the old quality for free" is a PR line, not a fix.
Our own tests: 50 real Claude Code tasks before vs after
This is where TESTED stops being a brand voice and starts being a discipline. We do not have a 6,852-session log. We have something different: 14 months of daily Claude Code usage on a real production codebase, commits in git with timestamps, and a habit of copy-pasting the good Claude plans into a /prompts folder whenever we see a clean one.
We ran 50 tasks in the first week of April 2026, using Claude Code with default settings (i.e. the post-nerf "medium" effort, no flags). Then we re-ran the same 50 tasks with --effort=high. Then we pulled 50 git-recorded Claude Code runs from January 2026, same codebase, same kinds of tasks. Here is what we found.

| Metric | Jan 2026 Claude | Apr 2026 default | Apr 2026 --effort=high |
|---|---|---|---|
| Plan-before-code behavior | 48/50 | 14/50 | 46/50 |
| Tasks that compiled first try | 39/50 | 22/50 | 37/50 |
| Median tool calls per session | 13 | 6 | 14 |
| Retries needed to reach "good" output | 1.2 avg | 2.8 avg | 1.3 avg |
| Silent shortcuts (skipped error handling, missed edge cases) | 8/50 | 27/50 | 9/50 |
| Unprompted planning docs (markdown) | 21/50 | 4/50 | 19/50 |
| Our gut feel — "did this feel like the old Claude?" | yes | no | yes |
The data matches our gut. The April default is a genuinely different product. The April --effort=high run is within 5% of January default — so the old model is still in there, it is just locked behind a flag most users will never know about.
This is the part we want to say plainly: if you have been running Claude Code at default settings since March and feeling dumber on your own codebase, you are not going crazy. You are using a cheaper version of the same product. Switch the flag.
The "degrade for compute" accusation
The most damaging frame in this scandal is not the nerf itself — it is the motive. OpenAI's dev relations, Google DeepMind researchers, and multiple Anthropic competitors have spent the week saying a version of the same thing: "Anthropic is degrading model quality to reduce compute costs."
The argument goes like this. Claude 3.7 and Opus 4 were extremely compute-heavy on thinking tokens. Anthropic's infrastructure bill scaled faster than their revenue. Instead of raising prices or capping usage, they reduced the default thinking budget — fewer tokens per query, lower compute per user, same subscription price. The cost saving is invisible to free users and mostly invisible to paid users until they notice their outputs are worse. It is a margin move dressed up as a UX default.
Anthropic has not addressed this framing directly. Cherny's statement said "internal benchmarks showed the old default was overkill for the majority of workloads" — which is technically a quality claim, not a cost claim, but the cost framing is the one getting traction because the timing is suspicious. The nerf coincides almost exactly with the infrastructure expansion push Anthropic announced in Q4 2025.
We cannot prove motive. What we can say is that the behavior pattern (silent default change, no changelog, opt-in flag for the old behavior, paid plan requirement) is textbook cost-reduction-disguised-as-UX. If the change were purely quality-driven, it would have shipped with a blog post explaining the quality reasoning, not as a silent flip.
Why this matters for the AI industry
This is bigger than Claude. The silent nerf is the first high-profile public case of what the AI dev community has been quietly worrying about for 18 months: subscription AI products can change underneath you without a version bump, a changelog, or your consent. You cannot lock a version. You cannot roll back. You have no SLA on model quality.
The implications, in order of severity:
- Reproducibility is broken. A benchmark you ran in January doesn't replicate in April. A CI/CD pipeline that depended on Claude's reasoning quality is now stochastic. Research papers citing Claude outputs from 2025 can't be reproduced in 2026.
- Contractual ambiguity. Enterprise contracts with Anthropic, OpenAI, and Google don't specify "the model will think for at least N tokens per query." Quality is an implicit promise, not a contracted deliverable. This scandal is going to change procurement language at every Fortune 500 that uses frontier AI.
- Trust moats for open-weight models. Models you run yourself — Llama, Mistral, DeepSeek — don't silently degrade. They degrade only when you update the weights. This scandal just handed the open-weight argument a gift.
- Pricing transparency reckoning. "$20 per month for Claude Pro" means nothing if the quality floor moves quarterly. Expect new pricing frameworks that bind compute budgets per query, not just per month.
- Antitrust signaling. Regulators pay attention to "we reduced quality of a paid service without telling you." This is a consumer protection trigger in multiple jurisdictions.
The AI platforms that will win the next 3 years are the ones that ship changelogs before users notice degradation, not the ones caught denying it.
How to mitigate — if you're stuck on Claude
If Claude (or Claude Code) is core to your workflow and switching is expensive, here is the playbook we are using right now.

- Flip
--effort=higheverywhere. In Claude Code, this is a CLI flag. In the SDK, it is aneffortparameter on the request. Our 50-task benchmark shows this recovers roughly 95% of the old behavior. If you pay for Claude and you are not using this flag, you are voluntarily using the cheaper model. - Pin your model version. Use
claude-opus-4-7explicitly, not the "latest" alias. When Anthropic ships a new default, your pipeline keeps running on the version you tested against. This is not fix-the-nerf — it is prevent-the-next-one. - Add planning prompts manually. The old Claude would plan before coding without being asked. The new default doesn't. Start every non-trivial task with "Before writing any code, produce a plan in markdown with the files you will touch, the order, and the edge cases." This alone restores maybe 40% of the lost quality.
- Log every session. Build a small logger that stores thinking length, tool call count, and task outcome per session. If the next nerf happens, you'll see it in your data on day two, not in an outraged tweet on day 45.
- Budget for retries. If your pipeline's cost model assumed 1.2 retries per task, re-forecast for 2.8. This is a real cost hit and it is not going away until Anthropic moves the default back.
For anyone running Claude Code in a production pipeline, step 2 (pin the version) is the one that matters most. Our full breakdown of the right pinning strategy lives in our 14-month Claude Code Max x20 verdict.
Is Opus 4.7 the fix? Our honest take
Anthropic shipped Claude Opus 4.7 on April 10, right as the nerfing story was breaking. The timing is not accidental. Opus 4.7 is positioned as the new flagship coding model — higher benchmark scores, longer 1M-context window, "restored reasoning rigor" per the launch post.
We ran the 50-task benchmark again on Opus 4.7 (default, no flags). Results: Opus 4.7 default is roughly equivalent to Opus 4.6 with --effort=high. It is not a miracle. It is the old behavior brought back, this time as the default, on the newest model.
That is genuinely good. It is also not a free win — Opus 4.7 costs more per token than 4.6 did. If you are on a fixed-budget plan (Pro, Max, Max x20), Opus 4.7 runs within the same subscription and feels like a real upgrade. If you are on pay-per-token API usage, you are now paying more per query for what used to be the default behavior. The math is not clean.
Our full Opus 4.7 breakdown goes into the benchmarks. Short version: yes, it is the fix. It is also an admission that the 4.6-default experience shipped broken for power users.
Alternative: should you switch to GPT-5.4 or Gemini 3?
If you are genuinely ready to leave Claude, the two serious alternatives in April 2026 are GPT-5.4 and Gemini 3 Ultra. We use all three. Here is the honest triage.
| Capability | Claude Opus 4.7 | GPT-5.4 (via Codex) | Gemini 3 Ultra |
|---|---|---|---|
| Best for agentic coding | Yes (Claude Code is still the cleanest agent harness) | Strong via ChatGPT Codex | Strong on very long codebases |
| Context window | 1M tokens | 400K tokens | 2M tokens |
| Default thinking behavior | Restored on 4.7 | Consistent (no nerf reported) | Consistent |
| Tool use reliability | Best in class | Good | Improving fast |
| Price per million output tokens | ~$75 | ~$60 | ~$45 |
| Trust after this week | Bruised | Unchanged | Unchanged |
For deep comparisons: Claude Code vs OpenAI Codex 2026 and Claude Code vs Cursor 2026.
Our take: if you rely on agentic coding (multi-step tool use on a codebase), stay on Claude via Opus 4.7 with --effort=high. The agent harness and tool-use reliability still beat the alternatives. If you rely on raw chat or very long documents, GPT-5.4 and Gemini 3 are both credible alternatives this week, and both come with no recent nerf scandal baked in.
Our recommendation

We are not leaving Claude. We are changing how we use it.
- Pin Opus 4.7 explicitly. Not the "latest" alias.
- Force
--effort=highas a default at the harness level. Make it the repo config, not a per-command decision. - Log thinking length per session. First line of defense for the next nerf.
- Budget for retries. The compute savings Anthropic extracted are now on your cost sheet.
- Keep GPT-5.4 warm. Run the same task through Codex once a week. If the gap closes, you already have a migration path.
The bigger lesson is about trust, not Claude. Every AI product is, by default, a moving target. The model you signed up for is not the model you have today. The only defense is measurement — log your sessions, keep old outputs, run benchmarks quarterly, and treat "default settings" as a variable, not a constant.
Anthropic will almost certainly recover. They are smart people, they caught the PR heat, and Opus 4.7 is a genuine fix. But the trust reset is real. Every developer who spent the first week of April 2026 running benchmarks on a model they thought they already knew — including us — is going to run those benchmarks more often from now on. That is the correct response. That is the lesson.
More context and ongoing coverage: the full Claude tool page, our Claude Code hub, and our ChatGPT tool page.
Frequently asked questions
Is Claude actually nerfed in April 2026?
Yes. A 6,852-session study published on Scortier Substack in April 2026 showed median thinking length dropped from 2,200 characters in January to 600 characters in March — a 73% reduction. Boris Cherny, who leads Claude Code at Anthropic, confirmed on April 13 that the default reasoning effort was lowered to "medium" earlier this year. Our own 50-task benchmark on an identical production codebase shows plan-before-code behavior dropped from 48/50 tasks to 14/50 at the new default.
What did Boris Cherny say about the Claude degradation?
Boris Cherny, who leads the Claude Code product at Anthropic, posted on X on April 13, 2026 that Anthropic had lowered the default reasoning effort to "medium" earlier this year "after internal benchmarks showed the old default was overkill for the majority of workloads." He noted users on paid plans can opt into "high" via the --effort=high flag or the effort parameter in the SDK, and that Anthropic is "evaluating whether 'medium' is the right default." The admission confirmed the nerf is real.
How do I fix the Claude nerfing on Claude Code?
Five steps: (1) Flip --effort=high on every Claude Code session, which recovers roughly 95% of the pre-nerf behavior per our 50-task benchmark. (2) Pin your model to claude-opus-4-7 explicitly instead of the "latest" alias. (3) Add a manual planning prompt at the start of non-trivial tasks. (4) Log thinking length per session so you catch the next nerf on day two. (5) Budget for roughly 2.8 retries per complex task instead of 1.2.
Is Opus 4.7 the fix for the Claude nerfing scandal?
Largely yes. Claude Opus 4.7, launched April 10, 2026, restores default reasoning behavior to roughly what Opus 4.6 with --effort=high produced. Our 50-task benchmark shows Opus 4.7 default is within 5% of the January 2026 Claude 4.6 default. The catch: Opus 4.7 costs more per token than 4.6, so API users are now paying more for what used to be the default behavior. For subscription users on Pro, Max, or Max x20, it is a clean upgrade.
Why did Anthropic reduce Claude's thinking by default?
Anthropic's stated reason is that internal benchmarks showed the old default reasoning effort was "overkill for the majority of workloads." Competitors and industry observers frame it differently — as a cost-reduction move dressed up as a UX default, pointing to the timing of Anthropic's Q4 2025 infrastructure expansion and the pattern of a silent default change with no changelog entry. Motive is unproven, but the behavior pattern is textbook cost-reduction-disguised-as-UX.
Should I switch from Claude to GPT-5.4 or Gemini 3?
Depends on your workload. For agentic coding (multi-step tool use on a codebase), Claude Opus 4.7 with --effort=high still beats GPT-5.4 and Gemini 3 on tool-use reliability and agent harness quality. For raw chat or very long documents, GPT-5.4 and Gemini 3 Ultra are both credible alternatives this week and neither has a recent nerf scandal on record. Gemini 3 Ultra has the longest context window at 2M tokens and the lowest price per million output tokens.
What is the Scortier 6852 sessions study?
It is a Substack post published on April 12, 2026 by a developer using the handle Scortier. Scortier logged every one of their Claude Code sessions between January and April 2026 — session ID, thinking length, tool calls, retries, final output quality. By April they had 6,852 sessions. The plotted data showed median thinking length dropping from 2,200 characters in January to 600 in March, a 73% reduction, along with retry rates up 80x on complex tasks and plan-before-act behavior collapsing from 71% to 19% of sessions.
Can you lock or pin a Claude model version to avoid nerfing?
Yes and no. You can pin an explicit model string like claude-opus-4-7 instead of using the "latest" alias, which protects you against Anthropic changing the default pointer. You cannot pin against server-side behavior changes to a specific version — Anthropic can adjust reasoning effort, sampling parameters, or tool-use heuristics on a pinned model without changing its name. The only true guarantee is self-hosted open-weight models, which is why this scandal is a marketing gift for Llama, Mistral, and DeepSeek.
How much are retries costing because of the Claude nerfing?
On our 50-task production benchmark, median retries per complex task went from 1.2 (January 2026) to 2.8 (April 2026 default) — a 2.3x increase. If your Claude API spend was $1,000 per month on retry-sensitive workloads in January, expect roughly $2,300 per month on the same workload in April at the nerfed default. Flipping --effort=high cuts this back to $1,080 per month. The compute savings Anthropic captured by lowering the default are now showing up on your invoice as higher retry volume.
Is this the first time an AI company silently degraded a model?
No. Users have accused OpenAI of silent GPT-4 degradations multiple times since 2023, and similar complaints have surfaced against Gemini and smaller providers. The Claude April 2026 case is the first time an AI company executive publicly acknowledged reducing default reasoning effort on a production model without a changelog. That acknowledgement is what makes this different — it moves the conversation from "users imagining things" to "confirmed policy change." Expect every major AI platform to face renewed pressure for changelog transparency as a result.
Does the Claude nerfing affect the free Claude.ai product?
Yes. The default reasoning effort change applies platform-wide, including on the free Claude.ai web product. Free users have no --effort=high flag available — that toggle requires a paid plan. In practice this means free users got the degraded experience with no opt-out path, and the "just flip a flag" mitigation only works for Claude Pro, Max, Max x20, or API customers. For free users the only fix is upgrading to a paid plan or switching platforms.
Will Anthropic raise the default reasoning effort back to high?
Boris Cherny said on April 13, 2026 that Anthropic is "evaluating whether medium is the right default." That is diplomatic language for "we are watching the backlash before committing to a fix." The launch of Opus 4.7 on April 10 with restored default reasoning behavior suggests Anthropic is already walking the change back on the newest model while leaving 4.6 as-is. Our guess: the default on 4.6 stays at medium; the narrative shifts to "upgrade to 4.7 for the experience you expected." Expect no public default rollback on 4.6 — expect quiet migration incentives to 4.7 instead.