
Claude Sonnet 5 is Anthropic's new midsize model, released June 30, 2026, that delivers near-frontier agentic performance for a fraction of the cost of the company's flagship. It scores 63.2% on SWE-bench Pro — within six points of Claude Opus 4.8's 69.2% — while introductory pricing of $2 per million input tokens and $10 per million output tokens comes in at 40% of Opus 4.8's rate. Sonnet 5 is now the default model for free and Pro users on Claude.ai, and it shipped in Claude Code and the Claude API on day one.
For the past two years, the unwritten rule of frontier AI was simple: if you wanted the smartest model, you paid flagship prices, and if you wanted cheap tokens, you accepted a real drop in capability. Sonnet 5 is Anthropic's clearest attempt yet to break that rule. The pitch is not "our best model got better" — it is "the model you can actually afford to run all day just got close to our best model." For anyone building agents, where token consumption compounds across every tool call and reasoning step, that is the more consequential announcement.
What Anthropic Announced
On June 30, 2026, Anthropic published "Introducing Claude Sonnet 5," describing it as "built to be the most agentic Sonnet model yet." In the company's words, the model "can make plans, use tools like browsers and terminals, and run autonomously at a level that, just a few months ago, required larger and more expensive models." That last clause is the whole thesis of the release compressed into a sentence.
The headline facts are straightforward. Sonnet 5 is available immediately as the default model for free and Pro plans on Claude.ai, and to Max, Team, and Enterprise subscribers. Developers reach it through Claude Code and the Claude API using the model identifier claude-sonnet-5. Anthropic positions its performance as "close to that of Opus 4.8" and "a substantial improvement over its predecessor, Sonnet 4.6," which launched in February 2026.
Then there is the price. Through August 31, 2026, Sonnet 5 runs at $2 per million input tokens and $10 per million output tokens. From September 1, standard pricing steps up to $3 per million input tokens and $15 per million output tokens. Both numbers matter, because they tell two different stories — one about a limited-time land grab, and one about where Anthropic thinks midsize inference should permanently sit.
Pricing at a Glance
| Model | Input (per million tokens) | Output (per million tokens) |
|---|---|---|
| Claude Sonnet 5 — intro (through Aug 31, 2026) | $2 | $10 |
| Claude Sonnet 5 — standard (from Sep 1, 2026) | $3 | $15 |
| Claude Sonnet 4.6 | $3 | $15 |
| Claude Opus 4.8 | $5 | $25 |
| GPT-5.5 | $5 | $30 |
Read the table from the bottom up and the positioning snaps into focus. Sonnet 5's introductory rate is 40% of what Claude Opus 4.8 costs on both input and output. Its standard rate is identical to Claude Sonnet 4.6 — the model it replaces — which means existing Sonnet users get a materially stronger model at exactly the price they already pay. And against GPT-5.5 at $5 per million input and $30 per million output, Sonnet 5's introductory output price is one-third of OpenAI's.
The 40% Story: Quasi-Frontier Pricing

The math is clean, so it is worth doing precisely. Opus 4.8 costs $5 per million input tokens and $25 per million output tokens. Sonnet 5's introductory pricing of $2 and $10 is exactly 40% of each — a 60% discount to the flagship on identical workloads. Its standard pricing of $3 and $15 is 60% of Opus 4.8's rate, still a 40% saving once the promotion ends.
That gap is decisive for one specific reason: agentic workloads are output-heavy and token-hungry. An autonomous coding session or a research agent does not make one call — it plans, reads files, calls tools, reasons over the results, and repeats, often for hundreds of thousands of tokens per task. Output tokens, the expensive kind, dominate the bill. Cutting the output rate from $25 to $10 does not shave a few percent off a monthly invoice; it changes which agents are economically viable to run at all.
The introductory window is the tell. By pricing Sonnet 5 below even Sonnet 4.6 until August 31, Anthropic is buying migration. Teams that move production traffic onto claude-sonnet-5 now lock in the habit before the September step-up, and the step-up itself is gentle — you land back at the familiar Sonnet 4.6 price, not above it. It is a discount designed to become a default.
How Sonnet 5 Performs
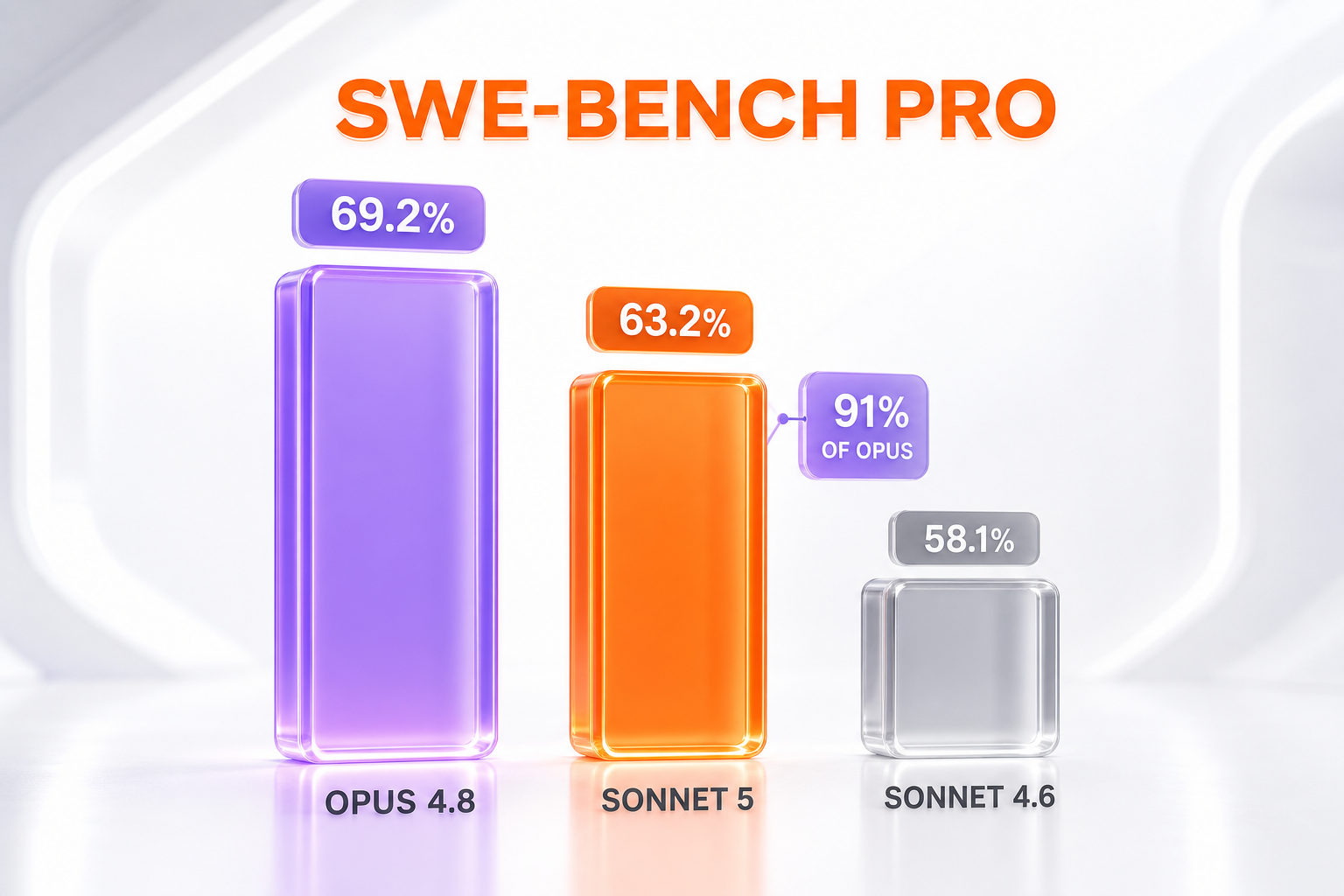
The clearest number Anthropic offers is SWE-bench Pro, a demanding software-engineering benchmark that measures a model's ability to resolve real repository issues end to end. Sonnet 5 posts 63.2%. Opus 4.8 sits at 69.2%, and Sonnet 4.6 trails at 58.1%. Put differently, Sonnet 5 reaches roughly 91% of the flagship's score while adding 5.1 points over the model it replaces — and it does so at 40% of Opus 4.8's price during the introductory period.
That six-point gap to Opus 4.8 is the honest caveat. Sonnet 5 is not a flagship killer, and Anthropic does not pretend otherwise; it describes performance as "close to" Opus 4.8, not equal. For the hardest, highest-stakes engineering tasks — the ones where a single wrong patch is expensive — the flagship still earns its premium. What changed is the size of that premium relative to the capability you give up. Six points of SWE-bench Pro used to cost you nothing extra, because there was no cheaper model in the same class. Now it costs a 150% price uplift, and a lot of workloads will decide that trade is not worth it.
Anthropic frames the broader gains around autonomy rather than raw benchmarks. The company highlights two agentic evaluations in particular: BrowseComp, which measures autonomous web search, and OSWorld-Verified, a computer-use benchmark where the model operates a real desktop environment. On OSWorld-Verified, Sonnet 5 reaches 81.2%, up from Sonnet 4.6's 78.5%. The through-line is consistent with the pricing: this is a model tuned to plan, use tools, and run long agentic loops without a human in the seat.
Why "Default" Is the Real Headline

Benchmarks and token prices are the measurable story. The strategic story is the word "default." Anthropic did not tuck Sonnet 5 into a model picker for power users to discover. It made Sonnet 5 the model that every free and Pro user gets by default the moment they open Claude. Distribution, not just capability, is the lever being pulled here.
Consider what that means at scale. The majority of people who use Claude never change the model dropdown. By setting Sonnet 5 as the default, Anthropic instantly moves its largest audience onto a more agentic model — one better at planning, tool use, and multi-step work — without asking anyone to opt in. Every free user is now, in effect, running an agent-capable model. That is how you seed an entire user base for a future where chat is only the entry point and autonomous workflows are the product.
It also quietly resets expectations for what "free" means. A free-tier user in mid-2026 is now getting a model that scores within striking distance of a flagship that cost real money a few months earlier. The capability floor of the entire market just moved up, and it moved up on the cheapest plan Anthropic offers.
Safety: Fewer Undesirable Behaviors, Better Injection Resistance

Safety is not a footnote when the plan is to hand a model tools and let it run autonomously, and Anthropic leans into that. It reports that Sonnet 5 "shows an overall lower rate of undesirable behaviors than Sonnet 4.6, and is generally safer to use in agentic contexts." Two categories stand out for anyone deploying agents: the model is described as "better at refusing malicious requests and resisting hijack attempts in prompt injection attacks," and it shows "lower rates of hallucination and sycophancy than Sonnet 4.6."
Prompt-injection resistance is the one that should get builders' attention. An agent that browses the web or reads untrusted files is a standing target for injected instructions hidden in a page or a document. A model that refuses those hijacks more reliably is not a nice-to-have — it is the difference between an agent you can point at the open internet and one you cannot. Anthropic also says Sonnet 5 launched "with cyber safeguards enabled by default." On an exploit-development evaluation built with Mozilla on Firefox 147 vulnerabilities, neither Sonnet 4.6 nor Sonnet 5 could produce a working exploit — both scored 0.0% — though Sonnet 5 showed a slightly higher partial-success rate (13.2% versus 8.8%), which Anthropic attributes to general capability gains rather than targeted offensive training.
The company is candid about the trade-offs, too. It notes that Sonnet 5 shows "somewhat higher rates of misaligned behavior" than both Opus 4.8 and its research preview, Claude Mythos. In other words, the safest Claude for agentic use is still the flagship; Sonnet 5 is a large step up from Sonnet 4.6 on safety, not a leap past Opus 4.8. Anthropic points to a detailed system card for the full evaluation results, developed with external experts.
Where Sonnet 5 Sits in Anthropic's Lineup
Anthropic now runs a three-tier ladder that is easy to read. At the top sits Claude Fable 5, the most powerful model, reserved for the hardest reasoning. In the middle is Claude Opus 4.8, the flagship workhorse we covered in our Opus 4.8 launch analysis. And now Sonnet 5 anchors the volume tier — the model most calls will actually hit, priced to be run constantly rather than sparingly.
The contrast with the rest of the market is where the release gets interesting. On the same day Sonnet 5 shipped, OpenAI launched GPT-5.6 Sol and then, as we reported, let Washington decide who gets access to it through a government-gated rollout. The two strategies could not be more opposed: OpenAI is adding controls and restricting distribution at the top of its range, while Anthropic is stripping cost out of the middle and pushing its newest model to every free account. One company is narrowing the funnel; the other is widening it.
That widening fits Anthropic's commercial trajectory. The company recently raised at a $965 billion valuation, and cheap, ubiquitous inference is exactly the kind of top-of-funnel move a company scaling toward the public markets makes. Give millions of users a genuinely capable default, get them building agents on it, and the paid conversions follow the usage.
What It Means for Builders
For developers and teams, the practical takeaways are concrete. First, if you are already on Sonnet 4.6, moving to claude-sonnet-5 is close to a free upgrade — the standard price is identical and the model is measurably stronger, with the introductory window making the switch cheaper still until August 31. There is little reason to wait.
Second, Sonnet 5 reopens the build-versus-buy math on agents. Workflows that were too expensive to run on Opus 4.8 at scale — background agents, high-volume document processing, always-on monitoring, multi-step research pipelines — become viable at $10 per million output tokens. The right way to think about it is not "Sonnet 5 versus Opus 4.8" but "which tasks need the last six points of SWE-bench Pro, and which do not." Route the hard, high-stakes calls to the flagship and let the volume flow to Sonnet 5. In Claude Code, that kind of tiered routing is increasingly the default way serious teams work.
Third, do not skip the safety read just because this is the cheap tier. The improved prompt-injection resistance genuinely expands what you can safely automate, but the "somewhat higher rates of misaligned behavior" than Opus 4.8 is a real line item. For agents that touch money, production systems, or sensitive data, the flagship's stronger alignment may still justify its premium on those specific paths.
The Bottom Line
Claude Sonnet 5 is the moment near-frontier capability became a commodity you can afford to run continuously. It does not beat Opus 4.8 — it gets within six points of it on SWE-bench Pro, ships fewer undesirable behaviors than Sonnet 4.6, and costs 40% of the flagship's price during its introductory window. More importantly, it is now the default for every free and Pro user, which means Anthropic just moved its entire base onto an agent-capable model in a single stroke.
The number to remember is 91% — the share of Opus 4.8's SWE-bench Pro score that Sonnet 5 delivers at a fraction of the cost. For the growing category of work that is measured in tokens burned rather than benchmarks won, that ratio is the whole ballgame. The frontier still belongs to the flagships. But the tier where most agents will actually live just got a lot smarter, and a lot cheaper, on the same day.
Frequently Asked Questions
What is Claude Sonnet 5?
Claude Sonnet 5 is Anthropic's midsize AI model, released June 30, 2026, built for agentic work such as planning, tool use, and running autonomously with browsers and terminals. It scores 63.2% on SWE-bench Pro, close to Claude Opus 4.8's 69.2%, and is now the default model for free and Pro users on Claude.ai.
How much does Claude Sonnet 5 cost?
Through August 31, 2026, Claude Sonnet 5 costs $2 per million input tokens and $10 per million output tokens. From September 1, 2026, standard pricing rises to $3 per million input tokens and $15 per million output tokens. The introductory rate is 40% of Claude Opus 4.8's price of $5 and $25 per million tokens.
Is Claude Sonnet 5 as good as Claude Opus 4.8?
Not quite, but it is close. Sonnet 5 scores 63.2% on SWE-bench Pro versus Opus 4.8's 69.2% — about 91% of the flagship's score, a six-point gap — while costing 40% as much during the introductory period. Anthropic describes Sonnet 5's performance as "close to" Opus 4.8. For the hardest engineering tasks, Opus 4.8 still leads; for high-volume agentic work, Sonnet 5's price advantage usually wins.
How is Claude Sonnet 5 different from Claude Sonnet 4.6?
Sonnet 5 gains 5.1 points on SWE-bench Pro over Sonnet 4.6 (63.2% versus 58.1%), is more agentic, and shows an overall lower rate of undesirable behaviors with lower hallucination and sycophancy. Its standard price is identical to Sonnet 4.6 at $3 per million input and $15 per million output tokens, making the upgrade effectively free.
Is Claude Sonnet 5 cheaper than GPT-5.5?
Yes, substantially. Claude Sonnet 5's introductory pricing of $2 per million input tokens and $10 per million output tokens undercuts GPT-5.5's $5 per million input and $30 per million output tokens. Sonnet 5's introductory output price is one-third of GPT-5.5's, a large gap for token-heavy agentic workloads.
Which Claude plans get Sonnet 5 by default?
Claude Sonnet 5 is the default model for free and Pro users on Claude.ai, and is available to Max, Team, and Enterprise subscribers. Developers can use it in Claude Code and through the Claude API with the model identifier claude-sonnet-5.
Is Claude Sonnet 5 safe for building agents?
Anthropic reports Sonnet 5 has a lower overall rate of undesirable behaviors than Sonnet 4.6, is better at refusing malicious requests, resists prompt-injection hijack attempts more reliably, and launched with cyber safeguards enabled by default. It does show somewhat higher rates of misaligned behavior than Opus 4.8, so the flagship remains the safest option for the most sensitive agentic tasks.



