
Figure AI ran three Figure 03 humanoid robots — nicknamed Bob, Frank, and Gary — through a continuous parcel-sorting shift that crossed 24 hours of uninterrupted autonomous operation on May 13-14, 2026, with zero failures and zero teleoperation. The fleet sorted more than 28,000 parcels at roughly 3 seconds per parcel — a pace CEO Brett Adcock described as "around human parity" — entirely under the control of Helix-02, Figure's unified vision-language-action network that fuses camera vision, tactile sensing, proprioception, and whole-body control into a single onboard policy. The original plan was an 8-hour test; after a failure-free first day, Figure kept the run going and pushed toward 30 hours, with Adcock signaling a target window that could stretch toward 50 hours. This is the strategic inflection that matters: not a scripted demo reel, but a long-horizon, self-recovering, fleet-level run that looks like the first credible bridge from humanoid demo theater to deployable warehouse labor.
We have watched humanoid robotics ship spectacular two-minute clips for three years. A robot folds laundry. A robot makes coffee. A robot dances. Every one of those clips has the same hidden asterisk: short horizon, narrow task, frequently teleoperated, and almost never run long enough to expose the failure modes that actually gate deployment. The Figure run on May 13-14 is interesting precisely because it inverts every one of those asterisks at once. The horizon is long. The task is sustained and repetitive in the way real labor is. There is no human in the loop. And the system recovers from its own mistakes without a person stepping in. That combination is the thing the industry has been promising and not delivering — and it is why this run is worth a strategic read rather than a headline skim.
What Figure Actually Demonstrated
Let us be precise about the confirmed facts, because the difference between "24 hours, confirmed" and "50 hours, announced" is exactly the kind of gap that gets a robotics story wrong. According to Interesting Engineering's reporting, corroborated by TechTimes, three Figure 03 units ran a parcel-sorting workload continuously past the 24-hour mark with zero failures, and the run was still progressing toward 30 hours at the time of publication on May 14, 2026. Brett Adcock framed a longer target — the run was extended live, and the CEO signaled the team would keep going, with figures up to 50 hours circulating from Figure's own messaging. We treat 24-hours-plus as the hard, corroborated number and the 30-to-50-hour band as the live, CEO-stated trajectory rather than a settled record.
The task itself is deliberately mundane, and that is the point. The robots detect barcodes on parcels, pick each parcel up, and place it barcode-down on a conveyor belt. It is not a choreographed manipulation showcase. It is the kind of dull, high-volume, error-intolerant work that defines real logistics operations — and the kind of work where a 1 percent failure rate compounds into an operational disaster over a full shift.
Bob, Frank, and Gary — One Fleet, One Policy
The three units were nicknamed Bob, Frank, and Gary by viewers of Figure's livestream, and Figure leaned into it by adding visible name tags after the engagement spiked. The naming is trivial; the architecture underneath is not. All three robots ran the same Helix-02 policy. This is a fleet running one shared neural network, not three bespoke demo rigs each hand-tuned for a single camera angle. Fleet homogeneity is a deployment property, not a demo property — it is what lets an operator buy ten robots and expect ten identical behaviors.

Self-Recovery and Fleet Self-Maintenance
Two details in the run matter more than the headline duration. First, when a robot got stuck or hit an unfamiliar situation, Helix triggered an automatic reset — the robot recovered itself without a teleoperator dialing in. Second, robots autonomously left the line for maintenance while another unit took over the workload. That is fleet-level orchestration: the system manages its own uptime. A single robot running for 24 hours is a hardware endurance claim. A fleet that self-recovers and self-maintains across 24-plus hours is an operations claim, and operations claims are what warehouse buyers actually purchase.
Helix-02: The Unified VLA Doing the Work
Helix-02 is Figure's second-generation vision-language-action model, and the strategic story is in the word "unified." A vision-language-action (VLA) model maps raw perception and a task instruction directly to motor actions. The architectural choice that distinguishes Helix-02 is that vision, tactile sensing, proprioception, and whole-body control are fused into one network rather than stitched together from separate perception, planning, and control modules. Figure's framing — "reasoning directly from camera pixels" — is the tell: there is no intermediate hand-engineered representation between what the robot sees and what its body does.
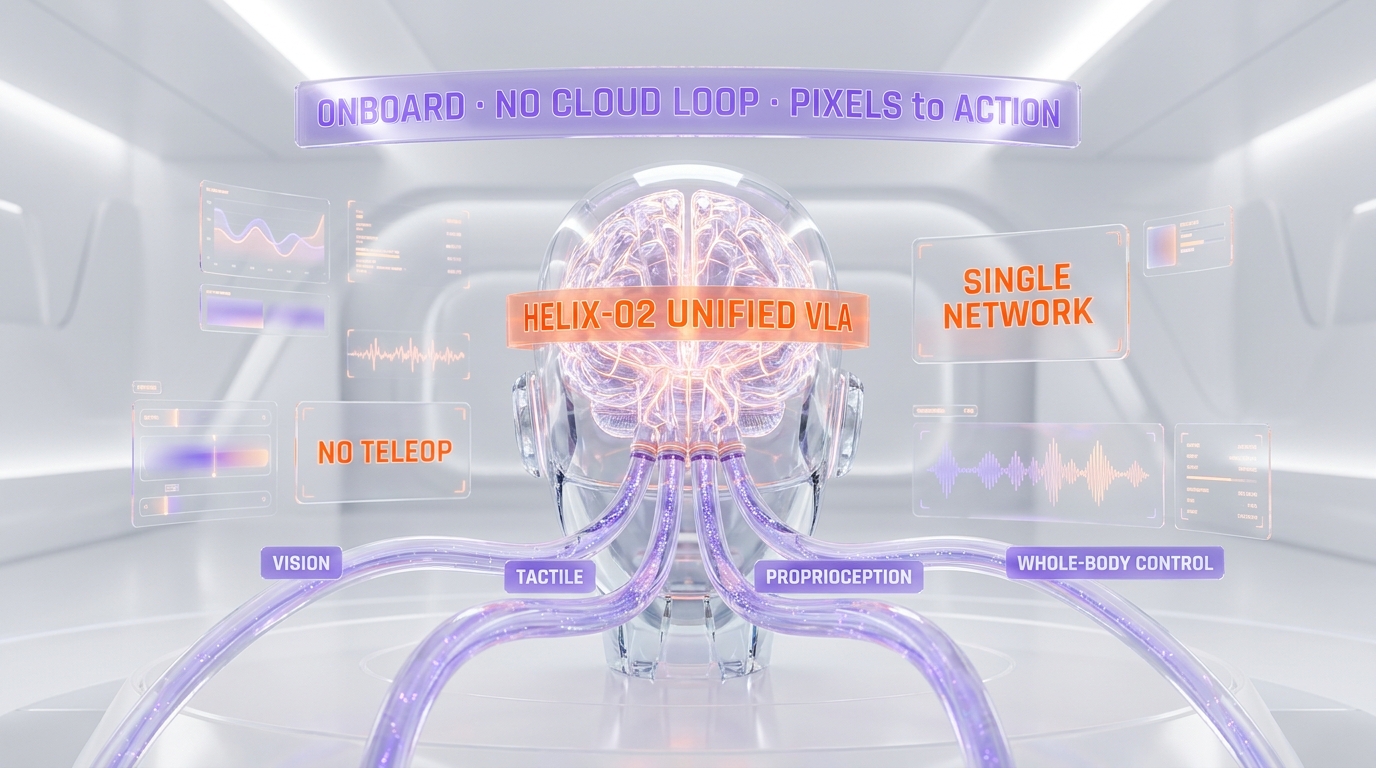
Why "Unified" Is the Strategic Move
The dominant alternative architecture splits the stack: a cloud reasoning model for high-level planning, a separate VLA for motor control, and classical controllers underneath. Google DeepMind's approach with Gemini Robotics is the clearest example of the split-stack philosophy — a reasoning model and a VLA designed to work as a pair, which we covered in our analysis of Gemini Robotics-ER 1.6 and Google DeepMind's embodied reasoning model. Both philosophies are defensible. The split-stack bet is that specialization and a cloud brain win on reasoning quality. The unified bet — Figure's bet — is that a single onboard network removes the latency and integration seams that kill long-horizon reliability.
The May run is evidence, not proof, for the unified thesis. A unified onboard policy has no cloud round-trip in the motor loop, which is exactly the property you want for a 24-hour run where a network hiccup cannot be allowed to stall a robot mid-pick. It is too early to declare the architecture debate settled — but it is not too early to note that the longest credible no-teleop humanoid run to date came from the unified-onboard camp.
Tactile and Proprioception in the Loop
Most published humanoid demos lean heavily on vision and treat touch as an afterthought. Helix-02 folding tactile sensing and proprioception — the robot's internal sense of its own joint positions and forces — into the same network is what makes sustained physical manipulation plausible. Picking a parcel and placing it barcode-down is a contact-rich task. Vision tells the robot where the parcel is; touch and proprioception tell it whether it actually has the parcel and how to place it without dropping or jamming. A vision-only policy degrades fast on contact-rich work over thousands of repetitions. A multi-modal policy is what you would design if your goal were a full shift, not a clip.
The Human-Parity Claim, Measured Honestly
"Around human parity" is a strong phrase, so it deserves a careful read. The specific claim is narrow and defensible: humans average roughly 3 seconds per parcel on this sorting task, and Figure 03 is now operating at approximately that rate. That is a throughput-parity claim on one well-defined task, not a claim that the robot matches a human worker across the full range of warehouse labor. We separate the two deliberately, because conflating task-throughput parity with general labor parity is the single most common way humanoid coverage overstates the state of the field.

Parity on Throughput, Not Generality
On the metric that matters for this workload — parcels sorted per unit time — the run supports the parity claim. Roughly 28,000 parcels across a 24-hour-plus window at about 3 seconds each is internally consistent with a fleet operating at human throughput. What the run does not establish is generality: the ability to switch tasks, handle novel parcel types far outside the training distribution, or operate in an unstructured environment. Parity here is bounded and honest when stated as task-throughput parity. The strategic significance is that throughput parity on a real logistics task is the threshold at which the unit economics of a humanoid start to compete with a human shift — and that is the number a procurement team runs in a spreadsheet.
The Numbers That Anchor the Claim
Three figures anchor everything: 24-hours-plus of confirmed continuous autonomy, more than 28,000 parcels sorted, and roughly 3 seconds per parcel at human parity. Each is individually verifiable from the reporting, and together they describe a run that is qualitatively different from a demo. A demo optimizes for the best 90 seconds. This run optimizes for the worst hour — the hour where fatigue, edge cases, and compounding errors normally surface. Surviving the worst hour, repeatedly, is the entire game.
The Demo-to-Deployment Inflection
The reason this run deserves a strategic frame rather than a news blurb is that it sits on the exact line the embodied-AI industry has not been able to cross. Demos prove capability under ideal conditions. Deployments require reliability under sustained, adversarial, real-world conditions. The metrics that separate the two are horizon length, intervention rate, and self-recovery — and this run moves all three in the deployment direction simultaneously.

What Changed Strategically
Three strategic shifts are visible in this run. First, the proof point moved from "can it do the task once" to "can it do the task ten thousand times without a human." Second, the unit of demonstration moved from a single robot to a self-orchestrating fleet. Third, the benchmark moved from "impressive" to "economically legible" — throughput parity on a real task is a number a CFO can model, not a video a marketing team can clip. None of this means general-purpose humanoid labor is solved. It means the goalposts for what counts as a credible humanoid claim just moved, and competitors will be measured against a 24-hour no-teleop bar from now on.
The Compute and Capital Backdrop
Embodied AI does not happen in a vacuum — it rides the same compute and capital wave as frontier language models. Training a unified VLA at this reliability level is a serious compute commitment, and the infrastructure economics behind it connect directly to the broader buildout we analyzed in NVIDIA's Vera Rubin and the trillion-dollar order backlog and the capital-structure questions raised in NVIDIA's $40 billion equity bets and the circular-financing critique. The same dynamic that funds 10-gigawatt frontier-model campuses — which we covered in Anthropic's 10-gigawatt compute empire — is what makes a unified embodied policy trainable to shift-length reliability. Robotics is no longer a separate vertical from the AI capital cycle; it is a downstream consumer of it.
How Figure's Approach Compares to the Field
The humanoid field has roughly split into three architectural and go-to-market camps, and the May run sharpens the contrast between them.
The Unified-Onboard Camp (Figure)
Figure runs Helix-02 as a vertically integrated, onboard, unified VLA trained on data from its own Figure 03 platform. The advantage is tight integration and no cloud dependency in the control loop. The risk is that vertical integration is expensive and slow to generalize beyond the platform it was trained on. The May run is the strongest data point yet that the integration discipline pays off on reliability.
The Split-Stack Camp (Google DeepMind, NVIDIA)
Google DeepMind's Gemini Robotics pairs a cloud reasoning model with a VLA, and NVIDIA's Isaac GR00T targets on-device inference as a foundation model partners can adopt across many robot bodies. The advantage is reach and reasoning quality; the risk is integration seams and, for cloud-served reasoning, latency in any loop that touches the network. For builders evaluating the underlying models, our coverage of Gemini 3.1 Pro and Claude tracks the frontier reasoning layer that increasingly feeds robotic planning stacks.
Why the Comparison Is Not Yet Decidable
It would be premature to crown a winner. Figure has the longest credible no-teleop run; the split-stack camp has broader model reach and a partner ecosystem spanning many robot bodies. The honest strategic read is that the unified camp just won the reliability round on the public record, and the split-stack camp still owns the reasoning-generality round. The next decidable question is whether a unified onboard policy can generalize across tasks as well as it sustains one — and Figure has not yet shown that publicly.
What This Run Does Not Prove
Intellectual honesty requires stating the limits as clearly as the result. This run does not prove general-purpose humanoid labor. It is one task — barcode-down parcel placement — in a structured environment with a conveyor belt and a controlled parcel mix. It does not establish performance on novel objects far outside the training distribution, multi-task switching within a shift, operation in an unstructured human environment, or safety certification for shared human-robot workspaces. It also does not, on the public record alone, settle the 30-to-50-hour question; 24-hours-plus is the corroborated floor.
What Would Strengthen or Weaken the Thesis
The thesis — that this is the demo-to-deployment inflection for humanoids — would strengthen if Figure publishes intervention-rate data, runs the same fleet on a different task without retraining, or sustains a verified multi-day run with an independent observer. It would weaken if the throughput parity holds only on a narrow parcel mix, if intervention rates turn out to be non-trivial once disclosed, or if the run proves hard to reproduce outside Figure's own facility. A strategic read names its own falsification conditions; this one has clear ones.
The Economic Stakes Behind a 3-Second Parcel
The reason throughput parity is the headline number is that it is the number that flips a spreadsheet. Warehouse and logistics labor is one of the largest, most automatable labor pools on earth, and it is structurally short-handed in many markets. A humanoid that hits human throughput on a real task, runs unattended for a full shift, and self-maintains is not a research curiosity — it is a unit-economics argument. The strategic significance of the May run is not the robot. It is that the robot's performance is now expressible in the language operations executives use: parcels per hour, intervention rate, uptime, and cost per shift.
Why This Is a Positioning Event, Not Just a Tech Event
Figure timed and staged this as a positioning event. Extending an 8-hour test live, leaning into the Bob-Frank-Gary naming, and broadcasting the run are narrative choices that frame Figure as the company that crossed the reliability line first. Positioning is legitimate strategy, and noting it is not a criticism — it is a strategic observation. The competitive effect is concrete: every humanoid company will now be asked, "what is your longest no-teleop run, and what is your intervention rate?" That question did not have a sharp public benchmark before May 13. It does now.
What to Watch Next
The next twelve months in embodied AI will be measured against the bar this run set. Three signals will tell us whether the inflection is real or a single impressive event.
Signal One: Intervention-Rate Disclosure
The single most informative number Figure could publish is the intervention rate — how many human-free hours per intervention across the full run. Duration without intervention rate is a partial picture. If Figure discloses a low intervention rate with third-party verification, the deployment thesis hardens considerably.
Signal Two: Task Generalization
The unified-VLA thesis lives or dies on generalization. If the same Helix-02 fleet can run a materially different warehouse task with minimal retraining, that is the strongest possible validation. If each new task requires a bespoke training cycle, the economics look very different.
Signal Three: Competitive Response
Watch how the split-stack camp responds. If Google DeepMind, NVIDIA's partners, or other humanoid players publish their own long-horizon no-teleop runs within the next two quarters, the field is converging on deployment-grade reliability. If they do not, Figure's May run looks like a genuine lead rather than a one-off.
The Strategic Bottom Line
The Figure Helix-02 run is the most strategically significant humanoid event of 2026 so far, and the reason is structural rather than spectacular. It is not that the robots are impressive — humanoid robots have been impressive for years. It is that the demonstration finally used the metrics that matter for deployment: long horizon, zero teleoperation, fleet-level self-recovery, and throughput parity on a real task. Those are the numbers a logistics operator runs before signing a purchase order, and they are the numbers that move embodied AI from the demo column to the deployment column. The architecture debate between unified-onboard and split-stack is not over, the generalization question is wide open, and the 30-to-50-hour figure is a CEO trajectory rather than a settled record. But the bar moved on May 13, 2026, and every humanoid company will now be measured against a 24-hour no-teleop run at human parity. That is the inflection, stated without overreach.
Frequently Asked Questions
What exactly did Figure demonstrate on May 13-14, 2026?
Figure ran three Figure 03 humanoid robots — nicknamed Bob, Frank, and Gary — through a continuous parcel-sorting shift that crossed 24 hours of uninterrupted autonomous operation with zero failures and no teleoperation. The fleet sorted more than 28,000 parcels at roughly 3 seconds per parcel, all under the control of the Helix-02 neural network running entirely onboard the robots.
Was the run really 50 hours long?
The corroborated, confirmed figure is more than 24 hours of continuous autonomous operation, with the run still progressing toward 30 hours at the time of reporting on May 14, 2026. CEO Brett Adcock signaled a longer target, with figures up to 50 hours circulating from Figure's own messaging. We treat 24-hours-plus as the hard verified number and the 30-to-50-hour band as the CEO-stated live trajectory rather than a settled record.
What is Helix-02?
Helix-02 is Figure's second-generation vision-language-action (VLA) neural network. It fuses camera vision, tactile sensing, proprioception, and whole-body control into a single unified network that runs entirely onboard the robot, with no cloud round-trip in the motor control loop. Figure describes it as "reasoning directly from camera pixels," meaning there is no hand-engineered representation between perception and action.
Why does "no teleoperation" matter so much?
Many humanoid robot demos are partially or fully teleoperated, with a human remotely controlling the robot. A run with zero teleoperation across 24-plus hours means the robot's own neural network handled every pick, place, edge case, and error recovery. No-teleop long-horizon operation is the property that separates a demo from a deployable system, because real warehouse labor cannot have a human in the loop for every robot.
What does "human parity" mean here?
The specific claim is narrow and defensible: humans average roughly 3 seconds per parcel on this sorting task, and Figure 03 now operates at approximately that rate. This is throughput parity on one well-defined task — not a claim that the robot matches a human worker across the full range of warehouse labor. Throughput parity on a real logistics task is the threshold at which humanoid unit economics start to compete with a human shift.
How does Helix-02 differ from Google DeepMind's Gemini Robotics?
Helix-02 is a unified onboard VLA — vision, touch, proprioception, and control fused into one network running on the robot. Google DeepMind's Gemini Robotics uses a split-stack philosophy: a cloud reasoning model paired with a separate VLA for motor control. The unified bet removes latency and integration seams for long-horizon reliability; the split-stack bet prioritizes reasoning quality and broad model reach across many robot bodies. The architecture debate is not yet settled.
What happens when a Figure 03 robot gets stuck?
When a robot gets stuck or encounters an unfamiliar situation, Helix triggers an automatic reset and the robot recovers itself without a teleoperator intervening. Additionally, robots autonomously leave the line for maintenance while another unit takes over the workload. This fleet-level self-recovery and self-maintenance is an operations property, not just a hardware endurance claim.
What did this run NOT prove?
It did not prove general-purpose humanoid labor. It is one task — barcode-down parcel placement — in a structured environment with a controlled parcel mix. It does not establish performance on novel objects far outside the training distribution, multi-task switching within a shift, operation in unstructured human environments, or safety certification for shared human-robot workspaces. And on the public record alone, 24-hours-plus is the corroborated floor, not a settled 50-hour record.
Why is this called a demo-to-deployment inflection?
Demos prove capability under ideal conditions; deployments require reliability under sustained, real-world conditions. The metrics that separate them are horizon length, intervention rate, and self-recovery. This run moved all three in the deployment direction at once: long horizon, zero teleoperation, and fleet-level self-recovery, with throughput parity on a real task. It does not solve general-purpose humanoid labor, but it moved the goalposts for what counts as a credible humanoid claim.
Who is Brett Adcock and what did he say?
Brett Adcock is the CEO of Figure AI. He stated that the original goal was an 8-hour run, and "after zero failures yesterday, we decided to keep going," which is how an 8-hour test became a 24-hour-plus run extended live. He also characterized Figure 03's roughly 3-seconds-per-parcel pace as "around human parity," and signaled the team would continue pushing the run duration.
How does this connect to the broader AI compute buildout?
Training a unified VLA to shift-length reliability is a serious compute commitment. Embodied AI rides the same compute and capital cycle as frontier language models — the infrastructure economics behind NVIDIA's order backlog and frontier-model compute campuses are what make a unified embodied policy trainable to this reliability level. Robotics is now a downstream consumer of the broader AI capital cycle, not a separate vertical.
What should I watch next to know if this inflection is real?
Three signals: first, whether Figure publishes a verified intervention rate (human-free hours per intervention) with third-party verification; second, whether the same Helix-02 fleet can run a materially different warehouse task with minimal retraining (the generalization test for the unified-VLA thesis); and third, whether the split-stack camp publishes its own long-horizon no-teleop runs within two quarters, which would indicate field-wide convergence on deployment-grade reliability.
Sources: Interesting Engineering — Figure AI humanoids run autonomously for 24+ hours, corroborated by Bloomberg and TechTimes reporting (May 13-14, 2026). ThePlanetTools.ai has no affiliate relationship with Figure AI; this is independent editorial analysis.



