
xAI launched Grok Build on May 14-15, 2026, a terminal-native coding agent that puts the company directly into competition with Claude Code, OpenAI Codex, and Google Antigravity. Grok Build is available in closed beta exclusively to SuperGrok Heavy subscribers at $300 per month, runs on the grok-code-fast-1 model with a 256K-token context window, and ships with eight parallel subagents, git worktree and headless modes, an Agent Client Protocol bridge, and an "Arena Mode" self-evaluation harness. The 256K context window trails the 1M-plus windows on Claude Opus and GPT-5.4, and Elon Musk publicly conceded that xAI had fallen behind on coding — making Grok Build the catch-up move that turns a three-way coding-agent race into a four-way one.
What Happened
On May 14, 2026, with broader coverage landing May 15, xAI introduced Grok Build, its first dedicated coding agent designed to run inside the terminal rather than inside a chat window or a browser tab. Engadget and DevOps.com reported the launch within hours of each other, framing it as xAI's formal entry into the agentic-coding category that Anthropic opened with Claude Code and that OpenAI extended with the Codex CLI.
Grok Build is not a general chatbot feature bolted onto Grok. It is a command-line program that reads a repository, plans a multi-step change, edits files, runs commands, and iterates against test output — the same execution loop that defines Claude Code and OpenAI Codex. The headline architectural claims are eight parallel subagents that fan work out across a task graph, git worktree isolation so concurrent agents do not collide on the same branch, a headless mode for non-interactive automation, and support for the Agent Client Protocol so the agent can be driven from external editors and orchestration layers.
The most distinctive feature in the announcement is "Arena Mode," an auto-evaluation harness in which Grok Build runs multiple candidate solutions against a task and scores them against each other before surfacing a winner. xAI is positioning Arena Mode as a quality mechanism that compensates for a smaller model by spending more inference on self-competition.
The Confirmed Specifications
The model behind Grok Build is grok-code-fast-1, a coding-tuned model with a 256K-token context window. That number is the single most important fact in the launch, and we will return to it repeatedly: 256K is a quarter of the 1M-plus context windows that Claude Opus and GPT-5.4 expose to their respective coding agents in May 2026. For large monorepos and long agent sessions, context budget is the constraint that determines how much of a codebase an agent can hold in working memory before it has to summarize, retrieve, or forget.
Beta access is the second defining fact. Grok Build is restricted to SuperGrok Heavy, xAI's top consumer subscription tier at $300 per month. There is no free tier, no standard SuperGrok access, and no published API-only path at launch. That pricing gate is materially higher than the entry point for either of the two incumbents it is chasing.
Musk Conceded xAI Was Behind
The launch did not arrive with the usual frontier-lab triumphalism. Elon Musk publicly acknowledged that xAI had been behind on coding — an unusually direct concession from a company that typically frames every release as a leap. Grok Build is best read in that light: not as a category-defining product, but as a catch-up release engineered to get xAI onto the board in a race it had been watching from the sideline.
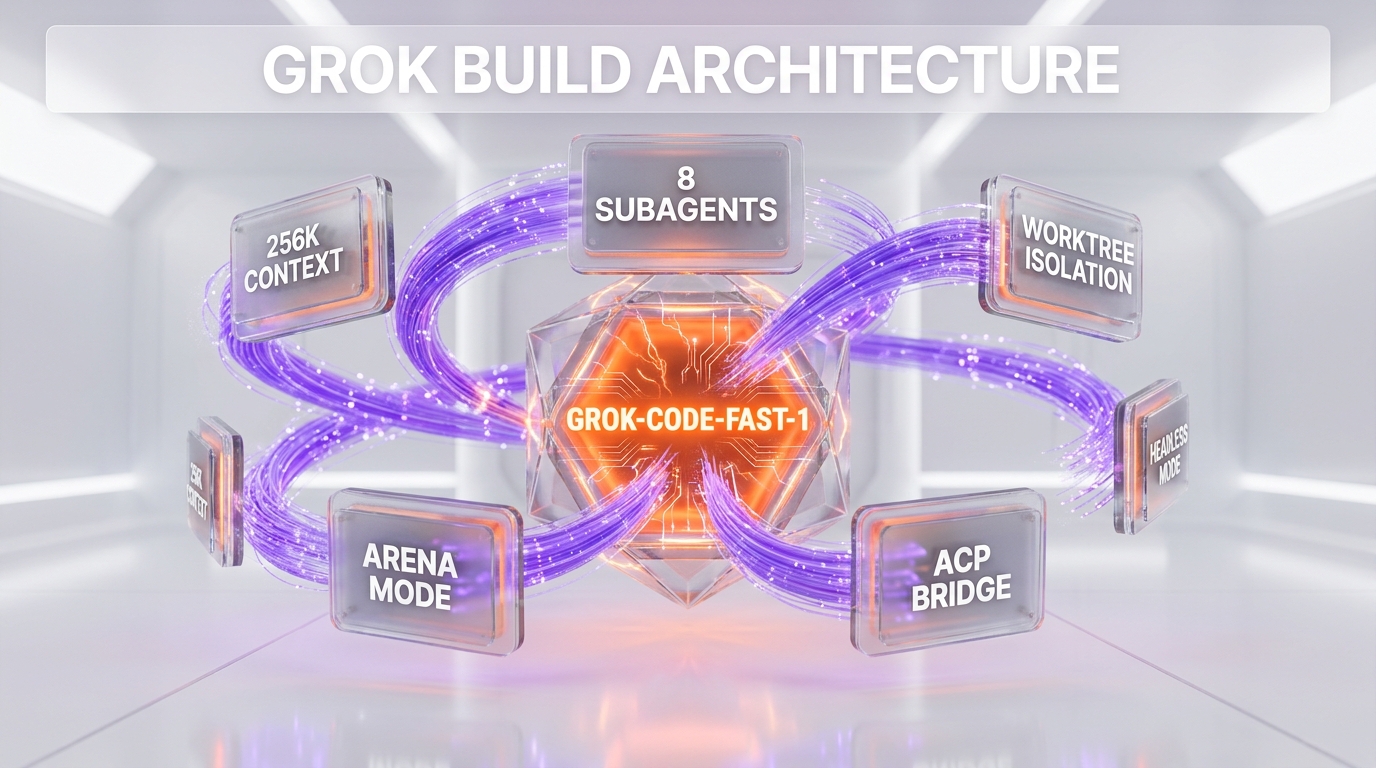
The Grok Build Architecture, Decoded
Strip away the launch language and Grok Build is a fairly conventional agentic-coding stack with one genuinely differentiated component. The conventional parts are the parts that matter for parity; the differentiated part is the bet xAI is making to stand out.
Eight Parallel Subagents
Grok Build fans a task out across up to eight subagents running concurrently. This is the same architectural pattern that Claude Code uses for its subagent delegation and that the OpenAI Codex CLI uses for parallel task execution — a head-to-head we break down in our Claude Code vs OpenAI Codex comparison. The premise is that a complex change — refactor a module, update its call sites, fix the tests, update the docs — decomposes into a graph of subtasks that can run in parallel rather than in a single serial transcript. Eight is a reasonable fan-out width; it is not a differentiator on its own, because the incumbents already do this.
Git Worktree Isolation
Running eight agents against one repository creates a collision problem: two agents editing the same files on the same branch corrupt each other's work. Grok Build's answer is git worktree isolation, where each concurrent agent operates in its own worktree so edits do not interleave destructively. This is table stakes for safe parallel execution, and the fact that xAI built it in at launch indicates the parallel-subagent claim is more than marketing — you do not need worktree isolation unless agents are genuinely running concurrently.
Headless Mode and the Agent Client Protocol
Headless mode lets Grok Build run non-interactively — in CI pipelines, in scheduled jobs, in scripts — without a human at a prompt. Agent Client Protocol support lets external editors and orchestration layers drive the agent through a standardized interface rather than scraping a terminal. Together these two features signal that xAI is targeting the same automation-and-integration surface that Claude Code and the OpenAI Codex CLI compete on — the same managed cloud-environment direction we covered in Cursor's cloud agent environments launch — not just an interactive REPL for individual developers.
Arena Mode — The Real Bet
Arena Mode is the feature that does not have a clean one-to-one analog in the incumbents. Grok Build generates multiple candidate solutions to a task, runs them, and scores them against each other in an internal tournament before presenting a result. The strategic logic is explicit: grok-code-fast-1 is a smaller, faster model with a tighter context window, so xAI is trading inference cost for quality by having the model compete against itself. Whether that trade pays off depends entirely on how good grok-code-fast-1's self-scoring is — a model that cannot reliably tell its good output from its bad output does not get better by generating more of both. Arena Mode is the most interesting thing in this launch and also the thing most dependent on benchmarks xAI has not yet published.

Grok Build vs Claude Code vs OpenAI Codex
The honest comparison at launch is structurally limited: xAI has published architecture and pricing but not the benchmark numbers that would let anyone rank coding quality. What can be compared today is the spec sheet and the access model, and on those axes Grok Build enters as the challenger, not the favorite.
Context Window — The Clearest Gap
This is a factual gap, not a quality judgment. Grok Build's grok-code-fast-1 exposes a 256K-token context window. Claude Code, running on Claude Opus, and the OpenAI Codex CLI, running on GPT-5.4, both operate with 1M-plus token context windows in May 2026. For a single-file change the difference is irrelevant. For a long agent session across a large monorepo, context budget is the variable that determines how much of the codebase the agent can keep in working memory before it has to compress or retrieve. A 256K window is roughly a quarter of a 1M window. That does not make Grok Build bad — many real tasks fit comfortably in 256K — but it does mean Grok Build starts the race with less working memory than the two agents it is chasing, and that constraint is structural rather than a tuning detail.
Access Model and Pricing
Claude Code is reachable through Anthropic's standard paid plans and API. The OpenAI Codex CLI is reachable through ChatGPT paid tiers and the OpenAI API. Grok Build, at launch, is reachable only through SuperGrok Heavy at $300 per month, with no free tier and no published standalone API path. For a developer evaluating coding agents on cost-to-try, Grok Build has the highest entry barrier of the three by a wide margin. That is a positioning choice — it gates the beta to xAI's highest-commitment users — but it is also a friction point that the incumbents do not impose on a developer who just wants to run the agent once against a real repository.
Feature Parity vs Differentiation
On parallel subagents, worktree isolation, headless execution, and editor protocol support, Grok Build is at rough feature parity with the incumbents — it does what they do. Arena Mode is the one place it does something they do not productize the same way. So the competitive question reduces to a single uncertainty: does grok-code-fast-1, amplified by Arena Mode self-competition, produce code quality competitive with Claude Opus inside Claude Code and GPT-5.4 inside the Codex CLI? xAI has not published the numbers that would answer that. Until it does, the responsible read is that Grok Build has achieved architectural parity and made one interesting quality bet, with the outcome of that bet unproven.
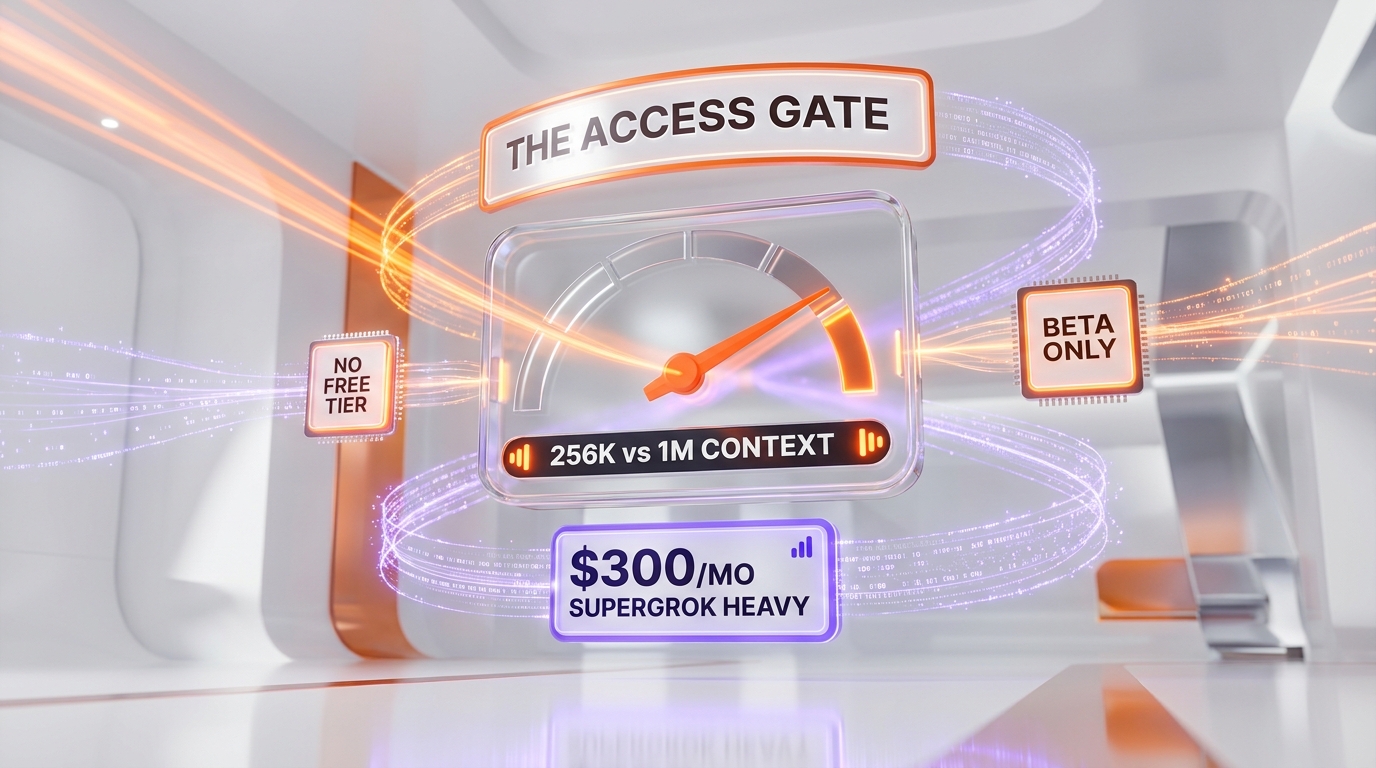
The $300 Gate and the 256K Constraint
Two numbers frame how Grok Build will be received in its first weeks: the $300 per month access price and the 256K context window. Both are deliberate, and both shape who can realistically evaluate the product and what they can do with it.
Why $300 per Month Is a Strategic Choice, Not an Accident
Gating a coding-agent beta to a $300 per month tier does two things for xAI. It limits beta load to a self-selected set of high-commitment users who will tolerate rough edges, and it signals positioning — Grok Build is being introduced as a premium capability for users already paying for xAI's most expensive plan, not as a growth-driver acquired through a free trial. xAI has been actively reshaping its consumer tiers, as we documented when xAI throttled the $30 SuperGrok tier. The cost is reach. Anthropic and OpenAI both let a developer run their coding agents at a far lower commitment, which means the population that will form first impressions of Claude Code and OpenAI Codex is much larger than the population that will form first impressions of Grok Build. In a category where developer word-of-mouth drives adoption, a high access gate slows the feedback and advocacy loop that the incumbents already have running.
What 256K Actually Costs You in Practice
Context window is not an abstract spec — it maps to concrete agent behavior. Inside a coding agent, the context budget has to hold the system prompt, the task description, the relevant source files, the tool-call history, the test output, and the running plan. On a focused change in a moderately sized service, 256K is comfortably enough. On a sprawling monorepo where the agent needs to reason across many files and a long action history, a 256K window forces earlier and more aggressive context compression — summarizing files it has already seen, dropping older tool output, retrieving on demand instead of holding state. A 1M-plus window pushes that compression boundary much further out. The practical consequence is that Grok Build will tend to feel comparable on small-to-medium tasks and comparatively more constrained on large, long-horizon tasks, relative to Claude Code and OpenAI Codex. That is the trade xAI made by shipping on grok-code-fast-1, and Arena Mode is the lever it is pulling to try to offset it.
The Speed Argument
grok-code-fast-1 is named for speed, and that is the other half of the trade. A faster model with a smaller window can run more iterations per unit of wall-clock time, which is exactly what Arena Mode needs — it spends extra inference generating and scoring candidates. xAI's implicit thesis is that speed plus self-competition can substitute for raw model scale and context size on a meaningful share of coding tasks. It is a coherent thesis. It is also unproven at launch, because the benchmark numbers that would validate it are not in the announcement.

Why This Matters: The Race Goes From Three to Four
The significance of Grok Build is less about the product specifications and more about the market structure. Until May 14, 2026, the serious agentic-coding race had three named participants with shipped, terminal-native agents. Grok Build makes it four.
The Field as of May 2026
Anthropic's Claude Code is the category opener and the agent most developers benchmark against. The OpenAI Codex CLI is the direct counter from the lab with the largest distribution. Google's Gemini-powered Antigravity is the hyperscaler entrant with cloud-platform gravity behind it. Grok Build is now the fourth — the entrant whose parent company openly admitted it was late. Four well-resourced labs now treat the terminal coding agent as a category they cannot afford to cede, which is itself the most important signal in this launch: agentic coding has moved from a frontier experiment to a contested core product line. The pressure is not limited to the labs — IDE-first tools like Cursor are racing the same direction, a dynamic visible in our Cursor vs Zed comparison.
What xAI Brings That the Others Do Not
xAI's structural advantage is distribution-adjacent rather than technical. Grok is embedded in X, and xAI now sits inside the consolidated Musk operating structure alongside SpaceX — the xAI-SpaceX merger that created a combined entity whose enterprise traction we have also tracked through xAI's Wall Street pilot push. The hypothesis xAI is testing is that a coding agent attached to a large existing consumer surface and a deep capital base can close a technical gap faster than a standalone product would. Whether that converts into developer adoption is an open question — developers choose coding agents on output quality and workflow fit, not on the size of the parent company's social platform — but it is the lever xAI has that Anthropic and a standalone OpenAI Codex do not.
The Catch-Up Pattern
Grok Build fits a recognizable pattern in the 2026 AI race: a frontier lab concedes it is behind in a category, ships a parity-level product fast to get on the board, and bets that iteration speed plus distribution can close the gap before the category consolidates. The pattern sometimes works and sometimes does not. What makes this instance notable is the unusual candor — Musk's public acknowledgment that xAI was behind reframes Grok Build from a victory lap into a starting gun.
What Grok Build Means for Developers Right Now
For a developer deciding what to actually use this week, the practical guidance is straightforward. If you are not a SuperGrok Heavy subscriber, Grok Build is not a near-term option — the $300 per month gate makes casual evaluation impractical, and Claude Code or the OpenAI Codex CLI remain the lower-friction ways to run an agentic-coding workflow today. If you are a SuperGrok Heavy subscriber, Grok Build is worth a hands-on trial specifically on the kind of tasks where Arena Mode's self-competition might pay off — well-scoped, testable changes where generating and scoring multiple candidates is cheap relative to getting the change right.
The honest summary for everyone else is that Grok Build is a credible architectural entry with one genuinely interesting idea and one structural disadvantage, launched by a company that admitted it was late. It is not yet a reason to switch off Claude Code or OpenAI Codex, and xAI has not published the data that would make it one.
What to Watch Next
Three things will determine whether Grok Build becomes a real fourth competitor or a footnote. First, benchmark disclosure: xAI needs to publish grok-code-fast-1 and Arena Mode results on standard coding evaluations against Claude Opus and GPT-5.4 — until it does, the quality question is unanswered. Second, access expansion: a broader beta beyond the $300 per month tier, and especially a standalone API path, would dramatically widen the population that can evaluate and advocate for the product. Third, context-window roadmap: whether xAI ships a larger-context successor to grok-code-fast-1 will signal how seriously it takes the long-horizon, large-monorepo use case that the 256K window currently constrains. We will track each of these as xAI's coding-agent strategy develops.
Frequently Asked Questions
What is Grok Build?
Grok Build is xAI's first dedicated coding agent, launched May 14-15, 2026. It is a terminal-native command-line agent that reads a repository, plans multi-step changes, edits files, runs commands, and iterates against test output — the same execution loop that defines Claude Code and the OpenAI Codex CLI. It runs on the grok-code-fast-1 model with a 256K-token context window and ships with eight parallel subagents, git worktree isolation, headless mode, Agent Client Protocol support, and an "Arena Mode" self-evaluation harness.
How much does Grok Build cost and how do I get access?
At launch, Grok Build is available in closed beta exclusively to SuperGrok Heavy subscribers, xAI's top consumer tier at $300 per month. There is no free tier, no standard SuperGrok access path, and no published standalone API path at launch. This makes Grok Build's entry barrier materially higher than Claude Code or the OpenAI Codex CLI, both of which a developer can run at a far lower commitment.
How does Grok Build's context window compare to Claude Code and OpenAI Codex?
Grok Build's grok-code-fast-1 model exposes a 256K-token context window. Claude Code, running on Claude Opus, and the OpenAI Codex CLI, running on GPT-5.4, both operate with 1M-plus token context windows in May 2026. A 256K window is roughly a quarter of a 1M window. For small-to-medium changes the difference is negligible; for long agent sessions across large monorepos, the smaller window forces earlier and more aggressive context compression, which is a structural constraint relative to the two incumbents.
What is Arena Mode?
Arena Mode is Grok Build's signature feature and the one without a clean one-to-one analog in the incumbents. The agent generates multiple candidate solutions to a task, runs them, and scores them against each other in an internal tournament before surfacing a result. The strategic logic is that grok-code-fast-1 is a smaller, faster model, so xAI trades extra inference cost for quality by having the model compete against itself. Its effectiveness depends on how reliably grok-code-fast-1 can score its own output, which xAI has not yet validated with published benchmarks.
Is Grok Build better than Claude Code?
That cannot be answered responsibly at launch because xAI has not published benchmark results. On architecture, Grok Build is at rough parity with Claude Code on parallel subagents, worktree isolation, headless execution, and editor protocol support. On confirmed specifications, it trails: a 256K context window against Claude Code's 1M-plus on Claude Opus, and a $300 per month access gate against Claude Code's lower-commitment availability. Arena Mode is its one differentiated bet. Until xAI releases coding-quality numbers, the responsible read is that Grok Build has achieved architectural parity with an unproven quality bet, not that it surpasses Claude Code.
Is Grok Build better than OpenAI Codex?
Same answer structure: unproven at launch. The OpenAI Codex CLI runs on GPT-5.4 with a 1M-plus context window and is accessible through ChatGPT paid tiers and the OpenAI API at a far lower entry barrier than Grok Build's $300 per month SuperGrok Heavy gate. Feature-wise the two are roughly comparable on parallel execution, headless mode, and protocol integration. Whether grok-code-fast-1 plus Arena Mode produces output competitive with GPT-5.4 inside the Codex CLI is the open question xAI has not yet answered with data.
Why did xAI launch Grok Build now?
Elon Musk publicly conceded that xAI had fallen behind on coding. Grok Build is the catch-up move: a parity-level product shipped quickly to get xAI onto the board in a category that Anthropic opened with Claude Code, OpenAI extended with the Codex CLI, and Google entered with Gemini-powered Antigravity. The launch turns a three-way agentic-coding race into a four-way one and reframes Grok Build as a starting gun rather than a victory lap.
Who are the four players in the coding-agent race as of May 2026?
As of May 14-15, 2026, the serious agentic-coding race has four named participants with shipped, terminal-native agents: Anthropic's Claude Code (the category opener), the OpenAI Codex CLI (the direct counter from the largest-distribution lab), Google's Gemini-powered Antigravity (the hyperscaler entrant), and now xAI's Grok Build (the entrant whose parent company openly admitted it was late). Four well-resourced labs now treat the terminal coding agent as a contested core product line.
What are eight parallel subagents and worktree isolation?
Grok Build can fan a complex task out across up to eight subagents running concurrently — for example, refactor a module, update its call sites, fix the tests, and update the docs as parallel subtasks rather than one serial transcript. Git worktree isolation gives each concurrent agent its own worktree so simultaneous edits do not collide destructively on the same branch. Both patterns are also used by Claude Code and the OpenAI Codex CLI, so they represent parity rather than differentiation.
What does the 256K context window actually cost in practice?
Inside a coding agent the context budget holds the system prompt, task description, relevant source files, tool-call history, test output, and the running plan. On a focused change in a moderately sized service, 256K is comfortably sufficient. On a large monorepo with a long action history, a 256K window forces earlier context compression — summarizing already-seen files, dropping older tool output, retrieving on demand. A 1M-plus window pushes that boundary much further out, so Grok Build will tend to feel comparable on small-to-medium tasks and more constrained on large, long-horizon ones.
Should developers switch to Grok Build right now?
For developers who are not SuperGrok Heavy subscribers, Grok Build is not a practical near-term option — the $300 per month gate makes casual evaluation impractical, and Claude Code or the OpenAI Codex CLI remain lower-friction ways to run an agentic-coding workflow. For SuperGrok Heavy subscribers, Grok Build is worth a hands-on trial specifically on well-scoped, testable changes where Arena Mode's self-competition can pay off. It is not yet a reason to switch off Claude Code or OpenAI Codex, and xAI has not published the data that would make it one.
What should I watch next for Grok Build?
Three signals matter. First, benchmark disclosure — xAI needs to publish grok-code-fast-1 and Arena Mode results on standard coding evaluations against Claude Opus and GPT-5.4. Second, access expansion — a broader beta beyond the $300 per month tier and especially a standalone API path would widen the population that can evaluate and advocate for the product. Third, context-window roadmap — a larger-context successor to grok-code-fast-1 would signal how seriously xAI takes the large-monorepo use case the 256K window currently constrains.
Sources: Engadget — xAI coding agent Grok Build, DevOps.com — xAI enters the coding agent race with Grok Build. This is independent editorial analysis; ThePlanetTools.ai has no affiliate relationship with xAI, Anthropic, or OpenAI.



