On April 21, 2026, Reuters obtained an internal Meta Superintelligence Labs memo revealing the Model Capability Initiative (MCI): a surveillance tool installed on every US-based Meta employee computer that records keystrokes, mouse movements, button clicks, dropdown navigation, keyboard shortcuts and periodic screenshots. The goal is not performance review. The goal is training Meta's autonomous AI agents to behave like humans navigating software. The leak hit TechCrunch, Gizmodo, Slashdot, Futurism, Fortune, CNBC and Euronews within 48 hours. Employees revolted on LinkedIn and Blind. Our read: this is the first time Big Tech has formalized turning its own workforce into a synthetic-data replacement for AI agent training, and it will not be the last.
Inside the Model Capability Initiative Leak
Reuters broke the story at 18:49 UTC on April 21, 2026, citing an internal memo from Meta Superintelligence Labs, the division run by Alexandr Wang after Meta paid $14.3 billion to acquire his Scale AI stake in 2025. The memo describes MCI as an internal tool that will, in Meta's own wording: "capture these kinds of inputs on certain applications to help us train our models." Within hours TechCrunch, Gizmodo, Fortune, Slashdot, Futurism and IBTimes UK had picked up the story. By April 22, CNBC confirmed the list of monitored platforms includes Google, LinkedIn, Wikipedia, GitHub, Slack and Atlassian products.
Meta's framing is defensive. The company told reporters: "If we're building agents to help people complete everyday tasks using computers, our models need real examples of how people actually use them. There are safeguards in place to protect sensitive content, and the data is not used for any other purpose." The word "actually" does a lot of work in that sentence. Meta is admitting that its current AI agents, trained on web-scale data and synthetic traces, cannot replicate the micro-behaviors of actual knowledge workers. The Model Capability Initiative is a confession that Llama-family agents have hit a ceiling on computer-use benchmarks, and Meta thinks the only path out is harvesting its own workforce.
The memo defines six categories of captured telemetry. Every keystroke, including keys not tied to text entry (shortcuts, navigation, modifier combinations). Every mouse movement with location and timing data. Every click with target element metadata. Every dropdown menu interaction, explicitly called out in the memo as behavior difficult to learn from web data. Periodic screenshots of screen content for context. And navigation patterns across a whitelist of hundreds of business applications. This is deeper and more granular than anything Microsoft, Google or Amazon has publicly deployed on their own workforces.
What Exactly Meta's MCI Tracks: The Technical Breakdown
We read the reporting from six independent sources and cross-referenced the CNBC list of monitored platforms with the Reuters memo quotes. Here is what the tool captures, in plain language, with no Meta PR varnish.
Keystrokes (all of them)
Every key pressed on a company machine is logged with a timestamp. This includes text you type, keyboard shortcuts (Cmd+K, Cmd+Shift+P, power-user combos), modifier keys, and navigation keys (Tab, Arrow, Escape). The training signal Meta wants is not the text content, it is the sequence and timing. When you hit Cmd+K then type three letters then press Enter, that is a "find command" behavioral pattern Meta's agent needs to learn. Web-scraped data does not contain this.
Mouse movements and clicks
Every pixel of mouse movement is captured along with click locations. The memo explicitly mentions dropdown menus because agents trained on screenshots alone cannot learn to hover, wait for a submenu to expand, then click the third item down. That is a motor-memory task humans do in 400 milliseconds without thinking. Capturing it from thousands of employees gives Meta a dataset no competitor has.
Screenshots and screen content
MCI takes periodic screenshots of employee screens. Meta has not disclosed the interval (every 5 seconds? every action? every minute?), but the memo describes them as "occasional snapshots" for context. In practice, this means Meta will have visual records of what its employees saw, read and typed throughout the workday. The data protection claim is that the tool will not send content from sensitive categories, but Meta has not published the sensitivity filter logic or allowed external audit.
Dropdown navigation and UI patterns
This is the category Meta most obviously needed. Modern AI agents can describe a dropdown in a screenshot but fail to operate one under real latency. The MCI dataset will teach Meta's agents the exact sequence of hover, wait, scan, click that humans perform when navigating application menus. Google, LinkedIn, Wikipedia, GitHub, Slack and Atlassian products were singled out because they contain the richest menu hierarchies in daily business software.
Keyboard shortcuts
The memo calls these out by name as "difficult to reproduce from general web data." That is a euphemism for "our agents cannot figure these out." Shortcuts are fingerprints of expertise. An engineer hitting Cmd+Shift+F in VS Code means "search across all files." An agent that can replicate that move on command saves Meta engineering time on every future workflow its AI touches.
Application whitelist
Per CNBC, the monitored platforms confirmed so far include Google products (Search, Docs, Gmail), LinkedIn, Wikipedia, GitHub, Slack and Atlassian (Jira, Confluence). Reuters described the list as "hundreds of websites and apps." Meta did not publish the full list. Employees have no per-application opt-out in any reporting we have seen.
Why Meta Took This Risk: The Agent Arms Race

To understand why Meta accepted the reputational hit of formalizing keystroke surveillance, you need to look at who Meta is racing. As of April 2026, the autonomous AI agent landscape has four credible players and Meta is fourth.
OpenAI shipped Operator in early 2025 and has iterated it into an agent platform that handles bookings, shopping and basic knowledge-worker tasks. Anthropic launched Computer Use with Claude 3.5 Sonnet in late 2024 and has since extended it to Claude Opus 4.7, our current daily driver for orchestration tasks. Google released Project Mariner and has integrated agent capabilities across Workspace and Chrome, using its own search and Gmail telemetry as training signal. Meta has Llama-family models and, as of Muse Spark in April 2026, a closed-source frontier model, but it has no agent product that ships to consumers at scale.
Our take: Meta's leadership concluded that synthetic data, web-scraped traces and public agent demonstration videos have run out of training signal. Every frontier lab is hitting the same wall. OpenAI and Anthropic mitigate it by having billions of API interactions and consumer chat sessions to mine, with consent captured in terms of service. Google has the largest organic telemetry pool on the planet via Search, Gmail, Chrome and Android. Meta's consumer products are social graphs, not workflow tools. The company does not watch its users navigate Jira or Figma. Its own engineers do. Turning that internal workflow data into training corpus is the shortest path to competitive agents.
The alternative Meta could have chosen, paying third-party data labelers to perform scripted computer-use tasks on camera, is already saturated. Scale AI, Surge and Invisible all run that playbook and the signal quality has degraded as labelers learn the "right answers." Real employees working on real tasks produce noisier but more representative traces. It is the same argument Tesla makes for fleet data versus simulation.
Context: Meta Superintelligence Labs and the Alexandr Wang Playbook

The Model Capability Initiative did not come from the Llama team. It came from Meta Superintelligence Labs (MSL), the division Mark Zuckerberg created in June 2025 and staffed by acquiring Alexandr Wang's stake in Scale AI for $14.3 billion. We covered the broader MSL play in our earlier analysis of Meta Muse Spark and the closed-source superintelligence bet, and our take on how Muse Spark effectively killed Meta's open-source Llama commitment.
Wang spent eight years running Scale AI as the largest commercial data-labeling operation in the world. Scale's entire business model was converting human labor into AI training data. The MCI leak reads like a Scale playbook applied in-house. The key insight is that Wang does not see this as surveillance. He sees it as data supply-chain optimization. Every employee on MSL payroll is a professional with specialized workflow knowledge. Capturing that knowledge as telemetry is, from Wang's frame, the fastest path to closing the gap with OpenAI and Anthropic on agent capability benchmarks.
This frame is coherent internally and disastrous externally. Meta has spent five years losing public trust battles on Cambridge Analytica, Instagram teen mental health and content moderation. Announcing that it will record every keystroke of its own workforce, on the same day that the Coinbase clones story broke about executives turning themselves into AI agents, was the worst possible news-cycle collision.
The Coinbase Parallel: Same Day, Same Question
April 21, 2026 was the day AI training data ethics broke into mainstream news on two fronts at once. While Reuters was leaking the Meta memo, Coinbase was announcing that Fred Ehrsam and Balaji Srinivasan had willingly cloned themselves as AI agents on the company Slack. We covered that story in depth in our analysis of the Coinbase executive clones.
The structural difference matters. Ehrsam and Balaji opted in as billionaire founders choosing to extend their influence. Meta employees did not opt in as knowledge workers employed on at-will contracts. Consent is not the same thing when power asymmetry is that large. Both stories are about turning humans into AI training corpus, but one is a public relations win (founders "giving back" their expertise) and the other is a public relations crisis (surveillance rebranded).
Our read: these two stories arriving on the same day is not a coincidence of the news cycle. It is the visible surface of a deeper industry shift. The frontier AI labs have concluded that the next capability jump requires human behavioral data that is not available on the open web. Scale AI's contractor model is saturated. Synthetic data plateaued. The remaining options are (A) opt-in volunteers who are already famous and powerful, or (B) employees who cannot meaningfully refuse. April 21 was the day both paths went public in parallel.
The Legal Landscape: US vs EU on Workplace Surveillance
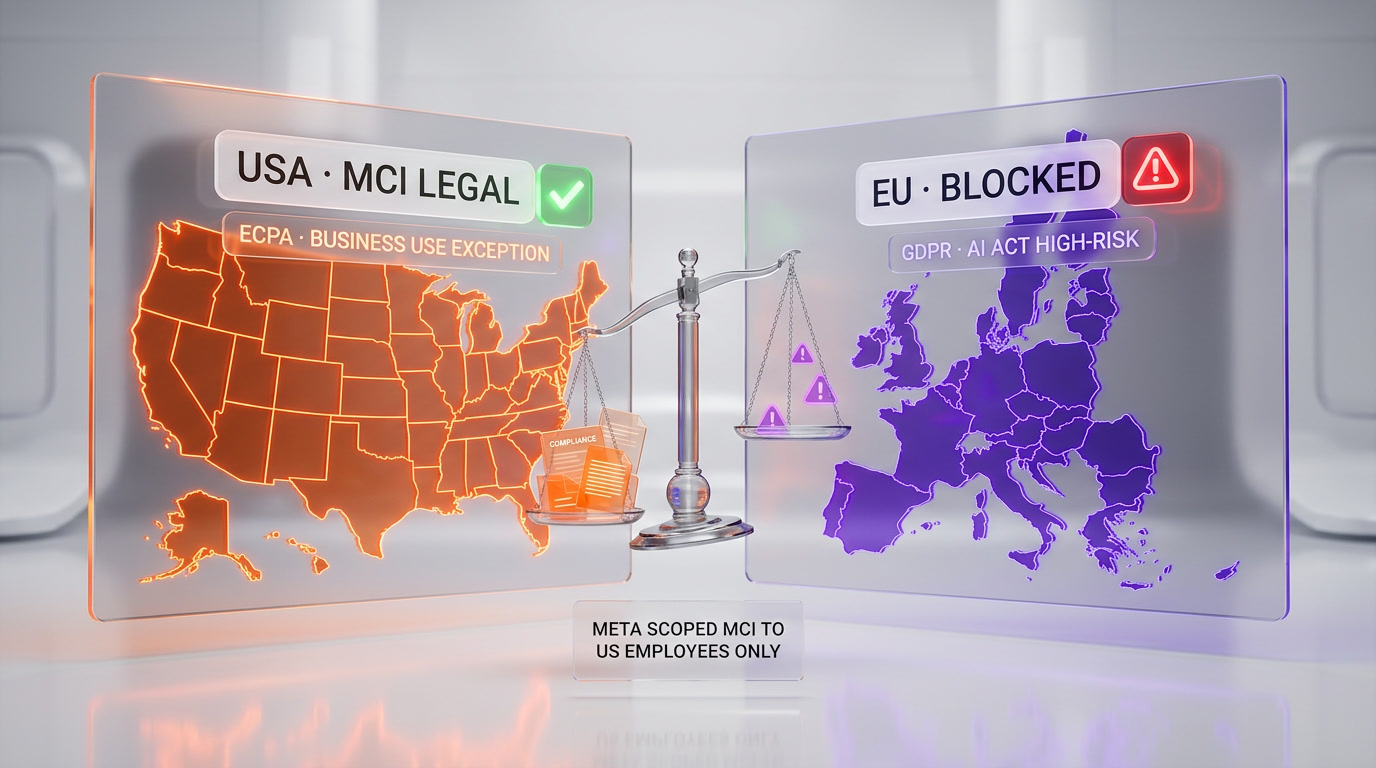
MCI is legal in the United States. Federal law and the law of every US state permits employer monitoring of company-owned devices as long as employees are notified. The Electronic Communications Privacy Act carves out a "business use" exception that covers the full MCI capture scope. Two states, Connecticut and Delaware, require written notice of electronic monitoring, which Meta can satisfy with a sentence in an employee handbook update.
The scope restriction to "US employees" in the memo is not an accident. The same program would be impossible to run on Meta's European workforce. Under GDPR, processing of personal data for a purpose (AI training) distinct from the purpose the data was collected for (performing job duties) requires explicit, informed, freely given consent, documented and revocable. Freely given consent from an employee to an employer is, under consistent European Data Protection Board guidance, essentially impossible to establish because the power asymmetry invalidates it. The EU AI Act, which entered full force in 2025, adds a second layer by classifying systematic workplace behavioral monitoring as high-risk AI processing requiring conformity assessment.
This is why Meta scoped MCI to the US. It also means European employees in Dublin, Paris and London will watch their US colleagues be monitored and draw conclusions. Expect internal attrition pressure on the monitored group and internal recruiting pressure from the European offices offering a comparable role without the keystroke capture.
Employee Reaction: Blind, LinkedIn and the Quiet Resignations

Within six hours of the Reuters leak, Blind threads and LinkedIn posts from verified Meta employees hit public feeds. The most widely quoted line, cited in Futurism, Fortune and IBTimes UK: "This makes me super uncomfortable." Other employee reactions surfaced patterns we have seen before on similar surveillance rollouts.
The first pattern is framing disagreement. Meta's internal message argued that "employee activities on company machines have been monitored for years, we are formalizing." Employees countered that "formalizing" is doing heavy lifting for "massively expanding scope from security telemetry to full behavioral capture for AI training." Both statements are technically true. The gap between them is where the trust breakdown lives.
The second pattern is lateral comparison. Engineers on Blind pointed out that OpenAI, Anthropic and Google do not run equivalent programs on their own engineers. That claim is partly true (no equivalent program has leaked) and partly unfalsifiable (we do not know what is running internally that has not leaked). What matters for Meta's retention is that the perception exists.
The third pattern is the quiet exit. A subset of senior engineers with marketable skills (Infrastructure, AI Research, Security) publicly signaled they were updating LinkedIn profiles and taking outside calls. Meta's compensation structure is designed to make leaving expensive, but the calculus shifts when the surveillance is visible and the market is hot. We expect attrition metrics on the MSL-adjacent teams to be the real measure of whether MCI was a net-positive move for Meta, not public relations sentiment.
What This Means for Big Tech: The New Training Frontier
Meta is the first Big Tech company to formalize and leak employee telemetry as AI training data. It will not be the last. Our analysis of the incentive structure suggests three outcomes over the next 18 months.
First, every frontier lab will quietly deploy something similar or explicitly confirm they have not. OpenAI, Anthropic and Google can no longer stay silent on workforce monitoring policy. Silence will be read as admission. Expect public statements from all three within the quarter, framing their own data supply as "synthetic plus licensed corpora" or "voluntary contributor programs."
Second, the "volunteer data contributor" role will professionalize. Scale AI and competitors already pay for high-skill annotators. Expect a new tier above that where domain experts (lawyers, accountants, engineers) are paid to have their actual work captured at rates that make the trade-off explicit. This is the opt-in version of MCI, priced as a product.
Third, the EU AI Act will be tested. Someone, somewhere, will try to run MCI-equivalent programs on European employees by routing the data through a US subsidiary. The first enforcement action will set the precedent for the rest of the decade. We expect Ireland's Data Protection Commission to be the first regulator to weigh in, given its jurisdiction over Meta's European operations.
The broader story is that 2026 is the year the AI industry stopped pretending that "training data" is a solved problem. Meta's MCI is the loudest single admission yet that the path to agentic AI runs through captured human behavior, that synthetic data has diminishing returns, and that Big Tech is willing to monetize its own workforce to close the gap. This is the same structural logic driving Google's aggressive Chrome AI push, where the browser becomes the surveillance surface that feeds Gemini's agent capabilities.
Our Analysis: Three Uncomfortable Conclusions
We have spent the last 48 hours reading the primary reporting, the employee reactions on Blind and LinkedIn, and the historical precedents from Amazon warehouse monitoring to Teramind's call-center products. Three conclusions emerge.
Our first conclusion is that Meta will not roll this back. The reputational cost has already been paid. The training signal is too valuable to walk away from. Expect internal messaging over the coming weeks to reframe MCI as a routine extension of existing security telemetry, followed by silence. The story will be out of the news cycle within three weeks and the program will continue as planned.
Our second conclusion is that the agent benchmark gap will close. If MCI delivers even a fraction of the behavioral signal Meta's leadership hopes for, Llama-family agents will approach OpenAI and Anthropic parity on computer-use tasks within two model generations. We are skeptical of the magnitude but not the direction. The industry will watch the next Llama release and the next Meta Muse Spark capability update for evidence.
Our third conclusion, and the most uncomfortable one, is that every knowledge worker reading this article now lives in a world where their workflow patterns are a valuable commodity. If your employer is a Big Tech firm, assume you are the training data. If your employer is not Big Tech, assume the software you use (Slack, Figma, GitHub, Notion) is harvesting behavioral telemetry that will eventually be licensed for agent training. We are not paranoid. We are reading the 10-Ks. Enterprise software vendors are explicitly adding "product usage data may be used to improve AI features" clauses to their terms. The lines are already drawn. MCI is the moment they became visible.
For developers and technical operators, the practical implication is to think about which tools you route professional work through. Terminal-native, local-first workflows (we use Claude Code daily for exactly this reason) expose less behavioral surface than cloud-hosted IDEs and browser-based suites. Self-hosted tooling is no longer a preference. It is a threat model question.
The Verdict: A Formalized Ethics Break

Our bottom line: the Model Capability Initiative is legal, rational from Meta's strategic position, and a permanent precedent. It is also the clearest statement yet that Big Tech views its workforce as a primary data source, not a collection of professionals with independent labor value. Those two things do not cancel out. They stack.
Meta did not invent workplace surveillance. It formalized and scaled it for a new purpose. The AI industry will follow. The regulatory response will lag by at least 24 months. The individual response, for anyone working inside a Big Tech company in 2026, is to understand that your keystroke patterns are now a line item in the training data budget. Act accordingly.
Frequently Asked Questions
What is Meta's Model Capability Initiative (MCI)?
MCI is an internal surveillance tool Meta is installing on all US-based employee computers, revealed April 21, 2026 via a Reuters leak. It records keystrokes, mouse movements, clicks, dropdown navigation, keyboard shortcuts and periodic screenshots. The captured data trains Meta's autonomous AI agents to replicate human computer-use behavior. Meta states the data is not used for performance reviews.
Which applications and websites does MCI track?
According to CNBC reporting, confirmed platforms include Google products (Search, Docs, Gmail), LinkedIn, Wikipedia, GitHub, Slack and Atlassian tools (Jira, Confluence). Reuters described the full list as "hundreds of websites and apps." Meta has not published the complete whitelist and employees have no per-application opt-out disclosed in any reporting.
Why is Meta capturing employee keystrokes instead of using synthetic data?
Meta's memo explicitly states that behaviors like dropdown navigation and keyboard shortcuts are "difficult to reproduce from general web data." Synthetic data plateaued for agent training across the industry. Real employees doing real work produce higher-quality behavioral traces than scripted data labelers. MCI is Meta's attempt to close the agent capability gap with OpenAI Operator, Anthropic Computer Use and Google Project Mariner.
Is the Model Capability Initiative legal?
Yes, in the United States. Federal law and the Electronic Communications Privacy Act permit employer monitoring of company-owned devices with employee notice. Connecticut and Delaware require written notice, which Meta can provide via handbook update. The same program would be illegal under EU GDPR and the EU AI Act due to consent requirements that power asymmetry invalidates, which is why MCI is scoped to US employees only.
Who runs Meta Superintelligence Labs behind MCI?
Alexandr Wang runs Meta Superintelligence Labs (MSL), the division Mark Zuckerberg created in June 2025. Meta paid $14.3 billion to acquire Wang's Scale AI stake as part of the deal. Wang spent eight years at Scale AI converting human labor into AI training data at commercial scale. MCI reads as a Scale AI playbook applied inside Meta's workforce.
How did Meta employees react to the MCI leak?
Meta employees revolted publicly on Blind and LinkedIn within hours. The most widely quoted reaction across Futurism, Fortune and IBTimes UK was "This makes me super uncomfortable." Senior engineers with marketable skills signaled they were updating profiles and taking outside calls. Meta's internal response framed MCI as "formalizing" existing monitoring, which employees disputed as misrepresenting a scope expansion.
Do OpenAI, Anthropic and Google run similar programs?
No equivalent program at OpenAI, Anthropic or Google has publicly leaked as of April 2026. That is a factual statement, not a guarantee. All three companies face the same training-data pressures Meta faces. Expect public statements from each within the quarter clarifying their own workforce data practices. Silence will increasingly be read as admission as the story matures.
What does MCI capture that web data cannot?
Six categories. Full keystroke sequences including shortcuts and modifier keys. Pixel-level mouse movement with timing. Click locations with target element metadata. Dropdown menu navigation (hover, wait, click patterns). Keyboard shortcut combinations. Periodic screenshots of screen content. Web-scraped data and synthetic traces lack the motor-memory timing and menu-interaction patterns that distinguish expert computer users from novices.
How does MCI compare to the Coinbase executive clones story?
Both stories broke April 21, 2026. Coinbase cloned Fred Ehrsam and Balaji Srinivasan as AI agents on company Slack with their explicit consent as billionaire founders. Meta's MCI captures rank-and-file employee behavior under at-will employment contracts. The structural difference is consent quality. Both signal that frontier AI labs have concluded human behavioral data is the next training frontier, but only one version scales as a public relations story.
Can MCI be used for performance reviews or firing decisions?
Meta publicly states the data will not be used for performance assessments. That is a policy commitment, not a technical guarantee. The captured data sits in Meta's data infrastructure and could in principle be queried for any purpose. Employees have no external audit mechanism to verify the restriction. Historical precedent from other companies (Amazon warehouse monitoring, call-center productivity tools) shows these policy commitments erode over time as data becomes useful for other purposes.
What can knowledge workers do if their employer deploys similar tools?
Three practical responses. First, read the terms of service on enterprise software you use at work (Slack, Figma, GitHub, Notion) for "product usage data may be used to improve AI" clauses. Second, prefer local-first and terminal-native tools for sensitive work where possible. We use Claude Code and other CLI tools for exactly this reason. Third, monitor company policy updates for scope changes to employee monitoring, which are often communicated via handbook revisions rather than company-wide announcements.
Will other Big Tech companies follow Meta with similar surveillance programs?
Our analysis says yes, quietly. The training-data economics that drove MCI apply to every frontier AI lab. Expect publicly-announced "voluntary contributor" programs as the opt-in version, priced as a paid role. Expect internal deployments at competitor companies that do not leak. Expect the first EU AI Act enforcement action within 18 months once someone tries to route equivalent programs through a US subsidiary to reach European employee data.