Claude Fable 5 vs Gemini 3.1 Pro: Capability King vs Value King (2026)


Claude Fable 5 posts 80.3% on SWE-Bench Pro vs Gemini's 54.2% — but costs $10 vs $2 per million input tokens. We break down which frontier model wins.

Feature Comparison
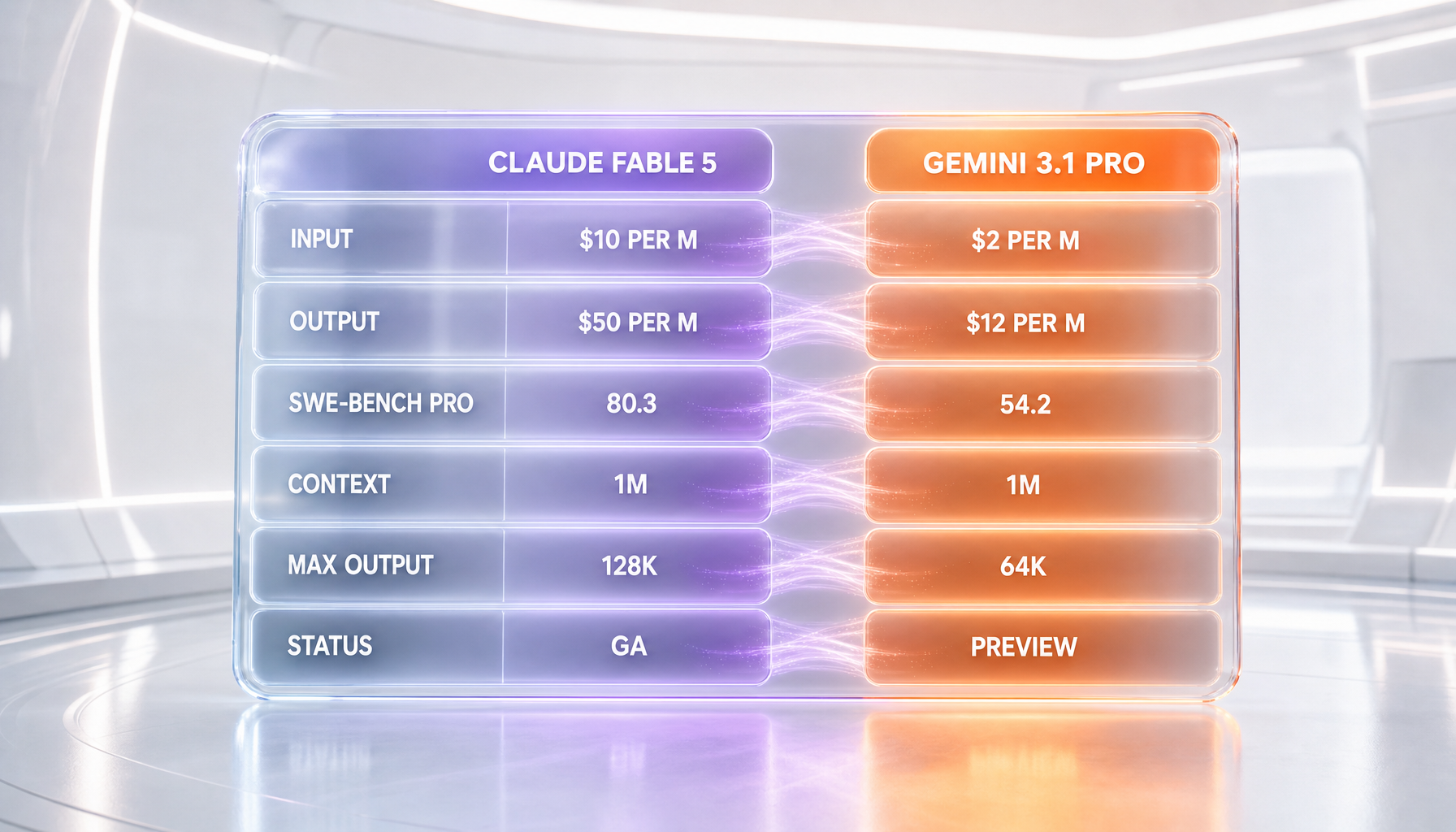
| Feature | Claude Fable 5 | Gemini 3.1 Pro Preview |
|---|---|---|
| Standard input price (per million tokens) | $10 | $2 (up to 200K), $4 (above 200K) |
| Standard output price (per million tokens) | $50 | $12 (up to 200K), $18 (above 200K) |
| SWE-Bench Pro (agentic coding) | 80.3% (early third-party coverage, not independently verified) | 54.2% (same early coverage) |
| GDPval-AA (knowledge work) | About 1932 Elo (early coverage) | Not reported in the early coverage |
| GPQA Diamond (reasoning) | Not published in comparable form | 94.3% (no tools, official model card) |
| Context window | 1M tokens input | 1M tokens input / 64K output |
| Max output tokens | 128K | 64K |
| Native multimodality | Text, images, PDFs | Text, images, audio, video |
| Availability status | Generally available (June 9, 2026) | Preview (GA expected later 2026) |
| Overall pick of this head-to-head | Most capable frontier model (capability crown) | Best price-to-performance (value crown) |
Pricing Comparison
Claude Fable 5
Gemini 3.1 Pro Preview
Detailed Comparison
Claude Fable 5 vs Gemini 3.1 Pro is a comparison between Anthropic's new top-tier frontier model and Google DeepMind's flagship multimodal reasoner. Claude Fable 5, generally available since June 9, 2026, sits a full tier above Claude Opus 4.8 and costs $10 per million input tokens and $50 per million output tokens, with a 1M-token context window and 128K tokens of output. Gemini 3.1 Pro, still in preview, costs $2 per million input tokens and $12 per million output tokens up to 200K context — roughly five times cheaper on input. Early third-party coverage of Anthropic's launch table puts Fable 5 at 80.3% on SWE-Bench Pro versus 54.2% for Gemini 3.1 Pro, a 26-point gap that is directional rather than independently verified. If you want the most capable agentic model money can buy today, Fable 5 wins this head-to-head; if you want the best price-to-performance with the broadest native multimodality, Gemini 3.1 Pro keeps the value crown.
Disclosure: ThePlanetTools.ai has no affiliation with Anthropic or Google DeepMind. We are not paid to recommend either model, and there are no affiliate links in this comparison. Last compared: June 2026. Every price below was fetched directly from the vendor pages, every benchmark is attributed to its source, and where a number comes from early coverage rather than independent verification, we flag it.
Quick Verdict
These two models are not priced for the same buyer, so the honest answer starts with what you are optimizing for. Here is the short version before the detail.
- Best for raw capability and agentic coding: Claude Fable 5. It is Anthropic's most capable model ever — a new tier above Opus 4.8 — and early coverage of the launch table reports 80.3% on SWE-Bench Pro, twenty-six points clear of Gemini 3.1 Pro's 54.2% in the same early reports. The numbers are directional, not independently verified, but the official specs back the positioning: 128K output tokens, a 1M context window, and general availability today.
- Best for price, multimodality, and Google-native workflows: Gemini 3.1 Pro. Its vendor-confirmed pricing is $2 input and $12 output per million tokens up to 200K context — roughly a fifth of Fable 5's input rate — and it natively understands images, audio, and video across the Gemini API, Vertex AI, the Gemini app, and NotebookLM.
- Best overall in this head-to-head: Claude Fable 5, on capability — which is the dimension this matchup is about. If your budget rules and your workload is high-volume, Gemini 3.1 Pro remains the rational default; nothing at five times the input price wins a cost argument.
This is a deliberate verdict, not a fence-sit: a capability king and a value king, and your workload decides which crown matters.
Fable 5 vs Gemini 3.1 Pro at a Glance
Before the section-by-section breakdown, here is the headline comparison. Every number is attributed to its source, and we mark the rows where figures come from early coverage rather than official documentation.
| Dimension | Claude Fable 5 | Gemini 3.1 Pro | Edge |
|---|---|---|---|
| Vendor | Anthropic | Google DeepMind | Tie |
| Status | Generally available (June 9, 2026) | Preview (GA expected later 2026) | Fable 5 |
| Standard input price (per million tokens) | $10 | $2 (up to 200K), $4 (above 200K) | Gemini |
| Standard output price (per million tokens) | $50 | $12 (up to 200K), $18 (above 200K) | Gemini |
| SWE-Bench Pro (agentic coding) | 80.3% (early third-party coverage, not independently verified) | 54.2% (same early coverage) | Fable 5 (see source caveat) |
| GDPval-AA (knowledge work) | About 1932 Elo (early coverage) | Not reported in the early coverage | Fable 5 (only one with a reported score) |
| GPQA Diamond (reasoning) | Not published in comparable form | 94.3% (no tools, official model card) | Gemini (only one with a published score) |
| Context window | 1M tokens input | 1M tokens input | Tie |
| Max output tokens | 128K | 64K | Fable 5 |
| Native multimodality | Text, images, PDFs | Text, images, audio, video | Gemini |
| Reasoning controls | Adaptive thinking, always on | Three-level thinking system | Tie |
| Safety routing | Flagged cyber and bio queries reroute to Opus 4.8 at Opus pricing | Standard safety filters | Tie |
The single most important pair of rows is pricing versus SWE-Bench Pro. One model costs five times more on input; the early coverage says it delivers a twenty-six-point coding lead. Whether that trade is worth it is the entire question, and we walk through it below.
Claude Fable 5 in One Paragraph
Claude Fable 5 is Anthropic's most capable model, generally available since June 9, 2026, and positioned as a new tier above Claude Opus 4.8 rather than a replacement for it. Anthropic prices it at $10 per million input tokens and $50 per million output tokens — double Opus 4.8 on both sides — with US-only inference available at 1.1 times the standard rate. The official API documentation lists a 1M-token context window and 128K tokens of maximum output, the largest output ceiling in Anthropic's lineup. Fable 5 runs adaptive thinking always on: the API does not even accept a request to disable it, which tells you how central deliberate reasoning is to the model's design. Anthropic describes it as thorough and proactive, built to run agent systems for days at a time — planning across stages, delegating to sub-agents, and checking its own work. Two operational details matter for adopters: queries that trip Anthropic's cybersecurity or biology safeguards are automatically rerouted to Opus 4.8, and you are not charged Fable prices for rerouted requests; and using Fable requires 30-day data retention for safety monitoring, which compliance teams should note before committing.
Gemini 3.1 Pro in One Paragraph
Gemini 3.1 Pro is Google DeepMind's flagship reasoning model, documented in an official model card dated February 19, 2026, and still in preview with general availability expected later in 2026. Google pitches the Gemini family as the strongest in the world for multimodal understanding, agentic capabilities, and vibe-coding, and the specs back the multimodal half of that claim: native understanding of text, images, audio, and video, a confirmed 1M-token input context with 64K tokens of output, and a 94.3% score on GPQA Diamond with no tools — one of the highest published reasoning numbers anywhere. Its pricing, which we confirmed directly on Google's Gemini API pricing page this week, is $2 per million input tokens and $12 per million output tokens up to 200K context, stepping up to $4 and $18 above that, with context caching available at $0.20 per million tokens up to 200K. It ships across the Gemini API, Vertex AI, the Gemini consumer app, and NotebookLM, and adds a three-level thinking system that lets you trade reasoning depth against latency and cost.
Benchmarks: A Big Gap, Honestly Sourced
This is where we have to be careful, because the most dramatic number in this comparison is also the one with the weakest sourcing. Here is the honest breakdown of what we can compare and how much weight each figure deserves.
SWE-Bench Pro: a 26-point gap from the same early-coverage wave
SWE-Bench Pro is the harder, contamination-resistant successor to SWE-bench Verified, measuring whether a model can resolve real software-engineering issues end to end. The early third-party coverage of Anthropic's June 9 launch — including Weights and Biases' ml-news roundup and mainstream tech press — reports Claude Fable 5 at 80.3%, against 69.2% for Claude Opus 4.8, 58.6% for GPT-5.5, and 54.2% for Gemini 3.1 Pro. Taken at face value, that is a twenty-six-point lead over Gemini and an eleven-point jump over Anthropic's own previous best.
Now the caveat, stated plainly: both SWE-Bench Pro figures in this matchup come from the same early-coverage wave relaying Anthropic's launch materials. Neither has been independently verified at the time of writing, and Google has not published its own SWE-Bench Pro figure for Gemini 3.1 Pro in its model card. We treat the gap as directional — large enough that the ordering is unlikely to flip, but not a number we would put in a procurement document without running our own evaluation. Early reviewers also report that Fable 5's lead grows as tasks get longer, with Anthropic citing a 50-million-line codebase migration at Stripe completed in a day; that is vendor-amplified anecdote, and we label it as such.
GDPval-AA: Fable 5 reports a knowledge-work score Gemini does not
GDPval-AA is an Elo-style benchmark of economically valuable knowledge work — the spreadsheet-and-memo labor that fills most professional days. Early coverage of the Fable 5 launch reports a score of about 1932, positioned as the top of the field. Gemini 3.1 Pro does not have a comparable GDPval-AA figure in the early coverage or in its model card, so there is no head-to-head here — only a signal of where Anthropic is aiming Fable 5: long-horizon professional work, not just code.
GPQA Diamond: Gemini publishes a score Fable 5 does not
The mirror image is graduate-level science reasoning. Gemini 3.1 Pro's official model card reports 94.3% on GPQA Diamond with no tools — a genuinely elite, officially documented number. Anthropic's Fable 5 page does not publish a GPQA Diamond figure in comparable form, so we cannot oppose the two directly. As with every asymmetric benchmark in this series, we say so rather than inventing an opponent's score: Gemini holds the best officially documented reasoning number in this matchup, and Fable 5 holds the best early-reported agentic coding number. Those are different kinds of evidence, and we weight the official one higher per point.
How to read this section: only SWE-Bench Pro appears for both models, and both of those figures trace back to the same early coverage of Anthropic's launch table. GDPval-AA is Fable-only; GPQA Diamond is Gemini-only and the only officially documented benchmark on the table. For the previous generation's fully sourced head-to-head, see our Claude Opus 4.8 vs Gemini 3.1 Pro comparison.
Pricing: Five Times Apart, Both Vendor-Confirmed
Pricing is the cleanest part of this comparison because we pulled every number directly from the vendor pages — Anthropic's Fable page for Claude Fable 5, and Google's Gemini API pricing docs for Gemini 3.1 Pro — rather than trusting summaries. There is no ambiguity here, only a very large gap.
| Tier | Claude Fable 5 | Gemini 3.1 Pro |
|---|---|---|
| Input, standard (per million tokens) | $10 | $2 up to 200K context, $4 above 200K |
| Output, standard (per million tokens) | $50 | $12 up to 200K context, $18 above 200K |
| Regional and caching options | US-only inference at 1.1 times standard pricing | Context caching at $0.20 per million tokens up to 200K, $0.40 above |
At the standard tier and under 200K tokens of context, Gemini 3.1 Pro is five times cheaper on input and about 4.2 times cheaper on output. Even above 200K tokens, where Gemini steps up to $4 input and $18 output, it remains well under half of Fable 5's flat $10 and $50. And Gemini's context caching — $0.20 per million cached tokens — compounds the advantage for workloads that re-read the same large context repeatedly, which is exactly what long-context workloads do.
There is no spin that makes Fable 5 the budget option, and Anthropic is not pretending otherwise: Fable 5 is priced as a premium tier above its own Opus 4.8, which already costs $5 input and $25 output. The relevant question is not which model is cheaper — it is whether Fable 5's capability premium pays for itself in fewer failed runs, less human cleanup, and longer autonomous stretches. We run that math in the cost example below.
Context, Output, and Thinking Controls
On paper, the context war is a tie: both models offer a 1M-token input window, among the largest in any frontier model. The difference is on the way out. Fable 5's official API documentation lists 128K tokens of maximum output — double Gemini 3.1 Pro's 64K. For workloads that produce long artifacts — full refactors, generated test suites, long-form analysis delivered in one pass — that output ceiling is a real, spec-sheet advantage that does not depend on any benchmark.
The two models also philosophize differently about reasoning. Fable 5 runs adaptive thinking always on; the model decides when and how deeply to deliberate, and the API will reject an attempt to switch thinking off entirely. Gemini 3.1 Pro goes the opposite way with a three-level thinking system that hands the dial to you, letting cost-sensitive calls run shallow and hard problems run deep. Neither approach is strictly better: Anthropic is betting the model knows best, Google is betting you do. Teams that want deterministic cost control per call will prefer Gemini's explicit levels; teams that want maximum quality without tuning will prefer Fable 5's always-on default.
Two Fable-specific operational details belong in any honest comparison. First, safety routing: queries flagged by Anthropic's cybersecurity or biology safeguards are automatically rerouted to Opus 4.8, and Anthropic confirms you are not charged Fable prices for rerouted requests. For most teams this is invisible; for security-research teams it means a subset of prompts will silently run on a different model. Second, retention: using Fable requires 30-day data retention for safety monitoring. Organizations with strict zero-retention requirements need to clear that with compliance before adopting — Gemini 3.1 Pro carries no equivalent requirement on its pricing page.
Multimodality and Ecosystem
This is Gemini's strongest ground. Gemini 3.1 Pro natively understands text, images, audio, and video, and Google positions the family explicitly as the best in the world for multimodal understanding. Fable 5 handles text, images, and PDFs — entirely sufficient for coding, documents, and most knowledge work, but it does not natively ingest video or audio. If your pipeline analyzes meeting recordings, video content, or mixed-media archives, Gemini is the only one of the two that does it natively.
Ecosystem follows the same pattern. Gemini 3.1 Pro ships across the Gemini API, Vertex AI for enterprise governance, the Gemini consumer app, and NotebookLM for research workflows — a team already inside Google Cloud adopts it with almost no new plumbing. Fable 5's reach is the Claude API and Anthropic's surfaces, including Claude Code for agentic development, plus availability through cloud marketplaces. The trade-off flips on production status: Fable 5 is generally available today, while Gemini 3.1 Pro is still in preview with general availability expected later in 2026. If procurement requires GA, Fable 5 clears the bar now and Gemini does not yet.
Winner Per Category
Because the two models are priced and positioned for different jobs, the most useful way to pick is by use case rather than a single score.
- Best for agentic software engineering: Claude Fable 5. The early-reported 26-point SWE-Bench Pro gap, the 128K output ceiling, and Anthropic's days-long-agent positioning all point the same direction — with the source caveat on the benchmark noted.
- Best for cost-sensitive scale: Gemini 3.1 Pro. Five times cheaper input, vendor-confirmed, plus context caching. High-volume workloads are not a contest.
- Best for multimodal pipelines: Gemini 3.1 Pro. Native audio and video understanding that Fable 5 simply does not offer.
- Best for long-output work: Claude Fable 5. 128K output tokens against 64K is a clean, official spec win.
- Best for documented reasoning: Gemini 3.1 Pro, on the evidence available — its 94.3% GPQA Diamond is the only officially documented reasoning score in this matchup.
- Best for production stability today: Claude Fable 5. Generally available since June 9, 2026; Gemini 3.1 Pro remains in preview.
- Best for Google-native teams: Gemini 3.1 Pro. Vertex AI, the Gemini app, and NotebookLM integration is hard to beat if you already live in Google Cloud.
Pros and Cons of Each
Claude Fable 5
Pros
- Most capable Anthropic model ever, a full tier above Opus 4.8
- Early coverage reports 80.3% on SWE-Bench Pro, 26 points clear of Gemini 3.1 Pro
- 128K max output tokens, double Gemini's ceiling, with a 1M context window
- Generally available since June 9, 2026 — no preview caveat
Cons
- $10 input and $50 output per million tokens — five times Gemini's input rate
- Headline benchmark lead comes from early coverage, not independent verification
- Requires 30-day data retention for safety monitoring
- No native audio or video understanding
Gemini 3.1 Pro
Pros
- Vendor-confirmed pricing at $2 input and $12 output up to 200K — the value play
- Native multimodality across text, images, audio, and video
- 94.3% GPQA Diamond, the only officially documented reasoning score here
- Deep Google ecosystem: Vertex AI, Gemini app, NotebookLM, context caching
Cons
- Still in preview, with general availability expected later in 2026
- Early coverage places it 26 points behind Fable 5 on SWE-Bench Pro
- Output ceiling of 64K tokens is half of Fable 5's
- Pricing steps up above 200K tokens of context ($4 input, $18 output)
When to Pick Each Model
When to pick Claude Fable 5
Choose Fable 5 if agentic capability is the point: autonomous coding agents that run for hours or days, large-scale refactors and migrations, long-horizon knowledge work where the model plans, delegates, and checks its own output. Choose it if you need 128K tokens of output in a single pass, if procurement requires a generally available model today, or if you have already maxed out Opus 4.8 and need the next tier. The honest caveat: you are paying a confirmed five-times input premium partly on the strength of early-coverage benchmarks, so run your own evaluation on your own codebase before committing serious budget — and clear the 30-day retention requirement with compliance first.
When to pick Gemini 3.1 Pro
Choose Gemini 3.1 Pro if your bill matters and your volume is high — at one-fifth the input price, it is the only rational default for cost-sensitive scale. Choose it if your pipeline is multimodal, because native audio and video understanding is something Fable 5 does not offer at any price. Choose it if you already operate inside Google Cloud and want Vertex AI governance, or if your workloads re-read large contexts and can exploit caching at $0.20 per million tokens. The trade-offs: it is still in preview, its early-reported agentic coding number trails badly, and its output ceiling is half of Fable 5's.
How We Compared
We did not run a controlled head-to-head benchmark of both models on identical prompts — no such public test exists yet for Fable 5, nine days after its general availability, and we will not pretend otherwise. We have hands-on experience with Claude Fable 5 in our own agentic coding workflow, where it powers the long-horizon content and code pipelines behind this site, and that experience informs our read on its autonomy and self-checking behavior. Our experience with Gemini 3.1 Pro is lighter, so we lean on its official model card and Google's documentation for performance claims rather than our own testing.
For pricing, we fetched the vendor pages directly this week: Anthropic's Fable page, which confirms $10 input and $50 output per million tokens, US-only inference at 1.1 times, the Opus 4.8 safety rerouting, and the 30-day retention requirement; and Google's Gemini API pricing page, which confirms $2 and $12 up to 200K context, $4 and $18 above, and the caching rates. For benchmarks, we attribute every figure: SWE-Bench Pro and GDPval-AA numbers come from early third-party coverage relaying Anthropic's launch table and are flagged as not independently verified; GPQA Diamond comes from Google DeepMind's official model card. Where only one model reports a benchmark, we say so rather than inventing an opponent's score.
A Real-World Cost Example
Per-token prices are abstract until you run them against a real workload, so here is a concrete illustration. Imagine an agentic coding pipeline that processes 50 million input tokens and produces 10 million output tokens in a month — a realistic figure for a team running automated code-review and refactoring agents at scale.
On Claude Fable 5, that workload costs 50 million input tokens at $10 per million, which is $500, plus 10 million output tokens at $50 per million, which is $500 — a total of $1,000 for the month. On Gemini 3.1 Pro, assuming calls stay under 200K tokens of context, the same volume costs 50 million input tokens at $2 per million, which is $100, plus 10 million output tokens at $12 per million, which is $120 — a total of $220. That is a difference of $780 a month: the Fable 5 bill is about 4.5 times the Gemini bill for identical token volume.
Here is the counter-math that keeps the example honest. If the early benchmark gap translates into real-world reliability — fewer failed agent runs, fewer human interventions, tasks that finish autonomously instead of stalling — then the $780 premium buys back engineering hours that cost far more than $780. A single senior engineer-day saved per month more than covers it. If, on the other hand, your workload is simple enough that both models complete it reliably, the premium buys you nothing and Gemini wins outright. The price gap is a fact; whether the capability gap justifies it is a function of how hard your tasks are.
Switching Costs and Lock-In
Both models expose standard API surfaces, so raw integration work is comparable, and the real lock-in is ecosystem rather than syntax. Gemini 3.1 Pro pulls you toward Google Cloud: Vertex AI for governance, the Gemini app for end users, NotebookLM for research, and caching economics that reward staying put. If your organization already runs on Google Cloud, that gravity is a feature. Fable 5 pulls you toward Anthropic's agentic stack — Claude Code, sub-agent orchestration, and the kind of long-horizon workflows the model is explicitly built for — plus broad availability through cloud marketplaces.
Two Fable-specific commitments deserve a second mention because they are contractual rather than technical: the 30-day data retention requirement for safety monitoring, and the automatic rerouting of flagged cybersecurity and biology queries to Opus 4.8. Neither is a dealbreaker for typical commercial work, but both are the kind of thing you want in the adoption memo before, not after, legal review. Gemini's equivalent consideration is its preview status: building production dependencies on a model whose general availability date is still "later 2026" is a risk some change-management boards will not sign off on.
The Final Verdict
If you came for a single name: Claude Fable 5 wins this head-to-head — it is the most capable model of the pair, and as of June 2026 the most capable model Anthropic has ever shipped. Gemini 3.1 Pro keeps the value crown, and for budget-driven, high-volume, or multimodal workloads it remains the rational default.
The reasoning, dimension by dimension: Fable 5 takes capability on the strength of official specs we can verify — a 128K output ceiling double Gemini's, a 1M context window, general availability, and vendor-confirmed positioning a full tier above Opus 4.8 — reinforced by an early-reported 26-point SWE-Bench Pro lead that is directional but consistent across every early source we checked. Gemini 3.1 Pro takes price by a factor of five on input, takes multimodality outright with native audio and video, and holds the only officially documented reasoning score in the matchup at 94.3% GPQA Diamond.
So the crowns split, but the verdict does not waffle: this comparison is about the frontier, and Fable 5 is the frontier. Pick Claude Fable 5 when the task is hard enough that capability decides the outcome — autonomous agents, massive refactors, days-long knowledge work — and the premium repays itself in completed runs. Pick Gemini 3.1 Pro when volume, budget, or multimodal inputs decide the outcome, which for many teams is most of the time. A capability king and a value king; your workload picks the throne that matters.
Related Reading
If Fable 5's premium is too steep, our head-to-head of Claude Opus 4.8 vs Gemini 3.1 Pro covers the tier below, where the price gap narrows and the verdict flips. For the OpenAI angle on the same generation, see Claude Opus 4.8 vs GPT-5.5, and for how this matchup looked one generation back, our Claude Opus 4.7 vs Gemini 3.1 Pro comparison shows how fast the ground is shifting.
Frequently Asked Questions
What is Claude Fable 5?
Claude Fable 5 is Anthropic's most capable AI model, generally available since June 9, 2026, and positioned as a new tier above Claude Opus 4.8. It costs $10 per million input tokens and $50 per million output tokens, offers a 1M-token context window with 128K tokens of maximum output, and runs adaptive thinking always on. It is built for long-horizon agentic work — planning across stages, delegating to sub-agents, and checking its own output over runs that can last days.
What is Gemini 3.1 Pro?
Gemini 3.1 Pro is Google DeepMind's flagship multimodal reasoning model, documented in an official model card dated February 19, 2026, and currently in preview. It natively understands text, images, audio, and video, confirms a 1M-token input context with 64K-token output, reports 94.3% on GPQA Diamond, and costs $2 per million input tokens and $12 per million output tokens up to 200K context. It is available on the Gemini API, Vertex AI, the Gemini app, and NotebookLM.
Which model is better at coding, Claude Fable 5 or Gemini 3.1 Pro?
Early third-party coverage of Anthropic's launch table reports Claude Fable 5 at 80.3% on SWE-Bench Pro versus 54.2% for Gemini 3.1 Pro — a 26-point gap, with Claude Opus 4.8 at 69.2% and GPT-5.5 at 58.6% between them. Both figures come from the same early-coverage wave and are not independently verified, so treat the gap as directional. The official specs lean the same way: Fable 5 offers double the output ceiling and is explicitly positioned for agentic software engineering.
Which model is cheaper, Claude Fable 5 or Gemini 3.1 Pro?
Gemini 3.1 Pro, by a wide margin. We confirmed directly on Google's Gemini API pricing page that it costs $2 per million input tokens and $12 per million output tokens up to 200K context, against Fable 5's vendor-confirmed $10 and $50. That makes Gemini five times cheaper on input and about 4.2 times cheaper on output at the standard tier, and it stays well under half of Fable 5's rates even above 200K tokens, where its prices step up to $4 and $18.
What is SWE-Bench Pro and why does it matter here?
SWE-Bench Pro is a harder, contamination-resistant benchmark that measures whether a model can resolve real software-engineering issues end to end. It matters in this comparison because it is the only benchmark for which both models have a reported figure — Fable 5 at 80.3% and Gemini 3.1 Pro at 54.2% in early third-party coverage of Anthropic's launch table. The caveat is that both numbers trace to the same early coverage and are not independently verified.
How big is each model's context window?
Both models offer a 1M-token input context window, among the largest available in any frontier model. The difference is output: Claude Fable 5's official API documentation lists 128K tokens of maximum output, double Gemini 3.1 Pro's 64K. For workloads that generate long artifacts in a single pass — full refactors, complete test suites, long-form reports — Fable 5's ceiling is a clean spec advantage.
What is adaptive thinking in Claude Fable 5?
Adaptive thinking means Fable 5 decides for itself when and how deeply to reason before answering, and it is always on — the API does not accept a request to disable thinking entirely. Gemini 3.1 Pro takes the opposite approach with a three-level thinking system that lets you choose the reasoning depth per call. Anthropic's design bets the model knows best; Google's bets you do. Cost-control purists tend to prefer explicit levels, while quality-first teams prefer the always-on default.
Why does Claude Fable 5 sometimes route requests to Opus 4.8?
Anthropic runs cybersecurity and biology safeguards on Fable 5, and queries flagged in those domains are automatically rerouted to Claude Opus 4.8. Anthropic confirms you are not charged Fable prices for rerouted requests. For typical commercial workloads this is invisible, but security-research teams should know that a subset of prompts will silently run on a different model. Using Fable also requires 30-day data retention for safety monitoring.
Is Claude Fable 5's benchmark lead over Gemini 3.1 Pro verified?
Not independently, no. The 80.3% versus 54.2% SWE-Bench Pro comparison comes from early third-party coverage relaying Anthropic's launch table, and Google has not published its own SWE-Bench Pro figure for Gemini 3.1 Pro. We treat the 26-point gap as directional — consistent across every early source we checked, but not procurement-grade evidence. Fable 5's verifiable advantages are its official specs: 128K output tokens, a 1M context window, and general availability.
Does Gemini 3.1 Pro handle images and video better than Fable 5?
For video and audio, it is not a contest — Gemini 3.1 Pro natively understands both, while Claude Fable 5 accepts text, images, and PDFs but does not natively ingest video or audio at any price. For static images and documents, both models are strong. If your pipeline analyzes meeting recordings, video archives, or mixed-media content, Gemini 3.1 Pro is the only one of the two that does it natively.
Is Claude Fable 5 worth five times the price of Gemini 3.1 Pro?
It depends entirely on task difficulty. On a workload of 50 million input and 10 million output tokens per month, Fable 5 costs about $1,000 versus $220 on Gemini — a $780 premium. If Fable 5's capability edge means fewer failed agent runs and less human cleanup, one saved senior engineer-day per month more than repays that premium. If both models complete your tasks reliably, the premium buys nothing and Gemini wins outright. Hard, long-horizon work justifies Fable 5; routine volume does not.
Which model should most teams choose in 2026?
Teams whose work is capability-critical — autonomous coding agents, large migrations, days-long knowledge work — should choose Claude Fable 5: it wins this head-to-head as the most capable, generally available model of the pair. Teams optimizing for budget, volume, or multimodal inputs should choose Gemini 3.1 Pro, whose vendor-confirmed pricing at one-fifth the input cost and native audio-video understanding make it the better value. Run your own evaluation before committing either way; the benchmark gap is early-reported, not verified.

Our Verdict
Claude Fable 5 wins this head-to-head on capability — official specs (a 128K output ceiling double Gemini's, a 1M context window, general availability since June 9, 2026) plus an early-reported 26-point SWE-Bench Pro lead (80.3% vs 54.2%, not independently verified) make it the most capable model of the pair. Gemini 3.1 Pro keeps the value crown: vendor-confirmed pricing at $2 input and $12 output per million tokens up to 200K context (five times cheaper on input), native audio and video multimodality, and the only officially documented reasoning score in the matchup (GPQA Diamond 94.3%). Best for capability-critical agentic work: Claude Fable 5. Best for cost-sensitive scale and multimodal pipelines: Gemini 3.1 Pro.
Choose Claude Fable 5
Anthropic's most capable widely released model — the public, safety-classified Mythos-class frontier tier.
Try Claude Fable 5 →Choose Gemini 3.1 Pro Preview
Google DeepMind's flagship Gemini 3.1 Pro Preview — 94.3% GPQA Diamond, 77.1% ARC-AGI-2, 1M-token context, multimodal in/text out, vibe coding plus agentic tool use. Preview status as of April 2026.
Try Gemini 3.1 Pro Preview →Frequently Asked Questions
Is Claude Fable 5 better than Gemini 3.1 Pro Preview?
Claude Fable 5 wins this head-to-head on capability — official specs (a 128K output ceiling double Gemini's, a 1M context window, general availability since June 9, 2026) plus an early-reported 26-point SWE-Bench Pro lead (80.3% vs 54.2%, not independently verified) make it the most capable model of the pair. Gemini 3.1 Pro keeps the value crown: vendor-confirmed pricing at $2 input and $12 output per million tokens up to 200K context (five times cheaper on input), native audio and video multimodality, and the only officially documented reasoning score in the matchup (GPQA Diamond 94.3%). Best for capability-critical agentic work: Claude Fable 5. Best for cost-sensitive scale and multimodal pipelines: Gemini 3.1 Pro.
Which is cheaper, Claude Fable 5 or Gemini 3.1 Pro Preview?
Claude Fable 5 is priced at $10 in / $50 out per M tokens. Gemini 3.1 Pro Preview is priced at $2 in / $12 out per M tokens. Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Fable 5 and Gemini 3.1 Pro Preview?
The key differences span across 10 features we compared. For Standard input price (per million tokens), Claude Fable 5 offers $10 while Gemini 3.1 Pro Preview offers $2 (up to 200K), $4 (above 200K). For Standard output price (per million tokens), Claude Fable 5 offers $50 while Gemini 3.1 Pro Preview offers $12 (up to 200K), $18 (above 200K). For SWE-Bench Pro (agentic coding), Claude Fable 5 offers 80.3% (early third-party coverage, not independently verified) while Gemini 3.1 Pro Preview offers 54.2% (same early coverage). See the full feature comparison table above for all details.