Qwen 3.6
Alibaba's flagship LLM family — Plus and Max Preview proprietary plus Apache 2.0 open-weight 27B and 35B-A3B.
Quick Summary
Qwen 3.6 is Alibaba's flagship LLM family — Plus (proprietary, 1M context, $0.325 per 1M input + $1.95 per 1M output), Max Preview (closed weights, 6 coding benchmark wins), and Apache 2.0 open-weight 27B and 35B-A3B variants on Hugging Face. Score 8.5/10.
 LLM family with Apache 2.0 open weights" loading="lazy" class="rounded-xl w-full" />
LLM family with Apache 2.0 open weights" loading="lazy" class="rounded-xl w-full" />Qwen 3.6 is Alibaba's flagship large language model family. The lineup mixes a proprietary tier — Qwen 3.6 Plus with a 1M-token context window at 0.325 dollars per 1M input tokens and 1.95 dollars per 1M output tokens, plus Qwen 3.6 Max Preview that tops six coding benchmarks at launch — with Apache 2.0 open-weight releases, Qwen3.6-27B and Qwen3.6-35B-A3B, both downloadable from Hugging Face. Score 8.5 out of 10.
TL;DR — Our Verdict
Score: 8.5 out of 10. Qwen 3.6 is the open-weight LLM that finally makes the proprietary side optional for serious agentic coding work — the 35B-A3B sparse MoE hits 73.4% SWE-bench Verified with only 3B active parameters, and the 27B dense variant reaches 77.2%. The proprietary Plus tier at 0.325 dollars per 1M input is the cheapest credible flagship on the market in April 2026. Best for cost-sensitive agentic coding, self-hosted research, and any team that needs Apache 2.0 commercial freedom without Llama 4's 700M MAU clause. Pass if you need top-of-leaderboard reasoning at any cost — GPT-5.5 and Gemini 3.1 Pro Preview still lead Artificial Analysis Intelligence Index by a wide margin.
- Apache 2.0 open weights — full commercial freedom on 27B and 35B-A3B
- Plus pricing roughly 5x cheaper than GPT-5.5 and Claude Sonnet 4.6 for comparable work
- 1M-token native context on Plus and Flash variants
- Plus and Max Preview are closed weights — China-hosted, data residency caveats
- Reasoning topline is mid-tier — trails frontier Western models like GPT-5.5 and Gemini 3.1 Pro Preview
Our Methodology for This Review
We have not had production hands-on access to Qwen 3.6 in our daily ThePlanetTools.ai workflow — our content pipeline runs on Claude Opus 4.7 and Claude Haiku 4.5, and our daily-driver chat models are Claude, ChatGPT, and Gemini. This review compiles the official Alibaba press release dated April 2 2026 announcing Qwen 3.6 Plus, the Qwen team blog and qwenlm.github.io documentation last checked April 2026, the Qwen3.6 GitHub repository at github.com/QwenLM/Qwen3.6 covering the open-weight 27B and 35B-A3B releases, the OpenRouter pricing pages for Qwen 3.6 Plus and Flash, the Artificial Analysis benchmark pages for Plus, the marktechpost coverage of the Qwen3.6-27B agentic coding results dated April 22 2026, and community sentiment from r/LocalLLaMA threads where the open-weight variants are being benchmarked. Our score reflects feature completeness, pricing transparency, license terms, benchmark performance, and open-source dynamics weighted against the closed-weight proprietary frontier (GPT-5.5, Gemini 3.1 Pro Preview, Claude Opus 4.7).
What Is Qwen 3.6?
Qwen 3.6 is the April 2026 generation of Alibaba's Qwen large language model family, developed by the Qwen team inside Alibaba's DAMO Academy and Cloud Intelligence groups. The family is split into two delivery modes that share architecture lineage but ship independently: a proprietary tier accessible through Alibaba Cloud's Model Studio and the Qwen Chat web app, and an Apache 2.0 open-weight tier published on Hugging Face Hub and ModelScope.
The proprietary side launched first. Alibaba unveiled Qwen 3.6 Plus on April 2 2026 with a 1M-token context window, multimodal perception across text, images, and video, and a focus on repository-level agentic coding. Two weeks later on April 16 2026, the open-weight Qwen3.6-35B-A3B sparse Mixture-of-Experts model dropped under Apache 2.0. On April 20 2026 came Qwen 3.6 Max Preview, a closed-weight flagship-of-flagships built around a preserve_thinking API parameter. April 22 2026 closed the launch sprint with Qwen3.6-27B, a dense 27 billion-parameter open-weight model that outperforms Alibaba's own previous-generation Qwen3.5-397B-A17B MoE on multiple agentic coding tasks despite being roughly 15x smaller.
The strategic context matters. Meta pivoted to closed-source with Muse Spark in early April 2026, abandoning the original Llama open-weight roadmap. DeepSeek V4 launched April 24 2026 as the other major open-weight flagship contender. That left Qwen 3.6, with its Apache 2.0 license and no MAU revenue thresholds, as the most permissive flagship-grade open-weight family in the market.
Key Features
Apache 2.0 open-weight 27B and 35B-A3B
The headline differentiator is the license. Apache 2.0 means commercial use, modification, and redistribution with no revenue threshold (Llama 4's Community License kicks in restrictions above 700M monthly active users; Stability AI's Community License caps at 1M dollars in revenue). Qwen3.6-27B is a dense model with 64 transformer layers and 262,144 tokens of native context extensible to roughly 1,010,000 tokens via YaRN scaling. The FP8 build (Qwen/Qwen3.6-27B-FP8) fits comfortably on a single H100 80GB and runs on a 2x RTX 4090 setup for self-hosting. Qwen3.6-35B-A3B is a sparse MoE that activates only 3B parameters per token despite the 35B total — the most aggressive sparsity ratio in the April 2026 open-weight comparison versus DeepSeek V4 and Llama 4.
Qwen 3.6 Plus — proprietary 1M-context flagship
Plus is the daily-driver proprietary model. It supports a 1M-token native context window, full multimodal input including high-density document parsing, physical-world visual analysis, and long-form video reasoning. Visual coding is a notable addition: feed Plus a UI screenshot, a hand-drawn wireframe, or a product prototype mockup, and it returns production-grade frontend code. Available through Alibaba Cloud Model Studio, the Qwen Chat web app at qwen.ai/chat, and routed through OpenRouter for multi-provider deployments. Output throughput measured by Artificial Analysis sits at 52.8 tokens per second with a 2.80 second time-to-first-token.
Qwen 3.6 Max Preview — preserve_thinking and 6 benchmark wins
Max Preview is a closed-weight 35B total / 3B active MoE released April 20 2026. Its claim to fame is taking first place across six coding benchmarks at launch — SWE-bench Pro, Terminal-Bench 2.0, SkillsBench, NL2Repo, QwenClawBench, and QwenWebBench — and introducing the preserve_thinking API parameter, which maintains internal reasoning traces across multiple conversation turns. For agentic workflows where 30-step plans get truncated by context budget, preserve_thinking keeps the logical scaffolding intact. Mid-tier on the AA Intelligence Index, 256K context window. Currently routed via Alibaba's API and OpenRouter at 1.30 dollars per 1M input and 1.30 dollars per 1M output, and labeled preview, meaning weights, pricing, and feature surface may shift before stable release.
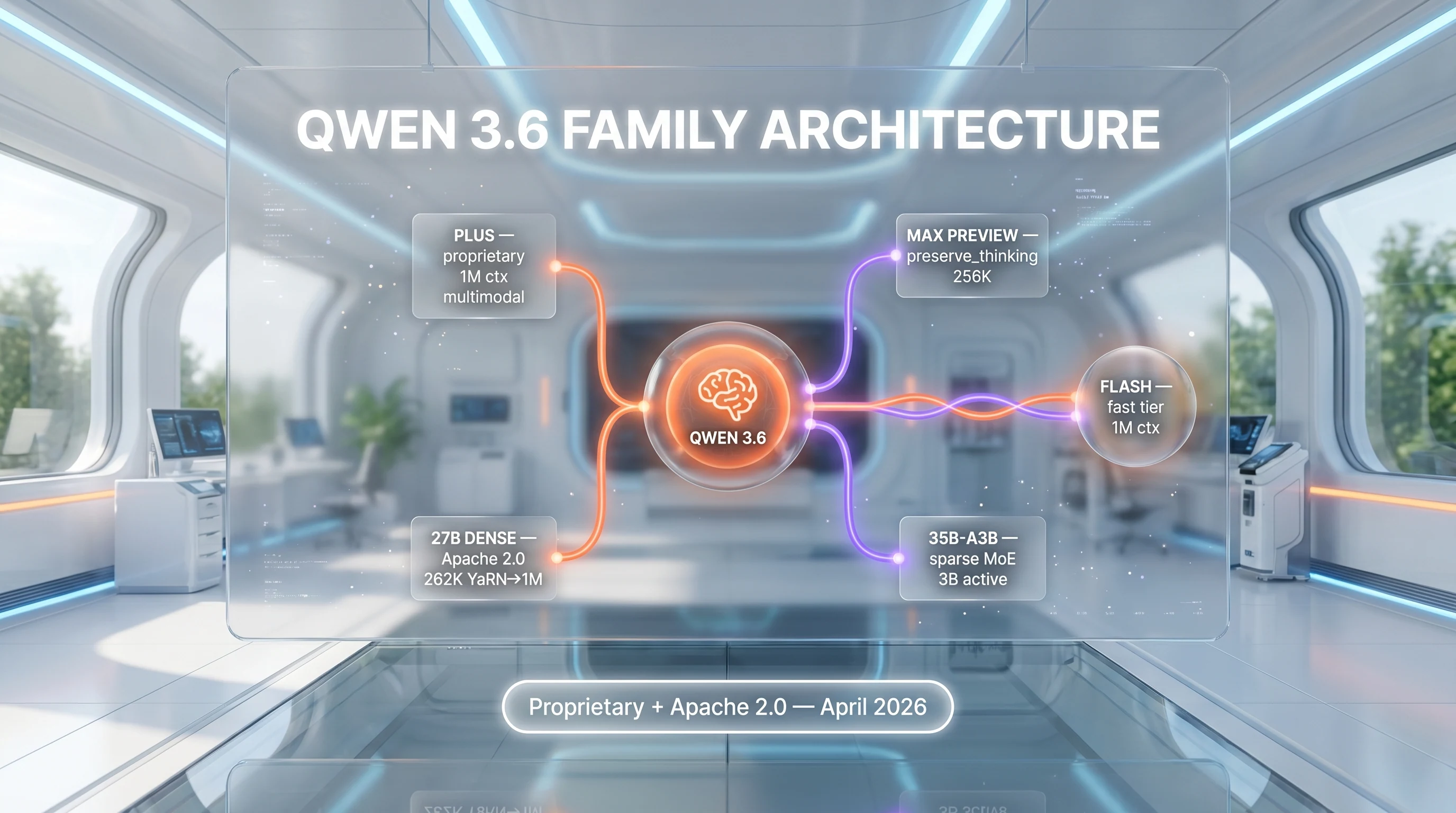
Qwen 3.6 Flash — 1M context at 0.25 dollars per 1M input
Flash is the cost-optimized speed tier. 1M-token context window, 65,536 max output tokens, multimodal text/image/video input, and tiered pricing that increases above 256K tokens. At 0.25 dollars per 1M input and 1.50 dollars per 1M output, it undercuts Gemini 3 Flash and Claude Haiku 4.5 by a meaningful margin for high-volume batch jobs.
Repository-level agentic coding
The whole family is tuned for multi-file repo-aware agent work. Terminal-Bench 2.0 score of 59.3 on the 27B (matching Claude Opus 4.5 territory according to the Qwen team's reported numbers), SWE-bench Pro at 53.5, and SWE-bench Verified at 77.2. The 35B-A3B reaches 73.4% SWE-bench Verified — at 3B active parameters, that is genuinely industry-leading per-active-parameter efficiency.
Compatibility with OpenClaw, Claude Code, and Cline
Alibaba shipped explicit out-of-the-box compatibility with the major agentic coding harnesses — OpenClaw, Anthropic's Claude Code, and Cline. That means a developer can swap a Claude or GPT API key for a Qwen 3.6 Plus key and keep the same harness, prompts, and workflow. Vercel AI Gateway also lists Qwen 3.6 Plus, lowering integration friction further for Next.js teams.
Qwen 3.6 Pricing in 2026
Qwen 3.6 has a hybrid pricing model. The open-weight variants are free under Apache 2.0 (compute costs only); the proprietary tiers run on a token-metered API priced through Alibaba Cloud Model Studio with passthrough on OpenRouter and Vercel AI Gateway.
| Variant | Price | Key Features |
|---|---|---|
| Qwen3.6-27B (open weight) | $0 — Apache 2.0 | 27B dense, 262K context (1M with YaRN), 77.2% SWE-bench Verified, FP8 build for H100/RTX 4090 self-hosting |
| Qwen3.6-35B-A3B (open weight) | $0 — Apache 2.0 | 35B total / 3B active MoE, 262K context, 73.4% SWE-bench Verified at 3B active |
| Qwen 3.6 Flash | $0.25 per 1M input + $1.50 per 1M output | 1M context, 65K max output, multimodal text/image/video, tiered above 256K |
| Qwen 3.6 Plus | $0.325 per 1M input + $1.95 per 1M output | 1M context, multimodal, agentic coding, visual coding from screenshots and wireframes |
| Qwen 3.6 Max Preview | $1.30 per 1M input + $1.30 per 1M output | 256K context, preserve_thinking, top of 6 coding benchmarks at launch, preview status |
| Enterprise / Volume | Contact Alibaba Cloud sales | Custom rate cards, dedicated capacity, EU/SG region routing options on Model Studio |
Best for: teams that want a proprietary frontier API at roughly one-fifth of GPT-5.5 or Claude Sonnet 4.6 cost, plus an Apache 2.0 fallback they can self-host the day a procurement review demands data residency.

The Open-Source Angle — Why Apache 2.0 Matters
The license is the story. Apache 2.0 with no revenue threshold separates Qwen 3.6 cleanly from Llama 4 (Community License with 700M MAU clause) and Stability AI's Community License (capped at 1M dollars revenue). For a startup building on top of an open-weight LLM, Qwen3.6-27B and Qwen3.6-35B-A3B let you ship a derivative product, fine-tune on proprietary data, and resell — without ever crossing a license tripwire.
Hugging Face hosts both variants with FP8 quantizations for the 27B (Qwen/Qwen3.6-27B-FP8), making single-GPU H100 self-hosting realistic. ModelScope mirrors all weights for users in China where Hugging Face access is restricted. Self-hosting is supported through vLLM, SGLang, Ollama, and llama.cpp. The community at r/LocalLLaMA has run extensive comparisons against DeepSeek V4 (also released April 2026) and the legacy Llama 4 weights — the consensus position is that Qwen3.6-35B-A3B punches well above its 3B active parameter weight class while DeepSeek V4 dominates raw coding benchmarks at 1.6T parameters but requires far more compute to self-host. The reasoning-specialist DeepSeek R2 remains a separate lineage focused on chain-of-thought rather than raw scaling.
Why does this matter strategically in April 2026? Meta's Muse Spark pivot to closed-source killed the Llama open-weight roadmap. DeepSeek V4 is open-weight under MIT but its 1.6T MoE is impractical for most self-hosters. Qwen 3.6 sits in the gap: flagship-grade reasoning and coding scores at sizes most teams can actually deploy, under the most permissive license available on a frontier-tier model in 2026.
Pros and Cons After Research
What we liked
- Apache 2.0 with no revenue threshold. The most permissive flagship LLM license in April 2026. Beats Llama 4 Community License (700M MAU clause) and Stability AI Community License (1M dollars revenue cap). You can ship derivatives commercially without lawyer review.
- Plus pricing crushes Western proprietary frontier. 0.325 dollars per 1M input plus 1.95 dollars per 1M output is roughly 5x cheaper than GPT-5.5 and Claude Sonnet 4.6 for comparable agentic coding throughput. At scale this is the difference between unit economics that work and unit economics that don't.
- 1M-token native context on Plus and Flash. Genuinely useful for full-codebase analysis, multi-document synthesis, and long-form video reasoning. Only Llama 4 Scout's 10M and Gemini 3.1 Pro Preview's 2M context windows beat it among flagships.
- Best-in-class per-active-parameter efficiency. Qwen3.6-35B-A3B at 73.4% SWE-bench Verified with 3B active parameters is industry-leading. The 27B dense at 77.2% SWE-bench Verified plus 53.5 SWE-bench Pro plus 59.3 Terminal-Bench 2.0 is competitive with the closed-weight frontier.
- Out-of-the-box compatibility with OpenClaw, Claude Code, Cline. Drop-in replacement at the API layer for teams already on Anthropic or OpenAI tooling.
- preserve_thinking is a genuine product innovation. Maintaining reasoning traces across turns matters for long agentic workflows where context truncation otherwise erases scaffolding. Currently Max Preview only.
Where it falls short
- Plus and Max Preview are closed weights, China-hosted by default. EU and US enterprises with data residency requirements on regulated workloads have to either self-host the open variants or negotiate regional routing through Alibaba Cloud Model Studio. Adds procurement friction.
- Reasoning topline trails the Western frontier. Plus and Max Preview land mid-tier on the AA Intelligence Index — solid but below GPT-5.5 and Gemini 3.1 Pro Preview at the top of the 2026 leaderboard. For pure reasoning ceiling, Qwen 3.6 is not the answer.
- English documentation lags Chinese. Some technical details and benchmark methodology surface first in Chinese on ModelScope before getting an English follow-up. Less of an issue for the open weights (Hugging Face model cards are bilingual) but slows enterprise evaluation cycles.
- Max Preview is preview status. Weights, pricing, and feature surface (including preserve_thinking) may shift before stable release. Production teams should pin to Plus or the open weights for reliability.
Real-World Use Cases
Self-hosted agentic coding on a single H100
Qwen3.6-27B-FP8 fits on an H100 80GB with room for a healthy KV cache. Run it under vLLM with PagedAttention, expose an OpenAI-compatible API endpoint, and point Claude Code or Cline at it. Result: full agentic coding loop without any data leaving the box. The 77.2% SWE-bench Verified score makes this realistic for production work, not a research toy.
Cost-optimized enterprise agent platforms
Teams building internal agent platforms where the unit economics get reviewed every quarter find Qwen 3.6 Plus the only proprietary option that survives. At 0.325 dollars per 1M input, an agent that consumes 10M input tokens per task across a workforce of 1,000 employees costs 3,250 dollars per month — versus 16,000+ dollars per month on GPT-5.5 or Claude Sonnet 4.6 for the same throughput.
Long-context legal and codebase analysis
1M-token context covers most monorepos in a single prompt. Plus's repo-level agentic coding plus the long context means a code review pass over a 500K-line codebase fits in one call. Same logic applies to legal corpora, contract review, and multi-document due diligence.
Multimodal product prototyping
Plus's visual coding takes UI screenshots, hand-drawn wireframes, or Figma exports and returns production-grade frontend code. Useful for product teams that want to compress the design-to-code handoff. Quality is reportedly close to GPT Image 2 plus Claude Code's combined capabilities for the equivalent task, at a fraction of the cost.
Translation and multilingual content pipelines
Qwen-MT inside the Qwen 3.6 family officially supports 100-plus languages with translation-tuned weights. Useful for international content operations where DeepL costs more and Claude/GPT translation quality varies by language pair.
Research and fine-tuning labs
Apache 2.0 means a research lab can fine-tune Qwen3.6-27B on proprietary data, ship a derivative model commercially, and never trip a license tripwire. The same is not true of Llama 4 above 700M MAU or Stability above 1M dollars revenue.
Latency-tolerant batch processing
Plus throughput at 52.8 tokens per second and 2.80s time-to-first-token is not winning latency benchmarks, but for batch document classification, long-form generation, and offline data enrichment, the price-per-call advantage dominates.
Qwen 3.6 vs DeepSeek V4 vs Llama 4 vs Mistral Large 3
The 2026 open-weight and cost-optimized proprietary LLM landscape has four credible flagships in the same TIER 2 bucket. Here is how Qwen 3.6 sits among them.
| Feature | Qwen 3.6 (Plus) | DeepSeek V4 (Pro) | Llama 4 (Maverick) | Mistral Large 3 |
|---|---|---|---|---|
| License (open weights) | Apache 2.0 (27B, 35B-A3B) | MIT (Pro, Flash, base, instruct) | Community License (700M MAU clause) | Mistral Research License (non-commercial open) |
| Largest open weights | 35B-A3B (3B active) | 1.6T MoE (49B active Pro) | ~400B Maverick | Closed |
| Proprietary input price | $0.325 per 1M | $0.435 per 1M (Pro discount) | n/a (open only) | $2 per 1M |
| Proprietary output price | $1.95 per 1M | $0.87 per 1M (Pro discount) | n/a | $6 per 1M |
| Native context | 1M (Plus, Flash) | 128K (Pro), 1M (Flash) | 10M (Scout) / 1M (Maverick) | 128K |
| SWE-bench Verified | 77.2% (27B), 73.4% (35B-A3B) | 80.6% (Pro) | ~70% (Maverick) | ~65% |
| Self-host realism | Single H100 (27B FP8) | Multi-node only (1.6T) | 2-4 H100s (Maverick) | n/a |
| Vendor | Alibaba (China) | DeepSeek (China) | Meta (US) | Mistral (France/EU) |
Synthesis: Versus open-source competitors like Google Gemma 4 (Apache 2.0, smaller) or DeepSeek R2 (reasoning specialist) the picture sharpens further. Pick Qwen 3.6 when the priority is Apache 2.0 license freedom plus a single-GPU self-host story plus the cheapest proprietary tier. Pick DeepSeek V4 when raw coding ceiling is the only thing that matters and you have multi-node infrastructure. Pick Llama 4 Scout when 10M context is non-negotiable. Pick Mistral Large 3 when EU sovereignty and a French-headquartered vendor are procurement requirements. Most teams should evaluate Qwen 3.6 first — it covers the broadest cost / license / self-host combination.

Frequently Asked Questions
Is Qwen 3.6 free?
The open-weight variants — Qwen3.6-27B and Qwen3.6-35B-A3B — are free under Apache 2.0, downloadable from Hugging Face Hub and ModelScope. Compute costs apply when you self-host. The proprietary variants — Plus, Flash, and Max Preview — are paid via Alibaba Cloud Model Studio or routed through OpenRouter at metered token pricing. Qwen Chat at qwen.ai/chat offers free interactive use of Plus with rate limits.
How much does Qwen 3.6 Plus cost in 2026?
Qwen 3.6 Plus is priced at 0.325 dollars per 1M input tokens and 1.95 dollars per 1M output tokens on OpenRouter as of late April 2026. That is roughly 5x cheaper than GPT-5.5 and Claude Sonnet 4.6 for comparable agentic coding work. Pricing on Alibaba Cloud Model Studio is similar with possible regional uplift. Volume and enterprise discounts available via Alibaba Cloud sales.
What is the difference between Qwen 3.6 Plus and Max Preview?
Plus is the stable proprietary flagship — 1M context, multimodal, available since April 2 2026. Max Preview is a closed-weight 35B total / 3B active MoE released April 20 2026 with a 256K context that tops six coding benchmarks at launch and introduces the preserve_thinking API parameter for maintaining reasoning traces across turns. Max Preview is preview status — weights, pricing, and feature surface may shift before stable release.
Is Qwen 3.6 open source?
Partially. The 27B dense and 35B-A3B sparse MoE variants are released under Apache 2.0 with no revenue threshold — fully open-weight, commercially usable, fine-tunable, and redistributable. The Plus, Flash, and Max Preview variants are closed-weight proprietary and only available through Alibaba Cloud Model Studio, the Qwen Chat web app, or third-party routers like OpenRouter and Vercel AI Gateway.
Can Qwen 3.6 run locally?
Yes — the open-weight variants run locally. Qwen3.6-27B-FP8 fits on a single H100 80GB or 2x RTX 4090 setup. Qwen3.6-35B-A3B (3B active) runs on consumer-grade hardware via Ollama, llama.cpp, or vLLM. The proprietary Plus, Flash, and Max Preview variants cannot run locally — they are API-only through Alibaba Cloud or OpenRouter.
How does Qwen 3.6 compare to DeepSeek V4?
DeepSeek V4 leads raw coding ceiling — 80.6% SWE-bench Verified on the 1.6T Pro variant versus 77.2% on Qwen3.6-27B and 73.4% on Qwen3.6-35B-A3B. Qwen 3.6 wins on accessibility — its open-weight variants are practical to self-host, while DeepSeek V4 Pro at 1.6T parameters requires multi-node infrastructure. License is similar (Apache 2.0 vs MIT). Pricing favors DeepSeek V4 Pro discount tier slightly until May 31 2026.
What context window does Qwen 3.6 support?
Plus and Flash both support a 1,000,000 token native context window. Max Preview is 256,000 tokens. The open-weight 27B and 35B-A3B variants support 262,144 tokens natively, extensible to roughly 1,010,000 tokens via YaRN scaling. Tiered pricing on Flash and Plus kicks in above 256K tokens.
Does Qwen 3.6 support multimodal input?
Yes. Plus accepts text, images (including high-density document parsing and physical-world visual analysis), and long-form video. Flash accepts text, image, and video. Max Preview is text-focused. The open-weight 27B and 35B-A3B variants are text-only at release; multimodal extensions ship separately as Qwen-Image-Edit and related models in the broader Qwen family.
Is Qwen 3.6 secure for enterprise use?
The open-weight variants are fully self-hostable, which gives complete data control. The proprietary Plus, Flash, and Max Preview variants are hosted by Alibaba Cloud — primarily in China with regional routing options for Singapore and selected international regions on Model Studio. EU and US enterprises with data residency requirements should evaluate either the self-hosted open weights or negotiate region-pinned routing through Alibaba Cloud sales before production deployment on regulated workloads.
What languages does Qwen 3.6 support?
Qwen 3.6 officially supports more than 100 languages through the broader Qwen family, with Qwen-MT specifically tuned for translation-quality output. Strong coverage on English, Simplified and Traditional Chinese, Japanese, Korean, French, German, Spanish, Portuguese, Italian, Russian, and Arabic. Quality varies by language pair and benchmark — community testing on r/LocalLLaMA suggests it is competitive with DeepL on the major European pairs and stronger than Llama 4 on East Asian languages.
Does Qwen 3.6 have an API?
Yes. The Qwen 3.6 family is accessible through the Alibaba Cloud Model Studio API, the Qwen API on OpenRouter (Plus, Flash, Max Preview routed), the Vercel AI Gateway (Plus listed), and standard self-hosted OpenAI-compatible endpoints when running the open weights under vLLM or SGLang. Compatible with OpenClaw, Claude Code, and Cline harnesses out of the box.
Who founded Qwen?
The Qwen team is part of Alibaba Group, with research leadership from Alibaba's DAMO Academy and the Qwen team inside Alibaba Cloud Intelligence. The team has shipped the Qwen series since 2023, releasing Qwen2 in 2024, Qwen 3 in 2025, and the Qwen 3.6 generation across April 2026. Public face of the team includes researchers active on Hugging Face and the qwenlm.github.io blog.
Verdict: 8.5 out of 10

Qwen 3.6 earns a 8.5 out of 10 on three things — Apache 2.0 with no revenue threshold on flagship-grade open weights, the cheapest credible proprietary frontier API in 2026 at 0.325 dollars per 1M input on Plus, and genuinely state-of-the-art per-active-parameter efficiency from the 35B-A3B sparse MoE. What raises the score is the combination — most open-weight families nail one of those three, almost none nail all three. What's holding it back from higher: reasoning topline trails GPT-5.5 and Gemini 3.1 Pro Preview at the AA Intelligence Index frontier, Plus is China-hosted by default with data residency caveats, and Max Preview is preview status with potential weight and pricing shifts before stable release.
Score breakdown:
- Features: 8.8 out of 10 — full multimodal stack, 1M context, preserve_thinking innovation, repo-level agentic coding
- Ease of Use: 8.0 out of 10 — drop-in OpenAI-compatible API plus OpenClaw / Claude Code / Cline harness compatibility, but English documentation lags Chinese
- Value: 9.2 out of 10 — best price-to-performance on a flagship API in 2026 plus Apache 2.0 free open weights
- Support: 7.8 out of 10 — Alibaba Cloud Model Studio is enterprise-grade but China-headquartered with regional routing required for EU/US data residency
Final word: If you are building agentic coding pipelines, internal LLM platforms, or self-hosted research stacks and you care about license freedom plus unit economics plus a flagship-grade coding ceiling — Qwen 3.6 should be at the top of your evaluation list in April 2026. The 27B FP8 build on a single H100 covers the self-host scenario, Plus at 0.325 dollars per 1M input covers the proprietary scenario, and Apache 2.0 covers the legal scenario. Pass if you need the absolute reasoning ceiling — GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro Preview still lead the frontier on the AA Intelligence Index. Last researched: April 2026.
Key Features
Pros & Cons
Pros
- Apache 2.0 open weights for the 27B and 35B-A3B variants — full commercial use, fine-tunable, self-hostable on Hugging Face and ModelScope, no $1M revenue threshold like Llama 4 Community License.
- Best-in-class price-to-performance on the proprietary side — Qwen 3.6 Plus at $0.325 per 1M input and $1.95 per 1M output is roughly 5x cheaper than GPT-5.5 and Claude Sonnet 4.6 for comparable agentic coding work.
- Massive 1M-token native context window on Plus and Flash variants — covers entire monorepos in a single prompt without retrieval gymnastics.
- Genuine state-of-the-art agentic coding scores: 35B-A3B hits 73.4% SWE-bench Verified with only 3B active parameters; 27B dense reaches 77.2% SWE-bench Verified plus 53.5 SWE-bench Pro and 59.3 Terminal-Bench 2.0 (matching Claude Opus 4.5 territory).
- Multimodal stack matures with Qwen-Image-Edit, Qwen-MT translation, and visual coding from screenshots/wireframes/prototypes — covered under the same family.
- preserve_thinking API parameter on Max Preview maintains internal reasoning traces across turns, useful for long agentic workflows where context budget would otherwise erase scaffolding.
- Compatible out of the box with OpenClaw, Claude Code, and Cline — no proprietary IDE lock-in like some Western flagships.
Cons
- Plus and Max Preview are closed-weights — Plus requires Alibaba Cloud Model Studio access, Max remains a preview with potential weight, pricing, and feature shifts before stable release.
- Reasoning topline is solid but not market-leading: Plus AA Intelligence Index 50, Max Preview 52 — both behind GPT-5.5 (~70) and Gemini 3.1 Pro Preview at the frontier on the same benchmark family.
- Documentation in English is thinner than DeepSeek's or Meta's open-weight model cards; some technical details still surface first in Chinese on ModelScope before English follow-up.
- China-based hosting raises data residency questions for European and US enterprises shipping regulated workloads — self-host the open variants if that matters.
- Output throughput on Plus measured at 52.8 tokens per second by Artificial Analysis is decent but trails Cerebras-hosted DeepSeek and Groq-hosted Llama 4 by a wide margin for latency-sensitive use cases.
Best Use Cases
Platforms & Integrations
Available On
Integrations
Compare Qwen 3.6

We're developers and SaaS builders who use these tools daily in production. Every review comes from hands-on experience building real products — DealPropFirm, ThePlanetIndicator, PropFirmsCodes, and many more. We don't just review tools — we build and ship with them every day.
Written and tested by developers who build with these tools daily.
Frequently Asked Questions
What is Qwen 3.6?
Alibaba's flagship LLM family — Plus and Max Preview proprietary plus Apache 2.0 open-weight 27B and 35B-A3B.
How much does Qwen 3.6 cost?
Qwen 3.6 has a free tier. All features are currently free.
Is Qwen 3.6 free?
Yes, Qwen 3.6 offers a free plan.
What are the best alternatives to Qwen 3.6?
Top-rated alternatives to Qwen 3.6 include Claude Code (9.9/10), Cursor (9.5/10), Claude Opus 4.7 (9.4/10), Veo 3.1 (9.4/10) — all reviewed with detailed scoring on ThePlanetTools.ai.
Is Qwen 3.6 good for beginners?
Qwen 3.6 is rated 8/10 for ease of use.
What platforms does Qwen 3.6 support?
Qwen 3.6 is available on Web (qwen.ai/chat), REST API (Alibaba Cloud Model Studio), OpenRouter (Plus, Flash, Max Preview routed), Self-hosted (Hugging Face Hub, ModelScope, vLLM, Ollama, llama.cpp).
Does Qwen 3.6 offer a free trial?
Yes, Qwen 3.6 offers a free trial.
Is Qwen 3.6 worth the price?
Qwen 3.6 scores 9.2/10 for value. We consider it excellent value.
Who should use Qwen 3.6?
Qwen 3.6 is ideal for: Self-hosted agentic coding on a single H100 or 2x RTX 4090 setup using Qwen3.6-27B-FP8 — full repo-level edits without sending source to any vendor., Cost-sensitive enterprise agent workflows where Plus at $0.325 per 1M input is the only proprietary option that survives unit-economics review at scale., Long-context document analysis on multi-million-token codebases or legal corpora using Plus or Flash 1M context., Multimodal product prototyping — feed a Figma screenshot or whiteboard photo to Plus, get production React or Vue components back., Translation pipelines via Qwen-MT for the 100-plus languages the Qwen family officially supports., Research and fine-tuning labs — Apache 2.0 means you can ship a derivative model commercially with no revenue threshold or attribution beyond standard license requirements., Latency-tolerant batch processing where 52 tokens per second on Plus is acceptable and the price per call is the deciding factor..
What are the main limitations of Qwen 3.6?
Some limitations of Qwen 3.6 include: Plus and Max Preview are closed-weights — Plus requires Alibaba Cloud Model Studio access, Max remains a preview with potential weight, pricing, and feature shifts before stable release.; Reasoning topline is solid but not market-leading: Plus AA Intelligence Index 50, Max Preview 52 — both behind GPT-5.5 (~70) and Gemini 3.1 Pro Preview at the frontier on the same benchmark family.; Documentation in English is thinner than DeepSeek's or Meta's open-weight model cards; some technical details still surface first in Chinese on ModelScope before English follow-up.; China-based hosting raises data residency questions for European and US enterprises shipping regulated workloads — self-host the open variants if that matters.; Output throughput on Plus measured at 52.8 tokens per second by Artificial Analysis is decent but trails Cerebras-hosted DeepSeek and Groq-hosted Llama 4 by a wide margin for latency-sensitive use cases..
Best Alternatives to Qwen 3.6



Ready to try Qwen 3.6?
Start with the free plan
Try Qwen 3.6 Free →