
A Huawei-led research team completed full-parameter post-training of DeepSeek V4-Pro, a 1.6-trillion-parameter open-weight model, on a cluster of at least 1,000 Huawei Ascend 910C chips, according to the Shenzhen government and reporting by Tom's Hardware in June 2026. This is the most concrete sign yet that a Chinese frontier-class model can be tuned without NVIDIA silicon. But the widely repeated claim that V4-Pro is "the first frontier model trained without NVIDIA" is misleading. Post-training is not pre-training, the chips used were the older 910C rather than the new Ascend 950, and DeepSeek itself has reportedly found Ascend unattractive for training models from scratch, the heaviest and costliest job. The accurate story is narrower and, in some ways, more revealing about what US export controls have actually produced.
What Actually Happened
In early June 2026, a research group that includes Huawei Technologies announced it had completed full-parameter post-training of DeepSeek-V4-Pro on a cluster of at least 1,000 Huawei Ascend 910C accelerators. The claim was relayed through the Shenzhen government and covered by Tom's Hardware. DeepSeek-V4-Pro is the flagship variant of the V4 family that DeepSeek open-sourced on April 24, 2026 under the MIT license: 1.6 trillion total parameters, 49 billion active per forward pass, a 1-million-token context window, and a reported 80.6% on SWE-bench Verified. It launched as a preview, and DeepSeek has not announced a dated stable release.
The verb matters. The Huawei-led team did not pre-train V4-Pro on Ascend. It ran post-training, the tuning stage that follows the much larger and more expensive pre-training phase and shapes behavior through instruction-following, alignment, and task-specific data. Pre-training a 1.6-trillion-parameter model from scratch is a different order of difficulty, and nothing in the announcement demonstrates that Ascend chips can do that job today.
Separately, Huawei stated on April 24 that its full range of Ascend Supernode products now supports DeepSeek-V4, and that its A3 Supernode "has completed adaptation" to lower the barrier for enterprises to fine-tune V4 models. Read carefully, that is a statement about running and fine-tuning V4 on Ascend, not about where V4 was originally built. V4's pre-training is widely understood to have run on NVIDIA hardware, consistent with DeepSeek's established practice; an earlier attempt to migrate training to Ascend during 2025 reportedly hit a training failure.
Why "Trained Without NVIDIA" Is a Myth
The phrase travels well on social media, and several secondary outlets ran with it. The primary record does not support it as stated. Three precise facts cut against the absolute claim.
First, post-training is not pre-training. As Tom's Hardware put it, completing post-training on Ascend silicon "doesn't demonstrate that the chips can pre-train a frontier model from scratch, which is the heavier and costlier job." Pre-training is where the vast majority of compute is spent, and it is the bottleneck export controls were designed to choke.
Second, the claim carries no benchmarks. The announcement gives no figure for how long the post-training run took, how it compared to the same job on NVIDIA hardware, or how efficiently the 1,000-chip cluster was used. A milestone without a throughput number is a press release, not a benchmark.
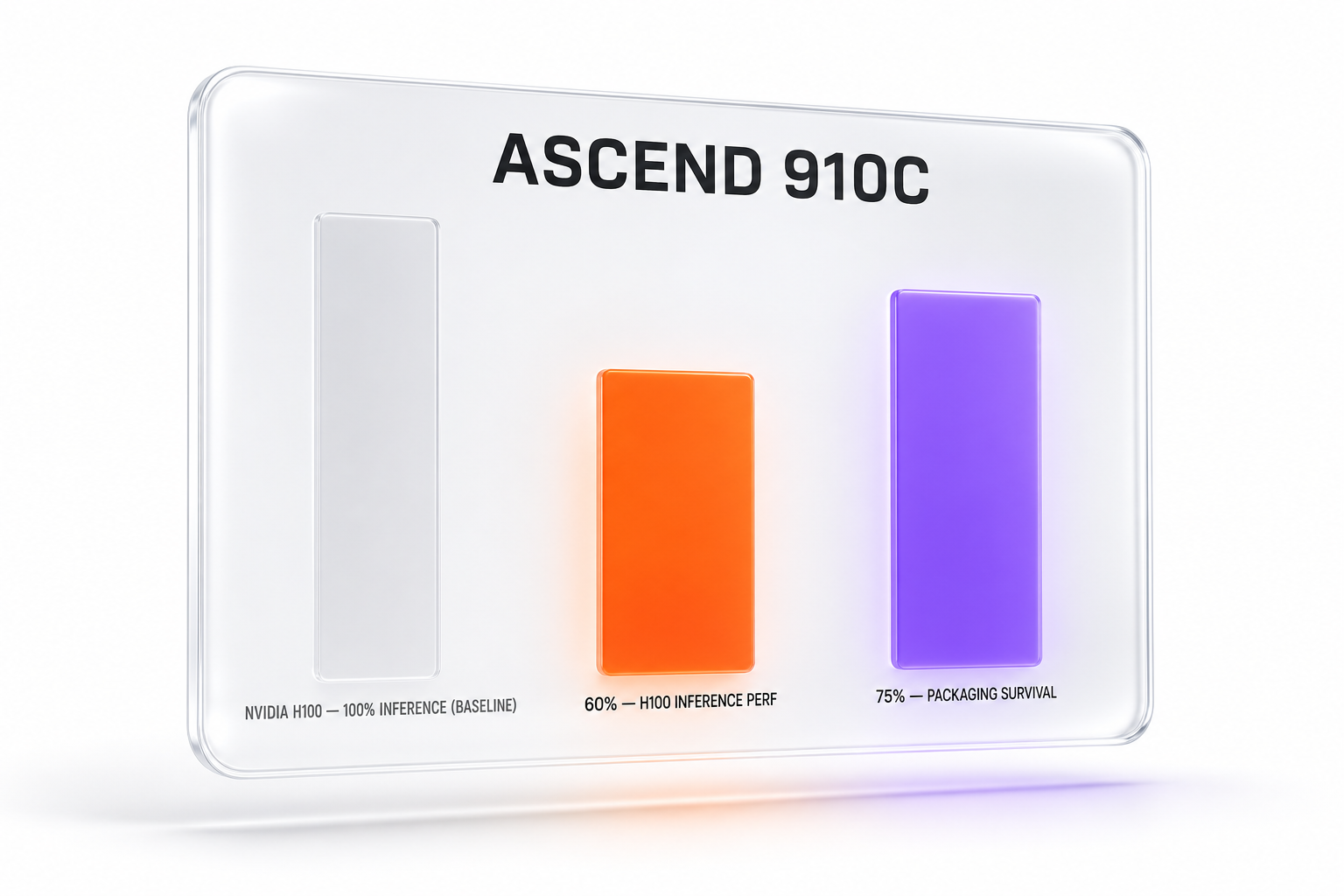
Third, the chips were 910C, not the new 950. The 910C is the generation before Huawei's just-announced 950 family — though, with the training-focused 950DT not yet shipped, it remains Huawei's most capable deployed accelerator for training-class work. Huawei's newer Ascend 950PR shipped for inference in the first quarter of 2026, and the training-focused Ascend 950DT is not scheduled until the fourth quarter of 2026. The post-training run used the older 910C rather than the not-yet-shipped 950, which makes the result more impressive in one sense and less indicative of frontier pre-training in another.

What the Numbers Say About Ascend vs NVIDIA
The most useful figures come from the Center for Strategic and International Studies, which has tracked the export-control story closely. According to CSIS, DeepSeek "has reportedly evaluated the Ascend chips and found that they are unattractive for training AI models," while each Ascend 910C delivers "roughly 60 percent of the performance of an Nvidia H100 for inferencing AI models." That single sentence frames the entire situation: Ascend is a credible inference part and a weak training part, relative to NVIDIA.
Why does that asymmetry matter? Because the market is tilting toward inference. CSIS notes that "by 2026, 70 percent of AI compute demand will come from inference." A chip that reaches 60 percent of an H100 on inference, at domestic prices and with no export risk, is genuinely useful even if it cannot lead on training. China does not need Ascend to win the pre-training race to extract enormous value from it; it needs Ascend to serve the inference majority.
Supply is the other constraint. CSIS reports that government officials said TSMC manufactured "more than 2 million Ascend 910B logic dies" that are now with Huawei, but that "roughly 75 percent of the Ascend 910Cs currently survive the advanced packaging process." A 25 percent loss at packaging is a meaningful tax on volume. Capacity, not raw design, remains the gating factor for how many frontier-scale clusters China can stand up.
The Huawei Ascend Roadmap, Briefly
Huawei laid out a three-year Ascend roadmap at Huawei Connect in September 2025, and the 2026 parts are now arriving. The Ascend 950PR launched in the first quarter of 2026 for prefill inference and recommendation workloads, with 128 GB of HiBL 1.0 memory and 1.6 TB per second of bandwidth. The training-and-decode-focused Ascend 950DT is slated for the fourth quarter of 2026, with 144 GB of HiZQ 2.0 memory and 4 TB per second of bandwidth. Both deliver about 1 PFLOPS in FP8 and 2 PFLOPS in MXFP4, with interconnect bandwidth around 2 TB per second.
The strategic read is straightforward. The 950DT, not the 910C, is the chip Huawei is positioning for serious training. If a future DeepSeek model pre-trains on 950DT clusters in 2027, then "trained without NVIDIA" stops being a myth and becomes a headline. For now, the training-grade hardware has not even shipped, which is exactly why the current claim should be read as a post-training milestone rather than a pre-training breakthrough.
What Export Controls Actually Produced
The US export-control regime was designed to deny China the advanced compute needed to train frontier models. The honest assessment in 2026 is mixed. Controls did not stop DeepSeek from shipping V4, an open-weight model that competes with closed Western frontier systems on price and on several coding benchmarks. What they did, in the CSIS framing, was incentivize "innovation in efficiency" and accelerate a domestic-silicon software stack that did not meaningfully exist two years ago.
The unintended consequence is a surge of capable open-weight Chinese models that any organization can self-host. Because V4 ships under the MIT license, even teams in jurisdictions that restrict the hosted API can run it on hardware they control. Pair that with an inference chip at 60 percent of an H100 and you get the outline of a parallel stack: Chinese weights on Chinese silicon, sold at Chinese prices, increasingly independent of CUDA for the inference workloads that will dominate demand. That is the real signal in the Ascend story, and it is more consequential than any single training claim.
It also reframes the funding side of the picture. The same lab that closed its first external funding round in June 2026 is now the showcase customer for a domestic chip campaign. China's broader compute-sovereignty push, visible in Huawei's advances in 3D chip packaging and in the mirror-image decoupling of talent and tooling, treats models and silicon as a single program. The West is responding with its own open-weight efforts, such as NVIDIA's Nemotron 3 Ultra, and with sovereignty packages like the EU's chips-and-cloud plan.
Pricing and Access
DeepSeek-V4-Pro is open weight under the MIT license, and the hosted API is among the cheapest frontier-class options available. As of late June 2026, DeepSeek's official pricing lists deepseek-v4-pro at about $0.435 per million input tokens on a cache miss, $0.003625 per million input tokens on a cache hit, and $0.87 per million output tokens, with a maximum output of 384K tokens. DeepSeek cut these prices sharply from the launch figures of $1.74 per million input and $3.48 per million output, a roughly four-fold reduction that tracks the broader collapse in token prices through 2026.
For teams comparing options, we maintain a full breakdown in our DeepSeek V4 review and in head-to-head pieces such as GPT-5.5 vs DeepSeek V4, GLM-5.2 vs DeepSeek V4, and Kimi K2.7 vs DeepSeek V4. The smaller DeepSeek R2 remains the lighter reasoning option in the same family.
Our Take
The Ascend post-training milestone is real and worth taking seriously. A Chinese-built accelerator just full-parameter-tuned a 1.6-trillion-parameter model, and the software stack that makes that possible is the part export controls cannot easily touch. But the version of this story that travels fastest is the one that is wrong. V4-Pro was not pre-trained without NVIDIA, the run used the older 910C silicon rather than the new 950, and the claim arrived without a single throughput number. Treating a post-training result as a pre-training breakthrough flatters Huawei and misreads the strategic picture.
The more durable conclusion is about inference, not training. If 70 percent of compute demand is inference, and Ascend reaches 60 percent of an H100 there, then China can build a largely CUDA-independent inference economy long before it can pre-train frontier models on domestic chips. The chip to watch is the Ascend 950DT in the fourth quarter of 2026. If a DeepSeek successor pre-trains on it, the myth becomes the headline. Until then, the precise, sourced version of this story is the one worth citing.
Frequently Asked Questions
What is DeepSeek V4-Pro?
DeepSeek V4-Pro is the flagship variant of DeepSeek's V4 family, open-sourced on April 24, 2026 under the MIT license. It is a Mixture-of-Experts model with 1.6 trillion total parameters and 49 billion active per forward pass, a 1-million-token context window, and a reported 80.6% on SWE-bench Verified. It launched as a preview, and no dated stable release has been announced.
Was DeepSeek V4-Pro really trained without NVIDIA?
Not in the way the headline suggests. A Huawei-led team completed full-parameter post-training of V4-Pro on at least 1,000 Huawei Ascend 910C chips, per the Shenzhen government and Tom's Hardware. But post-training is the lighter tuning stage, not pre-training. V4-Pro's original pre-training is widely understood to have run on NVIDIA hardware, and CSIS reports that DeepSeek has found Ascend "unattractive for training AI models" from scratch.
What is the difference between pre-training and post-training?
Pre-training is the heavy, expensive stage where a model learns from vast amounts of data, and it consumes the large majority of compute. Post-training is the lighter follow-on stage that tunes behavior through instruction-following, alignment, and task-specific data. The Huawei-led Ascend result was post-training, which does not demonstrate that Ascend can pre-train a frontier model from scratch.
What is the Huawei Ascend 910C, and how does it compare to NVIDIA?
The Ascend 910C is the generation before Huawei's just-announced 950 family, and remains its most capable deployed accelerator for training-class work. According to CSIS, each 910C delivers roughly 60 percent of the inference performance of an NVIDIA H100, while remaining weak for training relative to NVIDIA. CSIS also reports that about 75 percent of 910C units survive advanced packaging, a yield bottleneck that limits how many can be built.
What about the new Huawei Ascend 950?
The Ascend 950 is a newer family. The 950PR launched in the first quarter of 2026 for inference, with 128 GB of memory and 1.6 TB per second of bandwidth. The training-focused 950DT is scheduled for the fourth quarter of 2026, with 144 GB of memory and 4 TB per second of bandwidth. The DeepSeek post-training run did not use the 950; it used the older 910C.
Why does this matter if it was only post-training?
Because the AI market is tilting toward inference. CSIS estimates that 70 percent of AI compute demand will come from inference by 2026. A domestic chip that reaches 60 percent of an H100 on inference lets China build a largely CUDA-independent inference economy, even without leading on training. That strategic shift is more consequential than any single training claim.
How much does DeepSeek V4-Pro cost to use?
DeepSeek's official API lists V4-Pro at about $0.435 per million input tokens on a cache miss, $0.003625 per million input tokens on a cache hit, and $0.87 per million output tokens, with a 384K-token maximum output, as of late June 2026. That is a roughly four-fold cut from the launch prices of $1.74 per million input and $3.48 per million output. The weights are also free to self-host under the MIT license.
Did US export controls cause this?
Largely, yes. Export controls restricted China's access to advanced NVIDIA chips, which CSIS argues incentivized efficiency innovation and accelerated a domestic-silicon software stack. The unintended consequence is a wave of capable open-weight Chinese models, like V4 under the MIT license, that can run on domestic hardware and are increasingly independent of CUDA for inference.
Is DeepSeek V4 better than GPT-5.5 or other frontier models?
It depends on the task. V4-Pro is competitive on coding benchmarks, with a reported 80.6% on SWE-bench Verified, and it is far cheaper than most closed frontier systems. Closed models such as GPT-5.5 or Claude Opus may still lead on certain reasoning tasks. See our comparisons of GPT-5.5 vs DeepSeek V4, GLM-5.2 vs DeepSeek V4, and Kimi K2.7 vs DeepSeek V4 for task-by-task detail.
When could a model actually be pre-trained without NVIDIA?
The chip to watch is Huawei's Ascend 950DT, the training-and-decode part scheduled for the fourth quarter of 2026. If a future DeepSeek model pre-trains from scratch on 950DT clusters in 2027, then "trained without NVIDIA" would move from myth to headline. As of mid-2026, the training-grade Ascend hardware has not yet shipped.



