AI agent costs are now driven by token consumption, not seat count, and for some heavy-usage engineering teams the compute bill can rival or exceed a salary. According to a Fortune report from May 22, 2026, Microsoft began canceling most of its direct Claude Code licenses roughly six months after granting them, moving engineers in its Experiences and Devices division toward GitHub Copilot CLI by a June 30, 2026 deadline. The story is not a clean verdict that AI is more expensive than humans; it is a snapshot of how unpredictable agentic token spending is colliding with enterprise budgets that were built for fixed per-seat software.
The headline that traveled fastest — "AI sometimes costs more than an employee" — is real but narrow. It comes from a specific quote, a specific set of usage patterns, and a moment when several large organizations discovered that agentic coding tools do not behave like the seat-based SaaS they replaced. This is an analysis of the cost dynamics underneath that headline: what actually changed, what Microsoft did and did not say, and what teams deploying AI agents in 2026 should take away from it.
What Happened: Microsoft's Claude Code Pullback
According to Fortune's May 22, 2026 reporting, recoupled with coverage from Windows Central and TechRadar, Microsoft started canceling most of the direct Claude Code licenses it had handed to engineers in its Experiences and Devices group. The licenses were reportedly granted around December 2025; the cancellations began roughly six months later. Affected engineers were directed to GitHub Copilot CLI instead, with a deadline of June 30, 2026 to stop using Claude Code — a date that aligns neatly with the close of Microsoft's fiscal year.
Two things matter about the framing here. First, this is a move within one division, not a company-wide ban, and Microsoft has not publicly stated a financial motive for the change. Second, it is not a rupture with Anthropic. Anthropic's Claude models — Sonnet 4.5, Opus 4.1, and the faster, cheaper Haiku tier — remain available inside GitHub Copilot CLI. So engineers losing standalone Claude Code access can, in many cases, still reach the same underlying models through Microsoft's own tool. The shift is about which front door the spend flows through, and how that spend is metered, far more than it is about which lab's model wins.
The reported per-engineer cost of running Claude Code at scale — roughly $500 to $2,000 per month per engineer in heavy-usage scenarios — is what gave the story its charge. At the top of that band, a single engineer's tooling can approach a meaningful fraction of a junior salary in some markets. But that number is a consumption figure, not a license fee, and that distinction is the entire point.
The Quote That Defined the Story
The most-cited line in the coverage did not come from Microsoft at all. It came from Bryan Catanzaro, VP of Applied Deep Learning at Nvidia, who said: "For my team, the cost of compute is far beyond the costs of the employees." Read carefully, that is a statement about one team's specific economics — a research group running enormous compute workloads — not a general law about software engineering.
It resonated because it inverted an assumption that has held for decades: that people are the expensive line item and software is the cheap leverage on top of them. For most of the SaaS era, a developer tool cost tens of dollars per seat per month while the developer cost thousands. Agentic AI breaks that ratio in specific, high-intensity workloads, because the tool no longer sits idle between keystrokes. It runs loops, reads large codebases, calls other tools, and burns tokens continuously while it works. When the work is heavy enough, the meter can climb past the human.

Per-Seat Versus Per-Use: The Structural Shift
The cleanest way to understand this story is as a change in the unit of cost. Traditional developer software was priced per seat. You bought a license per engineer, you knew the number months in advance, and the cost was flat whether the engineer used the tool for ten minutes or ten hours. Budgeting was an arithmetic problem: headcount multiplied by seat price.
Agentic AI tools are priced, fundamentally, per token. Even when a vendor wraps them in a monthly subscription, the underlying economics are metered. An agent that reads an entire repository, plans a multi-step refactor, runs tests, reads the failures, and tries again can consume tokens in volumes that vary wildly between engineers and between days. The same seat that costs almost nothing in a quiet week can cost hundreds of dollars in a sprint. The budgeting problem stops being arithmetic and becomes forecasting — and forecasting consumption is far harder than counting seats.
This is why the Microsoft story landed as more than a procurement footnote. It is an early, visible instance of a large organization confronting the gap between how it buys software and how AI agents actually consume resources. A per-seat mental model applied to a per-use product produces budget surprises, and budget surprises produce procurement decisions like the one Microsoft reportedly made.
Uber Burned a Year of Budget in Four Months
Microsoft is not the only large company to hit this wall. Uber's CTO, Praveen Neppalli Naga, reported that the company exhausted its entire 2026 budget for AI coding tools in just four months — by around April 2026. That is a roughly three-fold overrun against plan, and it happened not because anyone made a mistake in the spreadsheet but because the consumption curve of agentic tools bent far steeper than the seat-based assumptions the budget was built on.
The Uber data point is, in some ways, more instructive than the Microsoft one, because there is no ambiguity about what happened: a real budget, set for a real year, ran out in a third of the time. It is the clearest available illustration that the cost of agentic coding is not just high, it is hard to predict. When usage is elastic and tied to how aggressively engineers lean on agents, a budget set in January can be a fiction by April.


The 24x Token Explosion Goldman Sachs Sees Coming
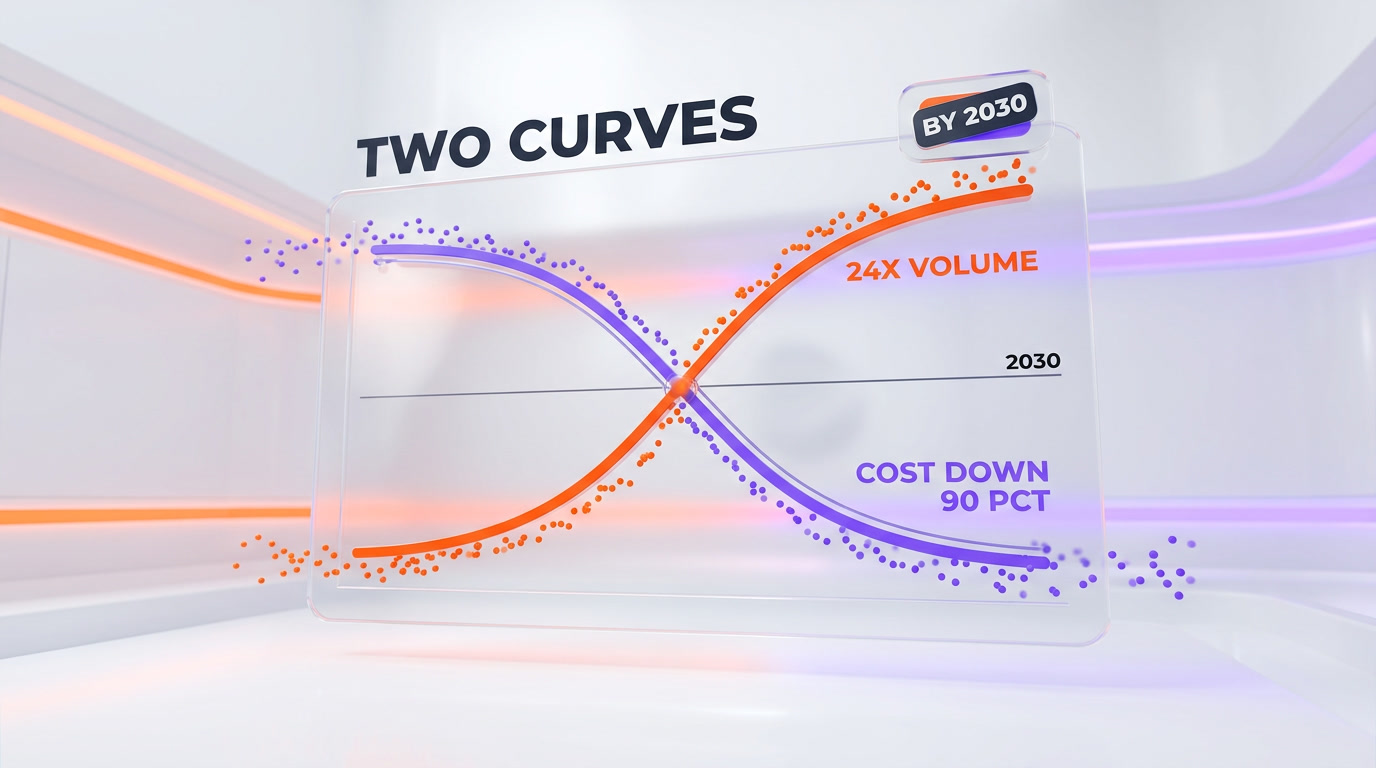
If individual budgets are already straining, the macro forecast suggests the pressure is structural. Goldman Sachs projects that agentic AI could drive an approximately 24x increase in token consumption by 2030, targeting a figure on the order of 120 quadrillion tokens per month across the industry. The mechanism is straightforward: agents do not ask a single question and stop. They reason in loops, they call tools, they spawn sub-tasks, and each step is more tokens. A workflow that a human might describe in one prompt can expand into thousands of model calls under the hood.
This is the difference between using a model as a chatbot and deploying it as an agent. Chat is bounded by human typing speed and patience. Agentic execution is bounded only by the task and the budget. When you multiply that across an entire engineering organization — and then across every organization adopting agents — you get a consumption curve that bends sharply upward. Goldman's 24x is not a prediction that costs will rise 24x; it is a prediction that volume will. What happens to total cost depends on what happens to the price of each token, which is the other half of the equation.
The Other Side: Gartner Sees Inference Costs Falling ~90%
Here is the part the viral headline tends to drop. Gartner analyst Will Sommer projects that the inference cost for trillion-parameter LLMs will fall by nearly 90% by 2030 compared to 2025. Hardware is getting faster and cheaper per unit of compute, model serving is getting more efficient, and competition among labs is pushing per-token prices down. So while volume may rise roughly 24x, the price of each token may fall by close to an order of magnitude over the same window.
Those two trends partly cancel. A naive multiplication — 24x more tokens at one-tenth the price — lands somewhere around a 2.4x increase in total spend, not a runaway explosion. That is a real increase, but it is a manageable one for organizations that plan for it. The honest read is that token economics in 2026 is a story of two curves moving in opposite directions, and the outcome for any given team depends on where they sit between them.
But Gartner attaches a sharp caveat, and it is the most important nuance in the entire debate: cheaper commodity tokens do not mean cheaper frontier reasoning. The 90% decline applies to the bulk, undifferentiated inference that gets cheaper as it commoditizes. The hardest reasoning — the frontier work that agents lean on for complex, multi-step problem solving — does not commoditize the same way. Frontier capability stays scarce and stays expensive, because the demand for the best reasoning rises right alongside the supply of cheap commodity tokens.
Why "AI Costs More Than a Human" Is the Wrong Takeaway
It is worth being precise here, because the framing matters. The data does not support a clean conclusion that AI is more expensive than employees. What the data supports is narrower and more useful: for certain high-intensity, high-consumption workloads, the compute cost of running agents can exceed the cost of the people who would otherwise do the work — and that cost is far harder to predict than a payroll line.
Catanzaro's quote was about his team. Microsoft's pullback was within one division and came without a stated financial reason. Uber's overrun was a budgeting variance, not a declaration that engineers are now cheaper than tools. String those together and you get a real phenomenon — agentic token spend is large and volatile — but not the sweeping verdict the headline implies. The interesting story is the volatility, not a tidy human-versus-machine cost comparison.
There is also a strategic reading of Microsoft's move that has nothing to do with cost at all. Microsoft owns GitHub Copilot. Standardizing its own engineers on Copilot CLI consolidates usage onto a first-party product, gives it cleaner telemetry on how its tooling performs, and reduces dependency on a competitor's standalone client — all while keeping access to the same underlying Claude models through that first-party surface. The June 30 deadline aligning with fiscal year-end is consistent with a planned platform consolidation as much as with any cost-cutting narrative.
Claude Code Versus GitHub Copilot CLI: What Actually Changed for Engineers
For the engineers affected, the practical change is the interface and the metering, not necessarily the intelligence. Claude Code is Anthropic's standalone terminal agent, billed directly against Anthropic usage. GitHub Copilot CLI is Microsoft's terminal agent, billed within the Copilot ecosystem — and it can route to Claude models including Sonnet 4.5, Opus 4.1, and Haiku, alongside other providers.
So an engineer moved from Claude Code to Copilot CLI can often still reach Claude. What changes is the billing relationship, the governance layer, and the consumption controls Microsoft can apply on its own platform. That is precisely the kind of control a large organization wants when usage is volatile: a single pane to see spend, set limits, and route work to the cheapest model that can do the job. The move reads less like "Anthropic out, Microsoft in" and more like "consolidate the spend where we can govern it." For a broader look at how Microsoft is positioning Copilot as an agentic platform rather than a chat assistant, our coverage of Microsoft Copilot Cowork's move from chat to autonomous task execution tracks the same consolidation logic, and the scale of that push is clear in Copilot crossing 20 million paying users.
The Real Lesson: Plan for Consumption, Not Seats
The actionable takeaway for any team deploying AI agents in 2026 is to stop budgeting agents like seat-based SaaS and start budgeting them like cloud compute. The discipline that organizations learned the hard way with AWS bills a decade ago is the same discipline agentic AI now demands: meter everything, set per-team and per-engineer budgets, alert on anomalies, and route the bulk of work to cheaper models while reserving frontier reasoning for the tasks that truly need it.
Concretely, that means a few things. Track token consumption at the team and individual level, not just the aggregate. Cap budgets with hard or soft limits so a single runaway agent loop does not consume a quarter's allowance in a weekend. Use model routing aggressively — a Haiku-class model for routine work and an Opus-class model only where the reasoning depth pays for itself. And treat the per-engineer cost as a range, not a number: somewhere between near-zero in a quiet week and several hundred dollars in a heavy sprint.
This is also why governance-first tooling is winning enterprise mindshare. The teams shipping agent platforms with built-in cost controls, multi-model routing, and per-repository configuration are responding directly to the budget-surprise problem. The same dynamic is visible across the coding-agent market — from the way xAI's Grok Build is being positioned against Claude Code and OpenAI Codex to how OpenAI is extending Codex onto mobile control surfaces. The competition is increasingly about who governs consumption best, not just who reasons best.

The Billing Layer Is Where the Battle Moves Next
If the cost of running agents is the new constraint, then the billing and metering layer becomes strategically central — and the vendors know it. Pricing model changes, usage caps, and consumption dashboards are no longer back-office details; they are product features that determine whether an enterprise can adopt agents at scale without budget shock. We have already seen developers forced to re-plan around shifting billing terms, as in the Claude Agent SDK billing changes landing June 15, 2026, and seen vendors expand raw capacity to keep heavy users productive, as Anthropic did when it doubled Claude Code limits on the back of the SpaceX Colossus 1 compute deal.
The pattern is consistent: as agents consume more, the contest shifts from model quality alone toward who can deliver predictable, governable, well-priced consumption. The lab with the smartest model does not automatically win the enterprise if its spend is impossible to forecast. That is the deeper signal in Microsoft's pullback — predictability is becoming a feature, and the platforms that deliver it will capture the heavy-usage teams that drive the bills.
What This Means for the Broader AI Labor Debate
It is tempting to fold this story into the larger narrative about AI replacing workers, but the token-economics story actually complicates that narrative rather than confirming it. If the compute cost of an aggressive agent can rival a salary in heavy workloads, then the case for wholesale human replacement weakens precisely where it was supposed to be strongest. The economics only favor agents decisively when token prices fall far enough — which is exactly what Gartner projects, but not uniformly across commodity and frontier work.
That tension shows up in how companies are restructuring. Organizations betting hard on agents are simultaneously discovering the bills, which is why the more sober adopters are pairing agent rollouts with strict consumption governance rather than headcount-for-tokens swaps. The broader restructuring debate — visible in moves like ClickUp's bet on 3,000 AI agents alongside a 22% workforce cut — runs straight into the same constraint Microsoft and Uber hit: agents are not free, and at scale they are not cheap, and their cost is volatile. The labor math and the token math are now inseparable.
The Bottom Line
Microsoft's decision to cancel most of its direct Claude Code licenses and consolidate engineers onto GitHub Copilot CLI by June 30, 2026 is best understood as a snapshot of a structural shift, not a verdict. The shift is from per-seat pricing, which is predictable, to per-use token consumption, which is not. The reported $500 to $2,000 per month per engineer for heavy Claude Code usage, Uber's full-year budget burned in four months, and Catanzaro's compute-beats-employees quote all point to the same underlying fact: agentic AI consumes resources in volumes that are large and hard to forecast.
But the counterweight is real. Goldman Sachs sees roughly 24x more tokens by 2030; Gartner sees inference costs for trillion-parameter models falling nearly 90% over a comparable window — with the crucial caveat that frontier reasoning will not commoditize like bulk tokens. Net, total spend is likely to rise, but not explode, for teams that plan for consumption rather than seats. Microsoft has not stated a financial motive, the move keeps Claude models reachable inside Copilot CLI, and the cleanest takeaway is operational: budget your agents like cloud compute, meter everything, route aggressively, and treat per-engineer cost as a range. The companies that internalize that will deploy agents at scale without the budget shock that defined the spring of 2026.
Frequently Asked Questions
Did Microsoft ban Claude Code?
No. According to Fortune's May 22, 2026 report, Microsoft began canceling most of its direct Claude Code licenses for engineers in its Experiences and Devices division, with a June 30, 2026 deadline to move to GitHub Copilot CLI. It is a division-level consolidation, not a company-wide ban, and Microsoft has not publicly stated a financial motive. Claude models remain reachable inside Copilot CLI.
Is this a break between Microsoft and Anthropic?
Not a clean one. Anthropic's Claude models — Sonnet 4.5, Opus 4.1, and Haiku — remain available inside GitHub Copilot CLI, so engineers moved off the standalone Claude Code client can often still reach the same underlying models through Microsoft's own tool. The change is about which front door the spend flows through and how it is metered, not which lab's model is used.
How much does Claude Code cost per engineer?
Corroborating reports cite roughly $500 to $2,000 per month per engineer in heavy-usage scenarios. That is a consumption figure, not a flat license fee, so it varies widely between engineers and between weeks depending on how aggressively agents are used. A quiet week can cost almost nothing; a heavy sprint can hit the top of that band.
Does AI really cost more than an employee?
Only in specific, high-intensity workloads. Nvidia's Bryan Catanzaro said "for my team, the cost of compute is far beyond the costs of the employees," but that describes one compute-heavy team, not a general rule. The accurate framing is that agentic token spend can rival or exceed a salary in heavy usage and is much harder to predict — not that AI is universally more expensive than people.
What happened with Uber's AI coding budget?
Uber's CTO Praveen Neppalli Naga reported that the company exhausted its entire 2026 budget for AI coding tools in just four months, by around April 2026 — roughly a three-fold overrun. It is the clearest illustration that agentic tooling cost is not only high but hard to forecast, because consumption is elastic and tied to how heavily engineers lean on agents.
What is the difference between per-seat and per-use pricing for AI tools?
Per-seat pricing charges a fixed fee per user regardless of usage, making budgets a simple headcount calculation. Per-use pricing meters actual token consumption, so the same seat can cost near-zero in a quiet week and hundreds of dollars in a heavy sprint. Agentic AI is fundamentally per-token even when wrapped in a subscription, which turns budgeting from arithmetic into forecasting.
How much will token consumption grow by 2030?
Goldman Sachs projects that agentic AI could drive an approximately 24x increase in token consumption by 2030, targeting roughly 120 quadrillion tokens per month industry-wide. The driver is agentic execution: agents reason in loops, call tools, and spawn sub-tasks, so a single human request can expand into thousands of model calls under the hood.
Are AI inference costs going up or down?
Both volume and price are moving, in opposite directions. Volume is projected to rise roughly 24x by 2030 (Goldman Sachs), while Gartner analyst Will Sommer projects inference cost for trillion-parameter LLMs falling nearly 90% by 2030 versus 2025. The two trends partly cancel, so total spend likely rises moderately rather than exploding — for teams that plan for it.
What is Gartner's warning about cheaper tokens?
Gartner cautions that cheaper commodity tokens do not mean cheaper frontier reasoning. The projected ~90% inference cost decline applies to bulk, undifferentiated inference that commoditizes over time. The hardest multi-step reasoning that agents rely on stays scarce and expensive, because demand for the best reasoning rises alongside the supply of cheap commodity tokens.
What is the difference between Claude Code and GitHub Copilot CLI?
Claude Code is Anthropic's standalone terminal coding agent, billed directly against Anthropic usage. GitHub Copilot CLI is Microsoft's terminal agent, billed within the Copilot ecosystem, and it can route to multiple models including Claude Sonnet 4.5, Opus 4.1, and Haiku. For an engineer, the move between them changes the billing relationship and governance layer more than the underlying intelligence.
How should companies budget for AI agents?
Budget agents like cloud compute, not seat-based SaaS. Meter token consumption at the team and individual level, set hard or soft budget caps so a runaway agent loop cannot burn a quarter's allowance, route routine work to cheaper models like Haiku while reserving frontier models like Opus for tasks that need deep reasoning, and treat per-engineer cost as a range rather than a fixed number.
Why did Microsoft move engineers to its own Copilot CLI?
Beyond any cost angle, Microsoft owns GitHub Copilot, so standardizing engineers on Copilot CLI consolidates usage onto a first-party product, gives cleaner telemetry, and adds consumption controls on a platform it governs — while keeping access to Claude models. The June 30, 2026 deadline aligning with fiscal year-end is consistent with planned platform consolidation as much as cost-cutting.