
Reve 2.0 is a 4K image generation model launched on June 3, 2026 by Reve, an independent research lab of roughly 65 people. Its core idea is to replace the text prompt with a structured "layout" — every element carries a position, a size, and a local description, making the image addressable and editable like code. Reve 2.0 generates native 4096-by-4096 output and ranks second on the Text-to-Image Arena, behind OpenAI's GPT Image 2 and ahead of Google's Nano Banana 2. Reve says it reached that level "trained on 10x fewer GPUs" and with "1/10 to 1/100" the resources of its larger competitors.
That last claim is the part worth sitting with. The frontier of image generation in 2026 has been a contest of capital — OpenAI, Google, and the labs orbiting trillion-dollar balance sheets. Reve 2.0 is a counter-argument: a sub-$1T company shipping the second-best model on a public human-preference leaderboard, built on a different bet about how images should be controlled in the first place. This article breaks down what Reve actually shipped, why the "images as code" framing matters, and where it sits against the models we already cover.
What Happened: Reve Ships a 4K Layout Model
On June 3, 2026, Reve announced Reve 2.0, calling it "the best 4K image model in the world." The headline number is native 4096-by-4096 generation — 16 megapixels in a square frame — which Reve frames as true native generation rather than a low-resolution image followed by an upscale pass. For anyone who has fought with upscaler artifacts on text, fine textures, or repeated patterns, native 4K is a meaningful distinction, not a marketing footnote.
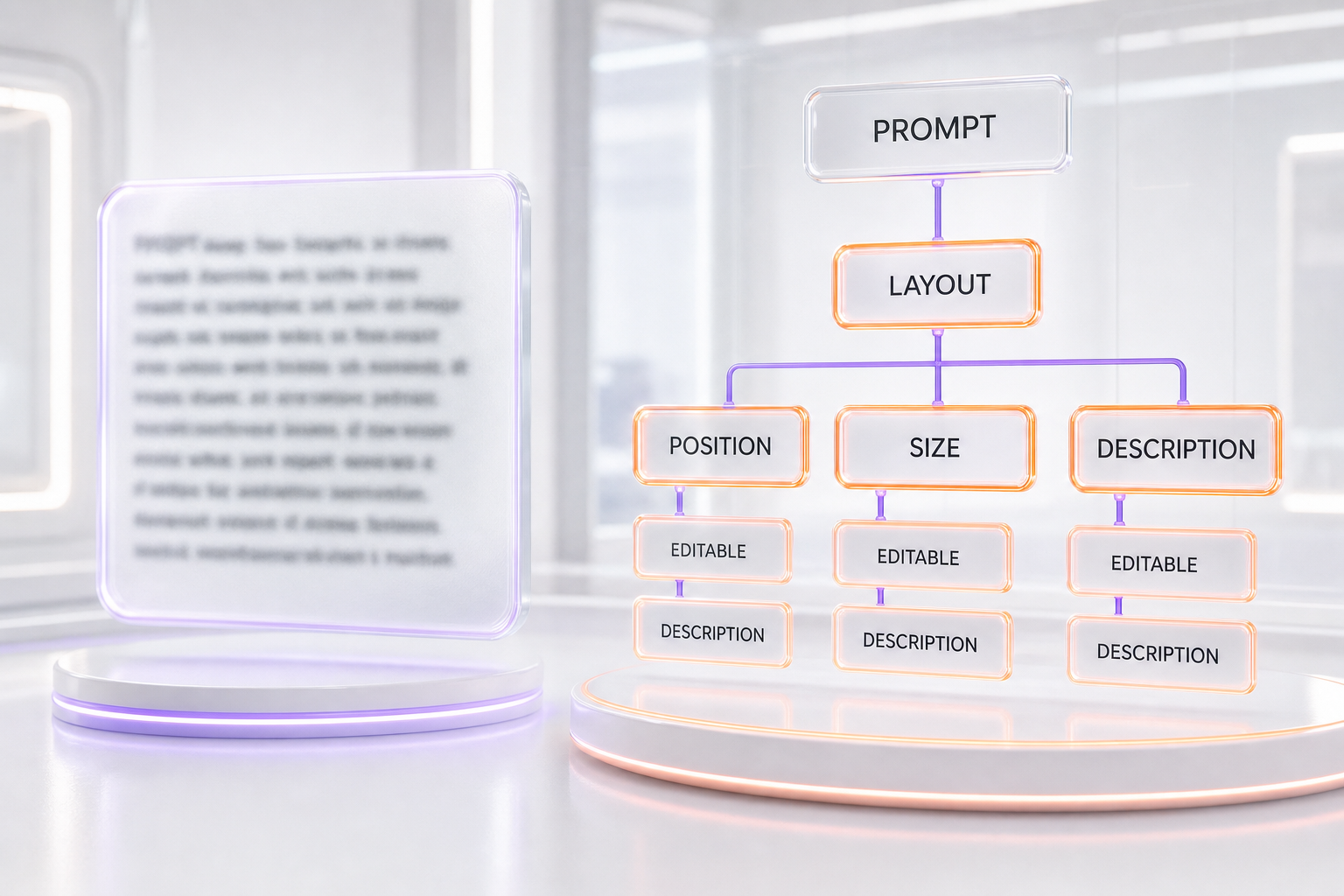
But resolution is the easy part of the story. The hard part — and the reason Reve 2.0 is getting attention well beyond its team size — is how you tell the model what to make. Reve 2.0 abandons the single text prompt as the primary control surface. In its place is what Reve calls a layout: a structured, hierarchical representation where, in the company's own words, "every element has a location, a size, a local description, and other optional attributes like image references or color." The layout is an intermediate representation Reve compares to HTML or SVG. You can refine the result either through natural language or by directly editing the layout itself.
The practical consequence is the line Reve has been repeating: "for the first time, it's possible to create images you can touch." Instead of re-rolling a full prompt and praying the rest of the image survives, you can grab a single element, move it, resize it, or rewrite its local description — and only that region changes. That is the difference between editing a JPEG and editing a document.
Images as Code: The Layout Bet Explained
The clearest way to understand Reve 2.0 is the analogy Reve uses itself: a layout is to an image what HTML is to a web page. A prompt is a paragraph of intent; a layout is a structured tree of addressable nodes. Each node has coordinates, dimensions, a description of what lives there, and optional attributes like a reference image or a color. The model reads that tree and renders pixels — but the tree remains the source of truth you can keep editing.
Why does this matter? Because the dominant failure mode of prompt-based generation has always been spatial and compositional control. Tell a text-to-image model "a red mug on the left, a laptop on the right, a window behind them" and you are negotiating with a black box about placement. Models have improved at this, but the control is implicit and brittle — change one clause and the whole composition can reshuffle. Reve's bet is that making composition explicit and editable removes the negotiation entirely.
This is the same conceptual shift several models are circling in mid-2026. Ideogram 4.0 shipped the same day with its own move toward structured, layout-aware control. We are not the first to notice that "from the prompt to the layout" is becoming the dominant narrative of the season — the difference is that Reve has built its entire model around the idea rather than bolting controls onto a prompt-first system.
Why Layouts Fix Text, Signs, and Interfaces
The most immediately useful payoff of the layout approach is text. Garbled lettering has been the signature tell of AI images for years — the warped sign, the invented alphabet on a book spine, the menu that dissolves into glyph soup. Reve integrates text layers directly into the layout graph, which means a sign, a logo, an app interface, or a book cover is described as a discrete element with its own region rather than emerging from a global denoising process that has no idea where words start and stop.
This is a genuine wedge against the broader field. Models like GPT Image 2 and Nano Banana 2 have made large strides on text rendering, but they get there by scaling and training tricks on top of a prompt-first architecture. Reve's claim is structural: if the word lives in its own addressable region of the layout, the model has a much cleaner job rendering it legibly and editing it later without disturbing the rest of the frame. For designers producing posters, UI mockups, packaging, or social graphics, that is exactly the workflow that has been missing.
The Architecture: Large Layout Model on Open Weights
Reve 2.0 is powered by what Reve calls a unified Large Layout Model (LLayoutM). According to Reve, the model "takes any combination of layouts, instructions, and images as input, derives a layout from its internal thinking trace, and then renders the final pixels." In other words, even when you hand it a plain instruction or a reference image, it reasons its way to an internal layout before painting — the layout is the spine of the whole system, not an optional input.
The lineage is notable. Reve says the Large Layout Model was created through continued pretraining of open-source LLMs — specifically the Qwen family — paired with a novel data pipeline bootstrapped from dense human annotations. That is a striking architectural choice: build an image model by extending a language model, because layout reasoning is fundamentally a structured-sequence problem that LLMs are already good at. It also helps explain the efficiency claim — starting from strong open weights is cheaper than training a frontier model from scratch.
Reve also published an ablation result that supports the core thesis. Reconstruction quality, measured by CLIP similarity, improves as you give the layout more regions to work with — more structure yields better fidelity. Reve says layout models outperform equal-size prompt-based generators in its ablations — the kind of apples-to-apples comparison that suggests the gains are coming from the approach, not just from scale.

Second on the Text-to-Image Arena
The benchmark headline is simple: Reve 2.0 ranks second on the Text-to-Image Arena, behind OpenAI's GPT Image 2 and ahead of Google's Nano Banana 2 (Gemini 3.1 Flash Image Preview). The Arena is a human-preference leaderboard — real people pick the better of two images in blind pairings — which makes it one of the harder numbers to game and one of the more credible signals of perceived quality.
What makes second place remarkable here is the company sitting in first. GPT Image 2 is OpenAI's flagship image model, the same one we now use for our own premium article imagery. For a roughly 65-person lab to land directly behind it, on a public head-to-head leaderboard, on its 2.0 release, is the kind of result that does not usually come out of a team that small. The gap to GPT Image 2 exists, but the margin between the top models on the Arena has been compressing all year, and Reve 2.0 is now inside that compressed band.
We covered the same dynamic when MAI-Image-2.5 landed at No. 3 and when Krea 2 came within a fraction of GPT Image 2 on the Contra Labs leaderboard. The pattern is consistent across 2026: the frontier is no longer a one-horse race, and the challengers increasingly come from smaller, scrappier teams making sharper architectural bets rather than simply outspending on compute.

The Efficiency Claim: 10x Fewer GPUs
The number Reve wants you to remember is not the resolution or the ranking — it is the resource gap. Reve describes Reve 2.0 as "the best image generation model made by a sub-$1T company, trained on 10x fewer GPUs," and the team has said publicly it reached top rankings "with 1/10 to 1/100 resources of our competitors." Whether you read the conservative end (10x) or the aggressive end (100x), the message is the same: this was not a brute-force win.
Two architectural choices make that plausible. First, building on open-source Qwen weights instead of training a language-and-vision stack from zero. Second, the layout-first design itself — if explicit structure does more of the heavy lifting, the model may need less raw capacity to reach a given quality bar. The ablation data, where fidelity rises with region count rather than with parameters, hints in that direction.
The caveat we always attach: "10x fewer GPUs" is Reve's framing, not an independently audited figure, and "1/10 to 1/100" is a wide range that does a lot of rhetorical work. We are reporting the claim, not certifying the accounting. But even discounted heavily, a sub-$1T lab landing second on a blind human-preference leaderboard is a real data point about where efficiency is headed in this category.
Why It Matters for Designers and Developers
For working designers, the layout model changes the unit of iteration. Today, refining an AI image usually means rewriting a prompt and re-rolling the whole frame, then hunting for the one variant that kept the good parts. With Reve 2.0, the promise is that you edit the part you want to change and leave the rest alone — move the headline, swap the product, recolor one object — because each is an addressable node in the layout. That is the difference between generation as a slot machine and generation as a design tool.
For developers, "images as code" is close to literal. A layout that behaves like HTML or SVG is a layout you can generate, diff, version, and template programmatically. Reve exposes create, edit, and remix workflows through an API, which means a layout-driven model fits naturally into pipelines that already think in structured data — product feeds, dynamic ad variants, localized creative, personalized covers. You are no longer string-concatenating prompts and hoping; you are constructing a document the model renders deterministically.
There is also a content-credibility angle. A model that places text and elements deterministically is a model you can trust to render the right price, the right legal line, or the right product name — the kind of correctness that prompt-based generation has never been able to guarantee. For commercial use, that reliability may matter more than the last point of aesthetic preference on a leaderboard.
How Reve 2.0 Compares to the Field
Reve 2.0 enters a crowded 2026 landscape. GPT Image 2 sits at the top of the Text-to-Image Arena and leads on broad photorealistic quality and text rendering through sheer scale. Google's Nano Banana 2 and Nano Banana Pro own the speed-and-integration position inside the Gemini ecosystem. Midjourney's V8 line still owns the aesthetic-default house style. FLUX 2 anchors the open-weights flagship tier for teams that need local control. Adobe Firefly holds the commercially-safe-license corner.
Reve 2.0's differentiation is not "prettier than all of them" — it is second on the Arena, not first. The differentiation is the control model. None of the incumbents are built layout-first; they are prompt-first systems with control features layered on. If Reve's bet is right that explicit, editable layout is the better primitive for serious creative work, then the relevant comparison is not a single quality score but the whole iteration loop — and on that axis Reve is offering something structurally different rather than incrementally better.
The honest counterpoint comes from early users. Some have flagged "cartoonish outputs" in certain styles and "lost style consistency" across edits — exactly the rough edges you would expect from a brand-new architecture on its 2.0 release. Overall sentiment has been strongly positive, but Reve 2.0 is a young model, and the leaderboard gap to GPT Image 2 is real. This is a credible challenger, not a coronation.

Pricing and Access
Reve 2.0 is available through Reve's app and API, with create, edit, and remix workflows exposed for programmatic use. Reve positions the model as low-cost per image relative to frontier competitors, consistent with its efficiency story — a model trained on far fewer GPUs can plausibly be served more cheaply per image. At the time of writing, the live pricing page sits behind Reve's authenticated app, so we are not quoting a specific per-image figure we could not confirm directly from the source. We would rather under-claim than publish a number we cannot stand behind.
What we can say with confidence: per-image API access is the distribution model, and aggressive pricing would be on-brand for a lab whose entire pitch is doing more with less. If the efficiency claims hold even partway, Reve 2.0 has room to undercut the frontier on cost while sitting one rank below it on quality — a combination that tends to win developer mindshare fast. We will update this article with exact figures once we can verify them on the official pricing page.
Our Take
We have watched a lot of "we're second on the Arena" announcements this year, and most of them are noise. Reve 2.0 is not, for one reason: the layout model is a real idea, not a feature. Replacing the prompt with an editable, addressable structure is the first proposal in a while that attacks the actual pain of working with these tools — the loss of control when you re-roll, the garbled text, the impossibility of editing one thing without breaking everything. If it works as advertised, it changes how the job feels, not just how the output scores.
We are also struck by the efficiency angle, even discounting Reve's framing. A roughly 65-person lab landing second on a blind human-preference leaderboard, built on continued pretraining of open weights, is a quiet rebuke to the assumption that frontier image quality requires frontier capital. That is the part the bigger labs should be nervous about — not this one model, but the proof that the moat is narrower than it looked.
What would make us more confident: an independent technical report substantiating the LLayoutM architecture and the GPU-efficiency claims, broader third-party benchmarks beyond the Arena, and resolution of the early reports of cartoonish output and style drift. The 2.0 release is a strong opening statement. Whether it becomes a category-shaping tool or a clever niche depends on the next few months of real-world use.
What's Next
The immediate question is whether layout-first control becomes the new default or stays a Reve specialty. Ideogram 4.0 moving in the same direction on the same day suggests the industry smells the same opportunity. If GPT Image 2 or the Nano Banana line ship serious layout-editing features in response, that is the strongest possible confirmation that Reve found the right primitive — and the moment the advantage starts to erode.
We will be watching three signals over the next 90 days: whether Reve publishes a technical report that backs the efficiency and architecture claims, whether the major labs answer with their own layout controls, and whether designers actually adopt the layout workflow or default back to prompts out of habit. For now, Reve 2.0 is the most interesting argument in image generation right now — a small team betting that the future of the field is structured, editable, and built like code, not typed like a wish.
Frequently Asked Questions
What is Reve 2.0 and when did it launch?
Reve 2.0 is a 4K image generation model launched on June 3, 2026 by Reve, an independent research lab of roughly 65 people. It generates native 4096-by-4096 output and replaces the traditional text prompt with a structured "layout" in which every element has a position, a size, and a local description, making the image addressable and editable like code. Reve calls it "the best 4K image model in the world," and it ranks second on the Text-to-Image Arena.
What does "images as code" mean in Reve 2.0?
It means Reve 2.0 represents an image as a structured, hierarchical layout — Reve compares it to HTML or SVG — rather than a single text prompt. Every element is a node with a location, a size, a local description, and optional attributes like image references or color. Because each part is addressable, you can edit one element without re-rolling the whole image, which is what Reve means by "images you can touch."
How does Reve 2.0 rank against GPT Image 2 and Nano Banana 2?
Reve 2.0 ranks second on the Text-to-Image Arena, a human-preference leaderboard where people pick the better of two images in blind pairings. It sits behind OpenAI's GPT Image 2 and ahead of Google's Nano Banana 2 (Gemini 3.1 Flash Image Preview). The gap to GPT Image 2 is real, but the margin between the top Arena models has compressed throughout 2026, and Reve 2.0 is now inside that band — a notable result for a roughly 65-person lab.
How is Reve 2.0 built, and what is the Large Layout Model?
Reve 2.0 is powered by a unified Large Layout Model (LLayoutM) that, per Reve, "takes any combination of layouts, instructions, and images as input, derives a layout from its internal thinking trace, and then renders the final pixels." Reve says the model was created through continued pretraining of open-source LLMs — the Qwen family — paired with a novel data pipeline bootstrapped from dense human annotations. The layout is the spine of the system even when you provide only a plain instruction.
Why is Reve 2.0 better at rendering text and signs?
Reve integrates text layers directly into the layout graph, so a sign, logo, app interface, or book cover is described as a discrete element with its own region rather than emerging from a global denoising process. Because the word lives in its own addressable region, the model has a cleaner job rendering it legibly and editing it later without disturbing the rest of the frame. This is a structural advantage over prompt-first models that improve text rendering through scale and training tricks.
How much does Reve 2.0 cost?
Reve 2.0 is available through Reve's app and API with create, edit, and remix workflows, and Reve positions it as low-cost per image relative to frontier competitors. At the time of writing, the live pricing page sits behind Reve's authenticated app, so we are not quoting a specific per-image figure we could not verify directly from the source. We will update this article with exact figures once they can be confirmed on the official pricing page.
What does Reve mean by training on "10x fewer GPUs"?
Reve describes Reve 2.0 as "the best image generation model made by a sub-$1T company, trained on 10x fewer GPUs," and the team has said it reached top rankings "with 1/10 to 1/100 resources of our competitors." Two choices make that plausible: building on open-source Qwen weights instead of training from scratch, and a layout-first design where explicit structure does more of the work. These are Reve's own framings, not independently audited figures.
Is Reve 2.0 really native 4K, or is it upscaled?
Reve frames Reve 2.0's 4096-by-4096 output — 16 megapixels in a square frame — as true native generation rather than a lower-resolution image followed by an upscale step. That distinction matters for text, fine textures, and repeated patterns, which are exactly the areas where upscalers tend to introduce artifacts. Native 4K combined with layout-level control is Reve's pitch for production-grade, edit-ready output.
Who should use Reve 2.0?
Reve 2.0 is best for designers who need precise compositional control — posters, UI mockups, packaging, social graphics, book covers — and for developers building programmatic image pipelines such as dynamic ad variants, localized creative, or personalized covers. Because the layout behaves like structured data you can generate, diff, and template, it fits teams that already think in code. Users who simply want one good image from a sentence may still prefer a prompt-first model like GPT Image 2 or Midjourney V8.
What are the limitations of Reve 2.0 right now?
It is a young 2.0 release. Some early users have reported "cartoonish outputs" in certain styles and "lost style consistency" across edits — the kind of rough edges expected from a brand-new architecture. The leaderboard gap to GPT Image 2 is real, the efficiency claims are Reve's own and not independently audited, and exact pricing is not yet confirmable from the public page. Overall sentiment has been strongly positive, but Reve 2.0 is a credible challenger, not a finished frontier leader.
How does Reve 2.0 relate to Ideogram 4.0 and the "layout" trend?
Ideogram 4.0 launched the same day, June 3, 2026, also moving toward structured, layout-aware control — part of a broader 2026 shift from prompt-first to layout-first image generation. The difference is that Reve built its entire model around the layout primitive, whereas most systems bolt control features onto a prompt-first core. The shared timing signals that "from the prompt to the layout" is becoming the defining narrative of the season rather than a single company's idea.
What signals should we watch to know if Reve 2.0 reshapes image generation?
Three things over the next 90 days. First, whether Reve publishes an independent technical report substantiating the Large Layout Model architecture and the GPU-efficiency claims. Second, whether the major labs — OpenAI's GPT Image 2 or Google's Nano Banana line — answer with their own layout-editing features, which would confirm Reve found the right primitive. Third, whether designers actually adopt the layout workflow in daily use rather than defaulting back to prompts out of habit.



