
Xiaomi MiMo UltraSpeed is a fast-inference mode of Xiaomi's 1-trillion-parameter MiMo-V2.5-Pro that the company claims decodes text at more than 1,000 tokens per second (peaking around 1,200) on a single standard 8-GPU commodity node. Announced June 8 and 9, 2026, it runs as an application-gated API trial from June 9 to June 23, 2026. Every speed figure here is a Xiaomi claim, with no independent third-party verification yet.
Speed numbers in large language models always come with caveats, and this one is no exception. But the headline deserves a careful read: Xiaomi is not claiming a smaller, faster model. It is claiming that the full trillion-parameter MiMo-V2.5-Pro can be served at over 1,000 tokens per second on commodity hardware any well-funded lab could rent. Here is what stands out, what is actually being claimed, and what to watch before anyone treats these numbers as fact.
What Xiaomi Announced
On June 8 and 9, 2026, Xiaomi published a technical blog post introducing MiMo-V2.5-Pro-UltraSpeed, a serving configuration of its flagship MiMo-V2.5-Pro model. The pitch, in Xiaomi's own framing, is blunt: "3x the price, 10x the output experience." According to Xiaomi's MiMo blog, the primary source for this story, UltraSpeed sustains a decode speed of more than 1,000 tokens per second, with a chart caption citing peaks of roughly 1,200.
The number that matters most is the hardware. Xiaomi says this runs on a single standard 8-GPU commodity node, with no wafer-scale chip, no SRAM-only memory design, and no bespoke accelerator in the loop. The entire claim rests on what Xiaomi calls "model-system co-design" on off-the-shelf GPUs. That is the part worth scrutinizing, because it is also the part that, if true, would be most reproducible by other teams.
Xiaomi also open-sourced the underlying checkpoint, publishing MiMo-V2.5-Pro-FP4-DFlash on Hugging Face and releasing select components of its TileRT runtime on GitHub. For a claim this big, the open checkpoint is arguably more newsworthy than the speed figure itself, because it gives the community a path to attempt independent verification rather than taking the benchmark on faith.
The Speed Claim, In One Table
Here is how the reported throughput stacks up against figures circulating in tech press coverage. Every value below is a vendor or press claim, not an independently verified measurement, and throughput depends heavily on provider, batch size, context length, and serving configuration.
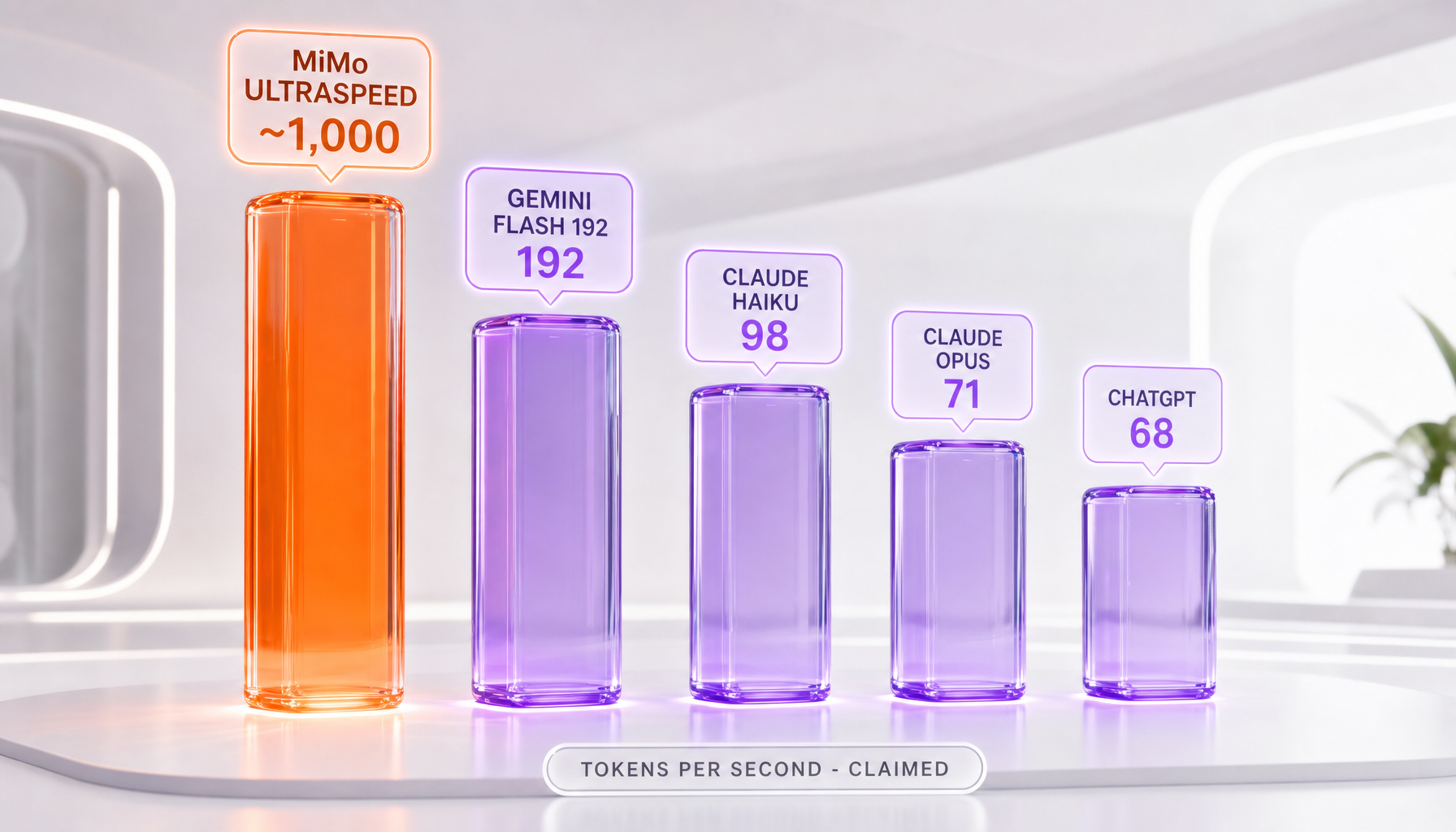
| Model | Claimed tokens per second | Note |
|---|---|---|
| MiMo-V2.5-Pro-UltraSpeed | ~1,000–1,200 tok/s | Xiaomi claim, 1T-param model on 8-GPU node |
| Gemini Flash | ~192 tok/s | Press figure citing Xiaomi's comparison |
| Claude Haiku | ~98 tok/s | Press figure citing Xiaomi's comparison |
| Claude Opus 4.6 | ~71 tok/s | Press figure citing Xiaomi's comparison |
| ChatGPT (GPT) | ~68 tok/s | Basis for the "15x faster" press framing |
All figures are vendor or press claims citing Xiaomi's own benchmarks, not independently verified. Per-model speeds vary by provider, batch size, context length, and serving config.
The "15 times faster than ChatGPT" line that has traveled across coverage from outlets like Gizchina, Gagadget, MarkTechPost, and ChinaBizInsider comes from comparing Xiaomi's roughly 1,000 tokens per second against a ChatGPT figure of about 68 tokens per second. That framing comes from press coverage, not from the Xiaomi blog itself, and it applies specifically to that ChatGPT comparison number. It is a headline, not a controlled benchmark.
How Xiaomi Got to 1,000 Tokens Per Second
The interesting engineering is in how Xiaomi says it reached this throughput. The company describes a three-layer stack, and each layer attacks a different bottleneck in serving a very large mixture-of-experts model. Xiaomi says the combination is what makes the numbers possible, not any single trick.
Layer 1: FP4 quantization on the experts only
The first layer is FP4 quantization applied through Quantization-Aware Training, but Xiaomi says it is applied only to the mixture-of-experts experts, while every other module stays at original precision. Quantization shrinks the numerical format used to store and compute weights, cutting memory bandwidth and speeding up math. By restricting the aggressive FP4 format to the experts, where most of a mixture-of-experts model's parameters live, Xiaomi says it captures most of the speed benefit while keeping capability essentially on par with the full-precision model. That last part is a claim, not a measured result anyone outside Xiaomi has confirmed.
Layer 2: DFlash block-level speculative decoding
The second layer is DFlash, a speculative decoding method. Conventional speculative decoding uses a small draft model to guess several upcoming tokens that the large model then verifies in parallel. Xiaomi's twist is block-level masked parallel prediction: the draft model fills an entire block of masked positions in a single forward pass, rather than predicting one token at a time. Xiaomi reports an average acceptance length of 6.30 tokens in coding scenarios, reaching 7.14 on some samples. A higher acceptance length means more guessed tokens survive verification per step, which is where a large share of the speedup comes from.

Layer 3: TileRT and the Persistent Engine Kernel
The third layer is TileRT, a runtime built around what Xiaomi calls a "Persistent Engine Kernel." The idea is to keep the entire compute pipeline persistently resident and flowing on the GPU instead of repeatedly launching and tearing down individual operators. Every time a GPU switches between operators, there is scheduling and launch overhead, and the hardware can sit idle between steps. By keeping the pipeline persistent, Xiaomi says it eliminates that operator-switching latency and keeps the GPUs near full utilization. When you are chasing 1,000 tokens per second, those microsecond gaps add up, and closing them is what lets the other two layers translate into wall-clock speed.
Taken together, the stack is a software-and-systems story, not a hardware one. That is the deliberate contrast Xiaomi draws with hardware-first fast-inference plays such as Cerebras Inference, which reaches its high token rates using custom wafer-scale silicon. Xiaomi argues you can get there on rentable GPUs if you co-design the model and serving stack tightly enough.
How It Compares
If the numbers hold, UltraSpeed would sit in a different tier from the mainstream hosted models people use daily. Frontier reasoning models such as Claude Opus 4.6 are reported around 71 tokens per second in this comparison, and ChatGPT around 68. Even the speed-tuned tiers, like Claude Haiku 4.5 at roughly 98 tokens per second and Gemini 3 Flash at about 192, sit well below the 1,000-plus figure Xiaomi is quoting.
Here is the crucial caveat. Tokens per second is a throughput metric, not a capability or quality benchmark; it tells you how fast a system emits text, not how good that text is. A model that streams 1,000 tokens per second is not, by virtue of that speed, smarter than one running at 70. UltraSpeed is about inference speed, not model intelligence; the underlying MiMo-V2.5-Pro is the same model whether served fast or slow. The comparison numbers are also sensitive to serving conditions: provider infrastructure, batch size, prompt length, and concurrency can all swing tokens-per-second figures substantially, which is why cross-vendor speed tables should be read as directional, not definitive.
There is also context from China's frontier labs worth noting. Xiaomi is far from the only Chinese player pushing aggressively on capable, efficient models in 2026, alongside efforts like DeepSeek V4 and Qwen 3.6. UltraSpeed fits a broader pattern of Chinese labs competing on serving efficiency and cost as much as on raw benchmark scores.
Availability: A Two-Week Trial
UltraSpeed is not a general release. Xiaomi is offering it through an application-gated API trial that runs from June 9 to June 23, 2026, closing at 23:59 Beijing Time. Access requires an application, and Xiaomi says it is prioritizing enterprise users. Pricing during the trial is set at three times the standard MiMo-V2.5-Pro rate, which is the cost side of the "3x the price, 10x the output experience" framing.
The trial also comes with reported constraints. According to press coverage, each account is limited to as many as 10 queued requests, sessions run roughly 30 minutes, and an idle connection drops after about 5 minutes. Those limits suggest Xiaomi is managing scarce serving capacity rather than opening the floodgates. For context, Xiaomi's earlier MiMo-V2-Flash from December 2025 ran at roughly 150 tokens per second at a published rate of $0.1 per million input tokens and $0.3 per million output tokens; UltraSpeed is framed as about 6.7 times faster than that predecessor.
Why Inference Speed Matters
It would be easy to file a tokens-per-second record under bragging rights, but inference speed has become one of the most consequential levers in applied AI. A jump to 1,000 tokens per second changes what is buildable.

The clearest beneficiary is agentic workflows. AI agents are not single-shot question-and-answer systems; they loop, generating intermediate reasoning, calling tools, reading results, and generating again, often producing many times more tokens than the final answer the user sees. When each step decodes ten or fifteen times faster, a multi-step agent that took minutes can finish in seconds. That difference determines whether an autonomous workflow is interactive or something you kick off and walk away from.
Speed also reshapes real-time user experience. Streaming responses that arrive faster than a person can read remove the lag that makes chat interfaces feel sluggish, opening up use cases like live coding assistance, voice interaction, and high-volume document processing where latency is the bottleneck. There is also a cost dimension: if a node serves far more tokens in the same wall-clock time, the effective cost per completed task can fall even when the per-token price is higher, because fixed serving costs are amortized across more output. That is the economic argument hiding inside Xiaomi's "3x the price, 10x the output" slogan, though whether the math holds depends on whether the throughput claim survives contact with real workloads.
Our Take
If UltraSpeed holds up, it is genuinely impressive, and not for the reason the headlines suggest. The "15x faster than ChatGPT" framing is the least interesting part of the story, because it compares a throughput number against a quality-tuned product under unspecified conditions. The interesting claim is the systems one: that you can serve a full trillion-parameter model at over 1,000 tokens per second on a single commodity 8-GPU node through quantization, speculative decoding, and a persistent-kernel runtime, with no exotic hardware. If that reproduces, it is a meaningful statement about how far software co-design can push commodity GPUs.
But "if it holds up" is doing real work in that sentence. As of now, there is no independent third-party verification of any of these numbers; they are Xiaomi's claims and press figures citing Xiaomi's benchmarks, and tokens per second is throughput, not intelligence. The single most important thing Xiaomi did here is not the speed claim at all. It is open-sourcing the FP4-DFlash checkpoint on Hugging Face and releasing TileRT modules on GitHub, because that is what makes the claim falsifiable. A benchmark you can only reach through a gated two-week trial is marketing; a checkpoint anyone can download and stress-test is evidence in the making.
What's Next and What to Watch
Three things are worth tracking. First, independent benchmarks: now that the checkpoint and some runtime components are public, expect researchers to try to reproduce the 1,000-tokens-per-second figure on their own 8-GPU nodes, and those results, not Xiaomi's blog, will settle whether the claim is real. Second, durability: the trial ends June 23, 2026, so the open question is whether UltraSpeed becomes a standing product or stays a limited showcase. Third, the quality-versus-speed tradeoff: Xiaomi says capability stays essentially on par after FP4 quantization of the experts, and independent evaluations on real tasks will show whether that holds or whether the speed hides subtle quality regressions a throughput chart never reveals.
For now, the honest summary is simple. Xiaomi has made a bold, well-specified claim, attributed entirely to its own benchmarks, and has taken the welcome step of open-sourcing enough to let others check its work. That is the part that earns a watch.
What is Xiaomi MiMo UltraSpeed?
Xiaomi MiMo UltraSpeed, formally MiMo-V2.5-Pro-UltraSpeed, is a fast-inference configuration of Xiaomi's 1-trillion-parameter MiMo-V2.5-Pro model. Xiaomi claims it decodes text at more than 1,000 tokens per second, peaking around 1,200, on a single standard 8-GPU commodity node with no custom silicon. It was announced on June 8 and 9, 2026, and is being offered through an application-gated API trial.
Is MiMo UltraSpeed really 15x faster than ChatGPT?
The "15 times faster than ChatGPT" line comes from tech press coverage, not from Xiaomi's blog directly, and it compares Xiaomi's claimed roughly 1,000 tokens per second against a ChatGPT figure of about 68 tokens per second. It is a throughput comparison under unspecified conditions, not an independently verified benchmark. Tokens per second measures emission speed, not answer quality.
How does Xiaomi reach 1,000 tokens per second?
Xiaomi credits a three-layer stack: FP4 quantization applied only to the mixture-of-experts experts via Quantization-Aware Training, DFlash block-level speculative decoding with a reported average acceptance length of 6.30 tokens in coding tasks, and a TileRT runtime whose "Persistent Engine Kernel" keeps the compute pipeline resident on the GPU to cut operator-switching latency. Xiaomi says the combination, not any single technique, produces the throughput.
Is MiMo UltraSpeed faster than Claude or Gemini?
According to figures Xiaomi reports and press repeats, UltraSpeed's roughly 1,000 to 1,200 tokens per second is well above Claude Opus 4.6 at about 71, Claude Haiku at about 98, and Gemini Flash at about 192 tokens per second. None of these numbers are independently verified, and they depend heavily on provider, batch size, and serving configuration, so treat the comparison as directional rather than definitive.
How much does MiMo UltraSpeed cost and when can I try it?
Xiaomi is running an application-gated API trial from June 9 to June 23, 2026, closing at 23:59 Beijing Time, with priority given to enterprise users. Pricing during the trial is three times the standard MiMo-V2.5-Pro rate, which Xiaomi frames as "3x the price, 10x the output experience." Reported trial limits include up to 10 queued requests per account, sessions of about 30 minutes, and idle disconnection after roughly 5 minutes.
Has the 1,000 tokens-per-second claim been independently verified?
No. As of writing, every speed figure is a Xiaomi claim or a press number citing Xiaomi's own benchmarks, with no independent third-party verification. The most meaningful step toward verification is that Xiaomi open-sourced the MiMo-V2.5-Pro-FP4-DFlash checkpoint on Hugging Face and released select TileRT modules on GitHub, which lets the community attempt to reproduce the results on its own hardware.



