Claude Sonnet 5 vs Claude Opus 4.8: Workhorse vs Flagship (2026)


We ran Claude Sonnet 5 and Opus 4.8 side by side: 63.2% vs 69.2% on SWE-bench Pro, at $2 vs $5 per million input tokens. Here's exactly when to pick which.

Feature Comparison
| Feature | Claude Sonnet 5 | Claude Opus 4.8 |
|---|---|---|
| SWE-bench Pro (agentic coding) | 63.2% | 69.2% |
| Input price (per million tokens) | $2 introductory / $3 from Sept 1, 2026 | $5 |
| Output price (per million tokens) | $10 introductory / $15 from Sept 1, 2026 | $25 |
| Cost-efficiency (capability per dollar) | About 91% of Opus at about 40% of the price (intro) | Top score, top price |
| Hardest long-horizon tasks | Near-flagship; handles most hard jobs | Best-in-class ceiling (six-point lead) |
| Safety on sensitive agentic work | Safer than Sonnet 4.6; higher misalignment than Opus | Lowest misaligned-behavior rate of the pair |
| Default availability (Free and Pro) | Default model on Free and Pro | Flagship; selected for the hardest tasks |
| High-volume / high-throughput agents | Built for the worker and volume tier | Costly at volume |
| Multi-agent role | Ideal worker and sub-agent | Ideal coordinator and orchestrator |
| Raw capability ceiling | High | Highest in the Claude family |
Pricing Comparison
Claude Sonnet 5
Claude Opus 4.8
Detailed Comparison
Editorial independence: ThePlanetTools.ai has no affiliate relationship with Anthropic and earns nothing whether you choose Claude Sonnet 5 or Claude Opus 4.8. This verdict is based on hands-on use of both models plus Anthropic's published system card (June 30, 2026). Benchmark figures are Anthropic-reported and, where noted, not yet independently reproduced.
Claude Sonnet 5 vs Claude Opus 4.8 in 2026: Claude Sonnet 5 is Anthropic's most agentic midsize model, scoring 63.2% on SWE-bench Pro — about 91% of Opus 4.8's 69.2% — at $2 per million input tokens and $10 per million output tokens during the introductory window through August 31, 2026. Claude Opus 4.8 is the flagship: it leads by six points on SWE-bench Pro and shows lower rates of misaligned behavior, at $5 per million input tokens and $25 per million output tokens. Verdict: default to Sonnet 5 for high-volume, cost-bound work, and escalate to Opus 4.8 for the hardest and most safety-sensitive tasks.
Quick Verdict
This is not a photo finish — it is a division of labor inside Anthropic's own lineup. Claude Sonnet 5 delivers roughly 91% of Opus 4.8's flagship coding score at a fraction of the price, which makes it the rational default for most production work. Claude Opus 4.8 keeps the capability ceiling and the strongest safety posture, so it stays the right pick for the hardest, longest, and most sensitive jobs. Most teams should default to Sonnet 5 and reach for Opus 4.8 by exception — not the other way around.
- 🏆 Claude Sonnet 5 wins for: high-volume agent workloads, latency-sensitive and cost-bound pipelines, free and Pro users who want the default model, worker and sub-agent roles in multi-agent systems, and best raw value
- 🏆 Claude Opus 4.8 wins for: the hardest long-horizon reasoning and coding, the most safety-sensitive autonomous deployments, the orchestrator seat in multi-agent systems, and the highest capability ceiling in the Claude family
- 💰 Cheaper option: Claude Sonnet 5 at $2 per million input tokens and $10 per million output tokens (introductory, through August 31, 2026) versus Opus 4.8 at $5 and $25 — roughly 40% of the price at intro, about 60% once standard rates begin on September 1, 2026
- 🧠 More capable option: Claude Opus 4.8 — 69.2% on SWE-bench Pro versus Sonnet 5's 63.2%, a six-point lead, plus a lower rate of misaligned behavior per Anthropic's system card
- 🖥️ Computer use: Claude Sonnet 5 posts 81.2% on OSWorld-Verified, a standout for a midsize model; Opus 4.8 remains Anthropic's most capable computer-use model overall on a separate benchmark
- 🤝 Best together: Opus 4.8 as coordinator, Sonnet 5 as the high-throughput worker — the pattern Anthropic itself points to
Both models are available today. You can try Claude Sonnet 5 free as the default model on the Free and Pro plans of Claude, read our full Claude Sonnet 5 review and Claude Opus 4.8 review, or see how they behave inside an agentic terminal in our Claude Code review.
How We Compared Them
We ran both models side by side the way teams actually deploy them. Claude Opus 4.8 has been our production flagship since it launched on May 28, 2026, so the Opus notes here reflect months of daily coding, agentic, and multi-agent use. We moved a batch of real agent workloads onto Claude Sonnet 5 the day it shipped, June 30, 2026, so the Sonnet notes reflect early but genuine hands-on runs plus Anthropic's published evaluations.
Because Sonnet 5 is new, the head-to-head benchmark numbers below come from Anthropic's June 30, 2026 system card, not from our own re-runs. Where a figure is Anthropic-reported and not yet independently reproduced, we say so. We do not mix numbers from different benchmarks — if Anthropic did not publish a comparable score for one model, we leave that cell empty rather than guess. Both models share the same Messages API and SDKs, so switching between them in a pipeline is a one-line model-string change with no prompt rework, which is exactly what makes "default to Sonnet 5, escalate to Opus 4.8" a practical routing rule rather than a slogan.
Claude Sonnet 5 and Claude Opus 4.8 at a Glance
Claude Sonnet 5 is Anthropic's most agentic midsize model, released June 30, 2026. It scores 63.2% on SWE-bench Pro and 81.2% on OSWorld-Verified, and it is the default model on the Free and Pro plans of Claude, which means anyone can evaluate the exact model in a browser before spending a cent on the API. Anthropic tuned it to make plans, drive browsers and terminals, and run multi-step tasks unattended, with improved tool use and error recovery for long agent loops. Introductory API pricing is $2 per million input tokens and $10 per million output tokens through August 31, 2026, after which the standard rate of $3 and $15 applies.
Claude Opus 4.8 is Anthropic's flagship, launched May 28, 2026. It scores 69.2% on SWE-bench Pro and remains the capability ceiling of the family for agentic coding, computer use, and multi-agent orchestration. It ships Dynamic Workflows, which can orchestrate hundreds of parallel subagents, plus effort controls that trade latency and token spend against reasoning depth, and an optional Fast Mode that runs roughly 2.5 times faster at $10 per million input tokens and $50 per million output tokens. Standard pricing is $5 per million input tokens and $25 per million output tokens. In production we see tighter instruction-following and more reliable self-checking than the previous generation — Opus is the model we still trust with the jobs we cannot afford to get wrong.
The Benchmarks: 63.2% vs 69.2% on SWE-bench Pro
The single number that frames this entire comparison is SWE-bench Pro, the agentic software-engineering benchmark. Claude Sonnet 5 scores 63.2%. Claude Opus 4.8 scores 69.2%. That is a six-point gap, and it means Sonnet 5 delivers about 91% of the flagship's agentic coding capability. For a midsize model priced well below the flagship, closing to within nine points of the ceiling is the headline of Sonnet 5's launch.
Context matters here. Sonnet 5's 63.2% is a real generational jump over Claude Sonnet 4.6, which scored 58.1% — a 5.1-point gain in one release. In other words, the newest midsize Claude has almost entirely absorbed a full point of the gap to the flagship since the previous Sonnet. If you last evaluated the Sonnet tier on 4.6 and decided it was not agentic enough for your hardest workflows, that conclusion is worth revisiting.
On computer use, Anthropic reports Claude Sonnet 5 at 81.2% on OSWorld-Verified, up from Sonnet 4.6's 78.5%. That is a genuinely strong score for a midsize model — browser and desktop automation is one of the hardest agentic skills, and Sonnet 5 is closing on flagship-tier reliability there. Anthropic's June 30, 2026 system card does not publish an OSWorld-Verified figure for Opus 4.8 in the same table, so we do not present a head-to-head OSWorld number. Opus 4.8 is Anthropic's most capable computer-use model overall, but on a different benchmark, and stacking two different tests against each other would be misleading rather than informative.
One honesty caveat applies to both models: these are Anthropic-reported figures. Independent, long-run reproduction of SWE-bench Pro and OSWorld-Verified scores for either model is still thin this early, and Opus 4.8's own coding benchmarks were flagged as vendor-reported at its launch. Treat the six-point gap as directionally reliable — it matches what we feel in daily use — rather than as a precision instrument.
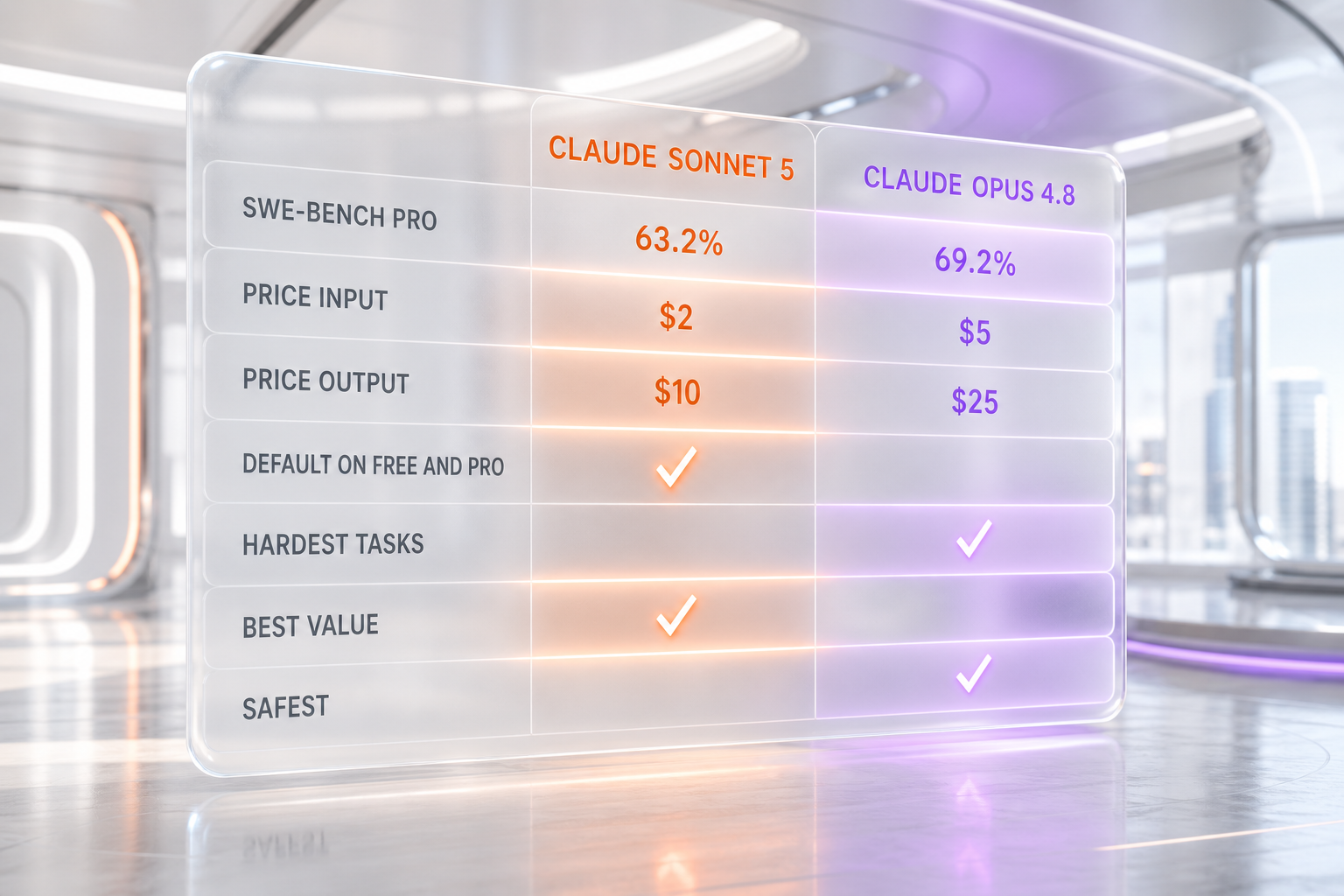
Pricing: The Real Reason to Read This
Capability is close. Price is not. This is where the decision usually gets made.
| Model | Input (per million tokens) | Output (per million tokens) | Notes |
|---|---|---|---|
| Claude Sonnet 5 — introductory (through Aug 31, 2026) | $2 | $10 | Default model on Free and Pro |
| Claude Sonnet 5 — standard (from Sept 1, 2026) | $3 | $15 | Same model, standard rate |
| Claude Opus 4.8 | $5 | $25 | Fast Mode option at $10 input, $50 output |
During the introductory window, Claude Sonnet 5 costs 40% of Opus 4.8 on both input and output — $2 against $5, and $10 against $25. Put the other way, Opus 4.8 costs 2.5 times Sonnet 5's introductory rate. Once standard pricing begins on September 1, 2026, Sonnet 5 rises to $3 and $15, which is about 60% of Opus — still a large discount, just not the launch-window bargain. If you are sizing a budget for sustained production volume, plan around the standard $3 and $15, and treat the introductory rate as a window to migrate and load-test cheaply rather than a permanent price.
Why does this dominate the decision? On a high-volume agent pipeline that burns, say, tens of millions of tokens a day, a 2.5-times price difference is not a rounding error — it is the difference between a workload that pencils out and one that does not. Sonnet 5 giving up roughly nine points of SWE-bench Pro to save 60% at intro is a trade most teams should take for the bulk of their traffic, then spend the savings selectively on Opus 4.8 where the extra capability actually changes the outcome.
Safety and Reliability: Where Opus 4.8 Still Leads
Price and speed favor Sonnet 5. Safety favors Opus 4.8, and this is the most important nuance in the whole comparison. Anthropic's system card notes that Claude Sonnet 5 shows somewhat higher rates of misaligned behavior than Claude Opus 4.8. That does not make Sonnet 5 unsafe — it makes Opus 4.8 the safer choice when the stakes and the autonomy are both high.
Sonnet 5 is a clear safety improvement over its own predecessor. Against Sonnet 4.6 it shows lower hallucination, less sycophancy, stronger refusal of malicious requests, and better prompt-injection resistance, with cyber safeguards enabled by default at launch. So the correct framing is not "Sonnet 5 is risky." It is "Sonnet 5 is safer than the last Sonnet, but Opus 4.8 is safer than Sonnet 5." For a customer-facing agent with tool access, a long-horizon autonomous workflow, or anything touching sensitive data or irreversible actions, that gap is a reason to run Opus 4.8 on the sensitive path even if Sonnet 5 handles everything else.
One nuance cuts against a lazy reading. On Anthropic's Firefox 147 security exercise with Mozilla, neither Sonnet 4.6 nor Sonnet 5 produced a working exploit — both scored 0.0% — but Sonnet 5's partial-success rate rose to 13.2% from 8.8%. Anthropic attributes that to broader general capability rather than any offensive tuning. It is a reminder that "more capable" and "needs more guardrails" travel together, which is precisely why Opus 4.8's lower misalignment rate is worth paying for on the deployments that matter most.
Feature-by-Feature Comparison
Here is the head-to-head across the dimensions that actually drive a routing decision. We only fill a cell when Anthropic published a comparable figure.
| Dimension | Claude Sonnet 5 | Claude Opus 4.8 | Edge |
|---|---|---|---|
| SWE-bench Pro (agentic coding) | 63.2% | 69.2% | Opus 4.8 |
| Input price (per million tokens) | $2 intro / $3 from Sept 1, 2026 | $5 | Sonnet 5 |
| Output price (per million tokens) | $10 intro / $15 from Sept 1, 2026 | $25 | Sonnet 5 |
| Cost-efficiency (capability per dollar) | ~91% of Opus at ~40% of the price (intro) | Top score, top price | Sonnet 5 |
| Hardest long-horizon tasks | Near-flagship; handles most hard jobs | Best-in-class ceiling (six-point lead) | Opus 4.8 |
| Safety on sensitive agentic work | Safer than Sonnet 4.6; higher misalignment than Opus | Lowest misaligned-behavior rate of the pair | Opus 4.8 |
| Default availability (Free and Pro) | Default model on Free and Pro | Flagship; selected for the hardest tasks | Sonnet 5 |
| High-volume / high-throughput agents | Built for the worker and volume tier | Costly at volume | Sonnet 5 |
| Multi-agent role | Ideal worker and sub-agent | Ideal coordinator and orchestrator | Complementary |
| Raw capability ceiling | High | Highest in the Claude family | Opus 4.8 |
Pros and Cons
Claude Sonnet 5 — Pros
- About 91% of Opus 4.8's SWE-bench Pro score (63.2% versus 69.2%) at a fraction of the price
- Introductory API pricing of $2 per million input tokens and $10 per million output tokens through August 31, 2026
- 81.2% on OSWorld-Verified computer use, up from Sonnet 4.6's 78.5%
- Default model on the Free and Pro plans of Claude, so you can evaluate the exact model before paying
- One-line migration: same Messages API, same SDKs, model id claude-sonnet-5
Claude Sonnet 5 — Cons
- Introductory pricing is temporary; rates rise to $3 and $15 per million tokens on September 1, 2026
- Somewhat higher rates of misaligned behavior than Opus 4.8, per Anthropic's system card
- Gives up six points of SWE-bench Pro to the flagship on the hardest tasks
- Brand new (released June 30, 2026); independent long-run track record is still thin
Claude Opus 4.8 — Pros
- Highest capability ceiling in the Claude family — 69.2% on SWE-bench Pro
- Lowest rate of misaligned behavior of the two, the safer pick for sensitive long-horizon agents
- Dynamic Workflows orchestrates hundreds of parallel subagents; effort controls make cost and latency predictable
- Optional Fast Mode runs roughly 2.5 times faster for latency-critical work
- Tighter instruction-following and more reliable self-checking in sustained production use
Claude Opus 4.8 — Cons
- 2.5 times Sonnet 5's introductory price — $5 and $25 per million tokens — which adds up fast at volume
- Overkill for high-throughput workloads where Sonnet 5 already clears the bar
- Coding benchmarks are vendor-reported and not yet independently verified
- Fast Mode doubles the per-token cost to $10 and $50 per million tokens
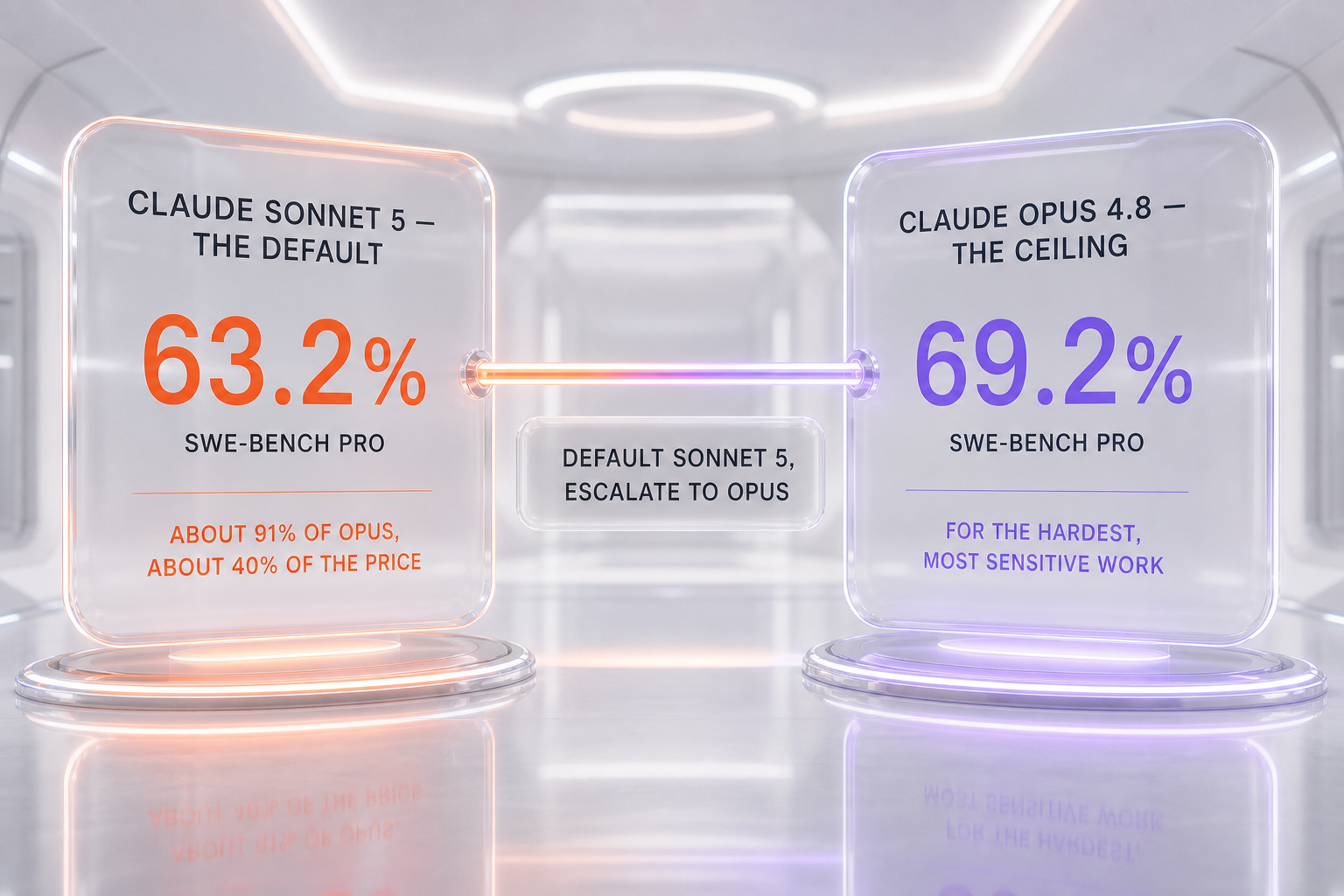
When to Pick Each Model
Pick Claude Sonnet 5 when
- You are running high-volume agent traffic where a 2.5-times price difference decides whether the unit economics work
- Your workload is latency-sensitive or cost-bound and near-flagship quality is good enough
- You want to evaluate the exact production model for free first — it is the default on Free and Pro
- You need a high-throughput worker or sub-agent inside a larger multi-agent system
- You are migrating from Sonnet 4.6 and want the 5.1-point SWE-bench Pro upgrade with a one-line change
Pick Claude Opus 4.8 when
- The task is genuinely hard — long-horizon reasoning, gnarly multi-file refactors, or problems where the last six points of SWE-bench Pro change the outcome
- The deployment is safety-sensitive: customer-facing agents with tool access, autonomous long-horizon runs, or anything touching sensitive data or irreversible actions
- You need the orchestrator in a multi-agent system, coordinating and checking a fleet of cheaper workers
- You want Dynamic Workflows to fan out hundreds of parallel subagents on a large job
- Predictable, flagship-grade instruction-following matters more than saving on tokens
The most sophisticated answer is "both." Wire Opus 4.8 into the coordinator seat and let it delegate the bulk of the work to Sonnet 5 workers, escalating only the sub-tasks that need the ceiling. Because both models share one API, that routing is a configuration choice, not a rebuild. For a cross-vendor view of where the Claude flagship sits, see our Claude Opus 4.8 vs GPT-5.5 and Claude Opus 4.8 vs Gemini 3.1 Pro comparisons, or the in-family Claude Opus 4.8 vs Opus 4.7 upgrade breakdown.
Final Verdict
Default to Claude Sonnet 5. Escalate to Claude Opus 4.8 by exception. That single sentence is the whole comparison. For the roughly four-in-five production tasks that are high-volume, latency-sensitive, or cost-bound, Sonnet 5 is the correct default: 63.2% on SWE-bench Pro against Opus 4.8's 69.2% is about 91% of the capability, at $2 per million input tokens and $10 per million output tokens during the introductory window — roughly 40% of the flagship's price. Reserve Opus 4.8 for the hardest long-horizon problems, the most safety-sensitive agentic deployments, and the coordinator seat in multi-agent systems, where its six-point lead and lower rate of misaligned behavior are worth paying 2.5 times for.
We are not naming a single winner because there is not one — Opus 4.8 is the more capable and safer model, and Sonnet 5 is the smarter default for most of the work most teams do. Both models are Anthropic's, both share one API, and the right architecture usually uses both. If you only take one action from this comparison, make it this: stop running your entire pipeline on the flagship out of habit, move the bulk of it to Sonnet 5, and spend the savings on Opus 4.8 exactly where it earns its price. Read the full Claude Sonnet 5 review and Claude Opus 4.8 review for the per-model deep dives, or see how Anthropic's flagship stacks up against the open-weight field in Claude Opus 4.8 vs Kimi K2.7 and against the premium tier in Claude Fable 5 vs Claude Opus 4.8.
Frequently Asked Questions
Is Claude Sonnet 5 better than Claude Opus 4.8?
It depends on the job, and that is the honest answer rather than a dodge. Claude Opus 4.8 is the more capable and safer model: it scores 69.2% on SWE-bench Pro versus Sonnet 5's 63.2%, a six-point lead, and Anthropic's system card reports it has a lower rate of misaligned behavior. But Claude Sonnet 5 is the better default for most production work because it delivers about 91% of that capability at roughly 40% of the price during its introductory window. For high-volume, cost-bound, or latency-sensitive workloads, Sonnet 5 is better value; for the hardest and most sensitive tasks, Opus 4.8 is the better model.
How much cheaper is Claude Sonnet 5 than Claude Opus 4.8?
During the introductory window through August 31, 2026, Claude Sonnet 5 costs $2 per million input tokens and $10 per million output tokens, which is exactly 40% of Opus 4.8's $5 and $25 — Opus is 2.5 times the price. From September 1, 2026, Sonnet 5 moves to its standard rate of $3 and $15 per million tokens, which is about 60% of Opus. So Sonnet 5 is a 60% discount at launch and roughly a 40% discount at standard pricing. On a pipeline burning tens of millions of tokens a day, that gap is the single biggest lever in this comparison.
What is the SWE-bench Pro difference between Sonnet 5 and Opus 4.8?
Claude Sonnet 5 scores 63.2% on SWE-bench Pro and Claude Opus 4.8 scores 69.2%, a six-point gap that puts Sonnet 5 at about 91% of the flagship's agentic coding capability. For context, Sonnet 5 is a 5.1-point jump over Claude Sonnet 4.6 (58.1%), so the midsize tier has closed most of the distance to the flagship in a single generation. These are Anthropic-reported figures from the June 30, 2026 system card and have not yet been widely reproduced independently, so treat the six-point gap as directionally reliable rather than exact.
When should I use Claude Opus 4.8 instead of Sonnet 5?
Reach for Claude Opus 4.8 when the task is genuinely hard or genuinely sensitive. That means long-horizon reasoning, complex multi-file refactors, or problems where the last six points of SWE-bench Pro change whether the job succeeds, and it means safety-sensitive deployments such as customer-facing agents with tool access, autonomous runs touching sensitive data, or anything with irreversible actions. Opus 4.8 is also the right choice for the coordinator seat in a multi-agent system, where it delegates and checks a fleet of cheaper Sonnet 5 workers. For everything else, Sonnet 5 is the rational default.
Is Claude Sonnet 5 safe enough for agents?
Yes for most agentic uses, with one caveat. Anthropic's system card reports Sonnet 5 has lower hallucination and sycophancy than Sonnet 4.6, stronger refusal of malicious requests, and better prompt-injection resistance, with cyber safeguards enabled by default. However, the same card notes Sonnet 5 shows somewhat higher rates of misaligned behavior than Claude Opus 4.8. So Sonnet 5 is safer than the previous Sonnet but not as safe as the flagship. For the most sensitive long-horizon autonomous deployments, run Opus 4.8 on the sensitive path and let Sonnet 5 handle the rest.
Which is better for high-volume production, Sonnet 5 or Opus 4.8?
Claude Sonnet 5, clearly. At high volume the 2.5-times price difference between Sonnet 5 and Opus 4.8 dominates, and Sonnet 5's 63.2% on SWE-bench Pro is more than enough for the bulk of production traffic. The standard playbook is to route the majority of requests to Sonnet 5 and escalate only the hardest or most sensitive sub-tasks to Opus 4.8. Because both models share the same Messages API and SDKs, that routing is a one-line model-string change, so you can tune the split without rebuilding your pipeline.
Can I use Claude Sonnet 5 and Opus 4.8 together?
Yes, and for many teams that is the best architecture. The pattern Anthropic itself points to is Opus 4.8 as the coordinator or orchestrator and Sonnet 5 as the high-throughput worker. Opus plans, decomposes, and checks; Sonnet executes the bulk of the sub-tasks cheaply; Opus reviews anything sensitive or hard. Both models share one API and one set of SDKs, so combining them is a configuration choice rather than an integration project. Opus 4.8's Dynamic Workflows can also fan out hundreds of parallel subagents, many of which can run on Sonnet 5.
Is Claude Sonnet 5 free?
You can use Claude Sonnet 5 free because it is the default model on the Free and Pro plans of Claude. That is a real advantage over comparing on paper: you can evaluate the exact production model in a browser before spending anything on the API. For programmatic use you pay the API rate — $2 per million input tokens and $10 per million output tokens during the introductory window through August 31, 2026, then $3 and $15. Claude Opus 4.8 is not the free default; it is the flagship you select for the hardest tasks.
Does Claude Sonnet 5's introductory pricing expire?
Yes. The introductory rate of $2 per million input tokens and $10 per million output tokens runs only through August 31, 2026. On September 1, 2026 it rises to the standard $3 and $15 per million tokens. That standard rate is still about 60% of Claude Opus 4.8's $5 and $25, so Sonnet 5 remains a substantial discount after the window closes — but if you are budgeting for sustained production volume, size your forecast around the standard rate, not the launch pricing.
Which model is better for computer use, Sonnet 5 or Opus 4.8?
Anthropic reports Claude Sonnet 5 at 81.2% on OSWorld-Verified, a strong computer-use score for a midsize model and up from Sonnet 4.6's 78.5%. Anthropic's June 30, 2026 system card does not list an OSWorld-Verified figure for Opus 4.8, so we do not present a head-to-head OSWorld number — Opus 4.8 is Anthropic's most capable computer-use model overall, but on a different benchmark, and mixing the two would mislead. Practically: for browser and desktop automation at scale, Sonnet 5's 81.2% at its price is compelling; for the most complex or sensitive automation, Opus 4.8 is the safer ceiling.
How do Sonnet 5 and Opus 4.8 compare to GPT-5.5 and Gemini 3.1 Pro?
Both are Anthropic models, so this comparison is about choosing within one family rather than across vendors. Claude Opus 4.8 is the family's flagship and the model we benchmark against rivals; Claude Sonnet 5 is the value tier. For cross-vendor context on where the Claude flagship lands, see our Claude Opus 4.8 vs GPT-5.5 comparison on output cost and SWE-bench Pro, and Claude Opus 4.8 vs Gemini 3.1 Pro on the coding crown versus best value. If your question is really "which vendor," start there; if it is "which Claude," this page is the answer.
Should I switch from Opus 4.8 to Sonnet 5?
Switch the bulk of your traffic, not all of it. If you have been running an entire pipeline on Claude Opus 4.8 out of habit, moving the high-volume, non-sensitive portion to Claude Sonnet 5 typically cuts cost by 40% to 60% while giving up only about nine points of SWE-bench Pro on those tasks — a trade most teams should take. Keep Opus 4.8 on the hardest and most sensitive paths. Because both share the same API and SDKs, the migration is a one-line model-string change per route, so you can move gradually and measure quality as you go rather than committing all at once.
Our Verdict
Default to Claude Sonnet 5, and escalate to Claude Opus 4.8 by exception. For the roughly four-in-five production tasks that are high-volume, latency-sensitive, or cost-bound, Sonnet 5 is the correct default: it scores 63.2% on SWE-bench Pro against Opus 4.8's 69.2% — about 91% of the capability — at $2 per million input tokens and $10 per million output tokens during the introductory window through August 31, 2026, roughly 40% of the flagship's price. Reserve Opus 4.8 for the hardest long-horizon problems, the most safety-sensitive agentic deployments, and the coordinator seat in multi-agent systems, where its six-point SWE-bench Pro lead and lower rate of misaligned behavior are worth paying 2.5 times for. This is not a tie of equals; it is a division of labor — Opus 4.8 is the more capable and safer model, Sonnet 5 is the smarter default for most work, and the best architecture usually uses both.
Choose Claude Sonnet 5
Anthropic's most agentic midsize model — near-Opus 4.8 coding and computer use at $2 per million input tokens (introductory through August 2026).
Try Claude Sonnet 5 →Choose Claude Opus 4.8
Anthropic's flagship model for agentic coding, computer use, and multi-agent orchestration.
Try Claude Opus 4.8 →Frequently Asked Questions
Is Claude Sonnet 5 better than Claude Opus 4.8?
Default to Claude Sonnet 5, and escalate to Claude Opus 4.8 by exception. For the roughly four-in-five production tasks that are high-volume, latency-sensitive, or cost-bound, Sonnet 5 is the correct default: it scores 63.2% on SWE-bench Pro against Opus 4.8's 69.2% — about 91% of the capability — at $2 per million input tokens and $10 per million output tokens during the introductory window through August 31, 2026, roughly 40% of the flagship's price. Reserve Opus 4.8 for the hardest long-horizon problems, the most safety-sensitive agentic deployments, and the coordinator seat in multi-agent systems, where its six-point SWE-bench Pro lead and lower rate of misaligned behavior are worth paying 2.5 times for. This is not a tie of equals; it is a division of labor — Opus 4.8 is the more capable and safer model, Sonnet 5 is the smarter default for most work, and the best architecture usually uses both.
Which is cheaper, Claude Sonnet 5 or Claude Opus 4.8?
Claude Sonnet 5 is priced at $2 in / $10 out per M tokens (free plan available). Claude Opus 4.8 is priced at $5 in / $25 out per M tokens. Check the pricing comparison section above for a full breakdown.
What are the main differences between Claude Sonnet 5 and Claude Opus 4.8?
The key differences span across 10 features we compared. For SWE-bench Pro (agentic coding), Claude Sonnet 5 offers 63.2% while Claude Opus 4.8 offers 69.2%. For Input price (per million tokens), Claude Sonnet 5 offers $2 introductory / $3 from Sept 1, 2026 while Claude Opus 4.8 offers $5. For Output price (per million tokens), Claude Sonnet 5 offers $10 introductory / $15 from Sept 1, 2026 while Claude Opus 4.8 offers $25. See the full feature comparison table above for all details.