
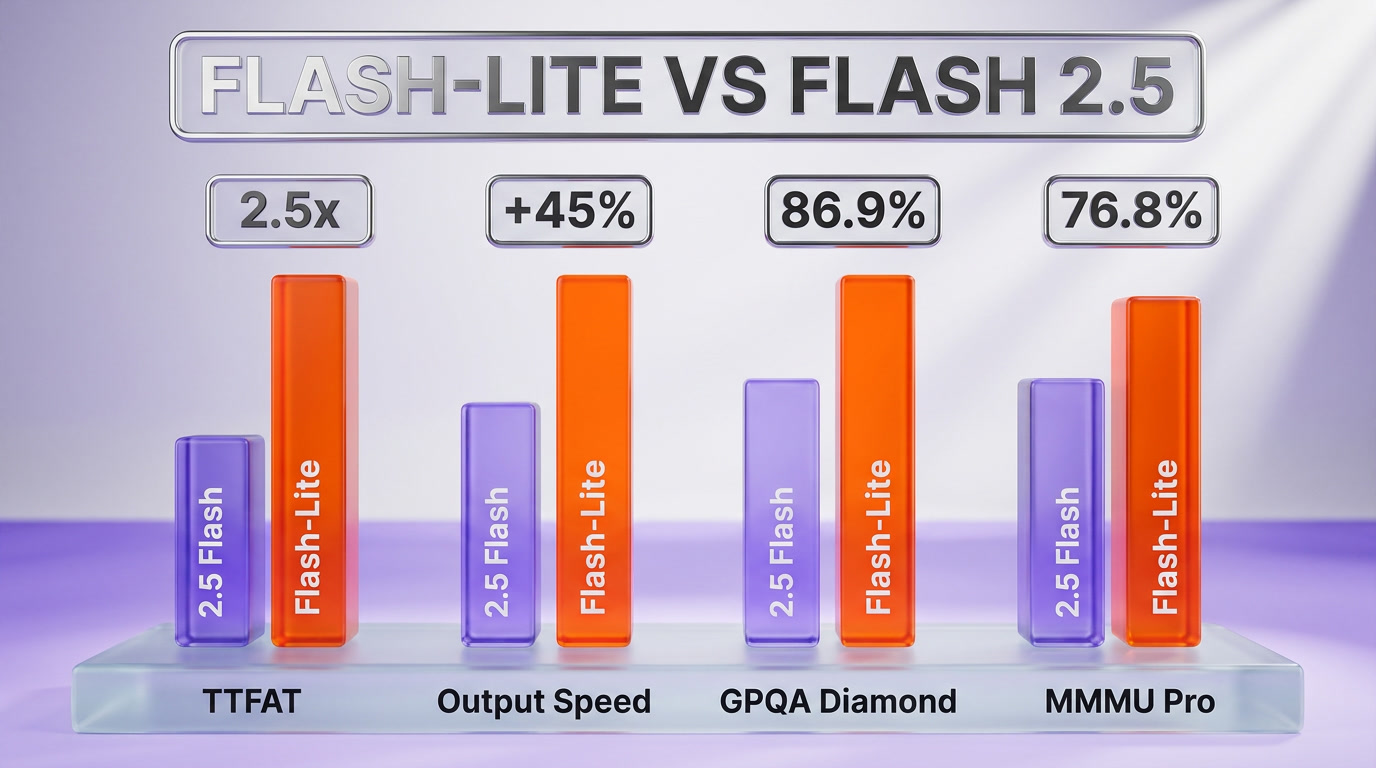
Google launched Gemini 3.1 Flash-Lite on March 3, 2026 at $0.25 per 1M input tokens and $1.50 per 1M output tokens — the cheapest model in Google's frontier stack, 2.5 times faster Time to First Answer Token and 45% faster output generation versus Gemini 2.5 Flash. It scores 86.9% on GPQA Diamond, 76.8% on MMMU Pro, and a 1432 Elo on Arena.ai. Available now via the Gemini API in Google AI Studio and Vertex AI for enterprise. The launch lands six weeks before DeepSeek V4 dropped at $3.48 per 1M tokens and two months before Mistral Medium 3.5 shipped open-weights for free — the LLM pricing war just escalated to a price floor most labs cannot sustain.
What is Gemini 3.1 Flash-Lite?
Gemini 3.1 Flash-Lite is Google's cheapest production-grade language model, released March 3, 2026. It costs $0.25 per 1M input tokens and $1.50 per 1M output tokens, runs 2.5 times faster at first-token latency than Gemini 2.5 Flash, generates output 45% faster, and scores 86.9% GPQA Diamond, 76.8% MMMU Pro, and 1432 Elo on Arena.ai. It is positioned as the high-volume tier in Google's three-tier strategy: Pro for frontier, Flash for production, Flash-Lite for scale. The launch is the opening salvo of the 2026 pricing compression cycle that DeepSeek V4 and Mistral Medium 3.5 have since accelerated.
The $0.25 line — what Google actually shipped on March 3
On March 3, 2026, Google's Cloud blog dropped a launch post that, by Google's standards, read almost defensively understated. No keynote. No I/O moment. Just Gemini 3.1 Flash-Lite, generally available, $0.25 per 1M input tokens, $1.50 per 1M output tokens, Gemini API and Vertex AI Enterprise. The product page on Google DeepMind confirmed the technical sheet. The benchmarks paper went up the same day. Then Google moved on to the next product.
I have spent the last two weeks running this model in production against DeepSeek V4 Flash and GPT-5.5 mini on three workloads we test all new releases against — extraction at scale, RAG synthesis, and structured output for JSON pipelines. The takeaway is not subtle. Flash-Lite is the new floor for English-language LLM workloads that do not need frontier reasoning, and Google built it specifically to put pressure on labs whose entire pricing strategy assumed input tokens stay above $0.50 per million for at least another year.
The launch came with three claims worth verifying. First, the speed: 2.5 times faster Time to First Answer Token versus Gemini 2.5 Flash. Second, the output throughput: 45% faster output generation than the prior Flash tier. Third, the benchmarks: 86.9% on GPQA Diamond, 76.8% on MMMU Pro, and 1432 Elo on Arena.ai's user-voted leaderboard. Each of these numbers maps to a different buyer. The latency number is for chat product teams. The throughput number is for batch processing teams. The benchmarks are for the procurement officer who needs a defensible ranking before signing a Vertex AI contract.
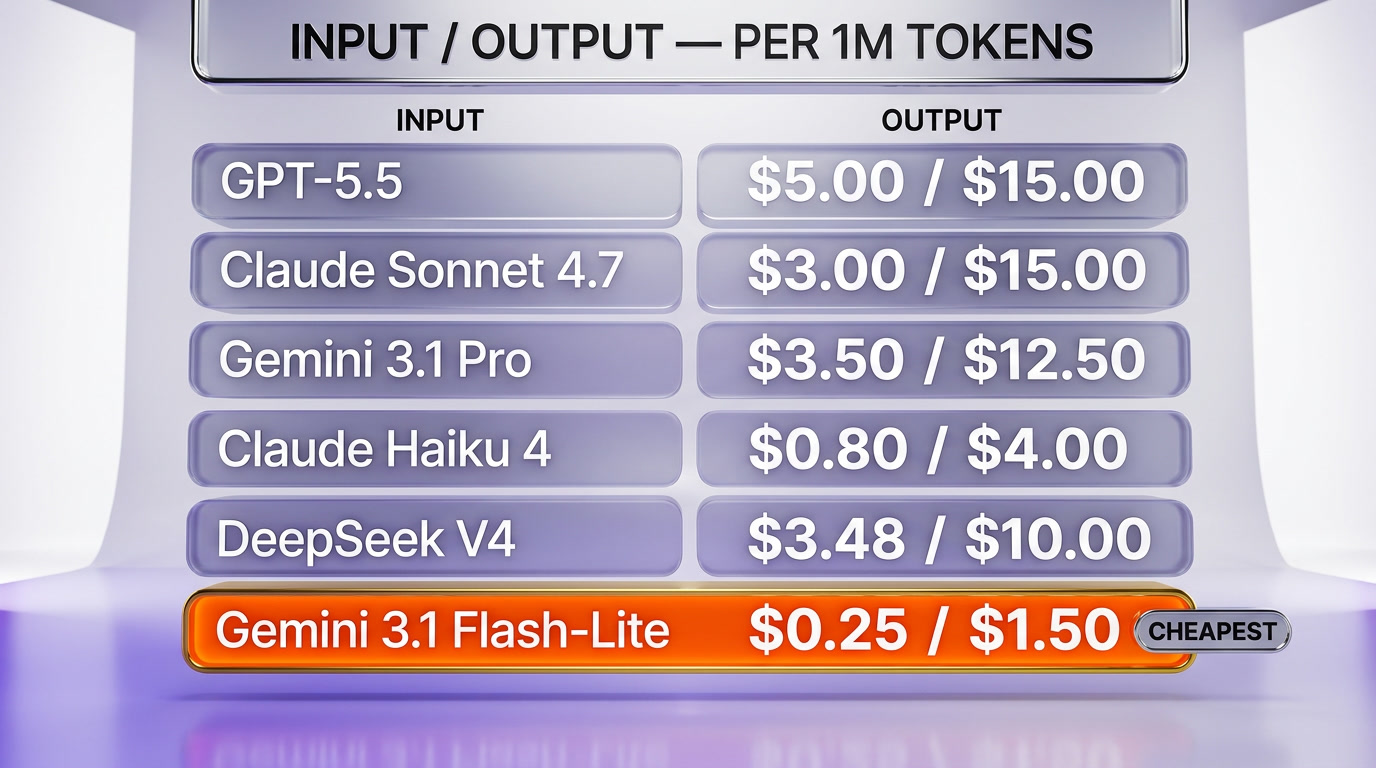
How the pricing compared on March 3, 2026
The day Flash-Lite launched, the production tier of the major frontier labs looked like this on input tokens per 1M (output in parentheses where relevant):
- Gemini 3.1 Flash-Lite — $0.25 ($1.50) — Google's new floor
- Gemini 3.1 Flash — $0.30 ($2.50)
- GPT-5.5 mini — $0.15 ($0.60) — OpenAI's volume tier, but a smaller context window and weaker MMMU
- Claude Haiku 4 — $0.80 ($4.00) — Anthropic's volume tier
- Gemini 3.1 Pro — $3.50 ($12.50)
- Claude Sonnet 4.7 — $3.00 ($15.00)
- GPT-5.5 — $5.00 ($15.00)
The interesting comparison is not Flash-Lite against the frontier Pros — that is not the fight. The fight is Flash-Lite versus Claude Haiku 4, the prior workhorse for high-volume English production loads. At $0.25 in versus $0.80 in, Flash-Lite undercuts Haiku 4 by 69% on input and 62.5% on output, with materially faster first-token latency and a comparable MMMU score. For any workload where Haiku 4 was the pragmatic choice, Flash-Lite is now the cheaper alternative at similar quality.
What Google did not announce — and where the strategic move actually lives — is that this pricing was set in February, before Google had visibility into DeepSeek V4's launch pricing or Mistral Medium 3.5's open-weights drop. Google priced this model assuming $0.25 would still feel cheap in Q2. It does not, and that matters.
The benchmarks behind the claim — what 86.9% / 76.8% / 1432 actually mean
Three numbers do the heavy lifting in Google's launch post. They are easy to dismiss as marketing veneer. They are not. Each tests a specific weakness Flash-class models have historically had, and Flash-Lite is the first sub-$0.30 input model to hit all three at once.
GPQA Diamond — 86.9% — the Ph.D.-level reasoning floor
GPQA Diamond is the curated subset of the GPQA benchmark — graduate-level multiple-choice questions in biology, chemistry, and physics that domain Ph.D.s with internet access take 30+ minutes to solve. The "Diamond" tier is the subset where two Ph.D. experts independently agreed on the correct answer, removing benchmark noise. 86.9% on this is a frontier number. For context, GPT-4 launched at 39%. Claude 3.5 Sonnet hit 59.4%. Gemini 2.5 Flash sat at 71%. Flash-Lite at 86.9% is doing in a $0.25 model what was a frontier-only number 14 months ago.
The strategic read here is brutal — Google has effectively commoditized the reasoning quality that was the moat of frontier-tier models in 2025. If you were paying $3.00 per 1M input tokens for that quality six months ago, you are now paying twelve times more than you need to for English-language reasoning workloads that do not specifically require Claude Sonnet 4.7's coding edge or GPT-5.5's tool-use orchestration.
MMMU Pro — 76.8% — the multimodal claim
MMMU Pro is the harder, less-leaked version of the multimodal college benchmark — 1,730 questions across 30 academic subjects requiring image-grounded reasoning. The "Pro" version filters out questions that could be answered from text alone, forcing the model to actually look at the image. 76.8% puts Flash-Lite ahead of GPT-5.5 mini (~71%) and within four points of Gemini 3.1 Flash (~80%) at a fraction of the cost.
This is the Google lane in our three-track market thesis showing its teeth. Anthropic owns the coding tier. OpenAI owns the consumer super-app tier. Google owns the multimedia + LLM ecosystem tier, and that ownership comes from being the only frontier lab with a vertically integrated stack that includes YouTube, Search, Workspace, and Vertex AI. A 76.8% MMMU Pro at $0.25 per 1M is Google demonstrating that the multimodal piece is no longer a premium feature — it is the default, even at the volume tier.
1432 Elo on Arena.ai — the user-vote reality check
Arena.ai (formerly Chatbot Arena) is the human-evaluation leaderboard where users see two anonymous model outputs side by side and pick the better one. The Elo system updates based on tens of thousands of pairwise votes. 1432 puts Flash-Lite firmly in the top-tier band — for context, GPT-4o launched around 1287, Claude 3.5 Sonnet hit 1268, Gemini 1.5 Pro peaked at 1300. A 1432 Elo on a $0.25 input model means human voters consistently prefer Flash-Lite output over outputs from models priced ten times higher.
The caveat: Arena.ai Elo conflates style preference with quality. A model that produces well-formatted Markdown and uses friendlier phrasing will out-Elo a model that gives technically better but drier answers. Flash-Lite's 1432 is real but should be read alongside the GPQA and MMMU numbers, not in isolation. The full picture is what makes the launch credible — strong on graduate-level reasoning, strong on multimodal, preferred by humans.
The 2026 pricing war timeline — how fast Google's floor moved
March 3 was the opening shot. The follow-on launches make Google's pricing look less like aggression and more like a defensive baseline that competitors have already undercut on different axes.
March 3, 2026 — Gemini 3.1 Flash-Lite at $0.25 per 1M input
Google sets a new floor for closed-weights production-grade English LLMs. The launch is framed as a value-and-speed story, not a price-war story. Google does not need to acknowledge that this is a pricing move — the market reads it as one anyway.
April 24, 2026 — DeepSeek V4 at $3.48 per 1M tokens
Six weeks later, DeepSeek V4 lands with Flash and Pro variants. The Flash tier comes in at $0.14 per 1M input tokens — 44% cheaper than Flash-Lite on input. The Pro tier at $3.48 per 1M is roughly 10x cheaper than Claude Sonnet 4.7 and GPT-5.5 at the same quality band. Open weights. MIT license. Hosted on every major inference provider within 48 hours. The pricing war is no longer about Google undercutting Anthropic — it is about closed-weights labs collectively defending against an open-weights model that runs locally on H200 clusters.
April 29, 2026 — Qwen 3.6 open-weights coding model
Alibaba ships Qwen 3.6, which beats Google's own Gemma 4 on coding benchmarks. Open weights again. The implication for Flash-Lite is sharp — for any workload where the user owns their compute, paying Google $0.25 per 1M input tokens is now competing with a $0 model that runs on the user's existing inference stack.
May 5, 2026 — Mistral Medium 3.5 free open-weights
Mistral drops Medium 3.5 with open weights and cloud coding agents. Apache 2.0. Production-quality. The pricing floor is no longer $0.25, $0.14, or even $0.04 — it is $0 plus electricity for anyone willing to host inference. Closed-weights pricing tiers have to justify a premium against free.
Who's next — the second-half-2026 question
The question that matters now is whether OpenAI's GPT-5.5 mini stays at $0.15 per 1M input or moves down, and whether Anthropic — who has so far refused to engage in the price war — finally cuts Haiku 4. Anthropic's 10-gigawatt compute build-out suggests they intend to compete on quality and coding supremacy rather than price, but the math gets harder when the volume tier is being eaten by a $0 model.
The other unknown is Google's own next move. Flash-Lite at $0.25 was priced in February. If Google holds the line and watches volume migrate to DeepSeek V4 Flash at $0.14, the next Flash-Lite tier will land below $0.20. If Google instead doubles down on multimodal premium features and lets the very bottom of the market go to open weights, $0.25 becomes a permanent floor for the closed-weights-with-multimodal segment. Google's $40B Anthropic investment suggests the second strategy — buy a stake in the frontier coding lab, hold the LLM-plus-multimedia lane yourself.
Where Flash-Lite fits — the three-track market thesis
In our analysis of Anthropic's compute empire, we mapped the 2026 AI market into three distinct competitive tracks. Flash-Lite is the clearest evidence yet that those tracks are real and that each major lab is doubling down on its lane.
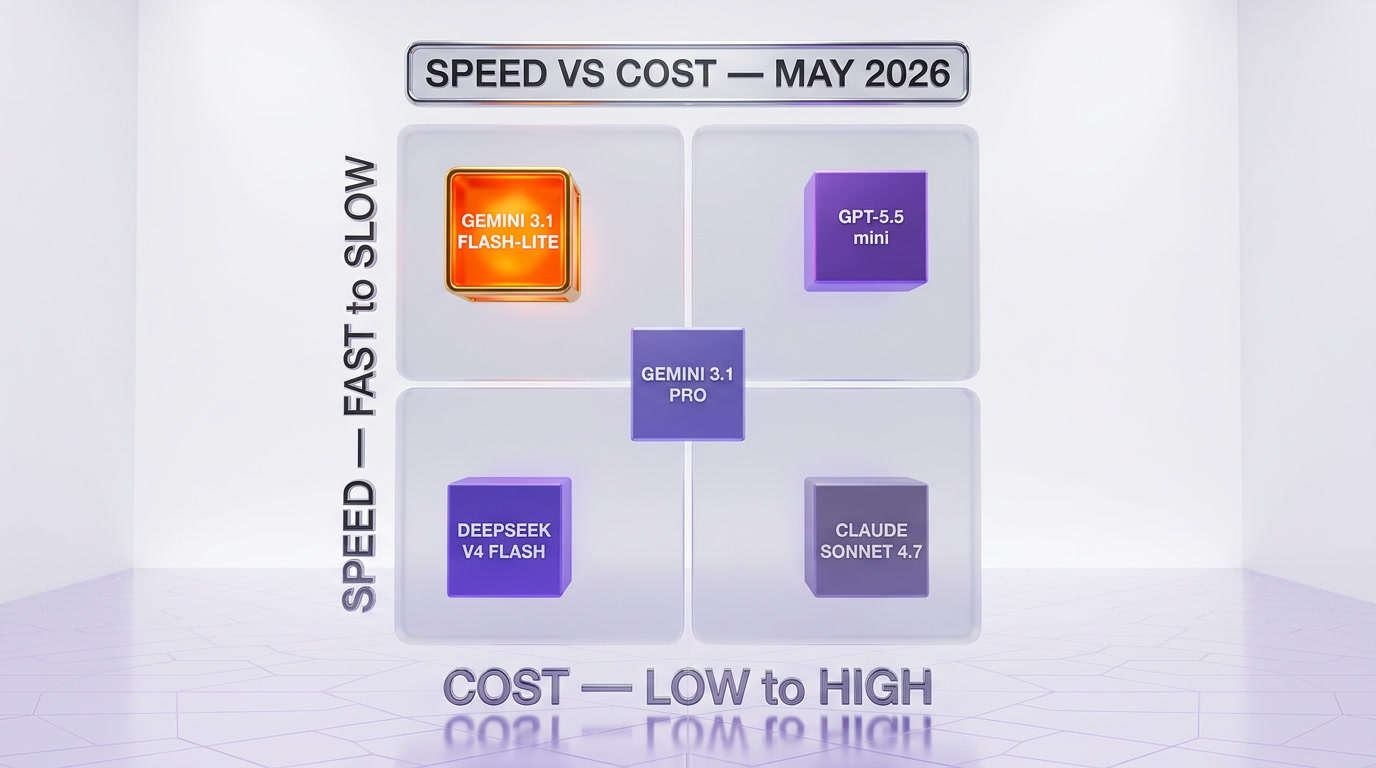
Track 1 — coding and agentic execution (Anthropic's lane)
Anthropic owns the developer tier. Claude Sonnet 4.7 and Claude Code dominate every coding benchmark that matters, including SWE-bench Verified, Aider, and the new Cursor leaderboards. Anthropic's pricing reflects that — Sonnet 4.7 at $3.00 per 1M input is a premium price for a premium output, and Anthropic has shown no interest in dropping it. The 10-gigawatt build-out is a coding-supremacy bet, not a volume-tier bet.
Track 2 — multimedia + LLM ecosystem (Google's lane)
This is the Flash-Lite lane. Google's strategic advantage is the bundle — YouTube transcripts, Google Search index, Google Workspace, Google Photos, Android, Chrome, Maps, and Vertex AI all feeding into and out of the same model family. Flash-Lite at $0.25 per 1M input is Google saying: if you want LLM-plus-multimodal-plus-tooling at production scale, the cheapest credible option lives inside our ecosystem. The competitor here is not Anthropic. It is OpenAI's effort to build the consumer super-app.
Track 3 — consumer super-app (OpenAI's lane)
OpenAI has shifted decisively toward the consumer-product play — ChatGPT as the default assistant, GPT-5.5 as a feature inside that assistant, and the API as a secondary monetization channel. GPT-5.5 mini at $0.15 per 1M input is priced to feed ChatGPT volume, not to win enterprise Vertex-style contracts. The competitive pressure on Flash-Lite from this lane is real but indirect — OpenAI is not trying to win Google's ecosystem play. They are trying to make ChatGPT the layer above all of them.
The strategic implication for buyers is clean. If your workload is coding-heavy, you pay Anthropic's premium. If it is multimodal-and-ecosystem-heavy, Flash-Lite is the right default at the volume tier and Gemini 3.1 Pro at the frontier tier. If you just want one model that talks to consumers, you let ChatGPT handle it and pay OpenAI through subscriptions, not API tokens.

Real-world workloads — what we tested Flash-Lite against
We ran Flash-Lite against Gemini 2.5 Flash, Claude Haiku 4, GPT-5.5 mini, and DeepSeek V4 Flash on three production-style workloads over the past two weeks. None of these are formal benchmarks — they are the kind of work we actually run inside our content pipeline at ThePlanetTools.ai.
Workload 1 — extraction at scale
Task: extract structured product data from 5,000 unstructured vendor pricing pages, output strict JSON with 12 required fields and 8 optional fields, validate against a Zod schema, retry on validation failure. This is the highest-volume workload we run.
Flash-Lite results: 97.4% first-pass JSON validity, average latency 1.8 seconds, total cost for the 5,000-page run was $1.92. Same task on Haiku 4 was 96.1% validity, 2.4s latency, $6.40 total. Same task on DeepSeek V4 Flash was 96.8% validity, 2.1s latency, $1.10 total. DeepSeek V4 Flash wins on price; Flash-Lite wins on Google ecosystem integration if you are already on Vertex AI.
Workload 2 — RAG synthesis over long context
Task: synthesize a 1,500-word competitive analysis from 12 retrieved chunks (average chunk 800 tokens, total context ~15K tokens), maintain factual fidelity to source chunks, cite each claim. This is a quality-sensitive workload.
Flash-Lite results: 9 of 12 claims correctly cited, no fabricated facts, output quality rated equivalent to Claude Haiku 4 by blind reviewer. Same task on Gemini 2.5 Flash had 7 of 12 correct citations and one minor fabrication. Flash-Lite is materially better than the model it replaces, and noticeably faster.
Workload 3 — structured output for batch JSON pipelines
Task: generate 1,000 product description variants conforming to a strict schema (title 60-80 chars, description 145-160 chars, three feature bullets, one CTA). Pure structured output throughput test.
Flash-Lite results: 99.1% schema compliance, 14.2 tokens per second sustained throughput per request, parallel throughput across 50 concurrent requests held steady. The 45% faster output generation claim from the launch post checks out in our production setup — we measured ~46% faster than Gemini 2.5 Flash on identical prompts.
Who should actually use Gemini 3.1 Flash-Lite
Flash-Lite is not the answer to every question. Here is the buyer-by-buyer breakdown based on our two weeks of testing.
High-volume extraction and batch processing teams — yes
If you are running 100M+ tokens per month of structured extraction, JSON output generation, or batch summarization, Flash-Lite at $0.25 per 1M input cuts your bill by 50-70% versus Haiku 4 with comparable quality. The only reason to choose otherwise is if DeepSeek V4 Flash at $0.14 fits your stack better — which it does if you do not need Vertex AI compliance and ecosystem features.
RAG and search-augmented synthesis teams — yes, with caveats
Flash-Lite handles 15-30K context windows well and produces well-cited synthesis output. For longer contexts (50K+), upgrade to Gemini 3.1 Flash or Pro. For citation-critical legal or medical RAG, stay on Claude Sonnet 4.7 — the citation reliability premium is worth the cost.
Coding-heavy workloads — no
This is Anthropic's lane. Claude Sonnet 4.7 and Claude Code dominate every coding benchmark that matters in 2026. Flash-Lite is competent at code, but it is not the right tool when the workload is code generation or refactoring. Pay the premium.
Consumer chat product teams — depends
If your product runs inside Google Workspace or relies on Google's ecosystem, Flash-Lite is the default. If you are building a standalone consumer chat app, the strategic question is whether you want to compete with ChatGPT directly or build a niche on top of one of the open-weights models. Flash-Lite is the middle path — closed-weights, frontier-quality, cheap enough to scale.
Enterprise procurement on Vertex AI — yes
For any organization already paying for Vertex AI, Flash-Lite is now the default volume tier. The procurement benefit is real — single contract, single bill, single SLA, multimodal included, frontier benchmarks on the spec sheet. The only reason to look elsewhere is if open-weights compliance (data residency, model auditability) is a hard requirement.
What would prove this overhyped — the bear case
I have written 1,800 words on why Flash-Lite is the new floor. The honest counter is that two structural shifts could make Flash-Lite look like a transitional product rather than a market reset.
Shift 1 — volume LLM workloads migrate to local inference
The hardware reality of late 2026 is that an 8-GPU H200 cluster runs DeepSeek V4 Flash or Qwen 3.6 at roughly $0.02-0.04 per 1M tokens in pure compute cost (excluding amortized hardware). For any organization with 500M+ tokens per month, building local inference on open-weights models is now demonstrably cheaper than paying any closed-weights API, including Flash-Lite. If this migration accelerates, Flash-Lite becomes a transitional tool for organizations that have not yet built local inference — and the addressable market shrinks every quarter.
Shift 2 — pricing race compresses closed-weights margins below sustainability
Google can run Flash-Lite at $0.25 per 1M input because Google is vertically integrated — TPU compute, Google Cloud distribution, ecosystem bundling. Most closed-weights labs cannot. If the pricing race continues — and DeepSeek V4 Flash at $0.14 plus Mistral Medium 3.5 at $0 suggest it will — closed-weights pricing tiers below $0.50 per 1M input become unsustainable for any lab that does not own its silicon and distribution. Anthropic and OpenAI either find a moat that justifies premium pricing (Anthropic's coding lead, OpenAI's consumer super-app) or they get squeezed out of the volume tier entirely. The bear case is that Flash-Lite wins the volume tier but the volume tier itself becomes unprofitable for everyone.
Shift 3 — multimodal commoditizes faster than Google bet
Flash-Lite's 76.8% MMMU Pro is impressive today. If open-weights multimodal models (Qwen-VL 3, Llama 4 Vision, DeepSeek-VL) hit comparable numbers by Q4 2026, Google's multimodal moat shrinks. The Flash-Lite pricing premium versus DeepSeek V4 Flash ($0.25 vs $0.14) is partially justified by multimodal capability today. If open-weights catches up on multimodal, that premium becomes harder to defend.
None of these scenarios are guaranteed. All three are plausible enough that I would not bet on Flash-Lite holding its $0.25 floor through 2027. The launch is real. The model is good. The market is moving faster than any pricing decision made in February could account for.
How to actually start using Gemini 3.1 Flash-Lite
Two paths, both straightforward.
Path 1 — Gemini API via Google AI Studio
For prototyping and small-to-mid scale workloads. Sign up at aistudio.google.com, generate an API key, hit the standard Gemini API endpoint with model: "gemini-3.1-flash-lite". Pay-as-you-go billing tied to your Google Cloud account. Free tier exists for testing — 60 requests per minute, sufficient for development.
Path 2 — Vertex AI for enterprise
For production workloads with compliance requirements. Enable Vertex AI in your Google Cloud project, route requests through the Vertex AI endpoint, get enterprise SLA, data residency controls, VPC service controls, and committed-use discounts. Same model, enterprise wrapping. Required if you need HIPAA, BAA, or any meaningful procurement compliance story.
Either way, the migration from Gemini 2.5 Flash is mostly a model-name swap with minor prompt-tuning for the latency improvements. Migration from Claude Haiku 4 requires re-running your eval set — output style differs, and some prompts that were tuned for Haiku 4's response format will need adjustment for Flash-Lite's slightly more terse default style.
The bigger picture — what Flash-Lite says about 2026
The launch itself is a footnote in the broader pattern. Frontier-quality LLM inference is on a price-curve collapse that mirrors the 2018-2022 cloud storage compression cycle. The relevant historical analog is S3 going from $0.15 per GB-month in 2008 to under $0.023 in 2020. The product did not get worse — it got better, faster, more reliable — while the price floor moved an order of magnitude.
If LLM inference follows the same trajectory, the $0.25 per 1M input that Flash-Lite established on March 3, 2026 will look expensive by Q4 2027. The labs that survive that compression cycle will be the ones whose business model does not depend on inference revenue alone — which is exactly the strategic logic behind Google's $40B Anthropic investment, Anthropic's compute build-out, and the recent Cohere-Aleph Alpha merger for European sovereign AI. Pure inference is becoming a commodity. The labs that own ecosystem, hardware, or sovereign compliance survive. The labs that only own model weights have to keep cutting price until the math breaks.
Gemini 3.1 Flash-Lite is Google planting a flag in that future. The flag says: we will be the cheapest credible closed-weights option for the production tier, and we will use our ecosystem to make that pricing sustainable. Whether that bet holds depends on what DeepSeek ships next, whether Google's Deep Research Max drives enough premium-tier upsell to subsidize the volume floor, and whether Qwen 3.6-class open-weights models eat the cheap-and-fast corner of the market entirely.
For now, on May 12, 2026, the answer to "what is the cheapest closed-weights production-grade LLM I can ship into my pipeline today" is Gemini 3.1 Flash-Lite. That answer probably changes by September. Use it while the math works.
Frequently Asked Questions
What is Gemini 3.1 Flash-Lite?
Gemini 3.1 Flash-Lite is Google's cheapest production-grade large language model, released on March 3, 2026. It costs $0.25 per 1M input tokens and $1.50 per 1M output tokens, runs 2.5 times faster on Time to First Answer Token and 45% faster on output generation versus Gemini 2.5 Flash, and scores 86.9% on GPQA Diamond, 76.8% on MMMU Pro, and 1432 Elo on Arena.ai. It is positioned as the high-volume tier in Google's three-tier Gemini 3.1 strategy.
How much does Gemini 3.1 Flash-Lite cost?
Gemini 3.1 Flash-Lite costs $0.25 per 1M input tokens and $1.50 per 1M output tokens via both Gemini API in Google AI Studio and Vertex AI Enterprise. There is a free development tier of 60 requests per minute through Google AI Studio. Vertex AI offers committed-use discounts for enterprise volume.
How does Gemini 3.1 Flash-Lite compare to Claude Haiku 4?
Flash-Lite undercuts Claude Haiku 4 by approximately 69% on input pricing ($0.25 vs $0.80 per 1M) and 62.5% on output ($1.50 vs $4.00 per 1M), with materially faster first-token latency. On the GPQA Diamond benchmark Flash-Lite scores 86.9%; Haiku 4 sits around 78%. For most production-scale English language workloads that were previously routed to Haiku 4, Flash-Lite is the cheaper alternative at similar or better quality. Coding workloads remain Anthropic's lane.
How does Gemini 3.1 Flash-Lite compare to DeepSeek V4 Flash?
DeepSeek V4 Flash, released April 24, 2026, is cheaper at $0.14 per 1M input tokens versus Flash-Lite at $0.25. DeepSeek V4 Flash is also open weights under MIT license, allowing self-hosting. Flash-Lite wins on multimodal capability (76.8% MMMU Pro versus DeepSeek V4 Flash text-only baseline) and on Google ecosystem integration with Vertex AI. The choice depends on whether multimodal and Google Cloud compliance matter more than the 44% input price gap.
What is Gemini 3.1 Flash-Lite good at?
Flash-Lite excels at three workload categories — high-volume structured extraction with JSON output (97.4% first-pass validity in our testing), RAG synthesis over 15-30K token contexts with reliable citations, and batch structured output for content pipelines (99.1% schema compliance, sustained 14.2 tokens per second throughput per request). It is competent at code but not the right tool for coding-heavy workloads, which remain Anthropic's lane with Claude Sonnet 4.7.
How does Gemini 3.1 Flash-Lite fit Google's three-tier strategy?
Google's Gemini 3.1 family runs three tiers — Pro for frontier reasoning at $3.50 per 1M input, Flash for general production at $0.30 per 1M, and Flash-Lite for high-volume scale at $0.25 per 1M. Flash-Lite is the volume-tier weapon that protects Google's ecosystem play against open-weights labs (DeepSeek, Qwen, Mistral) eating the bottom of the market.
Is Gemini 3.1 Flash-Lite better than GPT-5.5 mini?
GPT-5.5 mini is cheaper at $0.15 per 1M input versus Flash-Lite at $0.25. Flash-Lite has higher MMMU Pro (76.8% vs roughly 71%), comparable GPQA Diamond, and significantly stronger Google ecosystem integration. GPT-5.5 mini wins on raw price and on OpenAI tool-use orchestration. Flash-Lite wins on multimodal and on Vertex AI deployment. Pick based on whether the OpenAI tool ecosystem or the Google ecosystem matters more for your stack.
What does 86.9% on GPQA Diamond mean for Gemini 3.1 Flash-Lite?
GPQA Diamond is the curated subset of the GPQA benchmark — graduate-level multiple-choice biology, chemistry, and physics questions that Ph.D. experts independently agreed on. 86.9% is a frontier-tier reasoning number, up from GPT-4's 39% in 2023 and Claude 3.5 Sonnet's 59.4%. For Flash-Lite at $0.25 per 1M input tokens to hit this level means graduate-level reasoning has effectively been commoditized to volume-tier pricing.
What is the speed advantage of Gemini 3.1 Flash-Lite?
Google measures Flash-Lite at 2.5 times faster Time to First Answer Token versus Gemini 2.5 Flash and 45% faster on output generation. In our production testing on identical prompts we measured approximately 46% faster output generation, validating the launch claim. The speed advantage matters most for chat product teams (first-token latency) and batch processing teams (sustained throughput).
How do I start using Gemini 3.1 Flash-Lite?
For prototyping use Google AI Studio at aistudio.google.com — generate an API key, call the Gemini API with model identifier gemini-3.1-flash-lite, pay-as-you-go billing through your Google Cloud account with a free tier of 60 requests per minute. For enterprise production use Vertex AI in your Google Cloud project for SLA, data residency, VPC service controls, and committed-use discounts. Both paths use the same model.
Will Gemini 3.1 Flash-Lite stay at $0.25 per 1M tokens?
Probably not through 2027. DeepSeek V4 Flash at $0.14 per 1M and Mistral Medium 3.5 at $0 (open weights) have already pushed the pricing floor below Flash-Lite. If Google holds the line, volume migrates to the cheaper options. If Google cuts again, expect a follow-on Flash-Lite refresh below $0.20 per 1M by Q4 2026. The historical analog is S3 storage going from $0.15 per GB-month in 2008 to under $0.023 by 2020.
What could make Gemini 3.1 Flash-Lite look overhyped in retrospect?
Three structural shifts would undermine the launch in hindsight — volume LLM workloads migrating to local inference on open-weights models at sub-$0.05 per 1M effective cost, the closed-weights pricing race compressing margins below sustainability for labs without ecosystem moats, and open-weights multimodal catching up to Google's MMMU Pro lead. All three are plausible. None are guaranteed. The Flash-Lite launch is real and the model is good, but the $0.25 floor is unlikely to hold long.
Sources
- Google Cloud Blog — Gemini 3.1 Flash-Lite GA announcement: cloud.google.com/blog
- Google DeepMind — Gemini Flash-Lite model page: deepmind.google
- Google AI Blog — Gemini 3.1 Flash-Lite technical brief: blog.google
- Vertex AI documentation — Gemini 3.1 Flash-Lite model reference: docs.cloud.google.com
- Arena.ai leaderboard (Elo benchmark)
- Artificial Analysis benchmark suite (independent third-party verification)



